
Latar belakang
Kebetulan server diserang oleh virus ransomware, yang, oleh "kebetulan", sebagian menyisihkan file .ibd (file data mentah tabel innodb), tetapi sepenuhnya mengenkripsi file .fpm (file struktur). Pada saat yang sama .idb dapat dibagi menjadi:
- dapat dipulihkan melalui alat dan panduan standar. Untuk kasus seperti itu, ada artikel bagus;
- sebagian tabel terenkripsi. Sebagian besar ini adalah tabel besar, yang (seperti yang saya mengerti), para penyerang tidak memiliki cukup RAM untuk enkripsi penuh;
- Nah, tabel sepenuhnya terenkripsi yang tidak dapat dipulihkan.
Dimungkinkan untuk menentukan opsi mana tabel milik dengan membuka di editor teks apa pun di bawah pengkodean yang diinginkan (dalam kasus saya itu adalah UTF8) dan hanya melihat file untuk keberadaan bidang teks, misalnya:
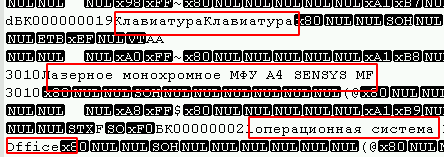
Juga, di awal file Anda dapat mengamati sejumlah besar 0-byte, dan virus yang menggunakan algoritma enkripsi blok (yang paling umum) biasanya memengaruhi mereka.

Dalam kasus saya, penyerang di akhir setiap file terenkripsi meninggalkan string 4 byte (1, 0, 0, 0), yang menyederhanakan tugas. Sebuah skrip sudah cukup untuk mencari file yang tidak terinfeksi:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
Jadi ternyata menemukan file milik tipe pertama. Yang kedua menyiratkan manual yang panjang, tetapi sudah ditemukan sudah cukup. Semuanya akan baik-baik saja, tetapi perlu mengetahui struktur yang benar - benar tepat dan (tentu saja) ada kasus seperti itu sehingga saya harus bekerja dengan tabel yang sering berubah. Tidak ada yang ingat apakah jenis bidang itu berubah, atau kolom baru sedang ditambahkan.
Sayangnya, Debri City tidak dapat membantu dengan kasus ini, oleh karena itu artikel ini sedang ditulis.
Langsung ke intinya
Ada struktur tabel 3 bulan lalu yang tidak bertepatan dengan yang sekarang (mungkin satu bidang, tetapi mungkin lebih). Struktur meja:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
dalam hal ini, Anda perlu mengekstrak:
id_point INT (11);id_user INT (11);date_start DATETIME;date_finish DATETIME.
Untuk pemulihan, analisis byte file .ibd digunakan, diikuti dengan terjemahannya dalam bentuk yang lebih mudah dibaca. Karena untuk menemukan apa yang diperlukan, cukup bagi kita untuk menganalisis tipe data seperti int dan data, hanya saja mereka akan dijelaskan dalam artikel, tetapi kadang-kadang mereka juga akan merujuk pada tipe data lain, yang dapat membantu dalam insiden serupa lainnya.
Masalah 1 : bidang dengan tipe DATETIME dan TEXT memiliki nilai NULL, dan mereka hanya dilewati dalam file, karena ini, tidak mungkin untuk menentukan struktur untuk pemulihan dalam kasus saya. Di kolom baru, nilai defaultnya adalah nol, dan beberapa transaksi bisa hilang karena pengaturan innodb_flush_log_at_trx_commit = 0, jadi waktu tambahan harus dihabiskan untuk menentukan struktur.
Masalah 2 : harus dicatat bahwa baris yang dihapus melalui DELETE semua akan persis di file ibd, tetapi dengan ALTER TABLE struktur mereka tidak akan diperbarui. Akibatnya, struktur data dapat bervariasi dari awal file hingga akhirnya. Jika Anda sering menggunakan OPTIMIZE TABLE, Anda tidak akan menemui masalah serupa.
Harap perhatikan bahwa versi DBMS memengaruhi cara data disimpan, dan contoh ini mungkin tidak berfungsi untuk versi utama lainnya. Dalam kasus saya, windows versi mariadb 10.1.24 digunakan. Juga, meskipun dalam mariadb Anda bekerja dengan tabel InnoDB, sebenarnya mereka XtraDB , yang mengecualikan penerapan metode dengan InnoDB mysql.
Analisis file
Dalam python, tipe data byte () menampilkan data dalam Unicode, bukan set angka yang biasa. Meskipun Anda dapat mempertimbangkan file dalam formulir ini, tetapi untuk kenyamanan, Anda dapat menerjemahkan byte ke dalam bentuk numerik dengan menerjemahkan array byte ke dalam array biasa (daftar (example_byte_array)). Bagaimanapun, kedua metode berguna untuk analisis.
Setelah melihat beberapa file ibd, Anda dapat menemukan yang berikut:
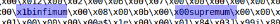
Selain itu, jika Anda membagi file dengan kata kunci ini, Anda akan mendapatkan sebagian besar blok data datar. Kami akan menggunakan infimum sebagai pembagi.
table = table.split("infimum".encode())
Pengamatan yang menarik, untuk tabel dengan sejumlah kecil data, antara infimum dan supremum ada penunjuk ke jumlah baris di blok.
 - Meja tes dengan baris ke-1
- Meja tes dengan baris ke-1
 - Meja tes dengan 2 baris
- Meja tes dengan 2 baris
Array tabel baris [0] dapat dilewati. Setelah melihatnya, saya masih tidak dapat menemukan data mentah dari tabel. Kemungkinan besar, blok ini digunakan untuk menyimpan indeks dan kunci.
Dimulai dengan tabel [1] dan menerjemahkannya ke dalam array numerik, Anda sudah dapat melihat beberapa pola, yaitu:

Ini adalah nilai int yang disimpan dalam string. Byte pertama menunjukkan apakah angka itu positif atau negatif. Dalam kasus saya, semua angka positif. Dari 3 byte yang tersisa, Anda dapat menentukan angka menggunakan fungsi berikut. Skrip:
def find_int(val: str):
Misalnya, 128, 0, 0, 1 = 1 , atau 128, 0, 75, 108 = 19308 .
Tabel memiliki kunci utama dengan penambahan otomatis, dan di sini Anda juga dapat menemukannya

Membandingkan data dari tabel uji, terungkap bahwa objek DATETIME terdiri dari 5 byte, dimulai dengan 153 (kemungkinan besar menunjukkan interval tahunan). Karena rentang DATTIME adalah '1000-01-01' hingga '9999-12-31', saya pikir jumlah byte dapat bervariasi, tetapi dalam kasus saya, data jatuh pada periode dari 2016 hingga 2019, jadi kami menganggap bahwa 5 byte sudah cukup .
Untuk menentukan waktu tanpa detik, fungsi-fungsi berikut ditulis. Skrip:
day_ = lambda x: x % 64 // 2
Selama satu tahun dan satu bulan, tidak mungkin untuk menulis fungsi kerja yang sehat, jadi saya harus melakukan hardcode. Skrip:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
Saya yakin bahwa jika Anda menghabiskan banyak waktu, maka kesalahpahaman ini dapat diperbaiki.
Selanjutnya, fungsi mengembalikan objek datetime dari string. Skrip:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
Itu mungkin untuk mendeteksi nilai yang sering diulang dari int, int, datetime, datetime 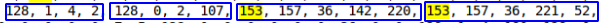 Tampaknya inilah yang Anda butuhkan. Selain itu, urutan seperti itu tidak diulang dua kali per baris.
Tampaknya inilah yang Anda butuhkan. Selain itu, urutan seperti itu tidak diulang dua kali per baris.
Menggunakan ekspresi reguler, kami menemukan data yang diperlukan:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
Harap perhatikan bahwa saat mencari dengan ungkapan ini, tidak akan mungkin untuk menentukan nilai NULL di bidang yang diperlukan, tetapi dalam kasus saya ini tidak penting. Setelah kami mengulangi ditemukan. Skrip:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
Sebenarnya semuanya, data dari array hasil, ini adalah data yang kami butuhkan. ### PS. ###
Saya memahami bahwa metode ini tidak cocok untuk semua orang, tetapi tujuan utama dari artikel ini adalah untuk meminta tindakan daripada menyelesaikan semua masalah Anda. Saya pikir solusi yang paling tepat adalah mulai mempelajari kode sumber mariadb itu sendiri, tetapi karena waktu yang terbatas, metode saat ini tampaknya yang tercepat.
Dalam beberapa kasus, setelah menganalisis file, Anda dapat menentukan struktur perkiraan dan mengembalikan salah satu metode standar dari tautan di atas. Itu akan jauh lebih benar dan menyebabkan lebih sedikit masalah.