
Baru-baru ini, ada beberapa artikel yang mengkritik ImageNet, mungkin set gambar paling terkenal yang digunakan untuk melatih jaringan saraf.
Pada artikel pertama, Mendekati CNN dengan model fitur lokal yang bekerja sangat baik di ImageNet, penulis mengambil model yang mirip dengan bag-of-words dan menggunakan fragmen dari gambar sebagai "kata-kata". Fragmen ini dapat berukuran hingga 9x9 piksel. Dan pada saat yang sama, pada model seperti itu, di mana setiap informasi tentang penataan ruang fragmen-fragmen ini sama sekali tidak ada, penulis mendapatkan akurasi 70 hingga 86% (misalnya, akurasi dari ResNet-50 reguler adalah ~ 93%).
Dalam artikel kedua CNN yang dilatih ImageNet, bias terhadap tekstur, penulis menyimpulkan bahwa seluruh dataset ImageNet dan cara orang dan jaringan saraf memandang gambar yang salah dan menyarankan menggunakan dataset baru - Stylized-ImageNet.
Lebih detail tentang apa yang dilihat orang dalam gambar dan jaringan saraf apa
ImageNet
Dataset ImageNet mulai dibuat pada tahun 2006 oleh upaya Profesor Fei-Fei Li dan terus berkembang hingga hari ini. Saat ini, itu berisi sekitar 14 juta gambar milik lebih dari 20 ribu kategori yang berbeda.
Sejak 2010, subset dataset ini, dikenal sebagai ImageNet 1K dengan ~ 1 juta gambar dan ribuan kelas, telah digunakan dalam Tantangan Pengenalan Visual Skala Besar (ILSVRC) ImageNet. Dalam kompetisi ini, pada tahun 2012, AlexNet, jaringan saraf convolutional, menembak pada akurasi top-1 60% dan top-5 di 80%.
Pada subset dataset inilah orang-orang dari lingkungan akademik mengukur SOTA mereka ketika mereka menawarkan arsitektur jaringan baru.
Sedikit tentang proses pembelajaran pada dataset ini. Kami akan berbicara tentang protokol pelatihan tentang ImageNet di lingkungan akademik. Yaitu, ketika hasil dari beberapa blok SE, jaringan ResNeXt atau DenseNet ditunjukkan kepada kami di artikel, prosesnya terlihat seperti ini: jaringan belajar selama 90 era, kecepatan belajar berkurang pada era 30 dan 60, setiap 10 kali, sebagai pengoptimal SGD biasa dengan pembobotan bobot kecil dipilih, hanya RandomCrop dan HorizontalFlip yang digunakan dari augmentasi, gambar biasanya diubah ukurannya menjadi 224x224 piksel.
Berikut ini contoh skrip pytorch untuk pelatihan di ImageNet.
BagNet
Mari kita kembali ke artikel yang disebutkan sebelumnya. Dalam yang pertama ini, penulis menginginkan model yang lebih mudah diinterpretasikan daripada jaringan dalam biasa. Terinspirasi oleh gagasan model tas fitur, mereka membuat keluarga model mereka sendiri - BagNets. Menggunakan sebagai dasar jaringan ResNet-50 biasa.
Mengganti beberapa konvolusi 3x3 dengan 1x1 di ResNet-50, mereka memastikan bahwa bidang neuron reseptif pada lapisan convolutional terakhir berkurang secara signifikan, hingga 9x9 piksel. Dengan demikian, mereka membatasi informasi yang tersedia untuk satu neuron individu menjadi fragmen yang sangat kecil dari seluruh gambar - sepetak beberapa piksel. Perlu dicatat bahwa untuk ResNet-50 yang masih asli, ukuran bidang reseptif lebih dari 400 piksel, yang sepenuhnya mencakup gambar, yang biasanya mengubah ukuran menjadi 224x224 piksel.
Patch ini adalah fragmen maksimum gambar yang darinya model dapat mengekstraksi data spasial. Pada akhir model, semua data diringkas dan model sama sekali tidak bisa tahu di mana masing-masing tambalan berada dalam kaitannya dengan tambalan lainnya.
Secara total, tiga varian jaringan dengan bidang reseptif 9x9, 17x17 dan 33x33 diuji. Dan, meskipun sama sekali tidak memiliki informasi spasial, model seperti itu mampu mencapai akurasi yang baik dalam klasifikasi di ImageNet. Akurasi top-5 untuk patch 9x9 adalah 70%, untuk 17x17 - 80%, untuk 33x33 - 86%. Sebagai perbandingan, akurasi top-5 ResNet-50 adalah sekitar 93%.

Struktur model ditunjukkan pada gambar di atas. Setiap patch piksel qxqx3 yang dipotong dari gambar diubah menjadi vektor 2048 oleh jaringan. Selanjutnya, vektor ini diumpankan ke input classifier linier, yang menghasilkan skor untuk masing-masing dari 1000 kelas. Dengan mengumpulkan skor setiap patch dalam array 2d, Anda bisa mendapatkan peta panas untuk setiap kelas dan setiap piksel dari gambar asli. Skor akhir untuk gambar diperoleh dengan menjumlahkan peta panas masing-masing kelas.
Contoh heatmap untuk beberapa kelas:

Seperti yang Anda lihat, kontribusi terbesar untuk manfaat kelas tertentu dibuat oleh tambalan yang terletak di tepi objek. Tambalan dari latar belakang hampir diabaikan. Sejauh ini, semuanya baik-baik saja.
Mari kita lihat tambalan paling informatif:

Sebagai contoh, penulis mengambil empat kelas. Untuk masing-masing dari mereka, 2x7 patch paling signifikan dipilih (yaitu, patch di mana skor kelas ini adalah yang tertinggi). Baris atas 7 tambalan diambil dari gambar hanya kelas yang sesuai, bagian bawah - dari seluruh sampel gambar.
Apa yang bisa dilihat dalam foto-foto ini luar biasa. Misalnya, untuk kelas tench (tench, fish), jari adalah ciri khas. Ya, jari manusia biasa dengan latar belakang hijau. Dan semua karena ada nelayan di hampir semua gambar dengan kelas ini, yang, pada kenyataannya, memegang ikan ini di tangannya, memamerkan piala.
Untuk komputer laptop, fitur karakteristik adalah tombol huruf. Kunci mesin tik juga diperhitungkan untuk kelas ini.
Fitur khas dari sampul buku adalah huruf-huruf dengan latar belakang berwarna. Biarkan itu menjadi tulisan pada T-shirt atau di tas.
Tampaknya masalah ini seharusnya tidak mengganggu kita. Karena itu melekat hanya dalam kelas jaringan yang sempit dengan bidang penerimaan yang sangat terbatas. Tetapi lebih lanjut, penulis menghitung korelasi antara log (output jaringan sebelum softmax akhir) ditugaskan untuk setiap kelas BagNet dengan bidang reseptif yang berbeda, dan log dari VGG-16, yang memiliki bidang reseptif yang cukup besar. Dan mereka menemukannya cukup tinggi.
Korelasi antara BagNets dan VGG-16 Para penulis bertanya-tanya apakah BagNet berisi petunjuk tentang bagaimana jaringan lain mengambil keputusan.
Untuk salah satu tes, mereka menggunakan teknik seperti Image Scrambling. Yang terdiri dalam menggunakan generator tekstur berdasarkan matriks gram untuk menyusun gambar di mana tekstur disimpan, tetapi informasi spasial hilang.

VGG-16, dilatih dengan gambar biasa, diatasi dengan gambar acak seperti itu dengan cukup baik. Akurasi top-5-nya turun dari 90% menjadi 80%. Artinya, bahkan jaringan dengan bidang reseptif yang agak besar masih lebih suka mengingat tekstur dan mengabaikan informasi spasial. Oleh karena itu, keakuratannya tidak jatuh pada gambar acak.
Para penulis melakukan serangkaian percobaan di mana mereka membandingkan bagian mana dari gambar yang paling signifikan untuk BagNet dan jaringan lain (VGG-16, ResNet-50, ResNet-152 dan DenseNet-169). Semuanya mengisyaratkan bahwa jaringan lain, seperti BagNet, bergantung pada potongan-potongan kecil gambar dan membuat kesalahan yang sama ketika membuat keputusan. Ini terutama terlihat untuk jaringan yang tidak terlalu dalam seperti VGG.
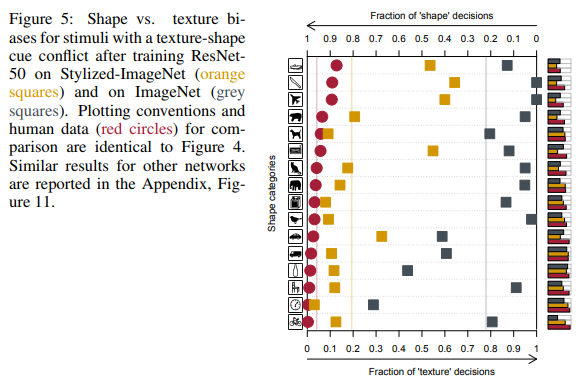
Kecenderungan jaringan untuk membuat keputusan berdasarkan tekstur, tidak seperti kita, orang yang lebih suka bentuk (lihat gambar di bawah), mendorong penulis artikel kedua untuk membuat dataset baru berdasarkan ImageNet.
ImageNet bergaya
Pertama-tama, penulis artikel menggunakan transfer gaya menciptakan satu set gambar di mana bentuk (data spasial) dan tekstur dalam satu gambar saling bertentangan. Dan kami membandingkan hasil orang-orang dan jaringan konvolusi mendalam dari berbagai arsitektur pada set data yang disintesis dari 16 kelas.

Pada gambar paling kanan, orang melihat kucing, jaringan - gajah.

Perbandingan hasil orang dan jaringan saraf.
Seperti yang Anda lihat, orang-orang ketika menugaskan objek ke kelas tertentu bergantung pada bentuk objek, jaringan saraf pada tekstur. Pada gambar di atas, orang melihat kucing, jaringan - gajah.
Ya, di sini Anda dapat menemukan kesalahan dengan fakta bahwa jaringnya juga agak benar dan ini, misalnya, bisa jadi gajah yang difoto dari jarak dekat dengan tato kucing kesayangan. Tetapi fakta bahwa jaringan ketika membuat keputusan berperilaku berbeda dari orang, penulis mempertimbangkan masalah dan mulai mencari cara untuk menyelesaikannya.
Seperti disebutkan di atas, hanya mengandalkan tekstur, jaringan mampu mencapai hasil yang baik dengan akurasi top-5 86%. Dan ini bukan tentang beberapa kelas, di mana tekstur membantu untuk mengklasifikasikan gambar dengan benar, tetapi tentang sebagian besar kelas.
Masalahnya adalah di ImageNet sendiri, karena akan ditunjukkan nanti bahwa jaringan mampu mempelajari formulir, tetapi tidak, karena tekstur cukup untuk kumpulan data ini, dan neuron yang bertanggung jawab atas tekstur berada pada lapisan dangkal, yang jauh lebih mudah untuk dilatih.
Dengan menggunakan mekanisme transfer gaya cepat AdaIN yang sedikit berbeda, penulis membuat dataset baru - Stylized ImageNet. Bentuk objek diambil dari ImageNet, dan set tekstur dari kompetisi ini di Kaggle . Skrip untuk pembuatan tersedia di tautan .

Selanjutnya, untuk singkatnya, ImageNet akan disebut sebagai IN , Stylized ImageNet sebagai SIN .
Para penulis mengambil ResNet-50 dan tiga BagNet dengan bidang reseptif yang berbeda dan dilatih pada model terpisah untuk masing-masing kumpulan data.
Dan inilah yang mereka lakukan:
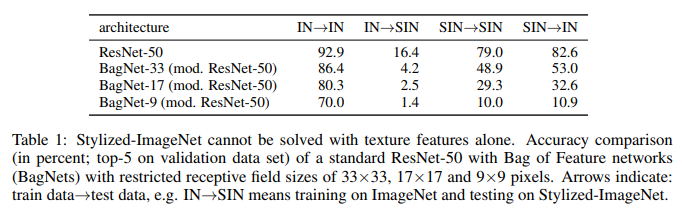
Apa yang kita lihat di sini. ResNet-50 yang dilatih tentang IN benar-benar lumpuh pada SIN. Yang sebagian menegaskan bahwa ketika pelatihan pada IN, jaringan overfits ke tekstur dan mengabaikan bentuk objek. Pada saat yang sama, ResNet-50 dilatih tentang SIN dengan sempurna mengatasi baik SIN maupun IN. Artinya, jika dirampas dari jalur yang sederhana, jaringan mengikuti jalur yang sulit - ia mengajarkan bentuk objek.
BagNet akhirnya mulai berperilaku seperti yang diharapkan, terutama pada tambalan kecil, karena tidak ada hubungannya dengan - informasi tekstur hilang begitu saja dari SIN.
Dalam enam belas kelas yang disebutkan sebelumnya, ResNet-50, yang dilatih tentang SIN, mulai memberikan jawaban yang lebih mirip dengan yang diberikan orang:
Selain hanya melatih ResNet-50 tentang SIN, penulis mencoba untuk melatih jaringan pada seperangkat gabungan SIN dan IN, termasuk fine-tuning secara terpisah pada IN murni.

Seperti yang Anda lihat, ketika menggunakan SIN + IN untuk pelatihan, hasilnya meningkat tidak hanya pada tugas utama - klasifikasi gambar di ImageNet, tetapi juga pada tugas mendeteksi objek pada dataset PASCAL VOC 2007.
Selain itu, jaringan SIN terlatih menjadi lebih tahan terhadap berbagai kebisingan dalam data.
Kesimpulan
Bahkan sekarang, pada 2019, setelah tujuh tahun sukses dengan AlexNet, ketika jaringan saraf banyak digunakan dalam visi komputer, ketika ImageNet 1K secara de facto menjadi standar untuk mengevaluasi kinerja model dalam lingkungan akademik, mekanisme bagaimana jaringan saraf membuat keputusan tidak sepenuhnya jelas. . Dan bagaimana set data di mana jaringan ini dilatih memengaruhi ini.
Para penulis artikel pertama mencoba menjelaskan bagaimana keputusan tersebut dibuat dalam jaringan dengan arsitektur bag-of-feature dengan bidang reseptif terbatas, yang lebih mudah untuk ditafsirkan. Dan, membandingkan jawaban BagNet dan jaringan saraf dalam yang biasa, kami sampai pada kesimpulan bahwa proses pengambilan keputusan di dalamnya sangat mirip.
Para penulis artikel kedua membandingkan bagaimana orang dan jaringan saraf mempersepsikan gambar-gambar di mana bentuk dan tekstur saling bertentangan. Dan mereka menyarankan menggunakan dataset baru, Stylized ImageNet, untuk mengurangi perbedaan persepsi. Setelah menerima bonus, peningkatan keakuratan klasifikasi di ImageNet dan deteksi pada set data pihak ketiga.
Kesimpulan utama dapat dibuat sebagai berikut: jaringan yang belajar dari gambar, memiliki kemampuan untuk mengingat properti spasial tingkat tinggi dari objek, lebih suka cara yang lebih mudah untuk mencapai tujuan - untuk mengenakan tekstur. Jika dataset yang mereka latih memungkinkan ini.
Selain minat akademis, masalah overfitting tekstur penting bagi kita semua yang menggunakan model pra-terlatih untuk mentransfer pembelajaran dalam tugas mereka.
Konsekuensi penting dari semua ini bagi kami adalah Anda tidak boleh mempercayai bobot model yang umumnya sudah dilatih sebelumnya di ImageNet, karena sebagian besar dari mereka merupakan penambahan sederhana yang digunakan, yang sama sekali tidak berkontribusi untuk menghilangkan overfitting. Dan lebih baik, jika memungkinkan, untuk memiliki model yang dilatih dengan augmentasi yang lebih serius atau Stylized ImageNet + ImageNet di sarang. Untuk selalu dapat membandingkan mana yang paling cocok untuk tugas kita saat ini.