Hai, saya membuat aplikasi untuk
Tarantool DBMS - ini adalah platform yang dikembangkan oleh Mail.ru Group yang menggabungkan DBMS berkinerja tinggi dan server aplikasi di Lua. Solusi Tarantool berbasis kecepatan tinggi dicapai, khususnya, dengan mendukung mode DBMS dalam memori dan kemampuan untuk mengeksekusi logika aplikasi bisnis dalam ruang alamat tunggal dengan data. Ini memastikan persistensi data menggunakan transaksi ACID (log WAL disimpan pada disk). Tarantool memiliki replikasi bawaan dan dukungan sharding. Dimulai dengan versi 2.1, kueri SQL didukung. Tarantool adalah sumber terbuka dan berlisensi di bawah BSD Sederhana. Ada juga versi Perusahaan komersial.
 Rasakan kekuatannya! (... aka nikmati pertunjukannya)
Rasakan kekuatannya! (... aka nikmati pertunjukannya)Semua hal di atas menjadikan Tarantool platform yang menarik untuk membuat aplikasi basis data yang sangat banyak. Dalam aplikasi seperti itu, replikasi data seringkali menjadi perlu.
Seperti disebutkan di atas, Tarantool memiliki replikasi data bawaan. Prinsip kerjanya adalah eksekusi berurutan pada replika semua transaksi yang terdapat dalam wizard log (WAL). Biasanya, replikasi tersebut (kami akan menyebutnya
tingkat rendah di bawah) digunakan untuk memberikan toleransi kesalahan dari aplikasi dan / atau untuk mendistribusikan beban bacaan antara node cluster.
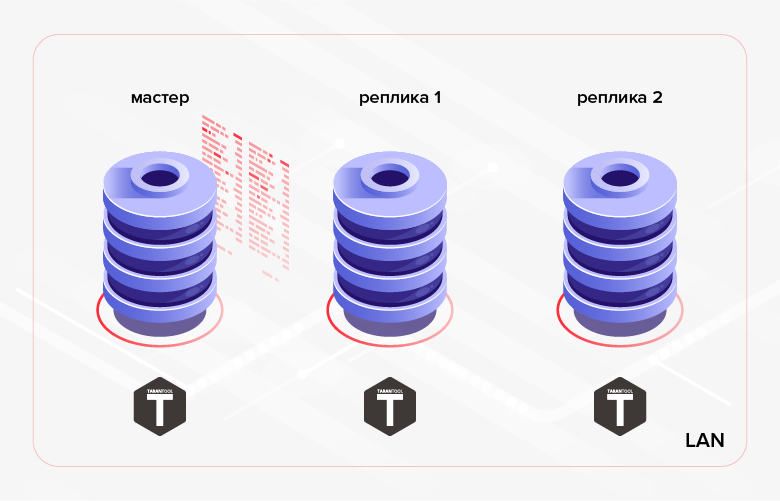 Fig. 1. Replikasi dalam cluster
Fig. 1. Replikasi dalam clusterContoh skenario alternatif adalah transfer data yang dibuat dalam satu basis data ke basis data lain untuk pemrosesan / pemantauan. Dalam kasus terakhir, solusi yang lebih mudah mungkin menggunakan replikasi
tingkat tinggi - replikasi data pada tingkat logika bisnis aplikasi. Yaitu Kami tidak menggunakan solusi siap pakai yang dibangun ke dalam DBMS, tetapi kami sendiri menerapkan replikasi di dalam aplikasi yang kami kembangkan. Pendekatan ini memiliki kelebihan dan kekurangan. Kami daftar pro.
1. Menghemat lalu lintas:
- Anda tidak dapat mentransfer semua data, tetapi hanya sebagian saja (misalnya, Anda hanya dapat mentransfer beberapa tabel, beberapa kolom atau catatan mereka yang memenuhi kriteria tertentu);
- tidak seperti replikasi tingkat rendah, yang dilakukan secara terus-menerus dalam mode asinkron (diimplementasikan dalam versi Tarantool saat ini - 1.10) atau mode sinkron (untuk diimplementasikan dalam versi Tarantool yang akan datang), replikasi tingkat tinggi dapat dilakukan dengan sesi (mis., aplikasi pertama kali melakukan sinkronisasi data - sesi pertukaran) data, maka ada jeda dalam replikasi, setelah sesi pertukaran berikutnya terjadi, dll);
- jika catatan telah berubah beberapa kali, Anda hanya dapat mentransfer versi terbarunya (tidak seperti replikasi tingkat rendah, di mana semua perubahan yang dilakukan pada wizard akan dimainkan secara berurutan pada replika).
2. Tidak ada kesulitan dengan implementasi pertukaran melalui HTTP, yang memungkinkan Anda untuk menyinkronkan basis data jauh.
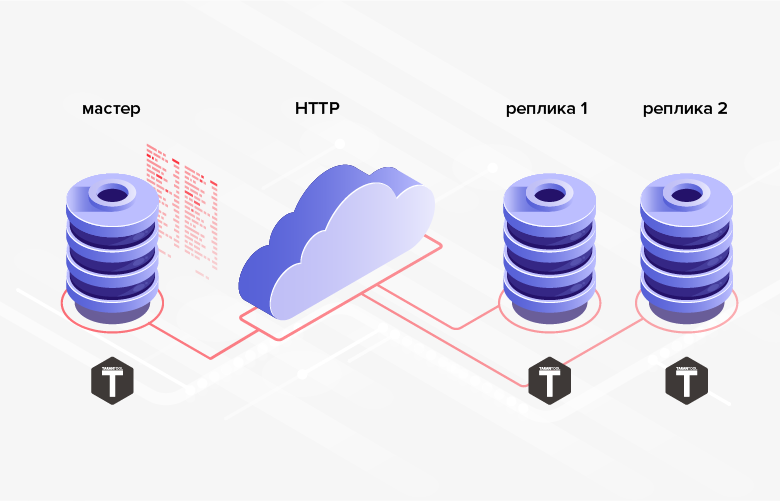 Fig. 2. Replikasi HTTP
Fig. 2. Replikasi HTTP3. Struktur basis data di mana data dikirimkan tidak harus sama (apalagi, dalam kasus umum, bahkan dimungkinkan untuk menggunakan DBMS, bahasa pemrograman, platform, dll.) Yang berbeda.
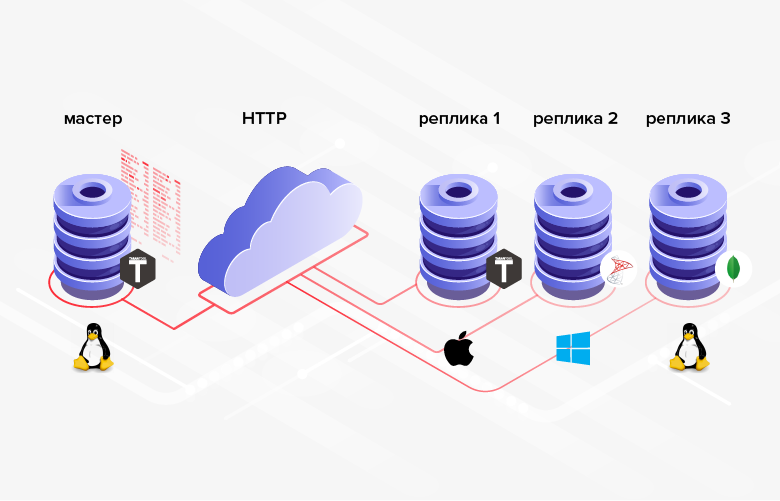 Fig. 3. Replikasi dalam sistem heterogen
Fig. 3. Replikasi dalam sistem heterogenKelemahannya adalah bahwa rata-rata, pemrograman lebih rumit / lebih mahal daripada konfigurasi, dan alih-alih mengatur fungsionalitas bawaan, Anda harus mengimplementasikannya sendiri.
Jika dalam situasi Anda keuntungan di atas memainkan peran yang menentukan (atau kondisi yang diperlukan), maka masuk akal untuk menggunakan replikasi tingkat tinggi. Mari kita pertimbangkan beberapa cara untuk mengimplementasikan replikasi data tingkat tinggi di Tarantool DBMS.
Minimalisasi lalu lintas
Jadi, salah satu manfaat replikasi tingkat tinggi adalah menghemat lalu lintas. Agar keuntungan ini dapat sepenuhnya terwujud, perlu untuk meminimalkan jumlah data yang dikirimkan selama setiap sesi pertukaran. Tentu saja, orang tidak boleh lupa bahwa pada akhir sesi penerima data harus disinkronkan dengan sumber (setidaknya untuk bagian dari data yang terlibat dalam replikasi).
Bagaimana cara meminimalkan jumlah data yang ditransfer selama replikasi tingkat tinggi? Solusi "di dahi" mungkin pemilihan data berdasarkan tanggal-waktu. Untuk melakukan ini, Anda bisa menggunakan bidang tanggal-waktu yang sudah ada di tabel (jika ada). Misalnya, dokumen "pesanan" mungkin memiliki bidang "waktu yang diperlukan untuk eksekusi pesanan" -
delivery_time . Masalah dengan solusi ini adalah bahwa nilai-nilai di bidang ini tidak harus dalam urutan yang sesuai dengan pembuatan pesanan. Dengan demikian, kami tidak dapat mengingat nilai maksimum bidang
delivery_time dikirim selama sesi pertukaran sebelumnya, dan pada sesi pertukaran berikutnya, pilih semua catatan dengan nilai yang lebih tinggi dari bidang
delivery_time . Di interval antara sesi pertukaran, catatan dengan nilai yang lebih kecil dari bidang
delivery_time dapat ditambahkan. Selain itu, pesanan dapat mengalami perubahan, yang tidak memengaruhi bidang
delivery_time . Dalam kedua kasus, perubahan tidak akan dikirim dari sumber ke penerima. Untuk mengatasi masalah ini, kita perlu mengirimkan data "tumpang tindih". Yaitu selama setiap sesi pertukaran, kami akan mentransfer semua data dengan nilai bidang
delivery_time yang melebihi beberapa titik di masa lalu (misalnya, N jam dari saat ini). Namun, jelas bahwa untuk sistem besar pendekatan ini sangat berlebihan dan dapat mengurangi penghematan lalu lintas yang kami tuju. Selain itu, tabel yang dikirimkan mungkin tidak memiliki bidang tanggal-waktu.
Solusi lain, yang lebih kompleks dalam hal implementasi, adalah mengakui penerimaan data. Dalam hal ini, pada setiap sesi pertukaran, semua data dikirimkan, tanda terima yang tidak dikonfirmasi oleh penerima. Untuk implementasi, Anda perlu menambahkan kolom Boolean ke tabel sumber (misalnya,
is_transferred ). Jika penerima mengonfirmasi penerimaan rekaman, bidang terkait disetel ke
true , setelah itu rekaman tidak lagi terlibat dalam pertukaran. Opsi implementasi ini memiliki kelemahan berikut. Pertama, untuk setiap catatan yang ditransfer, perlu untuk menghasilkan dan mengirim konfirmasi. Secara kasar, ini dapat dibandingkan dengan menggandakan jumlah data yang ditransfer dan mengarah ke penggandaan jumlah perjalanan bolak-balik. Kedua, tidak ada kemungkinan mengirim catatan yang sama ke beberapa penerima (penerima pertama akan mengkonfirmasi penerimaan untuk diri mereka sendiri dan untuk semua orang).
Metode, tanpa kekurangan di atas, adalah menambahkan kolom ke tabel yang akan dikirim untuk melacak perubahan dalam barisnya. Kolom seperti itu bisa dari tipe tanggal-waktu dan harus disetel / dimutakhirkan oleh aplikasi untuk waktu saat ini setiap kali menambah / mengubah catatan (secara atomis dengan menambahkan / mengubah). Sebagai contoh, mari kita sebut kolom
update_time . Setelah menyimpan nilai maksimum bidang kolom ini untuk catatan yang ditransfer, kita dapat memulai sesi pertukaran berikutnya dari nilai ini (pilih catatan dengan nilai bidang
update_time melebihi nilai yang disimpan sebelumnya). Masalah dengan pendekatan yang terakhir adalah bahwa perubahan data dapat terjadi dalam mode batch. Akibatnya, nilai bidang di kolom
update_time tidak unik. Dengan demikian, kolom ini tidak dapat digunakan untuk output data batch (halaman). Untuk output data halaman per halaman, akan perlu untuk menemukan mekanisme tambahan yang cenderung memiliki efisiensi sangat rendah (misalnya, mengambil dari database semua catatan dengan
update_time atas nilai yang ditentukan dan mengeluarkan sejumlah catatan, mulai dari offset tertentu dari awal sampel).
Anda dapat meningkatkan efisiensi transfer data dengan sedikit meningkatkan pendekatan sebelumnya. Untuk melakukan ini, kami akan menggunakan tipe integer (integer panjang) sebagai nilai kolom kolom untuk melacak perubahan.
row_ver kolom tersebut
row_ver . Nilai bidang kolom ini harus tetap disetel / dimutakhirkan setiap kali catatan dibuat / dimodifikasi. Tetapi dalam kasus ini, bidang akan ditugaskan bukan tanggal-waktu saat ini, tetapi nilai beberapa penghitung meningkat satu. Akibatnya, kolom
row_ver akan berisi nilai unik dan dapat digunakan tidak hanya untuk menghasilkan data "delta" (data ditambahkan / diubah setelah akhir sesi pertukaran sebelumnya), tetapi juga untuk paginasi yang sederhana dan efisien.
Metode terakhir yang diusulkan untuk meminimalkan jumlah data yang ditransfer sebagai bagian dari replikasi tingkat tinggi menurut saya paling optimal dan universal. Mari kita bahas lebih detail.
Transfer data menggunakan penghitung versi baris
Implementasi server / master
Dalam MS SQL Server, untuk menerapkan pendekatan ini, ada tipe kolom khusus -
rowversion . Setiap basis data memiliki penghitung, yang bertambah satu setiap kali Anda menambah / mengubah catatan dalam tabel yang memiliki kolom tipe
rowversion . Nilai penghitung ini secara otomatis ditetapkan ke bidang kolom ini dalam catatan yang ditambahkan / diubah. Tarantool DBMS tidak memiliki mekanisme bawaan yang serupa. Namun, di Tarantool, tidak sulit untuk mengimplementasikannya secara manual. Pertimbangkan bagaimana ini dilakukan.
Pertama, sedikit terminologi: tabel di Tarantool disebut spasi, dan catatan disebut tuple. Di Tarantool, Anda bisa membuat urutan. Urutan tidak lebih dari generator bernama nilai integer yang diurutkan. Yaitu inilah yang kita butuhkan untuk tujuan kita. Di bawah ini kita akan membuat urutan seperti itu.
Sebelum Anda melakukan operasi database apa pun di Tarantool, Anda harus menjalankan perintah berikut:
box.cfg{}
Akibatnya, Tarantool akan mulai menulis snapshot dan log transaksi ke direktori saat ini.
Buat urutan
row_version :
box.schema.sequence.create('row_version', { if_not_exists = true })
Opsi
if_not_exists memungkinkan
if_not_exists untuk menjalankan skrip pembuatan beberapa kali: jika objek ada, Tarantool tidak akan mencoba membuatnya kembali. Opsi ini akan digunakan dalam semua perintah DDL berikutnya.
Mari kita buat spasi sebagai contoh.
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' }, { name = 'row_ver', type = 'unsigned' } }, if_not_exists = true })
Di sini kita mengatur nama ruang (
goods ), nama-nama bidang dan jenisnya.
Bidang penambahan otomatis Tarantool juga dibuat menggunakan urutan. Buat kunci primer peningkatan-otomatis untuk bidang
id :
box.schema.sequence.create('goods_id', { if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
Tarantool mendukung beberapa jenis indeks. Paling sering, indeks jenis TREE dan HASH digunakan, yang didasarkan pada struktur yang sesuai dengan namanya. TREE adalah tipe indeks yang paling serbaguna. Ini memungkinkan Anda untuk mengambil data secara teratur. Tetapi untuk pilihan kesetaraan, HASH lebih cocok. Oleh karena itu, disarankan untuk menggunakan HASH untuk kunci utama (yang kami lakukan).
Untuk menggunakan kolom
row_ver untuk mengirimkan data yang diubah, Anda harus mengikat nilai urutan
row_ver ke bidang di kolom ini. Tapi tidak seperti kunci utama, nilai bidang di kolom
row_ver harus meningkat satu, tidak hanya saat menambahkan catatan baru, tetapi juga ketika mengubah yang sudah ada. Untuk melakukan ini, Anda bisa menggunakan pemicu. Tarantool memiliki dua jenis pemicu untuk spasi:
before_replace dan
on_replace . Pemicu dipicu setiap kali data dalam ruang diubah (untuk setiap tuple yang terpengaruh oleh perubahan, fungsi pemicu dipicu). Tidak seperti
on_replace ,
before_replace trigger memungkinkan Anda untuk memodifikasi data tuple yang memicu pelatuk dijalankan. Dengan demikian, jenis pemicu terakhir cocok untuk kita.
box.space.goods:before_replace(function(old, new) return box.tuple.new({new[1], new[2], new[3], box.sequence.row_version:next()}) end)
Pemicu ini menggantikan nilai bidang
row_ver dari tuple yang disimpan dengan nilai urutan
row_version berikutnya.
Agar dapat mengekstraksi data dari ruang
goods di kolom
row_ver , buat indeks:
box.space.goods:create_index('row_ver', { parts = { 'row_ver' }, unique = true, type = 'TREE', if_not_exists = true })
Jenis indeks adalah pohon (
TREE ), karena kita perlu mengambil data dalam urutan nilai yang naik di kolom
row_ver .
Tambahkan beberapa data ke ruang:
box.space.goods:insert{nil, 'pen', 123} box.space.goods:insert{nil, 'pencil', 321} box.space.goods:insert{nil, 'brush', 100} box.space.goods:insert{nil, 'watercolour', 456} box.space.goods:insert{nil, 'album', 101} box.space.goods:insert{nil, 'notebook', 800} box.space.goods:insert{nil, 'rubber', 531} box.space.goods:insert{nil, 'ruler', 135}
Karena bidang pertama adalah penghitung kenaikan otomatis, sebagai gantinya kami lulus nol. Tarantool akan secara otomatis menggantikan nilai berikutnya. Demikian pula, Anda dapat melewatkan nil sebagai nilai bidang di kolom
row_ver - atau tidak menentukan nilai sama sekali, karena kolom ini mengambil posisi terakhir di ruang.
Periksa hasil dari sisipan:
tarantool> box.space.goods:select()
Seperti yang Anda lihat, bidang pertama dan terakhir diisi secara otomatis. Sekarang akan mudah untuk menulis fungsi untuk paging membongkar
goods :
local page_size = 5 local function get_goods(row_ver) local index = box.space.goods.index.row_ver local goods = {} local counter = 0 for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do local obj = tuple:tomap({ names_only = true }) table.insert(goods, obj) counter = counter + 1 if counter >= page_size then break end end return goods end
Fungsi ini mengambil sebagai parameter nilai
row_ver dari catatan terakhir yang diterima (0 untuk panggilan pertama) dan mengembalikan kumpulan data yang diubah berikutnya (jika ada, jika tidak array kosong).
Pengambilan data di Tarantool dilakukan melalui indeks. Fungsi
get_goods menggunakan
row_ver index untuk mengambil data yang diubah. Jenis iterator adalah GT (Lebih Besar Dari, lebih dari). Ini berarti bahwa iterator akan secara berurutan melintasi nilai indeks mulai dari nilai berikutnya setelah kunci yang dilewati.
Iterator mengembalikan tupel. Agar selanjutnya dapat mentransfer data melalui HTTP, perlu untuk mengubah tuple ke struktur yang nyaman untuk serialisasi berikutnya. Dalam contoh, fungsi
tomap standar digunakan untuk ini. Alih-alih menggunakan
tomap Anda dapat menulis fungsi Anda sendiri. Misalnya, kami mungkin ingin mengganti
name bidang
name , bukan meneruskan bidang
code , dan menambahkan bidang
comment :
local function unflatten_goods(tuple) local obj = {} obj.id = tuple.id obj.goods_name = tuple.name obj.comment = 'some comment' obj.row_ver = tuple.row_ver return obj end
Ukuran halaman dari data output (jumlah catatan dalam satu bagian) ditentukan oleh variabel
page_size . Dalam contoh, nilai
page_size adalah 5. Dalam program nyata, ukuran halaman biasanya lebih penting. Itu tergantung pada ukuran rata-rata tuple ruang. Ukuran halaman yang optimal dapat dipilih secara empiris dengan mengukur waktu transfer data. Semakin besar halaman, semakin kecil jumlah perjalanan pulang pergi antara pihak pengirim dan penerima. Jadi, Anda dapat mengurangi total waktu untuk mengunggah perubahan. Namun, jika ukuran halaman terlalu besar, kami akan membutuhkan server terlalu lama untuk membuat serial pilihan. Akibatnya, mungkin ada keterlambatan dalam memproses permintaan lain yang datang ke server. Parameter
page_size dapat diambil dari file konfigurasi. Untuk setiap ruang yang ditransmisikan, Anda dapat mengatur nilai Anda sendiri. Namun, untuk sebagian besar spasi, nilai default (misalnya, 100) mungkin cocok.
get_goods fungsi
get_goods dalam modul. Buat file repl.lua yang berisi deskripsi variabel
page_size dan fungsi
get_goods . Di akhir file, tambahkan fungsi ekspor:
return { get_goods = get_goods }
Untuk memuat modul, jalankan:
tarantool> repl = require('repl')
Mari kita jalankan fungsi
get_goods :
tarantool> repl.get_goods(0)
Ambil nilai bidang
row_ver dari baris terakhir dan panggil fungsi itu lagi:
tarantool> repl.get_goods(5)
Dan lagi:
tarantool> repl.get_goods(8)
Seperti yang Anda lihat, dengan penggunaan ini, fungsi halaman-demi-halaman mengembalikan semua catatan ruang
goods . Halaman terakhir diikuti oleh pilihan kosong.
Kami akan membuat perubahan pada ruang:
box.space.goods:update(4, {{'=', 6, 'copybook'}}) box.space.goods:insert{nil, 'clip', 234} box.space.goods:insert{nil, 'folder', 432}
Kami mengubah nilai bidang
name untuk satu catatan dan menambahkan dua catatan baru.
Ulangi panggilan fungsi terakhir:
tarantool> repl.get_goods(8)
Fungsi mengembalikan catatan yang diubah dan ditambahkan. Dengan demikian, fungsi
get_goods memungkinkan
get_goods untuk mendapatkan data yang telah berubah sejak panggilan terakhirnya, yang merupakan dasar dari metode replikasi yang sedang dipertimbangkan.
Kami meninggalkan output hasil melalui HTTP dalam bentuk JSON di luar ruang lingkup artikel ini. Anda dapat membacanya di sini:
https://habr.com/ru/company/mailru/blog/272141/Implementasi bagian klien / budak
Pertimbangkan seperti apa penerapan sisi penerima. Buat ruang di sisi penerima untuk menyimpan data yang diunduh:
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' } }, if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
Struktur ruang menyerupai struktur ruang di sumbernya. Tetapi karena kami tidak akan mentransfer data yang diterima di tempat lain, kolom
row_ver di ruang penerima. Di bidang
id akan ditulis pengidentifikasi sumber. Oleh karena itu, di sisi penerima, tidak perlu membuatnya secara otomatis.
Selain itu, kami membutuhkan ruang untuk menyimpan nilai
row_ver :
box.schema.space.create('row_ver', { format = { { name = 'space_name', type = 'string' }, { name = 'value', type = 'string' } }, if_not_exists = true }) box.space.row_ver:create_index('primary', { parts = { 'space_name' }, unique = true, type = 'HASH', if_not_exists = true })
Untuk setiap ruang yang dimuat (field
space_name ), kami akan menyimpan di sini nilai
row_ver terakhir dimuat (
value bidang). Kunci utama adalah kolom
space_name .
Mari kita buat fungsi untuk memuat data ruang
goods melalui HTTP. Untuk melakukan ini, kita memerlukan pustaka yang mengimplementasikan klien HTTP. Baris berikut memuat pustaka dan instantiate klien HTTP:
local http_client = require('http.client').new()
Kami juga membutuhkan perpustakaan untuk deserialisasi json:
local json = require('json')
Ini cukup untuk membuat fungsi pemuatan data:
local function load_data(url, row_ver) local url = ('%s?rowVer=%s'):format(url, tostring(row_ver)) local body = nil local data = http_client:request('GET', url, body, { keepalive_idle = 1, keepalive_interval = 1 }) return json.decode(data.body) end
Fungsi melakukan permintaan HTTP di url, meneruskan
row_ver ke dalamnya sebagai parameter, dan mengembalikan hasil deserialized dari permintaan.
Fungsi menyimpan data yang diterima adalah sebagai berikut:
local function save_goods(goods) local n = #goods box.atomic(function() for i = 1, n do local obj = goods[i] box.space.goods:put( obj.id, obj.name, obj.code) end end) end
Siklus menyimpan data dalam ruang
goods ditempatkan dalam transaksi (fungsi
box.atomic digunakan untuk ini) untuk mengurangi jumlah operasi disk.
Akhirnya, fungsi sinkronisasi
goods antariksa lokal dengan sumber dapat diimplementasikan sebagai berikut:
local function sync_goods() local tuple = box.space.row_ver:get('goods') local row_ver = tuple and tuple.value or 0
Pertama, kita membaca nilai
row_ver sebelumnya disimpan untuk ruang
goods . Jika tidak ada (sesi pertukaran pertama), maka kami mengambil nol sebagai
row_ver . Selanjutnya, dalam loop, kami membuat paginate data yang dimodifikasi dari sumber ke url yang ditentukan. Pada setiap iterasi, kami menyimpan data yang diterima di ruang lokal yang sesuai dan memperbarui nilai
row_ver (dalam
row_ver row_ver dan dalam variabel
row_ver ) - kami mengambil nilai
row_ver dari baris terakhir dari data yang dimuat.
Untuk melindungi dari loop yang tidak disengaja (jika terjadi kesalahan dalam program),
while dapat diganti dengan
for :
for _ = 1, max_req do ...
Sebagai hasil dari fungsi
sync_goods ,
goods di penerima akan berisi versi terbaru dari semua catatan ruang
goods di sumber.
Jelas, penghapusan data tidak dapat disiarkan dengan cara ini. Jika kebutuhan seperti itu ada, Anda dapat menggunakan tanda penghapusan.
is_deleted bidang boolean
is_deleted ruang
goods dan bukannya menghapus catatan secara fisik, gunakan penghapusan logis - setel nilai bidang
is_deleted menjadi
true . Terkadang, alih-
is_deleted bidang Boolean
is_deleted , lebih nyaman menggunakan bidang yang
deleted , yang menyimpan tanggal-waktu penghapusan logis catatan. Setelah melakukan penghapusan logis, catatan yang ditandai untuk dihapus akan ditransfer dari sumber ke penerima (sesuai dengan logika yang dibahas di atas).
Urutan
row_ver dapat digunakan untuk mentransfer data dari ruang lain: tidak perlu membuat urutan terpisah untuk setiap ruang yang ditransmisikan.
Kami memeriksa cara replikasi data tingkat tinggi yang efektif dalam aplikasi menggunakan Tarantool DBMS.
Kesimpulan
- Tarantool DBMS adalah produk yang menarik dan menjanjikan untuk membuat aplikasi yang sangat dimuat.
- Replikasi tingkat tinggi menyediakan pendekatan yang lebih fleksibel untuk transfer data dibandingkan dengan replikasi tingkat rendah.
- Metode replikasi tingkat tinggi yang dipertimbangkan dalam artikel memungkinkan seseorang untuk meminimalkan jumlah data yang dikirimkan dengan hanya mentransfer catatan-catatan yang telah berubah sejak sesi pertukaran terakhir.