
Apakah Anda terbiasa dengan situasi di mana Anda menghabiskan banyak waktu untuk memilih film yang sebanding dengan waktu Anda menontonnya? Untuk pengguna bioskop online, ini adalah masalah umum, dan bagi bioskop itu sendiri - untung rugi.
Untungnya, kami memiliki Rekko - sistem rekomendasi pribadi yang telah berhasil membantu pengguna Okko selama setahun untuk memilih film dan seri dari lebih dari sepuluh ribu unit konten. Dalam artikel ini saya akan memberi tahu Anda bagaimana ia disusun dari sudut pandang algoritmik dan teknis, bagaimana kami mendekati pengembangannya dan bagaimana kami mengevaluasi hasilnya. Baiklah, saya juga akan memberi tahu Anda tentang hasil tes A / B tahunan.
Pertama, sedikit sejarah. Okko memulai keberadaannya pada tahun 2011 sebagai bagian dari Iota, dimulai dengan nama Yota Play.
Sudah pada tahun 2011, pengguna dengan antusias menerima gagasan menonton film secara legal di Internet Yota Play adalah layanan unik untuk masanya: ia terintegrasi dengan jejaring sosial dan menggunakan informasi tentang film yang dilihat dan dinilai oleh teman-teman di banyak bagian layanan, termasuk rekomendasi.

Pada 2012, diputuskan untuk melengkapi rekomendasi sosial dengan yang algoritmik. Begitulah "Oracle" muncul - sistem rekomendasi pertama dari bioskop online Okko. Berikut beberapa kutipan dari dokumen desainnya:
Pendekatan serupa digunakan dalam sistem rekomendasi pribadi yang diterapkan. Skala level digunakan dari “tidak ada” (kekosongan, ketidakhadiran) hingga “segalanya” (sepenuhnya, maksimal). Dalam kisaran [127 .. + 127] 0 - adalah tengah atau "norma". Pada skala ini, tingkat simpati untuk karakter utama dan harga subjektif dari produk dan tingkat warna "merah" juga dievaluasi. Misalnya, ukuran alam semesta diperkirakan +127 (pada skala dimensi), dan kegelapan diperkirakan 127 (pada skala intensitas cahaya).
Dalam membuat rekomendasi, penting tidak hanya latar belakang, tetapi juga sifat pengguna tertentu. Profil pribadi juga berisi 4 skala jenis karakter (menurut K. Leonhard - demonstratif, pedantic, mandek, mudah bergairah).
Batasan fisiologis otak tidak tergantung pada sifat-sifat karakter seseorang dan pada seberapa ramah dan mudah bergaulnya dia. Menurut profesor, pembatasan ada di neokorteks, departemen yang bertanggung jawab atas pikiran dan ucapan sadar. Pembatasan ini juga diperhitungkan dalam sistem yang diterapkan, terutama ketika mengembangkan rekomendasi untuk tipe karakter yang luar biasa dan ketika membentuk sampel pengguna tersebut di antara koneksi sosial.

Seperti yang sudah Anda pahami, zamannya liar, batas fisiologis otak tidak terbatas pada apa pun, dan neokorteks yang di-overclock sendiri dapat menghasilkan rekomendasi pribadi dengan kecepatan cahaya. Karena itu, model itu memutuskan untuk segera masuk ke produksi.
Sejauh orang dapat menilai dari artefak yang masih hidup dari peradaban kuno, "Oracle" adalah campuran liar dari algoritma penyaringan kolaboratif, yang dengan murah hati dibumbui dengan aturan bisnis.

Pada pertengahan 2013, semua orang mulai melepaskan sedikit dan akhirnya memutuskan untuk memeriksa kualitas mesin rekomendasi. Untuk melakukan ini, editor terlatih khusus mengisi bagian utama aplikasi dan meluncurkan tes A / B: setengah dari pengguna melihat output dari algoritma, setengah - pilihan editor.
Sekarang kita membaca artikel tentang kemenangan selanjutnya dari kecerdasan buatan dan dengan membayangkan membayangkan hari ketika dia akan kehilangan pekerjaan kita. Kemudian, pada 2013, situasinya berbeda: seseorang dengan gagah berani mengalahkan mobil, menciptakan lebih banyak pekerjaan di departemen konten. Oracle dimatikan dan tidak pernah dihidupkan lagi. Segera, semua chip sosial menghilang, dan Yota Play berubah menjadi Okko.
Periode 2013 hingga 2016 ditandai oleh "musim dingin" kecerdasan buatan dan aturan totaliter departemen konten: tidak ada rekomendasi pribadi dalam layanan ini.
Pada pertengahan 2017, menjadi jelas bahwa Anda tidak bisa hidup seperti itu lagi. Keberhasilan Netflix sangat dikenal oleh semua orang dan seluruh industri bergerak dengan cepat menuju personalisasi. Pengguna tidak lagi tertarik pada layanan statis "bodoh", mereka sudah mulai terbiasa dengan antarmuka "pintar", memahami mereka dengan sempurna dan memprediksi semua keinginan mereka.
Sebagai iterasi pertama, kami memutuskan untuk berintegrasi dengan dua pemasok besar rekomendasi Rusia. Sekali sehari, kedua layanan mengambil data yang diperlukan dari Okko, berkarat dengan kotak hitam mereka di server yang jauh dan mengunggah hasilnya.
Menurut hasil uji A / B enam bulan, tidak ada perbedaan signifikan secara statistik yang ditemukan pada kelompok kontrol dan kelompok uji.
Tepat pada akhir tes A / B ini, saya datang ke Okko untuk mulai menjadikan layanan tersebut benar-benar pribadi dengan kepala analitik, Mikhail Alekseev ( malekseev ). Kurang dari setahun kemudian, Danil Kazakov ( xaph ) bergabung dengan kami, akhirnya membentuk tim saat ini.
Pertimbangan umum
Ketika masalah bisnis yang telah lama dipelajari oleh komunitas internasional muncul di depan Anda dan, yang, perlu diselesaikan dengan cepat, Anda tergoda untuk mengambil solusi jaringan saraf dalam populer pertama yang Anda miliki, memasukkan data ke dalamnya dengan sekop, ram, dan membuangnya ke dalam produk.

Hal utama adalah jangan menyerah pada godaan ini. Tugas komunitas ilmiah - untuk mencapai kecepatan maksimum pada set data busuk dan sintetis - seringkali tidak sesuai dengan tugas bisnis - untuk mendapatkan lebih banyak uang, sambil menghabiskan lebih sedikit sumber daya.

Tidak, ini tidak berarti bahwa Anda tidak perlu jaringan berulang dan Anda dapat memperoleh miliaran menggunakan metode k tetangga terdekat. Mungkin saja ternyata bahwa pada data Anda, dekomposisi matriks klasik akan memungkinkan Anda untuk mendapatkan tambahan 100 juta bersyarat per tahun, dan jaringan berulang - 105 juta per tahun. Pada saat yang sama, memelihara rak server dengan kartu video untuk jaringan yang sama ini akan menelan biaya 10 juta per tahun dan memerlukan beberapa bulan ekstra untuk mengembangkan dan mengimplementasikan, dan integrasi sederhana dari dekomposisi matriks yang sudah jadi ke dalam bagian lain dari layanan dan mailing list akan memerlukan satu bulan perbaikan dan akan memberikan 100 juta kondisional lainnya. per tahun.
Oleh karena itu, penting untuk memulai dengan dasar-dasar - metode dasar yang terbukti - dan bergerak ke arah pendekatan yang lebih modern, pastikan untuk mengukur dan memprediksi efek apa yang akan dimiliki setiap metode baru pada bisnis, berapa biayanya dan berapa banyak yang akan memungkinkan Anda untuk menghasilkan.
Okko bisa mengukur dengan baik. Secara harfiah setiap fitur baru, setiap inovasi yang kami lakukan melalui uji A / B, diperiksa dalam konteks berbagai kelompok pengguna, efek diperiksa untuk signifikansi statistik dan hanya setelah itu keputusan dibuat apakah akan menerima atau menolak fungsi baru.

Dasbor Rekko saat ini, misalnya, membandingkan kontrol dan kelompok uji untuk lebih dari 50 metrik, termasuk pendapatan, waktu yang dihabiskan dalam layanan, waktu untuk memilih film, jumlah penayangan menurut berlangganan, konversi untuk membeli dan pembaruan otomatis, dan banyak lainnya. Dan ya, kami masih menyimpan sekelompok kecil pengguna yang belum pernah menerima rekomendasi hasil personalisasi (maaf).

Tentang sistem rekomendasi
Untuk memulai, pengantar kecil untuk sistem rekomendasi.
Tujuan dari sistem pemberi rekomendasi adalah untuk setiap pengguna pada ceritanya tentang berinteraksi dengan elemen untuk membangun hubungan pesanan pada set semua elemen. Ini artinya: tidak peduli apa pun dua elemen sewenang-wenang yang kami ambil, kami selalu dapat mengatakan mana yang lebih disukai untuk pengguna dan mana yang kurang.
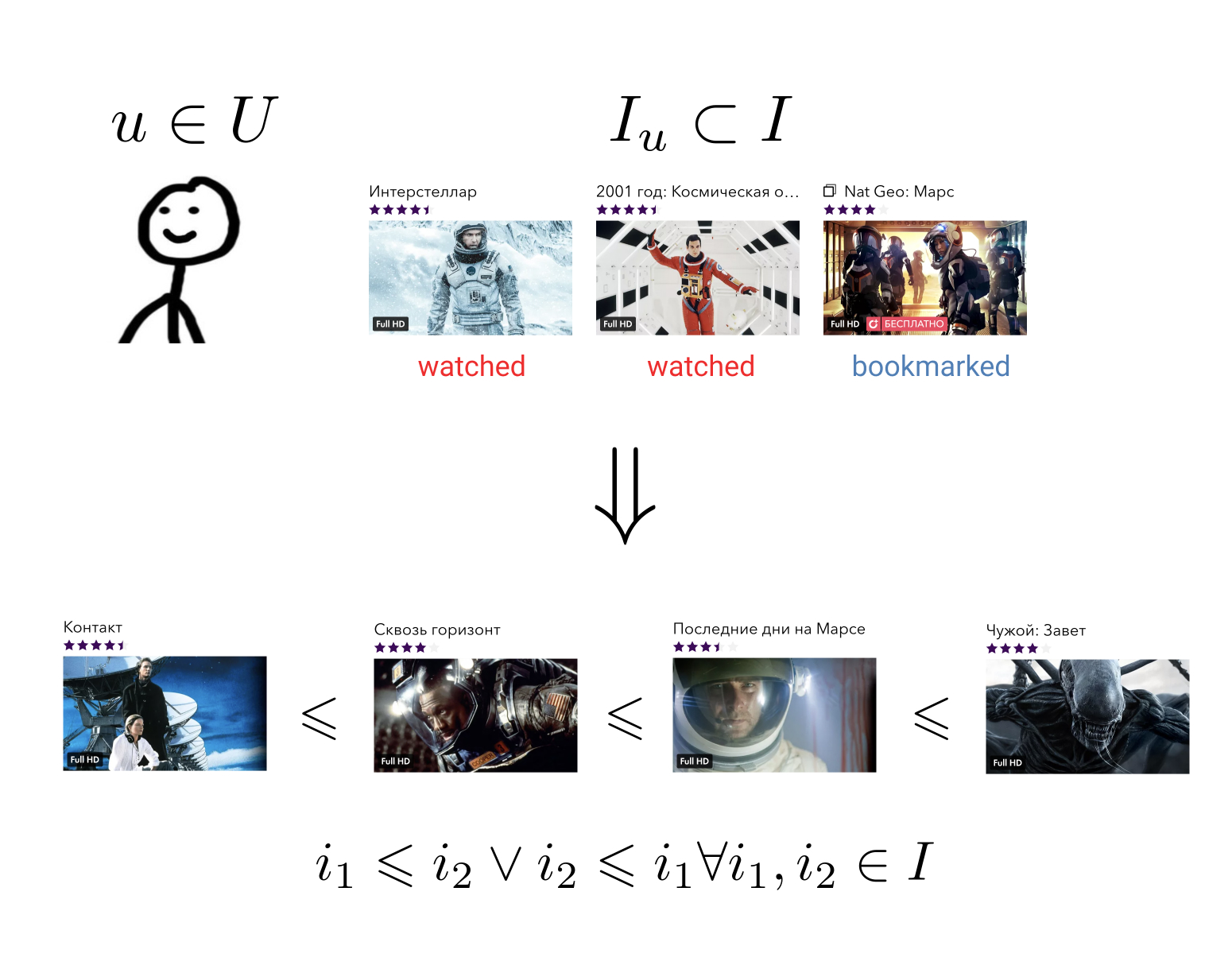
Tugas yang agak umum ini dapat direduksi menjadi tugas yang lebih sederhana: memetakan elemen ke himpunan di mana relasi urutan sudah ditentukan. Misalnya, pada set bilangan real. Dalam hal ini, perlu bagi setiap pengguna dan setiap elemen untuk dapat memprediksi nilai tertentu - berapa banyak pengguna ini lebih suka elemen ini.

Memiliki hubungan pesanan pada elemen kami, kami dapat menyelesaikan banyak masalah bisnis, misalnya, memilih dari antara semua elemen N yang paling relevan bagi pengguna atau mengurutkan hasil pencarian sesuai keinginannya.
Idealnya, kita membutuhkan seluruh keluarga hubungan keteraturan konteks-sensitif. Jika pengguna telah memasukkan koleksi "Action", ia kemungkinan besar akan lebih memilih film "Destroyer" daripada film "Oscar", tetapi dalam koleksi "Films with Sylvester Stallone" preferensi mungkin sebaliknya. Contoh serupa dapat diberikan untuk hari dalam seminggu, waktu dalam sehari, atau perangkat dari mana pengguna memasuki layanan.

Secara tradisional, semua metode untuk membangun rekomendasi pribadi dibagi menjadi tiga kelompok besar: filtering kolaboratif (CF), model konten (model konten, CM) dan model hybrid yang menggabungkan dua pendekatan pertama.
Metode penyaringan kolaboratif menggunakan informasi tentang interaksi semua pengguna dan semua elemen. Informasi tersebut, sebagai suatu peraturan, disajikan dalam bentuk matriks jarang, di mana baris berhubungan dengan pengguna, kolom dengan elemen, dan pengguna dan elemen mengandung nilai yang menandai interaksi di antara mereka, atau celah jika tidak ada interaksi seperti itu. Tugas membangun relasi pesanan di sini mengurangi tugas mengisi elemen matriks yang hilang.
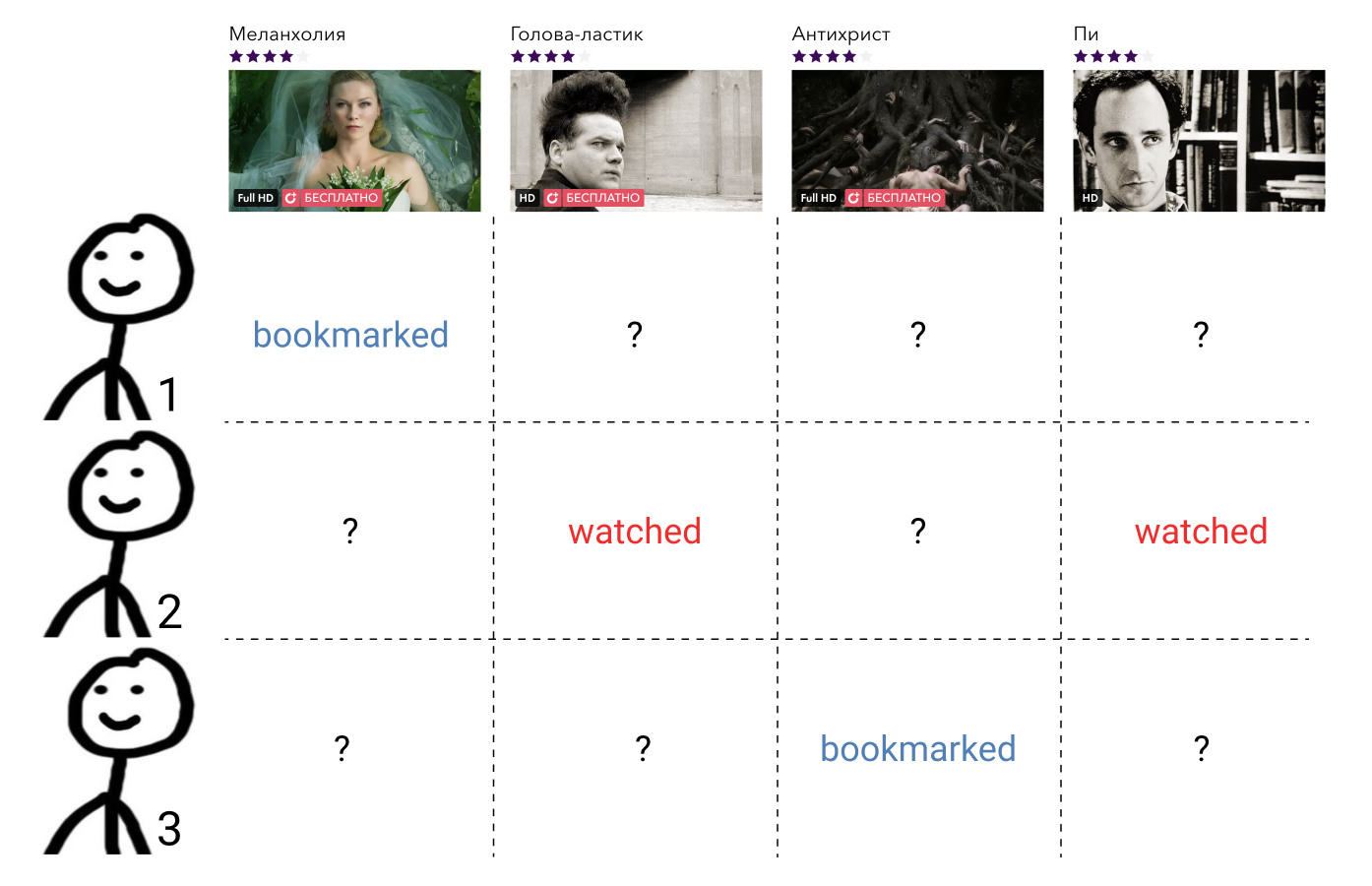
Metode ini, sebagai suatu peraturan, mudah dipahami dan diimplementasikan, cepat, tetapi tidak menunjukkan hasil terbaik.
Model konten - metode pembelajaran mesin sewenang-wenang untuk menyelesaikan masalah klasifikasi atau regresi, diparameterisasi oleh serangkaian parameter tertentu . Di pintu masuk, mereka menerima atribut pengguna dan atribut elemen, dan output adalah tingkat relevansi elemen yang diberikan kepada pengguna ini. Model seperti itu tidak diajarkan tentang interaksi semua pengguna dan semua elemen, seperti metode penyaringan kolaboratif, tetapi hanya pada preseden individu.

Model seperti itu, sebagai suatu peraturan, jauh lebih akurat daripada metode penyaringan kolaboratif, tetapi mereka jauh lebih lambat dalam kecepatan. Bayangkan jika kita memiliki fungsi beberapa bentuk umum yang menerima tanda-tanda pengguna dan elemen sebagai input, maka itu harus dipanggil untuk setiap pasangan . Dalam kasus seribu pengguna dan sepuluh ribu elemen, ini adalah sejuta panggilan.
Model hibrida menggabungkan kekuatan dari kedua pendekatan, menawarkan rekomendasi kualitas dalam jumlah waktu yang wajar.
Pendekatan hybrid paling populer saat ini adalah arsitektur dua tingkat, di mana model penyaringan kolaboratif memilih sejumlah kecil (100 - 1000) kandidat dari semua elemen yang mungkin, yang kemudian diberi peringkat oleh model konten yang jauh lebih kuat. Kadang-kadang ada beberapa tahap seleksi kandidat dan model yang semakin kompleks digunakan di setiap level baru.

Arsitektur seperti itu memiliki banyak keunggulan:
- Bagian kolaboratif dan konten tidak saling berhubungan dan dapat dilatih secara terpisah dengan frekuensi yang berbeda;
- Kualitas selalu lebih baik daripada model kolaboratif secara terpisah;
- Kecepatannya jauh lebih tinggi daripada model konten secara terpisah;
- "Gratis" kami mendapatkan vektor dari model kolaboratif, yang kemudian dapat digunakan untuk menyelesaikan masalah terkait.
Jika kita berbicara tentang teknologi tertentu, maka ada banyak kemungkinan kombinasi.
Sebagai bagian kolaboratif, Anda dapat mengambil langganan pengguna, konten populer, konten populer di antara teman-teman pengguna, Anda dapat menerapkan faktorisasi matriks atau tensor, melatih DSSM atau metode lainnya dengan prediksi yang cukup cepat.
Sebagai model konten, pendekatan apa pun dapat digunakan secara umum, mulai dari regresi linier hingga grid dalam.
Di Okko, kami saat ini berfokus pada kombinasi faktorisasi matriks dengan kehilangan WARP dan peningkatan gradien pada pohon, yang sekarang akan saya bahas secara rinci.
Tahap satu: pemilihan kandidat
Saya pikir saya tidak berbohong jika saya mengatakan bahwa algoritma faktorisasi matriks sejauh ini merupakan metode penyaringan kolaboratif yang paling populer. Inti dari metode ini jelas dari namanya: kami mencoba untuk menyajikan matriks interaksi pengguna yang telah disebutkan dengan konten oleh produk dari dua matriks peringkat lebih rendah, salah satunya akan menjadi "matriks pengguna" dan yang lainnya "matriks elemen". Dengan dekomposisi ini, kita dapat mengembalikan matriks asli beserta semua nilai yang hilang.

Dalam hal ini, tentu saja, kita bebas memilih kriteria untuk kesamaan matriks yang tersedia dan dipulihkan. Kriteria paling sederhana adalah standar deviasi.
Biarkan - baris matriks pengguna yang sesuai dengan pengguna , dan - kolom matriks elemen yang sesuai dengan elemen . Lalu, ketika mengalikan matriks, produk mereka akan berarti besarnya interaksi yang dimaksudkan antara pengguna yang diberikan dan elemen. Sekarang menghitung simpangan baku antara jumlah ini dan nilai interaksi apriori yang diketahui untuk semua pasangan pengguna dan elemen yang berinteraksi , kami mendapatkan fungsi kerugian yang dapat diminimalkan.
Sebagai aturan, regularisasi masih ditambahkan ke dalamnya.
Masalah seperti itu bukan cembung dan NP-kompleks. Namun, mudah untuk memperhatikan bahwa ketika memperbaiki salah satu matriks, tugas berubah menjadi regresi linier relatif terhadap matriks kedua, yang berarti bahwa kita dapat mencari solusi secara iteratif, secara bergantian membekukan baik matriks pengguna atau matriks elemen. Pendekatan ini disebut Alternating Least Squares (ALS).

Kelebihan utama dari ALS adalah kecepatan dan kemampuan untuk memparalelkan dengan mudah. Untuk ini, ia sangat dicintai di Yandex.Zen dan Vkontakte, di mana pengguna dan elemen berjumlah puluhan juta.
Namun, jika kita berbicara tentang jumlah data yang cocok pada satu mesin, ALS tidak tahan terhadap kritik. Masalah utamanya adalah ia mengoptimalkan fungsi kerugian yang salah. Ingat perumusan tugas membangun sistem rekomendasi. Kami ingin mendapatkan relasi pesanan pada set, dan bukannya mengoptimalkan standar deviasi.
Sangat mudah untuk memberikan contoh matriks yang standar deviasinya akan minimal, tetapi urutan unsur-unsurnya hancur tanpa harapan.
Mari kita lihat apa yang bisa kita lakukan. Di kepala pengguna, semua elemen yang berinteraksi dengannya diatur dalam urutan tertentu. Sebagai contoh, dia tahu pasti bahwa Interstellar lebih baik daripada Gravity, Gravity dan Alien adalah film yang sama baiknya, dan mereka semua sedikit lebih buruk daripada Terminator. Pada saat yang sama, ia juga mengalami sikap tertentu terhadap film yang belum ditonton pengguna, dan hal yang sama untuk semua orang. Dia mungkin percaya bahwa film-film semacam itu secara apriori lebih buruk daripada film-film yang dia tonton. Atau dia mungkin menganggap bahwa, misalnya, Prometheus adalah film yang buruk, dan film apa pun yang belum dia tonton akan lebih baik daripada dia.
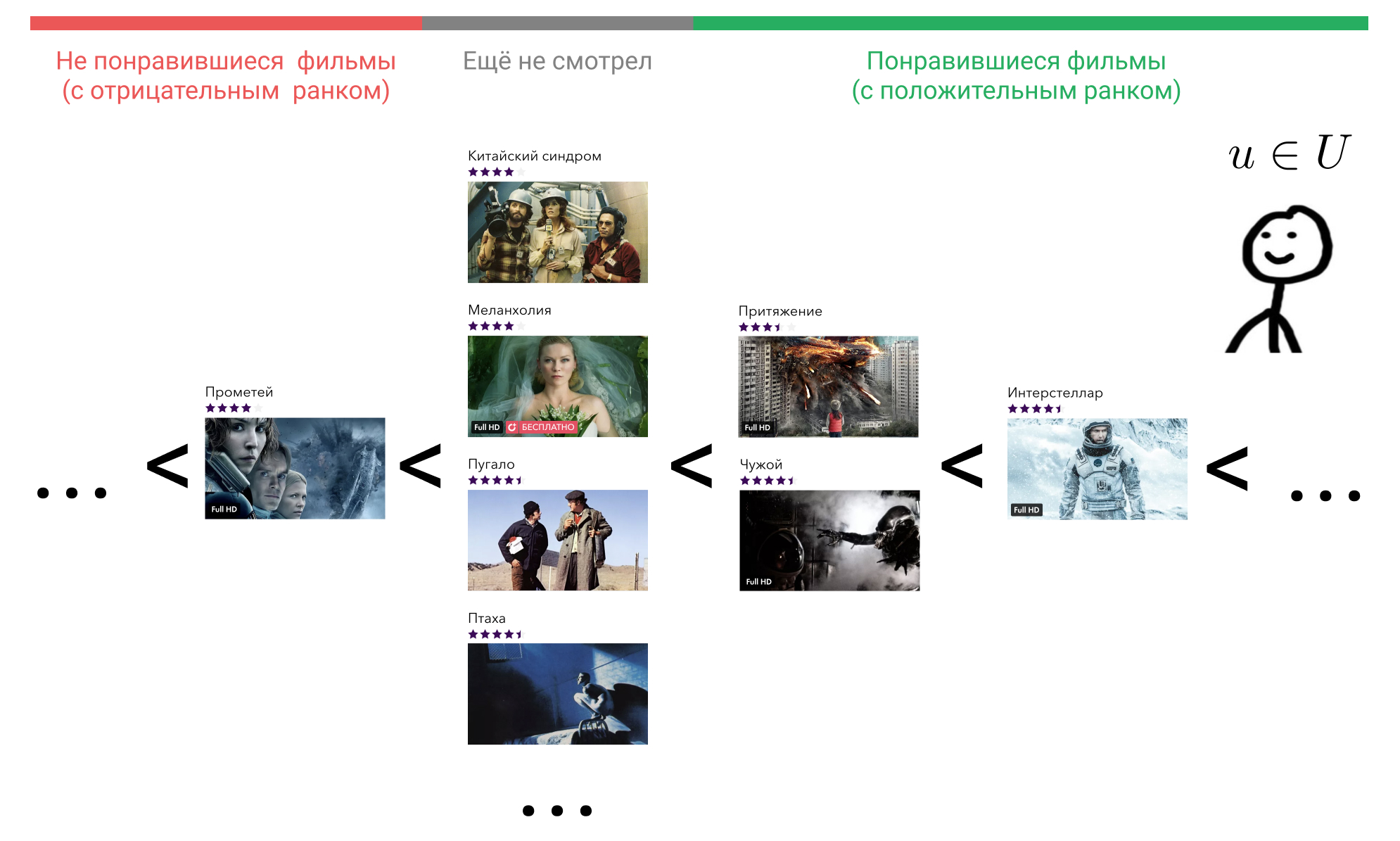
Bayangkan bahwa menurut beberapa tanda perilaku pengguna dalam layanan, kita dapat mengembalikan pesanan ini dengan menampilkan elemen yang berinteraksi dengannya, ke dalam bilangan bulat menggunakan fungsi tersebut. . Banyak film yang digunakan pengguna berinteraksi, dilambangkan sebagai . Kami setuju itu jika pengguna belum berinteraksi dengan film itu adalah . Jadi, jika pengguna menganggap film itu buruk, maka , dan jika bagus, maka .

Sekarang kita bisa masuk peringkat .
di sini menunjukkan fungsi indikator dan sama dengan unity if benar dan nol sebaliknya.
Mari kita berhenti sejenak dan berpikir apa arti peringkat itu.
Kami memperbaiki pengguna , ini adalah beberapa pengguna tertentu, yang mana - kami tidak tertarik. Dengan demikian, vektornya akan diperbaiki.
Ambil sekarang setiap film yang dia tonton, misalnya, Interstellar. Dalam rumusnya, ini . Selanjutnya, kami menemukan film yang menurut pengguna lebih buruk daripada Interstellar. Kita dapat memilih dari "Attraction", "Alien", "Prometheus", atau film apa pun yang belum dia tonton.

Ambil "Daya Tarik." Dalam rumusnya, ini . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
dimana — .
, , , .
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
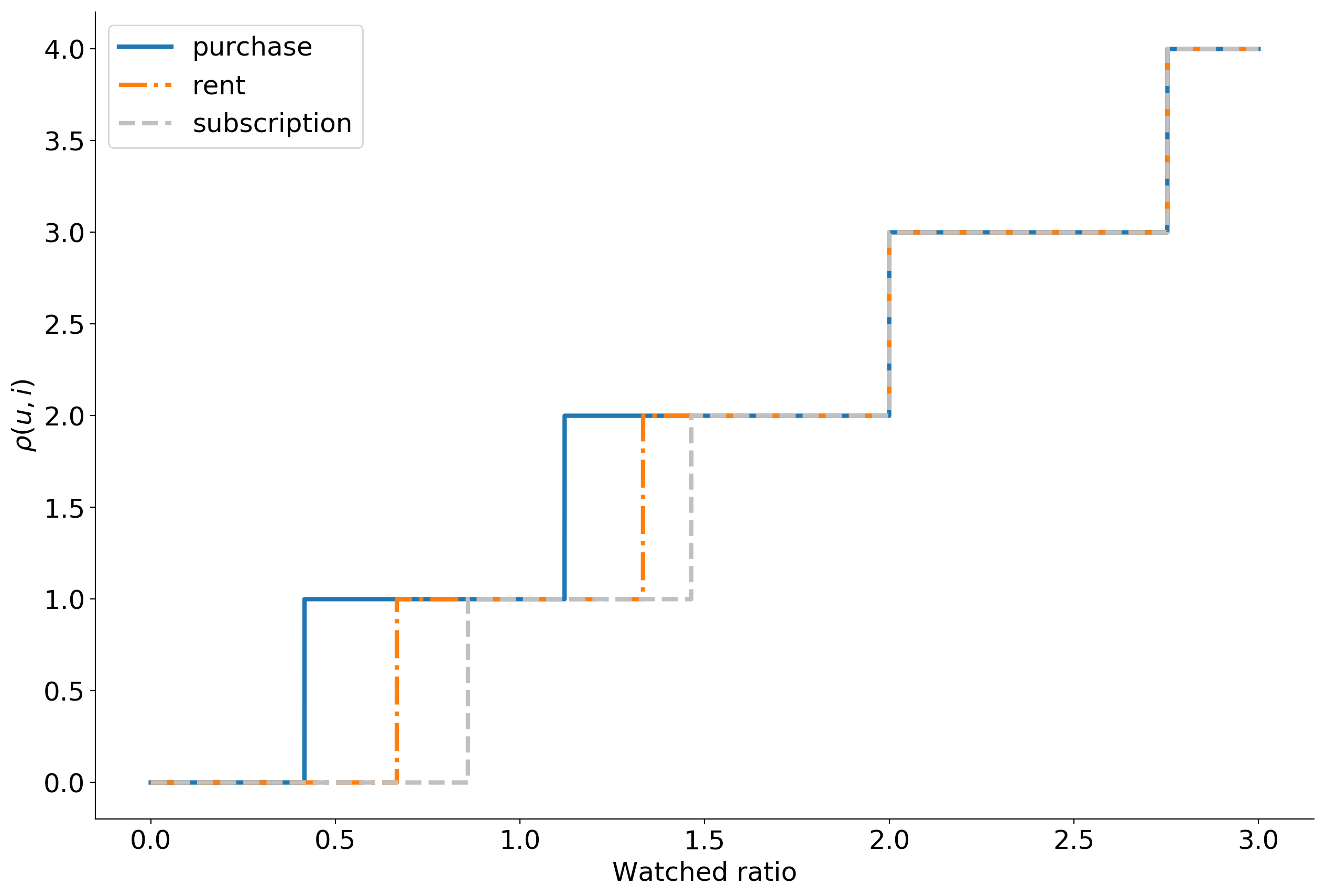
, , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
Masalah-masalah ini dihindari oleh model konten. Mereka kuat, ekspresif dan Anda bisa menempel tanda-tanda ke dalamnya, tetapi mereka sangat lambat. Solusinya adalah menjalankan model konten tidak pada semua elemen, tetapi pada kandidat yang diperoleh dari dekomposisi matriks. Mungkin ada banyak kandidat yang Anda proses, tetapi lebih baik setidaknya dua kali lipat dari yang Anda tunjukkan kepada pengguna. Dalam kasus kami, untuk 100 film yang direkomendasikan, solusi terbaik adalah menggunakan 400 kandidat.

Atribut yang kami kirimkan ke model konten dapat dibagi menjadi tiga kelompok: atribut pengguna, atribut elemen, dan tanda interaksi. Secara total, sekitar 50 tanda diperoleh.
Sebagai tanda-tanda pengguna, kami menggunakan statistik agregat dari perilaku mereka di layanan, misalnya:
- Persentase Tampilan Langganan
- distribusi perangkat dari mana pengguna login ke aplikasi,
- waktu hidup dalam layanan,
- dll.
Untuk film, kami menggunakan hampir semua meta-informasi yang tersedia: genre, tahun rilis, negara, aktor, sutradara, batas usia, dll. Metrik bisnis gabungan juga membantu dengan baik: persentase kunjungan ke kartu, jumlah penayangan, penambahan ke favorit, distribusi dengan melihat metode, perangkat, dll.
Tanda-tanda interaksi meliputi kecepatan dari tahap pemilihan kandidat dan statistik gabungan untuk semua interaksi pengguna dan film sebelumnya dengan partisipasi aktor, sutradara, penulis skenario yang sama dengan film yang dipermasalahkan.
Pertanyaan paling umum yang muncul ketika datang ke kandidat peringkat dengan model tingkat kedua adalah bagaimana melatih model ini. Dalam kasus faktorisasi matriks saja, kami membutuhkan dua set, dipisahkan oleh pelatihan waktu dan tes. Dalam hal sistem dua tahap, kita akan membutuhkan tiga di antaranya - dua pelatihan dan satu tes.
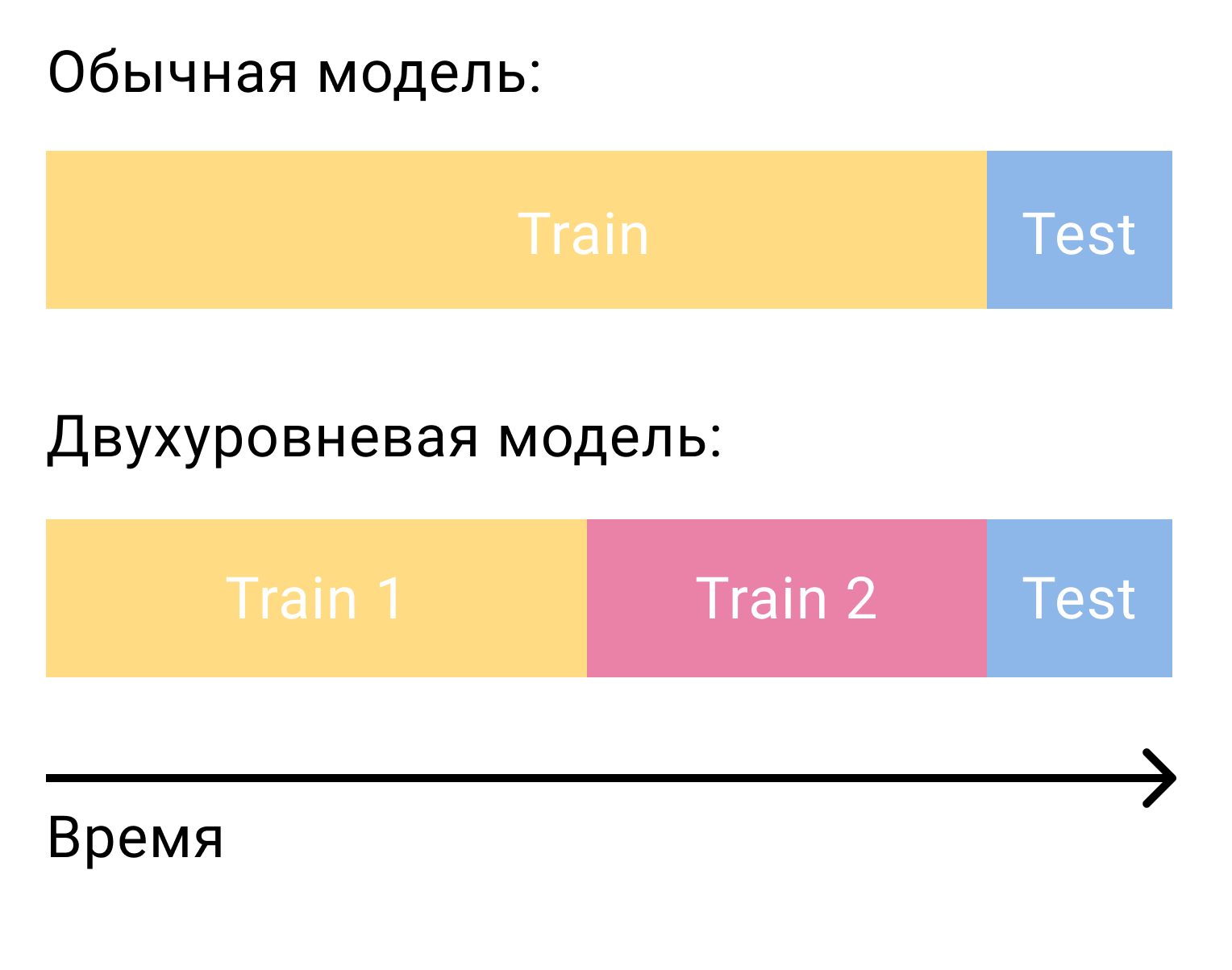
Pada set pelatihan pertama, kami akan melatih model tingkat pertama dan membangun kandidat. Dari kandidat, penting untuk mengecualikan elemen-elemen yang berinteraksi dengan pengguna dalam set ini. Kemudian kita akan melihat kandidat mana yang berinteraksi dengan pengguna di set pelatihan kedua. Kami menyebutnya positif, dan sisanya negatif. Ini akan menjadi set pelatihan kami untuk model konten.
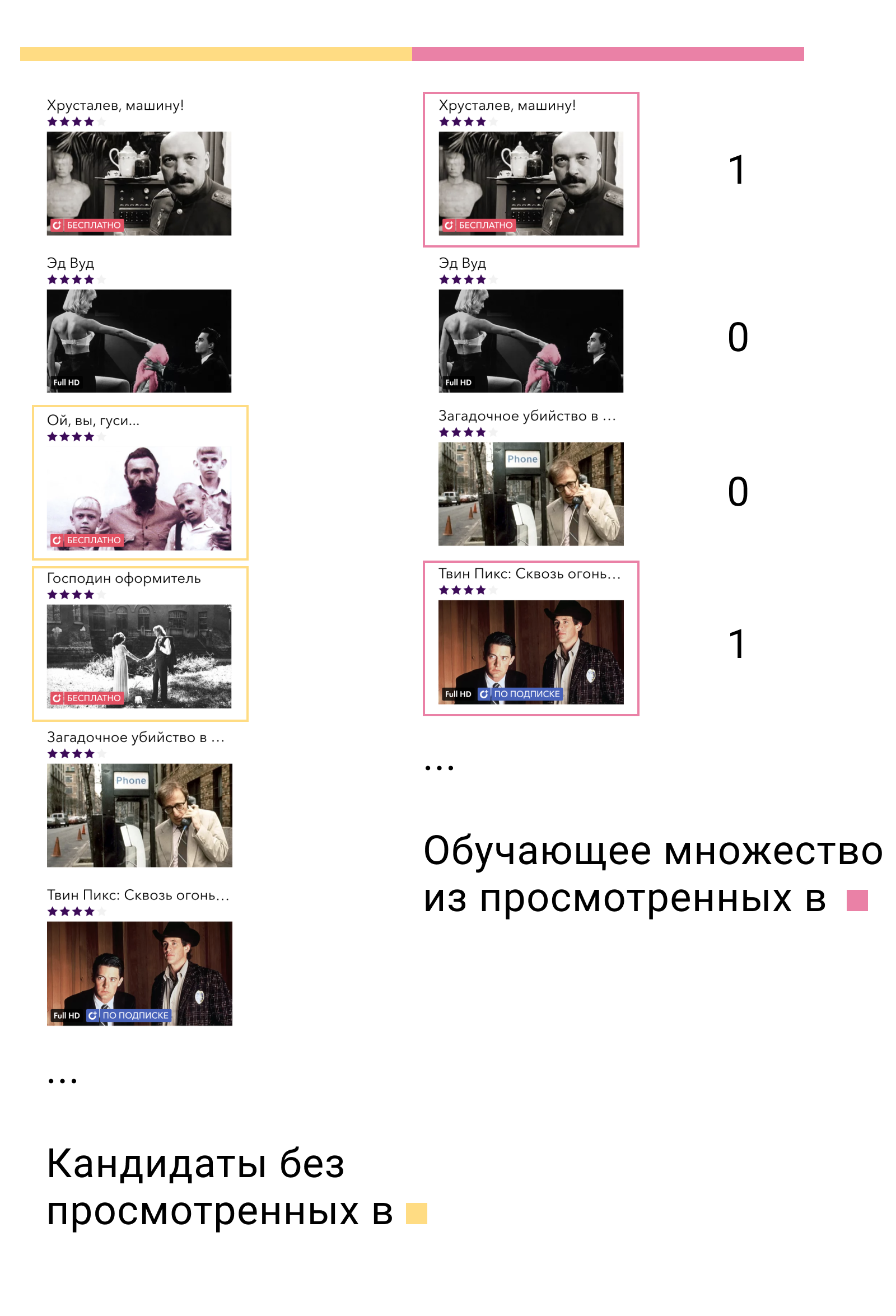
Mengapa ini berhasil? Pertama, kami melatih model tepat pada data yang akan digunakan - output dari model tingkat pertama. Kedua, di antara semua contoh negatif yang mungkin, kami mengambil yang paling kompleks - contoh yang disebut model tingkat pertama relevan bagi pengguna, tetapi tidak.
Apa selanjutnya Solusi paling sederhana dan paling jelas adalah untuk memecahkan masalah klasifikasi biner dan kemudian mengurutkan elemen-elemen dalam urutan probabilitas untuk menjadi contoh positif. Tetapi kita dapat kembali mengingat pernyataan masalah membangun sistem rekomendasi, memahami bahwa klasifikasi biner bukanlah masalah yang sedang kita selesaikan, dan sekali lagi beralih ke masalah peringkat.
Dalam XGBoost dan LightGBM, fungsi kehilangan utama untuk tugas peringkat adalah LambdaMART. Jika Anda tidak merinci, intuisi di baliknya cukup sederhana. Jika - Output model misalnya , maka probabilitas bahwa elemen akan memiliki peringkat lebih tinggi dari elemen akan sama
Fungsi kerugian kemudian dapat ditulis sebagai berikut.
di sini adalah probabilitas peringkat yang sebenarnya. Kami akan mendefinisikannya sebagai 1 jika , 0 jika dan 0,5 dalam kasus ini .
Model dua tingkat memberikan peningkatan metrik 50% dibandingkan dengan model satu tingkat. Fungsi kehilangan peringkat menambah 10% lainnya.
Bonus: film terkait
Ingat, dalam keunggulan pendekatan kami, saya menyebutkan vektor "bebas" dari faktorisasi matriks yang dapat digunakan untuk memecahkan masalah terkait? Jadi, salah satu dari tugas ini - pencarian film serupa - kami putuskan.
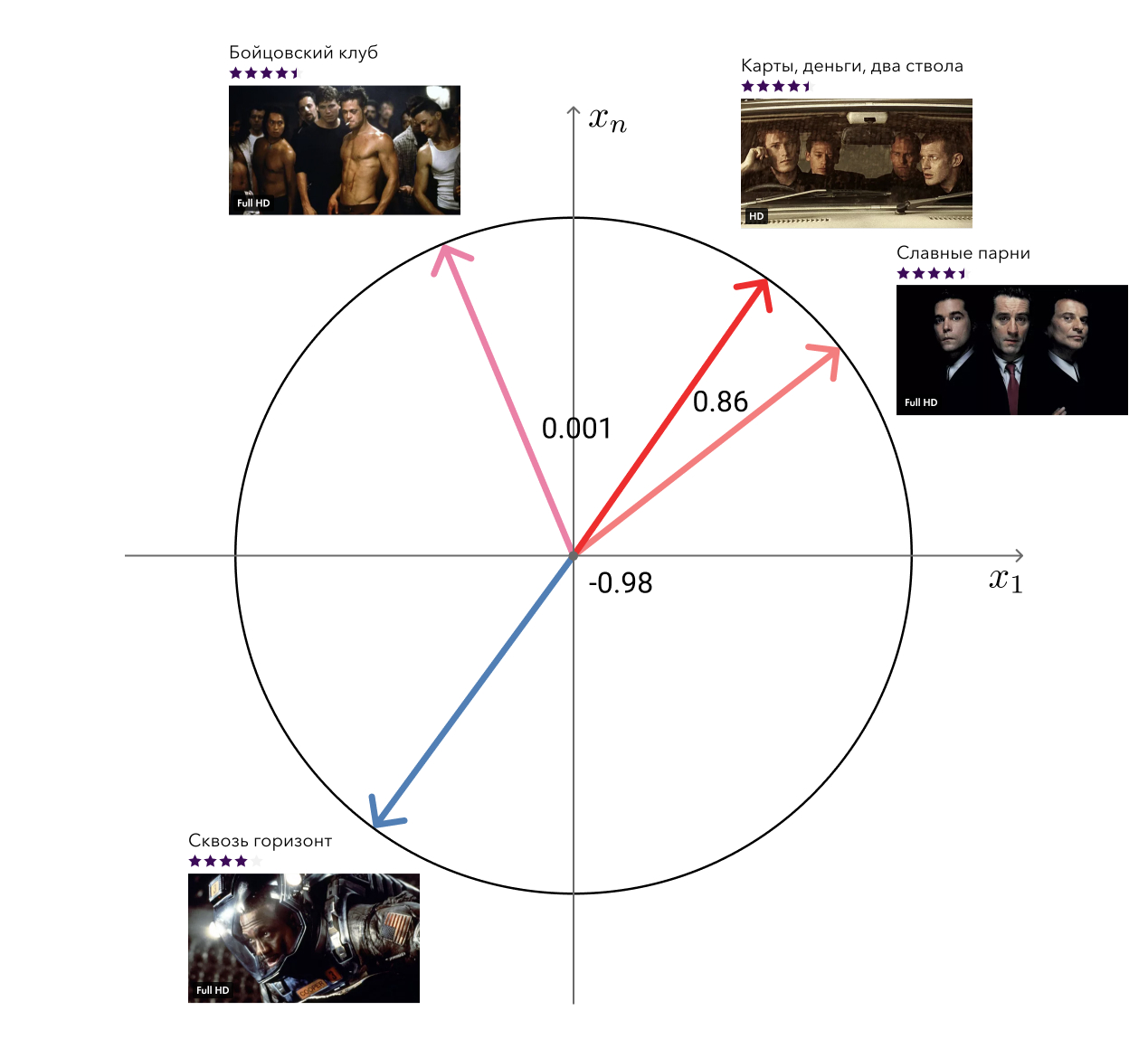
Solusi untuk aib itu sederhana: untuk setiap film, kami mengambil vektornya dan mencari yang terdekat dalam jarak kosinus ke sana. Terlihat cukup memadai untuk mata. Level selanjutnya adalah menambahkan informasi meta dan menggunakan algoritma grafik.

Implementasi teknis
Selain bagian algoritmik, saya ingin berbicara sedikit tentang implementasinya. Rekko terdiri dari tiga komponen: lynch, rekko-task dan rekko-service.
Lynch berjalan pada satu mesin yang kuat, bangun secara berkala, menyiapkan data untuk layanan mikro, dan menempatkannya dalam S3.
Rekko-tugas microservice dan rekko-layanan terletak di lingkungan produk Okko, bersama dengan semua layanan dan database Microsoft lainnya. Yang pertama dari mereka terus-menerus memonitor S3 untuk perubahan, jika ada, mengunduhnya dan menempatkannya di basis grosir. Layanan mikro kedua menggunakan hasil yang dihitung ini untuk menanggapi permintaan pengguna secara real time dan menghitung rekomendasinya.

Layanan Microsoft ditulis dalam Python menggunakan falcon, gunicorn dan gevent dan tidak mewakili sesuatu yang menarik kecuali untuk logika bisnis. Seperti semua layanan microser lainnya dari lingkungan produk Okko, mereka ditutup oleh penyeimbang.
Lynch jauh lebih menarik.
Apa yang perlu dilakukan untuk menghitung porsi rekomendasi selanjutnya untuk pengguna? Setidaknya:
- Unduh data baru yang telah muncul sejak penghitungan ulang terakhir;
- Proses mereka;
- Melatih faktorisasi matriks;
- Bangun kandidat
- Menyusun ulang kandidat;
- Terapkan aturan bisnis
- Bongkar.
Tampaknya itu tidak terdengar menakutkan, Anda dapat menempatkan setiap bagian ke dalam fungsi yang terpisah dan cukup memanggil mereka secara bergantian:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
Ya, semuanya bekerja dengan baik, apakah kita berbeda? Tidak juga. Tetapi bagaimana jika seluruh lembaran jatuh di suatu tempat? Nah, misalnya, karena kekurangan memori. Kami harus memulai kembali semuanya lagi, bahkan jika kami telah menghabiskan beberapa jam melatih model dan membangun kandidat.
Nah, maka mari kita simpan semua hasil antara ke file, dan setelah jatuh, periksa mana yang sudah ada, kembalikan negara dan mulai perhitungan dari saat yang tepat. Bahkan, ide ini bahkan lebih buruk dari yang sebelumnya. Suatu program dapat terganggu di tengah penulisan ke file, dan meskipun ada, itu akan berada dalam keadaan yang salah. Dalam kasus terbaik, seluruh perhitungan akan jatuh, yang terburuk akan berakhir dengan hasil yang salah.
Ok, mari kita menulis ke file atom. Dan kami mengambil setiap fungsi dalam entitas yang terpisah dan menunjukkan dependensi di antara mereka. Hasilnya adalah rangkaian perhitungan, yang masing-masing elemen dapat dilakukan atau tidak.

Sudah tidak buruk. Namun dalam kenyataannya, semua perhitungan yang diperlukan hampir tidak akan dijelaskan oleh daftar. Mempelajari faktorisasi matriks akan membutuhkan tidak hanya data transaksi, tetapi juga peringkat pengguna, membangun kandidat akan memerlukan daftar film yang diingat untuk mengecualikannya, menghitung film yang sama akan membutuhkan faktorisasi matriks yang terlatih dan meta-informasi dari katalog, dan sebagainya. Tugas kami tidak lagi dibangun dalam daftar yang hanya terhubung, tetapi dalam grafik yang diarahkan tanpa siklus (Directed Acyclic Graph, DAG).

DAG adalah organisasi komputasi yang sangat populer. Ada dua kerangka kerja utama untuk membangun DAG: Aliran Udara dan Luigi . Kami di Okko memutuskan yang terakhir. Luigi dikembangkan di Spotify, aktif dikembangkan, sepenuhnya ditulis dalam python, mudah diperluas dan memungkinkan Anda untuk mengatur perhitungan dengan sangat fleksibel.
Tugas dalam Luigi didefinisikan oleh kelas yang mewarisi dari luigi.Task dan mengimplementasikan tiga metode yang diperlukan: requires , output dan run . Seperti inilah tugas tipikal:
Luigi akan memastikan bahwa tugas diselesaikan dalam urutan yang benar tanpa melebihi konsumsi sumber daya yang tersedia. Jika tugas dapat dilakukan secara paralel, itu akan menjalankannya secara paralel, memaksimalkan pemanfaatan CPU dan meminimalkan waktu eksekusi keseluruhan. Jika beberapa tugas gagal, ia akan memulai kembali beberapa kali dan jika terjadi kegagalan akan memberi tahu kami. Dalam hal ini, semua tugas yang dapat dilakukan akan dilakukan. Ini berarti, misalnya, bahwa kesalahan dalam tugas kandidat peringkat tidak menghalangi penghitungan dan pengunggahan daftar film serupa.
Saat ini Lynch terdiri dari 47 tugas unik, menghasilkan sekitar 100 salinannya. Beberapa dari mereka sibuk dengan pekerjaan langsung, beberapa dari mereka menghitung metrik dan mengirimkannya ke alat BI Splunk kami. Lynch juga secara berkala mengirimkan statistik dasar dan laporan tentang pekerjaannya kepada kami melalui telegram. Dia juga menulis tentang kesalahan, tetapi di PM.
Pemantauan, pemisahan dan hasil

Aturan pertama Ilmu Data: Jangan memberi tahu siapa pun tentang gaji dalam Ilmu Data. Aturan kedua Ilmu Data: apa yang tidak dapat diukur tidak dapat diperbaiki.
Kami mencoba untuk melacak semuanya. Pertama-tama, ini, tentu saja, memeringkat metrik pada data historis. Mereka bahkan membantu pada tahap penelitian untuk memilih model terbaik dari beberapa dan memilih parameter hiper untuk itu.
Untuk model yang bekerja di produksi, kami juga mempertimbangkan metrik, tetapi sudah sehari-hari. Metrik semacam itu cukup fluktuatif, tetapi dapat dikatakan oleh mereka jika model tiba-tiba menurun karena alasan tertentu. Saat model baru diluncurkan di prod, Anda dapat membiarkannya diam selama seminggu dan memastikan bahwa metrik tidak melorot. Setelah itu, Anda dapat mengaktifkannya untuk beberapa pengguna, jalankan uji A / B dan pantau metrik bisnis.

Selain itu, kami mempertimbangkan distribusi rekomendasi berdasarkan genre, negara, tahun, jenis, dll. Ini memungkinkan kami untuk memahami sifat preferensi pengguna saat ini, membandingkannya dengan data tampilan nyata dan menangkap kesalahan dalam aturan bisnis.

Penting juga untuk melacak distribusi semua ciri yang digunakan. Perubahan yang tajam di dalamnya dapat disebabkan oleh kesalahan dalam sumber data dan menyebabkan hasil yang tidak terduga.
Tapi, tentu saja, hal terpenting yang perlu diperhatikan adalah metrik bisnis. Sebagai bagian dari sistem rekomendasi, metrik bisnis utama bagi kami adalah:
- Pendapatan dari model konsumsi transaksional dan berlangganan (pendapatan TVOD / SVOD);
- Pendapatan rata-rata per pengunjung (pendapatan rata-rata per pengunjung, ARPV);
- Cek rata-rata (harga rata-rata per pembelian, APPP);
- Pembelian rata-rata per pengguna (APPU);
- Konversi ke pembelian (CR untuk membeli);
- Konversi untuk melihat dengan berlangganan (CR untuk menonton);
- Konversi selama periode uji coba (CR ke uji coba).
Pada saat yang sama, kami melihat secara terpisah pada metrik dari bagian "Rekomendasi" dan "Mirip" dan metrik dari seluruh layanan secara keseluruhan untuk memperhitungkan efek redistribusi dan mempertimbangkan situasi dari sudut yang berbeda.
Ini mungkin terlihat seperti dasbor yang membandingkan beberapa model:

Seperti yang saya katakan di awal, kami membandingkan tidak hanya model satu sama lain, tetapi juga sekelompok pengguna dengan rekomendasi terhadap sekelompok pengguna tanpa rekomendasi. Hal ini memungkinkan kami untuk mengevaluasi efek bersih dari implementasi Rekko dan memahami di mana kami saat ini dan apa margin untuk perbaikan masih tersisa. Menurut tes A / B ini, saat ini kami memiliki:
- ARPV + 3.5%
- ARPV dengan margin + 5%
- APPU + 4,3%
- CR ke percobaan + 2,6%
- CR untuk menonton + 2.5%
- APPP -1%
Film di bioskop online dapat dibagi menjadi dua kelompok: item baru dan konten lama. Kami sudah tahu cara menjual kabar baik. Tujuan utama dari rekomendasi pribadi adalah untuk mendapatkan konten lama yang relevan bagi pengguna dari katalog. Hal ini menyebabkan peningkatan jumlah pembelian dan penurunan cek rata-rata, karena konten seperti itu secara alami lebih murah. Tetapi konten tersebut juga memiliki margin tinggi, yang mengkompensasi penurunan cek dan memberikan peningkatan pendapatan.
Konten berlangganan yang lebih relevan telah menyebabkan peningkatan konversi selama periode uji coba dan dilihat dengan berlangganan.
Tantangan Rekko
Dari 18 Februari hingga 18 April 2019, bersama dengan platform Boosters, kami mengadakan Rekko Challenge, di mana kami mengundang peserta untuk membangun sistem rekomendasi berdasarkan data produk yang dianonimkan.

Diharapkan para peserta yang membangun sistem dua tingkat yang mirip dengan kita ada di puncak. Pemenang yang mengambil tempat pertama dan ketiga berhasil menambah ensemble RNN. Dan peserta dari tempat kedelapan berhasil naik di atasnya hanya menggunakan model penyaringan kolaboratif.
Evgeni Smirnov, yang menempati posisi kedua dalam kompetisi, menulis sebuah artikel di mana ia berbicara tentang keputusannya.
Saat ini, kompetisi tersedia dalam bentuk kotak pasir, sehingga setiap orang yang tertarik dengan sistem rekomendasi dapat mencobanya dan mendapatkan pengalaman yang bermanfaat.
Kesimpulan
Dengan artikel ini, saya ingin menunjukkan kepada Anda bahwa sistem rekomendasi dalam produksi sama sekali tidak sulit, tetapi menyenangkan dan menguntungkan. Hal utama adalah memikirkan tujuan, bukan cara untuk mencapainya dan terus mengukur segalanya.
Dalam artikel mendatang, kami akan memberi tahu Anda lebih banyak tentang dapur interior Okko, jadi jangan lupa untuk berlangganan dan suka.