Kursus lengkap dalam bahasa Rusia dapat ditemukan di
tautan ini .
Kursus bahasa Inggris asli tersedia di
tautan ini .
 Kuliah baru dijadwalkan setiap 2-3 hari.
Kuliah baru dijadwalkan setiap 2-3 hari.Wawancara dengan Sebastian Trun, CEO Udacity
"Jadi, kami masih bersamamu dan bersama kami, seperti sebelumnya, Sebastian." Kami hanya ingin membahas lapisan yang sepenuhnya terhubung, lapisan padat yang sama. Sebelum itu, saya ingin mengajukan satu pertanyaan. Apa saja batasan dan hambatan utama yang akan menghalangi pembelajaran mendalam dan akan memiliki dampak terbesar dalam 10 tahun ke depan? Semuanya berubah begitu cepat! Menurut Anda apa yang akan menjadi "hal besar" berikutnya?
- Saya akan mengatakan dua hal. Yang pertama adalah AI umum untuk lebih dari satu tugas. Ini bagus! Orang dapat memecahkan lebih dari satu masalah dan jangan pernah melakukan hal yang sama. Yang kedua adalah membawa teknologi ke pasar. Bagi saya, kekhasan pembelajaran mesin adalah bahwa hal itu memberi komputer kemampuan untuk mengamati dan menemukan pola dalam data, membantu orang menjadi lebih baik di bidang - di tingkat ahli! Pembelajaran mesin dapat digunakan dalam bidang hukum, kedokteran, mobil otonom. Kembangkan aplikasi semacam itu karena dapat menghasilkan banyak uang, tetapi yang terpenting, Anda memiliki kesempatan untuk menjadikan dunia tempat yang lebih baik.
“Saya sangat suka cara Anda mengatakan semuanya menjadi satu gambar pembelajaran mendalam dan penerapannya - ini hanyalah alat yang dapat membantu Anda memecahkan masalah tertentu.
- Ya persis! Alat yang luar biasa, bukan?
- Ya, ya, saya sepenuhnya setuju dengan Anda!
"Hampir seperti otak manusia!"
- Anda menyebutkan aplikasi medis dalam wawancara pertama kami, di bagian pertama dari kursus video. Di aplikasi mana, menurut pendapat Anda, penggunaan pembelajaran mendalam menyebabkan kegembiraan dan kejutan terbesar?
- Banyak! Sangat! Kedokteran ada dalam daftar singkat bidang-bidang yang secara aktif menggunakan pembelajaran mendalam. Saya kehilangan saudara perempuan saya beberapa bulan yang lalu, dia menderita kanker, yang sangat menyedihkan. Saya pikir ada banyak penyakit yang dapat dideteksi sebelumnya - pada tahap awal, memungkinkan untuk menyembuhkannya atau memperlambat proses perkembangannya. Idenya, pada kenyataannya, adalah untuk mentransfer beberapa alat ke rumah (rumah pintar), sehingga dimungkinkan untuk mendeteksi penyimpangan seperti itu dalam kesehatan jauh sebelum saat ketika orang itu sendiri melihatnya. Saya juga akan menambahkan - semuanya diulangi, pekerjaan kantor apa pun, di mana Anda melakukan jenis tindakan yang sama berulang kali, misalnya, pembukuan. Bahkan saya, sebagai CEO, melakukan banyak tindakan berulang. Akan sangat bagus untuk mengotomatisasi mereka, bahkan bekerja dengan korespondensi surat!
- Saya tidak bisa tidak setuju dengan Anda! Dalam pelajaran ini, kami akan memperkenalkan siswa ke kursus dengan lapisan jaringan saraf yang disebut lapisan padat. Bisakah Anda memberi tahu kami secara lebih terperinci apa pendapat Anda tentang lapisan yang terhubung sepenuhnya?
- Jadi, mari kita mulai dengan fakta bahwa setiap jaringan dapat dihubungkan dengan cara yang berbeda. Beberapa dari mereka mungkin memiliki konektivitas yang sangat ketat, yang memungkinkan Anda untuk mendapatkan manfaat dalam penskalaan dan "menang" melawan jaringan besar. Terkadang Anda tidak tahu berapa banyak koneksi yang Anda butuhkan, jadi Anda menghubungkan semuanya dengan semuanya - ini disebut lapisan yang terhubung penuh. Saya menambahkan bahwa pendekatan ini memiliki lebih banyak kekuatan dan potensi daripada sesuatu yang lebih terstruktur.
- Saya sepenuhnya setuju dengan Anda! Terima kasih telah membantu kami mempelajari lebih banyak tentang lapisan yang terhubung sepenuhnya. Saya menantikan saat ketika kita akhirnya mulai mengimplementasikannya dan menulis kode.
- Selamat bersenang-senang! Ini akan sangat menyenangkan!
Pendahuluan
- Selamat datang kembali! Dalam pelajaran terakhir, Anda menemukan cara membangun jaringan saraf pertama Anda menggunakan TensorFlow dan Keras, cara kerja jaringan saraf, dan bagaimana proses pelatihan (pelatihan) bekerja. Secara khusus, kami melihat bagaimana melatih model untuk mengubah derajat Celsius ke derajat Fahrenheit.

- Kami juga berkenalan dengan konsep lapisan yang terhubung penuh (lapisan padat), lapisan paling penting dalam jaringan saraf. Tetapi dalam pelajaran ini kita akan melakukan banyak hal yang lebih keren! Dalam pelajaran ini, kita akan mengembangkan jaringan saraf yang dapat mengenali elemen pakaian dan gambar. Seperti yang kami sebutkan sebelumnya, pembelajaran mesin menggunakan input yang disebut "fitur," dan output yang disebut "label," dimana model belajar dan menemukan algoritma transformasi. Karena itu, pertama, kita perlu banyak contoh untuk melatih jaringan saraf untuk mengenali berbagai elemen pakaian. Biarkan saya mengingatkan Anda bahwa contoh untuk pelatihan adalah sepasang nilai - fitur input dan label output, yang diumpankan ke input jaringan saraf. Dalam contoh baru kami, input akan berupa gambar, dan label keluaran harus menjadi kategori pakaian yang menjadi milik item pakaian yang ditunjukkan dalam gambar. Untungnya, set data seperti itu sudah ada. Ini disebut Fashion MNIST. Kami akan melihat lebih dekat kumpulan data ini di bagian selanjutnya.
Mode MNIST Dataset
Selamat datang di dunia dataset MNIST! Jadi, set kami terdiri dari 28x28 gambar, masing-masing piksel mewakili warna abu-abu.

Kumpulan data berisi gambar kaus, atasan, sandal, dan bahkan sepatu bot. Berikut adalah daftar lengkap dari apa yang mengandung dataset MNIST kami:
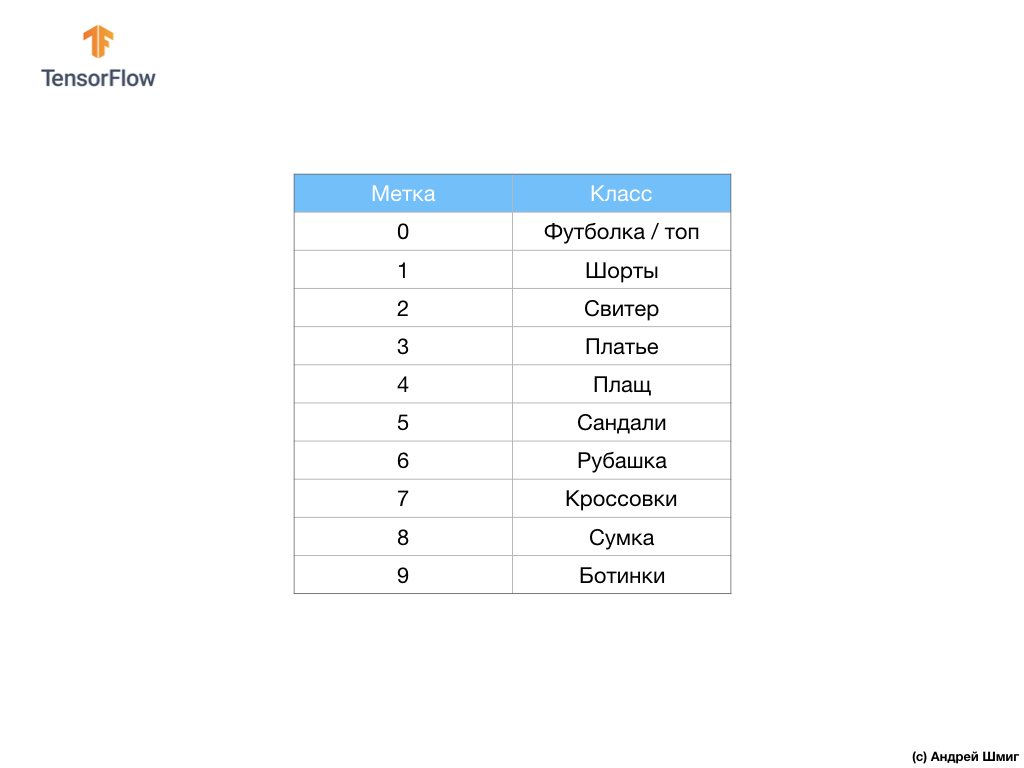
Setiap gambar input sesuai dengan salah satu label di atas. Dataset Mode MNIST berisi 70.000 gambar, jadi kami memiliki tempat untuk memulai dan bekerja. Dari 70.000 ini, kita akan menggunakan 60.000 untuk melatih jaringan saraf.
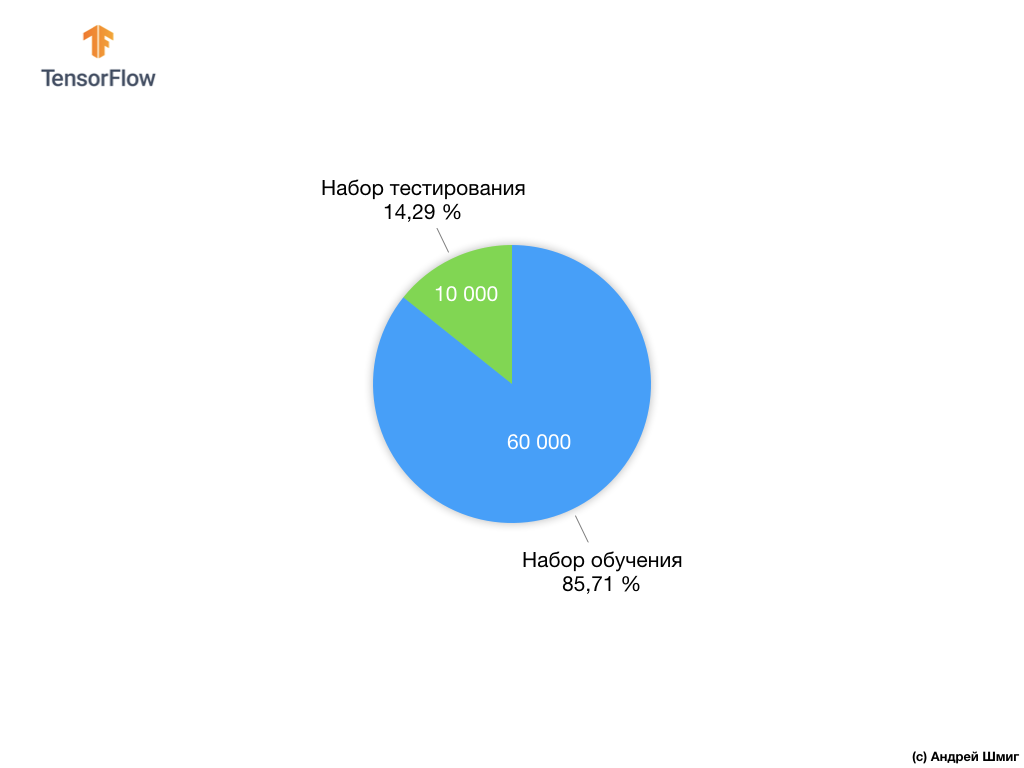
Dan kita akan menggunakan 10.000 elemen yang tersisa untuk menguji seberapa baik jaringan saraf kita telah belajar mengenali elemen pakaian. Nanti kami akan menjelaskan mengapa kami membagi set data menjadi set pelatihan dan satu set tes.
Jadi di sini adalah dataset Fashion MNIST kami.
Ingat, setiap gambar dalam dataset adalah gambar berukuran 28x28 dalam nuansa abu-abu, yang berarti bahwa setiap gambar berukuran 784 byte. Tugas kita adalah membuat jaringan saraf, yang menerima 784 byte ini pada input, dan pada output kembali ke kategori pakaian dari 10 yang tersedia, elemen yang diserahkan pada input tersebut adalah milik.
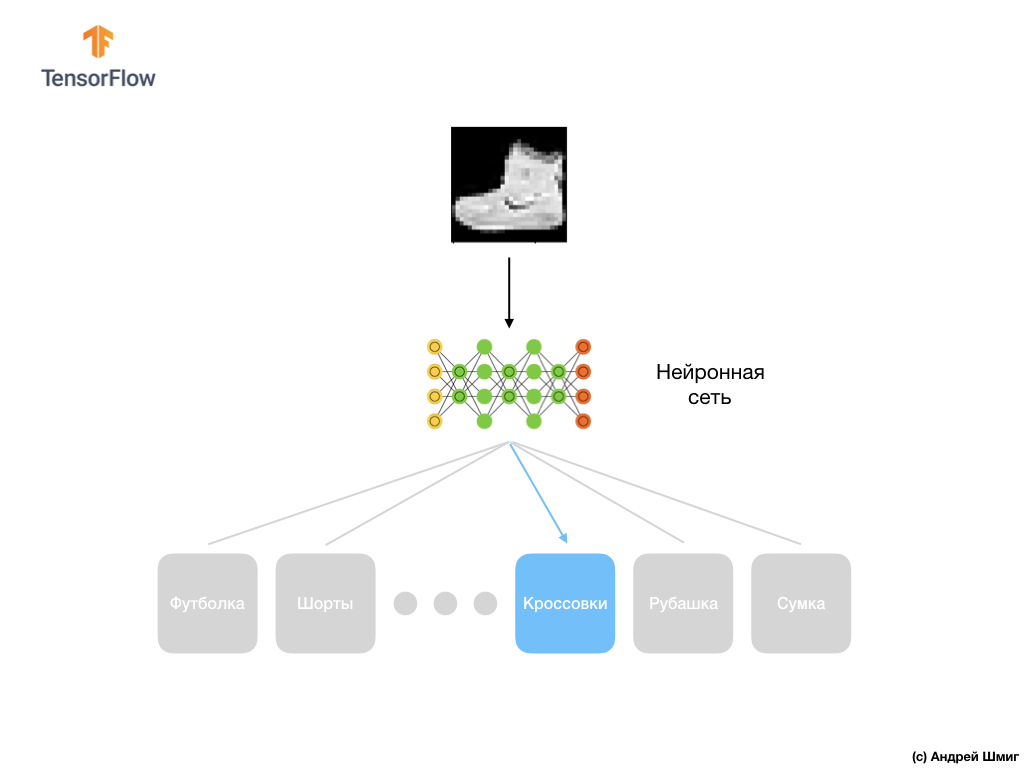
Jaringan saraf
Dalam pelajaran ini, kita akan menggunakan jaringan saraf yang dalam yang belajar untuk mengklasifikasikan gambar dari dataset Fashion MNIST.
Gambar di atas menunjukkan seperti apa jaringan saraf kita nantinya. Mari kita lihat lebih detail.
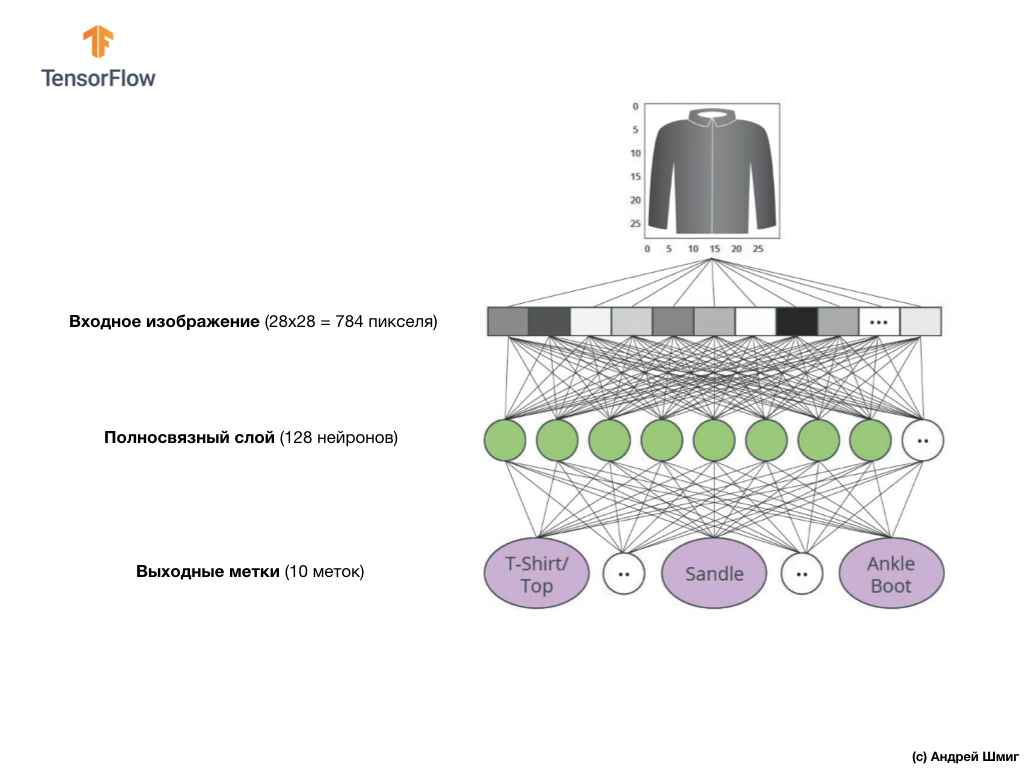
Nilai input dari jaringan saraf kami adalah array satu dimensi dengan panjang 784, array dengan panjang yang persis sama dengan alasan bahwa setiap gambar adalah 28x28 piksel (= total 784 piksel dalam gambar), yang akan dikonversi menjadi array satu dimensi. Proses mengubah gambar 2D menjadi vektor disebut perataan dan diimplementasikan melalui lapisan perataan - lapisan rata.
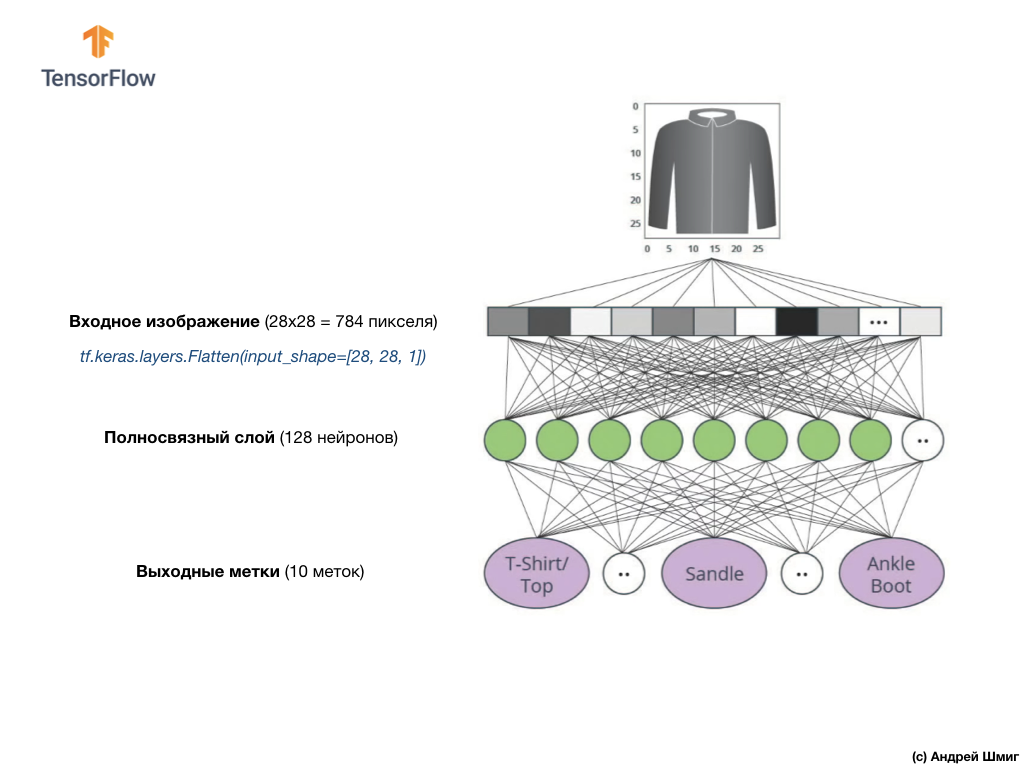
Anda dapat melakukan smoothing dengan membuat layer yang sesuai:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Lapisan ini mengubah gambar 2D 28x28 piksel (1 byte untuk skala abu-abu per piksel) menjadi array 1D 784 piksel.
Nilai input akan sepenuhnya terkait dengan lapisan jaringan
dense pertama kami, yang ukurannya kami pilih sama dengan 128 neuron.
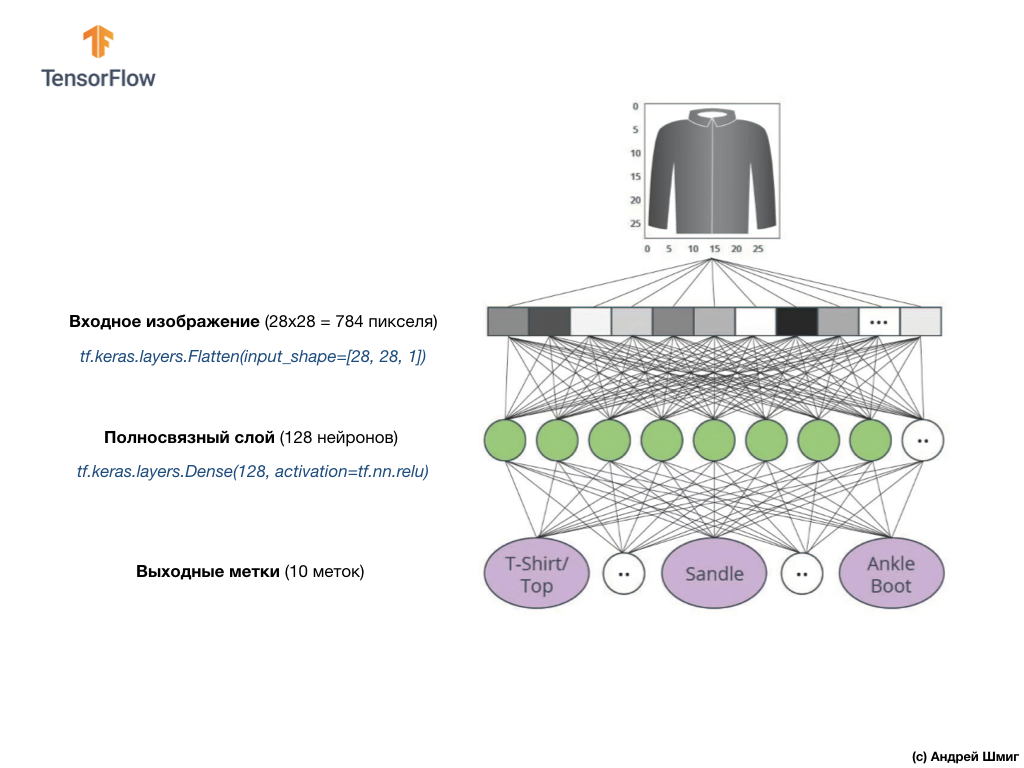
Beginilah ciptaan layer ini di dalam kode tersebut:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Hentikan itu! Apa itu
tf.nn.relu ? Kami tidak menggunakan ini dalam contoh jaringan saraf kami sebelumnya ketika mengkonversi derajat Celcius ke derajat Fahrenheit! Intinya adalah bahwa tugas saat ini jauh lebih rumit daripada yang digunakan sebagai contoh pencarian fakta - mengubah derajat Celsius ke derajat Fahrenheit.
ReLU adalah fungsi matematika yang kami tambahkan ke lapisan kami yang sepenuhnya terhubung dan yang memberi lebih banyak kekuatan ke jaringan kami. Sebenarnya, ini adalah ekstensi kecil untuk lapisan kami yang sepenuhnya terhubung, yang memungkinkan jaringan saraf kami untuk memecahkan masalah yang lebih kompleks. Kami tidak akan memerinci, tetapi sedikit informasi yang lebih terperinci dapat ditemukan di bawah.
Akhirnya, lapisan terakhir kami, juga dikenal sebagai lapisan keluaran, terdiri dari 10 neuron. Ini terdiri dari 10 neuron karena dataset Fashion MNIST kami berisi 10 kategori pakaian. Masing-masing dari 10 nilai output ini akan mewakili kemungkinan bahwa gambar input berada dalam kategori pakaian ini. Dengan kata lain, nilai-nilai ini mencerminkan "kepercayaan diri" model dalam kebenaran prediksi dan korelasi gambar yang diajukan dengan spesifik dari 10 kategori pakaian di output. Misalnya, apa kemungkinan gambar itu menunjukkan gaun, sepatu kets, sepatu, dll.
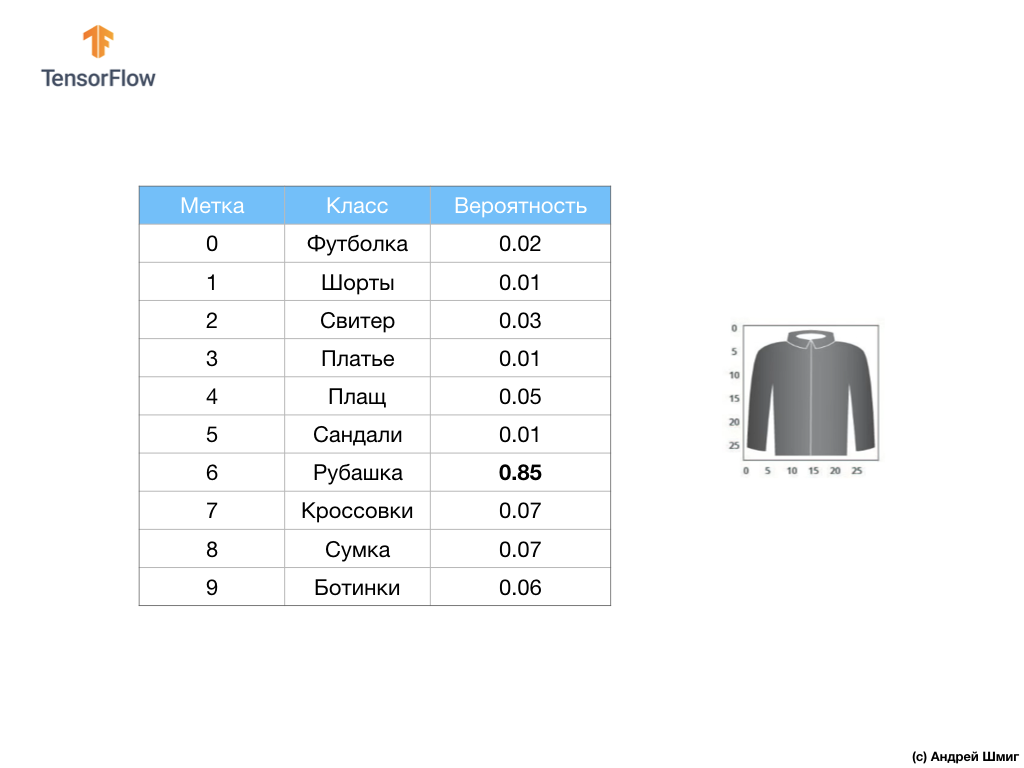
Misalnya, jika gambar baju diumpankan ke input jaringan saraf kami, maka model dapat memberi kami hasil seperti yang Anda lihat pada gambar di atas - probabilitas gambar input cocok dengan label output.
Jika Anda memperhatikan, Anda akan melihat bahwa probabilitas terbesar - 0,85 mengacu pada tag 6, yang sesuai dengan kemeja. Model 85% yakin bahwa gambar di baju. Biasanya, hal-hal yang terlihat seperti kemeja juga akan memiliki peringkat probabilitas tinggi, dan hal-hal yang paling mirip akan memiliki peringkat probabilitas yang lebih rendah.
Karena semua 10 nilai output sesuai dengan probabilitas, ketika menjumlahkan semua nilai ini, kami mendapatkan 1. 10 nilai ini juga disebut distribusi probabilitas.
Sekarang kita membutuhkan lapisan output untuk menghitung probabilitas untuk setiap label.

Dan kami akan melakukan ini dengan perintah berikut:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
Bahkan, setiap kali kita membuat jaringan saraf yang memecahkan masalah klasifikasi, kita selalu menggunakan lapisan yang terhubung penuh sebagai lapisan terakhir dari jaringan saraf. Lapisan terakhir dari jaringan saraf harus berisi jumlah neuron yang sama dengan jumlah kelas, di mana kita menentukan
softmax dan menggunakan fungsi aktivasi softmax.
ReLU - fungsi aktivasi neuron
Dalam pelajaran ini, kita berbicara tentang
ReLU sebagai sesuatu yang memperluas kemampuan jaringan saraf kita dan memberinya kekuatan tambahan.
ReLU adalah fungsi matematika yang terlihat seperti ini:
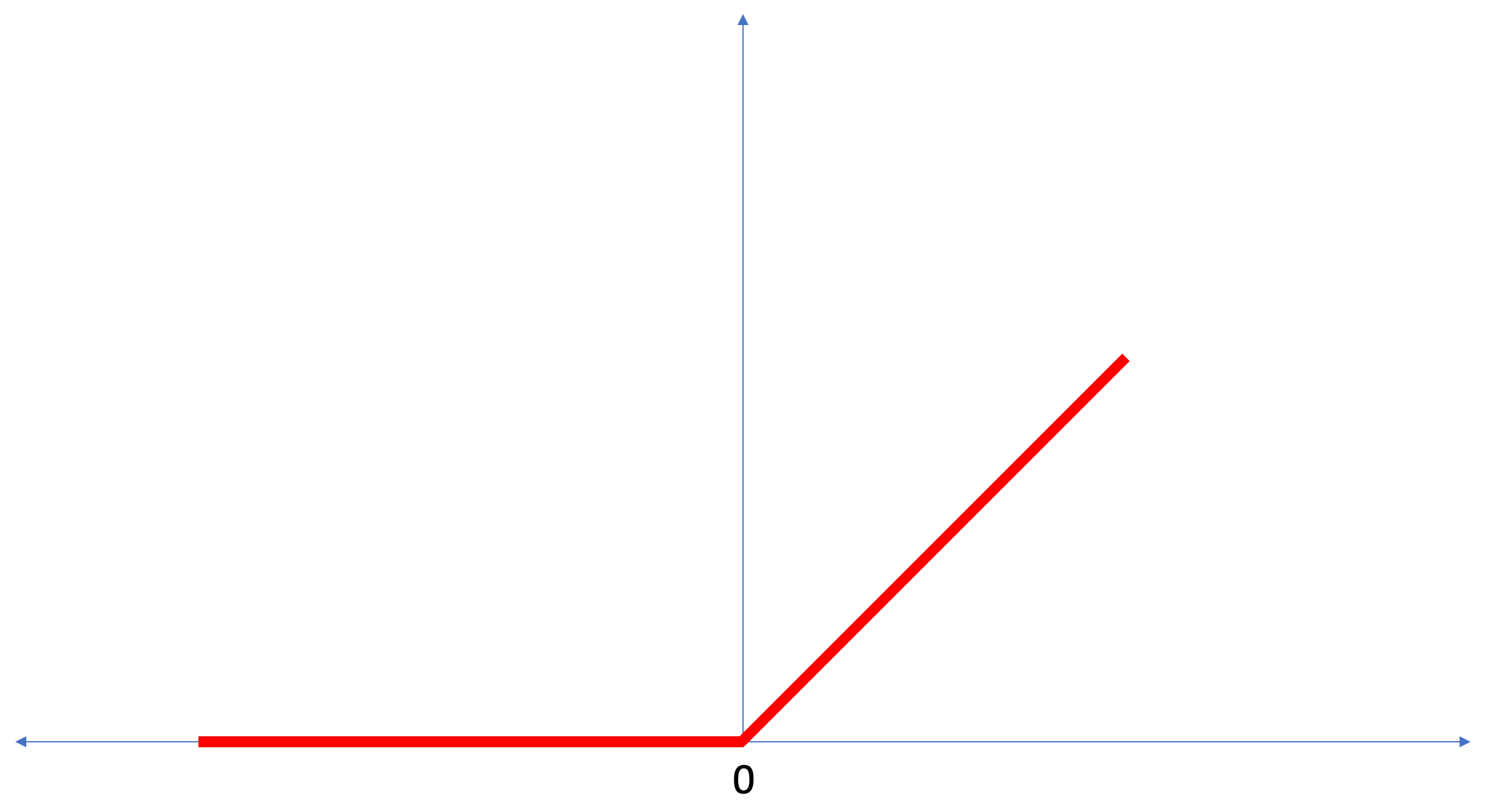
Fungsi
ReLU mengembalikan 0 jika nilai input adalah nilai negatif atau nol, dalam semua kasus lain fungsi akan mengembalikan nilai input asli.
ReLU memungkinkan untuk menyelesaikan masalah non-linear.
Mengubah derajat Celsius ke derajat Fahrenheit adalah tugas linier, karena ekspresi
f = 1.8*c + 32 adalah persamaan garis -
y = m*x + b . Tetapi sebagian besar tugas yang ingin kita selesaikan adalah non-linear. Dalam kasus seperti itu, menambahkan fungsi aktivasi ReLU ke lapisan kami yang terhubung sepenuhnya dapat membantu dengan tugas semacam ini.
ReLU hanyalah satu jenis fungsi aktivasi. Ada beberapa fungsi aktivasi seperti sigmoid, ReLU, ELU, tanh, namun
ReLU yang paling sering digunakan sebagai fungsi aktivasi default. Untuk membuat dan menggunakan model yang menyertakan ReLU, Anda tidak perlu memahami cara kerjanya secara internal. Jika Anda masih ingin mengerti lebih baik, maka kami merekomendasikan
artikel ini .
Mari kita bahas istilah-istilah baru yang diperkenalkan dalam pelajaran ini:
- Smoothing - proses mengubah gambar 2D menjadi vektor 1D;
- ReLU adalah fungsi aktivasi yang memungkinkan model untuk menyelesaikan masalah non-linear;
- Softmax - fungsi yang menghitung probabilitas untuk setiap kelas output yang mungkin;
- Klasifikasi - kelas tugas pembelajaran mesin yang digunakan untuk menentukan perbedaan antara dua atau lebih kategori (kelas).
Pelatihan dan pengujian
Saat melatih suatu model, model apa pun dalam pembelajaran mesin, selalu perlu untuk membagi set data menjadi setidaknya dua set yang berbeda - set data yang digunakan untuk pelatihan dan set data yang digunakan untuk pengujian. Pada bagian ini kita akan mengerti mengapa perlu melakukan ini.
Mari kita ingat bagaimana kita mendistribusikan set data kami dari Fashion MNIST yang terdiri dari 70.000 salinan.
Kami mengusulkan membagi 70.000 menjadi dua bagian - di bagian pertama, meninggalkan 60.000 untuk pelatihan, dan di bagian kedua 10.000 untuk pengujian. Perlunya pendekatan ini disebabkan oleh fakta berikut: setelah model dilatih pada 60.000 salinan, perlu untuk memeriksa hasil dan efektivitas kerjanya pada contoh-contoh yang belum dalam set data di mana model dilatih.
Dengan caranya sendiri, itu menyerupai lulus ujian di sekolah. Sebelum Anda lulus ujian, Anda rajin menyelesaikan masalah kelas tertentu. Kemudian, dalam ujian, Anda menemukan kelas masalah yang sama, tetapi dengan data input yang berbeda. Tidak masuk akal untuk mengirimkan data yang sama dengan yang ada selama pelatihan, jika tidak tugas akan dikurangi menjadi mengingat keputusan, dan tidak mencari model solusi. Itulah sebabnya pada ujian Anda dihadapkan dengan tugas-tugas yang sebelumnya tidak ada dalam kurikulum. Hanya dengan cara ini kami dapat memverifikasi apakah model telah mempelajari solusi umum atau tidak.
Hal yang sama terjadi dengan pembelajaran mesin. Anda memperlihatkan beberapa data yang mewakili kelas tugas tertentu yang ingin Anda pelajari bagaimana menyelesaikannya. Dalam kasus kami, dengan kumpulan data dari Fashion MNIST, kami ingin jaringan saraf dapat menentukan kategori di mana elemen pakaian dalam gambar berada. Itulah sebabnya kami melatih model kami pada 60.000 contoh yang berisi semua kategori item pakaian. Setelah pelatihan, kami ingin memeriksa keefektifan model, jadi kami memberi makan 10.000 item pakaian lainnya yang modelnya belum “lihat”. Jika kami memutuskan untuk tidak melakukan ini, tidak menguji dengan 10.000 contoh, kami tidak akan dapat mengatakan dengan pasti apakah model kami benar-benar dilatih untuk menentukan kelas item pakaian atau jika dia mengingat semua pasangan nilai input + output.
Itu sebabnya dalam pembelajaran mesin kami selalu memiliki dataset untuk pelatihan dan dataset untuk pengujian.
TensorFlow adalah kumpulan data pelatihan yang siap digunakan.
Kumpulan data biasanya dibagi menjadi beberapa blok, yang masing-masing digunakan pada tahap pelatihan tertentu dan menguji efektivitas jaringan saraf. Pada bagian ini kita berbicara tentang:
- set data pelatihan : set data yang dimaksudkan untuk melatih jaringan saraf;
- set data uji : set data yang dirancang untuk memverifikasi efisiensi jaringan saraf;
Pertimbangkan dataset lain, yang saya sebut dataset validasi. Kumpulan data ini tidak digunakan
untuk melatih model, hanya
selama pelatihan. Jadi, setelah model kami melewati beberapa siklus pelatihan, kami mengumpankannya set data pengujian kami dan melihat hasilnya. Sebagai contoh, jika selama pelatihan nilai fungsi kerugian menurun, dan akurasi menurun pada set data uji, maka ini berarti bahwa model kami cukup mengingat pasangan nilai input-output.
Set data verifikasi digunakan kembali pada akhir pelatihan untuk mengukur akurasi akhir prediksi model.
Untuk
informasi lebih
lanjut tentang set data pelatihan dan tes, lihat Google Crash Course .
Bagian praktis dalam CoLab
Tautan ke CoLab asli dalam bahasa Inggris dan
tautan ke CoLab Rusia .
Klasifikasi gambar barang-barang pakaian
Dalam bagian pelajaran ini, kami akan membangun dan melatih jaringan saraf untuk mengklasifikasikan gambar elemen pakaian, seperti gaun, sepatu kets, kemeja, t-shirt, dll.
Tidak apa-apa jika beberapa saat tidak jelas. Tujuan dari kursus ini adalah untuk memperkenalkan Anda kepada TensorFlow dan pada saat yang sama menjelaskan algoritme kerjanya dan mengembangkan pemahaman umum tentang proyek yang menggunakan TensorFlow, alih-alih menggali detail implementasi.
Di bagian ini, kami menggunakan
tf.keras , API tingkat tinggi untuk membangun dan melatih model di TensorFlow.
Menginstal dan mengimpor dependensi
Kita akan membutuhkan
dataset TensorFlow , sebuah API yang menyederhanakan pemuatan dan mengakses dataset yang disediakan oleh beberapa layanan. Kita juga membutuhkan beberapa perpustakaan bantu.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
Impor dataset Mode MNIST
Contoh ini menggunakan dataset Fashion MNIST, yang berisi 70.000 gambar item pakaian dalam 10 kategori dalam skala abu-abu. Gambar berisi item pakaian dalam resolusi rendah (28x28 piksel), seperti yang ditunjukkan di bawah ini:

Fashion MNIST digunakan sebagai pengganti dataset MNIST klasik - paling sering digunakan sebagai "Halo, Dunia!" dalam pembelajaran mesin dan visi komputer. Dataset MNIST berisi gambar angka tulisan tangan (0, 1, 2, dll.) Dalam format yang sama dengan item pakaian dalam contoh kita.
Dalam contoh kami, kami menggunakan Fashion MNIST karena variasi dan karena tugas ini lebih menarik dari sudut pandang implementasi daripada memecahkan masalah khas pada set data MNIST. Kedua set data cukup kecil, oleh karena itu, mereka digunakan untuk memeriksa operabilitas algoritma yang benar. Kumpulan data hebat untuk memulai mesin pembelajaran, pengujian, dan kode debugging.
Kami akan menggunakan 60.000 gambar untuk melatih jaringan dan 10.000 gambar untuk menguji akurasi pelatihan dan klasifikasi gambar. Anda dapat langsung mengakses dataset Fashion MNIST melalui TensorFlow menggunakan API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
Dengan memuat set data, kami mendapatkan metadata, set data pelatihan, dan set data uji.
- Model dilatih pada dataset dari `train_dataset`
- Model ini diuji pada dataset dari `test_dataset`
Gambar adalah array
2828 dua dimensi, di mana nilai-nilai di setiap sel dapat dalam interval
[0, 255] . Label - array bilangan bulat, di mana setiap nilai berada dalam interval
[0, 9] . Label-label ini sesuai dengan kelas gambar output sebagai berikut:
Setiap gambar milik satu tag. Karena nama-nama kelas tidak terkandung dalam kumpulan data asli, mari kita simpan untuk digunakan di masa mendatang ketika kita menggambar gambar:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
Kami meneliti data
Mari kita pelajari format dan struktur data yang disajikan dalam set pelatihan sebelum melatih model. Kode berikut akan menunjukkan bahwa 60.000 gambar ada dalam dataset pelatihan, dan 10.000 gambar ada dalam dataset uji:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
Pra-pemrosesan data
Nilai setiap piksel dalam gambar adalah dalam kisaran
[0,255] . Agar model bekerja dengan benar, nilai-nilai ini harus dinormalisasi - dikurangi menjadi nilai dalam interval
[0,1] . Oleh karena itu, sedikit lebih rendah, kami mendeklarasikan dan mengimplementasikan fungsi normalisasi, dan kemudian menerapkannya pada setiap gambar dalam set data pelatihan dan pengujian.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
Kami mempelajari data yang diproses
Mari kita gambar untuk melihatnya:
Kami menampilkan 25 gambar pertama dari kumpulan data pelatihan dan di bawah setiap gambar kami menunjukkan kelasnya.
Pastikan bahwa data dalam format yang benar dan kami siap untuk mulai membuat dan melatih jaringan.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

Membangun model
Membangun jaringan saraf memerlukan lapisan tuning, dan kemudian merakit model dengan fungsi optimasi dan kehilangan.
Kustomisasi layer
Elemen dasar dalam membangun jaringan saraf adalah lapisan. Lapisan mengekstraksi tampilan dari data yang masuk ke inputnya. Hasil dari pekerjaan beberapa lapisan terhubung, kami mendapatkan pandangan yang masuk akal untuk menyelesaikan masalah.
Sebagian besar waktu melakukan pembelajaran mendalam, Anda akan membuat tautan antara lapisan sederhana. Sebagian besar layer, misalnya, seperti tf.keras.layers.Dense, memiliki serangkaian parameter yang dapat "dipasang" selama proses pembelajaran.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
Jaringan terdiri dari tiga lapisan:
- input
tf.keras.layers.Flatten - layer ini mengubah gambar berukuran 28x28 piksel menjadi 1D-array dengan ukuran 784 (28 * 28). Pada layer ini, kami tidak memiliki parameter untuk pelatihan, karena layer ini hanya berurusan dengan konversi data input. - hidden layer
tf.keras.layers.Dense - lapisan 128 neuron yang terhubung erat. Setiap neuron (simpul) mengambil semua 784 nilai dari lapisan sebelumnya sebagai input, mengubah nilai input sesuai dengan bobot dan perpindahan internal selama pelatihan, dan mengembalikan nilai tunggal ke lapisan berikutnya. - output layer
ts.keras.layers.Dense - softmax terdiri dari 10 neuron, yang masing-masing mewakili kelas elemen pakaian tertentu. Seperti pada lapisan sebelumnya, setiap neuron menerima nilai input dari semua 128 neuron dari lapisan sebelumnya. Berat dan perpindahan masing-masing neuron pada lapisan ini berubah selama pelatihan sehingga nilai yang dihasilkan berada dalam interval [0,1] dan mewakili probabilitas bahwa gambar tersebut termasuk dalam kelas ini. Jumlah semua nilai output dari 10 neuron adalah 1.
Kompilasi model
Sebelum kita mulai melatih model, ada baiknya beberapa pengaturan lagi. Pengaturan ini dibuat selama perakitan model ketika metode kompilasi dipanggil:
- loss function - sebuah algoritma untuk mengukur seberapa jauh nilai yang diinginkan dari prediksi.
- fungsi optimisasi - suatu algoritma untuk "menyesuaikan" parameter internal (bobot dan offset) model untuk meminimalkan fungsi kerugian;
- metrik - digunakan untuk memantau proses pelatihan dan pengujian. Contoh di bawah ini menggunakan metrik seperti
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Kami melatih model
Pertama, kami menentukan urutan tindakan selama pelatihan pada set data pelatihan:
- Ulangi set data input dalam jumlah tak terbatas kali menggunakan metode
dataset.repeat() (parameter epochs , yang dijelaskan di bawah ini, menentukan jumlah semua iterasi pelatihan yang akan dilakukan) - Metode
dataset.shuffle(60000) semua gambar sehingga pelatihan model kami tidak terpengaruh oleh urutan input data input. - Metode
dataset.batch(32) memberi model.fit pelatihan model.fit menggunakan blok 32 gambar dan label model.fit kali variabel internal model diperbarui.
Pelatihan berlangsung dengan memanggil metode
model.fit :
- Mengirim
train_dataset ke input model. - Model belajar untuk mencocokkan gambar input dengan label.
- Parameter
epochs=5 membatasi jumlah sesi pelatihan hingga 5 iterasi pelatihan lengkap pada set data, yang pada akhirnya memberi kita pelatihan tentang 5 * 60.000 = 300.000 contoh.
(Anda dapat mengabaikan parameter
steps_per_epoch , segera parameter ini akan dikeluarkan dari metode).
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
Dan inilah kesimpulannya:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Selama pelatihan model, nilai fungsi kerugian dan metrik akurasi ditampilkan untuk setiap iterasi pelatihan. Model ini mencapai akurasi sekitar 0,88 (88%) pada data pelatihan.
Periksa akurasi
Mari kita periksa akurasi model apa yang dihasilkan pada data uji. Kami akan menggunakan semua contoh yang kami miliki di set data uji untuk memeriksa akurasi.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
Kesimpulan:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
Seperti yang Anda lihat, akurasi pada set data uji ternyata kurang dari akurasi pada set data pelatihan. Ini cukup normal karena model dilatih pada data train_dataset. Ketika model menemukan gambar yang belum pernah dilihat sebelumnya (dari dataset train_dataset), jelas bahwa efisiensi klasifikasi akan menurun.
Prediksikan dan jelajahi
Kita dapat menggunakan model yang terlatih untuk mendapatkan prediksi untuk beberapa gambar.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
Kesimpulan: Pada contoh di atas, model memperkirakan label untuk setiap gambar input uji. Mari kita lihat prediksi pertama:(32, 10)
predictions[0]
Kesimpulan: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
Ingat bahwa prediksi model adalah larik 10 nilai. Nilai-nilai ini menggambarkan "kepercayaan diri" model bahwa gambar input milik kelas tertentu (item pakaian). Kita dapat melihat nilai maksimum sebagai berikut: np.argmax(predictions[0])
Kesimpulan: 6
Ini berarti bahwa model itu paling yakin bahwa gambar ini milik kelas berlabel 6 (class_names [6]). Kami dapat memeriksa dan memastikan bahwa hasilnya benar dan benar: test_labels[0]
6
Kami dapat menampilkan semua gambar input dan prediksi model yang sesuai untuk 10 kelas: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
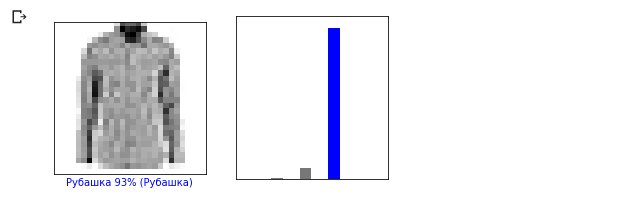
Mari kita lihat gambar ke-0, hasil prediksi model dan susunan prediksi. i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
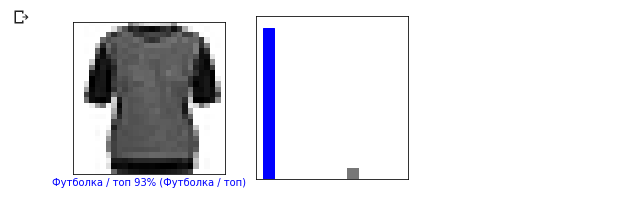 Sekarang mari kita menampilkan beberapa gambar dengan prediksi masing-masing. Prediksi yang benar berwarna biru, prediksi yang salah berwarna merah. Nilai di bawah gambar mencerminkan persentase kepercayaan bahwa gambar input sesuai dengan kelas ini. Harap dicatat bahwa hasilnya mungkin salah bahkan jika nilai "kepercayaan" tinggi.
Sekarang mari kita menampilkan beberapa gambar dengan prediksi masing-masing. Prediksi yang benar berwarna biru, prediksi yang salah berwarna merah. Nilai di bawah gambar mencerminkan persentase kepercayaan bahwa gambar input sesuai dengan kelas ini. Harap dicatat bahwa hasilnya mungkin salah bahkan jika nilai "kepercayaan" tinggi. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 Gunakan model yang terlatih untuk memprediksi label untuk satu gambar:
Gunakan model yang terlatih untuk memprediksi label untuk satu gambar: img = test_images[0] print(img.shape)
Kesimpulan: (28, 28, 1)
Model dalam tf.kerasdioptimalkan untuk prediksi dengan blok (koleksi). Karenanya, terlepas dari kenyataan bahwa kami menggunakan elemen tunggal, Anda perlu menambahkannya ke daftar: img = np.array([img]) print(img.shape)
Kesimpulan:(1, 28, 28, 1)Sekarang kita akan memprediksi hasilnya: predictions_single = model.predict(img) print(predictions_single)
Kesimpulan: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
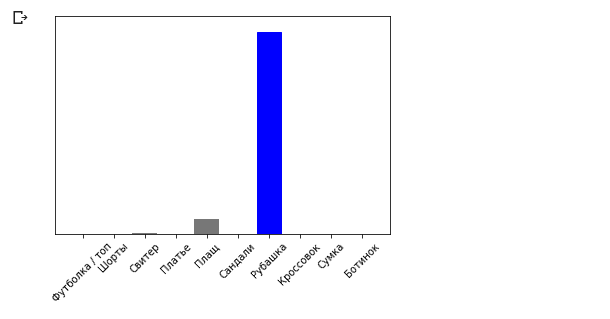 Metode model.predict mengembalikan daftar daftar (array array), masing-masing untuk gambar dari blok input. Kami mendapatkan satu-satunya hasil untuk gambar input tunggal kami:
Metode model.predict mengembalikan daftar daftar (array array), masing-masing untuk gambar dari blok input. Kami mendapatkan satu-satunya hasil untuk gambar input tunggal kami: np.argmax(predictions_single[0])
Kesimpulan: 6
Seperti sebelumnya, model ini memprediksi label 6 (kemeja).Latihan
Lakukan percobaan dengan berbagai model dan lihat bagaimana akurasi akan berubah. Secara khusus, coba ubah pengaturan berikut:- atur parameter zaman ke 1;
- ubah jumlah neuron di lapisan tersembunyi, misalnya, dari nilai rendah 10 menjadi 512 dan lihat bagaimana keakuratan model prakiraan akan berubah;
- tambahkan lapisan tambahan antara lapisan rata (lapisan penghalusan) dan lapisan akhir padat, bereksperimenlah dengan jumlah neuron pada lapisan ini;
- jangan menormalkan nilai piksel dan lihat apa yang terjadi.
Ingatlah untuk mengaktifkan GPU sehingga semua perhitungan lebih cepat ( Runtime -> Change runtime type -> Hardware accelertor -> GPU). Juga, jika Anda mengalami masalah selama operasi, cobalah mengatur ulang pengaturan lingkungan global:Edit -> Clear all outputsRuntime -> Reset all runtimes
Derajat Celcius VS MNIST
- Pada tahap ini, kita telah menemukan dua jenis jaringan saraf. Jaringan saraf pertama kami mempelajari cara mengonversi derajat Celsius ke derajat Frenheit, mengembalikan nilai tunggal yang dapat berada dalam rentang nilai numerik yang luas.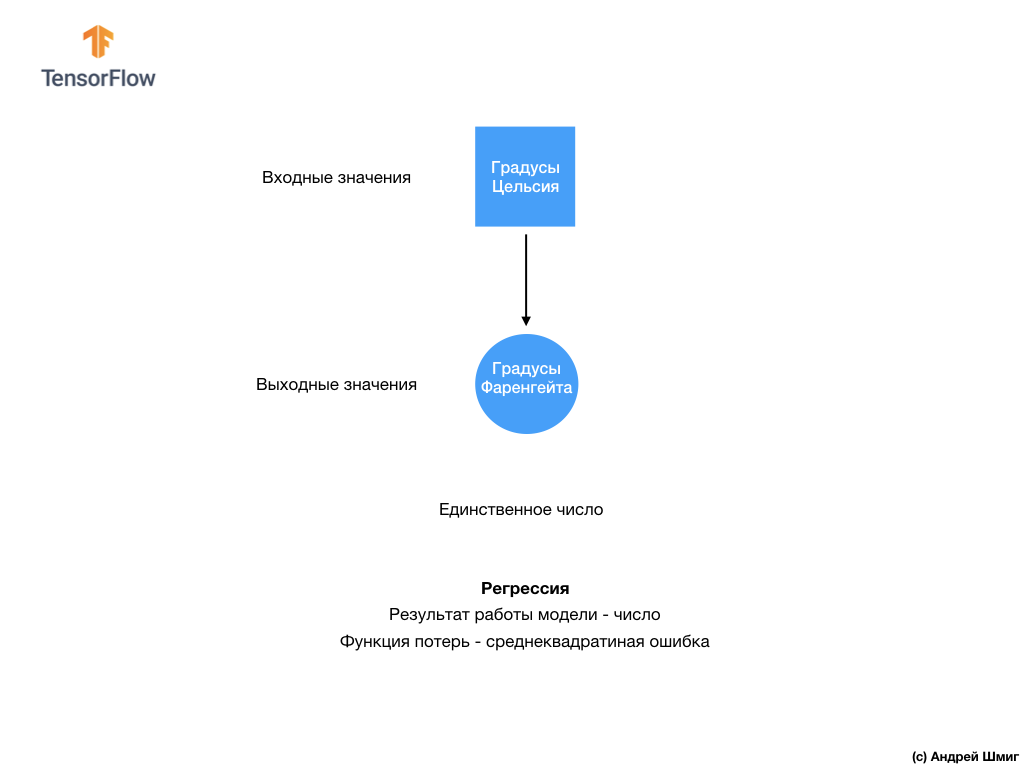 Jaringan syaraf kedua kami mengembalikan 10 nilai probabilitas yang mencerminkan kepercayaan jaringan bahwa gambar input sesuai dengan kelas tertentu.Jaringan saraf dapat digunakan untuk menyelesaikan berbagai masalah.
Jaringan syaraf kedua kami mengembalikan 10 nilai probabilitas yang mencerminkan kepercayaan jaringan bahwa gambar input sesuai dengan kelas tertentu.Jaringan saraf dapat digunakan untuk menyelesaikan berbagai masalah.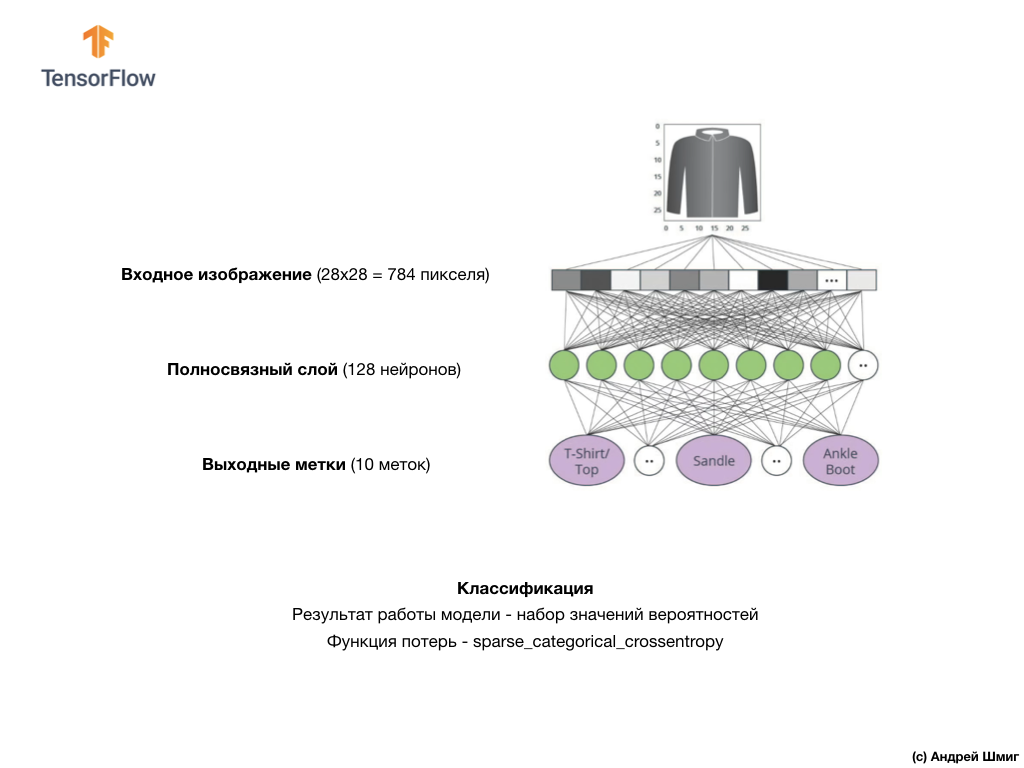 Kelas masalah pertama yang kami selesaikan dengan prediksi nilai tunggal disebut regresi. Konversi derajat Celsius ke derajat Fahrenheit adalah salah satu contoh tugas kelas ini. Contoh lain dari kelas tugas ini adalah tugas menentukan nilai sebuah rumah dengan jumlah kamar, total area, lokasi, dan karakteristik lainnya.Kelas tugas kedua yang kami pelajari dalam pelajaran ini mengelompokkan gambar ke dalam kategori yang tersedia disebut klasifikasi . Menurut data input, model akan mengembalikan distribusi probabilitas ("kepercayaan" model bahwa nilai input milik kelas ini). Dalam pelajaran ini, kami mengembangkan jaringan saraf yang mengklasifikasikan elemen pakaian ke dalam 10 kategori, dan dalam pelajaran berikutnya, kita akan belajar untuk menentukan siapa yang ditampilkan dalam foto - seekor anjing atau kucing, tugas ini juga berkaitan dengan tugas klasifikasi.Mari kita simpulkan dan catat perbedaan antara dua kelas masalah ini - regresi dan klasifikasi .
Kelas masalah pertama yang kami selesaikan dengan prediksi nilai tunggal disebut regresi. Konversi derajat Celsius ke derajat Fahrenheit adalah salah satu contoh tugas kelas ini. Contoh lain dari kelas tugas ini adalah tugas menentukan nilai sebuah rumah dengan jumlah kamar, total area, lokasi, dan karakteristik lainnya.Kelas tugas kedua yang kami pelajari dalam pelajaran ini mengelompokkan gambar ke dalam kategori yang tersedia disebut klasifikasi . Menurut data input, model akan mengembalikan distribusi probabilitas ("kepercayaan" model bahwa nilai input milik kelas ini). Dalam pelajaran ini, kami mengembangkan jaringan saraf yang mengklasifikasikan elemen pakaian ke dalam 10 kategori, dan dalam pelajaran berikutnya, kita akan belajar untuk menentukan siapa yang ditampilkan dalam foto - seekor anjing atau kucing, tugas ini juga berkaitan dengan tugas klasifikasi.Mari kita simpulkan dan catat perbedaan antara dua kelas masalah ini - regresi dan klasifikasi .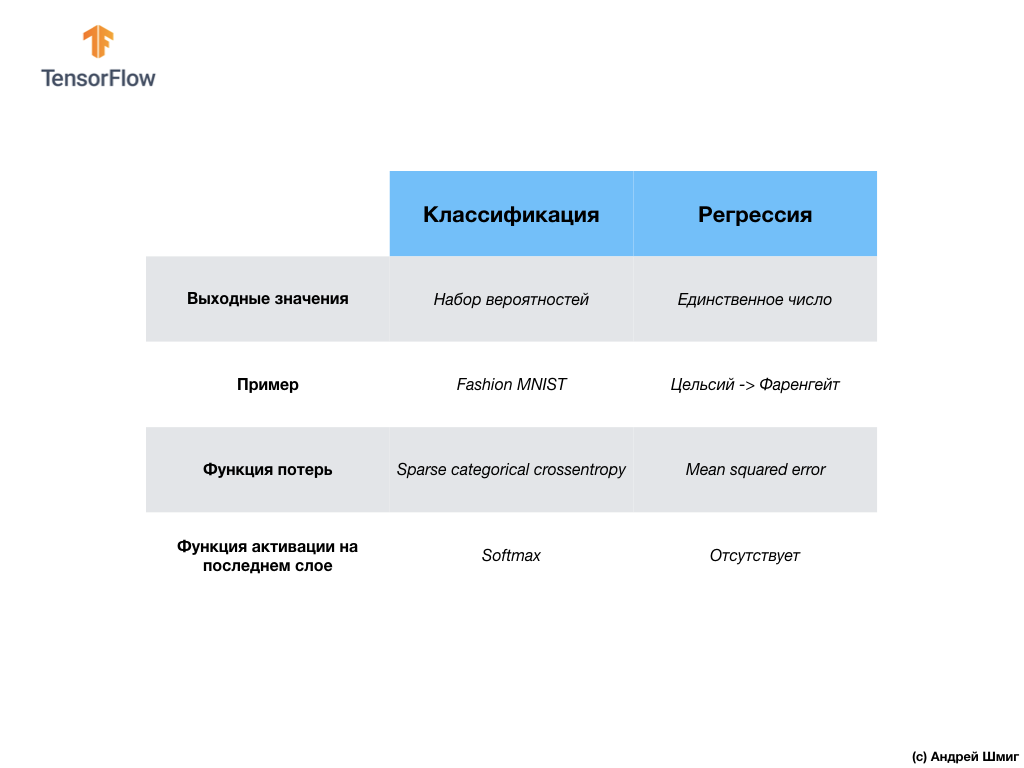 Selamat, Anda telah mempelajari dua jenis jaringan saraf! Bersiap-siap untuk kuliah berikutnya, di sana kita akan mempelajari jenis baru dari jaringan saraf - jaringan saraf convolutional (CNN).
Selamat, Anda telah mempelajari dua jenis jaringan saraf! Bersiap-siap untuk kuliah berikutnya, di sana kita akan mempelajari jenis baru dari jaringan saraf - jaringan saraf convolutional (CNN).Ringkasan
Dalam pelajaran ini, kami melatih jaringan saraf untuk mengklasifikasikan gambar dengan elemen pakaian. Untuk melakukan ini, kami menggunakan dataset Fashion MNIST, yang berisi 70.000 gambar item pakaian. 60.000 di antaranya kami gunakan untuk melatih jaringan saraf, dan 10.000 sisanya untuk menguji efektivitas kerjanya. Untuk mengirimkan gambar-gambar ini ke input jaringan saraf kami, kami perlu mengkonversi (memuluskan) mereka dari format 2D 28x28 menjadi format 1D dari 784 elemen. Jaringan kami terdiri dari lapisan yang terhubung penuh dari 128 neuron dan lapisan keluaran dari 10 neuron, sesuai dengan jumlah label (kelas, kategori item pakaian). 10 nilai output ini mewakili distribusi probabilitas untuk setiap kelas. Fungsi aktivasi Softmaxmenghitung distribusi probabilitas.Kami juga belajar tentang perbedaan antara regresi dan klasifikasi .- Regresi : Model yang mengembalikan nilai tunggal, seperti nilai rumah.
- Klasifikasi : Model yang mengembalikan distribusi probabilitas antara beberapa kategori. Misalnya, dalam tugas kami dengan Fashion MNIST, nilai output adalah 10 nilai probabilitas, yang masing-masing dikaitkan dengan kelas tertentu (kategori item pakaian). Saya mengingatkan Anda bahwa kami menggunakan fungsi aktivasi softmax hanya untuk mendapatkan distribusi probabilitas pada lapisan terakhir.
Versi video artikelVideo keluar beberapa hari setelah publikasi dan ditambahkan ke artikel.
... dan ajakan bertindak standar - daftar, beri nilai tambah, dan bagikan :)
YouTubeTelegramVKontakte