Saya lelah
melihat masa lalu. Ada banyak panduan untuk menciptakan kembali penampilan artefak sejarah, tetapi seringkali kita lupa bahwa ini adalah tindakan kreatif. Mungkin kita terlalu melekat pada layar kita, kita terlalu mementingkan penampilan. Sebagai gantinya, mari kita coba
mendengar sesuatu dari masa lalu.
Literatur yang kaya tentang archaeoacoustics dan lanskap bunyi membantu menciptakan kembali bunyi tempat
itu seperti sebelumnya (misalnya, lihat
Katedral Virtual St. Paul atau
karya Jeff Veitch tentang Ostia kuno ). Tapi saya tertarik untuk "menyuarakan" data itu sendiri. Saya ingin mendefinisikan sintaksis untuk merepresentasikan data dalam bentuk suara sehingga algoritma ini dapat digunakan dalam ilmu sejarah. Drucker mengatakan
ungkapan terkenal bahwa "data" tidak benar-benar apa yang diberikan, melainkan apa yang ditangkap, diubah, yaitu, 'capta'. Saat menyuarakan data, saya benar-benar
mereproduksi masa lalu di masa sekarang. Oleh karena itu, asumsi dan transformasi data ini mengemuka. Suara yang dihasilkan adalah "kinerja cacat" yang membuat Anda mendengar lapisan sejarah modern dengan cara baru.
Saya ingin mendengar makna masa lalu, tetapi saya tahu ini tidak mungkin. Namun, ketika saya mendengar alat musik, saya secara fisik dapat membayangkan musisi; oleh gema dan resonansi saya dapat membedakan ruang fisik. Saya merasakan bass, saya bisa bergerak dengan ritme. Musik menutupi tubuh saya, semua imajinasi saya. Asosiasi dengan suara, musik, dan nada yang sebelumnya didengar menciptakan pengalaman duniawi yang mendalam, suatu sistem hubungan yang diwujudkan antara saya dan masa lalu. Visualitas? Kami telah memiliki representasi visual dari masa lalu begitu lama sehingga tata bahasa ini hampir kehilangan ekspresif artistik dan aspek performatif mereka.
Dalam pelajaran ini, Anda akan belajar cara membuat suara dari data historis.
Pentingnya kebisingan ini, yah ... terserah Anda. Sebagian dari intinya adalah membuat data Anda tidak dikenal lagi. Dengan menerjemahkan, pengodean ulang,
memulihkannya , kami mulai melihat elemen data yang tetap tidak terlihat selama pemeriksaan visual. Deformasi ini konsisten dengan argumen yang dibuat, misalnya, oleh Mark Sample tentang
deformasi masyarakat atau Bethany Nouwiski tentang
"resistensi material .
" Scoring menuntun kita dari data ke "caption", dari ilmu sosial ke seni,
dari kesalahan ke estetika . Mari kita lihat seperti apa.
Isi
Tujuan dan sasaran
Dalam tutorial ini, saya akan membahas tiga cara untuk menghasilkan suara atau musik dari data Anda.
Pertama, kita akan menggunakan sistem Algoritma Musik yang bebas dan terbuka yang dikembangkan oleh Jonathan Middleton. Di dalamnya kita akan berkenalan dengan masalah-masalah dan istilah-istilah kunci. Kemudian kita akan mengambil pustaka Python kecil untuk "menerjemahkan" data ke keyboard 88-kunci dan membawa beberapa kreativitas ke dalam pekerjaan. Terakhir, unggah data ke program pemrosesan suara dan musik Sonic Pi real-time, yang telah menerbitkan banyak tutorial dan sumber referensi.
Anda akan melihat bagaimana bekerja dengan suara memindahkan kita dari visualisasi sederhana ke lingkungan yang sangat efektif.
Alat-alatnya
Sampel data
Pengantar kecil tentang sulih suara
Sonifikasi adalah metode menerjemahkan aspek-aspek data tertentu menjadi sinyal audio. Secara umum, metode dapat disebut "scoring" jika memenuhi kondisi tertentu. Ini termasuk reproduktifitas (peneliti lain dapat memproses data yang sama dengan cara yang sama dan mendapatkan hasil yang sama) dan apa yang bisa disebut "kejelasan" atau "kejelasan," yaitu, ketika elemen signifikan dari data asli secara sistematis tercermin dalam suara yang dihasilkan (lihat
Hermann, 2008 ). Karya
Mark Last dan Anna Usyskina (2015) menjelaskan serangkaian percobaan untuk menentukan tugas analitis yang dapat dilakukan saat mencetak data. Hasil
eksperimen mereka menunjukkan bahwa bahkan siswa yang tidak terlatih (tanpa pelatihan musik formal) dapat membedakan antara data pendengaran dan menarik kesimpulan yang berguna. Mereka menemukan bahwa pendengar dapat melakukan dengan baik tugas-tugas umum penggalian data, seperti klasifikasi dan pengelompokan (dalam percobaan mereka menyiarkan data ilmiah dasar pada skala musik Barat).
Last dan Usyskina fokus pada seri waktu. Menurut temuan mereka, data deret waktu sangat cocok untuk penilaian, karena ada persamaan paralel di sini. Musiknya konsisten, memiliki durasi, dan berkembang seiring waktu; juga dengan data deret waktu (
Terakhir, Usyskina 2015: p. 424 ). Tetap membandingkan data dengan output audio yang sesuai. Untuk mengintegrasikan aspek data dari berbagai pengukuran pendengaran, seperti tinggi, bentuk variasi, dan onset, metode pemetaan parameter digunakan dalam banyak aplikasi. Masalah dengan pendekatan ini adalah bahwa jika tidak ada koneksi sementara (atau, lebih tepatnya, koneksi non-linear) antara titik data sumber, suara yang dihasilkan dapat berubah menjadi "bingung" (
2015: 422 ).
Mengisi bagian yang kosong
Mendengarkan suara, seseorang mengisi saat-saat hening dengan harapannya. Pertimbangkan video di mana mp3 dikonversi ke MIDI dan kembali ke mp3; musik "rata", sehingga semua informasi audio direproduksi dengan satu instrumen (efeknya mirip dengan menyimpan halaman web sebagai .txt, membukanya di Word, dan kemudian menyimpannya lagi dalam format .html). Semua suara (termasuk vokal) diterjemahkan ke dalam nilai nada yang sesuai, dan kemudian kembali ke mp3.
Ini kebisingan, tetapi Anda dapat menangkap intinya:
Apa yang sedang terjadi di sini? Jika lagu ini diketahui oleh Anda, Anda mungkin mengerti "kata-kata" yang sebenarnya. Tetapi lagu itu tidak memiliki kata-kata! Jika Anda belum pernah mendengarnya, maka itu terdengar seperti hiruk-pikuk yang tidak berarti (lebih banyak contoh di
Situs web Andy Bayo). Efek ini kadang-kadang disebut halusinasi pendengaran. Contoh ini menunjukkan bagaimana dalam representasi data apa pun kita dapat mendengar / melihat apa, sebenarnya, bukan. Kami mengisi kekosongan dengan harapan kami sendiri.
Apa artinya ini bagi cerita? Jika kita menyuarakan data kita dan mulai mendengar pola dalam suara atau ledakan aneh, maka harapan budaya kita untuk musik (kenangan fragmen musik yang serupa yang terdengar dalam konteks tertentu) akan mewarnai interpretasi kita. Saya akan mengatakan bahwa ini berlaku untuk semua ide tentang masa lalu, tetapi penilaian sangat berbeda dari metode standar, sehingga kesadaran diri ini membantu mengidentifikasi atau mengungkapkan pola kritis tertentu dalam (data tentang) masa lalu.
Kami akan mempertimbangkan tiga alat untuk mencetak data dan mencatat bagaimana pilihan alat mempengaruhi hasil, dan bagaimana mengatasi masalah ini dengan memikirkan kembali data dalam alat lain. Pada akhirnya, penilaian tidak lebih objektif daripada visualisasi, sehingga peneliti harus siap untuk membenarkan pilihannya dan membuat pilihan ini transparan dan dapat direproduksi. (Agar tidak ada yang akan berpikir bahwa musik yang mencetak dan dihasilkan secara algoritmik adalah sesuatu yang baru, saya mengarahkan pembaca yang tertarik ke
Hedges, 1978 ).
Setiap bagian berisi pengantar konseptual, diikuti dengan panduan menggunakan data arkeologis atau historis.
Algoritma musik
Ada berbagai macam alat untuk menyuarakan data. Misalnya, paket untuk
lingkungan statistik R populer seperti
playitbyR dan
AudiolyzR . Tetapi yang pertama tidak didukung dalam versi R saat ini (pembaruan terakhir adalah beberapa tahun yang lalu), dan untuk membuat yang kedua berfungsi dengan baik, diperlukan konfigurasi serius perangkat lunak tambahan.
Sebaliknya, situs web
Musicalgorithms cukup mudah digunakan, telah beroperasi selama lebih dari sepuluh tahun. Meskipun kode sumber belum dipublikasikan, ini adalah proyek penelitian jangka panjang dalam musik komputasional oleh Jonathan Middleton. Saat ini dalam versi utama ketiga (iterasi sebelumnya tersedia di Internet). Mari kita mulai dengan Musicalalgorithms, karena memungkinkan kita untuk dengan cepat mengunduh dan mengkonfigurasi data kita untuk melepaskan presentasi sebagai file MIDI. Sebelum Anda mulai, pastikan untuk memilih
versi ketiga .
 Situs web Musicalgorithms per 2 Februari 2016
Situs web Musicalgorithms per 2 Februari 2016Algoritma Musik melakukan serangkaian transformasi data. Dalam contoh di bawah ini (secara default di situs) hanya ada satu baris data, meskipun terlihat seperti beberapa baris. Pola ini terdiri dari bidang yang dipisahkan oleh koma, yang dipisahkan secara internal oleh spasi.
# Suara, Nama Area Teks, Data Area Teks
1, morphBox,
, areaPitch1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8
, dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8
, mapArea1.20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78
, dMapArea1.1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1 5
, so_text_area1.20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78
Angka-angka ini mewakili sumber data dan konversi mereka. Berbagi file memungkinkan peneliti lain mengulangi pekerjaan atau melanjutkan pemrosesan dengan alat lain. Jika Anda memulai dari awal, maka Anda hanya perlu sumber data di bawah ini (daftar titik data):
# Suara, Nama Area Teks, Data Area Teks
1, morphBox,
, luas nada 1.24 72 12 84 21 81 14 81 24 81 44 51 94 01 44 51 24 31 5 43 61 04 21 81
Bagi kami, kuncinya adalah bidang 'areaPitch1' dengan data input, yang dipisahkan oleh spasi. Kolom lain akan diisi selama bekerja dengan berbagai pengaturan Algoritma Musik. Dalam data di atas (misalnya, 24 72 12 84, dll.), Nilainya adalah perhitungan awal dari jumlah prasasti di kota-kota Inggris di sepanjang jalan Romawi (nanti kita akan berlatih dengan data lain).
 Setelah memuat data di bilah menu atas, Anda dapat memilih berbagai operasi. Di tangkapan layar, mengarahkan mouse ke informasi menampilkan penjelasan tentang apa yang terjadi ketika Anda memilih operasi divisi untuk skala data ke rentang catatan yang dipilih
Setelah memuat data di bilah menu atas, Anda dapat memilih berbagai operasi. Di tangkapan layar, mengarahkan mouse ke informasi menampilkan penjelasan tentang apa yang terjadi ketika Anda memilih operasi divisi untuk skala data ke rentang catatan yang dipilihSekarang, ketika melihat berbagai tab di antarmuka (durasi, terjemahan tinggi, terjemahan durasi, opsi skala), berbagai transformasi tersedia. Dalam pemetaan nada, ada sejumlah opsi matematis untuk menerjemahkan data ke keyboard piano 88 tombol lengkap (dalam terjemahan linear, nilai
rata -
rata diterjemahkan ke rata-rata C, mis. 40). Anda juga dapat memilih jenis skala: minor atau mayor, dan sebagainya. Pada titik ini, setelah memilih berbagai transformasi, Anda harus menyimpan file teks. Pada tab File → Play, Anda dapat mengunduh file midi. Program audio default Anda harus dapat memutar midi (sering nada piano digunakan secara default). Alat midi yang lebih canggih ditugaskan dalam program mixer seperti GarageBand (Mac) atau
LMMS (Windows, Mac, Linux). Namun, penggunaan GarageBand dan LMMS berada di luar cakupan panduan ini: tutorial video LMMS tersedia di
sini , dan tutorial GarageBand lengkap di Internet. Misalnya,
panduan hebat tentang Lynda.com.
Kebetulan bahwa untuk poin yang sama ada beberapa kolom data. Katakanlah, dalam contoh kami dari Inggris, kami juga ingin menyuarakan perhitungan jenis keramik untuk kota yang sama. Kemudian Anda dapat memuat ulang baris data berikutnya, melakukan transformasi dan perbandingan - dan membuat file MIDI lainnya. Karena GarageBand dan LMMS memungkinkan Anda overlay suara, Anda dapat membuat urutan musik yang rumit.
Cuplikan layar GarageBand, di mana file midi adalah tema yang disuarakan dari buku harian John Adams. Di antarmuka GarageBand (dan LMMS), setiap file midi diseret dengan mouse ke tempat yang sesuai. Toolkit setiap file midi (mis. Trek) dipilih dalam menu GarageBand. Label trek telah diubah untuk mencerminkan kata kunci dalam setiap topik. Area hijau di sebelah kanan adalah visualisasi not pada setiap trek. Anda dapat menonton antarmuka ini beraksi dan mendengarkan musik di siniKonversi apa yang digunakan? Jika Anda memiliki dua kolom data, maka ini adalah dua suara. Mungkin dalam data hipotetis kita, masuk akal untuk mereproduksi suara pertama dengan keras sebagai suara utama: pada akhirnya, prasasti “berbicara” kepada kita dalam beberapa cara (prasasti Romawi secara harfiah merujuk pada orang yang lewat: “Oh, lewat ...”). Dan keramik mungkin merupakan artefak yang lebih sederhana yang dapat dibandingkan dengan ujung skala yang lebih rendah atau menambah durasi nada, yang mencerminkan keberadaannya di antara perwakilan berbagai kelas di wilayah ini.
Tidak ada satu pun cara "benar" untuk menerjemahkan data menjadi suara , setidaknya belum. Tetapi bahkan dalam contoh sederhana ini, kita melihat bagaimana nuansa makna dan interpretasi muncul dalam data dan persepsi mereka.
Tapi bagaimana dengan waktu? Data historis seringkali memiliki tanggal yang mengikat. Oleh karena itu, rentang waktu antara dua titik data harus dipertimbangkan. Di sinilah alat kami selanjutnya menjadi berguna jika titik data terkait satu sama lain dalam ruang waktu. Kami mulai beralih dari penilaian (titik data) ke musik (hubungan antar titik).
Berlatih
Di kolom pertama
set data adalah jumlah koin Romawi dan jumlah bahan lainnya dari kota yang sama. Informasi diambil dari Skema Barang Antik Portabel Museum British. Pemrosesan data ini dapat mengungkapkan beberapa aspek dari situasi ekonomi di sepanjang Watling Street, rute utama melalui Romawi Inggris. Titik data terletak secara geografis dari barat laut ke tenggara; dengan demikian, saat suara bereproduksi, kita mendengar gerakan di ruang angkasa. Setiap not mewakili setiap pemberhentian di jalan.
- Buka sertifikasi-roman-data.csv dalam spreadsheet. Salin kolom pertama ke dalam editor teks. Hapus akhir baris agar semua data berada pada baris yang sama.
- Tambahkan informasi berikut:
# Suara, Nama Area Teks, Data Area Teks
1, morphBox,
, areaPitch1,
... jadi data Anda mengikuti segera setelah koma terakhir (seperti pltcm ). Simpan file dengan nama yang bermakna, misalnya, coinsounds1.csv .
- Pergi ke situs web Musicalgorithms (versi ketiga) dan klik tombol 'Load'. Di jendela sembul, klik tombol biru 'Muat' dan pilih file yang disimpan di langkah sebelumnya. Situs ini akan mengunggah materi Anda dan, jika berhasil, akan menampilkan tanda centang hijau. Jika bukan ini masalahnya, pastikan bahwa nilainya dipisahkan oleh spasi dan segera ikuti koma terakhir dalam blok kode. Anda dapat mencoba mengunduh file demo dari panduan ini .

Setelah mengklik 'Muat', kotak dialog ini muncul di layar utama. Kemudian klik 'Muat File CSV'. Pilih file Anda, itu akan muncul di bidang. Kemudian klik tombol 'Muat' di bagian bawah.
- Klik pada 'Pitch Input' dan Anda akan melihat nilai-nilai data Anda. Jangan pilih opsi tambahan pada halaman ini saat ini (dengan demikian, nilai default berlaku).
- Klik pada 'Input Durasi'. Jangan pilih opsi apa pun di sini . Opsi ini akan membuat berbagai transformasi data Anda dengan perubahan durasi setiap catatan. Sampai Anda khawatir tentang opsi ini, lanjutkan.
- Klik 'Pemetaan Pitch'. Ini adalah pilihan yang paling penting, karena menerjemahkan (mis. Mengukur) data mentah Anda ke tombol keyboard. Biarkan
mapping dalam nilai 'divisi' (parameter lain adalah terjemahan modular atau logaritmik). Parameter Range dari 1 hingga 88 menggunakan seluruh panjang keyboard dari 88 tombol; dengan demikian, nilai terendah akan sesuai dengan nada terdalam pada piano, dan nilai tertinggi ke nada tertinggi. Sebagai gantinya, Anda dapat membatasi musik hingga rentang sekitar C tengah, kemudian masukkan kisaran 25 hingga 60. Outputnya akan berubah sebagai berikut: 31,34,34,34,25,28,30,60,28,25,26,26,25,25,60,25,25,38,33,26,25,25,25 . Ini bukan nomor Anda, tetapi catatan pada keyboard.

Klik di bidang 'Kisaran' dan masukkan 25. Nilai-nilai di bawah ini akan berubah secara otomatis. Di bidang 'ke', atur 60. Jika Anda pergi ke bidang lain, nilainya akan diperbarui
- Klik 'Pemetaan Durasi'. Seperti halnya penerjemahan ketinggian, di sini program mengambil rentang waktu yang ditentukan dan menggunakan berbagai parameter matematika untuk menerjemahkan rentang ini menjadi catatan. Jika Anda mengarahkan kursor ke
i , Anda akan melihat angka mana yang sesuai dengan seluruh catatan, kuartal, kedelapan, dan seterusnya. Biarkan default untuk saat ini.
- Klik pada 'Pilihan Skala'. Di sini kita mulai bekerja dengan apa yang sesuai dengan aspek “emosional”. Biasanya, skala utama dianggap sebagai "gembira," dan minor - sebagai "sedih"; diskusi terperinci tentang topik ini dapat ditemukan di sini . Untuk saat ini, tinggalkan 'skala menurut: utama'. Tinggalkan 'skala' di C.
Jadi, kami mengumumkan satu kolom data! Klik 'Simpan', lalu 'Simpan CSV'.
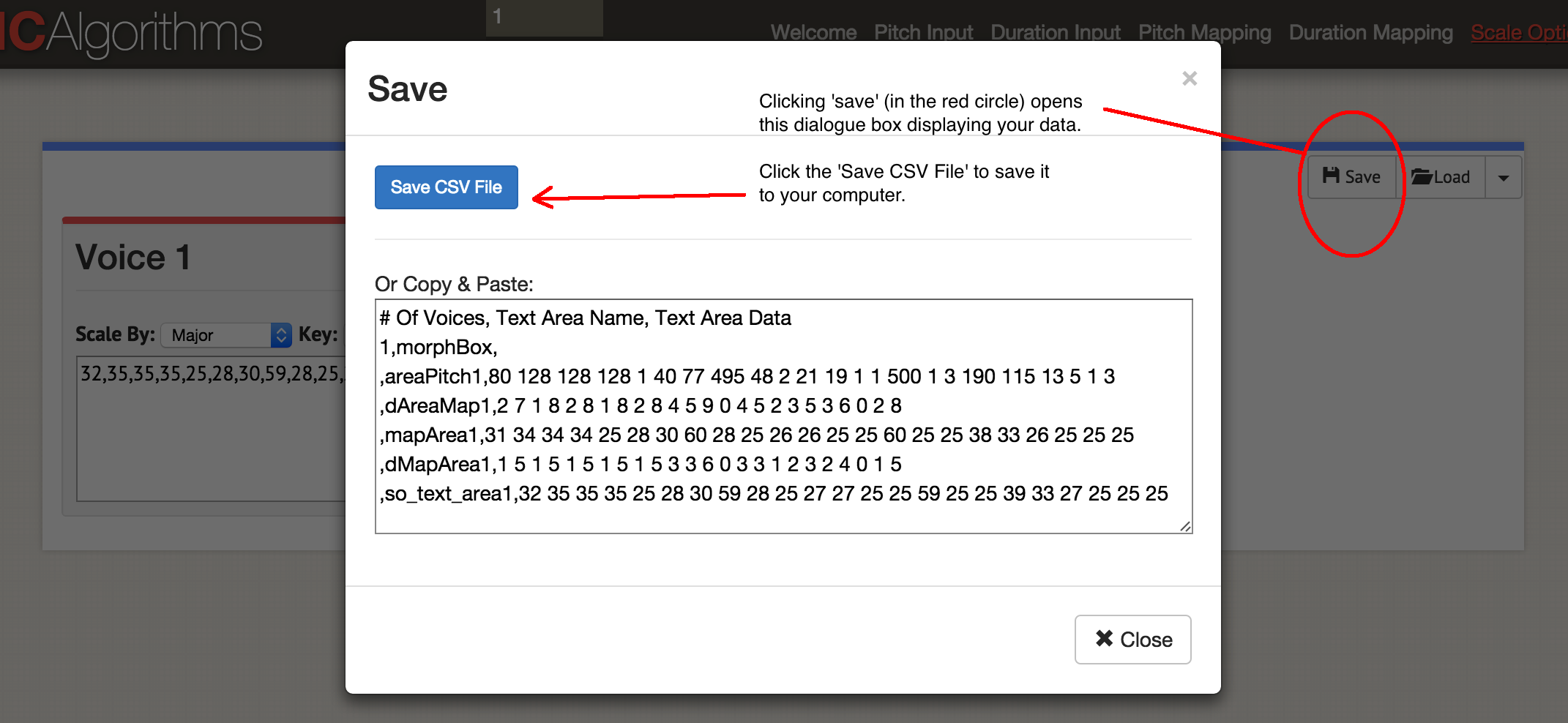 Kotak Dialog 'Simpan'
Kotak Dialog 'Simpan'Anda akan mendapatkan sesuatu seperti file ini:
# Suara, Nama Area Teks, Data Area Teks
1, morphBox,
, luas nada 1,80 128 128 128 128 1 40 77 495 48 2 21 19 1 1 500 1 3 190 115 13 5 1 3
, dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2
, mapArea1.31 34 34 34 25 28 30 60 28 25 26 26 25 25 60 25 25 38 33 26 25 25 25
, dMapArea1.1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1
, so_text_area1.32 35 35 35 25 28 30 59 28 25 27 27 25 25 59 25 25 39 33 27 25 25 25
Data asli tetap di bidang 'areaPitch1', dan kemudian pemetaan yang dibuat melangkah lebih jauh. Situs ini memungkinkan Anda untuk menghasilkan dalam satu file MIDI hingga empat suara sekaligus. Bergantung pada instrumen mana yang ingin Anda gunakan nanti, Anda dapat memilih untuk menghasilkan satu file MIDI sekaligus. Ayo mulai musiknya: klik 'Main'. Di sini Anda memilih langkah dan instrumen. Anda dapat mendengarkan data di browser atau menyimpan sebagai file MIDI dengan tombol biru 'Simpan file MIDI'.
Mari kita kembali ke awal dan memuat kedua kolom data ke dalam templat ini:
# Suara, Nama Area Teks, Data Area Teks
2, morphBox,
, areaPitch1,
, areaPitch2,
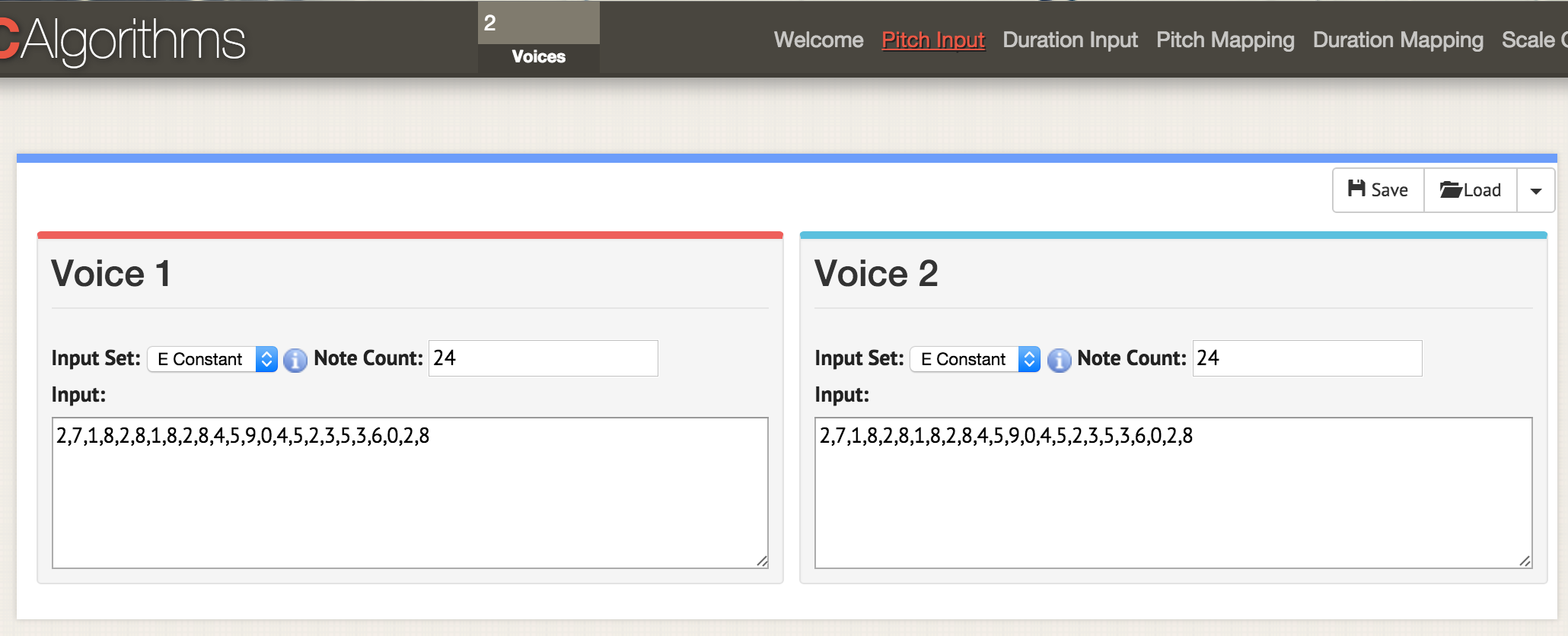 Di sini kita berada di halaman dengan parameter 'input pitch'. Di bagian atas jendela, tentukan dua suara, sekarang di halaman mana saja dengan parameter dua jendela untuk dua suara terbuka. Seperti sebelumnya, kami memuat data dalam format CSV, tetapi file tersebut harus diformat sehingga nilai 'areaPitch1' dan 'areaPitch2' ditunjukkan di sana. Data untuk suara pertama akan muncul di sebelah kiri, dan yang kedua - di sebelah kanan
Di sini kita berada di halaman dengan parameter 'input pitch'. Di bagian atas jendela, tentukan dua suara, sekarang di halaman mana saja dengan parameter dua jendela untuk dua suara terbuka. Seperti sebelumnya, kami memuat data dalam format CSV, tetapi file tersebut harus diformat sehingga nilai 'areaPitch1' dan 'areaPitch2' ditunjukkan di sana. Data untuk suara pertama akan muncul di sebelah kiri, dan yang kedua - di sebelah kananJika kita memiliki beberapa suara, apa yang harus dibawa kedepan? Harap perhatikan bahwa dengan pendekatan ini, pengisi suara kami tidak memperhitungkan jarak antara titik-titik di dunia nyata. Jika Anda pertimbangkan, itu akan sangat mempengaruhi hasilnya. Tentu saja, jarak tidak harus dikaitkan dengan geografi - jarak dapat dikaitkan dengan waktu. Alat berikut akan secara eksplisit menunjukkan faktor ini saat membuat skor.
Setup Python sebentar
Bagian manual ini membutuhkan Python. Jika Anda belum bereksperimen dengan bahasa ini, Anda harus meluangkan waktu untuk
mengenal baris perintah . Lihat juga
panduan instalasi cepat untuk modul .
Python sudah diinstal pada Mac. Anda dapat memeriksa: tekan PERINTAH dan spasi, masukkan
terminal di kotak pencarian dan klik pada aplikasi terminal. Perintah
$ type python —version akan menampilkan versi Python yang telah Anda instal. Pada artikel ini kami bekerja dengan Python 2.7, kode belum diuji dalam Python 3.
Pengguna Windows perlu menginstal Python sendiri: mulai dari
halaman ini , meskipun sedikit lebih rumit daripada yang dikatakannya. Pertama, Anda perlu mengunduh file
.msi (Python 2.7). Jalankan penginstalnya, itu akan diinstal di direktori baru, misalnya,
C:\Python27\ . Maka Anda perlu mendaftarkan direktori ini di paths, yaitu, beri tahu Windows di mana mencari Python ketika Anda menjalankan program Python. Ada beberapa cara untuk melakukan ini. Mungkin cara termudah untuk menemukan
Powershell di komputer Anda (ketik 'powershell' di bilah pencarian Windows). Buka Powershell dan pada prompt perintah, rekatkan keseluruhan ini:
[Lingkungan] :: SetEnvironmentVariable ("Path", "$ env: Path; C: \ Python27 \; C: \ Python27 \ Scripts \", "User") Jika tidak ada yang terjadi dengan menekan Enter, maka perintah telah berfungsi. Untuk memeriksa, buka prompt perintah (berikut adalah
10 cara untuk melakukan ini ) dan masukkan
python --version . Anda akan melihat respons yang menunjukkan
Python 2.7.10 atau versi serupa.
Bagian terakhir dari teka-teki adalah program yang disebut
Pip . Pengguna Mac dapat menginstalnya dengan perintah di terminal
sudo easy_install pip . Pengguna Windows akan memiliki sedikit lebih rumit. Pertama, klik kanan dan simpan file dengan
tautan ini (jika Anda cukup mengeklik tautannya, kode
get-pip.py akan terbuka di browser). Simpan di suatu tempat. Buka prompt perintah di direktori tempat Anda menyimpan
get-pip.py . Kemudian ketik
python get-pip.py di prompt perintah
python get-pip.py .
Ketika Anda memiliki kode Python yang ingin Anda jalankan, rekatkan ke editor teks dan simpan file dengan ekstensi
.py . Ini adalah file teks, tetapi ekstensi file memberitahu komputer untuk menggunakan Python untuk menafsirkannya. Ini diluncurkan dari baris perintah, di mana nama penerjemah ditunjukkan pertama, dan kemudian nama file:
python my-cool-script.py .
MIDITime
MIDITime adalah paket Python yang dikembangkan oleh
Reveal News (sebelumnya bernama Center for Investigative Journalism). Repositori
di Github . MIDITime dirancang khusus untuk memproses deret waktu (yaitu, serangkaian pengamatan yang dikumpulkan dari waktu ke waktu).
Sementara Algoritma Musikal memiliki antarmuka yang kurang lebih intuitif, keuntungan di sini adalah open source. Lebih penting lagi, alat sebelumnya tidak dapat memperhitungkan data dengan memperhitungkan waktu historis akun. MIDITime memungkinkan Anda untuk mengelompokkan informasi tentang faktor ini.
Misalkan kita memiliki buku harian sejarah dimana
model tematik telah diterapkan. Output yang dihasilkan dapat berisi entri buku harian dalam bentuk baris, dan di kolom akan ada persentase kontribusi dari setiap topik. Dalam hal ini,
mendengarkan nilai
- nilai akan membantu untuk memahami pola berpikir seperti itu dari buku harian yang tidak mungkin disampaikan dalam bentuk grafik. Mendengar ledakan yang langsung terlihat atau mengulang pola musik yang tidak terlihat pada grafik.
Mengatur MIDITime
Instalasi dengan satu perintah
pip :
$ pip install miditime
untuk bunga poppy;
$ sudo pip install miditime
di bawah Linux;
> python pip install miditime
di bawah Windows (jika instruksi tidak berhasil, Anda dapat mencoba
utilitas ini untuk menginstal Pip).
Berlatih
Pertimbangkan skrip contoh. Buka editor teks, salin dan tempel kode ini:
Simpan skrip sebagai
music1.py . Di terminal atau baris perintah, jalankan:
$ python music1.py
File
myfile.mid baru akan dibuat di
myfile.mid . Anda dapat membukanya untuk mendengarkan menggunakan Quicktime atau Windows Media Player (dan menambahkan alat di GarageBand atau
LMMS ).
Music1.py mengimpor miditime (ingat untuk menginstalnya sebelum menjalankan skrip:
pip install miditime ). Kemudian tentukan langkahnya. Semua catatan dicantumkan secara terpisah, di mana angka pertama adalah waktu mulai pemutaran, tingginya (yaitu, catatan itu sendiri!), Seberapa kuat atau irama catatan dimainkan (serangan) dan durasinya. Kemudian catatan direkam di trek, dan trek itu sendiri dicatat dalam file
myfile.mid .
Mainkan dengan skrip, tambahkan lebih banyak catatan. Berikut adalah catatan untuk lagu 'Baa Baa Black Sheep':
D, D, A, A, B, B, B, B, A
Baa, Baa, hitam, domba, punya, Anda, wol?
Bisakah Anda menulis instruksi agar komputer memainkan melodi (di sini adalah
diagram untuk membantu)?
Ngomong-ngomong . Ada format file teks khusus untuk menggambarkan musik yang disebut
Notasi ABC . Ini di luar ruang lingkup artikel ini, tetapi Anda dapat menulis skrip untuk mencetak, misalnya, dalam spreadsheet, membandingkan nilai catatan dalam notasi ABC (jika Anda pernah menggunakan konstruksi IF - THEN di Excel, Anda punya ide bagaimana melakukan ini), dan kemudian melalui situs
- situs
seperti ini, notasi ABC dikonversi menjadi file .mid.
Mengunggah Data Anda Sendiri
File ini berisi contoh model tema buku harian John Adams untuk situs web
Macroscope . Hanya sinyal terkuat yang tersisa di sini, membulatkan nilai dalam kolom ke dua tempat desimal. Untuk memasukkan data ini ke dalam skrip Python, Anda perlu memformatnya dengan cara khusus. Yang paling sulit adalah dengan bidang tanggal.
Untuk tutorial ini, mari kita biarkan nama variabel dan sisanya tidak berubah dari skrip contoh. Contoh dirancang untuk memproses data gempa bumi; oleh karena itu, di sini "besarnya" dapat direpresentasikan sebagai "kontribusi kita terhadap topik." my_data = [
{'event_date': <datetime object>, 'magnitude': 3.4},
{'event_date': <datetime object>, 'magnitude': 3.2},
{'event_date': <datetime object>, 'magnitude': 3.6},
{'event_date': <datetime object>, 'magnitude': 3.0},
{'event_date': <datetime object>, 'magnitude': 5.6},
{'event_date': <datetime object>, 'magnitude': 4.0}
] Ekspresi reguler dapat digunakan untuk memformat data, dan bahkan lebih mudah - spreadsheet. Salin elemen dengan nilai kontribusi tema ke lembar baru dan biarkan kolom kiri dan kanan. Dalam contoh di bawah ini, saya letakkan di kolom D dan kemudian diisi sisanya:
Kemudian salin dan tempel elemen yang tidak dapat diubah, isi seluruh kolom. Item dengan tanggal harus dalam format (tahun, bulan, hari). Setelah mengisi tabel, Anda dapat menyalin dan menempelkannya ke editor teks, menjadikannya bagian dari array
my_data , misalnya:
my_data = [
{'event_date': datetime (1753,6,8), 'magnitude': 0,0024499630},
{'event_date': datetime (1753,6,9), 'magnitude': 0,0035766320},
{'event_date': datetime (1753,6,10), 'magnitude': 0,0022171550},
{'event_date': datetime (1753,6,11), 'magnitude': 0,0033220150},
{'event_date': datetime (1753,6,12), 'magnitude': 0,0046445900},
{'event_date': datetime (1753,6,13), 'magnitude': 0,0035766320},
{'event_date': datetime (1753,6,14), 'magnitude': 0,0042241550}
] Perhatikan bahwa tidak ada koma di akhir baris terakhir.
Script terakhir akan terlihat seperti ini jika Anda menggunakan contoh dari halaman Miditime itu sendiri (potongan kode di bawah ini terputus oleh komentar, tetapi mereka harus dimasukkan bersama sebagai satu file dalam editor teks):
from miditime.MIDITime import MIDITime from datetime import datetime import random mymidi = MIDITime(108, 'johnadams1.mid', 3, 4, 1)
Nilai setelah MIDITime ditetapkan sebagai
MIDITime(108, 'johnadams1.mid', 3, 4, 1) , di sini:
- jumlah denyut per menit (108),
- file keluaran ('johnadams1.mid'),
- jumlah detik dalam musik untuk mewakili satu tahun dalam sejarah (3 detik per tahun kalender, sehingga entri buku harian selama 50 tahun diskalakan ke melodi 50 × 3 detik, yaitu, dua setengah menit),
- oktaf dasar untuk musik (rata-rata C biasanya direpresentasikan sebagai C5, jadi di sini 4 sesuai dengan satu oktaf lebih rendah dari referensi),
- dan jumlah oktaf untuk membandingkan ketinggian.
Sekarang kami meneruskan data ke skrip dengan memuatnya ke dalam array
my_data :
my_data = [ {'event_date': datetime(1753,6,8), 'magnitude':0.0024499630}, {'event_date': datetime(1753,6,9), 'magnitude':0.0035766320},
... di sini kita memasukkan semua data dan jangan lupa untuk
menghapus koma di akhir baris terakhir dari
event_date , dan setelah data meletakkan braket akhir pada baris yang terpisah:
{'event_date': datetime(1753,6,14), 'magnitude':0.0042241550} ]
lalu masukkan waktunya:
my_data_epoched = [{'days_since_epoch': mymidi.days_since_epoch(d['event_date']), 'magnitude': d['magnitude']} for d in my_data] my_data_timed = [{'beat': mymidi.beat(d['days_since_epoch']), 'magnitude': d['magnitude']} for d in my_data_epoched] start_time = my_data_timed[0]['beat']
Kode ini mengatur waktu antara entri buku harian yang berbeda; jika entri buku harian dekat satu sama lain dalam waktu, maka catatan yang sesuai juga akan lebih dekat. Akhirnya, kami menentukan bagaimana data dibandingkan dengan ketinggian. Nilai awal ditunjukkan sebagai persentase dalam rentang dari 0,01 (mis. 1%) hingga 0,99 (99%), jadi kami menetapkan
scale_pct antara 0 dan 1. Jika kami tidak memiliki persentase, maka kami menggunakan yang terendah dan tertinggi nilai-nilai. Jadi, kami menyisipkan kode berikut:
def mag_to_pitch_tuned(magnitude): scale_pct = mymidi.linear_scale_pct(0, 1, magnitude)
dan fragmen terakhir untuk menyimpan data ke file:
Simpan file ini dengan nama baru dan ekstensi
.py .
Untuk setiap kolom dalam sumber data kami membuat skrip unik dan jangan lupa
untuk mengubah nama file output ! Anda kemudian dapat mengunggah file midi individual ke GarageBand atau LMMS untuk instrumentasi. Ini
buku harian lengkap
John Adams .
Pi sonik
Memproses midi unik di GarageBand atau editor musik lain berarti pindah dari sulih suara sederhana menjadi seni musik. Bagian akhir artikel ini bukan panduan lengkap untuk menggunakan
Sonic Pi , melainkan pengantar lingkungan yang memungkinkan pengodean dan pemutaran data waktu nyata dalam bentuk musik (lihat
video untuk contoh pengodean dengan
pemutaran waktu nyata). Tutorial yang ada di dalam program akan menunjukkan cara menggunakan komputer sebagai alat musik (Anda memasukkan kode Ruby ke editor bawaan, dan penerjemah segera memainkan hasilnya).
Mengapa ini dibutuhkan? Seperti yang dapat Anda pahami dari panduan ini, saat Anda membaca data, Anda mulai membuat keputusan tentang bagaimana menerjemahkan data menjadi suara. Keputusan-keputusan ini mencerminkan keputusan implisit atau eksplisit tentang data apa yang penting. Ada kontinum "objektivitas," jika Anda suka. Di satu sisi, data historis yang disuarakan, di sisi lain - gagasan tentang masa lalu, sama menarik dan pribadinya dengan kuliah umum yang dibuat dengan baik. Sounding memungkinkan Anda untuk benar-benar mendengar data yang disimpan dalam dokumen: ini adalah semacam sejarah publik. Pertunjukan musikal dari data kami ... bayangkan saja!
Di sini saya mengusulkan potongan kode untuk mengimpor data, yang hanya daftar nilai yang disimpan sebagai csv. Terima kasih kepada pustakawan Universitas George Washington Laura Vrubel, yang mengunggah eksperimennya tentang operasi perpustakaan yang terdengar ke
gist.github.com .
Ada dua tema dalam
sampel ini (model tematik yang dihasilkan dari
Hubungan Jesuit ). Di baris pertama, tajuknya adalah 'topic1' dan 'topic2'.
Berlatih
Ikuti tutorial Sonic Pi bawaan hingga Anda terbiasa dengan antarmuka dan fitur-fiturnya (semua tutorial ini dikompilasi di
sini ; Anda juga dapat mendengarkan
wawancara dengan Sam Aaron, pencipta Sonic Pi). Kemudian salin kode berikut ke buffer baru (jendela editor) (sekali lagi, fragmen terpisah harus dikumpulkan dalam satu skrip):
require 'csv' data = CSV.parse(File.read("/path/to/your/directory/data.csv"), {:headers => true, :header_converters => :symbol}) use_bpm 100
Ingat bahwa
path/to/your/directory/ adalah lokasi sebenarnya dari data Anda di komputer. Pastikan file tersebut benar-benar disebut
data.csv , atau edit baris ini dalam kode.
Sekarang muat data ini ke komposisi musik:
Beberapa baris pertama memuat kolom data; kemudian kami menunjukkan sampel suara mana yang ingin kami gunakan (piano), dan kemudian menunjukkan untuk memainkan topik pertama (topik1) sesuai dengan kriteria yang ditentukan: untuk kekuatan nada (serangan), nilai acak kurang dari 0,5 dipilih; untuk pembusukan - nilai acak kurang dari 1; untuk amplitudo, nilai acak kurang dari 0,25.
Lihat garis dikalikan seratus (
*100 )? Dibutuhkan nilai data kami (desimal) dan mengubahnya menjadi bilangan bulat. Dalam fragmen ini, angkanya langsung disamakan dengan catatan. Jika nada terendah adalah 88 dan yang tertinggi adalah 1, maka pendekatan ini agak bermasalah: kita sebenarnya tidak menampilkan nada apa pun di sini! Dalam hal ini, Anda dapat menggunakan Musicalgorithms untuk menampilkan ketinggian, dan kemudian meneruskan nilai-nilai ini kembali ke Sonic Pi. Selain itu, karena kode ini kurang lebih merupakan Ruby standar, Anda dapat menggunakan metode normalisasi data, dan kemudian melakukan perbandingan linear dari nilai Anda dengan kisaran 1–88. Sebagai permulaan, senang melihat
karya Steve Lloyd tentang menyuarakan data cuaca dengan Sonic Pi.
Dan hal terakhir yang perlu diperhatikan di sini: nilai 'rand' (acak) memungkinkan Anda untuk menambahkan sedikit "kemanusiaan" ke musik dalam hal dinamika. Kami melakukan hal yang sama untuk 'topic2'.
Anda juga dapat menentukan ritme (denyut per menit), loop, sampel, dan efek lain yang didukung Sonic Pi. Lokasi kode mempengaruhi pemutaran: misalnya, jika ditempatkan di depan blok data di atas, ia akan diputar terlebih dahulu. Misalnya, jika Anda use_bpm 100memasukkan yang berikut setelah baris :
... Anda mendapatkan sedikit pengantar musik. Program menunggu 2 detik, memainkan sampel 'ambi_choir', lalu menunggu 6 detik sebelum mulai memutar data kami. Jika Anda ingin menambahkan sedikit drum yang tidak menyenangkan di seluruh melodi, letakkan bit ini berikutnya (di depan data Anda sendiri):
Kode ini cukup mudah: sampel loop 'bd_boom' dengan efek suara reverb pada kecepatan tertentu. Jeda antar siklus adalah 2 detik.Adapun "pengkodean waktu nyata," ini berarti Anda dapat membuat perubahan pada kode sambil memutar ulang perubahan itu . Tidak suka apa yang Anda dengar? Ubah kode segera!Menjelajahi Sonic Pi dapat dimulai dengan lokakarya ini . Lihat juga laporan Laura Vrubel tentang menghadiri seminar, yang juga menggambarkan pekerjaannya di bidang ini dan karya rekan-rekannya.Tidak ada yang baru di bawah matahari
Dan lagi saya ulangi: tidak perlu berpikir bahwa kita, dengan pendekatan algoritmik kita, berada di garis depan ilmu pengetahuan. Pada tahun 1978, sebuah artikel ilmiah diterbitkan pada "permainan dadu musik" abad ke-18, di mana gulungan dadu menentukan rekombinasi musik yang ditulis sebelumnya. Robin Newman mempelajari dan mengkodekan beberapa game ini untuk Sonic Pi . Untuk notasi musik, Newman menggunakan alat yang dapat digambarkan sebagai Markdown + Pandoc, dan untuk mengkonversi ke catatan, Lilypond . Jadi semua topik di blog The Programming Historian kami memiliki sejarah panjang!Kesimpulan
Saat menyuarakan, kami melihat bahwa data kami sering kali tidak mencerminkan cerita sebagai interpretasinya dalam kinerja kami. Ini sebagian karena kebaruan dan sifat artistik yang diperlukan untuk menerjemahkan data menjadi suara. Tetapi ini sangat membedakan interpretasi suara dari visualisasi tradisional. Mungkin suara yang dihasilkan tidak akan pernah naik ke level "musik"; tetapi jika mereka membantu mengubah pemahaman kita tentang masa lalu dan memengaruhi orang lain, maka upaya itu sepadan. Seperti yang Trevor Owens katakan, "Terdengar adalah penemuan yang baru, bukan justifikasi dari yang diketahui ."Ketentuan
- MIDI : . , ( ). . MIDI- , .
- MP3 : , .
- : ( C . .)
- :
- : ( , , . .)
- :
- Amplitudo : secara kasar, perhatikan volume