Halo, para pembaca Habr. Nama saya Rustem dan saya adalah pengembang utama di perusahaan IT Kazakhstani DAR. Pada artikel ini saya akan memberi tahu Anda apa yang perlu Anda ketahui sebelum pindah ke Peristiwa Sumber dan template CQRS menggunakan toolkit Akka.
Sekitar 2015, kami mulai merancang ekosistem kami. Setelah analisis dan berdasarkan pengalaman dengan Scala dan Akka, kami memutuskan untuk berhenti di toolkit Akka. Kami memiliki implementasi sukses dari templat Sourcing Acara dengan CQRS dan tidak demikian. Akumulasi keahlian di bidang ini, yang ingin saya bagikan dengan pembaca. Kita akan melihat bagaimana Akka menerapkan pola-pola ini, serta alat apa yang tersedia dan berbicara tentang perangkap Akka. Saya harap setelah membaca artikel ini, Anda akan lebih memahami risiko beralih ke Akka toolkit.
Pada subjek CQRS dan Event Sourcing banyak artikel tentang Habré dan sumber daya lainnya ditulis. Artikel ini ditujukan untuk pembaca yang sudah mengerti apa itu CQRS dan Event Sourcing. Dalam artikel itu saya ingin berkonsentrasi pada Akka.
Desain berbasis domain
Banyak materi telah ditulis tentang Desain Domain-Driven (DDD). Ada lawan dan pendukung dari pendekatan ini. Saya ingin menambahkan sendiri bahwa jika Anda memutuskan untuk beralih ke Event Sourcing dan CQRS, maka tidak akan berlebihan untuk mempelajari DDD. Selain itu, filosofi DDD sangat terasa di semua alat Akka.
Faktanya, Event Sourcing dan CQRS hanyalah sebagian kecil dari gambaran besar yang disebut Domain-Driven Design. Saat merancang dan mengembangkan, Anda mungkin memiliki banyak pertanyaan tentang bagaimana menerapkan pola-pola ini dengan baik dan mengintegrasikan ke dalam ekosistem, dan mengetahui DDD akan membuat hidup Anda lebih mudah.
Dalam artikel ini, istilah entitas (entitas oleh DDD) akan berarti Aktor Kegigihan yang memiliki pengidentifikasi unik.
Mengapa scala?
Kita sering ditanya mengapa Scala, dan bukan Java. Salah satu alasannya adalah Akka. Kerangka kerja itu sendiri, ditulis dalam bahasa Scala dengan dukungan untuk bahasa Jawa. Di sini saya harus mengatakan bahwa ada juga implementasi di .NET , tetapi ini adalah topik lain. Agar tidak menimbulkan diskusi, saya tidak akan menulis mengapa Scala lebih baik atau lebih buruk daripada Java. Saya hanya akan memberi tahu Anda beberapa contoh bahwa, menurut pendapat saya, Scala memiliki keunggulan dibandingkan Jawa ketika bekerja dengan Akka:
- Benda yang tidak bisa berubah. Di Jawa, Anda perlu menulis sendiri objek yang tidak dapat diubah. Percayalah, tidak mudah dan tidak nyaman untuk selalu menulis parameter akhir. Dalam
case class Scala sudah tidak dapat diubah dengan fungsi copy bawaan - Gaya pengkodean. Ketika diimplementasikan di Jawa, Anda masih akan menulis dalam gaya Scala, yaitu secara fungsional.
Berikut adalah contoh implementasi aktor di Scala dan Java:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Jawa:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(Contoh diambil dari sini )
Perhatikan implementasi metode createReceive() menggunakan contoh bahasa Java. Secara internal, melalui pabrik ReceiveBuilder , pencocokan pola diterapkan. receiveBuilder() adalah metode dari Akka untuk mendukung ekspresi lambda, yaitu pencocokan pola di Jawa. Di Scala, ini diterapkan secara asli. Setuju, kode dalam Scala lebih pendek dan lebih mudah dibaca.
- Dokumentasi dan contoh-contoh. Terlepas dari kenyataan bahwa dalam dokumentasi resmi ada contoh di Jawa, di Internet, hampir semua contoh ada di Scala. Juga, akan lebih mudah bagi Anda untuk menavigasi di sumber-sumber perpustakaan Akka.
Dalam hal kinerja, tidak akan ada perbedaan antara Scala dan Java, karena semuanya berputar di JVM.
Penyimpanan
Sebelum menerapkan Pengadaan Acara dengan Akka Persistence, saya sarankan Anda memilih dulu basis data untuk penyimpanan data permanen. Pilihan pangkalan tergantung pada persyaratan untuk sistem, pada keinginan dan preferensi Anda. Data dapat disimpan baik di NoSQL dan RDBMS, dan dalam sistem file, misalnya LevelDB dari Google .
Penting untuk dicatat bahwa Akka Persistence tidak bertanggung jawab untuk menulis dan membaca data dari database, tetapi melakukannya melalui plug-in yang seharusnya mengimplementasikan Akka Persistence API.
Setelah memilih alat untuk menyimpan data, Anda perlu memilih plugin dari daftar, atau menulisnya sendiri. Pilihan kedua, saya tidak merekomendasikan mengapa menemukan kembali roda.
Untuk penyimpanan data permanen, kami memutuskan untuk tetap di Cassandra. Faktanya adalah kami membutuhkan pangkalan yang andal, cepat, dan terdistribusi. Selain itu, Typesafe sendiri menyertai plugin , yang sepenuhnya mengimplementasikan Akka Persistence API . Itu terus diperbarui dan dibandingkan dengan yang lain, plugin Cassandra telah menulis dokumentasi yang lebih lengkap.
Perlu disebutkan bahwa plugin ini juga memiliki beberapa masalah. Misalnya, masih belum ada versi stabil (pada saat penulisan ini, versi terbaru adalah 0,97). Bagi kami, gangguan terbesar yang kami temui saat menggunakan plugin ini adalah hilangnya acara ketika membaca Persistent Query untuk beberapa entitas. Untuk gambar lengkap, di bawah ini adalah bagan CQRS:
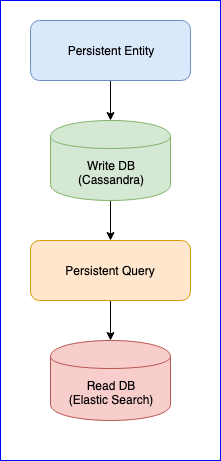
Persistent Entity mendistribusikan peristiwa entitas ke dalam tag menggunakan algoritma hash yang konsisten (misalnya, 10 pecahan):
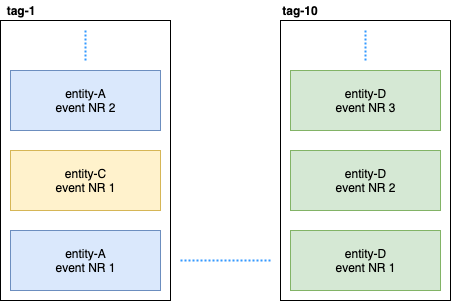
Lalu, Persistent Query berlangganan tag ini dan meluncurkan aliran yang menambahkan data ke Pencarian Elastis. Karena Cassandra berada dalam sebuah cluster, acara akan tersebar di seluruh node. Beberapa node dapat melorot dan akan merespons lebih lambat dari yang lain. Tidak ada jaminan bahwa Anda akan menerima acara dalam urutan yang ketat. Untuk mengatasi masalah ini, plugin diimplementasikan sehingga jika ia menerima peristiwa yang tidak berurutan, misalnya, entity-A event NR 2 , maka ia menunggu waktu tertentu untuk acara awal dan jika tidak menerimanya, ia hanya akan mengabaikan semua peristiwa entitas ini. Bahkan tentang ini, ada diskusi tentang Gitter. Jika ada yang tertarik, Anda dapat membaca korespondensi antara @kotdv dan pengembang plugin: Gitter
Bagaimana kesalahpahaman ini dapat diatasi:
- Anda perlu memperbarui plugin ke versi terbaru. Dalam versi terbaru, pengembang Typesafe telah memecahkan banyak masalah yang berkaitan dengan Konsistensi Akhirnya. Tapi, kami masih menunggu versi stabil
- Pengaturan yang lebih tepat telah ditambahkan untuk komponen yang bertanggung jawab untuk menerima acara. Anda dapat mencoba untuk meningkatkan batas waktu untuk acara yang tidak
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s untuk operasi plugin yang lebih andal: c assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Konfigurasikan Cassandra seperti yang direkomendasikan oleh DataStax. Masukkan pengumpul sampah G1 dan alokasikan memori sebanyak mungkin untuk Cassandra .
Pada akhirnya, kami memecahkan masalah dengan peristiwa yang hilang, tetapi sekarang ada penundaan data yang stabil di sisi Permintaan Persistensi (dari lima hingga sepuluh detik). Diputuskan untuk meninggalkan pendekatan untuk data yang digunakan untuk analitik, dan di mana kecepatan penting, kami secara manual menerbitkan acara di bus. Hal utama adalah memilih mekanisme yang sesuai untuk memproses atau memublikasikan data: paling tidak sekali atau paling banyak sekali. Deskripsi yang baik dari Akka dapat ditemukan di sini . Penting bagi kami untuk menjaga konsistensi data, dan oleh karena itu, setelah berhasil menulis data ke database, kami memperkenalkan keadaan transisi yang mengontrol keberhasilan publikasi data di bus. Berikut ini adalah contoh kode:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
Jika karena alasan tertentu tidak mungkin untuk mempublikasikan acara, maka pada awal SomeEntity berikutnya, ia akan tahu bahwa acara DidSomething tidak mencapai bus dan akan mencoba untuk mempublikasikan ulang data lagi.
Serializer
Serialisasi adalah hal yang sama pentingnya dalam menggunakan Akka. Dia memiliki modul internal - Akka Serialisasi . Modul ini digunakan untuk membuat cerita bersambung saat bertukar antar aktor dan saat menyimpannya melalui Persistence API. Secara default, Java serializer digunakan, tetapi disarankan untuk menggunakan yang lain. Masalahnya adalah bahwa Java Serializer lambat dan membutuhkan banyak ruang. Ada dua solusi populer - ini adalah JSON dan Protobuf. JSON, meskipun lambat, lebih mudah diimplementasikan dan dipelihara. Jika Anda perlu meminimalkan biaya serialisasi dan penyimpanan data, Anda bisa berhenti di Protobuf, tetapi kemudian proses pengembangannya akan lebih lambat. Selain Model Domain, Anda harus menulis Model Data lain. Jangan lupa tentang versi data. Bersiaplah untuk terus menulis pemetaan antara Model Domain dan Model Data.
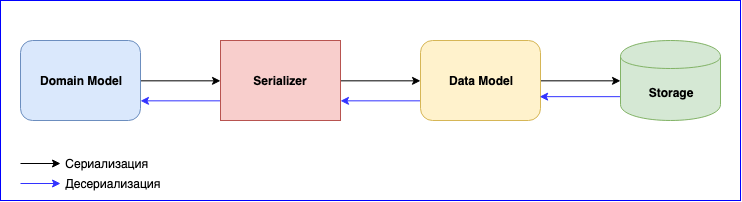
Menambahkan acara baru - tulis pemetaan. Mengubah struktur data - menulis versi baru Model Data dan mengubah fungsi pemetaan. Jangan lupa tentang tes untuk serialis. Secara umum, akan ada banyak pekerjaan, tetapi pada akhirnya Anda akan mendapatkan komponen yang digabungkan secara longgar.
Kesimpulan
- Pelajarilah dengan hati-hati dan pilihlah basis dan plugin yang cocok untuk Anda sendiri. Saya sarankan memilih plugin yang terpelihara dengan baik dan tidak akan berhenti berkembang. Daerah ini relatif baru, masih ada banyak kekurangan yang belum diselesaikan
- Jika Anda memilih penyimpanan terdistribusi, Anda harus menyelesaikan masalah dengan penundaan hingga 10 detik sendiri, atau tahan dengan itu
- Kompleksitas serialisasi. Anda dapat mengorbankan kecepatan dan berhenti menggunakan JSON, atau memilih Protobuf dan menulis banyak adaptor dan mendukungnya.
- Ada plus untuk templat ini, ini adalah komponen yang digabungkan secara longgar dan tim pengembangan independen yang membangun satu sistem besar.