Setiap tahun di Moskow, konferensi
Dialog diadakan, di mana ahli bahasa dan spesialis analisis data berpartisipasi. Mereka membahas apa itu bahasa alami, bagaimana cara mengajar mesin untuk memahami dan memprosesnya. Konferensi ini secara tradisional mengadakan kompetisi (trek)
Evaluasi Dialog . Mereka dapat dihadiri oleh perwakilan dari perusahaan besar yang menciptakan solusi di bidang pemrosesan bahasa alami (Natural Language Processing, NLP), serta para peneliti individu. Mungkin terlihat bahwa jika Anda seorang siswa yang sederhana, maka apakah Anda bersaing dengan sistem yang dibuat oleh spesialis besar perusahaan besar selama bertahun-tahun. Evaluasi Dialog - ini persis seperti ketika di klasemen akhir seorang siswa sederhana mungkin lebih tinggi daripada perusahaan terkenal.
Tahun ini akan menjadi yang ke-9 berturut-turut ketika Evaluasi Dialog diadakan di Dialog. Setiap tahun jumlah kompetisi berbeda. Tugas NLP seperti Analisis Sentimen, Induksi Kata Sense, Koreksi Ejaan Otomatis, Pengakuan Entitas Bernama, dan lainnya telah menjadi topik untuk trek.

Tahun ini, empat kelompok penyelenggara menyiapkan trek seperti itu:
- Generasi berita utama untuk artikel berita.
- Resolusi anafora dan coreference.
- Analisis morfologis pada materi bahasa sumber daya rendah.
- Analisis otomatis dari salah satu jenis elipsis (gapping).
Hari ini kita akan berbicara tentang yang terakhir: apa itu elips dan mengapa mengajarkan mobil cara mengembalikannya dalam teks, bagaimana kita membuat gedung baru untuk mengatasi masalah ini, bagaimana kompetisi diadakan dan hasil apa yang bisa dicapai oleh para peserta.
AGRR-2019 (Resolusi Gapping Otomatis untuk Bahasa Rusia)
Pada musim gugur 2018, kami menghadapi tugas penelitian yang terkait dengan elips - penghilangan yang disengaja dari rangkaian kata dalam teks yang dapat dipulihkan dari konteks. Bagaimana cara secara otomatis menemukan celah seperti itu dalam teks dan mengisinya dengan benar? Mudah bagi penutur asli, tetapi mengajarkan mobil ini tidak mudah. Cukup cepat menjadi jelas bahwa ini adalah bahan yang baik untuk kompetisi, dan kami mulai berbisnis.
Pengorganisasian kompetisi pada topik baru memiliki karakteristiknya sendiri, dan bagi kami, semua itu tampaknya lebih penting. Salah satu hal utama adalah pembuatan corpus (banyak teks dengan markup yang dapat Anda pelajari). Seperti apa bentuknya dan berapa seharusnya? Untuk banyak tugas, ada standar untuk penyajian data yang menjadi dasar pengembangannya. Misalnya, untuk
tugas mengidentifikasi entitas bernama , skema markup IO / BIO / IOBES telah dikembangkan, untuk tugas parsing sintaksis dan morfologis format CONLL secara tradisional digunakan, tidak ada yang perlu diciptakan, tetapi pedoman harus diikuti dengan ketat.
Dalam kasus kami, terserah kami untuk mengumpulkan korps dan merumuskan tugas.
Inilah tugas semacam itu ...
Di sini kita pasti harus membuat pengenalan linguistik populer tentang apa ellipsis secara umum dan gapping sebagai salah satu tipenya.
Apa pun gagasan yang Anda miliki tentang bahasa, sulit untuk menyatakan bahwa tingkat ekspresi (teks atau ucapan) bukan satu-satunya. Ungkapan tersebut adalah puncak gunung es. Gunung es itu sendiri meliputi penilaian pragmatis, pembangunan struktur sintaksis, pemilihan bahan leksikal dan sebagainya. Ellipsis adalah sebuah fenomena yang dengan indah menghubungkan permukaan dengan kedalaman. Ini adalah penghilangan elemen sintaksis rangkap. Jika kami menyajikan struktur sintaksis sebuah kalimat dalam bentuk pohon dan sub pohon yang sama dapat dipilih di pohon ini, maka sering (tetapi tidak selalu) agar kalimat menjadi alami, elemen duplikat dihapus. Penghapusan seperti itu disebut elipsis (contoh 1).
(1)
Mereka tidak menelepon saya kembali, dan saya tidak mengerti mengapa mereka tidak menelepon saya kembali .Kesenjangan yang diperoleh elipsis dapat dipulihkan dengan jelas dari konteks bahasa. Bandingkan contoh pertama dengan yang kedua (2), di mana ada pass, tetapi apa sebenarnya yang hilang tidak jelas. Kasing ini bukan elipsis.
(2)
Gapping adalah salah satu jenis frekuensi elipsis. Pertimbangkan contoh (3) dan pahami cara kerjanya.
(3)
Saya mengira dia orang Italia, dan dia orang Swedia.Dalam semua contoh ada lebih dari dua kalimat (klausa), mereka terdiri di antara mereka sendiri. Pada klausa pertama ada kata kerja (ahli bahasa lebih cenderung mengatakan "predikat") dan pesertanya
menerimanya :
Saya ,
dia, dan
Italia . Pada klausa kedua tidak ada kata kerja yang diutarakan, hanya ada "sisa" (atau sisa) dari kata
itu dan
untuk orang Swedia yang tidak terkait secara sintaksis, tetapi kami mengerti bagaimana celah dikembalikan.
Untuk mengembalikan pass, kita beralih ke klausa pertama dan menyalin seluruh struktur darinya (contoh 4). Kami mengganti hanya bagian-bagian yang ada sisa-sisa "paralel" dalam klausa yang tidak lengkap. Kami menyalin predikat,
kami menggantinya dengan
itu ,
untuk Italia kami menggantinya dengan sisa
untuk Swedia . Bagi
saya, tidak ada sisa paralel, yang berarti kami menyalinnya tanpa penggantian.
(4)
Saya salah mengira dia orang Italia, dan saya salah mengira dia orang Swedia.Tampaknya untuk mengembalikan celah, cukup bagi kita untuk menentukan apakah ada celah dalam kalimat ini, menemukan klausa yang tidak lengkap dan seluruh klausa yang terkait dengannya (dari mana bahan untuk restorasi diambil), dan kemudian memahami apa "sisa" (sisa) dalam klausa tidak lengkap dan apa yang mereka sesuai penuh. Tampaknya kondisi ini cukup untuk mengisi celah secara efektif. Jadi, kami mencoba untuk meniru proses di kepala seseorang membaca atau mendengar teks yang mungkin ada kelalaian.
Jadi, mengapa ini dibutuhkan?
Jelas bahwa bagi seseorang yang pertama kali mendengar tentang ellipsis dan kesulitan pemrosesan yang terkait dengannya, sebuah pertanyaan yang sah mungkin muncul, "Mengapa?" Skeptis ingin
mengajak para bapak ilmu linguistik untuk
membaca untuk menjelaskan bahwa jika solusi dari masalah terapan menyediakan bahan yang dapat berguna dalam penelitian teoretis, maka ini sudah merupakan jawaban yang cukup untuk pertanyaan tentang tujuan kegiatan semacam itu.
Para ahli teori telah mempelajari elipsis dalam berbagai bahasa selama sekitar 50 tahun, menjelaskan keterbatasan, menyoroti pola umum dalam berbagai bahasa. Pada saat yang sama, kita tidak menyadari keberadaan corpus yang menggambarkan semua jenis elipsis dengan lebih dari beberapa ratus contoh. Ini sebagian disebabkan oleh kelangkaan fenomena (misalnya, pada data kami, grapping ditemukan dalam tidak lebih dari 5 kalimat dari 10 ribu). Jadi penciptaan korps semacam itu sudah merupakan hasil yang penting.
Dalam sistem aplikasi yang bekerja dengan data teks, kelangkaan fenomena memungkinkan Anda untuk mengabaikannya. Ketidakmampuan parser sintaksis untuk mengembalikan celah yang hilang tidak benar-benar membawa banyak kesalahan. Tetapi dari peristiwa langka, pinggiran linguistik yang luas dan beraneka ragam terbentuk. Tampaknya pengalaman memecahkan masalah seperti itu sendiri harus menarik bagi mereka yang ingin membuat sistem yang bekerja tidak hanya pada teks sederhana, pendek, bersih dengan kosa kata umum, yaitu, pada teks berbentuk bola dalam ruang hampa yang praktis tidak terjadi di alam.
Beberapa parser memiliki sistem yang efektif untuk mendeteksi dan menyelesaikan elipsis. Tetapi dalam parser internal ABBYY ada modul yang bertanggung jawab untuk mengembalikan pass, dan didasarkan pada aturan yang ditulis secara manual. Berkat kemampuan parser ini, kami dapat membuat badan besar untuk kompetisi. Manfaat potensial bagi parser asli adalah mengganti modul yang berjalan lambat. Juga, saat mengerjakan kasus ini, kami melakukan analisis terperinci atas kesalahan sistem saat ini.
Bagaimana kami menciptakan tubuh
Bangunan kami terutama ditujukan untuk pelatihan sistem otomatis, yang berarti bahwa sangat penting untuk menjadi produktif dan beragam. Dipandu oleh ini, kami membangun pekerjaan pengumpulan data sebagai berikut. Untuk korps, kami memilih teks dari berbagai genre: dari dokumentasi teknis dan paten hingga berita dan posting dari media sosial. Semuanya ditandai oleh parser ABBYY. Dalam sebulan, kami mendistribusikan data antara ahli bahasa-juru tulis. Penanda diundang, tanpa mengubah markup, untuk mengevaluasinya dalam skala:
0 - tidak ada pemetaan dalam kalimat, markupnya tidak relevan.
1 - ada pemetaan, dan markupnya benar.
2 - ada celah, tetapi ada sesuatu yang salah dengan markup.
3 - kasus yang rumit, apakah ini pemetaan?
Akibatnya, masing-masing kelompok menjadi berguna. Contoh dari kategori 1 termasuk dalam kelas positif dari dataset kami. Kami pada dasarnya tidak ingin mengambil sampel contoh dari kategori 2 dan 3 secara manual untuk menghemat waktu, tetapi contoh-contoh ini berguna bagi kami nanti untuk mengevaluasi korpus yang kami hasilkan. Dari mereka, orang dapat menilai kasus mana yang secara konsisten salah ditandai oleh sistem, yang berarti mereka tidak termasuk dalam korps kami. Dan akhirnya, termasuk dalam contoh kasus yang diberikan oleh spidol ke kategori 0, kami memberikan sistem kesempatan untuk "belajar dari kesalahan orang lain", yaitu, tidak hanya mensimulasikan perilaku sistem asli, tetapi bekerja lebih baik daripada itu.
Setiap contoh dievaluasi oleh dua spidol. Setelah itu, sedikit lebih dari setengah proposal masuk ke korps dari sumber data. Seluruh kelas contoh positif dan bagian negatif terdiri dari mereka. Kami memutuskan untuk membuat kelas negatif dua kali lebih positif sehingga, di satu sisi, kelas-kelasnya sebanding dalam volume, dan di sisi lain, dominannya kelas negatif yang ada dalam bahasa tersebut dipertahankan.
Untuk memenuhi proporsi ini, kami harus menambahkan lebih banyak contoh negatif pada case, selain contoh yang dijelaskan pada kategori 0. Mari kita berikan contoh (5) dari kategori 0, yang dapat membingungkan tidak hanya mobil, tetapi juga orangnya.
(5)
Tetapi pada saat itu Jack jatuh cinta dengan Cindy Page, sekarang Ny. Jack Svaytek.Pada klausa kedua, dia tidak pulih
dalam cinta , karena maksud saya sekarang Cindy Page telah menjadi Ny. Jack Svaytek karena dia menikahinya.
Secara umum, untuk fenomena sintaksis yang relatif jarang seperti gapping, contoh negatifnya adalah hampir semua kalimat acak dari bahasa tersebut, karena kemungkinan ada gapping kecil dalam kalimat acak. Namun, penggunaan contoh negatif tersebut dapat menyebabkan pelatihan ulang pada tanda baca. Dalam kasus kami, contoh-contoh untuk kelas negatif diperoleh berdasarkan kriteria sederhana: kehadiran kata kerja, kehadiran koma atau tanda hubung, panjang kalimat minimum tidak kurang dari 6 token.
Untuk kompetisi, kami memilih dari bagian pengembangan bangunan pelatihan (dalam perbandingan 1: 5), yang para peserta diundang untuk menggunakan untuk mengkonfigurasi sistem mereka. Versi terakhir dari sistem dilatih pada kereta gabungan dan bagian dev. Kami memberi label secara manual pada test case kami sendiri, dalam hal volume, ini adalah bagian ke 10 dari train + dev. Berikut adalah jumlah contoh kelas yang tepat:
Selain data pelatihan yang diverifikasi secara manual, kami menambahkan file markup mentah yang diterima dari sistem sumber. Ada lebih dari 100 ribu contoh di dalamnya, dan para peserta dapat secara opsional menggunakan data ini untuk menambah sampel pelatihan. Ke depan, kami mengatakan bahwa hanya satu peserta yang tahu cara meningkatkan gedung pelatihan secara signifikan menggunakan data kotor tanpa kehilangan kualitas.
Format markup
Kami sengaja menolak untuk menggunakan parser pihak ketiga dan mengembangkan markup di mana semua elemen yang menarik bagi kami ditandai secara linier di baris teks. Kami menggunakan dua jenis markup. Yang pertama, dapat dibaca oleh manusia, dirancang untuk bekerja dengan markup, dan mudah untuk menganalisis kesalahan dari sistem yang dihasilkan. Dengan metode ini, semua elemen gapping ditandai dengan tanda kurung di dalam kalimat. Setiap pasangan tanda kurung ditandai dengan nama elemen yang sesuai. Kami menggunakan notasi berikut:

Kami memberikan contoh kalimat dengan gapping dengan tanda kurung.
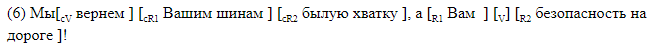
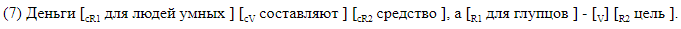

Penandaan braket cocok untuk analisis material. Dalam hal ini, data disimpan dalam format yang berbeda, yang, jika diinginkan, dapat dengan mudah diubah menjadi braket. Satu baris sesuai dengan satu kalimat. Kolom menunjukkan adanya celah dalam kalimat, dan untuk setiap label yang mungkin dalam kolomnya, ganti simbol dari awal dan akhir segmen yang sesuai dengan elemen diberikan. Ini adalah bagaimana markup offset terlihat, sesuai dengan markup braket di ().
Tugas untuk peserta
Peserta AGRR-2019 dapat memecahkan salah satu dari tiga masalah berikut:
- Klasifikasi biner Perlu untuk menentukan apakah ada celah dalam kalimat.
- Izin gapping. Perlu untuk mengembalikan posisi pass (V) dan posisi pengontrol kata kerja (cV).
- Markup penuh. Anda perlu mendefinisikan offset untuk semua elemen dari gapping.
Setiap tugas selanjutnya harus entah bagaimana menyelesaikan yang sebelumnya. Jelas bahwa markup apa pun hanya mungkin dalam kalimat di mana klasifikasi biner menunjukkan kelas positif (ada pemetaan), dan markup lengkap juga mencakup menemukan batas-batas predikat yang hilang dan mengendalikan.
Metrik
Untuk masalah klasifikasi biner, kami menggunakan metrik standar: keakuratan dan kelengkapan, dan hasil para peserta diberi peringkat berdasarkan ukuran-f.
Untuk tugas menyelesaikan gapping dan markup lengkap, kami memutuskan untuk menggunakan ukuran-s simbol, karena teks sumber tidak tokenized dan kami tidak ingin perbedaan dalam tokenizer yang digunakan oleh peserta untuk mempengaruhi hasil. Contoh-contoh benar-negatif tidak berkontribusi pada ukuran-f simbolik, untuk setiap elemen markup ukuran-f mereka sendiri dipertimbangkan, hasil akhir diperoleh dengan rata-rata makro atas seluruh tubuh. Berkat perhitungan metrik seperti itu, kasus positif palsu didenda secara signifikan, yang penting ketika ada banyak contoh yang kurang positif dalam data nyata daripada yang negatif.
Kursus kompetisi
Sejalan dengan perakitan gedung, kami menerima aplikasi untuk berpartisipasi dalam kompetisi. Sebagai hasilnya, kami mendaftarkan lebih dari 40 peserta. Kemudian kami meletakkan gedung pelatihan dan meluncurkan kompetisi. Peserta memiliki 4 minggu untuk membangun model mereka.
Tahap mengevaluasi hasil adalah sebagai berikut: para peserta menerima 20 ribu penawaran tanpa markup, di mana kasus uji terlibat. Tim harus menandai data ini dengan sistem mereka, setelah itu kami mengevaluasi hasil tanda pada bangunan tes. Mencampur tes dalam sejumlah besar data menjamin kami bahwa, dengan semua keinginan kami, kasing tidak dapat ditandai secara manual dalam beberapa hari yang diberikan untuk pelarian (penandaan otomatis).
Hasil Kompetisi
Sembilan tim mencapai final, termasuk perwakilan dari dua perusahaan IT, peneliti dari Moscow State University, Institut Fisika dan Teknologi Moskow, HSE dan IPPI RAS.
Semua kecuali satu tim berpartisipasi dalam ketiga kompetisi. Berdasarkan ketentuan AGRR-2019, semua tim menerbitkan kode untuk keputusan mereka. Tabel ringkasan dengan hasilnya diberikan di
repositori kami , di mana Anda juga dapat menemukan tautan ke solusi tim yang telah disusun dengan deskripsi singkat.
Hampir semua menunjukkan hasil yang baik. Berikut adalah penilaian dari keputusan tim yang menang:
Penjelasan terperinci tentang solusi teratas akan segera tersedia di artikel para peserta dalam koleksi Dialog.
Jadi, dalam artikel ini kita berbicara tentang bagaimana, mengambil sebagai dasar fenomena linguistik yang langka, untuk merumuskan tugas, menyiapkan korps dan melakukan kompetisi. Ada juga manfaat dari pekerjaan seperti itu untuk komunitas NLP, karena kompetisi membantu untuk membandingkan arsitektur dan pendekatan yang berbeda satu sama lain pada materi tertentu, dan ahli bahasa mendapatkan kasus fenomena langka dengan kemungkinan pengisian ulang (menggunakan keputusan pemenang). Kumpulan korps beberapa kali lebih besar dari volume korps yang ada saat ini (apalagi, untuk gapping, volume corpus adalah urutan besarnya lebih besar dari volume korps tidak hanya untuk Rusia, tetapi untuk semua bahasa pada umumnya). Semua data dan tautan ke keputusan peserta dapat ditemukan di github kami.
Pada 30 Mei, pada sesi khusus
Dialog yang didedikasikan untuk analisis otomatis kompetisi gapping, hasil AGRR-2019 akan diringkas. Kami akan berbicara tentang organisasi kompetisi dan memikirkan konten dari bangunan yang dibuat, dan para peserta akan mempresentasikan arsitektur yang dipilih yang dengannya mereka memecahkan masalah.
Kelompok Penelitian Lanjutan NLP