Hai Nama saya Vadim Madison, saya memimpin pengembangan System Platform Avito. Tentang bagaimana kita di perusahaan beralih dari arsitektur monolitik ke arsitektur layanan mikro, telah dikatakan lebih dari sekali. Sudah waktunya untuk berbagi bagaimana kami mengubah infrastruktur kami untuk mendapatkan yang terbaik dari layanan-layanan microser dan tidak membiarkan diri kita tersesat di dalamnya. Bagaimana PaaS membantu kami di sini, bagaimana kami menyederhanakan penyebaran dan mengurangi pembuatan layanan mikro menjadi satu klik - baca terus. Tidak semua yang saya tulis di bawah ini sepenuhnya dilaksanakan di Avito, sebagian adalah bagaimana kami mengembangkan platform kami.
(Dan di akhir artikel ini saya akan berbicara tentang kesempatan untuk mendapatkan seminar tiga hari dari seorang pakar arsitektur layanan mikro Chris Richardson).

Bagaimana kami sampai pada layanan microser
Avito adalah salah satu iklan baris terbesar di dunia, yang menerbitkan lebih dari 15 juta iklan baru per hari. Backend kami menerima lebih dari 20 ribu permintaan per detik. Sekarang kami memiliki beberapa ratus layanan mikro.
Kami telah membangun arsitektur layanan mikro selama beberapa tahun. Bagaimana tepatnya - kolega kami berbicara secara rinci di bagian kami di RIT ++ 2017. Di CodeFest 2017 (lihat video ), Sergey Orlov dan Mikhail Prokopchuk menjelaskan secara terperinci mengapa kami membutuhkan transisi ke layanan mikro dan peran apa yang dimainkan Kubernet di sini. Nah, sekarang kami melakukan segalanya untuk meminimalkan biaya penskalaan yang melekat pada arsitektur semacam itu.
Awalnya, kami tidak membuat ekosistem yang secara komprehensif akan membantu kami dalam pengembangan dan peluncuran layanan mikro. Mereka hanya mengumpulkan solusi open source yang masuk akal, meluncurkannya di rumah dan menyarankan pengembang untuk menanganinya. Akibatnya, ia pergi ke selusin tempat (dasbor, layanan internal), setelah itu ia menjadi lebih kuat dalam keinginan untuk memotong kode dengan cara lama, dalam monolit. Warna hijau pada diagram di bawah ini menunjukkan apa yang dilakukan pengembang dengan satu atau lain cara dengan tangannya sendiri, warna kuning menunjukkan otomatisasi.
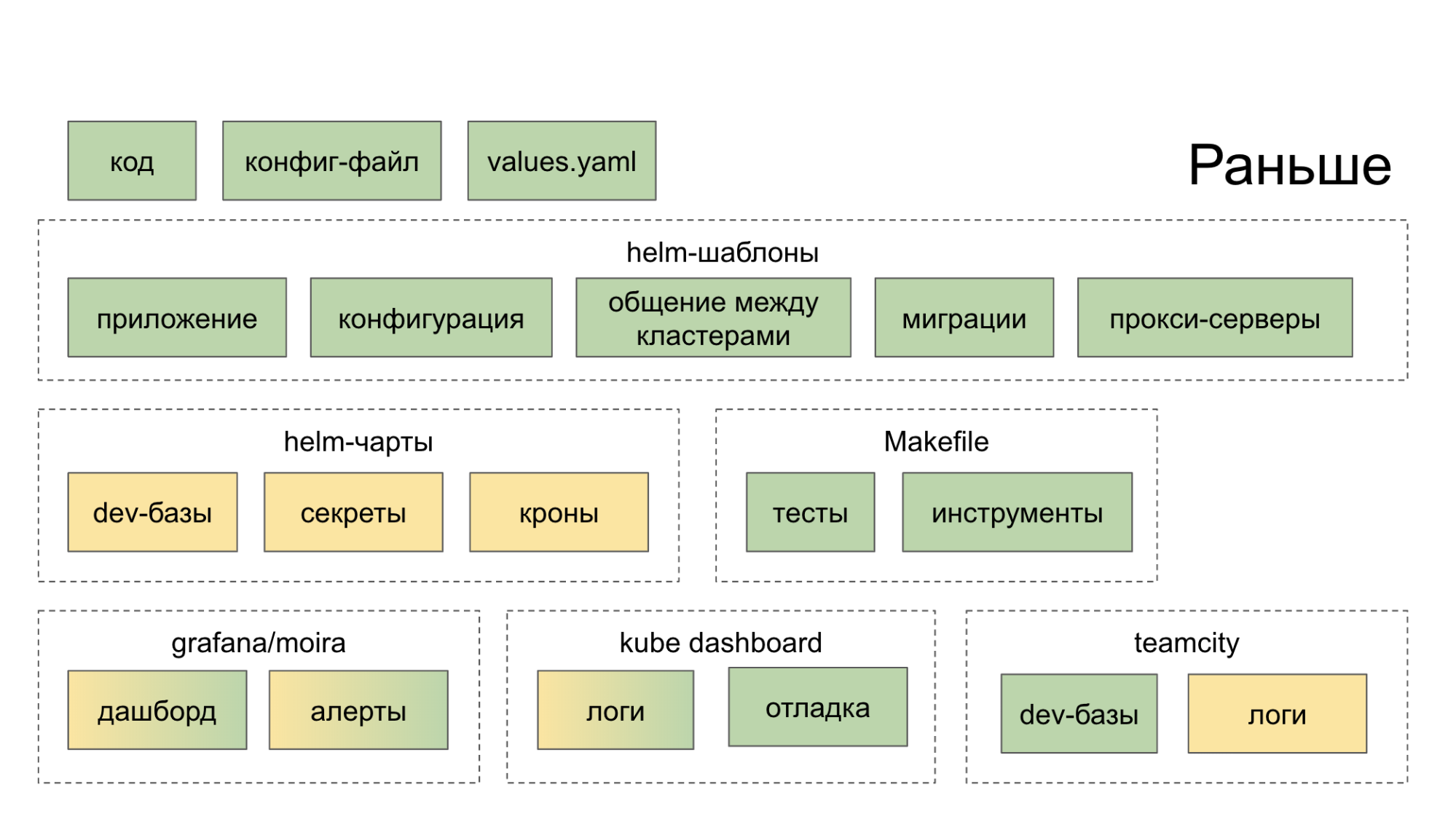
Sekarang di utilitas PaaS CLI, satu tim menciptakan layanan baru, dan dua lagi menambahkan database baru dan menyebarkan ke Stage.
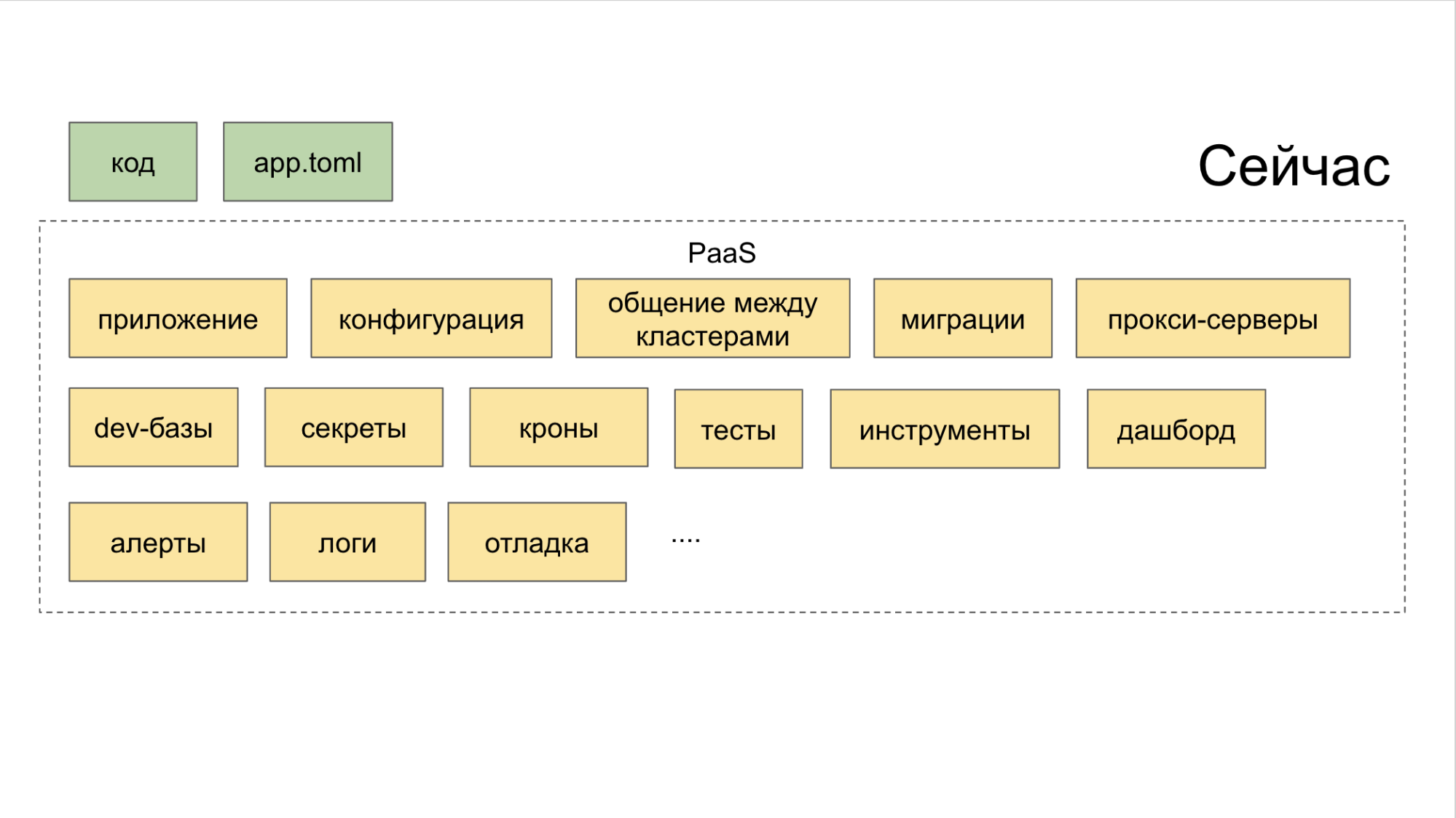
Cara mengatasi era "fragmentasi layanan mikro"
Dengan arsitektur monolitik, demi konsistensi perubahan dalam produk, pengembang dipaksa untuk mencari tahu apa yang terjadi dengan tetangga mereka. Saat mengerjakan arsitektur baru, konteks layanan tidak lagi bergantung satu sama lain.
Selain itu, agar arsitektur microservice menjadi efektif, banyak proses perlu ditetapkan, yaitu:
• logging;
• penelusuran kueri (Jaeger);
• agregasi kesalahan (Penjaga);
• status, pesan, acara dari Kubernetes (Pemrosesan Aliran Acara);
• batas balapan / pemutus sirkuit (Anda dapat menggunakan Hystrix);
• kontrol konektivitas layanan (kami menggunakan Netramesh);
• pemantauan (Grafana);
• perakitan (TeamCity);
• komunikasi dan notifikasi (Slack, email);
• pelacakan tugas; (Jira)
• kompilasi dokumentasi.
Sehingga ketika sistem berskala, ia tidak kehilangan integritasnya dan tetap efektif, kami memikirkan kembali organisasi kerja layanan-mikro di Avito.
Bagaimana kami menangani layanan microser
Melakukan “kebijakan partai” terpadu di antara banyak layanan mikro Avito membantu:
- pembagian infrastruktur menjadi lapisan-lapisan;
- Konsep Platform as a Service (PaaS);
- memantau semua yang terjadi dengan layanan-layanan microser.
Lapisan abstraksi infrastruktur mencakup tiga lapisan. Ayo pergi dari atas ke bawah.
A. Jaring servis atas. Awalnya kami mencoba Istio, tetapi ternyata menggunakan terlalu banyak sumber daya, yang terlalu mahal pada volume kami. Oleh karena itu, insinyur senior di tim arsitektur Alexander Lukyanchenko mengembangkan solusinya sendiri - Netramesh (tersedia di Open Source), yang sekarang kami gunakan dalam produksi dan yang menggunakan sumber daya beberapa kali lebih sedikit daripada Istio (tetapi tidak melakukan semua yang Istio tawarkan).
B. Medium - Kubernetes. Di atasnya kami menyebarkan dan mengoperasikan layanan microser.
C. Logam rendah - telanjang. Kami tidak menggunakan cloud dan hal-hal seperti OpenStack, tetapi duduk sepenuhnya di atas besi kosong.
Semua lapisan digabungkan oleh PaaS. Dan platform ini, pada gilirannya, terdiri dari tiga bagian.
I. Generator yang dikendalikan melalui utilitas CLI. Dialah yang membantu pengembang untuk menciptakan layanan mikro dengan cara yang benar dan dengan upaya minimal.
II Kolektor gabungan dengan kontrol semua alat melalui dasbor bersama.
III. Repositori . Ini mengganggu perencana yang secara otomatis mengatur pemicu untuk tindakan signifikan. Berkat sistem seperti itu, tidak ada satu tugas pun yang terlewatkan hanya karena seseorang lupa untuk menempatkan tugas di Jira. Kami menggunakan alat internal yang disebut Atlas untuk ini.

Implementasi layanan-layanan mikro di Avito juga dilakukan sesuai dengan skema tunggal, yang menyederhanakan kendali atas mereka pada setiap tahap pengembangan dan rilis.
Cara kerja pipeline pengembangan microservice standar
Secara umum, rantai pembuatan layanan-mikro adalah sebagai berikut:
Dorong-CLI → Integrasi Berkelanjutan → Panggang → Sebarkan → Tes Buatan → Tes Canary → Pengujian Peras → Produksi → Layanan.
Kami berjalan melaluinya dalam urutan ini.
CLI-push
• Membuat layanan microser .
Kami berjuang untuk waktu yang lama untuk mengajari setiap pengembang cara membuat layanan mikro. Termasuk menulis dalam petunjuk terperinci Confluence. Tetapi skema berubah dan ditambah. Intinya - hambatan yang terbentuk pada awal perjalanan: butuh lebih banyak waktu untuk memulai layanan mikro daripada yang diizinkan, dan masih, ketika membuat mereka, masalah sering muncul.
Pada akhirnya, kami membangun utilitas CLI sederhana yang mengotomatiskan langkah-langkah dasar saat membuat layanan mikro. Bahkan, itu menggantikan dorongan git pertama. Inilah yang dia lakukan.
- Membuat layanan sesuai dengan templat - langkah demi langkah, dalam mode "wizard". Kami memiliki template untuk bahasa pemrograman utama di backend Avito: PHP, Golang dan Python.
- Pada satu perintah, ini menyebarkan lingkungan untuk pengembangan lokal pada mesin tertentu - Minikube naik, grafik Helm secara otomatis dihasilkan dan diluncurkan di kubernet lokal.
- Menghubungkan database yang diinginkan. Pengembang tidak perlu mengetahui IP, login dan kata sandi untuk mengakses database yang ia butuhkan - setidaknya secara lokal, setidaknya dalam Stage, setidaknya dalam produksi. Selain itu, database segera digunakan dalam konfigurasi yang toleran terhadap kesalahan dan dengan penyeimbangan.
- Itu sendiri melakukan perakitan langsung. Katakanlah seorang pengembang memperbaiki sesuatu dalam microservice melalui IDE-nya. Utilitas melihat perubahan dalam sistem file dan, berdasarkan pada mereka, menyusun kembali aplikasi (untuk Golang) dan restart. Untuk PHP, kami cukup meneruskan direktori di dalam kubus dan di sana live-reload diperoleh "secara otomatis".
- Menghasilkan autotest. Dalam bentuk cakram, tetapi cukup cocok untuk digunakan.
• Menyebarkan layanan mikro .
Agak suram untuk menggunakan layanan mikro sebelumnya. Wajib wajib:
I. Dockerfile.
II Konfigurasi
III. Grafik Helm, yang dengan sendirinya tebal dan meliputi:
- grafik itu sendiri;
- templat;
- Nilai spesifik dengan mempertimbangkan lingkungan yang berbeda.
Kami menghilangkan rasa sakit karena mengulangi manifestasi Kubernet, dan sekarang mereka dihasilkan secara otomatis. Tetapi yang paling penting, mereka menyederhanakan penyebaran hingga batas. Mulai sekarang, kami memiliki Dockerfile, dan pengembang menulis seluruh konfigurasi dalam satu file app.toml tunggal.
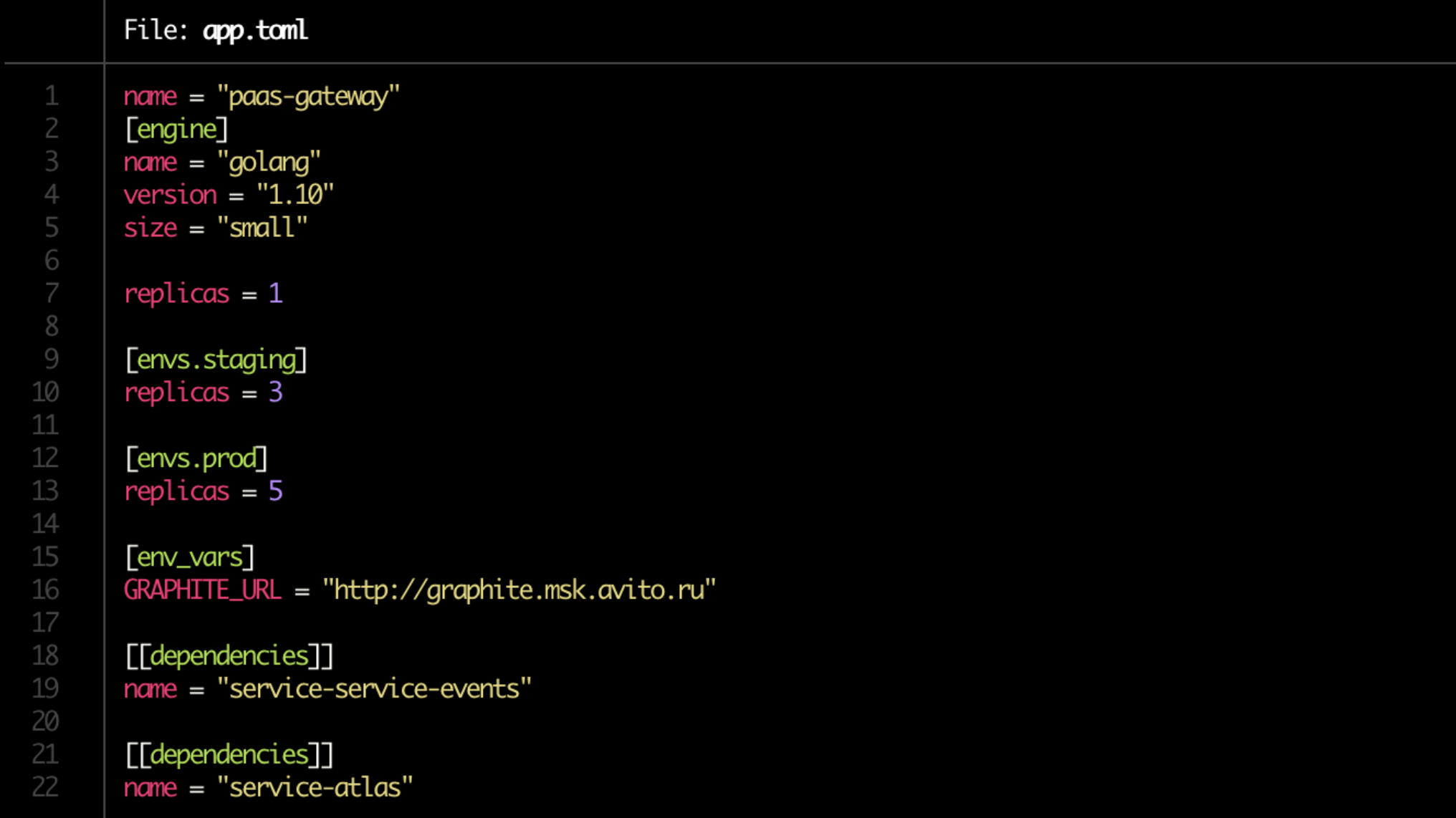
Ya, dan di app.toml sendiri sekarang urusan sebentar. Kami menuliskan di mana untuk berapa banyak salinan layanan untuk meningkatkan (pada server-dev, pada pementasan, pada produksi), menunjukkan dependensinya. Perhatikan ukuran garis = "kecil" di blok [mesin]. Ini adalah batas yang akan dialokasikan untuk layanan melalui Kubernetes.
Lebih lanjut berdasarkan konfigurasi, semua grafik Helm yang diperlukan secara otomatis dihasilkan dan koneksi ke database dibuat.
• Validasi dasar. Cek semacam itu juga otomatis.
Perlu dilacak:
- apakah ada Dockerfile;
- apakah ada app.toml;
- apakah ada dokumentasi;
- Apakah dependensi dalam urutan;
- adalah aturan peringatan yang ditetapkan.
Ke poin terakhir: pemilik layanan sendiri menunjukkan metrik produk mana yang harus dipantau.
• Persiapan dokumentasi.
Masih tempat yang bermasalah. Tampaknya menjadi yang paling jelas, tetapi pada saat yang sama pemecahan rekor "sering dilupakan", dan karenanya merupakan mata rantai yang rentan.
Perlu bahwa dokumentasi berada di bawah masing-masing layanan mikro. Blok-blok berikut termasuk di dalamnya.
I. Deskripsi singkat tentang layanan ini . Hanya beberapa kalimat tentang apa yang dia lakukan dan untuk apa diperlukan.
II Tautan ke diagram arsitektur . Adalah penting bahwa pandangan cepat membuatnya mudah dipahami, misalnya, apakah Anda menggunakan Redis untuk caching atau sebagai penyimpanan data utama dalam mode persisten. Di Avito, sejauh ini ini adalah tautan ke Confluence.
III. Runbook . Panduan singkat untuk meluncurkan layanan dan kerumitan penanganannya.
IV. FAQ , di mana akan lebih baik untuk mengantisipasi masalah yang mungkin dihadapi rekan Anda saat bekerja dengan layanan ini.
V. Deskripsi titik akhir untuk API . Jika tiba-tiba Anda tidak menunjukkan tujuan, Anda hampir pasti akan dibayar oleh kolega yang layanan mikronya terkait dengan Anda. Sekarang kami menggunakan Swagger untuk ini dan solusi kami disebut singkat.
VI. Label Atau spidol yang menunjukkan produk, fungsi, unit struktural perusahaan tempat layanan itu berada. Mereka membantu memahami dengan cepat, misalnya, jika Anda tidak melihat fungsionalitas yang diluncurkan oleh rekan kerja Anda seminggu yang lalu untuk unit bisnis yang sama.
VII. Pemilik atau pemilik layanan . Dalam kebanyakan kasus, itu - atau mereka - dapat ditentukan secara otomatis menggunakan PaaS, tetapi untuk asuransi kami mengharuskan pengembang untuk menentukannya secara manual.
Akhirnya, praktik yang baik untuk meninjau dokumentasi, mirip dengan tinjauan kode.
Integrasi berkelanjutan
- Mempersiapkan repositori.
- Membuat saluran pipa di TeamCity.
- Hak pengaturan.
- Cari pemilik layanan. Ada skema hybrid - penandaan manual dan otomatisasi minimal dari PaaS. Skema sepenuhnya otomatis gagal mentransfer layanan untuk mendukung tim pengembangan lain, atau, misalnya, jika pengembang layanan berhenti.
- Pendaftaran layanan di Atlas (lihat di atas). Dengan semua pemilik dan ketergantungannya.
- Periksa migrasi. Kami memeriksa untuk melihat apakah ada yang berpotensi berbahaya di antara mereka. Misalnya, di salah satu dari mereka, sebuah tabel alter muncul atau sesuatu yang lain yang dapat mengganggu kompatibilitas skema data antara versi layanan yang berbeda. Maka migrasi tidak dilakukan, tetapi dimasukkan ke dalam berlangganan - PaaS harus memberi sinyal kepada pemilik layanan ketika sudah aman untuk menggunakannya.
Panggang
Tahap selanjutnya adalah pengemasan layanan sebelum penyebaran.
- Bangun aplikasinya. Menurut klasik - pada gambar Docker.
- Grafik Generasi Helm untuk layanan itu sendiri dan sumber daya terkait. Termasuk untuk basis data dan cache. Mereka dibuat secara otomatis sesuai dengan konfigurasi app.toml yang dihasilkan pada tahap push-CLI.
- Membuat tiket untuk administrator untuk membuka port (bila diperlukan).
- Uji coba unit dan perhitungan cakupan kode . Jika cakupan kode di bawah nilai ambang batas yang diberikan, maka, kemungkinan besar, layanan akan gagal lebih lanjut - untuk digunakan. Jika berada di ambang yang diizinkan, maka koefisien “pesimisasi” akan diberikan ke layanan: kemudian, dengan tidak adanya peningkatan indikator dari waktu ke waktu, pengembang akan menerima pemberitahuan bahwa tidak ada kemajuan pada bagian dari pengujian (dan sesuatu harus dilakukan dengan ini).
- Pertimbangan keterbatasan memori dan CPU . Kami terutama menulis microservices di Golang dan menjalankannya di Kubernetes. Dari sini ada satu kehalusan yang terkait dengan kekhasan bahasa Golang: secara default, semua kernel pada mesin digunakan saat startup, jika Anda tidak secara eksplisit mengatur variabel GOMAXPROCS dan ketika beberapa layanan tersebut diluncurkan pada mesin yang sama, mereka mulai bersaing untuk sumber daya, saling mengganggu. Grafik di bawah ini menunjukkan bagaimana runtime berubah jika Anda menjalankan aplikasi tanpa kompetisi dan dalam perlombaan untuk sumber daya. (Sumber grafik ada di sini ).

Lead time, lebih sedikit lebih baik. Maksimal: 643ms; Minimum: 42ms. Foto dapat diklik.
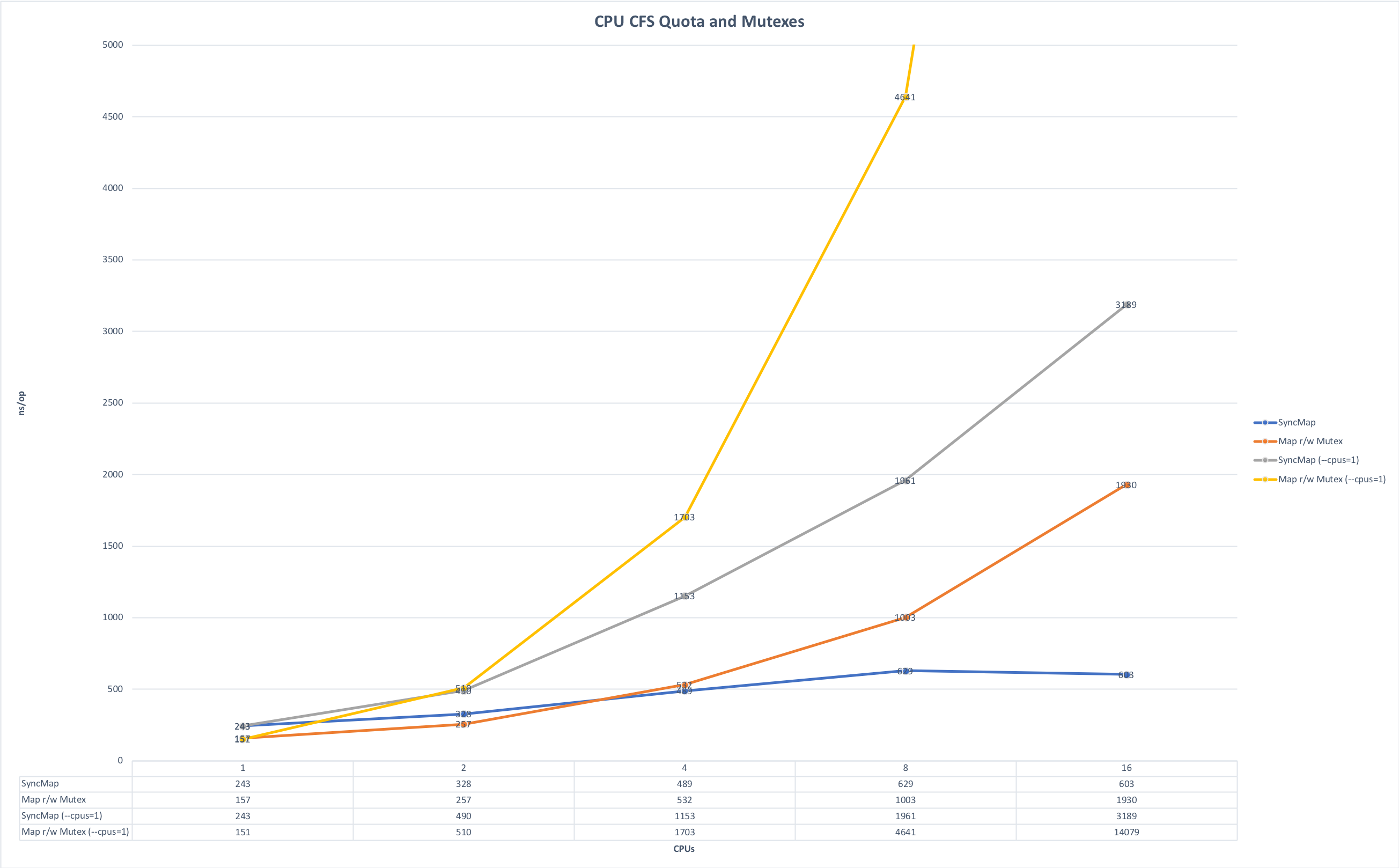
Waktu untuk operasi, lebih sedikit lebih baik. Maksimal: 14091 ns, Minimum: 151 ns. Foto dapat diklik.
Pada tahap mempersiapkan perakitan, Anda dapat mengatur variabel ini secara eksplisit atau Anda dapat menggunakan perpustakaan automaxprocs dari orang-orang Uber.
Sebarkan
• Verifikasi konvensi. Sebelum Anda mulai mengirim majelis layanan ke lingkungan yang dimaksud, Anda perlu memeriksa hal-hal berikut:
- Titik akhir API.
- Kepatuhan skema endpoint tanggapan API.
- Format log.
- Mengatur header untuk permintaan layanan (netramesh sedang melakukan ini sekarang)
- Mengatur token pemilik saat mengirim pesan ke bus (bus acara). Ini diperlukan untuk melacak konektivitas layanan melalui bus. Anda dapat mengirim data idempoten ke bus yang tidak meningkatkan konektivitas layanan (yang baik), serta data bisnis yang meningkatkan konektivitas layanan (yang sangat buruk!). Dan pada saat konektivitas ini menjadi masalah, memahami siapa yang menulis dan membaca bus membantu membagi layanan dengan benar.
Meskipun tidak ada banyak konvensi di Avito, tetapi kumpulan mereka berkembang. Semakin banyak perjanjian tersebut dalam bentuk perintah yang mudah dimengerti dan nyaman, semakin mudah untuk menjaga konsistensi antara layanan-layanan mikro.
Tes sintetis
• Pengujian loop tertutup. Baginya, kita sekarang menggunakan open source Hoverfly.io . Pertama, ia menulis beban nyata pada layanan, lalu - hanya dalam satu lingkaran tertutup - ia mengemulasi.
• Uji beban. Kami mencoba untuk membawa semua layanan ke kinerja yang optimal. Dan semua versi dari masing-masing layanan harus mengalami stress testing - sehingga kita dapat memahami kinerja layanan saat ini dan perbedaannya dengan versi sebelumnya dari layanan yang sama. Jika setelah layanan diperbarui kinerjanya turun satu setengah kali, ini adalah sinyal yang jelas bagi pemiliknya: Anda perlu menggali kode dan memperbaiki situasi.
Kami membangun berdasarkan data yang dikumpulkan, misalnya, untuk mengimplementasikan penskalaan otomatis dengan benar dan, pada akhirnya, memahami secara umum seberapa skalabel layanan tersebut.
Selama pengujian stres, kami memeriksa apakah konsumsi sumber daya memenuhi batas yang ditetapkan. Dan kami fokus terutama pada ekstrem.
a) Kami melihat total muatan.
- Terlalu kecil - kemungkinan besar sesuatu tidak berfungsi sama sekali jika beban tiba-tiba turun beberapa kali.
- Terlalu besar - optimasi diperlukan.
b) Kami melihat cut-off oleh RPS.
Di sini kita melihat perbedaan antara versi saat ini dan yang sebelumnya dan jumlah total. Sebagai contoh, jika suatu layanan menghasilkan 100 rps, maka ia ditulis dengan buruk atau spesifikasinya, tetapi bagaimanapun juga, ini adalah kesempatan untuk melihat dengan seksama pada layanan tersebut.
Jika RPS, sebaliknya, terlalu banyak, maka mungkin beberapa jenis bug dan beberapa titik akhir berhenti melakukan payload, tetapi beberapa jenis return true; dipicu return true;
Tes kenari
Setelah tes sintetik berlalu, kami menjalankan microservice pada sejumlah kecil pengguna. Kami mulai dengan hati-hati, dengan sebagian kecil dari perkiraan audiens layanan - kurang dari 0,1%. Pada tahap ini, sangat penting bahwa metrik teknis dan produk yang benar ditetapkan dalam pemantauan sehingga mereka menunjukkan masalah dalam layanan secepat mungkin. Waktu minimum untuk ujian kenari adalah 5 menit, yang utama adalah 2 jam. Untuk layanan yang rumit, kami mengatur waktu dalam mode manual.
Kami menganalisis:
- metrik khusus bahasa, khususnya pekerja php-fpm;
- kesalahan dalam Sentry;
- status tanggapan;
- waktu respons (waktu respons), akurat dan rata-rata;
- latensi;
- pengecualian, diproses dan tidak diproses;
- metrik makanan.
Tes pemerasan
Pengujian Squeeze juga disebut pengujian ekstrusi. Nama teknik ini diperkenalkan di Netflix. Esensinya adalah bahwa pada awalnya kita mengisi satu contoh dengan lalu lintas nyata ke keadaan gagal dan dengan demikian menetapkan batasnya. Selanjutnya, tambahkan contoh lain dan muat pasangan ini - lagi ke maksimum; kita melihat langit-langit dan delta mereka dengan "pemerasan" pertama. Jadi kami menghubungkan satu instance per langkah dan menghitung pola perubahan.
Data uji melalui "ekstrusi" juga berbondong-bondong ke basis metrik umum, tempat kami memperkaya mereka dengan hasil beban buatan, atau bahkan menggantinya dengan "sintetis".
Produksi
• Penskalaan. Dengan meluncurkan layanan ke produksi, kami melacak bagaimana skala. Dalam hal ini, pemantauan hanya indikator CPU, menurut pengalaman kami, tidak efisien. Penskalaan otomatis dengan pembandingan RPS dalam bentuk murni berfungsi, tetapi hanya untuk layanan tertentu, misalnya streaming online. Jadi kami melihat terutama pada metrik produk khusus aplikasi.
Akibatnya, saat penskalaan, kami menganalisis:
- Indikator CPU dan RAM,
- jumlah permintaan dalam antrian,
- waktu respons
- perkiraan berdasarkan data historis.
Saat meningkatkan layanan, penting juga untuk memantau ketergantungannya sehingga tidak muncul bahwa kami adalah layanan pertama dalam rantai penskalaan, dan layanan yang merujuknya jatuh di bawah beban. Untuk menetapkan beban yang dapat diterima untuk seluruh kumpulan layanan, kami melihat data historis dari layanan dependen "terdekat" (berdasarkan kombinasi CPU dan RAM dan metrik khusus aplikasi) dan membandingkannya dengan data historis dari layanan inisialisasi, dan seterusnya sepanjang seluruh "rantai ketergantungan" ", Dari atas ke bawah.
Layanan
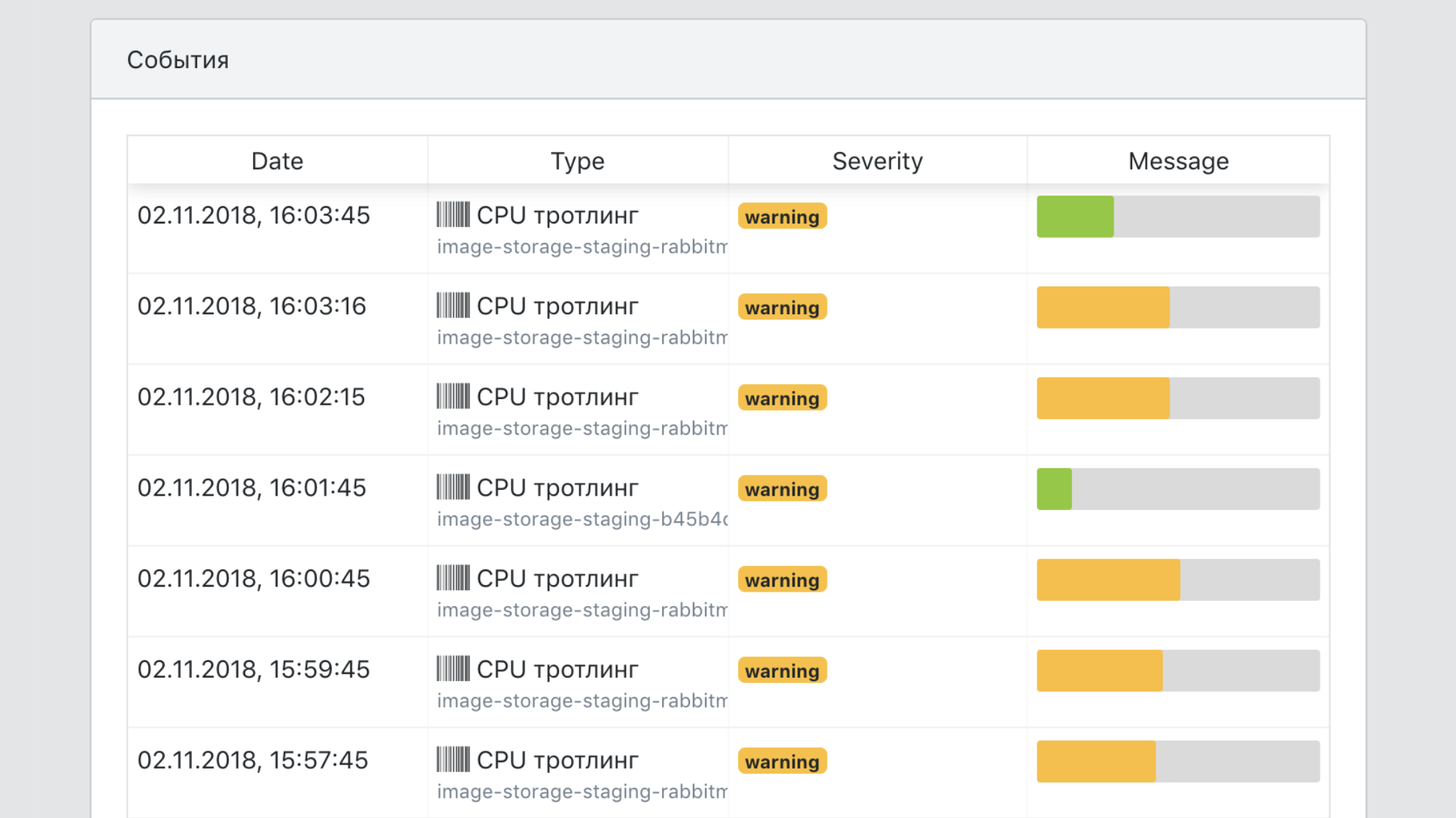
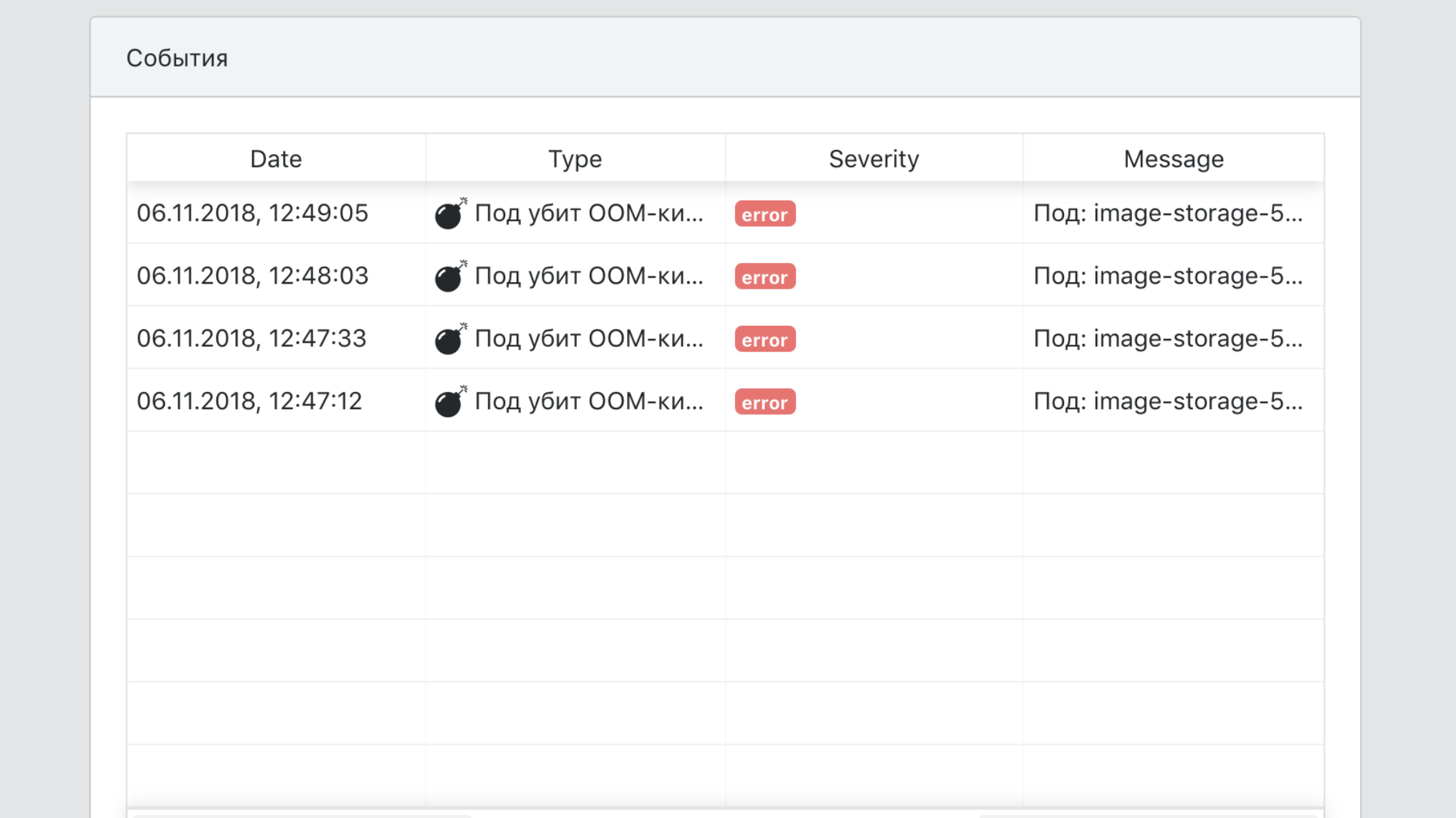
Setelah microservice dioperasikan, kita dapat menggantung pemicu di atasnya.
Berikut adalah situasi khas yang memicu kebakaran.
- Migrasi yang berpotensi berbahaya terdeteksi.
- Pembaruan keamanan telah dirilis.
- Layanan itu sendiri belum diperbarui untuk waktu yang lama.
- Beban pada layanan menurun secara signifikan atau salah satu metrik produknya berada di luar kisaran normal.
- Layanan tidak lagi memenuhi persyaratan platform baru.
Beberapa pemicu bertanggung jawab atas stabilitas pekerjaan, sebagian sebagai fungsi untuk melayani sistem - misalnya, beberapa layanan belum digunakan sejak lama dan gambar dasarnya telah berhenti melewati pemeriksaan keamanan.
Dasbor
Singkatnya, dasbor adalah panel kontrol seluruh PaaS kami.
- Satu titik informasi tentang suatu layanan, dengan data tentang cakupannya dengan pengujian, jumlah gambarnya, jumlah salinan produksi, versi, dll.
- Alat untuk memfilter data berdasarkan layanan dan label (penanda milik unit bisnis, fungsi produk, dll.)
- Sarana integrasi dengan alat infrastruktur untuk melacak, mencatat, memantau.
- Satu titik dokumentasi layanan.
- Satu sudut pandang dari semua acara layanan.
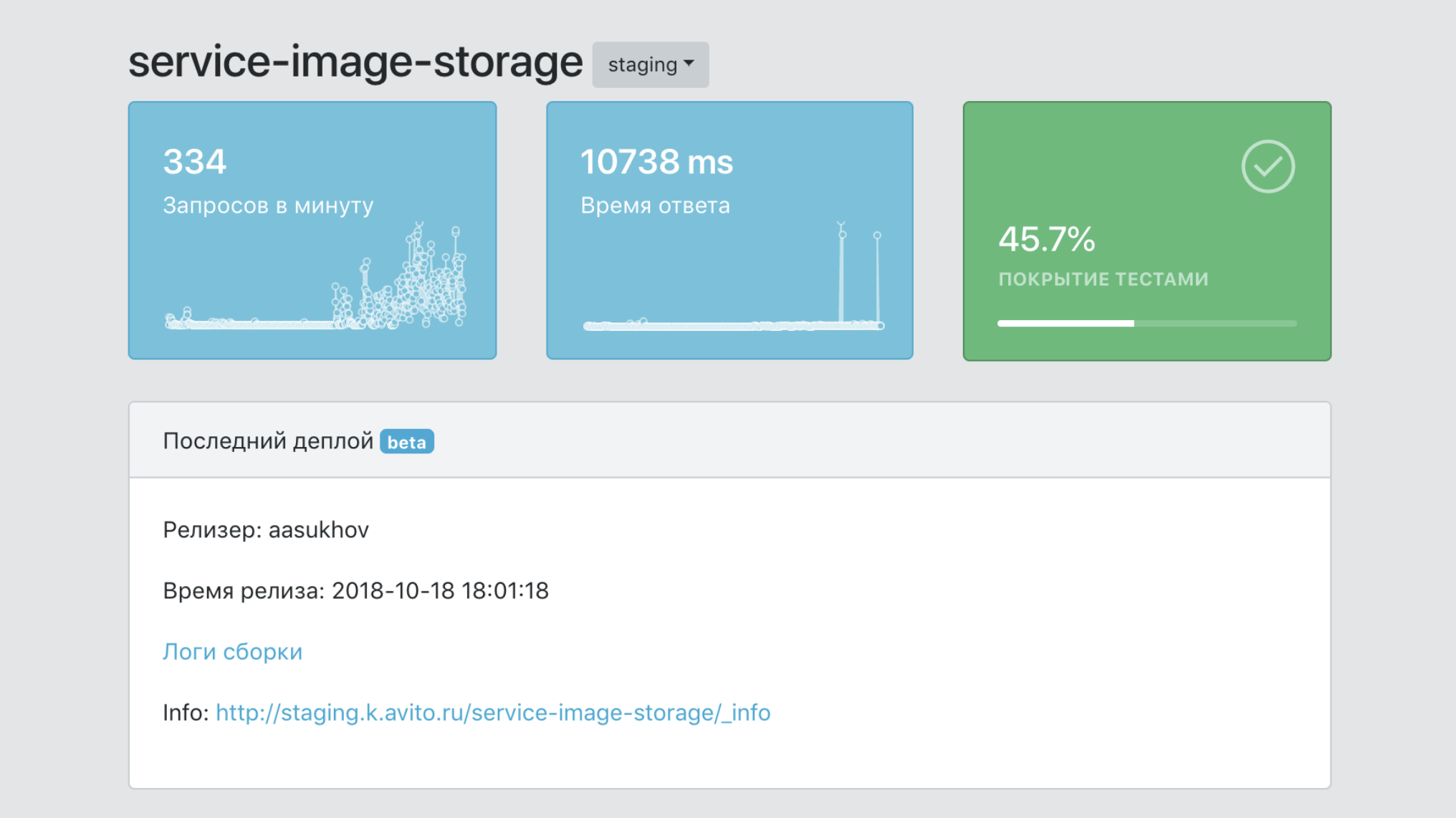
Total
Sebelum pengenalan PaaS, pengembang baru dapat menghabiskan beberapa minggu memilah semua alat yang diperlukan untuk meluncurkan layanan microser dalam produksi: Kubernetes, Helm, fitur internal TeamCity kami, mengatur koneksi ke database dan cache dalam bentuk toleran terhadap kesalahan, dll. Sekarang perlu beberapa jam untuk membaca quickstart dan membuat layanan itu sendiri.
Saya membuat laporan tentang topik ini untuk HighLoad ++ 2018, Anda dapat menonton video dan presentasi .
Track bonus untuk mereka yang telah membaca sampai akhir
Kami di Avito akan menyelenggarakan pelatihan tiga hari internal untuk pengembang dari Chris Richardson , seorang ahli dalam arsitektur layanan mikro. Kami ingin memberikan kesempatan untuk berpartisipasi di dalamnya kepada salah satu pembaca pos ini. Ini adalah program pelatihan.
Pelatihan akan diadakan dari 5 hingga 7 Agustus di Moskow. Ini adalah hari kerja yang akan sepenuhnya ditempati. Makan siang dan pelatihan akan diadakan di kantor kami, dan peserta yang dipilih membayar sendiri biaya perjalanan dan akomodasi.
Anda dapat mengajukan permohonan untuk berpartisipasi dalam formulir Google ini . Dari Anda - jawaban untuk pertanyaan mengapa Anda perlu menghadiri pelatihan dan informasi tentang cara menghubungi Anda. Jawab dalam bahasa Inggris, karena Chris akan memilih peserta yang mengikuti pelatihan.
Kami akan mengumumkan nama peserta pelatihan sebagai pembaruan untuk posting ini di jejaring sosial Avito untuk pengembang (AvitoTech di Facebook , Vkontakte , Twitter ) selambat-lambatnya 19 Juli.
UPD, 07/19: Kami menerima lusinan aplikasi. Chris memeriksa mereka dan memilih seorang peserta: bersama dengan rekan-rekan kami, Andrei Igumnov akan pergi belajar. Selamat!