
Jika ada proyek Anda menggunakan data yang disimpan dalam database Azhurov, maka sangat mungkin Anda memiliki kesempatan untuk menggunakan pencarian data menggunakan pencarian Azure. Anda dapat mencari tidak hanya dengan basis data (Azure Cosmos DB, Azure SQL Database, SQL Server yang dihosting di VM Azure), tetapi juga oleh Blob (Azure Blob Storage, Azure Table Storage).
Pencarian memiliki tarif gratis, yang memungkinkan Anda membuat hingga tiga indeks dengan ukuran total hingga 50 Mb. Tarif gratis tidak memiliki kemampuan load balancing, tetapi cukup cocok untuk digunakan.
Berurusan dengan pencarian tampak cukup sederhana bagi saya (meskipun tidak selalu jelas). Ada 3 jenis objek: sumber data, indeks dan pengindeks. Objek utama, mungkin, adalah indeks. Dialah yang bertanggung jawab untuk mencari dan apa yang harus dicari. Datasource adalah koneksi data, dan pengindeks adalah pekerjaan yang memperbarui data indeks.
Portal UI memungkinkan Anda untuk mengimpor data dan membuat ketiga objek. Peluang akan lewat dan menambah kemampuan kognitif untuk pencarian. Jika database SQL ada dalam langganan, maka Anda dapat memilihnya saat membuat sumber data. Meskipun kata sandi karena alasan tertentu, Anda masih harus memasukkan. Jika Anda ingin menggunakan Cosmos DB, Anda harus memasukkan string koneksi secara manual. Jangan lupa menunjukkan di baris dan database, menambahkan di akhir baris Database = YOUR_BASE_NAME
Setelah memilih sumber data, Anda akan diminta untuk menggunakan kemampuan pencarian kognitif. Perangkat keterampilan default masih cukup kecil: Anda dapat menentukan bahasa, mengekstrak nama, nama organisasi, tempat, dan frasa kunci. Ada juga peluang menarik untuk menentukan sifat teks untuk emosi positif atau negatif menggunakan deteksi sentimen. Keahlian ini harus nyaman digunakan dengan ulasan produk di toko online. Dimungkinkan untuk membuat keterampilan Anda sendiri menggunakan deskripsi API.
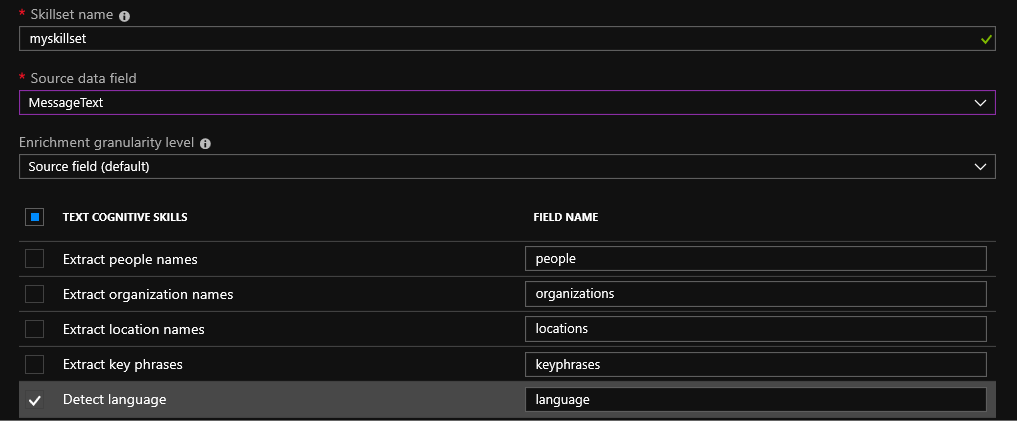
Untuk file yang diunggah ke gumpalan, OCR (Pengenalan Karakter Optik) dimungkinkan. Pengakuan tulisan tangan (sejauh ini hanya bahasa Inggris) dan teks cetak dimungkinkan. Dengan menggunakan layanan kognitif, dimungkinkan untuk mengidentifikasi berbagai objek dalam foto. Misalnya, tempat atau selebritas terkenal.
Langkah selanjutnya adalah membuat indeks. Satu-satunya opsi untuk mode Pencarian hari ini adalah "menganalisisInfixMatching"
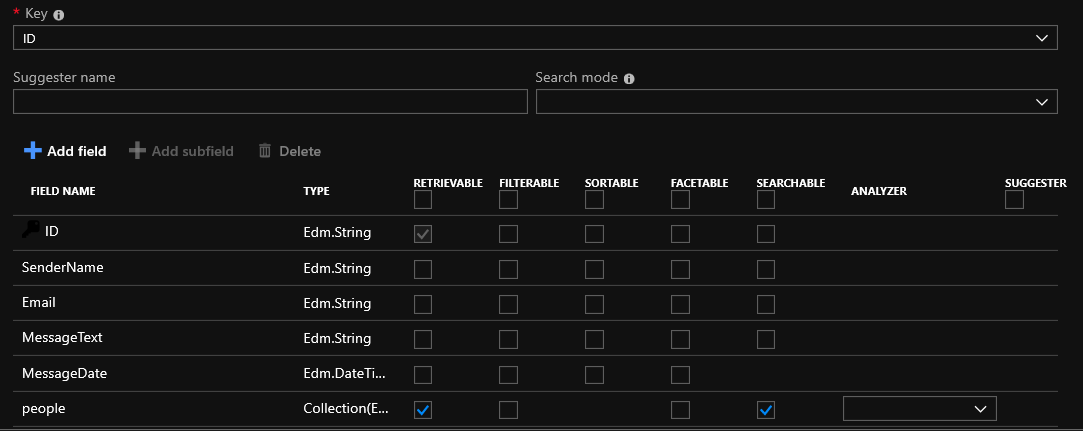
Pada titik ini, Anda dapat mencentang kotak di sebelah bidang di tabel Anda atau menambahkan beberapa bidang baru ke indeks. Untuk jaga-jaga, saya akan menjelaskan kemungkinan bidang:
Retrievable - bidang akan ada di hasil pencarian
Dapat difilter - nilai bidang dapat difilter
Diurutkan - Anda dapat mengurutkan hasilnya berdasarkan bidang ini
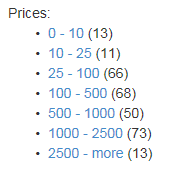
Facetable - semacam pengelompokan berdasarkan karakteristik tertentu. Misalnya, menggunakan facet ekspresi berikut = listPrice, nilai: 10 | 25 | 100 | 500 | 1000 | 2500, Anda bisa mendapatkan uraian berikut hasilnya menjadi grup
Dapat dicari - bidang ini akan mencari
Bidang Penganalisis menyarankan untuk memilih penganalisis untuk berbagai bahasa. 2 versi digunakan - Lucene dan Microsoft . Untuk memahami apa perbedaannya, Anda perlu memahami apa perbedaan antara dua istilah berikut:
Stamming adalah proses menemukan dasar kata untuk kata sumber yang diberikan. Batang (Bahasa Inggris) - batang, batang, asal. Stemming menggunakan algoritma. Sering memotong kata-kata dengan menghilangkan akhiran dan akhiran, memperoleh dasar kata.
Lemmatization adalah proses mereduksi bentuk kata menjadi lemma - bentuk normal (kosakata). Lemma adalah bentuk kata dasar yang kanonik. Lemmatization menggunakan pencarian kamus yang berisi berbagai bentuk kata.
Alat analisis Lucene menggunakan stemming. Penganalisa Microsoft menggunakan lemmatization.
Secara default, jika tidak ada yang dipilih, Lucene digunakan. Tetapi jika Anda mencari data dalam bahasa tertentu, maka tidak diragukan lagi lebih baik menggunakan penganalisa untuk bahasa ini.
Suggester - memungkinkan Anda untuk memberikan petunjuk dengan dokumen yang berisi teks yang dimasukkan menggunakan huruf awal pencarian.
Jika Anda menggunakan probester di Azure Search di aplikasi klien, Anda akan memiliki 2 opsi untuk menggunakannya: counsester itu sendiri atau autocomplete . Singkatnya, prompt menyarankan sepenuhnya seluruh baris dari bidang tabel, dan pelengkapan otomatis hanya menawarkan untuk menyelesaikan kata atau ungkapan dari beberapa kata. Artikel terbaik tentang perbedaan antara mode prompt dan autocomplete dijelaskan dalam artikel berikut: Autocomplete di Azure Search now in public preview Artikel ini memiliki gif yang sangat visual.
Pada tahap pengindeks , Anda harus menentukan kolom tanda air tinggi . Ini adalah bidang yang berubah setiap kali catatan diubah. Biasanya ini adalah sesuatu seperti bidang dengan tanggal perubahan terakhir atau bidang _ts di Cosmos DB. Selama pengindeksan, jika nilai bidang diubah, maka indeks juga akan berubah.
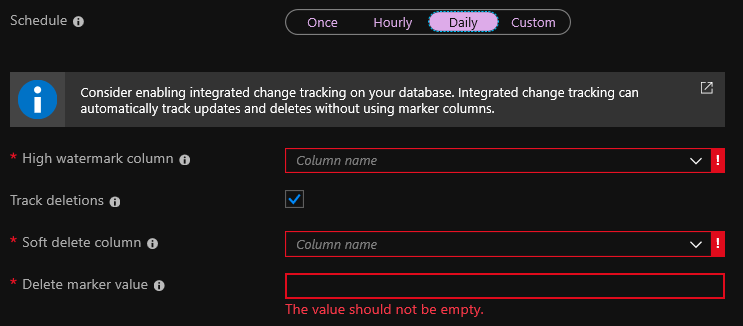
Penghapusan trek adalah opsi untuk menghapus entri dari indeks secara otomatis. Tetapi untuk ini, Anda harus mengkonfigurasi soft delete di dalam database Anda. Jika Anda menggunakan penghapusan lunak, maka ketika Anda menghapus catatan, itu tidak dihapus, tetapi hanya ditandai sebagai dihapus. Opsi standar adalah menambahkan bidang isDeleted ke database dan mengaturnya ke true jika catatan dihapus.
Atau, Anda dapat mengirim permintaan penghapusan dari pencarian ke Azure Search API setiap kali Anda menghapus entri dari database. Dalam hal ini, kotak centang penghapusan Trak dapat dihilangkan. Tapi saya tidak terlalu suka opsi ini, karena jika permintaan penghapusan tidak berfungsi, catatan akan tetap ada dalam indeks. Bagi saya, tidak ada cukup kesempatan untuk membangun kembali indeks sekali dalam periode waktu tertentu sepenuhnya.
Terlepas dari semua kenyamanan portal, setelah membuat Anda dapat menambahkan beberapa bidang baru ke indeks, tetapi Anda tidak dapat mengubah yang sudah ada. Apa yang harus dilakukan jika Anda perlu mengubah sesuatu? Anda dapat membuat ulang indeks. Hapus yang sudah ada dan buat yang baru yang berisi perubahan yang diperlukan. Menggunakan portal untuk melakukan ini adalah tugas yang agak suram. Saya menggunakan API untuk tujuan ini. Menggunakan aplikasi seperti Postman, Anda bisa mendapatkan indeks JSON dan menggunakannya untuk menulis permintaan pembuatan indeks. Anda hanya perlu melakukan perubahan kecil (misalnya, menghapus bidang sistem "@ odata.context" dan "@ odata.etag").
Agar dapat bekerja dengan API, Anda harus mengambil kunci dari portal, yang harus ditambahkan ke header setiap permintaan API. Kuncinya diambil di sini:
Permintaan untuk mendapatkan data indeks adalah:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
api-key: [admin key] harus ditambahkan ke tajuk api-key: [admin key]
Membuat indeks dimungkinkan menggunakan salah satu dari dua pertanyaan berikut:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
atau
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
Dalam isi, Anda harus menentukan JSON dengan isi indeks. Versi terbaru saat ini adalah 2019-05-06, dan sebelum itu digunakan untuk waktu yang lama 2017-11-11
Bekerja melalui API, Anda dapat menggunakan beberapa fitur pencarian yang tidak tersedia di portal.
Untuk memberikan prioritas pada beberapa bidang dalam pencarian, Anda dapat menggunakan profil penilaian .
JSON berikut yang ditambahkan ke permintaan memberikan bidang "judul" keuntungan ganda dari bidang "info":
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
Selain kemampuan untuk memberikan prioritas beberapa bidang menggunakan bobot, dimungkinkan untuk menggunakan beberapa fungsi yang telah ditentukan: kesegaran, besarnya, jarak, dan tag.
Kesegaran hanya digunakan dengan bidang DateTime dan memungkinkan Anda untuk membuka catatan terbaru dalam pencarian. Magnitude digunakan dengan bidang int dan ganda. Dengan baik dan sesuai, fungsi ini baik untuk digunakan dengan bidang menyimpan harga, jumlah unduhan dan informasi numerik lainnya. Jarak hanya digunakan dengan bidang seperti Edm.GeographyPoint dan dimunculkan dalam pencarian berdasarkan jarak dari lokasi tertentu. Jika tag ditentukan sebagai jenis fungsi, maka dokumen yang berisi tag yang muncul dalam string pencarian akan dimunculkan dalam pencarian.
Salah satu opsi paling populer adalah mengambil dokumen terbaru dalam pencarian seperti ini:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Dokumen yang bidang dokumenTanggalnya berisi tanggal tujuh hari terakhir ("P7D") akan dimunculkan.
Setelah Anda membuat profil penilaian, Anda dapat menentukan namanya dalam permintaan. Hanya dalam kasus ini bidang yang diperlukan akan dimunculkan dalam pencarian.
Baca selengkapnya di dokumentasi resmi: Tambahkan profil penilaian ke indeks Pencarian Azure
Kebijakan Deteksi Perubahan Data
API menyediakan sedikit lebih banyak fitur untuk sumber data. Seperti yang Anda baca di atas, saat membuat sumber data, Anda bisa menentukan bidang yang digunakan untuk menentukan apakah data telah berubah. Dalam bentuk JSON, tampilannya seperti ini:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } soft delete policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Jika Anda menggunakan SQL Server dan basis data Anda mendukung Ubah Pelacakan, maka catatan yang dihapus dapat dihapus dari indeks secara otomatis. Menentukan highWaterMarkColumnName dalam kasus ini tidak diperlukan. Cukup menentukan SqlIntegratedChangeTrackingPolicy alih-alih HighWaterMarkChangeDetectionPolicy
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
Sangat nyaman. Namun ada nuansa yang tidak memungkinkan untuk menikmati fitur ini sepenuhnya.
Pertama, SqlIntegratedChangeTrackingPolicy tidak dapat digunakan dengan tampilan. Kedua, tabel tidak boleh memiliki kunci primer komposit. Tak perlu dikatakan bahwa versi SQL Server harus lebih atau kurang baru. Dan akhirnya, Ubah Pelacakan harus diaktifkan untuk database dan tabel yang digunakan oleh pencarian. Untuk database, ini menyala seperti ini:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
Dan untuk tabel seperti ini:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Tapi itu belum semuanya. Sangat disarankan agar Anda mengaktifkan isolasi snapshot untuk basis.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
Selain menari dengan rebana saat menginstal Ubah TraCking untuk database bagi saya, kerugiannya adalah ketidakmampuan untuk menggunakan tampilan. Jadi saya biasanya masih harus menggunakan HighWaterMarkChangeDetectionPolicy
Pencarian Data
Secara default, pencarian Azure menggunakan sintaks kueri sederhana . Ini mungkin tidak mengejutkan, tetapi cukup sederhana:
wifi + pencarian mewah untuk kata-kata wifi dan mewah pada saat yang sama
"hotel mewah" sedang mencari frasa
wifi | kemewahan mencari kata wifi atau kata kemewahan
wifi –luxury mencari teks dengan kata wifi tetapi tanpa kata mewah
lux mencari kata-kata yang dimulai dengan lux
Dimungkinkan untuk menggabungkan aturan pencarian menggunakan tanda kurung. Misalnya, aturan motel + (wifi | mewah) mencari kata motel dan kata wifi atau kata mewah
Sangat menyenangkan bahwa Azure Search dapat menggunakan sintaks Lucene . Untuk menggunakannya, perlu menambahkan queryType = penuh ke permintaan pencarian
Perbedaan antara sintaksis Azure dan Lucene klasik hanya dalam ketiadaan kisaran.
Jadi di Azure Search Anda tidak bisa: mod_date:[20020101 TO 20030101]
Namun dalam Azure Search, Anda dapat menggunakan $ filter dengan sintaks ODATA . Berikut ini contoh filter:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Filter juga dapat digunakan dengan sintaks kueri sederhana.
Di Lucene, logika "atau" diimplementasikan menggunakan OR atau ||
Kedua nilai dapat ditemukan dengan menentukan pernyataan "dan" dengan: AND , && atau +
Untuk "tidak", Anda dapat menggunakan salah satu dari yang berikut: BUKAN ,! atau -
Instruksi “not” memiliki fitur umum untuk sintaksis sederhana dan Lucene. Perilakunya tergantung pada mode pencarian, yang dapat diatur di searchMode = all dan di searchMode = any (nilai ini digunakan secara default). Dalam mode apa pun, mencari wifi -luxury akan menemukan dokumen dengan kata wifi atau dokumen tanpa kata mewah. Dalam semua mode, dengan permintaan yang sama, ia akan menemukan dok dengan kata wifi dan secara bersamaan tanpa kata mewah.
Mari kita lihat beberapa fitur Lucene yang menarik.
Pencarian fuzzy memungkinkan Anda untuk mencari kata-kata yang berbeda dari pencarian dengan satu atau lebih huruf. Artinya, ada baiknya berurusan dengan kesalahan ketik. Misalnya, pencarian "biru ~" atau "biru ~ 1" akan mengembalikan Anda dengan "biru" dan "biru" dan bahkan "lem". Tetapi pada saat yang sama, pencarian "analis bisnis" akan berarti bisnis atau analis
Kedekatan memungkinkan Anda untuk mencari kata-kata yang ada di dekatnya. Misalnya, "bandara hotel" ~ 5 akan menemukan kata "hotel" dan "bandara" yang terdapat dalam teks tidak lebih dari 5 kata satu sama lain.
Peningkatan jangka memungkinkan Anda untuk menetapkan prioritas kata dalam pencarian. Contoh: "rock ^ 2 elektronik" mencari kata-kata rock dan elektronik, tetapi entri dengan kata rock dalam pencarian akan ditampilkan di atas.
Ekspresi reguler - menggunakan ekspresi reguler. Semuanya di sini sesuai dengan dokumentasi resmi Lucene regex. Anda dapat menemukannya dengan tautan berikut . Saat mencari, ekspresi reguler harus ditempatkan di antara garis miring "/". Misalnya, seperti ini: / [mh] otel /
Jika string pencarian Anda mengandung karakter khusus, mereka harus lolos dengan garis miring terbalik. Contoh karakter untuk melarikan diri: + - && ||! () {} [] ^ "~ * ?: \ /
Pencarian dapat dilakukan menggunakan permintaan GET. Contoh resmi adalah ini:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Tetapi Anda dapat menggunakan permintaan POST dengan isi. Sekali lagi, contoh resmi:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Jika Anda menggunakan permintaan GET atau POST dengan aplikasi tipe data / x-www-form-urlencoded, maka Anda harus menyandikan karakter yang tidak aman dan dilindungi undang-undang.
Simbol /?: @ = & dicadangkan
Karakter `` <> #% {} | \ ^ ~ [] tidak aman.
Misalnya, simbol # akan menjadi% 23 dan simbol? menjadi% 3F
Beberapa tautan untuk pengembang.
Jika .NET adalah pengembang, maka Anda dapat menggunakan paket NuGet Microsoft.Azure.Search.Selain itu, ada contoh di NodeJS dan Java .
Contoh aplikasi sederhana pada .NET Core dapat Anda temukan di sini sampel pencarian ASP.NET Core Azure