Sistem moderasi otomatis diimplementasikan dalam layanan web dan aplikasi di mana diperlukan untuk memproses sejumlah besar pesan pengguna. Sistem semacam itu dapat mengurangi biaya moderasi manual, mempercepatnya dan memproses semua pesan pengguna secara real-time. Dalam artikel ini, kita akan berbicara tentang membangun sistem moderasi otomatis untuk memproses bahasa Inggris menggunakan algoritma pembelajaran mesin. Kami akan membahas seluruh pekerjaan pipa mulai dari tugas-tugas penelitian dan pilihan algoritma ML untuk diluncurkan ke produksi. Mari kita lihat di mana mencari sendiri dataset yang sudah jadi dan bagaimana cara mengumpulkan data untuk tugas itu sendiri.
Disiapkan dengan Ira Stepanyuk ( id_step ), Data Scientist di Poteha LabsDeskripsi tugas
Kami bekerja dengan obrolan aktif multi-pengguna, di mana pesan singkat dari puluhan pengguna dapat datang dalam satu obrolan setiap menit. Tugasnya adalah untuk menyoroti pesan dan pesan beracun dengan komentar cabul dalam dialog dari obrolan tersebut. Dari sudut pandang pembelajaran mesin, ini adalah tugas klasifikasi biner, di mana setiap pesan harus ditugaskan ke salah satu kelas.
Untuk mengatasi masalah ini, pertama-tama, perlu untuk memahami apa pesan beracun itu dan apa yang sebenarnya membuatnya beracun. Untuk melakukan ini, kami melihat sejumlah besar pesan khas pengguna di Internet. Berikut adalah beberapa contoh yang telah kami bagi menjadi pesan beracun dan normal.
Dapat dilihat bahwa pesan beracun sering mengandung kata-kata cabul, tapi tetap saja ini bukan prasyarat. Pesan tersebut mungkin tidak mengandung kata-kata yang tidak pantas, tetapi menyinggung seseorang (contoh (1)). Selain itu, terkadang pesan beracun dan normal berisi kata-kata yang sama yang digunakan dalam konteks yang berbeda - menyinggung atau tidak (contoh (2)). Pesan seperti itu juga harus dapat dibedakan.
Setelah mempelajari berbagai pesan, untuk sistem moderasi kami, kami menyebut pesan itu
beracun yang berisi pernyataan yang cabul, ekspresi menghina atau kebencian terhadap seseorang.
Data
Buka data
Salah satu dataset moderasi paling terkenal adalah dataset dari
Tantangan Klasifikasi Komentar Kaggle
Toxic . Bagian dari markup dalam dataset tidak benar: misalnya, pesan dengan kata-kata cabul dapat ditandai sebagai normal. Karena itu, Anda tidak bisa hanya mengikuti kompetisi Kernel dan mendapatkan algoritma klasifikasi yang berfungsi dengan baik. Anda perlu lebih banyak bekerja dengan data, melihat contoh mana yang tidak cukup, dan menambahkan data tambahan dengan contoh tersebut.
Selain kompetisi, ada beberapa publikasi ilmiah dengan tautan ke dataset yang sesuai (
misalnya ), tetapi tidak semua dapat digunakan dalam proyek komersial. Sebagian besar kumpulan data ini berisi pesan dari jejaring sosial Twitter, tempat Anda dapat menemukan banyak tweet beracun. Selain itu, data dikumpulkan dari Twitter, karena tagar tertentu dapat digunakan untuk mencari dan menandai pesan pengguna yang beracun.
Data manual
Setelah kami mengumpulkan dataset dari sumber terbuka dan melatihnya model dasar, menjadi jelas bahwa data terbuka tidak cukup: kualitas model tidak memuaskan. Selain membuka data untuk menyelesaikan masalah, pilihan pesan yang tidak terisi dari messenger game dengan sejumlah besar pesan beracun juga tersedia bagi kami.

Untuk menggunakan data ini untuk tugas mereka, mereka harus diberi label entah bagaimana. Pada saat itu, sudah ada classifier dasar terlatih, yang kami putuskan untuk digunakan untuk penandaan semi-otomatis. Setelah menjalankan semua pesan melalui model, kami mendapatkan probabilitas toksisitas setiap pesan dan diurutkan dalam urutan menurun. Pada awal daftar ini dikumpulkan pesan-pesan dengan kata-kata cabul dan menyinggung. Pada akhirnya, sebaliknya, ada pesan pengguna normal. Dengan demikian, sebagian besar data (dengan nilai probabilitas yang sangat besar dan sangat kecil) tidak dapat ditandai, tetapi segera ditugaskan ke kelas tertentu. Tetap menandai pesan yang jatuh di tengah daftar, yang dilakukan secara manual.
Augmentasi Data
Seringkali dalam kumpulan data Anda dapat melihat pesan yang diubah di mana pengklasifikasi tersebut salah, dan orang tersebut benar memahami artinya.
Ini karena pengguna menyesuaikan dan belajar menipu sistem moderasi sehingga algoritma membuat kesalahan pada pesan beracun dan artinya tetap jelas bagi orang tersebut. Apa yang sedang dilakukan pengguna:
- kesalahan ketik menghasilkan: Anda adalah orang tolol, mengacaukan Anda ,
- ganti karakter alfabet dengan angka yang serupa dalam uraian: n1gga, b0ll0cks ,
- masukkan spasi tambahan: idiot ,
- hapus spasi di antara kata-kata: dieyoustupid .
Untuk melatih pengklasifikasi yang tahan terhadap penggantian seperti itu, Anda harus melakukan seperti yang dilakukan pengguna: menghasilkan perubahan yang sama dalam pesan dan menambahkannya ke pelatihan yang diatur ke data utama.
Secara umum, perjuangan ini tidak terhindarkan: pengguna akan selalu berusaha menemukan kerentanan dan peretasan, dan moderator akan menerapkan algoritma baru.
Deskripsi subtugas
Kami dihadapkan dengan subtugas untuk menganalisis pesan dalam dua mode berbeda:
- mode online - analisis pesan secara real-time, dengan kecepatan respons maksimum;
- mode offline - analisis log pesan dan alokasi dialog beracun.
Dalam mode online, kami memproses setiap pesan pengguna dan menjalankannya melalui model. Jika pesan itu beracun, sembunyikan di antarmuka obrolan, dan jika itu normal, maka tampilkan. Dalam mode ini, semua pesan harus diproses dengan sangat cepat: model harus memberikan respons secepatnya agar tidak mengganggu struktur dialog antar pengguna.
Dalam mode offline, tidak ada batasan waktu untuk bekerja, dan karena itu saya ingin mengimplementasikan model dengan kualitas tertinggi.
Mode online. Pencarian Kamus
Terlepas dari model mana yang dipilih berikutnya, kita harus menemukan dan memfilter pesan dengan kata-kata cabul. Untuk menyelesaikan masalah ini, paling mudah untuk menyusun kamus kata-kata dan ekspresi yang tidak valid yang tidak dapat dilewati, dan mencari kata-kata tersebut di setiap pesan. Pencarian harus cepat, sehingga algoritma pencarian substring naif untuk waktu itu tidak cocok. Algoritma yang cocok untuk menemukan serangkaian kata dalam string adalah
algoritma Aho-Korasik . Karena pendekatan ini, dimungkinkan untuk dengan cepat mengidentifikasi beberapa contoh beracun dan memblokir pesan sebelum dikirim ke algoritma utama. Menggunakan algoritma ML akan memungkinkan Anda untuk "memahami arti" dari pesan dan meningkatkan kualitas klasifikasi.
Mode online. Model pembelajaran mesin dasar
Untuk model dasar, kami memutuskan untuk menggunakan pendekatan standar untuk klasifikasi teks: Algoritma klasifikasi klasik TF-IDF +. Lagi karena alasan kecepatan dan kinerja.
TF-IDF adalah ukuran statistik yang memungkinkan Anda menentukan kata-kata paling penting untuk teks dalam tubuh menggunakan dua parameter: frekuensi kata dalam setiap dokumen dan jumlah dokumen yang mengandung kata tertentu (lebih terinci di
sini ). Setelah menghitung untuk setiap kata dalam pesan TF-IDF, kami mendapatkan representasi vektor dari pesan ini.
TF-IDF dapat dihitung untuk kata-kata dalam teks, serta untuk kata-kata dan karakter n-gram. Perpanjangan seperti itu akan bekerja lebih baik, karena ia akan mampu menangani frasa dan kata yang sering muncul yang tidak ada dalam perangkat pelatihan (out-of-vocabulary).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
Contoh menggunakan TF-IDF pada n-gram kata dan karakterSetelah mengonversi pesan ke vektor, Anda dapat menggunakan metode klasik apa pun untuk klasifikasi:
regresi logistik, SVM ,
hutan acak, peningkatan .
Kami memutuskan untuk menggunakan regresi logistik dalam tugas kami, karena model ini memberikan peningkatan kecepatan dibandingkan dengan pengklasifikasi ML klasik lainnya dan memprediksi probabilitas kelas, yang memungkinkan Anda untuk secara fleksibel memilih ambang klasifikasi dalam produksi.
Algoritma yang diperoleh dengan menggunakan TF-IDF dan regresi logistik dengan cepat berfungsi dan mendefinisikan pesan dengan baik dengan kata-kata dan ekspresi yang cabul, tetapi tidak selalu memahami artinya. Misalnya, sering pesan dengan kata-kata '
hitam ' dan '
feminizm ' masuk dalam kelas beracun. Saya ingin memperbaiki masalah ini dan belajar untuk lebih memahami arti pesan menggunakan versi classifier selanjutnya.
Mode offline
Untuk lebih memahami makna pesan, Anda dapat menggunakan algoritma jaringan saraf:
- Embeddings (Word2Vec, FastText)
- Jaringan Saraf Tiruan (CNN, RNN, LSTM)
- Model pra-terlatih baru (ELMo, ULMFiT, BERT)
Kami akan membahas beberapa algoritma ini dan bagaimana mereka dapat digunakan secara lebih rinci.
Word2Vec dan FastText
Menanamkan model memungkinkan Anda untuk mendapatkan representasi vektor kata dari teks. Ada
dua jenis Word2Vec : Skip-gram dan CBOW (Continuous Bag of Words). Dalam Lewati-gram, konteksnya diprediksi oleh kata, tetapi dalam CBOW, sebaliknya: kata tersebut diprediksi oleh konteks.
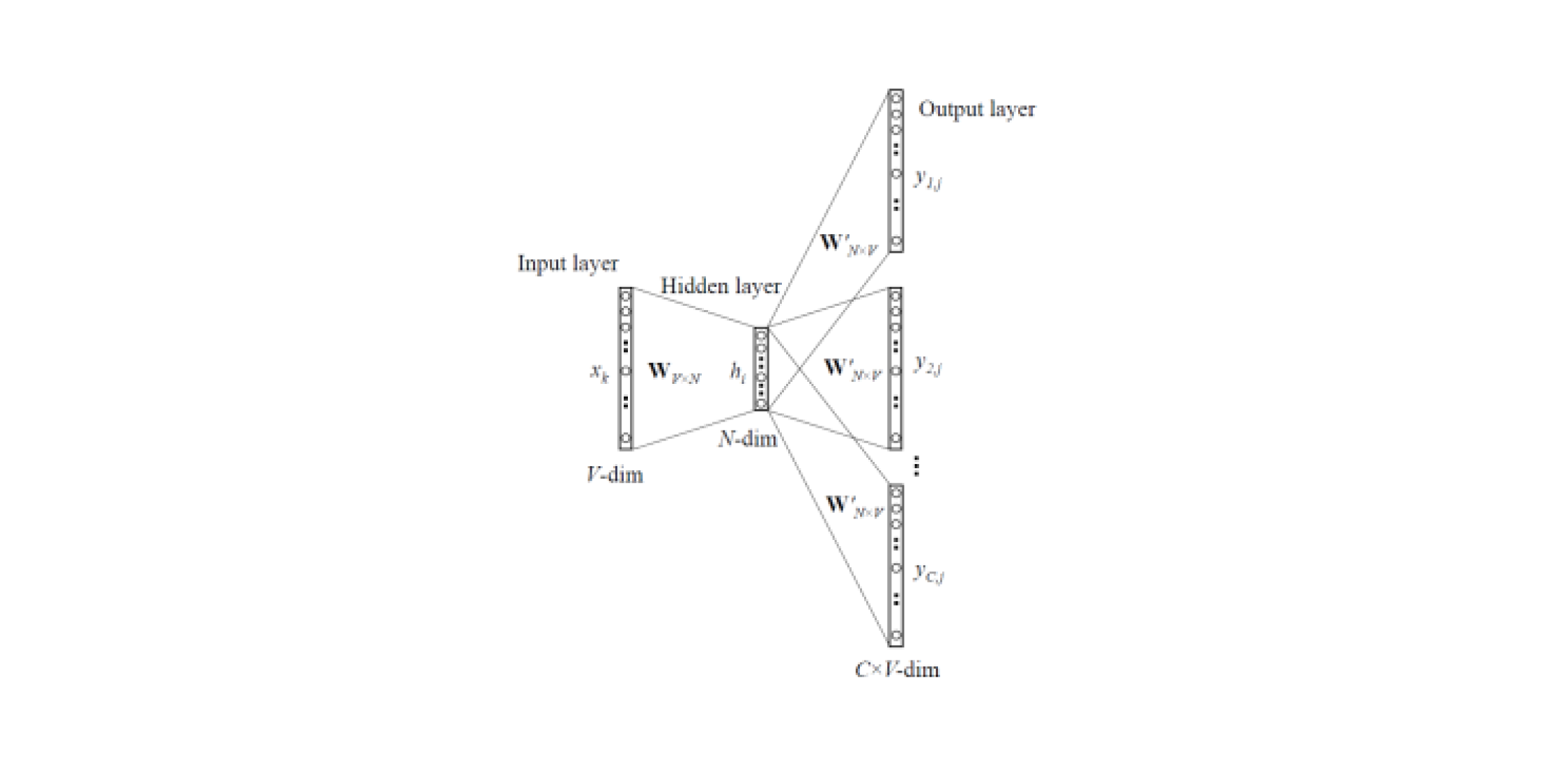
Model semacam itu dilatih pada kumpulan besar teks dan memungkinkan Anda untuk mendapatkan representasi kata-kata vektor dari lapisan tersembunyi dari jaringan saraf yang terlatih. Kerugian dari arsitektur ini adalah bahwa model belajar dari serangkaian kata-kata terbatas yang terkandung dalam corpus. Ini berarti bahwa untuk semua kata yang tidak ada di badan teks pada tahap pelatihan, tidak akan ada embeddings. Dan situasi ini sering terjadi ketika model pra-pelatihan digunakan untuk tugas mereka: untuk beberapa kata tidak akan ada embeddings, sehingga sejumlah besar informasi yang berguna akan hilang.
Untuk mengatasi masalah dengan kata-kata yang tidak ada dalam kamus (OOV, out-of-vocabulary) ada model penyematan ditingkatkan -
FastText . Alih-alih menggunakan kata-kata tunggal untuk melatih jaringan saraf, FastText membagi kata-kata menjadi n-gram (subword) dan belajar darinya. Untuk mendapatkan representasi vektor dari suatu kata, Anda perlu mendapatkan representasi vektor dari n-gram kata ini dan menambahkannya.
Dengan demikian, model Word2Vec dan FastText yang telah dilatih sebelumnya dapat digunakan untuk mendapatkan vektor fitur dari pesan. Karakteristik yang diperoleh dapat diklasifikasikan dengan menggunakan pengklasifikasi ML klasik atau jaringan saraf yang terhubung penuh.
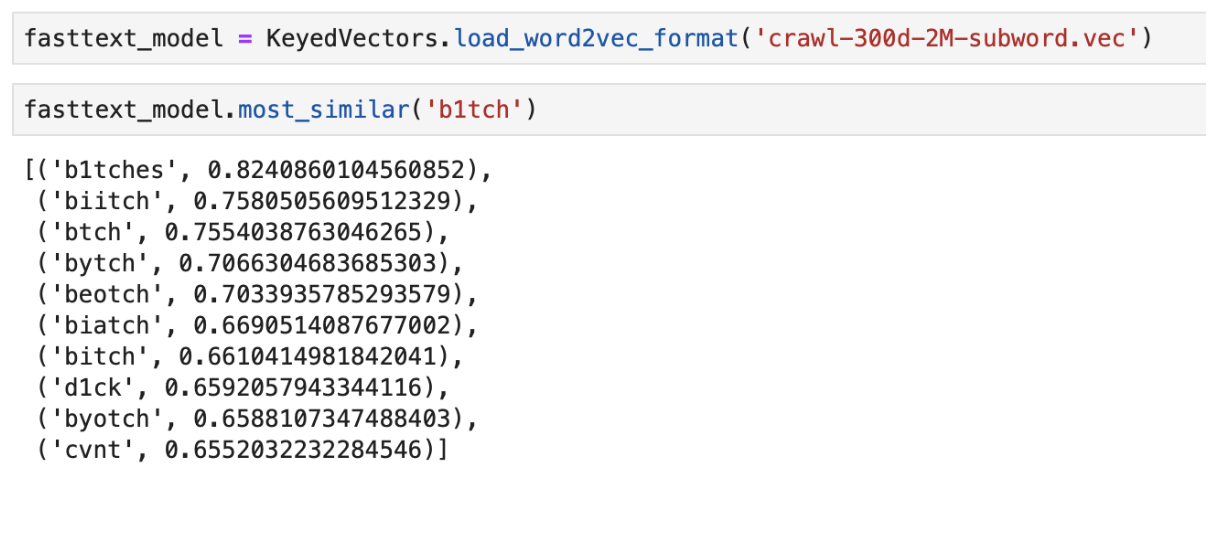 Contoh output dari kata "terdekat" dalam arti menggunakan FastText yang sudah dilatih sebelumnya
Contoh output dari kata "terdekat" dalam arti menggunakan FastText yang sudah dilatih sebelumnyaCNN Classifier
Untuk pemrosesan dan klasifikasi teks dari algoritma jaringan saraf, jaringan berulang (LSTM, GRU) lebih sering digunakan, karena mereka bekerja dengan urutan yang baik. Jaringan konvolusional (CNN) paling sering digunakan untuk pemrosesan gambar, tetapi mereka juga
dapat digunakan dalam tugas klasifikasi teks. Pertimbangkan bagaimana ini bisa dilakukan.
Setiap pesan adalah sebuah matriks di mana pada setiap baris untuk token (kata) representasi vektornya ditulis. Konvolusi diterapkan pada matriks semacam itu dengan cara tertentu: filter konvolusi “meluncur” ke seluruh baris matriks (vektor kata), tetapi ia menangkap beberapa kata sekaligus (biasanya 2-5 kata), sehingga memproses kata-kata tersebut dalam konteks kata-kata tetangga. Detail tentang bagaimana hal ini terjadi dapat dilihat pada
gambar .
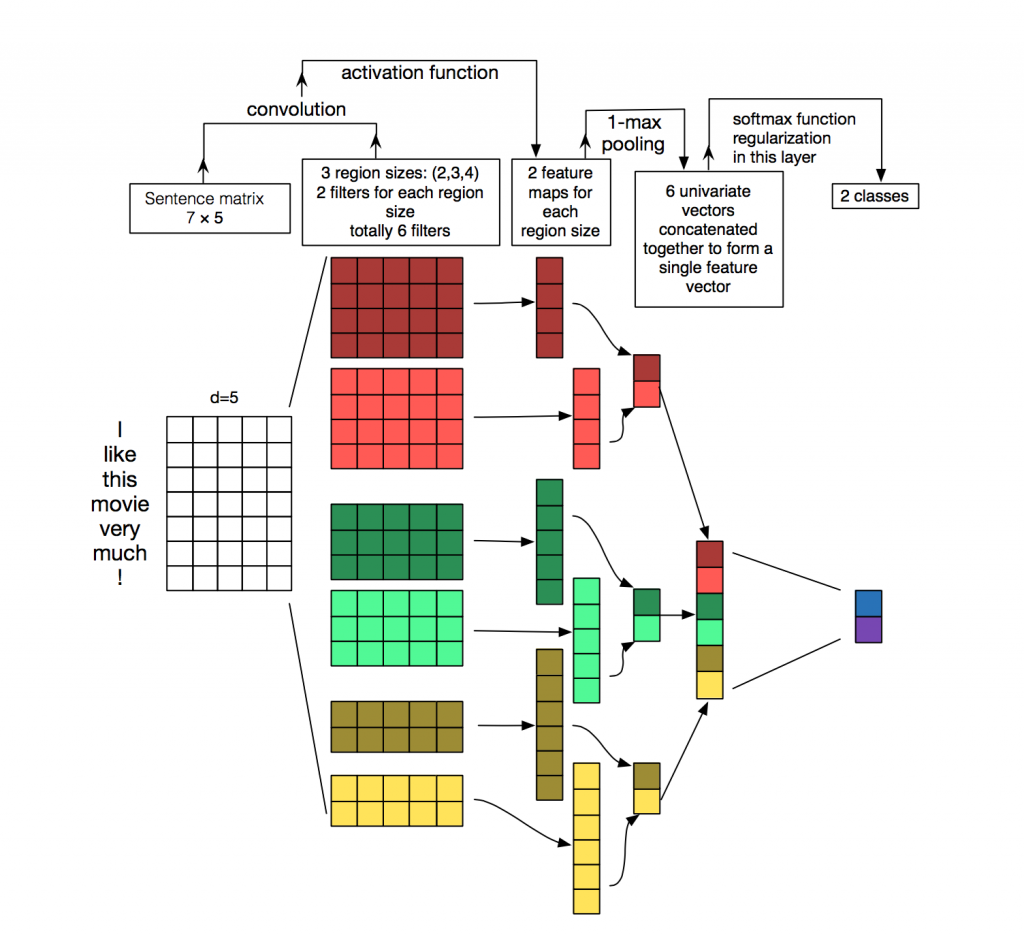
Mengapa menggunakan jaringan convolutional untuk pengolah kata ketika Anda dapat menggunakan berulang? Faktanya adalah konvolusi bekerja lebih cepat. Menggunakannya untuk klasifikasi pesan, Anda dapat sangat menghemat waktu untuk pelatihan.
ELMo
ELMo (Embeddings from Language Models) adalah model penyematan berdasarkan model bahasa yang
baru saja diperkenalkan . Model penyematan baru berbeda dari model Word2Vec dan FastText. Vektor kata ELMo memiliki kelebihan tertentu:
- Penyajian setiap kata tergantung pada keseluruhan konteks tempat kata itu digunakan.
- Representasi didasarkan pada simbol, yang memungkinkan pembentukan representasi yang andal untuk kata-kata OOV (out-of-vocabulary).
ELMo dapat digunakan untuk berbagai tugas di NLP. Misalnya, untuk tugas kami, vektor pesan yang diterima menggunakan ELMo dapat dikirim ke classifier ML klasik atau menggunakan jaringan yang konvolusional atau terhubung sepenuhnya.
Embedded pra-terlatih ELMo cukup mudah digunakan untuk tugas Anda, contoh penggunaan dapat ditemukan di
sini .
Fitur Implementasi
API Labu
API prototipe ditulis dalam Flask, karena mudah digunakan.
Dua Gambar Docker
Untuk penyebaran, kami menggunakan dua gambar buruh pelabuhan: yang dasar, di mana semua dependensi diinstal, dan yang utama untuk meluncurkan aplikasi. Ini sangat menghemat waktu perakitan, karena gambar pertama jarang dibangun kembali, dan ini menghemat waktu selama penyebaran. Cukup banyak waktu dihabiskan untuk membangun dan mengunduh perpustakaan pembelajaran mesin, yang tidak perlu dilakukan setiap komitmen.
Pengujian
Keunikan penerapan sejumlah besar algoritma pembelajaran mesin adalah bahwa bahkan dengan metrik tinggi pada dataset validasi, kualitas nyata dari algoritma dalam produksi dapat rendah. Oleh karena itu, untuk menguji operasi algoritma, seluruh tim menggunakan bot di Slack. Ini sangat nyaman, karena setiap anggota tim dapat memeriksa respons apa yang diberikan algoritma untuk pesan tertentu. Metode pengujian ini memungkinkan Anda untuk segera melihat bagaimana algoritma akan bekerja pada data langsung.
Alternatif yang baik adalah meluncurkan solusi di situs publik seperti Yandex Toloka dan AWS Mechanical Turk.
Kesimpulan
Kami memeriksa beberapa pendekatan untuk memecahkan masalah moderasi pesan otomatis dan menjelaskan fitur-fitur dari implementasi kami.
Pengamatan utama yang diperoleh selama bekerja:
- Pencarian kamus dan algoritma pembelajaran mesin berdasarkan TF-IDF dan regresi logistik memungkinkan untuk mengklasifikasikan pesan dengan cepat, tetapi tidak selalu dengan benar.
- Algoritma jaringan saraf dan model embeddings pra-terlatih lebih baik mengatasi tugas ini dan dapat menentukan toksisitas dalam makna pesan.
Tentu saja, kami memasang demo
Poteha Toxic Comment Detection yang terbuka di bot
Facebook . Bantu kami membuat bot lebih baik!
Saya akan dengan senang hati menjawab pertanyaan di komentar.