 Diposting oleh Lyudmila Dezhkina, Solution Architect, DataArt
Diposting oleh Lyudmila Dezhkina, Solution Architect, DataArtSelama sekitar enam bulan, tim kami telah bekerja pada Predictive Maintenance Platform, sistem yang seharusnya memprediksi kemungkinan kesalahan dan kegagalan peralatan. Area ini berada di persimpangan IoT dan Machine Learning, dan Anda harus bekerja di sini dengan perangkat keras dan, pada kenyataannya, dengan perangkat lunak. Bagaimana kami membangun Serverless ML dengan pustaka Scikit-learn di AWS akan dibahas dalam artikel ini. Saya akan berbicara tentang kesulitan yang kami temui dan alat yang saya gunakan untuk menghemat waktu.
Untuk jaga-jaga, sedikit tentang diri Anda.Saya telah terlibat dalam pemrograman selama lebih dari 12 tahun, dan selama ini saya berpartisipasi dalam berbagai proyek. Termasuk game, e-commerce, highload, dan Big Data. Selama sekitar tiga tahun saya telah terlibat dalam proyek-proyek yang terkait dengan Machine Learning dan Deep Learning.
 Itu tampak seperti persyaratan yang diajukan oleh pelanggan sejak awal
Itu tampak seperti persyaratan yang diajukan oleh pelanggan sejak awalWawancara dengan klien itu sulit, terutama kami berbicara tentang pembelajaran mesin, kami banyak ditanya tentang algoritma dan pengalaman pribadi tertentu. Tapi saya tidak akan rendah hati - pada bagian ini, kami awalnya sangat mengerti. Batu sandungan pertama adalah bagian dari Perangkat Keras yang berisi sistem. Meskipun demikian, pengalaman saya dengan besi secara pribadi tidak begitu beragam.
Pelanggan menjelaskan kepada kami: "Lihat, kami memiliki conveyor." Saya segera datang dengan ban berjalan di kasir di supermarket. Apa dan apa yang bisa diajarkan di sana? Tetapi dengan cepat menjadi jelas bahwa kata conveyor menyembunyikan pusat penyortiran dengan luas 300-400 meter persegi. m, dan sebenarnya, ada banyak konveyor di sana. Artinya, banyak elemen peralatan yang perlu dihubungkan bersama: sensor, robot. Ilustrasi klasik konsep
"Revolusi Industri 4.0" , di mana IoT dan ML digabungkan.
Tema Pemeliharaan Prediktif pasti akan meningkat setidaknya dua hingga tiga tahun ke depan. Setiap conveyor didekomposisi menjadi elemen: dari robot atau motor yang menggerakkan belt conveyor ke bantalan yang terpisah. Terlebih lagi, jika salah satu dari bagian ini gagal, seluruh sistem berhenti, dan dalam beberapa kasus satu jam konveyor menganggur dapat menelan biaya satu setengah juta dolar (ini bukan berlebihan!).
Salah satu pelanggan kami bergerak di bidang pengangkutan dan logistik kargo: atas dasar itu, robot membongkar 40 truk dalam 8 menit. Tidak ada penundaan di sini, mobil harus datang dan pergi sesuai dengan jadwal yang sangat ketat, tidak ada yang memperbaiki apa pun selama proses pembongkaran. Secara umum, hanya ada dua atau tiga orang dengan tablet di pangkalan ini. Tetapi ada dunia yang sedikit berbeda di mana segala sesuatu tidak terlihat begitu modis, dan di mana mekanik dengan sarung tangan dan tanpa komputer secara langsung pada objek.
Proyek prototipe kecil pertama kami terdiri dari sekitar 90 sensor, dan semuanya berjalan dengan baik sampai proyek harus ditingkatkan. Untuk melengkapi bagian terpisah terkecil dari pusat penyortiran nyata, sekitar 550 sensor sudah diperlukan.
PLC dan sensor
Pengontrol logika yang dapat diprogram - komputer kecil dengan program siklik bawaan - paling sering digunakan untuk mengotomatisasi proses. Sebenarnya, dengan bantuan PLC, kami mengambil bacaan dari sensor: misalnya, akselerasi dan kecepatan, level tegangan, getaran di sepanjang sumbu, suhu (dalam kasus kami, 17 indikator). Sensor sering keliru. Meskipun proyek kami telah berusia lebih dari 8 bulan, kami masih memiliki laboratorium sendiri, tempat kami bereksperimen dengan sensor, memilih model yang paling sesuai. Sekarang, misalnya, kami sedang mempertimbangkan penggunaan sensor ultrasonik.
Secara pribadi, saya pertama kali melihat PLC, hanya ketika saya mengunjungi situs pelanggan. Sebagai seorang pengembang, saya belum pernah bertemu mereka sebelumnya, dan itu agak tidak menyenangkan: segera setelah kami menggali lebih dalam dari dua, tiga, dan empat fase motor dalam percakapan, saya mulai kehilangan utas. Sekitar 80% dari kata-kata itu masih dapat dipahami, tetapi makna umum dengan keras kepala hilang begitu saja. Secara umum, ini adalah masalah serius, yang akar-akarnya berada pada ambang batas yang cukup tinggi untuk memasuki pemrograman PLC - komputer mikro tempat Anda benar-benar dapat melakukan sesuatu dengan biaya setidaknya $ 200-300. Pemrograman itu sendiri tidak rumit, dan masalah dimulai hanya ketika sensor terpasang ke konveyor atau motor nyata.
 Perangkat Sensor Standar 37-in-1
Perangkat Sensor Standar 37-in-1Sensor, seperti yang Anda tahu, berbeda. Yang paling sederhana yang berhasil kami temukan harganya mulai $ 18. Karakteristik utama - "bandwidth dan resolusi" - berapa banyak data yang ditransmisikan sensor dalam satu menit. Dari pengalaman saya sendiri, saya dapat mengatakan bahwa jika sebuah pabrikan mengklaim, katakanlah, 30 titik data per menit, pada kenyataannya jumlah mereka tidak mungkin lebih dari 15. Dan ini juga menimbulkan masalah serius: topiknya modis, dan beberapa perusahaan berusaha menghasilkan uang dengan hype ini. Kami menguji sensor senilai $ 158, bandwidth yang secara teoritis memungkinkan untuk membuang sebagian kode kami. Tetapi pada kenyataannya, mereka ternyata menjadi analog absolut dari perangkat yang sama seharga $ 18 masing-masing.
Tahap pertama: kita lampirkan sensor, mengumpulkan data
Sebenarnya, fase pertama dari proyek ini adalah instalasi perangkat keras, instalasi itu sendiri adalah proses yang panjang dan membosankan. Ini juga merupakan ilmu keseluruhan - data yang dikumpulkannya tergantung pada bagaimana Anda memasang sensor ke motor atau kotak. Kami memiliki case ketika salah satu dari dua sensor identik terpasang di dalam kotak, dan yang lainnya di luar. Logika menunjukkan bahwa suhu di dalam harus lebih tinggi, tetapi data yang dikumpulkan menunjukkan sebaliknya. Ternyata sistem gagal, tetapi ketika pengembang tiba di pabrik, ia melihat bahwa sensor tidak hanya di dalam kotak, tetapi tepat di kipas yang terletak di sana.
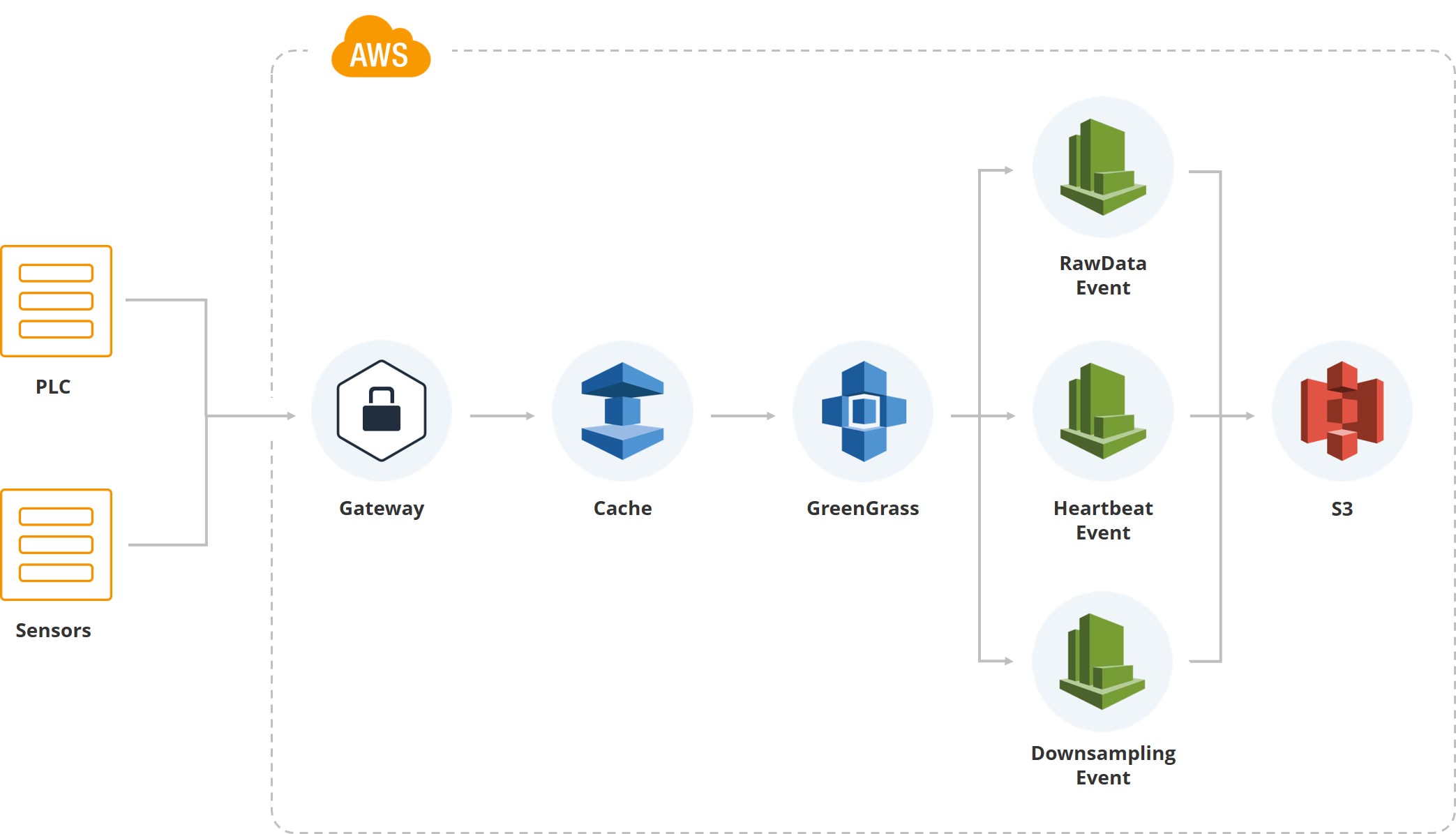
Ilustrasi ini menunjukkan bagaimana data pertama memasuki sistem. Kami memiliki gateway, ada PLC dan sensor yang terkait dengannya. Lebih lanjut, tentu saja, peralatan cache biasanya berjalan pada kartu seluler dan semua data dikirimkan melalui Internet seluler. Karena salah satu pusat penyortiran pelanggan terletak di area di mana sering terjadi badai, dan koneksi mungkin terputus, kami mengakumulasikan data pada gateway hingga dipulihkan.
Selanjutnya, kami menggunakan layanan Greengrass dari Amazon, yang mengirimkan data di dalam sistem cloud (AWS).
Segera setelah data di dalam cloud, banyak peristiwa dipicu. Misalnya, kami memiliki acara untuk data mentah yang menyimpan data sistem file. Ada "detak jantung" untuk menunjukkan kinerja sistem normal. Ada "downsampling", yang digunakan untuk tampilan pada UI, dan untuk pemrosesan (nilai rata-rata, katakanlah, per menit untuk indikator tertentu) diambil. Artinya, selain data mentah, kami memiliki data downsampling yang jatuh di layar pengguna yang memantau sistem.
Data mentah disimpan dalam format parket. Awalnya kami memilih JSON, lalu kami mencoba CSV, tetapi pada akhirnya kami sampai pada kesimpulan bahwa tim analisis dan tim pengembangan puas dengan "parket".
Sebenarnya, versi pertama sistem dibangun di DynamoDB, dan saya tidak ingin mengatakan hal buruk tentang database ini. Hanya saja begitu kami mendapat analitik - ahli matematika yang harus bekerja dengan data yang diperoleh - ternyata bahasa permintaan di DynamoDB terlalu rumit untuk mereka. Mereka harus secara khusus menyiapkan data untuk ML dan analitik. Oleh karena itu, kami memilih Athena, editor kueri di AWS. Bagi kami, keuntungannya adalah memungkinkan Anda membaca data Parket, menulis SQL, dan mengumpulkan hasilnya dalam file CSV. Apa yang dibutuhkan tim analisis.
Tahap kedua: apa yang kita analisis?
Jadi, dari satu objek kecil, kami mengumpulkan sekitar 3 GB data mentah. Sekarang kita tahu banyak tentang suhu, getaran, dan akselerasi aksial. Jadi, inilah saatnya matematikawan kita berkumpul untuk memahami bagaimana dan, pada kenyataannya, apa yang kita coba prediksi berdasarkan informasi ini.
Tujuannya adalah untuk meminimalkan waktu henti peralatan. Orang-orang memasuki pabrik Coca-Cola ini hanya ketika mereka menerima sinyal tentang kerusakan, kebocoran minyak, atau, katakanlah, genangan air di lantai. Biaya satu robot dimulai dengan $ 30.000 dolar, tetapi hampir semua produksi dibangun di atasnya
Orang-orang memasuki pabrik Coca-Cola ini hanya ketika mereka menerima sinyal tentang kerusakan, kebocoran minyak, atau, katakanlah, genangan air di lantai. Biaya satu robot dimulai dengan $ 30.000 dolar, tetapi hampir semua produksi dibangun di atasnya Sekitar 10.000 orang bekerja di enam pabrik Tesla, dan untuk produksi skala seperti ini sangat sedikit. Menariknya, pabrik Mercedes bahkan lebih otomatis. Jelas bahwa semua robot yang terlibat perlu pemantauan terus-menerus
Sekitar 10.000 orang bekerja di enam pabrik Tesla, dan untuk produksi skala seperti ini sangat sedikit. Menariknya, pabrik Mercedes bahkan lebih otomatis. Jelas bahwa semua robot yang terlibat perlu pemantauan terus-menerusSemakin mahal robot, semakin sedikit bagian kerjanya yang bergetar. Dengan tindakan sederhana, ini mungkin tidak menentukan, tetapi operasi yang lebih halus, katakanlah dengan leher botol, mengharuskannya diminimalkan. Tentu saja, tingkat getaran mobil mahal harus terus dipantau.
Layanan yang menghemat waktu
Kami meluncurkan instalasi pertama hanya dalam waktu tiga bulan, dan saya pikir ini cepat.
 Sebenarnya, ini adalah lima poin utama yang memungkinkan untuk menyelamatkan upaya pembangunan
Sebenarnya, ini adalah lima poin utama yang memungkinkan untuk menyelamatkan upaya pembangunanHal pertama yang kami kurangi untuk timeline adalah bahwa sebagian besar sistem dibangun pada AWS, yang diskalakan dengan sendirinya. Segera setelah jumlah pengguna melebihi ambang tertentu, pemindaian otomatis dipicu, dan tidak ada tim yang harus menghabiskan waktu untuk hal ini.
Saya ingin menarik perhatian pada dua nuansa. Pertama, kami bekerja dengan volume data yang besar, dan dalam versi pertama dari sistem kami memiliki jaringan pipa untuk membuat cadangan. Setelah beberapa waktu, data menjadi terlalu banyak, dan menyimpan salinan untuk mereka menjadi terlalu mahal. Lalu, kami hanya membiarkan data mentah tergeletak di ember hanya-baca, melarangnya dihapus, dan menolak cadangan.
Sistem kami melibatkan integrasi berkelanjutan, untuk mendukung situs baru dan instalasi baru tidak memakan banyak waktu.
Jelas bahwa waktu nyata dibangun di atas peristiwa. Meskipun, tentu saja, kesulitan muncul karena fakta bahwa beberapa peristiwa bekerja dua kali atau sistem kehilangan sentuhan, misalnya, karena kondisi cuaca.
Enkripsi data, seperti yang dipersyaratkan oleh pelanggan, secara otomatis dilakukan di AWS. Setiap klien memiliki embernya sendiri, dan kami tidak melakukan apa pun yang kami enkripsi.
Bertemu dengan analis
Kami menerima kode pertama dalam format PDF bersama dengan permintaan untuk menerapkan satu atau model lain. Sampai kami mulai menerima kode dalam bentuk .ipynb, itu mengkhawatirkan, tetapi faktanya analis adalah ahli matematika yang jauh dari pemrograman. Semua operasi kami berlangsung di cloud, kami tidak mengizinkan mengunduh data. Bersama-sama, semua poin ini mendorong kami untuk mencoba platform SageMaker.
SageMaker memungkinkan Anda untuk menggunakan sekitar 80 algoritma di luar kotak, termasuk kerangka kerja: Caffe2, Mxnet, Gluon, TensorFlow, Pytorch, kit alat kognitif Microsoft. Saat ini kami menggunakan Keras + TensorFlow, tetapi semua orang kecuali alat kognitif Microsoft berhasil mencoba. Cakupan luas seperti itu memungkinkan kami untuk tidak membatasi tim analisis kami sendiri.

Tiga sampai empat bulan pertama, orang melakukan semua pekerjaan dengan bantuan matematika sederhana, benar-benar tidak ada ML. Bagian dari sistem ini didasarkan pada hukum matematika murni, dan dirancang untuk data statistik. Yaitu, kami memantau tingkat suhu rata-rata, dan jika kami melihat bahwa itu mati skala, peringatan dipicu.
Kemudian ikuti pelatihan model. Semuanya terlihat mudah dan sederhana, dan sepertinya sebelum dimulainya implementasi.
Bangun, latih, gunakan ...

Saya akan menjelaskan secara singkat bagaimana kita keluar dari situasi tersebut. Lihatlah kolom kedua: kami mengumpulkan data, mengolahnya, membersihkannya, menggunakan S3 bucket dan Glue untuk meluncurkan acara dan membuat "partisi". Kami memiliki semua data yang diatur dalam partisi untuk Athena, ini juga merupakan nuansa yang penting, karena Athena dibangun di atas S3. Athena sendiri sangat murah. Tetapi kami membayar untuk membaca data dan mengeluarkannya dari S3, karena setiap permintaan bisa sangat mahal. Oleh karena itu, kami memiliki sistem partisi yang besar.
Kami memiliki downtime. Dan Amazon EMR, yang memungkinkan Anda mengumpulkan data dengan cepat. Sebenarnya, untuk rekayasa fitur, di cloud kami, untuk setiap analis, Notebook Jupyter diangkat - ini adalah contoh mereka sendiri. Dan mereka menganalisis semuanya secara langsung di cloud itu sendiri.
Berkat SageMaker, kami dapat melewati fase Training Clusters. Jika kami tidak menggunakan platform ini, kami harus meningkatkan cluster di Amazon, dan salah satu insinyur DevOps harus mengikuti mereka. SageMaker memungkinkan menggunakan parameter metode, gambar pada Docker untuk menaikkan cluster, tetap saja untuk menunjukkan jumlah instance dalam parameter yang ingin Anda gunakan.
Selanjutnya, kita tidak harus berurusan dengan penskalaan. Jika kami ingin memproses beberapa algoritma besar atau jika kami sangat perlu menghitung sesuatu, kami mengaktifkan autoscaling (semuanya tergantung pada apakah Anda ingin menggunakan CPU atau GPU).
Selain itu, semua model kami dienkripsi: ini juga keluar dari kotak di SageMaker - binari yang ada di S3.
Penerapan model
Kami sedang mendekati model pertama yang digunakan dalam suatu lingkungan. Sebenarnya, SageMaker memungkinkan Anda untuk menyimpan artefak model, tetapi hanya pada tahap ini kami memiliki banyak kontroversi, karena SageMaker memiliki format model sendiri. Kami ingin menghindarinya, menyingkirkan pembatasan, sehingga model kami disimpan dalam format acar sehingga kami dapat menggunakan bahkan Keras, bahkan TensorFlow atau yang lainnya jika diinginkan. Meskipun kami menggunakan model pertama dari SageMaker, sebagaimana adanya, melalui API asli.
SageMaker memungkinkan Anda menyederhanakan pekerjaan dalam tiga tahap. Setiap kali Anda mencoba memprediksi sesuatu, Anda harus memulai proses tertentu, memberikan data, dan mendapatkan nilai prediksi. Semuanya berjalan baik dengan ini sampai algoritma kustom diperlukan.

Analis tahu bahwa mereka memiliki CI dan repositori. Ada folder di repositori CI di mana mereka harus meletakkan tiga file. Serve.py adalah file yang memungkinkan SageMaker untuk meningkatkan layanan Flask dan berkomunikasi dengan SageMaker sendiri. Train.py adalah kelas dengan metode kereta, di mana mereka harus meletakkan semua yang diperlukan untuk model. Akhirnya, predict.py - dengan bantuannya mereka menaikkan kelas ini, di dalamnya ada metode. Memiliki akses, mereka meningkatkan semua jenis sumber daya dari S3 dari sana - di dalam SageMaker kami memiliki gambar yang memungkinkan Anda untuk menjalankan apa pun dari antarmuka dan secara terprogram (kami tidak membatasi mereka).
Dari SageMaker kita mendapatkan akses ke predict.py - gambar di dalam hanyalah aplikasi Flask yang memungkinkan Anda untuk memanggil prediksi atau berlatih dengan parameter tertentu. Semua ini terkait dengan S3 dan, di samping itu, mereka memiliki kemampuan untuk menyimpan model dari Notebook Jupyter. Yaitu, di Notebook Jupyter, analis memiliki akses ke semua data, dan mereka dapat melakukan semacam eksperimen.
Dalam produksi, semua ini jatuh sebagai berikut. Kami memiliki pengguna, ada nilai akhir yang diprediksi. Data terletak pada S3 dan pergi ke Athena. Setiap dua jam, sebuah algoritma diluncurkan yang menghitung prediksi untuk dua jam berikutnya. Langkah waktu ini disebabkan oleh fakta bahwa dalam kasus kami, sekitar 6 jam analitik sudah cukup untuk mengatakan bahwa ada sesuatu yang salah dengan motor. Bahkan pada saat dinyalakan, motor memanas dari 5-10 menit, dan lompatan yang tajam tidak terjadi.
Dalam sistem kritis, katakanlah, ketika Air France memeriksa turbin pesawat, prediksi dilakukan pada kecepatan 10 menit. Dalam hal ini, akurasinya adalah 96,5%.
Jika kami melihat ada sesuatu yang salah, sistem notifikasi menyala. Kemudian salah satu dari banyak pengguna pada arloji atau perangkat lain menerima pemberitahuan bahwa motor tertentu berperilaku tidak normal. Dia pergi dan memeriksa kondisinya.
Kelola instance notebook
Padahal, semuanya sangat sederhana. Datang untuk bekerja, analis meluncurkan contoh di Notebook Jupyter. Dia mendapatkan peran dan sesi, sehingga dua orang tidak dapat mengedit file yang sama. Sebenarnya, kami sekarang memiliki contoh untuk setiap analis.
Buat pekerjaan pelatihan
SageMaker memiliki pemahaman tentang pekerjaan pelatihan. Hasilnya, jika Anda hanya menggunakan API - biner yang disimpan di S3: dari parameter yang Anda berikan, model Anda diperoleh.
sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed')
Contoh Pelatihan Params
{ "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] }
Parameter Yang pertama adalah peran: Anda harus menunjukkan akses instance SageMaker Anda. Artinya, dalam kasus kami, jika analis bekerja dengan dua produksi yang berbeda, ia harus melihat satu ember dan tidak melihat yang lain. Konfigurasi output adalah tempat Anda menyimpan semua metadata model.
Kami melewati skala otomatis dan hanya dapat menentukan jumlah instance yang Anda inginkan untuk menjalankan pekerjaan pelatihan ini. Pada awalnya, kami biasanya menggunakan instance menengah tanpa TensorFlow atau Keras, dan itu sudah cukup.
Hyperparameter Anda menentukan gambar Docker di mana Anda ingin memulai. Sebagai aturan, Amazon menyediakan daftar algoritma dan gambar mereka, yaitu, Anda harus menentukan hyperparameters - parameter dari algoritma itu sendiri.
Buat model
%%time import boto3 from time import gmtime, strftime job_name = 'kmeans-lowlevel-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print("Training job", job_name) from sagemaker.amazon.amazon_estimator import get_image_uri image = get_image_uri(boto3.Session().region_name, 'kmeans') output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training artifacts will be uploaded to: {}'.format(output_location)) create_training_params = \ { "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] } sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed') %%time import boto3 from time import gmtime, strftime model_name=job_name print(model_name) info = sagemaker.describe_training_job(TrainingJobName=job_name) model_data = info['ModelArtifacts']['S3ModelArtifacts'] print(info['ModelArtifacts']) primary_container = { 'Image': image, 'ModelDataUrl': model_data } create_model_response = sagemaker.create_model( ModelName = model_name, ExecutionRoleArn = role, PrimaryContainer = primary_container) print(create_model_response['ModelArn'])
Membuat model adalah hasil dari pekerjaan pelatihan. Setelah yang terakhir selesai, dan ketika Anda memantaunya, itu disimpan pada S3, dan Anda bisa menggunakannya.

Begitulah terlihat dari sudut pandang analis. Analis kami pergi ke model dan berkata: dalam gambar ini saya ingin meluncurkan model ini. Mereka hanya menunjuk ke folder S3, Gambar dan memasukkan parameter ke antarmuka grafis. Tetapi ada nuansa dan kesulitan, jadi kami beralih ke algoritme khusus.
Buat titik akhir
%%time import time endpoint_name = 'KMeansEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print(endpoint_name) create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name) print(create_endpoint_response['EndpointArn']) resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Status: " + status) try: sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name) finally: resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Arn: " + resp['EndpointArn']) print("Create endpoint ended with status: " + status) if status != 'InService': message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Endpoint creation did not succeed')
Begitu banyak kode yang diperlukan untuk membuat Endpoint yang berkedut dari lambda dan dari luar. Setiap dua jam, sebuah peristiwa dipicu yang menarik Endpoint.
Tampilan titik akhir

Beginilah cara analis melihatnya. Mereka hanya menunjukkan algoritma, waktu dan menariknya dengan tangannya dari antarmuka.
Aktifkan titik akhir
import json payload = np2csv(train_set[0][30:31]) response = runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType='text/csv', Body=payload) result = json.loads(response['Body'].read().decode()) print(result)
Dan ini adalah bagaimana hal itu dilakukan dari lambda. Artinya, kami memiliki Endpoint di dalamnya, dan setiap dua jam kami mengirim payload untuk membuat prediksi.
Tautan SageMaker yang Berguna: tautan github
Ini adalah tautan yang sangat penting. Sejujurnya, setelah kami mulai menggunakan GUI Sagemaker yang biasa, semua orang mengerti bahwa cepat atau lambat kami akan sampai pada algoritma kustom, dan semua ini akan dirakit secara manual. Dengan menggunakan tautan ini, Anda tidak hanya dapat menemukan penggunaan algoritme, tetapi juga kumpulan gambar khusus:
github.com/awslabs/amazon-sagemaker-examplesgithub.com/aws-samples/aws-ml-vision-end2endgithub.com/juliensimongithub.com/aws/sagemaker-sparkApa selanjutnya
Kami mendekati produksi keempat dan sekarang, selain analitik, kami memiliki dua jalur pengembangan. Pertama, kami mencoba untuk mendapatkan kayu dari mekanik, yaitu kami mencoba datang ke pelatihan dengan dukungan. Log Mantainence pertama yang kami terima terlihat seperti ini: sesuatu pecah pada hari Senin, saya tiba di sana pada hari Rabu, dan mulai memperbaikinya pada hari Jumat. Kami sekarang mencoba untuk memasok pelanggan dengan CMS - sistem manajemen konten yang akan memungkinkan pencatatan peristiwa kegagalan.
Bagaimana ini dilakukan? Sebagai aturan, segera setelah kerusakan terjadi, mekanik tiba dan mengubah bagian dengan sangat cepat, tetapi ia dapat mengisi semua jenis kertas, katakanlah, dalam seminggu. Pada saat ini, orang tersebut hanya melupakan apa yang sebenarnya terjadi pada bagian itu. CMS, tentu saja, membawa kita ke tingkat interaksi baru dengan mekanik.
Kedua, kita akan menginstal sensor ultrasonik pada motor yang membaca suara dan terlibat dalam analisis spektral.
Mungkin saja kita akan meninggalkan Athena, karena pada data besar, menggunakan S3 itu mahal. Pada saat yang sama, Microsoft baru-baru ini mengumumkan layanannya sendiri, dan salah satu pelanggan kami ingin mencoba melakukan hal yang sama pada Azure. Sebenarnya, salah satu kelebihan sistem kami adalah dapat dibongkar dan dirakit di tempat lain, seperti dari kubus.