Pendahuluan
Perhatian, ini bukan artikel "Hello world" lainnya tentang cara mengedipkan LED atau memasuki interupsi pertama pada STM32. Namun, saya mencoba untuk memberikan penjelasan komprehensif tentang semua masalah yang diangkat, sehingga artikel ini akan bermanfaat tidak hanya bagi banyak profesional dan bermimpi menjadi pengembang seperti itu (seperti yang saya harapkan), tetapi juga untuk pemrogram mikrokontroler pemula, karena topik ini karena beberapa alasan beredar di banyak situs / blog "guru pemrograman MK."
Mengapa saya memutuskan untuk menulis ini?
Meskipun saya melebih-lebihkan, setelah mengatakan sebelumnya bahwa bit banding perangkat keras keluarga Cortex-M tidak dijelaskan pada sumber daya khusus, masih ada tempat-tempat di mana fitur ini dibahas (dan bahkan bertemu satu artikel di sini), tetapi topik ini jelas perlu ditambah dan dimodernisasi. Saya perhatikan bahwa ini juga berlaku untuk sumber daya berbahasa Inggris. Di bagian selanjutnya, saya akan menjelaskan mengapa fitur kernel ini bisa sangat penting.
Teori
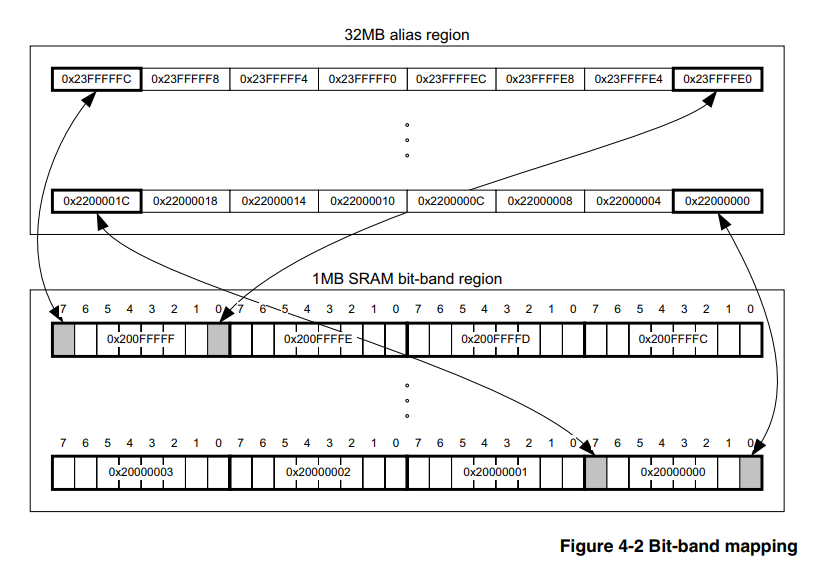
(dan mereka yang mengenalnya bisa langsung berlatih)Hardware bit banding adalah fitur dari inti itu sendiri, dan oleh karena itu tidak tergantung pada keluarga dan perusahaan pembuat mikrokontroler, hal utama adalah bahwa inti tersebut cocok. Dalam kasus kami, biarlah Cortex-M3. Oleh karena itu, informasi tentang masalah ini harus dicari dalam dokumen resmi tentang inti itu sendiri, dan ada dokumen seperti
itu ,
ini dia , bagian 4.2 menjelaskan secara rinci bagaimana menggunakan alat ini.
Di sini saya ingin membuat penyimpangan teknis kecil untuk programmer yang tidak terbiasa dengan assembler, yang mayoritasnya sekarang, karena kompleksitas propagandized dan tidak berguna assembler untuk mikrokontroler 32-bit "serius" seperti STM32, LPC, dll. Selain itu, kita sering dapat menghadapi upaya kecaman untuk penggunaan assembler di daerah ini, bahkan pada Habr. Pada bagian ini saya ingin menjelaskan secara singkat mekanisme penulisan ke memori MK, yang seharusnya menjelaskan keunggulan bit banding.
Saya akan menjelaskan contoh sederhana spesifik untuk sebagian besar STM32. Misalkan saya perlu mengubah PB0 menjadi output untuk keperluan umum. Solusi khas akan terlihat seperti ini:
GPIOB->MODER |= GPIO_MODER_MODER0_0;
Jelas, kami menggunakan bitwise "OR" agar tidak menimpa bit register yang tersisa.
Untuk kompiler, ini diterjemahkan ke dalam 4 instruksi berikut:
- Unduh GPIOB-> MODER ke register tujuan umum (RON)
- Unggah nilai ke RON lain di alamat yang ditunjukkan di RON dari p1.
- Buat bitwise ATAU dari nilai ini dengan GPIO_MODER_MODER0_0.
- Unduh hasilnya kembali ke GPIOB-> MODER.
Juga, orang tidak boleh lupa bahwa kernel ini menggunakan set instruksi thumb2, yang berarti bahwa mereka dapat berbeda dalam volume. Saya juga mencatat bahwa di mana-mana kita berbicara tentang tingkat optimasi O3.
Dalam bahasa assembly, tampilannya seperti ini:

Dapat dilihat bahwa instruksi pertama adalah tidak lebih dari instruksi semu dengan offset, kami menemukan alamat register di alamat PC (diberi ban berjalan) + 0x58.
Ternyata kami memiliki 4 langkah (dan lebih banyak siklus clock) dan 14 byte memori yang digunakan per operasi.
Jika Anda ingin tahu lebih banyak tentang ini, maka saya merekomendasikan buku [2], omong-omong, ada juga dalam bahasa Rusia.
Kami meneruskan ke metode bit_banding.
Intinya, menurut petani, adalah bahwa prosesor memiliki area memori yang dialokasikan khusus, menulis nilai-nilai di mana kita tidak mengubah bit lain dari register periferal atau RAM. Artinya, kita tidak perlu memenuhi poin 2) dan 3) yang dijelaskan di atas, dan untuk ini cukup dengan hanya menceritakan alamat sesuai dengan rumus dari [1].

Kami mencoba melakukan operasi serupa, assemblernya:

Alamat yang dihitung ulang:

Di sini kami menambahkan instruksi tulis # 1 di RON, tetapi bagaimanapun, hasilnya adalah 10 byte, bukan 14, dan beberapa siklus clock lebih sedikit.
Tetapi bagaimana jika perbedaannya konyol?
Di satu sisi, penghematan tidak signifikan, terutama dalam siklus ketika sudah menjadi kebiasaan overclocking controller ke 168 MHz. Dalam proyek rata-rata, saat-saat di mana Anda dapat menerapkan metode ini masing-masing adalah 40 - 80, dalam byte penghematan dapat mencapai 250 byte jika alamatnya berbeda. Dan jika kita menganggap bahwa pemrograman MK secara langsung pada register sekarang dianggap sebagai "zashkvar", dan "keren" untuk menggunakan segala macam dadu-kubus, maka penghematannya bisa lebih banyak.
Juga, angka 250 byte terdistorsi oleh fakta bahwa perpustakaan tingkat tinggi secara aktif digunakan dalam komunitas, firmware mengembang hingga ukuran tidak senonoh. Ketika pemrograman pada level rendah, ini setidaknya 2 - 5% dari volume perangkat lunak untuk proyek rata-rata, dengan arsitektur yang kompeten dan optimalisasi O3.
Sekali lagi, saya tidak ingin mengatakan bahwa ini adalah semacam alat keren super-duper-mega yang harus digunakan oleh setiap programmer MK yang menghargai diri sendiri. Tetapi jika saya dapat memotong biaya bahkan dengan sebagian kecil, lalu mengapa tidak?Implementasi
Semua opsi hanya akan diberikan untuk mengkonfigurasi periferal, karena saya tidak menemukan situasi di mana akan diperlukan untuk RAM. Tegasnya, untuk RAM, rumusnya mirip, cukup ganti alamat dasar untuk perhitungan. Jadi bagaimana Anda menerapkan ini?
Assembler
Mari kita pergi dari bawah, dari Assembler tercinta.
Pada proyek assembler, saya biasanya mengalokasikan beberapa 2-byte (sesuai dengan instruksi yang bekerja dengan mereka) RON di bawah # 0 dan # 1 untuk seluruh proyek, dan menggunakannya juga dalam makro, yang mengurangi saya 2 byte lagi secara berkelanjutan. Catatan, saya tidak menemukan CMSIS di Assembler untuk STM, karena saya langsung memasukkan nomor bit di makro, dan bukan nilai registernya.
Implementasi untuk GNU Assembler @ . MOVW R0, 0x0000 MOVW R1, 0x0001 @ .macro PeriphBitSet PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4)) STR R1, [R3] .endm @ .macro PeriphBitReset PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4)) STR R0, [R3] .endm
Contoh:
Contoh Assembler PeriphSet TIM2_CCR2, 0 PeriphBitReset USART1_SR, 5
Keuntungan yang tidak diragukan dari opsi ini adalah bahwa kami memiliki kontrol penuh, yang tidak dapat dikatakan tentang opsi lebih lanjut. Dan seperti yang akan ditunjukkan bagian terakhir artikel ini, plus yang ini
sangat penting.
Namun, tidak ada yang membutuhkan proyek untuk MK di Assembler, dari sekitar akhir nol, yang berarti Anda harus beralih ke SI.
Biasa c
Jujur, opsi Sishny sederhana ditemukan oleh saya di awal jalan, di suatu tempat di jaringan yang luas. Pada saat itu, saya sudah menerapkan bit banding di Assembler, dan secara tidak sengaja menemukan file C, itu segera bekerja dan saya memutuskan untuk tidak menciptakan apa pun.
Implementasi untuk C polos #define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0 #define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A) #define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A) #define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A) #define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A) #define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A) #define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A) #define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A) #define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A) #define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A) #define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A) #define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A) #define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A) #define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A) #define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A) #define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A) #define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A) #define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A) #define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A) #define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A) #define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A) #define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A) #define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A) #define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A) #define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A) #define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A) #define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A) #define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A) #define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A) #define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A) #define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A) #define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A) #define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
Seperti yang Anda lihat, sepotong kode yang sangat sederhana dan langsung ditulis dalam bahasa prosesor. Pekerjaan utama di sini adalah terjemahan nilai-nilai CMSIS ke dalam bit number, yang tidak ada sebagai kebutuhan untuk versi assembler.
Oh ya, gunakan opsi ini seperti ini:
Contoh untuk plain C BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0;
Namun, tren modern (secara besar-besaran, menurut pengamatan saya, sekitar tahun 2015) lebih suka mengganti C dengan C ++ bahkan untuk MK. Dan makro bukan alat yang paling dapat diandalkan, jadi versi berikutnya ditakdirkan untuk dilahirkan.
Cpp03
Di sini, yang sangat menarik dan didiskusikan, tetapi sedikit digunakan mengingat kompleksitasnya, dengan satu contoh basi dari faktorial muncul, alat ini metaprogramming.
Lagi pula, tugas menerjemahkan nilai variabel ke dalam bit number ideal (sudah ada nilai dalam CMSIS), dan dalam hal ini praktis untuk waktu kompilasi.
Saya menerapkan ini sebagai berikut menggunakan template:
Implementasi untuk C ++ 03 template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value { enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num }; }; template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)> { enum { bit_num = 31 }; }; #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
Anda dapat menggunakannya dengan cara yang sama:
Contoh untuk C ++ 03 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false;
Dan mengapa makro kiri? Faktanya adalah bahwa saya tidak tahu cara lain untuk memasukkan operasi ini dengan aman tanpa membuka bagian lain dari kode program. Saya akan sangat senang jika mereka meminta komentar saya. Baik templat maupun fungsi inline tidak memberikan jaminan seperti itu. Ya, dan makro di sini mengatasi tugasnya dengan sangat baik, tidak ada gunanya mengubahnya hanya karena seseorang yang
konformis menganggap ini “tidak aman”.
Anehnya, waktu masih tidak berhenti, kompiler semakin mendukung C ++ 14 / C ++ 17, mengapa tidak mengambil keuntungan dari inovasi, membuat kode lebih mudah dimengerti.
Cpp14 / cpp17
Implementasi untuk C ++ 14 constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num) { return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1); } #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
Seperti yang Anda lihat, saya baru saja mengganti template dengan fungsi constexpr rekursif, yang, menurut pendapat saya, lebih jelas bagi mata manusia.
Gunakan cara yang sama. Omong-omong, dalam C ++ 17, pada prinsipnya, Anda dapat menggunakan fungsi constexpr lambda rekursif, tapi saya tidak yakin bahwa ini akan mengarah pada setidaknya beberapa penyederhanaan, dan juga tidak akan menyulitkan urutan assembler.
Singkatnya, ketiga implementasi C / Cpp memberikan seperangkat instruksi yang sama benarnya, menurut bagian Teori. Saya telah bekerja dengan semua implementasi pada IAR ARM 8.30 dan gcc 7.2.0 untuk waktu yang lama.Latihan itu menyebalkan
Sepertinya itu saja yang terjadi. Penghematan memori dihitung, implementasi dipilih, siap untuk meningkatkan kinerja. Tidak di sini, itu hanya kasus perbedaan teori dan praktik. Dan kapan itu berbeda?
Saya tidak akan pernah menerbitkannya jika saya belum mengujinya, tetapi seberapa realistis volume yang diduduki berkurang pada proyek. Saya secara khusus pada beberapa proyek lama menggantikan makro ini dengan implementasi reguler tanpa topeng, dan melihat perbedaannya. Hasilnya mengejutkan dengan tidak menyenangkan.
Ternyata, volumenya tetap tidak berubah. Saya secara khusus memilih proyek di mana tepatnya 40-50 instruksi tersebut digunakan. Menurut teori, saya harus menyimpan dengan baik setidaknya 100 byte, dan paling banyak 200 byte. Dalam praktiknya, perbedaannya menjadi 24 - 32 byte. Tapi mengapa?
Biasanya, ketika Anda mengatur periferal, Anda mengatur 5-10 register hampir berturut-turut. Dan pada tingkat optimasi yang tinggi, kompiler tidak mengatur instruksi persis dalam urutan register, tetapi mengatur instruksi yang tampaknya benar, kadang-kadang mengganggu mereka di tempat-tempat yang tampaknya tidak dapat dipisahkan.
Saya melihat dua opsi (berikut adalah spekulasi saya):
- Atau kompilernya sangat pintar sehingga Anda tahu bagaimana cara mengoptimalkan set instruksi
- Atau kompiler masih tidak lebih pintar dari seseorang, dan membingungkan dirinya sendiri ketika dia menemukan konstruksi seperti itu
Yaitu, ternyata metode ini dalam bahasa "tingkat tinggi" pada tingkat optimasi yang tinggi hanya berfungsi dengan benar jika tidak ada operasi serupa yang berdekatan dengan satu operasi tersebut.
Kebetulan, pada level O0, teori dan praktik bertemu dalam kasus apa pun, tetapi saya tidak tertarik pada tingkat optimasi ini.
Saya meringkas
Hasil negatif juga merupakan hasil. Saya pikir semua orang akan menarik kesimpulan untuk dirinya sendiri. Secara pribadi, saya akan terus menggunakan teknik ini, itu pasti tidak akan lebih buruk dari itu.
Saya harap itu menarik dan saya ingin menyampaikan rasa hormat yang besar kepada mereka yang telah membaca sampai akhir.
Daftar literatur
- "Manual Referensi Teknis Cortex-M3", Bagian 4.2, ARM 2005.
- Panduan definitif untuk ARM Cortex-M3, Joseph Yiu.
PS saya miliki di tas saya sedikit cakupan topik yang terkait dengan pengembangan elektronik tertanam. Biarkan saya tahu, jika tertarik, saya perlahan akan mendapatkannya.
PPS Entah bagaimana ternyata bengkok untuk menyisipkan bagian dari kode, tolong katakan padaku bagaimana meningkatkan, jika memungkinkan. Secara umum, Anda dapat menyalin sepotong kode yang menarik ke notepad dan menghindari emosi yang tidak menyenangkan dalam analisis.
UPD:
Atas permintaan pembaca, saya menunjukkan bahwa operasi bit banding itu sendiri adalah atom, yang memberi kita keamanan ketika bekerja dengan register. Ini adalah salah satu fitur terpenting dari metode ini.