Halo semuanya. Tim saya di Tinkoff sedang membangun sistem rekomendasi. Jika Anda senang dengan cashback bulanan Anda, maka ini adalah bisnis kami. Kami juga membangun sistem rekomendasi penawaran khusus dari mitra dan terlibat dalam koleksi Cerita individu dalam aplikasi Tinkoff. Dan kami senang berpartisipasi dalam kompetisi pembelajaran mesin untuk menjaga diri kami dalam kondisi yang baik.
Selama dua bulan, dari 18 Februari hingga 18 April, sebuah kompetisi diadakan di Boosters.pro untuk membangun sistem rekomendasi data nyata dari salah satu bioskop online Rusia terbesar, Okko . Penyelenggara bertujuan untuk meningkatkan sistem rekomendasi yang ada. Saat ini, kompetisi tersedia dalam mode kotak pasir , di mana Anda dapat menguji pendekatan Anda dan mengasah keterampilan Anda dalam membangun sistem rekomendasi.
Deskripsi Data
Akses ke konten di Okko dilakukan melalui aplikasi di TV atau smartphone, atau melalui antarmuka web. Konten dapat disewa®, dibeli (P) atau dilihat dengan berlangganan (S). Penyelenggara kompetisi memberikan data tentang pandangan selama N hari (N> 60), selain itu, informasi tentang peringkat dan penanda yang ditambahkan tersedia. Perlu diingat satu detail penting, jika pengguna menonton satu film beberapa kali atau beberapa episode dari seri, maka hanya tanggal transaksi terakhir dan total waktu yang dihabiskan per unit konten akan direkam dalam tablet.
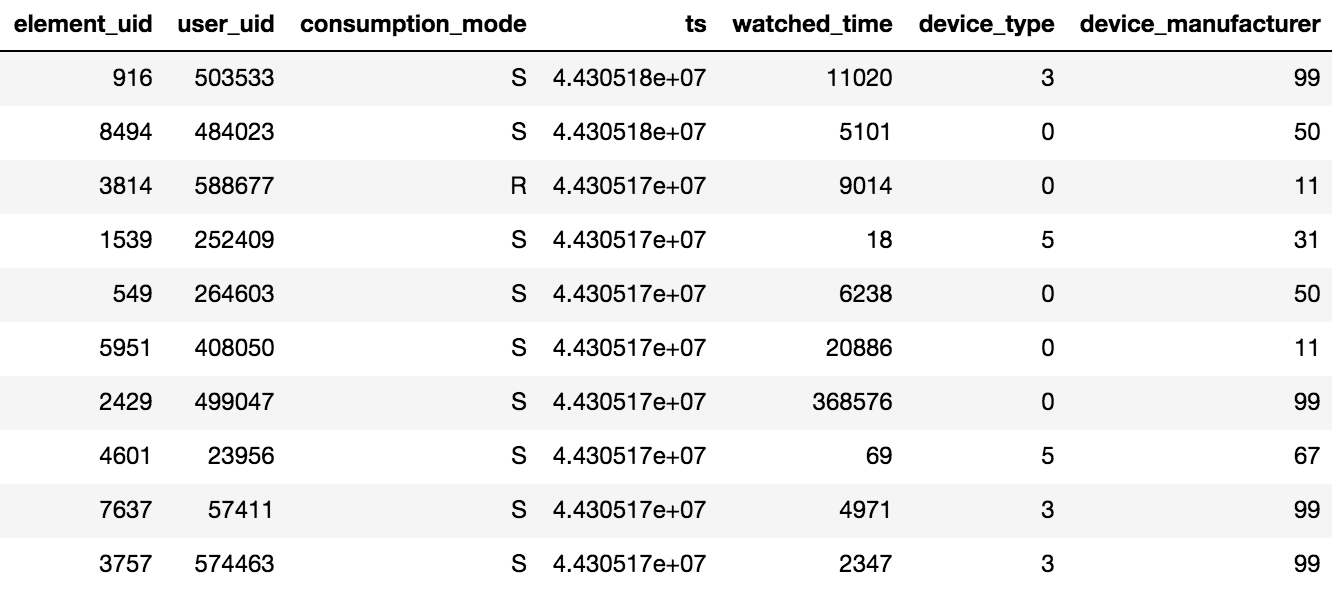
Sekitar 10 juta transaksi, 450 ribu peringkat dan 950 ribu fakta bookmark untuk 500 ribu pengguna disediakan.
Sampel tidak hanya berisi pengguna aktif, tetapi juga pengguna yang telah menonton beberapa film selama periode tersebut.
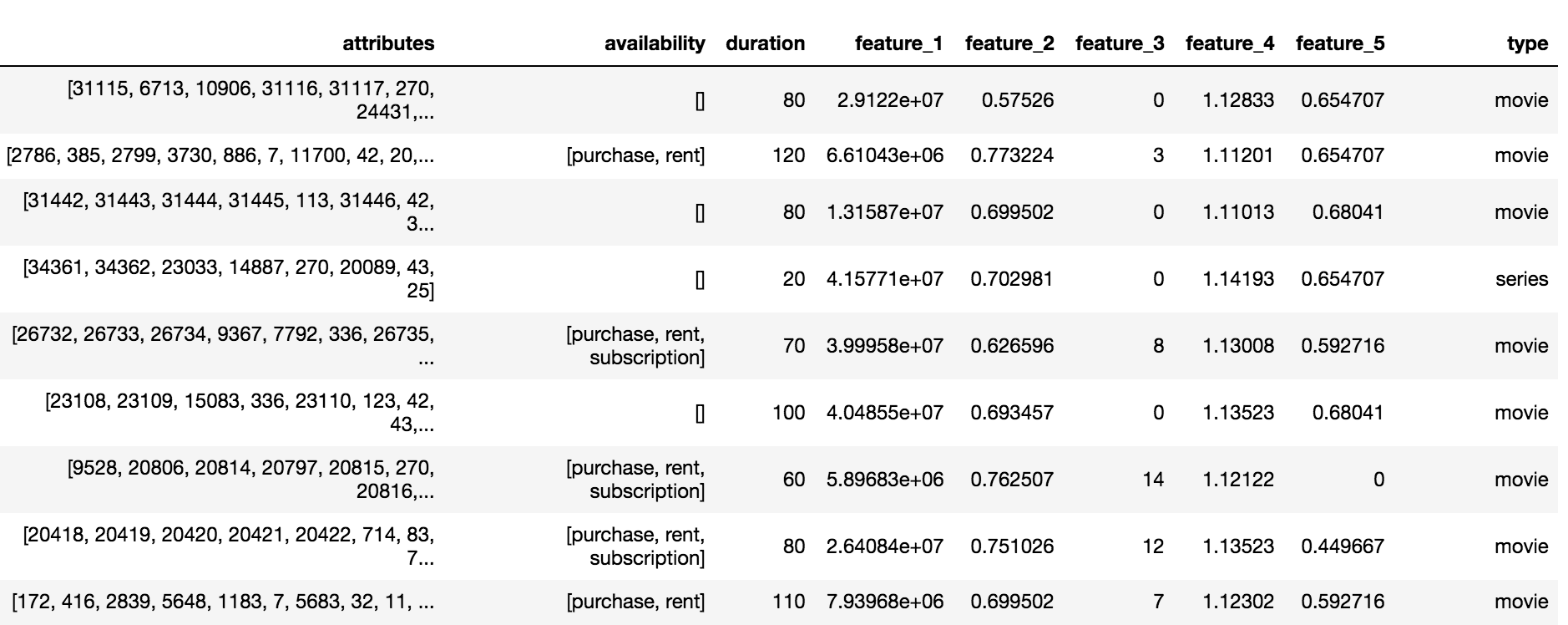
Katalog Okko berisi tiga jenis konten: film (film), seri (seri) dan film seri (multipart_movie), total 10.200 objek. Untuk setiap objek, satu set atribut dan atribut anonim (fitur_1, ..., feature_5) tersedia, berlangganan, sewa atau ketersediaan dan durasi pembelian.
Variabel dan Metrik Target
Tugas yang diperlukan untuk memprediksi banyak konten yang akan dikonsumsi pengguna selama 60 hari ke depan. Diyakini bahwa pengguna akan mengkonsumsi konten jika ia:
- Beli atau sewa
- Tonton lebih dari separuh film dengan berlangganan
- Tonton lebih dari sepertiga dari seri ini dengan berlangganan
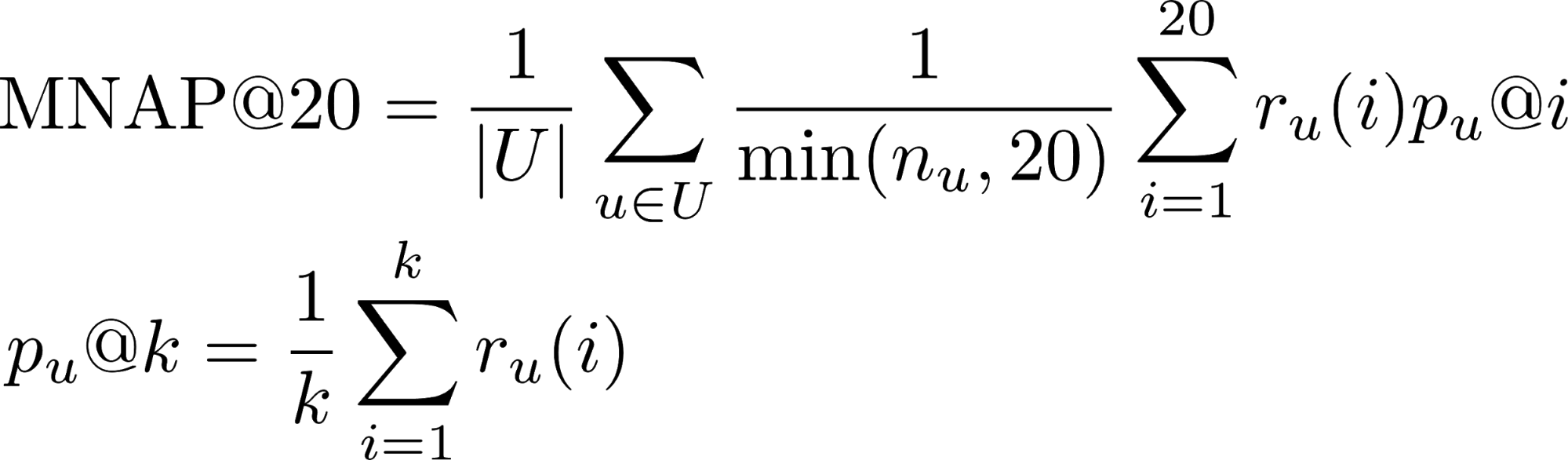
- r_u (i) - apakah pengguna Anda mengkonsumsi konten yang diprediksi kepadanya di tempat saya (1 atau 0)
- n_u - jumlah elemen yang dikonsumsi pengguna selama periode pengujian
- U - banyak pengguna uji
Anda dapat mempelajari lebih lanjut tentang metrik untuk tugas peringkat dari pos ini.
Sebagian besar pengguna menonton film sampai akhir, sehingga pangsa kelas positif pada transaksi adalah 65%. Kualitas algoritma dievaluasi menggunakan subset dari 50 ribu pengguna dari sampel yang disajikan.
Peringkat agregat
Keputusan kompetisi dimulai dengan agregasi semua interaksi pengguna dengan konten ke dalam skala peringkat tunggal. Diasumsikan bahwa jika pengguna membeli konten, ini berarti bunga maksimum. Film ini lebih pendek daripada seri, oleh karena itu untuk melihat seri secara keseluruhan, Anda perlu memberikan lebih banyak poin. Akibatnya, peringkat agregat dibentuk sesuai dengan aturan berikut:
- Pembagian film * 5
- Acara TV Bagikan * 10
- [Bookmarking film] * 0.5
- [Bookmark seri] * 1.5
- [Beli / sewa konten] * 15
- Peringkat + 2
Model tingkat pertama
Panitia memberikan solusi dasar berdasarkan penyaringan kolaboratif dengan skala Tf-IDF. Menambahkan semua jenis interaksi ke peringkat teragregasi, meningkatkan jumlah tetangga terdekat dari 20 menjadi 150 dan mengganti Tf-IDF dengan bobot BM25 tersingkir sekitar 0,03 pada LB (Papan Pemimpin).
Terinspirasi oleh posisi tim yang mengambil tempat ke-3 di RecSys Challenge 2018 , saya memilih model LightFM dengan kehilangan WARP sebagai model base kedua. LightFM dengan parameter hiper yang dipilih: learning_rate, no_components, item_alpha, user_alpha, max_sampled memberi 0,033 pada LB.

Validasi model dilakukan tepat waktu: 80% pertama interaksi jatuh ke kereta, 20% sisanya ke validasi. Untuk pengiriman pada LB, model dilatih pada seluruh dataset dengan parameter yang dipilih untuk validasi.
Pencampuran Model
Pada tahap sebelumnya, ternyata membangun dua garis dasar yang kuat, apalagi rekomendasi mereka berpotongan rata-rata untuk 60 persen dari konten yang direkomendasikan. Jika ada dua model yang kuat dan pada saat yang sama berkorelasi lemah, maka pencampuran mereka adalah langkah yang masuk akal.
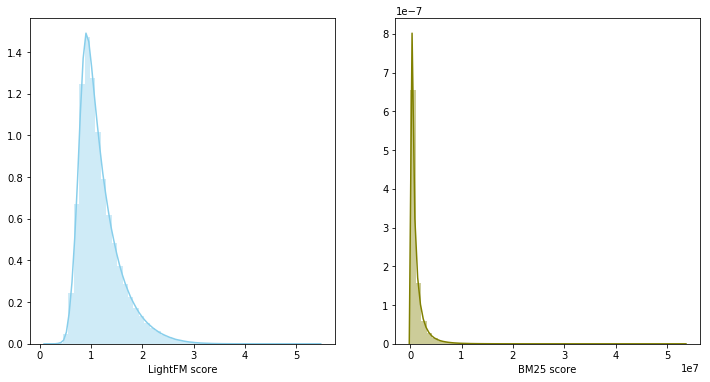
Dalam hal ini, skor model menjadi milik distribusi yang berbeda dan memiliki skala yang berbeda, sehingga diputuskan untuk menggunakan jumlah peringkat untuk menggabungkan kedua model. Blending model menghasilkan 0,0347 pada LB.

Model tingkat kedua
Sistem rekomendasi sering menggunakan pendekatan dua tingkat untuk membangun model: pertama, kandidat teratas dipilih oleh model tingkat pertama yang sederhana, kemudian top yang dipilih diurutkan kembali oleh model yang lebih kompleks dengan penambahan sejumlah besar fitur.

Dataset dibagi dalam waktu menjadi bagian pelatihan dan validasi. Sejumlah rekomendasi dikumpulkan untuk bagian validasi untuk setiap pengguna, yang terdiri dari kombinasi top200 prediksi model tingkat pertama dengan pengecualian film yang sudah ditonton. Selanjutnya, itu diperlukan untuk mengajarkan model untuk mengatur ulang hasil yang dihasilkan untuk setiap pengguna. Masalahnya dirumuskan dalam hal klasifikasi biner. Sepasang (pengguna, konten) milik kelas positif hanya jika pengguna mengkonsumsi konten selama periode validasi. Sebagai model tingkat kedua, peningkatan gradien digunakan, yaitu paket LightGBM.
Tanda
Model tingkat pertama untuk pasangan (pengguna, konten) mengevaluasi relevansi dalam bentuk kecepatan, pengurutan yang dalam urutan menurun Anda bisa mendapatkan peringkat. Model dilatih pada tanda-tanda pangkat dan kecepatan, bersama dengan tanda-tanda dari katalog konten, pingsan 0,0359 pada LB.
Dari bentuk distribusi fitur anonim pertama, disimpulkan bahwa ini adalah tanggal film muncul dalam katalog, oleh karena itu, model sangat dilatih ulang untuk fitur ini dengan skema validasi yang dipilih. Menghapus karakteristik dari sampel memberikan peningkatan LB menjadi 0,0367
Model LightFM, selain untuk memprediksi relevansi konten untuk pengguna, mengembalikan dua vektor: bias item dan bias pengguna, yang berkorelasi dengan tingkat popularitas konten dan jumlah film yang dilihat oleh pengguna. Menambahkan tanda menaikkan kecepatan pada LB menjadi 0,0388 .
Anda dapat menetapkan peringkat untuk suatu pasangan (pengguna, konten) sebelum atau setelah menghapus film yang sudah ditonton. Perubahan metode untuk yang terakhir memberikan peningkatan LB menjadi 0,0395 .
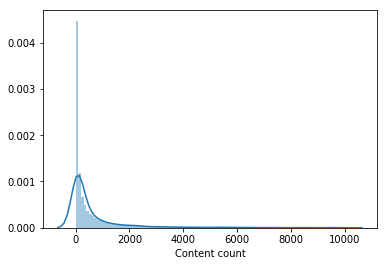
Hampir tidak ada yang menonton bagian penting dari katalog film. Konten yang ditonton oleh kurang dari 100 pengguna dihapus dari sampel untuk pelatihan model tingkat kedua, yang mengurangi katalog hingga setengahnya. Penghapusan konten yang tidak populer membuat pemilihan dari model tingkat pertama lebih relevan dan hanya setelah itu vektor pengguna dari LightFM meningkatkan kecepatan validasi dan memberikan peningkatan pada LB menjadi 0,0429 .
Selanjutnya, tanda ditambahkan - pengguna menambahkan bookmark ke buku, tetapi tidak melihat periode kereta, yang meningkatkan kecepatan pada LB menjadi 0,0447 . Juga, tanda-tanda tentang tanggal transaksi pertama dan terakhir ditambahkan, mereka menaikkan kecepatan ke 0,0457 pada LB.

Kami akan menganggap model ini final. Yang paling signifikan adalah tanda-tanda dari model tingkat pertama dan tanda-tanda anonim dari katalog konten.
Fitur-fitur berikut tidak meningkat ke model akhir:
- jumlah bookmark + pangsa konten yang dilihat dari bookmark - 0,0453 LB
- jumlah film yang dibeli 0,0451 LB
Tetapi ketika menyatu dengan model terakhir, mereka tersingkir 0,0465 pada LB. Terinspirasi oleh hasil pencampuran, model-model berikut dilatih secara terpisah:
- dengan fraksi yang berbeda dari sampel pelatihan untuk model tingkat pertama. Perpecahan 90% / 10% memberikan peningkatan, berbeda dengan pemisahan 95% / 5% dan 70% / 30%.
- dengan metode agregasi peringkat yang dimodifikasi.
- dengan tambahan film yang tidak populer pada pelatihan yang ditetapkan untuk model tingkat kedua. Untuk setiap unit konten, kompilasi 1000 pengguna dikompilasi.
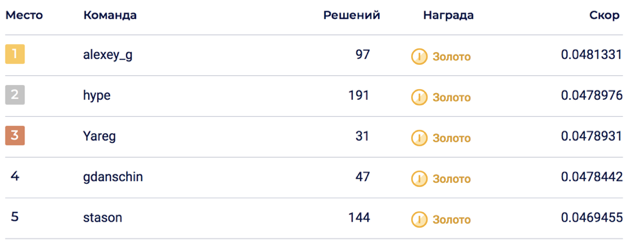
Pencampuran terakhir dari 6 model memungkinkan untuk mencapai 0,0469678 pada LB, yang sesuai dengan tempat ke-5.

Pada bagian pribadi, goncangan terjadi, yang melemparkan solusi ke tempat ke-2. Saya pikir solusinya ternyata berkelanjutan berkat pencampuran sejumlah besar model.
Tidak dimasukkan
Dalam proses penyelesaian kompetisi, banyak tanda-tanda yang muncul yang tampaknya masuk, tetapi sayangnya. Tanda dan pendekatan yang paling tepercaya:
- Atribut konten anonim. Tidak diketahui secara pasti apa yang dikandungnya, tetapi semua peserta dalam kompetisi percaya bahwa mereka berisi informasi tentang aktor, sutradara, komposer ... Dalam keputusan saya, saya mencoba menambahkannya dalam beberapa format: populer sebagai karakter biner, mengeluarkan matriks konten atribut menggunakan LightFM dan BigARTM, dan kemudian tarik vektor dan menambahkannya ke model tingkat kedua.
- Vektor konten dari model LigthFM di model tingkat kedua.
- Atribut perangkat tempat pengguna melihat konten.
- Menurunkan berat konten populer untuk model tingkat kedua.
- Proporsi film / acara TV sehubungan dengan jumlah konten yang dilihat.
- Metrik peringkat dari CatBoost.
Fakta menarik tentang kompetisi
- Solusi Top1 ternyata lebih buruk daripada model produk okko 0,048 vs 0,062. Harus diingat bahwa model produk sudah diluncurkan pada saat pengambilan sampel.
- Sekitar satu minggu setelah dimulainya kompetisi, dataset diubah, bagi mereka yang berpartisipasi sejak awal mereka menambahkan 30 kiriman, yang secara tak terduga terbakar setelah tim digabungkan.
- Validasi tidak selalu berkorelasi dengan LB, yang mengindikasikan kemungkinan guncangan.
Kode keputusan
Solusinya tersedia di github dalam bentuk dua jupyter-laptop: agregasi peringkat, model pelatihan tingkat pertama dan kedua.
Solusi tempat ke-3 juga tersedia di github .
Keputusan penyelenggara
Alih-alih seribu kata, saya melampirkan fitur teratas dari penyelenggara.
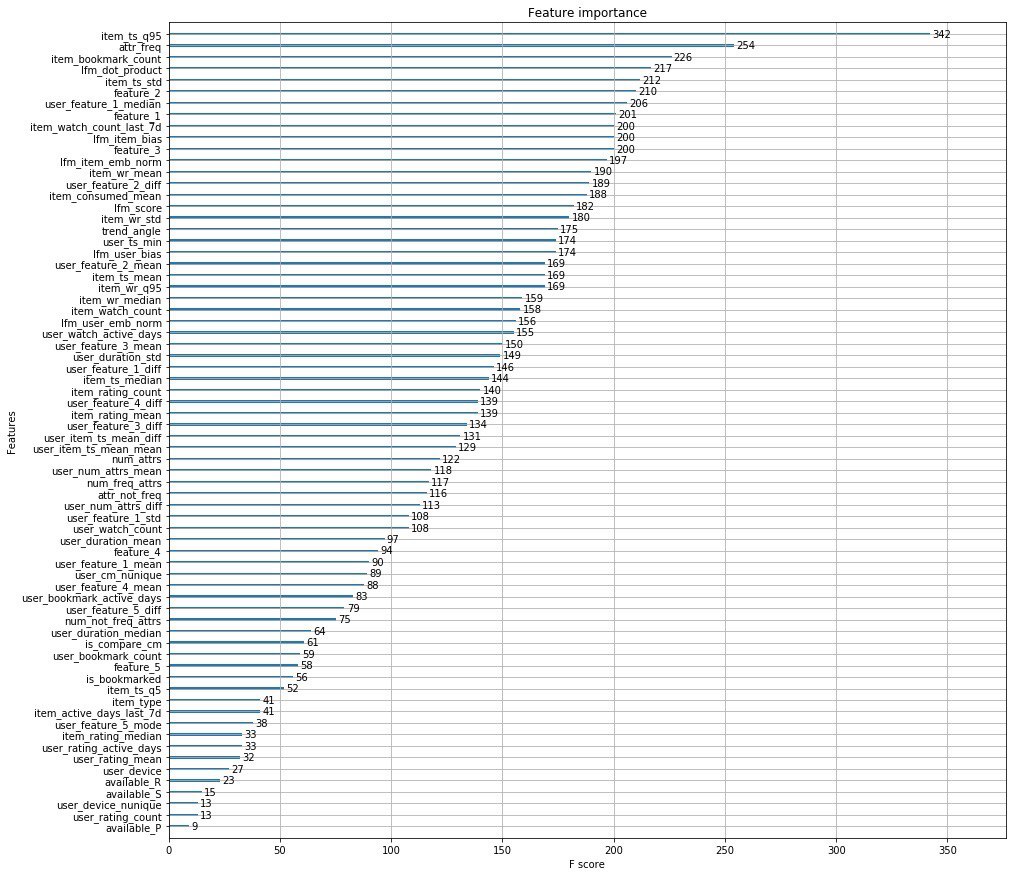
Selain itu, orang-orang dari Okko merilis sebuah artikel di mana mereka berbicara tentang tahap pengembangan mesin rekomendasi mereka.
PS di sini Anda dapat melihat kinerja di Data Fest 6 tentang solusi untuk masalah ini.