Halo rekan!
Mungkin judul publikasi hari ini akan terlihat lebih baik dengan tanda tanya - sulit dikatakan. Bagaimanapun, hari ini kami ingin menawarkan tur singkat yang akan memperkenalkan Anda ke perpustakaan
Dask , yang dirancang untuk memparalelkan tugas dengan Python. Kami berharap untuk kembali ke topik ini secara lebih menyeluruh di masa depan.
 Foto diambil di
Foto diambil diDask adalah, tanpa berlebihan, alat pemrosesan data paling revolusioner yang pernah saya temui. Jika Anda suka
Pandas dan Numpy , tetapi kadang-kadang Anda tidak dapat mengatasi data yang tidak sesuai dengan RAM, maka Dask adalah persis apa yang Anda butuhkan. Dask mendukung kerangka data Pandas dan struktur data Numpy (array). Dask dapat dijalankan di komputer lokal atau diskalakan, lalu dijalankan di kluster. Intinya, Anda menulis kode hanya sekali, dan kemudian memilih apakah akan menggunakannya pada mesin lokal atau menyebarkannya dalam sekelompok banyak node menggunakan sintaksis Python paling umum untuk semua ini. Fiturnya sendiri hebat, tetapi saya memutuskan untuk menulis artikel ini hanya untuk menekankan: setiap Ilmuwan Data (setidaknya menggunakan Python) harus menggunakan Dask. Dari sudut pandang saya, keajaiban Dask adalah dengan meminimalkan kodenya, Anda dapat memparalelkannya dengan menggunakan daya komputasi yang sudah tersedia, misalnya di laptop saya. Dengan pemrosesan data paralel, program berjalan lebih cepat, Anda harus menunggu lebih sedikit, dan karenanya, lebih banyak waktu tersisa untuk analitik. Secara khusus, dalam artikel ini kita akan berbicara tentang objek
dask.delayed dan bagaimana hal itu cocok dengan aliran tugas ilmu data.
Memperkenalkan Dask
Sebagai pengantar Dask, berikut adalah beberapa contoh hanya untuk memberi Anda gambaran tentang sintaks yang sepenuhnya tidak mengganggu dan alami. Kesimpulan paling penting yang ingin saya sarankan dalam kasus ini adalah bahwa pengetahuan yang sudah Anda miliki akan cukup untuk bekerja; Anda tidak perlu mempelajari alat data besar baru seperti Hadoop atau Spark.
Dask menawarkan 3 koleksi paralel di mana Anda dapat menyimpan data yang melebihi ukuran RAM, yaitu Dataframe, Bags dan Array. Di setiap jenis koleksi ini, Anda dapat menyimpan data dengan mensegmentasi mereka antara RAM dan hard drive, serta mendistribusikan data di beberapa node dalam sebuah cluster.
Dask DataFrame terdiri dari kerangka data yang diparut, seperti yang ada di Pandas, sehingga memungkinkan Anda untuk menggunakan subset fitur dari sintaks query Pandas. Di bawah ini adalah contoh kode yang mengunduh semua file csv untuk tahun 2018, mem-parsing bidang dengan stempel waktu, dan meluncurkan permintaan Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Contoh Dask DataframeDi Dask Bag, Anda dapat menyimpan dan memproses koleksi objek pythonic yang tidak sesuai dengan memori. Dask Bag sangat bagus untuk memproses log dan koleksi dokumen dalam format json. Dalam contoh kode ini, semua file json untuk 2018 dimuat ke dalam struktur data Dask Bag, setiap catatan json diuraikan, dan data pengguna difilter menggunakan fungsi lambda:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
Contoh Dask BagStruktur data Dask Arrays mendukung irisan Numpy-style. Dalam contoh berikut, satu set data HDF5 dibagi menjadi blok dimensi (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Contoh Dask ArrayPemrosesan Paralel dalam Dask
Judul lain yang sama akuratnya untuk bagian ini adalah "Kematian dari siklus berurutan." Sesekali saya menemukan pola umum: beralih ke daftar elemen, dan kemudian jalankan metode Python dengan setiap elemen, tetapi dengan argumen input yang berbeda. Skenario pemrosesan data yang umum termasuk menghitung agregat fitur untuk setiap klien atau menggabungkan peristiwa dari log untuk setiap siswa. Alih-alih menerapkan fungsi ke setiap argumen dalam loop berurutan, objek Dask Delayed memungkinkan Anda untuk memproses banyak elemen secara paralel. Ketika bekerja dengan Dask Tertunda, semua panggilan fungsi di-antri, dimasukkan ke dalam grafik eksekusi, setelah itu mereka direncanakan untuk diproses.
Saya selalu sedikit malas untuk menulis mesin threading sendiri atau menggunakan asyncio, jadi saya bahkan tidak akan menunjukkan contoh serupa kepada Anda untuk perbandingan. Dengan Dask, Anda tidak dapat mengubah sintaks atau gaya pemrograman! Anda hanya perlu membubuhi keterangan atau membungkus metode, yang akan dieksekusi secara paralel dengan
@dask.delayed dan memanggil metode komputasi setelah kode loop dieksekusi.
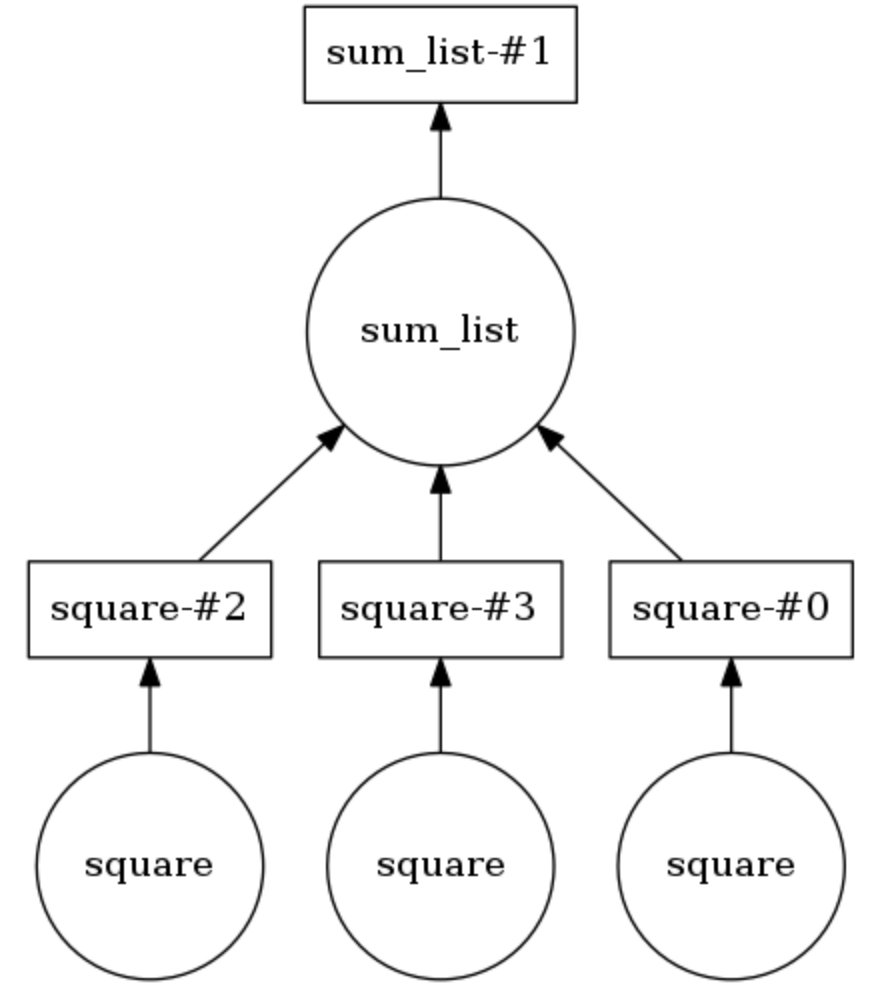
Contoh Grafik Komputasi Dask
Pada contoh di bawah ini, kedua metode tersebut beranotasi
@dask.delayed . Tiga angka disimpan dalam daftar, mereka harus dikuadratkan, dan kemudian dijumlahkan bersama. Dask membangun grafik komputasi yang menyediakan eksekusi paralel dari metode kuadrat, setelah itu hasil operasi ini diteruskan ke metode
sum_list . Grafik komputasi dapat ditampilkan dengan memanggil
calling .visualize() .
Calling .compute() mengeksekusi grafik komputasi. Seperti yang jelas dari
kesimpulan , item daftar diproses bukan dalam urutan, tetapi secara paralel.
Jumlah utas dapat disetel (misalnya,
dask.set_options( pool=ThreadPool(10) ), dan mereka juga dapat dengan mudah ditukar untuk menggunakan proses pada laptop atau PC Anda (mis.
dask.config.set( scheduler='processes' ) .
Jadi, saya menunjukkan betapa sepele akan menambahkan pemrosesan paralel tugas ke proyek dari bidang Ilmu Data menggunakan Dask. Sesaat sebelum menulis artikel ini, saya menggunakan Dask untuk membagi data tentang aliran klik pengguna (riwayat kunjungan) menjadi sesi 40 menit, dan kemudian menggabungkan atribut untuk setiap pengguna untuk pengelompokan lebih lanjut. Beri tahu kami bagaimana Anda menggunakan Dask!