
Banyak orang terbiasa menilai film di KinoPoisk atau imdb setelah menontonnya, dan bagian "Juga dibeli dengan produk ini" dan "Produk populer" ada di toko online mana pun. Tetapi ada beberapa jenis rekomendasi yang kurang dikenal. Pada artikel ini saya akan berbicara tentang tugas apa yang direkomendasikan oleh sistem rekomendasi, ke mana harus menjalankan dan apa ke google.
Apa yang kami rekomendasikan?
Bagaimana jika kami ingin merekomendasikan
rute yang
nyaman bagi pengguna ? Berbagai aspek perjalanan penting bagi pengguna yang berbeda: ketersediaan tempat duduk, waktu perjalanan, lalu lintas, AC, pemandangan yang indah dari jendela. Tugas yang tidak biasa, tetapi cukup jelas bagaimana membangun sistem seperti itu.
Bagaimana jika kami merekomendasikan
beritanya ? Berita dengan cepat menjadi usang - Anda perlu menunjukkan artikel terbaru kepada pengguna saat masih relevan. Penting untuk memahami konten artikel. Sudah lebih sulit.
Dan jika kami merekomendasikan
restoran berdasarkan ulasan? Namun kami merekomendasikan tidak hanya restoran, tetapi juga hidangan tertentu yang patut dicoba. Anda juga dapat memberikan rekomendasi ke restoran tentang apa yang layak ditingkatkan.
Bagaimana jika kita
memperluas tugas dan mencoba menjawab pertanyaan: "Produk apa yang menarik bagi kelompok orang terbesar?". Ini menjadi sangat tidak biasa dan tidak segera jelas bagaimana menyelesaikannya.
Bahkan, ada banyak variasi tugas rekomendasi dan masing-masing memiliki nuansa tersendiri. Anda dapat merekomendasikan hal-hal yang sama sekali tidak terduga. Contoh favorit saya merekomendasikan
preview di Netflix .

Tugas yang lebih sempit
Ambil tugas yang akrab dan akrab untuk merekomendasikan musik. Apa sebenarnya yang ingin kami rekomendasikan?

Pada kolase ini Anda dapat menemukan contoh berbagai rekomendasi dari Spotify, Google dan Yandex.
- Sorot minat homogen dalam Bauran Harian
- Radar Siaran Berita Pribadi, Dirilis Rilis Baru, Premiere
- Pilihan pribadi apa yang Anda suka - Daftar Putar Hari
- Pilihan trek pribadi yang belum didengar pengguna - Discover Weekly, Dejavu
- Kombinasi dari dua poin sebelumnya dengan bias pada trek baru - I'm Feeling Lucky
- Terletak di perpustakaan, tetapi belum terdengar - Cache
- Lagu Top Anda 2018
- Lagu-lagu yang Anda dengarkan pada usia 14 dan yang membentuk selera Anda - Your Time Capsule
- Lagu yang mungkin Anda sukai, tetapi berbeda dari yang biasanya didengar pengguna - Pemecah rasa
- Jejak artis yang tampil di kota Anda
- Koleksi Gaya
- Pilihan aktivitas dan suasana hati
Dan pastinya Anda dapat menemukan sesuatu yang lain. Bahkan jika kita benar-benar dapat memprediksi trek mana yang disukai pengguna, pertanyaannya masih tetap dalam bentuk apa dan dalam tata letak apa mereka harus dikeluarkan.
Pementasan klasik
Dalam pernyataan klasik masalah, yang kita miliki hanyalah matriks peringkat barang-pengguna. Ini sangat jarang dan tugas kami adalah mengisi nilai yang hilang. Biasanya RMSE dari peringkat yang diprediksi digunakan sebagai metrik, namun,
ada pendapat bahwa ini tidak sepenuhnya benar dan karakteristik rekomendasi secara keseluruhan harus diperhitungkan, dan bukan keakuratan memprediksi nomor tertentu.
Bagaimana cara mengevaluasi kualitas?
Evaluasi online
Cara yang paling disukai untuk mengevaluasi kualitas sistem adalah verifikasi langsung pada pengguna dalam konteks metrik bisnis. Ini mungkin RKPT, waktu yang dihabiskan dalam sistem, atau jumlah pembelian. Tetapi percobaan pada pengguna mahal, dan saya tidak ingin meluncurkan algoritma yang buruk bahkan untuk sekelompok kecil pengguna, sehingga mereka menggunakan metrik kualitas offline sebelum pengujian online.
Evaluasi offline
Metrik peringkat, seperti MAP @ k dan nDCG @ k, biasanya digunakan sebagai metrik kualitas.
Relevance dalam konteks
MAP@k adalah nilai biner, dan dalam konteks
nDCG@k dapat ada skala peringkat.
Namun, selain keakuratan prediksi, kami mungkin tertarik pada hal-hal lain:
- cakupan - bagian barang yang dikeluarkan oleh pemberi rekomendasi,
- personalisasi - betapa berbedanya rekomendasi antara pengguna,
- keanekaragaman - seberapa beragam produk dalam rekomendasi.
Secara umum, ada ulasan yang baik tentang metrik.
Seberapa baik sistem rekomendasi Anda? Sebuah survei evaluasi yang direkomendasikan . Contoh formalisasi metrik kebaruan dapat ditemukan di
Peringkat dan Relevansi dalam Metrik Kebaruan dan Keragaman untuk Sistem Rekomendasi .
Data
Umpan balik eksplisit
Matriks penilaian adalah contoh data eksplisit. Seperti, tidak suka, peringkat - pengguna sendiri telah dengan jelas menyatakan tingkat ketertarikannya pada item tersebut. Data seperti itu biasanya langka. Misalnya, dalam
Tantangan Rekko dalam data pengujian, hanya 34% pengguna yang memiliki setidaknya satu tanda.
Umpan balik tersirat
Ada lebih banyak informasi tentang preferensi tersirat - tampilan, klik, bookmark, pengaturan notifikasi. Tetapi jika pengguna menonton film - itu hanya berarti bahwa sebelum menonton film itu tampak cukup menarik baginya. Kami tidak dapat menarik kesimpulan langsung tentang apakah film itu disukai atau tidak.
Fungsi Kehilangan untuk Belajar
Untuk menggunakan umpan balik implisit, kami datang dengan metode pengajaran yang sesuai.
Peringkat pribadi Bayesian
Artikel asliDiketahui item apa yang berinteraksi dengan pengguna. Kami berasumsi bahwa ini adalah contoh positif yang ia sukai. Masih banyak item yang belum berinteraksi dengan pengguna. Kami tidak tahu yang mana dari mereka yang akan menarik bagi pengguna dan yang tidak, tetapi kami tentu tahu bahwa tidak semua contoh ini akan menjadi positif. Kami membuat generalisasi kasar dan menganggap tidak adanya interaksi sebagai contoh negatif.
Kami akan mencicipi tiga kali lipat {pengguna, item positif, item negatif} dan mendenda model jika contoh negatif dinilai lebih tinggi dari yang positif.
Perkiraan-Peringkat Tertimbang Berpasangan
Tambahkan ke tingkat pembelajaran adaptif ide sebelumnya. Kami akan mengevaluasi pelatihan sistem berdasarkan jumlah sampel yang harus kami telusuri untuk menemukan contoh negatif untuk pasangan {user, contoh positif} yang diberikan, yang dinilai sistem lebih tinggi daripada positif.
Jika kami menemukan contoh seperti itu pertama kali, maka denda harus besar. Jika Anda harus mencari waktu yang lama, maka sistem sudah bekerja dengan baik dan Anda tidak perlu terlalu banyak denda.
Apa lagi yang layak dipikirkan?
Mulai dingin
Segera setelah kami belajar membuat prediksi untuk pengguna dan produk yang ada, dua pertanyaan muncul: - "Bagaimana cara merekomendasikan produk yang belum pernah dilihat orang?" dan "Apa yang harus saya rekomendasikan kepada pengguna yang belum memiliki peringkat tunggal?". Untuk mengatasi masalah ini, mereka mencoba mengekstrak informasi dari sumber lain. Ini mungkin data tentang pengguna dari layanan lain, kuesioner selama pendaftaran, informasi tentang item dari isinya.
Dalam hal ini, ada tugas-tugas yang keadaan awal dinginnya konstan. Di Session Based Recommenders, Anda perlu punya waktu untuk memahami sesuatu tentang pengguna selama dia ada di situs. Barang-barang baru terus-menerus muncul di merekomendasikan produk berita atau produk mode, sementara barang-barang lama dengan cepat menjadi usang.
Ekor panjang
Jika untuk setiap item kami menghitung popularitasnya dalam bentuk jumlah pengguna yang berinteraksi dengannya atau memberikan peringkat positif, maka sangat sering kami akan mendapatkan grafik seperti pada gambar:
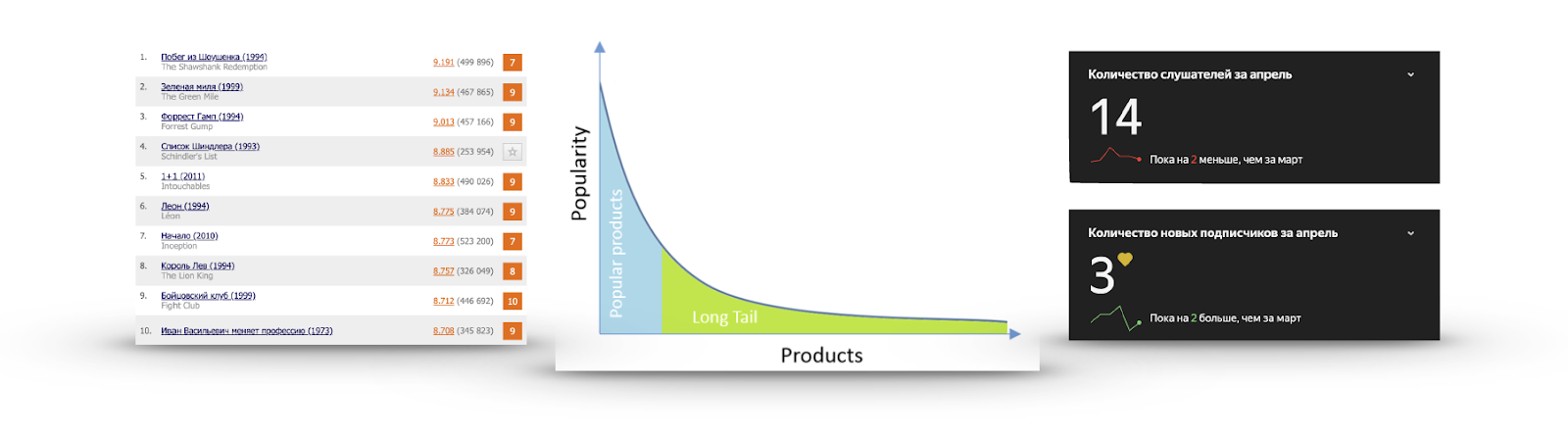
Ada sejumlah kecil item yang diketahui semua orang. Tidak ada gunanya merekomendasikan mereka, karena pengguna kemungkinan besar sudah melihat mereka dan tidak memberikan peringkat, tahu tentang mereka dan akan melihat mereka, atau telah dengan tegas memutuskan untuk tidak menonton sama sekali. Saya menonton trailer Daftar Schindler lebih dari sekali, tetapi saya tidak akan melihatnya.
Di sisi lain, popularitas menurun sangat cepat, dan hampir tidak ada yang melihat sebagian besar barang. Membuat rekomendasi dari bagian ini lebih bermanfaat: ada konten menarik yang tidak mungkin ditemukan oleh pengguna. Misalnya, di sebelah kanan adalah statistik mendengarkan dari salah satu grup favorit saya di Yandex.Music.
Eksplorasi vs Eksploitasi
Katakanlah kita tahu persis apa yang disukai pengguna. Apakah ini berarti kita harus merekomendasikan hal yang sama? Ada perasaan bahwa rekomendasi semacam itu akan dengan cepat menjadi membosankan dan kadang-kadang ada baiknya menunjukkan sesuatu yang baru. Ketika kami merekomendasikan apa yang seharusnya disukai adalah eksploitasi. Jika kami mencoba menambahkan sesuatu yang kurang populer ke rekomendasi atau entah bagaimana mendiversifikasikannya - ini adalah eksplorasi. Saya ingin menyeimbangkan hal-hal ini.
Rekomendasi yang tidak dipersonalisasi
Opsi termudah adalah merekomendasikan hal yang sama kepada semua orang.
Urutkan berdasarkan popularitas
Nilai = (peringkat positif) - (peringkat negatif)
Anda dapat mengurangi ketidaksukaan dari suka dan mengurutkannya. Namun dalam hal ini, kami tidak memperhitungkan rasio persentase mereka. Ada perasaan bahwa 200 suka dari 50 tidak suka tidak sama dengan 1200 suka dan 1050 tidak suka.
Skor = (Nilai positif) / (Nilai total)
Anda dapat membagi jumlah suka dengan jumlah tidak suka, tetapi dalam hal ini kami tidak memperhitungkan jumlah peringkat dan produk dengan satu peringkat 5 poin akan diberi peringkat lebih tinggi dari produk yang sangat populer dengan peringkat rata-rata 4,8.
Bagaimana
tidak mengurutkan berdasarkan peringkat rata-rata dan mempertimbangkan jumlah peringkat? Hitung interval kepercayaan: "Berdasarkan perkiraan yang tersedia, apakah probabilitas probabilitas 95% dari pangsa sebenarnya dari peringkat positif setidaknya apa?" Jawaban untuk pertanyaan ini diberikan oleh Edwin Wilson pada tahun 1927.
- Bagian yang diamati dari peringkat positif
- Kuantil 1-alfa dari distribusi normal
Kompatibilitas
Pemilihan set produk yang sering ditemui meliputi seluruh kelompok tugas penambangan pola:
penambangan pola berkala ,
penambangan aturan sekuensial ,
penambangan pola sekuensial ,
penambangan itemset utilitas tinggi ,
penambangan itemset yang sering (analisis keranjang) . Setiap tugas spesifik akan memiliki
metodenya sendiri, tetapi jika secara umum digeneralisasi, algoritma untuk menemukan rangkaian yang sering melakukan pencarian singkat pertama, mencoba untuk tidak memilah opsi yang jelas-jelas buruk.
Set langka dipotong pada dukungan batas yang diberikan - jumlah atau frekuensi kemunculan set dalam data.
Setelah menyoroti itemset yang sering, kualitas ketergantungan mereka dievaluasi menggunakan metrik Lift atau Confindence (a, b) / Confidence (! A, b). Mereka ditujukan untuk menghilangkan dependensi palsu.
Misalnya, pisang sering dapat ditemukan di keranjang belanjaan bersama dengan barang-barang kalengan. Tetapi intinya bukanlah dalam hubungan khusus, tetapi pada kenyataan bahwa pisang populer dengan sendirinya, dan ini harus diperhitungkan ketika mencari kecocokan.
Rekomendasi yang dipersonalisasi
Berbasis konten
Gagasan pendekatan berbasis konten adalah untuk membuat baginya vektor preferensi di ruang objek berdasarkan sejarah tindakan pengguna dan merekomendasikan produk yang dekat dengan vektor ini.
Artinya, item tersebut harus memiliki beberapa deskripsi karakteristik. Sebagai contoh, ini mungkin genre film. Sejarah suka dan tidak suka film membentuk vektor preferensi,
menyoroti beberapa genre dan menghindari yang lain. Dengan membandingkan vektor pengguna dan vektor item, Anda dapat membuat peringkat dan mendapatkan rekomendasi.
Penyaringan kolaboratif

Pemfilteran kolaboratif mengasumsikan matriks penilaian item-pengguna. Idenya adalah untuk menemukan "tetangga" yang paling mirip untuk setiap pengguna dan mengisi kekosongan pengguna tertentu dengan memberi bobot rata-rata peringkat "tetangga".
Demikian pula, Anda dapat melihat kesamaan barang, percaya bahwa barang serupa disukai oleh orang yang sama. Secara teknis, ini hanya akan menjadi pertimbangan dari matriks estimasi yang diubah.
Pengguna menggunakan skala peringkat secara berbeda - seseorang tidak pernah menempatkannya di atas delapan, dan seseorang menggunakan seluruh skala. Ini berguna untuk memperhitungkan, dan karena itu dimungkinkan untuk memprediksi bukan peringkat itu sendiri, tetapi penyimpangan dari peringkat rata-rata.
Atau Anda dapat menormalkan perkiraan sebelumnya.
Faktorisasi Matriks
Dari matematika,
kita tahu bahwa setiap matriks dapat diuraikan menjadi produk dari tiga matriks. Tetapi matriks peringkat sangat jarang, 99% biasa. Dan SVD tidak tahu apa itu kesenjangan. Mengisi mereka dengan nilai rata-rata sangat tidak diinginkan. Dan secara umum, kami tidak terlalu tertarik pada matriks nilai singular - kami hanya ingin mendapatkan tampilan tersembunyi dari pengguna dan objek, yang, ketika dikalikan, akan mendekati nilai sebenarnya. Anda dapat segera terurai menjadi dua matriks.
Apa yang harus dilakukan dengan kartu pass? Palu pada mereka. Ternyata Anda dapat berlatih untuk memperkirakan peringkat berdasarkan metrik RMSE menggunakan SGD atau ALS, mengabaikan kelalaian sama sekali. Algoritme pertama seperti itu adalah
Funk SVD , yang ditemukan pada tahun 2006 dalam rangka menyelesaikan persaingan dari Netflix.
Hadiah Netflix
Netflix Prize - peristiwa penting yang memberikan dorongan kuat untuk pengembangan sistem rekomendasi. Tujuan dari kompetisi ini adalah untuk mengambil alih sistem rekomendasi Cinematch RMSE yang ada sebesar 10%. Untuk tujuan ini, set data besar yang berisi 100 juta peringkat diberikan pada saat itu. Tugas itu mungkin tidak tampak begitu sulit, tetapi untuk mencapai kualitas yang diperlukan itu diperlukan untuk menemukan kembali kompetisi dua kali - solusi diterima hanya untuk 3 tahun kompetisi. Jika diperlukan untuk memperoleh peningkatan sebesar 15%, mungkin ini tidak akan mungkin tercapai pada data yang diberikan.
Selama kompetisi,
beberapa fitur
menarik ditemukan dalam data. Grafik menunjukkan peringkat rata-rata film tergantung pada tanggal mereka muncul di katalog Netflix. Kesenjangan yang jelas terkait dengan fakta bahwa saat ini Netflix beralih dari skala objektif (film yang buruk, film yang bagus) ke yang subjektif (saya tidak suka, saya sangat menyukainya). Orang-orang kurang kritis ketika mengekspresikan penilaian mereka, daripada mengkarakterisasi suatu objek.
Grafik ini menunjukkan bagaimana peringkat film rata-rata berubah setelah rilis. Dapat dilihat bahwa lebih dari 2000 hari skornya naik 0,2. Artinya, setelah film tidak lagi menjadi baru, mereka yang cukup percaya diri bahwa ia akan menyukai film, yang meningkatkan peringkat, mulai menontonnya.
Hadiah menengah pertama diambil oleh tim spesialis dari AT&T - Korbell. Setelah 2000 jam bekerja dan menyusun sebuah ensemble dari 107 algoritma, mereka berhasil mendapatkan peningkatan sebesar 8,43%.
Di antara model adalah variasi SVD dan RBM, yang dengan sendirinya menyediakan sebagian besar input. 105 algoritma yang tersisa hanya meningkat seperseratus dari metrik. Netflix mengadaptasi kedua algoritma ini untuk volume data dan masih menggunakannya sebagai bagian dari sistem.
Pada tahun kedua kompetisi, kedua tim bergabung dan sekarang hadiah diambil oleh Bellkor di BigChaos. Mereka menyerang total 207 algoritma dan meningkatkan akurasi dengan seperseratus lainnya, mencapai nilai 0,8616. Kualitas yang dibutuhkan masih belum tercapai, tetapi sudah jelas bahwa tahun depan semuanya akan berhasil.
Tahun ketiga Menggabungkan dengan tim lain, mengganti nama Pragmatic Chaos Bellkor dan mencapai kualitas yang diperlukan, sedikit lebih rendah dari The Ensemble. Tapi ini hanya bagian publik dari dataset.
Di sisi tersembunyi, ternyata keakuratan tim-tim ini bertepatan dengan tempat desimal keempat, sehingga pemenang ditentukan oleh selisih komit 20 menit.
Netflix membayar jutaan yang dijanjikan kepada para pemenang, tetapi tidak pernah
menggunakan solusi yang dihasilkan . Mengimplementasikan ansambel ternyata terlalu mahal, dan tidak ada banyak manfaat darinya - lagipula, hanya dua algoritma yang sudah menyediakan sebagian besar peningkatan akurasi. Dan yang paling penting - pada saat akhir kompetisi di tahun 2009, Netflix sudah mulai terlibat dalam layanan streaming selain menyewa DVD selama dua tahun. Mereka memiliki banyak tugas dan data lain yang dapat mereka gunakan dalam sistem mereka. Namun, layanan penyewaan surat DVD mereka masih
melayani 2,7 juta pelanggan yang bahagia .
Jaringan saraf
Dalam sistem rekomendasi modern, pertanyaan yang sering muncul adalah bagaimana memperhitungkan berbagai sumber informasi yang eksplisit dan implisit. Seringkali ada data tambahan tentang pengguna atau item dan Anda ingin menggunakannya. Jaringan saraf adalah cara akuntansi yang baik untuk informasi semacam itu.
Pada masalah menggunakan jaringan untuk rekomendasi, Anda harus memperhatikan ulasan dari
Sistem Rekomendasi berdasarkan Deep Learning: Sebuah Survei dan Perspektif Baru . Ini menggambarkan contoh penggunaan sejumlah besar arsitektur untuk berbagai tugas.
Ada banyak arsitektur dan pendekatan. Salah satu nama yang diulang adalah
DSSM . Saya juga ingin menyebutkan
Penyaringan Kolaboratif Attentive .
ACF mengusulkan untuk memperkenalkan dua tingkat pelemahan:
- Bahkan dengan peringkat yang sama, beberapa item berkontribusi lebih banyak untuk preferensi Anda daripada yang lain.
- Item bukan atom, tetapi terdiri dari komponen. Beberapa memiliki dampak yang lebih besar pada penilaian daripada yang lain. Film ini bisa menarik hanya karena kehadiran aktor favorit.
Bandit multi-bersenjata adalah salah satu topik paling populer belakangan ini. Apa itu bandit multi-bersenjata dapat dibaca dalam sebuah artikel tentang
Habré atau di
Medium .
Ketika diterapkan pada rekomendasi, tugas Contextual-Bandit akan terdengar seperti ini: "Kami memberi makan pengguna dan vektor konteks barang ke input sistem, kami ingin memaksimalkan kemungkinan interaksi (klik, pembelian) untuk semua pengguna dari waktu ke waktu dengan membuat pembaruan yang sering pada kebijakan rekomendasi." Formulasi ini secara alami menyelesaikan masalah eksplorasi vs eksploitasi dan memungkinkan Anda untuk dengan cepat meluncurkan strategi optimal untuk semua pengguna.
Setelah popularitas arsitektur transformator, ada juga upaya untuk menggunakannya dalam rekomendasi.
Rekomendasi Barang Berikutnya dengan Perhatian Diri berupaya menggabungkan preferensi pengguna jangka panjang dan terkini untuk meningkatkan rekomendasi.
Alat-alatnya
Rekomendasi bukanlah topik populer seperti CV atau NLP, jadi untuk menggunakan arsitektur grid terbaru Anda harus mengimplementasikannya sendiri, atau berharap implementasi penulisnya cukup nyaman dan mudah dimengerti. Namun, beberapa alat dasar masih ada:
Kesimpulan
Sistem pemberi rekomendasi telah jauh dari pernyataan standar tentang mengisi matriks penilaian, dan masing-masing area spesifik akan memiliki nuansa tersendiri. Ini menimbulkan kesulitan, tetapi juga menambah minat. Selain itu, mungkin sulit untuk memisahkan sistem rekomendasi dari produk secara keseluruhan. Memang, tidak hanya daftar barang yang penting, tetapi juga metode dan konteks penyerahan. Apa, bagaimana, kepada siapa dan kapan merekomendasikan. Semua ini menentukan kesan interaksi dengan layanan.