Sampai saat ini, layanan Bitrix24 tidak memiliki ratusan gigabit lalu lintas, tidak ada armada server yang besar (walaupun tentu saja ada banyak server yang ada). Tetapi bagi banyak pelanggan, ini adalah alat utama untuk bekerja di perusahaan, itu adalah aplikasi bisnis yang sangat penting. Karena itu, jatuh - yah, tidak mungkin. Tetapi bagaimana jika kejatuhan itu benar-benar terjadi, tetapi layanan itu "memberontak" begitu cepat sehingga tidak ada yang memperhatikan sesuatu? Dan bagaimana Anda mengatur penerapan failover tanpa kehilangan kualitas pekerjaan dan jumlah pelanggan? Alexander Demidov, direktur layanan cloud Bitrix24, memberi tahu blog kami tentang bagaimana sistem cadangan telah berevolusi selama 7 tahun keberadaan produk.

“Dalam bentuk SaaS, kami meluncurkan Bitrix24 7 tahun yang lalu. Kesulitan utama, mungkin, adalah sebagai berikut: sebelum diluncurkan di depan umum dalam bentuk SaaS, produk ini ada hanya dalam format solusi kotak. Pelanggan membelinya dari kami, meletakkannya di server mereka, mengatur portal perusahaan - solusi umum untuk komunikasi karyawan, penyimpanan file, manajemen tugas, CRM, itu saja. Dan pada 2012, kami memutuskan bahwa kami ingin meluncurkannya sebagai SaaS, mengelola sendiri, memberikan toleransi kesalahan dan keandalan. Kami memperoleh pengalaman dalam proses tersebut, karena sampai saat itu kami tidak memilikinya - kami hanya produsen perangkat lunak, bukan penyedia layanan.
Saat meluncurkan layanan, kami memahami bahwa yang paling penting adalah memastikan toleransi kesalahan, keandalan, dan ketersediaan layanan yang konstan, karena jika Anda memiliki situs biasa yang sederhana, toko, misalnya, dan telah jatuh dari Anda dan terletak satu jam - hanya Anda sendiri yang menderita, Anda kehilangan pesanan , Anda kehilangan pelanggan, tetapi untuk klien Anda sendiri - baginya ini tidak terlalu kritis. Dia kesal, tentu saja, tetapi pergi dan membeli di situs lain. Dan jika ini adalah aplikasi yang semua pekerjaan dalam perusahaan, komunikasi, solusi terkait, maka hal yang paling penting adalah untuk mendapatkan kepercayaan dari pengguna, yaitu, tidak mengecewakan mereka dan tidak jatuh. Karena semua pekerjaan bisa bangun jika sesuatu di dalam tidak berfungsi.
Bitrix 24 sebagai SaaS
Prototipe pertama yang kami kumpulkan setahun sebelum peluncuran publik, pada 2011. Berkumpul sekitar seminggu, tampak, bengkok - dia bahkan bekerja. Artinya, dimungkinkan untuk masuk ke formulir, masukkan nama portal di sana, portal baru sedang dibuka, basis pengguna sedang disiapkan. Kami melihatnya, mengevaluasi produk pada prinsipnya, mematikannya, dan menyelesaikannya setahun kemudian. Karena kami memiliki tugas besar: kami tidak ingin membuat dua basis kode yang berbeda, kami tidak ingin mendukung produk kotak yang terpisah, secara terpisah solusi cloud - kami ingin melakukan semua ini dalam kerangka satu kode.

Aplikasi web pada waktu itu adalah satu server tempat beberapa kode php dijalankan, basis mysql, file sedang diunduh, dokumen, gambar diletakkan di unggah ayah - yah, semuanya berfungsi. Sayangnya, tidak mungkin untuk menjalankan layanan web yang sangat berkelanjutan ini. Tembolok yang didistribusikan tidak didukung di sana, replikasi basis data tidak didukung.
Kami merumuskan persyaratan: kemampuan ini untuk ditempatkan di lokasi yang berbeda, untuk mendukung replikasi, idealnya ditempatkan di pusat data yang berbeda secara geografis. Pisahkan logika produk dan, pada kenyataannya, penyimpanan data. Secara dinamis dapat skala sesuai dengan beban, umumnya membuat statika. Dari pertimbangan ini, sebenarnya, ada persyaratan untuk produk, yang baru saja kami kembangkan sepanjang tahun. Selama waktu ini, di platform yang ternyata bersatu - untuk solusi kotak, untuk layanan kami sendiri - kami memberikan dukungan untuk hal-hal yang kami butuhkan. Dukungan untuk replikasi mysql di tingkat produk itu sendiri: yaitu, pengembang yang menulis kode tidak berpikir tentang bagaimana permintaannya akan didistribusikan, ia menggunakan api kami, dan kami dapat dengan benar mendistribusikan permintaan tulis dan baca antara tuan dan budak.
Kami membuat dukungan tingkat produk untuk berbagai toko objek cloud: penyimpanan google, amazon s3, - plus, dukungan untuk open stack swift. Oleh karena itu, baik bagi kami sebagai layanan maupun bagi pengembang yang bekerja dengan solusi kotak: jika mereka hanya menggunakan api kami untuk bekerja, mereka tidak berpikir di mana file akan disimpan, baik secara lokal pada sistem file atau ke dalam penyimpanan file objek. .
Akibatnya, kami segera memutuskan bahwa kami akan memesan pada tingkat pusat data secara keseluruhan. Pada 2012, kami meluncurkan sepenuhnya di Amazon AWS, karena kami sudah memiliki pengalaman dengan platform ini - situs web kami sendiri dihosting di sana. Kami tertarik oleh fakta bahwa di setiap wilayah di Amazon ada beberapa zona akses - pada kenyataannya, dalam terminologi mereka, beberapa pusat data yang lebih atau kurang independen satu sama lain dan memungkinkan kami untuk memesan di tingkat pusat data secara keseluruhan: jika tiba-tiba gagal, database master-master direplikasi, server aplikasi web dicadangkan, dan statis dipindahkan ke penyimpanan objek s3. Bebannya seimbang - pada saat itu elb Amazon, tetapi sedikit kemudian kami sampai pada penyeimbang kami sendiri, karena kami membutuhkan logika yang lebih kompleks.
Apa yang mereka inginkan, mereka mendapatkannya ...
Semua hal dasar yang ingin kami berikan - toleransi kesalahan dari server itu sendiri, aplikasi web, database - semuanya bekerja dengan baik. Skenario paling sederhana: jika beberapa aplikasi web gagal, maka semuanya sederhana - dimatikan dari keseimbangan.

Penyeimbang mesin (maka itu adalah elb Amazon) yang menabrak mesin itu sendiri ditandai tidak sehat, mematikan distribusi beban pada mereka. Autoscaling Amazon bekerja: ketika beban bertambah, mobil baru ditambahkan ke grup autoscaling, beban didistribusikan ke mobil baru - semuanya baik-baik saja. Dengan penyeimbang kami, logikanya kira-kira sama: jika sesuatu terjadi pada server aplikasi, kami menghapus permintaan darinya, membuang mesin-mesin ini, memulai yang baru dan terus bekerja. Skema selama bertahun-tahun telah sedikit berubah, tetapi terus bekerja: sederhana, dapat dimengerti, dan tidak ada kesulitan dengan ini.
Kami bekerja di seluruh dunia, beban puncak pelanggan benar-benar berbeda, dan, dengan cara yang baik, kami harus dapat melakukan pekerjaan pemeliharaan tertentu dengan komponen sistem kami kapan saja - tanpa terlihat oleh pelanggan. Oleh karena itu, kami memiliki kesempatan untuk mematikan basis data dari pekerjaan, mendistribusikan kembali beban pada pusat data kedua.
Bagaimana cara kerjanya? - Kami mengalihkan lalu lintas ke pusat data yang berfungsi - jika ini merupakan kecelakaan di pusat data, maka sepenuhnya, jika ini adalah pekerjaan yang direncanakan dengan basis satu, maka kami bagian dari lalu lintas yang melayani klien ini, beralih ke pusat data kedua, berhenti replikasi. Jika Anda membutuhkan mesin baru untuk aplikasi web, karena beban pada pusat data kedua telah meningkat, mereka secara otomatis mulai. Kami menyelesaikan pekerjaan, replikasi dikembalikan, dan kami mengembalikan seluruh beban kembali. Jika kita perlu mirror beberapa pekerjaan di DC kedua, misalnya, instal pembaruan sistem atau ubah pengaturan di database kedua, maka, secara umum, kami mengulangi hal yang sama, hanya dengan cara lain. Dan jika ini adalah kecelakaan, maka kami melakukan semuanya dalam basi: dalam sistem pemantauan kami menggunakan mekanisme event-handler. Jika beberapa pemeriksaan berfungsi untuk kami dan statusnya menjadi kritis, maka penangan ini diluncurkan, penangan yang dapat menjalankan logika ini atau itu. Untuk setiap basis data, kami telah mendaftarkan server mana yang gagal untuk itu, dan di mana Anda perlu beralih lalu lintas jika tidak tersedia. Kami - seperti yang telah dikembangkan secara historis - digunakan dalam satu bentuk atau nagios lain atau garpu-garpu lainnya. Pada prinsipnya, mekanisme serupa ada di hampir semua sistem pemantauan, kami belum menggunakan sesuatu yang lebih rumit, tapi mungkin suatu hari nanti kami akan melakukannya. Sekarang pemantauan dipicu oleh tidak dapat diaksesnya dan memiliki kemampuan untuk mengubah sesuatu.
Sudahkah kita memesan semuanya?
Kami memiliki banyak pelanggan dari Amerika Serikat, banyak pelanggan dari Eropa, banyak pelanggan yang lebih dekat ke Timur - Jepang, Singapura dan sebagainya. Tentu saja, sebagian besar pelanggan di Rusia. Artinya, pekerjaan masih jauh dari berada di satu wilayah. Pengguna menginginkan tanggapan cepat, ada persyaratan untuk mematuhi berbagai undang-undang setempat, dan di setiap wilayah kami memesan dua pusat data, ditambah ada beberapa layanan tambahan yang, nyaman untuk ditempatkan di dalam satu wilayah - untuk pelanggan yang ada di pekerjaan wilayah. Penangan REST, server otorisasi, mereka kurang penting bagi klien secara keseluruhan, Anda dapat beralih di antara mereka dengan penundaan kecil yang dapat diterima, tetapi Anda tidak ingin menciptakan sepeda, cara memantau mereka dan apa yang harus dilakukan dengan mereka. Karena itu, semaksimal mungkin kami mencoba menggunakan solusi yang ada, dan tidak mengembangkan beberapa kompetensi dalam produk tambahan. Dan di suatu tempat, kami dengan sepele menggunakan switching pada level dns, dan kami menentukan keaktifan layanan dengan dns yang sama. Amazon memiliki layanan Route 53, tetapi tidak hanya di mana Anda dapat merekam semuanya, itu jauh lebih fleksibel dan nyaman. Melalui itu, Anda dapat membangun layanan geo-didistribusikan dengan geolokasi, ketika Anda menggunakannya untuk menentukan dari mana klien berasal dan memberi mereka catatan tertentu - dengan itu Anda dapat membangun arsitektur failover. Pemeriksaan kesehatan yang sama dikonfigurasikan di Route 53 itu sendiri, Anda menentukan titik akhir yang dipantau, menetapkan metrik, dan menentukan protokol mana yang menentukan daya layanan - tcp, http, https; atur frekuensi pemeriksaan yang menentukan apakah layanan tersebut aktif atau tidak. Dan di dns itu sendiri Anda meresepkan apa yang akan menjadi primer, apa yang akan menjadi sekunder, ke mana harus beralih jika pemeriksaan kesehatan di dalam rute 53 dipicu. Semua ini dapat dilakukan dengan beberapa alat lain, tetapi apa yang lebih nyaman - kami mengaturnya sekali dan kemudian tidak berpikir tentang bagaimana kita melakukan pengecekan, bagaimana kita beralih: semuanya bekerja dengan sendirinya.
"Tapi" pertama : bagaimana dan bagaimana memesan rute 53 itu sendiri? Apakah itu terjadi jika sesuatu terjadi padanya? Untungnya, kita belum pernah menginjak menyapu ini, tetapi sekali lagi, di depan saya, saya akan punya cerita mengapa kita berpikir bahwa kita masih perlu memesan. Di sini kita meletakkan sedotan terlebih dahulu. Beberapa kali sehari kami melakukan pembongkaran lengkap semua zona yang kami miliki di rute 53. API Amazon memungkinkan Anda untuk mengirimkannya dengan aman ke JSON, dan kami telah mengangkat beberapa server berlebihan di mana kami mengubahnya, mengunggahnya dalam bentuk konfigurasi dan, secara kasar, memiliki konfigurasi cadangan. Dalam hal ini kita dapat dengan cepat menyebarkannya secara manual, kita tidak akan kehilangan data pengaturan dns.
"Tapi" kedua : apa yang tidak dicadangkan dalam gambar ini? Sang penyeimbang sendiri! Kami telah membuat distribusi pelanggan berdasarkan wilayah sangat sederhana. Kami memiliki domain bitrix24.ru, bitrix24.com, .de - sekarang ada 13 domain berbeda yang bekerja di zona yang sangat berbeda. Kami datang sebagai berikut: masing-masing daerah memiliki penyeimbang sendiri. Lebih mudah untuk mendistribusikan menurut wilayah, tergantung di mana beban puncak pada jaringan. Jika ini adalah kegagalan pada tingkat penyeimbang satu, maka itu hanya dinonaktifkan dan dihapus dari dns. Jika masalah terjadi dengan sekelompok penyeimbang, mereka dicadangkan di situs lain, dan beralih di antara mereka dilakukan dengan menggunakan rute yang sama53, karena karena ttl pendek, beralih terjadi selama maksimum 2, 3, 5 menit.
"Tapi" yang ketiga : apa yang belum dipesan? S3, benar. Kami, menempatkan file yang disimpan oleh pengguna di s3, dengan tulus percaya bahwa itu menusuk baju besi dan tidak perlu menyimpan apa pun di sana. Tetapi sejarah menunjukkan apa yang terjadi secara berbeda. Secara umum, Amazon menggambarkan S3 sebagai layanan mendasar, karena Amazon sendiri menggunakan S3 untuk menyimpan gambar mesin, konfigurasi, gambar AMI, foto ... Dan jika s3 crash, seperti yang pernah terjadi dalam 7 tahun ini, berapa banyak bitrix24 yang telah kami gunakan, diikuti oleh kipas menarik banyak segalanya - tidak dapat diaksesnya mulai mesin virtual, api tidak berfungsi dan sebagainya.
Dan S3 bisa jatuh - itu terjadi sekali. Oleh karena itu, kami sampai pada skema berikut: beberapa tahun yang lalu tidak ada objek penyimpanan umum yang serius di Rusia, dan kami mempertimbangkan pilihan untuk melakukan sesuatu sendiri ... Untungnya, kami tidak mulai melakukan ini, karena kami akan menggali pemeriksaan yang tidak kami lakukan. memiliki, dan mungkin akan melakukannya. Sekarang Mail.ru memiliki penyimpanan kompatibel s3, Yandex memilikinya, dan sejumlah penyedia masih memilikinya. Sebagai hasilnya, kami sampai pada kesimpulan bahwa kami ingin memiliki, pertama, cadangan, dan kedua, kemampuan untuk bekerja dengan salinan lokal. Untuk wilayah Rusia tertentu, kami menggunakan layanan Hotbox Mail.ru, yang kompatibel dengan api s3. Kami tidak memerlukan modifikasi serius pada kode di dalam aplikasi, dan kami membuat mekanisme berikut: di s3 ada pemicu yang bekerja untuk membuat / menghapus objek, Amazon memiliki layanan seperti Lambda - ini adalah kode berjalan tanpa server yang akan menjalankan hanya ketika pemicu tertentu dipicu.
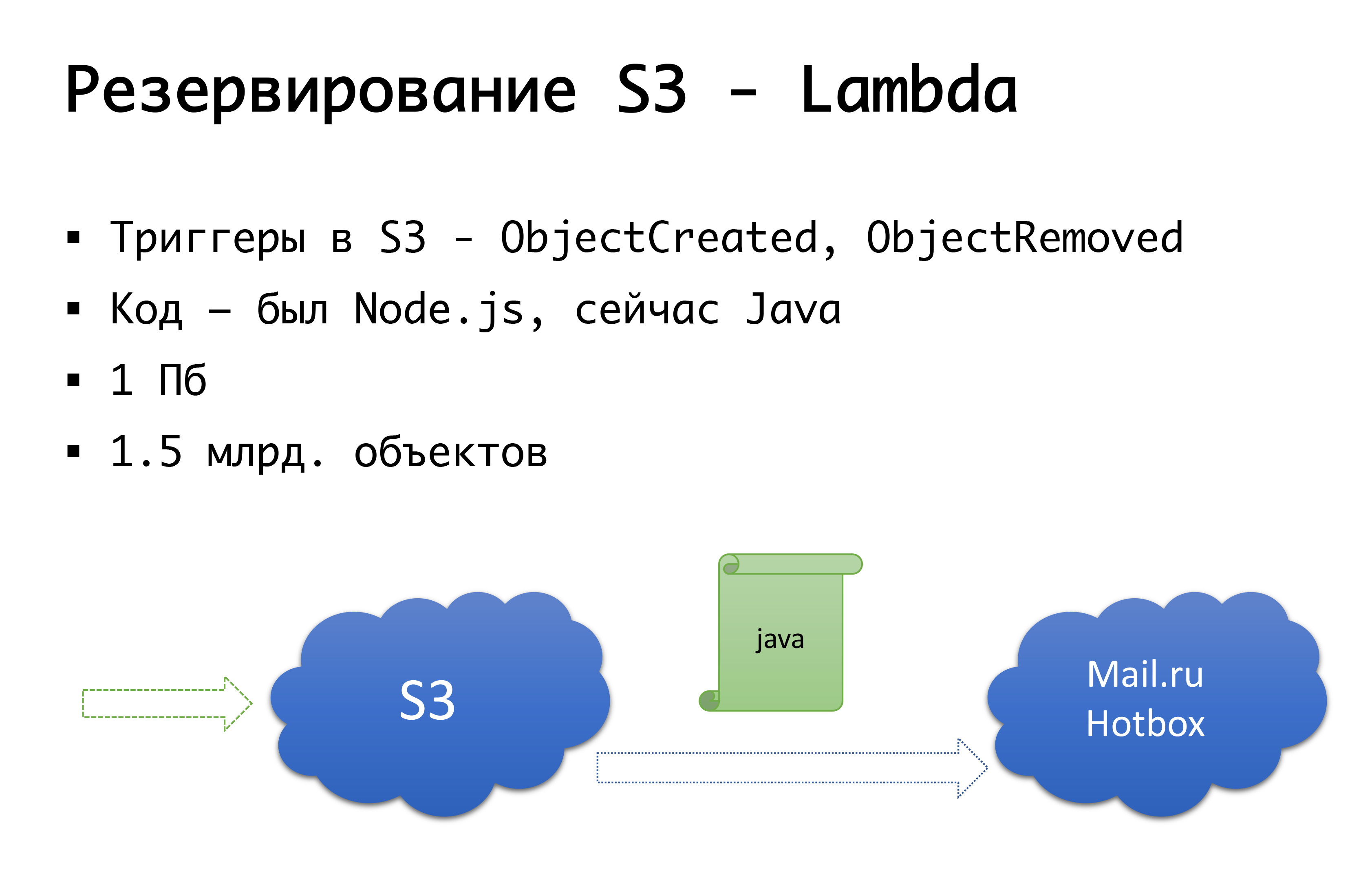
Kami melakukannya dengan sangat sederhana: jika pemicu kami menyala, kami mengeksekusi kode yang akan menyalin objek ke repositori Mail.ru. Untuk sepenuhnya mulai bekerja dengan salinan data lokal, kami juga perlu sinkronisasi terbalik, sehingga klien yang berada di segmen Rusia dapat bekerja dengan penyimpanan yang lebih dekat dengan mereka. Mail akan menyelesaikan pemicu dalam repositori - dimungkinkan untuk melakukan sinkronisasi terbalik yang sudah ada di tingkat infrastruktur, tetapi untuk saat ini kami sedang melakukan ini di tingkat kode kami sendiri. Jika kami melihat bahwa klien telah menempatkan beberapa jenis file, maka pada level kode kami, kami menempatkan acara dalam antrian, memprosesnya dan melakukan replikasi terbalik. Mengapa itu buruk: jika kita memiliki semacam pekerjaan dengan benda-benda di luar produk kita, yaitu, dengan beberapa cara eksternal, kita tidak akan mempertimbangkan ini. Oleh karena itu, kami menunggu hingga akhir ketika pemicu muncul di tingkat penyimpanan sehingga dari mana pun kami menjalankan kode, objek yang datang kepada kami akan disalin dengan cara lain.
Pada level kode, untuk setiap klien, kedua repositori terdaftar: satu dianggap utama, yang lain cadangan. Jika semuanya baik-baik saja, kami bekerja dengan penyimpanan yang lebih dekat dengan kami: yaitu, pelanggan kami yang berada di Amazon, mereka bekerja dengan S3, dan mereka yang bekerja di Rusia, mereka bekerja dengan Hotbox. Jika kotak centang berfungsi, maka failover harus terhubung ke kami, dan kami akan mengalihkan klien ke penyimpanan lain. Kami dapat mengatur bendera ini secara independen berdasarkan wilayah dan dapat mengubahnya bolak-balik. Dalam praktiknya, kami belum menggunakan ini, tetapi kami telah membayangkan mekanisme ini dan kami berpikir bahwa suatu hari kita akan membutuhkan dan menggunakan saklar ini. Setelah itu terjadi.
Oh, dan Amazon Anda lolos ...
April ini adalah hari peringatan dimulainya kunci Telegram di Rusia. Penyedia yang paling terpengaruh yang datang di bawah ini adalah Amazon. Dan, sayangnya, perusahaan Rusia yang bekerja di seluruh dunia lebih menderita.
Jika perusahaan itu bersifat global dan Rusia untuk itu adalah segmen yang sangat kecil, 3-5% - well, satu atau lain cara, Anda dapat menyumbangkannya.
Jika ini adalah perusahaan yang sepenuhnya Rusia - Saya yakin Anda perlu mencari secara lokal - yah, hanya saja para pengguna itu sendiri akan merasa nyaman, nyaman, akan ada risiko yang lebih kecil.
Dan jika ini adalah perusahaan yang bekerja secara global, dan memiliki kira-kira pangsa pelanggan yang sama dari Rusia, dan di suatu tempat di seluruh dunia? Konektivitas segmen itu penting, dan mereka harus bekerja satu sama lain.
Pada akhir Maret 2018, Roskomnadzor mengirim surat ke operator terbesar yang menyatakan bahwa mereka berencana memblokir beberapa juta ip Amazon untuk memblokir ... kurir Zello. Berkat penyedia layanan ini - mereka berhasil membocorkan surat kepada semua orang, dan ada pemahaman bahwa konektivitas dengan Amazon bisa berantakan. Saat itu hari Jumat, kami berlari ke rekan-rekan dari server.ru dengan panik, dengan kata-kata: "Teman-teman, kami membutuhkan beberapa server yang tidak akan berada di Rusia, bukan di Amazon, tetapi, misalnya, di suatu tempat di Amsterdam," untuk setidaknya dapat menempatkan vpn dan proxy kami sendiri di sana untuk beberapa titik akhir yang sama sekali tidak dapat kami pengaruhi, misalnya endpont dari s3 yang sama - kami tidak dapat mencoba untuk meningkatkan layanan baru dan mendapatkan ip lain, kami Anda masih harus ke sana. Dalam beberapa hari, kami menyiapkan server ini, membesarkannya, dan secara umum, mempersiapkan dimulainya kunci. Sangat mengherankan bahwa ILV, melihat hype dan kepanikan yang meningkat, berkata: "Tidak, kami tidak akan memblokir apa pun sekarang." (Tapi ini persis sampai saat mereka mulai memblokir telegram.) Setelah mengatur opsi pintas dan menyadari bahwa mereka tidak memasuki kunci, kami, bagaimanapun, tidak membongkar semuanya. Jadi, untuk jaga-jaga.

Dan pada tahun 2019, kami masih hidup dalam kondisi terkunci. Saya melihat tadi malam: sekitar satu juta ip terus diblokir. , Amazon , 20 … , , , — . . — , , . , , . - , AS-, , , — direct connect l2. , , , - , vpn, proxy, , . , Amazon, S3, .
… ?
Amazon . . , , . : , -, , -. . , . . , , , . - , .
Amazon ; , Google, , -… , Amazon availability- , — . , , , «Amazon — Amazon», .
? -. «» , , «» — . . - — « », « ». . - - , , - , . , , .
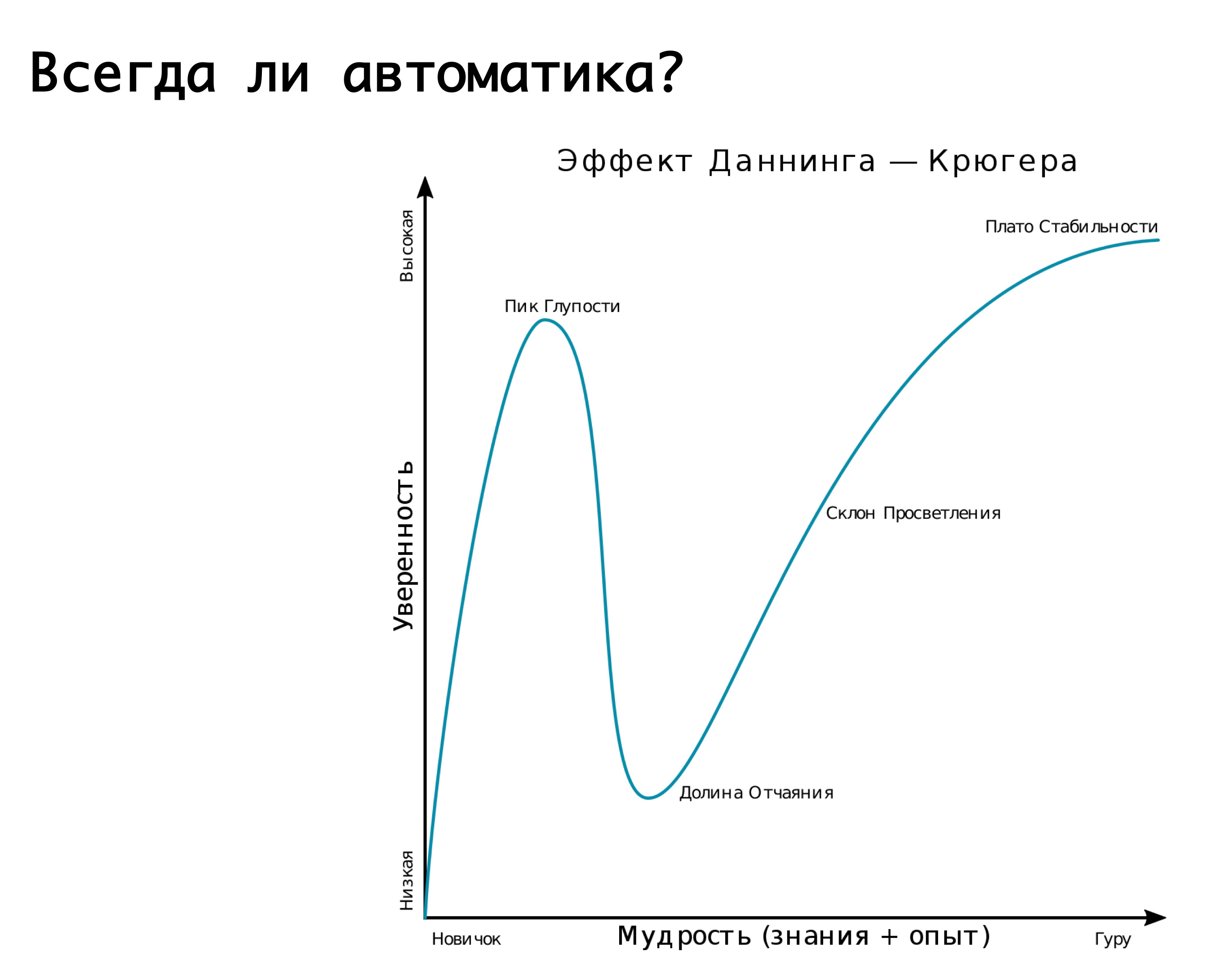
— . — , . , , , . -: false positive, - , , -, . , - — . , . , . Tapi! , , , , , , …
Kesimpulan
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
Kompromi yang masuk akal antara perfeksionisme dan kekuatan nyata, waktu, uang yang bisa Anda pakai untuk skema yang nantinya akan Anda miliki.Teks ini adalah versi tambahan dan diperluas dari laporan Alexander Demidov pada konferensi Uptime day 4 .