Dalam artikel sebelumnya, kami menguji pendekatan yang kami terapkan pada masalah pemrosesan data (agregasi) komputasi untuk visualisasi pada dashboard interaktif. Artikel menyentuh pada tahap pengiriman informasi dari sumber utama kepada pengguna dalam konteks kasus analitis, yang memungkinkan untuk memutar kubus informasi. Model konversi data yang disajikan dengan cepat menciptakan abstraksi, menyediakan format kueri tunggal dan konstruktor untuk menggambarkan perhitungan, agregasi, dan integrasi semua jenis sumber yang terhubung - tabel basis data, layanan, dan file .
Sumber yang terdaftar lebih cenderung terstruktur, menyiratkan prediktabilitas format data dan keunikan prosedur untuk pemrosesan dan visualisasi. Tetapi bagi analis, data yang tidak terstruktur tidak kalah menarik, yang ketika hasil pertama kali muncul, kadang-kadang terlalu tinggi dari ekspektasi sistem tersebut. Nafsu makan datang dengan makan, dan kehilangan kehati-hatian dapat dengan tepat mengulangi kisah ...
- Lebih Banyak! Lebih banyak emas!
Tapi mengi itu nyaris tak terdengar dan kengerian muncul di matanya
(Dongeng "Antelope Emas")

Di bawah potongan, artikel menguraikan fitur utama dan desain multi-peran cluster dan perayap perilaku oleh pengguna virtual yang mengotomatisasi rutin mengumpulkan informasi dari sumber daya Internet yang kompleks. Dan hanya pertanyaan tentang batas sistem seperti itu yang diangkat.
Saat mempertimbangkan metode perayapan, sumber daya Internet hipotetis yang darinya kita perlu mengekstraksi informasi dapat ditempatkan pada skala dengan dua ekstrem - dari sumber daya statis dan API sederhana ke situs interaktif dinamis yang memerlukan keterlibatan pengguna yang tinggi. Yang pertama termasuk generasi lama dari robot pencarian (yang modern, setidaknya, telah belajar untuk memproses JavaScript ), yang terakhir termasuk sistem dengan browser farm dan algoritma yang mensimulasikan pekerjaan pengguna atau menariknya ketika mengumpulkan informasi.
Dengan kata lain, teknologi perayapan dapat ditempatkan pada skala kompleksitas:

Di satu sisi, kompleksitas sumber dapat dipahami sebagai rangkaian tindakan yang diperlukan untuk mendapatkan informasi primer, dan di sisi lain, teknologi yang harus diterapkan untuk mendapatkan data yang dapat dibaca mesin yang sesuai untuk analisis.
Bahkan ekstraksi teks yang tampaknya sederhana dari halaman statis tidak selalu sepele dalam praktiknya - Anda perlu mengembangkan dan memelihara aturan planarisasi HTML untuk semua jenis halaman, atau mengotomatisasi dan menemukan heuristik dan solusi kompleks. Hingga taraf tertentu, penataan disederhanakan dengan pengembangan markup mikro ( khususnya, Schema.org , RDFa , Data Tertaut ), tetapi hanya dalam kasus-kasus khusus yang sempit, untuk mengunduh kartu perusahaan, produk, kartu bisnis dan produk optimisasi mesin pencari lainnya dan data terbuka.
Di bawah ini kami akan dengan sengaja mempersempit ruang lingkup dan fokus pada komponen teknologi dari subset peramban peramban yang dirancang untuk mengunduh informasi dari situs yang kompleks, khususnya jaringan sosial - ini adalah kasus yang tepat ketika metode perayapan sederhana lainnya tidak berfungsi.
Pertimbangkan suatu pendekatan yang mengurangi tugas mengumpulkan informasi dari jejaring sosial ke pembentukan pita waktu informasi - kumpulan atau aliran objek yang diperbarui dengan atribut dan stempel waktu. Daftar jenis objek dan atributnya berbeda, dapat dimodifikasi dan diperluas, misalnya: posting, suka, komentar, reposts dan entitas lain yang ditambahkan ke sistem oleh pengembang dan operator analitik, dan dimuat oleh crawler.
Karena rekaman itu adalah aliran objek terstruktur, muncul pertanyaan tentang pengisiannya. Kami mendukung dua jenis kaset:
- kaset sederhana yang diisi dengan konten dari sumber tetap;
- feed topik diisi dengan konten sesuai dengan kata kunci, frasa, dan istilah pencarian.
Contoh umpan sederhana dengan sumber tetap ( daftar URL untuk profil dan halaman ditetapkan ):

Jenis rekaman sederhana melibatkan perayapan berkala profil dan halaman ini di berbagai jejaring sosial dengan kedalaman perayapan dan pemuatan objek yang dipilih pengguna. Saat terisi, rekaman itu tersedia untuk dilihat, dianalisis, dan diunggah data:

Pita topik adalah ekstensi sederhana, ini menyediakan pencarian teks lengkap dan penyaringan objek yang dimuat ke dalam rekaman. Sistem secara otomatis mengontrol set sumber tape dan kedalaman bypass mereka, menganalisis relevansi dan hubungan sumber. Fitur implementasi ini adalah karena tidak adanya atau "aneh" pekerjaan pencarian built-in untuk kata kunci di jejaring sosial. Bahkan ketika fungsi seperti itu tersedia, paling sering hasilnya tidak sepenuhnya dihasilkan dan menurut beberapa algoritma internal, yang sepenuhnya tidak kompatibel dengan persyaratan untuk crawler.
Sebuah mekanisme khusus dengan heuristik tertentu bertanggung jawab untuk mengelola rekaman dalam sistem - ia menganalisis data dan sejarah, menambahkan sumber-sumber yang relevan (profil dan umpan komunitas), di mana salah satu ungkapan tertentu disebutkan, atau entah bagaimana terkait dengan mereka, dan menghilangkan yang tidak relevan.
Contoh rekaman tematik:

Di masa depan, kaset digunakan sebagai sumber dalam transformasi analitis dengan visualisasi hasil selanjutnya, misalnya, dalam bentuk grafik:

Dalam beberapa kasus, pemrosesan streaming objek yang masuk dilakukan dengan menyimpan ke koleksi target khusus atau mengunggah melalui REST API untuk menggunakan konten yang dikumpulkan dalam sistem pihak ketiga ( contoh ). Di yang lain, pemrosesan blok oleh timer dilakukan. Operator menjelaskan skrip pemrosesan dengan skrip atau membuat proses dengan sinyal kontrol dan blok fungsi, misalnya:

Kelompok tugas
Kaset aktif menentukan kumpulan tugas utama, yang masing-masing membentuk tugas terkait. Misalnya, satu tugas traversal profil dapat menghasilkan banyak sub-tugas terkait - mem-bypass teman, pelanggan, atau mengunduh posting baru dan informasi terperinci, dll. Ada juga tahap pra-pemrosesan objek baru dari pita tematik, yang juga membentuk tugas yang berkaitan dengan sumber-sumber baru yang relevan.
Akibatnya, kami mendapatkan sejumlah besar jenis tugas yang berbeda terkait satu sama lain, memiliki prioritas, waktu dan kondisi eksekusi - semua kebun binatang ini perlu dikelola dengan benar sehingga tidak ada situasi di mana beberapa tugas akan menyeret semua sumber daya gugusan ke diri mereka sendiri sehingga merugikan tugas dari kaset lain. .
Untuk menyelesaikan ketidakkonsistenan, sistem mengimplementasikan sumber daya virtual bersama dan mekanisme untuk penentuan prioritas dinamis, yang mempertimbangkan jenis tugas, waktu saat ini dan kemungkinan peluncuran dalam bentuk "kubah". Secara umum - prioritas pada titik tertentu menjadi maksimal, tetapi segera memudar, tugas "masam", tetapi dalam keadaan tertentu itu dapat tumbuh lagi.
Rumus untuk kubah tersebut memperhitungkan beberapa faktor, khususnya: prioritas tugas induk, relevansi sumber terkait, dan waktu upaya terakhir (dengan perayapan berulang untuk melacak perubahan atau ketika kesalahan terjadi).
Pengguna virtual
Dalam arti luas, pengguna virtual dapat dipahami sebagai tiruan maksimum dari tindakan manusia, secara praktis - seperangkat properti yang harus dimiliki oleh crawler:
- jalankan kode halaman menggunakan alat yang sama seperti pengguna - OS, browser, UserAgent, plugins, set font dan banyak lagi;
- berinteraksi dengan halaman, mensimulasikan pekerjaan seseorang dengan keyboard dan mouse - gerakkan kursor pada halaman, buat gerakan acak, jeda, tekan tombol saat mencetak teks dan banyak lagi ( jangan lupa tentang perangkat seluler );
- berinteraksi dengan pusat keputusan yang mempertimbangkan konteks dan konten halaman:
- memperhitungkan duplikat akun, relevansi objek pada halaman, kedalaman perayapan, kerangka waktu, dan lainnya;
- menanggapi situasi yang tidak biasa - dalam kasus captcha atau kesalahan, membentuk permintaan dan menunggu solusi baik menggunakan layanan pihak ketiga atau dengan keterlibatan operator sistem;
- memiliki legenda yang dapat dipercaya - simpan riwayat penelusuran dan cookie Anda (profil browser), gunakan alamat IP tertentu, perhitungkan periode akun sebagian besar aktivitas (misalnya, pagi-sore atau makan siang-malam).
Dalam tampilan ideal, satu pengguna virtual dapat memiliki beberapa akun, menggunakan beberapa browser pada periode waktu yang berbeda dan terhubung dengan pengguna virtual lainnya, serta memiliki perilaku dan kebiasaan berselancar internet yang menjadi ciri khas seseorang.
Misalnya, bayangkan situasi seperti itu - virtual menggunakan satu browser dan IP seolah-olah sedang bekerja (IP yang sama dapat digunakan oleh "rekan"), browser lain dan IP seolah-olah di rumah ("tetangga" menggunakannya), dan dari waktu ke waktu ponsel. Dengan pandangan masalah ini, melawan pengumpulan otomatis oleh layanan Internet tampaknya menjadi tugas yang tidak sepele dan, mungkin, tidak praktis.
Dalam praktiknya, semuanya jauh lebih sederhana - perang melawan perayap mirip gelombang dan mencakup serangkaian teknik kecil: moderasi manual, analisis perilaku pengguna (frekuensi dan keseragaman tindakan) dan menunjukkan captcha. Claruler, yang memiliki setidaknya sampai batas tertentu sifat-sifat dari daftar di atas, sepenuhnya menerapkan konsep pengguna virtual dan, dengan perhatian operator, dapat memenuhi fungsinya untuk waktu yang lama, tetap " Joe sulit dipahami ".
Tapi bagaimana dengan sisi etis dan hukum menggunakan pengguna virtual?
Agar tidak bermain-main dengan konsep data publik dan pribadi, masing-masing pihak memiliki argumen sendiri yang berat, kami hanya akan menyentuh pada poin mendasar.
Publikasi otomatis konten, surat spam, pendaftaran akun, dan aktivitas "aktif" lain dari pengguna virtual dapat dengan mudah dianggap ilegal atau memengaruhi kepentingan pihak ketiga. Dalam hal ini, sistem mengimplementasikan pendekatan di mana pengguna virtual hanya pengamat yang ingin tahu mewakili pengguna (operator mereka) dan melakukan rutinitas untuk mengumpulkan informasi sebagai gantinya.
Pengelolaan sumber daya virtual bersama
Seperti dijelaskan di atas, pengguna virtual adalah entitas kolektif yang menggunakan beberapa sumber daya sistem dan virtual dalam prosesnya. Beberapa sumber daya digunakan sendiri, sementara yang lain dibagikan dan digunakan oleh beberapa pengguna virtual, misalnya:
- alamat simpul keluaran (IP eksternal) - terkait dengan satu atau lebih pengguna virtual;
- profil browser - terkait dengan satu pengguna virtual;
- sumber daya komputasi - terhubung ke server, menetapkan batasan server secara keseluruhan dan untuk setiap jenis tugas;
- layar virtual - menetapkan batasan server, tetapi digunakan oleh pengguna virtual.
Setiap sumber daya virtual memiliki tipe dan sekelompok instance yang disebut slot. Pada setiap node cluster, konfigurasi sumber daya virtual dan slot didefinisikan, yang ditambahkan ke kumpulan sumber daya virtual dan dapat diakses ke semua node cluster. Selain itu, untuk satu jenis sumber daya virtual, jumlah slot yang tetap dan variabel dapat ditambahkan.
Setiap slot dapat memiliki atribut yang akan digunakan sebagai kondisi saat menautkan dan mengalokasikan sumber daya. Misalnya, kita dapat mengaitkan setiap pengguna virtual dengan jenis tugas tertentu, server, alamat IP, akun, periode aktivitas perayapan terbesar, dan atribut sewenang-wenang lainnya.
Dalam kasus umum, siklus hidup suatu sumber daya terdiri dari tahapan-tahapan tertentu:
- Ketika node cluster diluncurkan di kumpulan sumber daya virtual, slot terbuka tambahan terdaftar, serta tautan antara sumber daya;
- Ketika tugas diluncurkan oleh dispatcher dari kumpulan sumber daya virtual, slot gratis yang sesuai dipilih dan diblokir. Pada gilirannya, memblokir sumber daya induk mengarah ke pemblokiran sumber daya terkait, dan tanpa adanya slot gratis, kegagalan dihasilkan;
- Setelah menyelesaikan tugas, slot sumber daya utama dan slot yang terkait dibebaskan.
Selain yang ditentukan dalam konfigurasi simpul, ada juga sumber daya virtual pengguna - entitas yang digunakan operator sistem. Secara khusus, operator menggunakan antarmuka registri pengguna virtual, yang mendukung beberapa fungsi berguna sekaligus:
- pengelolaan detail dan atribut tambahan yang menunjukkan spesifikasi penggunaan, khususnya, pengguna virtual dapat dibagi menjadi beberapa kelompok dan digunakan untuk tujuan yang berbeda;
- melacak status dan statistik pengguna virtual;
- koneksi ke layar virtual - pelacakan kerja real-time, melakukan tindakan dalam browser alih-alih pengguna virtual (widget desktop jarak jauh).
Contoh registri sumber daya virtual pengguna:

Kasing keren yang tidak berakar
Selain kaset informasi sebagai "pembunuh fitchi", kami mengembangkan grafik pencarian prototipe untuk melakukan pencarian kompleks dan melakukan penyelidikan online. Gagasan utamanya adalah membangun grafik visual di mana simpul-simpulnya adalah templat obyek (orang, organisasi, grup, publikasi, suka, dll.), Dan tautannya adalah pola koneksi antara objek yang ditemukan.
Contoh grafik pencarian orang dan hubungan di antara mereka:

Pendekatan ini mengasumsikan bahwa pencarian dimulai dengan informasi minimum yang diketahui. Setelah pencarian awal, pengguna memeriksa hasil dan secara bertahap menambahkan kondisi tambahan ke grafik pencarian, mempersempit pilihan dan meningkatkan kedalaman merangkak dan akurasi hasil. Pada akhirnya, grafik mengambil bentuk di mana masing-masing node adalah umpan informasi terpisah dengan hasilnya. Rekaman ini juga dapat digunakan sebagai sumber untuk analisis dan visualisasi lebih lanjut pada dasbor dan widget.

Misalnya ...Sebagai contoh, kita dapat mempertimbangkan beberapa kasus sederhana:
- temukan semua teman orang tersebut dengan nama yang diberikan;
- Temukan semua posting teman seseorang dengan nama yang diberikan dan atribut lainnya;
- temukan semua pelanggan ke halaman-halaman di mana frasa kunci yang disebutkan disebutkan, atau kumpulkan lingkungan di sekitar tulisan atau penulis tertentu;
- atau temukan persimpangan - penulis komentar pada semua posting yang ditulis oleh penulis yang pernah menerbitkan posting tentang topik tertentu.
Ketika kami mengumumkan pengembangan kecocokan semacam itu, para pelanggan dan mitra kami dengan hangat mendukung gagasan ini, tampaknya justru sangat kekurangan solusi serupa yang ada. Tetapi setelah menyelesaikan prototipe kerja, dalam praktiknya ternyata pelanggan tidak siap untuk mengubah proses internal mereka, dan investigasi internet agak dianggap sebagai sesuatu yang bisa berguna jika mereka tiba-tiba perlu. Pada saat yang sama, dari sisi teknologi, fungsionalitasnya serius dan membutuhkan penyempurnaan dan dukungan lebih lanjut. Akibatnya, karena kurangnya permintaan dan kepentingan praktis dari mitra kami, fitch ini harus dibekukan untuk sementara waktu hingga waktu yang lebih baik.
Reinkarnasi
Mengingat vektor pengembangan solusi kami saat ini, fitur ini tampaknya masih relevan, tetapi dari sudut pandang teknis sudah terlihat dengan cara yang berbeda. Alih-alih, ini merupakan perpanjangan dari fungsi Cubisio, yaitu, editor model domain dan editor proses pengolahan data, yang sejauh ini telah diimplementasikan sebagai prototipe, tetapi menyediakan pendekatan serupa dalam bentuk umum.
Contoh model ontologis area subjek "Jejaring sosial" (mengklik gambar editor terbuka):

Contoh grafik pencarian-analitik berdasarkan ontologi di atas (mengklik gambar membuka editor):

Tumpukan teknologi cluster

Sistem yang dijelaskan dikembangkan bersama dengan platform (kami menyebutnya dWires) beberapa tahun yang lalu, berfungsi dan masih digunakan. Solusi sukses utama secara alami bermigrasi ke perkembangan baru kami. Secara khusus, platform yang dideskripsikan mewakili generasi pertama perancang sistem informasi-analitis, dari mana platform jsBeans dan perkembangan kami lainnya telah berputar.
Singkatnya, sistem ini didasarkan pada kelompok Akka, juru bahasa Badak dan server web Jetty yang tertanam. Beberapa fitur arsitektur yang bermanfaat dapat dilihat pada diagram di atas. , , , JavaScript- , jsBeans .
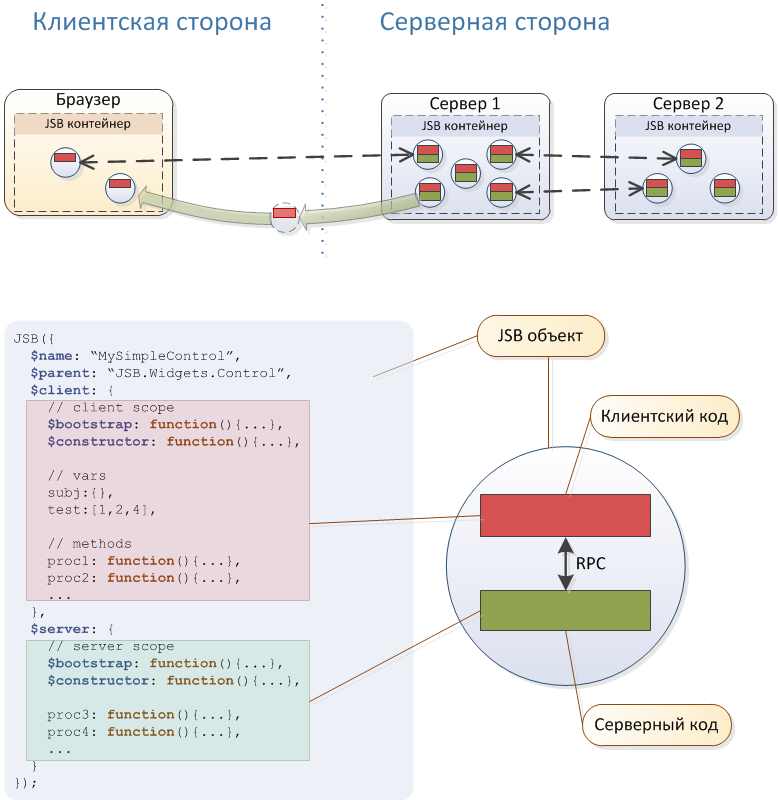
, – .
Java. , , – - JavaScript. JavaScript ( ), , , . – , , , , , - .
Akka - . - Akka Cluster , . , " " ( ) .
Selenium WebDriver , : , , API . WebDriver ( , IP ).
( ):
- , , Xvfb;
- VNC , , x11vnc;
- VNC Web Viewer , , noVNC -.
MongoDB, – . Elasticsearch, MongoDB. (H2, EhCache, Db4o).
" ", , bash , ( ). . , .
, .
. – . , " ".
, .
,
( « »)