HighLoad ++ sudah ada sejak lama, dan kami berbicara tentang bekerja dengan PostgreSQL secara teratur. Tetapi pengembang masih memiliki masalah yang sama dari bulan ke bulan, dari tahun ke tahun. Ketika di perusahaan kecil tanpa DBA di negara bagian ada kesalahan dalam bekerja dengan database, ini tidak mengejutkan. Perusahaan-perusahaan besar juga membutuhkan basis data, dan bahkan dengan proses debug, kesalahan masih terjadi dan basis data jatuh. Tidak masalah apa ukuran perusahaan itu - kesalahan masih terjadi, database mengalami crash, crash secara berkala.

Tentu saja, ini tidak akan pernah terjadi pada Anda, tetapi memeriksa daftar periksa itu tidak sulit, dan akan sangat layak untuk menyelamatkan saraf di masa depan. Di bawah cat, kami akan membuat daftar kesalahan khas teratas yang dibuat pengembang ketika bekerja dengan PostgreSQL, lihat mengapa kami tidak perlu melakukan ini, dan mencari tahu caranya.
Tentang pembicara: Alexey Lesovsky dimulai sebagai administrator sistem Linux. Dari tugas-tugas sistem virtualisasi dan pemantauan secara bertahap datang ke PostgreSQL. Sekarang PostgreSQL DBA di
Data Egret , sebuah perusahaan konsultan yang bekerja dengan banyak proyek berbeda dan melihat banyak contoh masalah berulang. Ini adalah
tautan ke penyajian laporan di HighLoad ++ 2018.
Dari mana datangnya masalah
Untuk pemanasan, beberapa cerita tentang bagaimana kesalahan terjadi.
Sejarah 1. Fitur
Salah satu masalah adalah fitur apa yang digunakan perusahaan ketika bekerja dengan PostgreSQL. Semuanya dimulai sederhana: PostgreSQL, kumpulan data, pertanyaan sederhana dengan BERGABUNG. Kami mengambil data, lakukan SELECT - semuanya sederhana.
Kemudian kita mulai menggunakan fungsionalitas tambahan PostgreSQL, tambahkan fungsi baru, ekstensi. Fiturnya semakin besar. Kami menghubungkan replikasi streaming, sharding. Berbagai utilitas dan body kit muncul di sekitar - pgbouncer, pgpool, patroni. Sesuatu seperti itu.

Setiap kata kunci adalah alasan munculnya kesalahan.
Sejarah 2. Penyimpanan Data
Cara kami menyimpan data juga merupakan sumber kesalahan.
Ketika proyek pertama kali muncul, ada beberapa data dan tabel di dalamnya. Permintaan sederhana sudah cukup untuk menerima dan merekam data. Tetapi kemudian ada semakin banyak tabel. Data dipilih dari tempat yang berbeda, BERGABUNG muncul. Kueri rumit dan termasuk konstruksi CTE, SUBQUERY, IN, LATERAL. Membuat kesalahan dan menulis kueri kurva menjadi lebih mudah.
Dan ini hanyalah puncak gunung es - di suatu tempat di sampingnya terdapat 400 tabel, partisi, dari mana data juga kadang-kadang dibaca.
Sejarah 3. Siklus Hidup
Kisah bagaimana produk itu diikuti. Data selalu perlu disimpan di suatu tempat, jadi selalu ada database. Bagaimana database berkembang ketika suatu produk berkembang?
Di satu sisi, ada
pengembang yang sibuk dengan bahasa pemrograman. Mereka menulis aplikasi mereka dan mengembangkan keterampilan di bidang pengembangan perangkat lunak, tidak memperhatikan layanan. Seringkali mereka tidak tertarik pada cara kerja Kafka atau PostgreSQL - mereka mengembangkan fitur baru dalam aplikasi mereka, dan mereka tidak peduli dengan yang lain.
 Admin, di sisi
Admin, di sisi lain. Mereka meningkatkan instance Amazon baru di Bare-metal dan sibuk dengan otomatisasi: mereka mengatur penyebaran untuk membuat tata letak berfungsi dengan baik, dan mengkonfigurasi agar layanan saling berinteraksi dengan baik.

Ada situasi ketika tidak ada waktu atau keinginan untuk penyetelan komponen yang tipis, dan juga basis data. Basis data bekerja dengan konfigurasi default, dan kemudian mereka benar-benar melupakannya - "berfungsi, jangan menyentuhnya".
Akibatnya, garu tersebar di berbagai tempat, yang sekarang dan kemudian terbang ke dahi pengembang. Pada artikel ini, kami akan mencoba untuk mengumpulkan semua garu ini dalam satu gudang sehingga Anda tahu tentang mereka dan tidak menginjaknya ketika bekerja dengan PostgreSQL.
Perencanaan dan pemantauan
Pertama, bayangkan kita memiliki proyek baru - selalu merupakan pengembangan aktif, pengujian hipotesis, dan implementasi fitur baru. Pada saat aplikasi baru saja muncul dan sedang berkembang, ia memiliki sedikit lalu lintas, pengguna dan pelanggan, dan mereka semua menghasilkan sejumlah kecil data. Basis data memiliki kueri sederhana yang cepat diproses. Tidak perlu menyeret data dalam jumlah besar, tidak ada masalah.
Tetapi ada lebih banyak pengguna, lalu lintas datang: data baru muncul, basis data bertambah dan permintaan lama berhenti berfungsi. Anda perlu melengkapi indeks, menulis ulang, dan mengoptimalkan kueri. Ada masalah kinerja. Semua ini mengarah pada peringatan jam 4 pagi, tekanan untuk admin dan ketidakpuasan manajemen.
Apa yang salah
Dalam pengalaman saya, paling sering tidak ada cukup disk.
Contoh pertama . Kami membuka jadwal untuk memantau pemanfaatan disk, dan kami melihat bahwa
ruang kosong pada disk sudah habis .
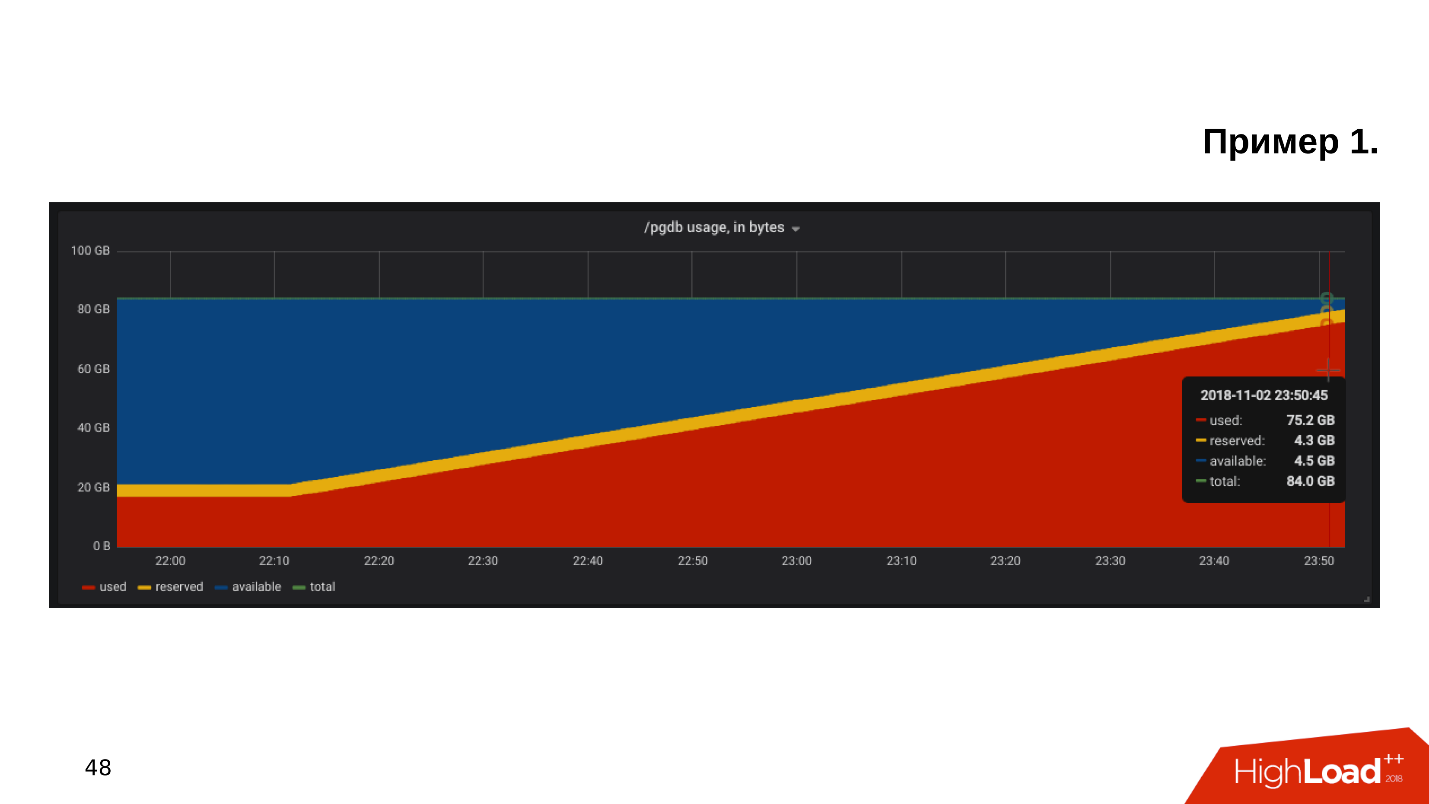
Kami melihat berapa banyak ruang dan apa yang dimakan - ternyata ada direktori pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
Admin database biasanya tahu apa direktori ini, dan mereka tidak menyentuhnya - itu ada dan ada. Tetapi pengembang, terutama jika dia melihat pementasan, menggaruk kepalanya dan berpikir:
- Beberapa jenis log ... Mari kita hapus pg_xlog!Menghapus direktori, basis data berhenti berfungsi . Segera Anda harus mencari cara meningkatkan database setelah Anda menghapus log transaksi.
 Contoh kedua
Contoh kedua . Sekali lagi, kami membuka pemantauan dan melihat bahwa tidak ada cukup ruang. Kali ini tempat itu ditempati semacam pangkalan.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
Kami mencari basis data mana yang paling banyak memakan ruang, tabel dan indeks mana.

Ternyata ini adalah tabel dengan log historis. Kami tidak pernah membutuhkan catatan sejarah. Mereka ditulis berjaga-jaga, dan jika bukan karena masalah dengan tempat, tidak ada yang akan melihat mereka sampai kedatangan kedua:
- Mari kita bersihkan semua yang mm ... lebih tua dari Oktober!Buat permintaan pembaruan, jalankan, itu akan berhasil dan hapus beberapa baris.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
Kueri berjalan selama 10 menit, tetapi tabel masih membutuhkan jumlah ruang yang sama.
PostgreSQL menghapus baris dari tabel - semuanya benar, tetapi tidak mengembalikan tempat ke sistem operasi. Perilaku PostgreSQL ini tidak diketahui oleh sebagian besar pengembang dan bisa sangat mengejutkan.
Contoh ketiga . Misalnya, ORM membuat permintaan yang menarik. Biasanya semua orang menyalahkan ORM karena membuat kueri "buruk" yang membacakan beberapa tabel.
Misalkan ada beberapa operasi BERGABUNG yang membaca tabel secara paralel di banyak utas. PostgreSQL dapat memparalelkan operasi data dan dapat membaca tabel dalam banyak utas. Tetapi, mengingat kami memiliki beberapa server aplikasi, kueri ini membaca semua tabel beberapa ribu kali per detik. Ternyata server database kelebihan beban, disk tidak dapat mengatasinya, dan semua ini mengarah ke
502 Bad Gateway error dari backend - database tidak tersedia.
Tapi itu belum semuanya. Anda dapat mengingat fitur-fitur PostgerSQL lainnya.
- Rem proses latar belakang DBMS - PostgreSQL memiliki semua jenis pos pemeriksaan, vakum, dan replikasi.
- Overhead virtualisasi . Ketika database berjalan pada mesin virtual, pada besi yang sama ada juga mesin virtual di samping, dan mereka dapat konflik sumber daya.
- Penyimpanan berasal dari pabrikan Cina , NoName , yang kinerjanya tergantung pada bulan di Capricorn atau posisi Saturnus, dan tidak ada cara untuk mengetahui mengapa ia bekerja dengan cara ini. Basisnya adalah penderitaan.
- Konfigurasi default . Ini adalah topik favorit saya: pelanggan mengatakan bahwa basis datanya melambat - Anda lihat, dan ia memiliki konfigurasi default. Faktanya adalah konfigurasi default PostgreSQL dirancang untuk dijalankan pada teko terlemah . Basis diluncurkan, ia bekerja, tetapi ketika sudah bekerja pada perangkat keras tingkat menengah, maka konfigurasi ini tidak cukup, perlu disetel.
Paling sering, PostgreSQL tidak memiliki ruang disk atau kinerja disk. Untungnya, dengan prosesor, memori, dan jaringan, sebagai aturan, semuanya kurang lebih teratur.
Bagaimana menjadi Perlu pemantauan dan perencanaan! Kelihatannya jelas, tetapi untuk beberapa alasan, dalam banyak kasus, tidak ada yang merencanakan basis, dan pemantauan tidak mencakup semua yang perlu dipantau selama operasi PostgreSQL. Ada seperangkat aturan yang jelas, yang dengannya semuanya akan bekerja dengan baik, dan tidak "secara acak".
Perencanaan
Host basis data pada SSD tanpa ragu-ragu . SSD telah lama menjadi andal, stabil, dan produktif. Model SSD perusahaan telah ada selama bertahun-tahun.
Selalu rencanakan skema data . Jangan menulis ke database bahwa Anda meragukan apa yang dibutuhkan - dijamin tidak diperlukan. Contoh sederhana adalah tabel yang sedikit dimodifikasi dari salah satu pelanggan kami.

Ini adalah tabel log di mana ada kolom data tipe json. Secara relatif, Anda dapat menulis apa pun di kolom ini. Dari catatan terakhir dari tabel ini jelas bahwa log menempati 8 MB. PostgreSQL tidak memiliki masalah menyimpan catatan dengan panjang ini. PostgreSQL memiliki penyimpanan yang sangat baik yang mengunyah catatan tersebut.
Tetapi masalahnya adalah ketika server aplikasi membaca data dari tabel ini, mereka akan dengan mudah menyumbat seluruh bandwidth jaringan, dan permintaan lainnya akan menderita. Ini adalah masalah perencanaan skema data.
Gunakan partisi untuk setiap petunjuk dari cerita yang perlu disimpan selama lebih dari dua tahun . Partisi terkadang tampak rumit - Anda perlu repot dengan pemicu, dengan fungsi yang akan membuat partisi. Dalam versi baru PostgreSQL, situasinya lebih baik dan sekarang pengaturan partisi jauh lebih sederhana - setelah selesai, dan berfungsi.
Dalam contoh penghapusan data yang dipertimbangkan dalam 10 menit,
DELETE dapat diganti dengan
DROP TABLE - operasi semacam itu dalam kondisi yang sama hanya akan memakan waktu beberapa milidetik.
Ketika data diurutkan berdasarkan partisi, partisi tersebut dihapus secara harfiah dalam beberapa milidetik, dan OS langsung mengambil alih. Mengelola data historis lebih mudah, lebih mudah, dan lebih aman.
Pemantauan
Pemantauan adalah topik besar yang terpisah, tetapi dari sudut pandang basis data ada rekomendasi yang dapat masuk ke dalam satu bagian artikel.
Secara default, banyak sistem pemantauan menyediakan pemantauan prosesor, memori, jaringan, ruang disk, tetapi, sebagai aturannya,
tidak ada pembuangan perangkat disk . Informasi tentang seberapa dimuat disk, berapa bandwidth saat ini pada disk dan nilai latensi harus selalu ditambahkan ke pemantauan. Ini akan membantu Anda dengan cepat mengevaluasi bagaimana drive dimuat.
Ada banyak opsi pemantauan PostgreSQL, ada untuk setiap selera. Inilah beberapa poin yang harus ada.
- Klien yang Terhubung . Penting untuk memantau status mereka bekerja, dengan cepat menemukan pelanggan "berbahaya" yang membahayakan database, dan mematikannya.
- Kesalahan Penting untuk memantau kesalahan untuk melacak seberapa baik database berfungsi: tidak ada kesalahan - hebat, kesalahan telah muncul - alasan untuk melihat log dan mulai memahami apa yang salah.
- Permintaan (pernyataan) . Kami memantau karakteristik permintaan kuantitatif dan kualitatif untuk menilai secara kasar apakah kami memiliki permintaan yang lambat, panjang, atau padat sumber daya.
Untuk informasi lebih lanjut, lihat laporan
"Dasar-Dasar Pemantauan PostgreSQL" dengan HighLoad ++ Siberia dan halaman
Pemantauan di Wiki PostgreSQL.
Ketika kami merencanakan semuanya dan "menutupi diri kami" dengan pemantauan, kami masih bisa menghadapi beberapa masalah.
Scaling
Biasanya, pengembang melihat garis database di konfigurasi. Dia tidak terlalu tertarik pada bagaimana hal itu diatur secara internal - bagaimana pos pemeriksaan, replikasi, penjadwal bekerja. Pengembang sudah memiliki sesuatu untuk dilakukan - selain itu ada banyak hal menarik yang ingin ia coba.
"Beri aku alamat pangkalan, lalu aku sendiri." © Pengembang anonim.
Ketidaktahuan subjek menyebabkan konsekuensi yang cukup menarik ketika pengembang mulai menulis pertanyaan yang berfungsi dalam database ini. Fantasi saat menulis kueri terkadang memberikan efek yang menakjubkan.
Ada dua jenis transaksi.
Transaksi OLTP cepat, pendek, ringan yang mengambil pecahan satu milidetik. Mereka bekerja sangat cepat, dan ada banyak dari mereka.
OLAP - kueri analitis - lambat, panjang, berat, baca array tabel besar dan baca statistik.
Selama 2-3 tahun terakhir, singkatan
HTAP sering berbunyi - Hybrid Transaction / Analytical Processing atau
hybrid transactional-analytical processing . Jika Anda tidak punya waktu untuk memikirkan penskalaan dan keragaman permintaan OLAP dan OLTP, Anda dapat mengatakan: "Kami memiliki HTAP!" Tetapi pengalaman dan rasa sakit kesalahan menunjukkan bahwa, setelah semua, berbagai jenis permintaan harus hidup terpisah satu sama lain, karena permintaan OLAP lama memblokir permintaan OLTP ringan.
Jadi kita sampai pada pertanyaan tentang bagaimana skala PostgreSQL untuk menyebarkan beban, dan semua orang puas.
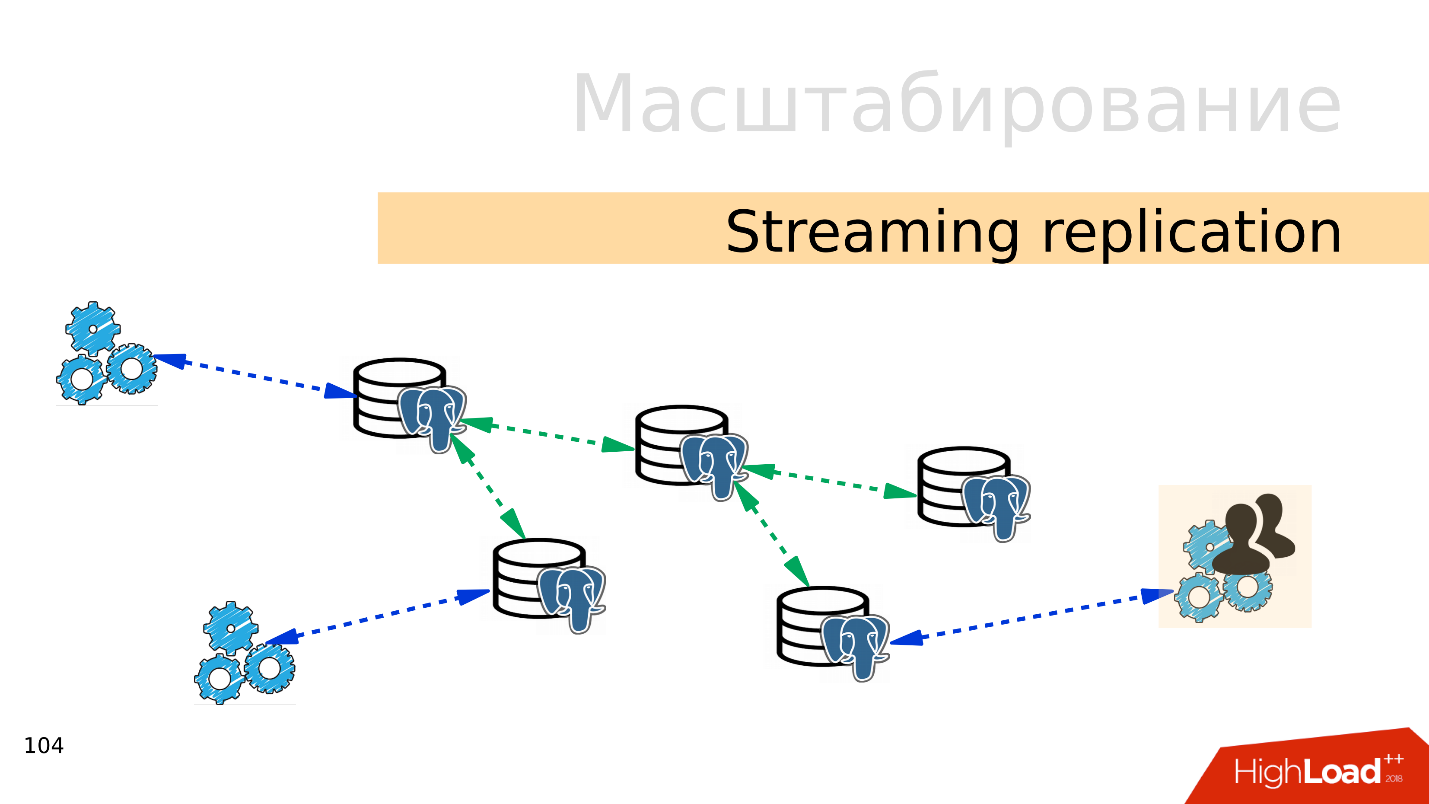
Streaming replikasi . Opsi termudah adalah
replikasi streaming . Ketika aplikasi bekerja dengan database, kami menghubungkan beberapa replika ke database ini dan mendistribusikan beban. Rekaman masih pergi ke pangkalan utama, dan membaca ke replika. Metode ini memungkinkan Anda untuk skala sangat luas.
Plus, Anda dapat menghubungkan lebih banyak replika ke replika individual dan mendapatkan
replikasi berjenjang . Grup pengguna atau aplikasi terpisah yang, misalnya, membaca analytics, dapat dipindahkan ke replika terpisah.
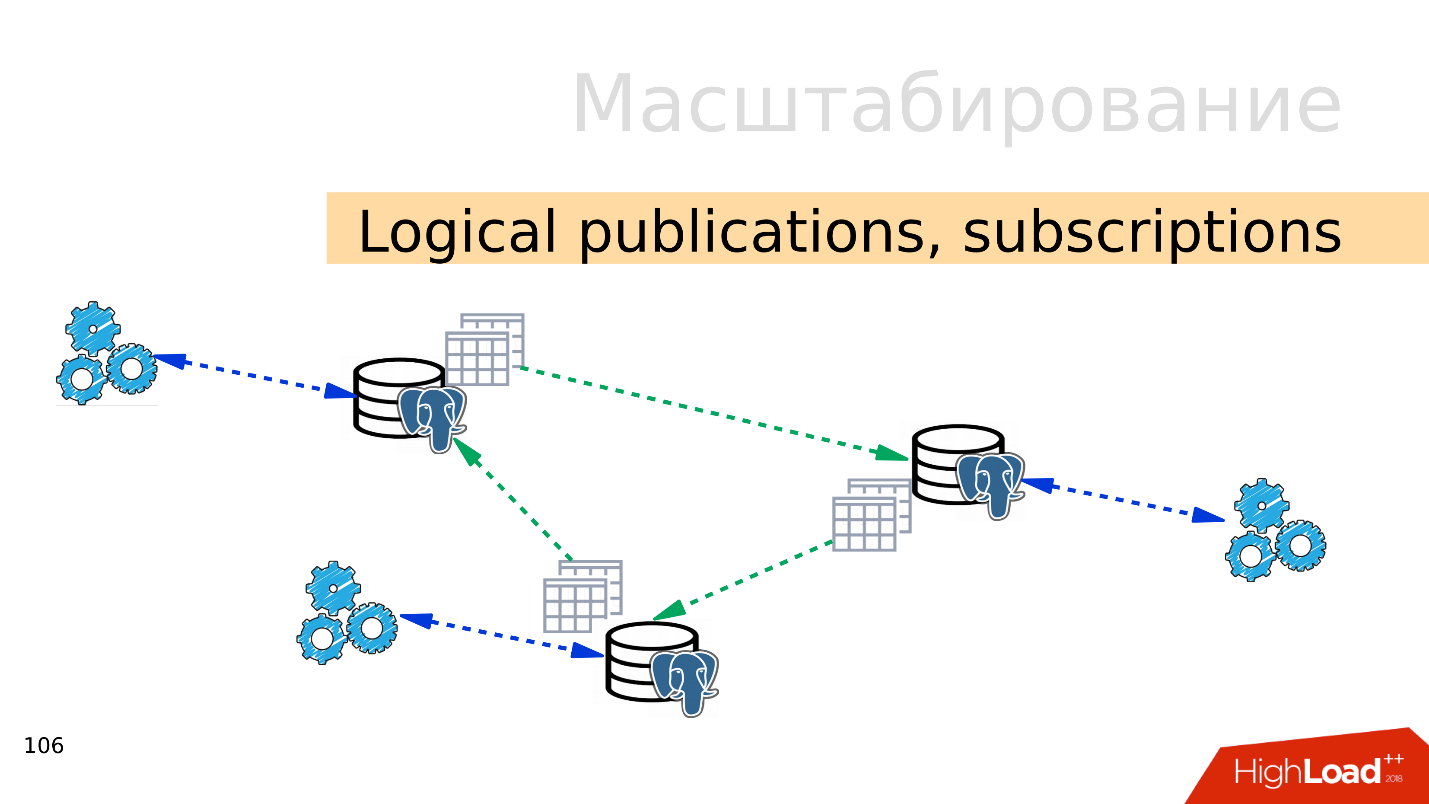
 Publikasi logis, langganan
Publikasi logis, langganan - mekanisme publikasi logis dan langganan menyiratkan adanya beberapa server PostgreSQL independen dengan basis data dan kumpulan tabel terpisah. Kumpulan tabel ini dapat dihubungkan ke database tetangga, mereka akan terlihat oleh aplikasi yang dapat menggunakannya secara normal. Artinya, semua perubahan yang terjadi pada sumber direplikasi ke basis tujuan dan terlihat di sana. Bekerja sangat baik dengan PostgreSQL 10.
 Tabel asing, Partisi Deklaratif - partisi deklaratif dan tabel eksternal
Tabel asing, Partisi Deklaratif - partisi deklaratif dan tabel eksternal . Anda dapat mengambil beberapa PostgreSQL dan membuat beberapa set tabel di sana yang akan menyimpan rentang data yang diinginkan. Ini bisa berupa data untuk tahun tertentu atau data yang dikumpulkan dari rentang apa pun.
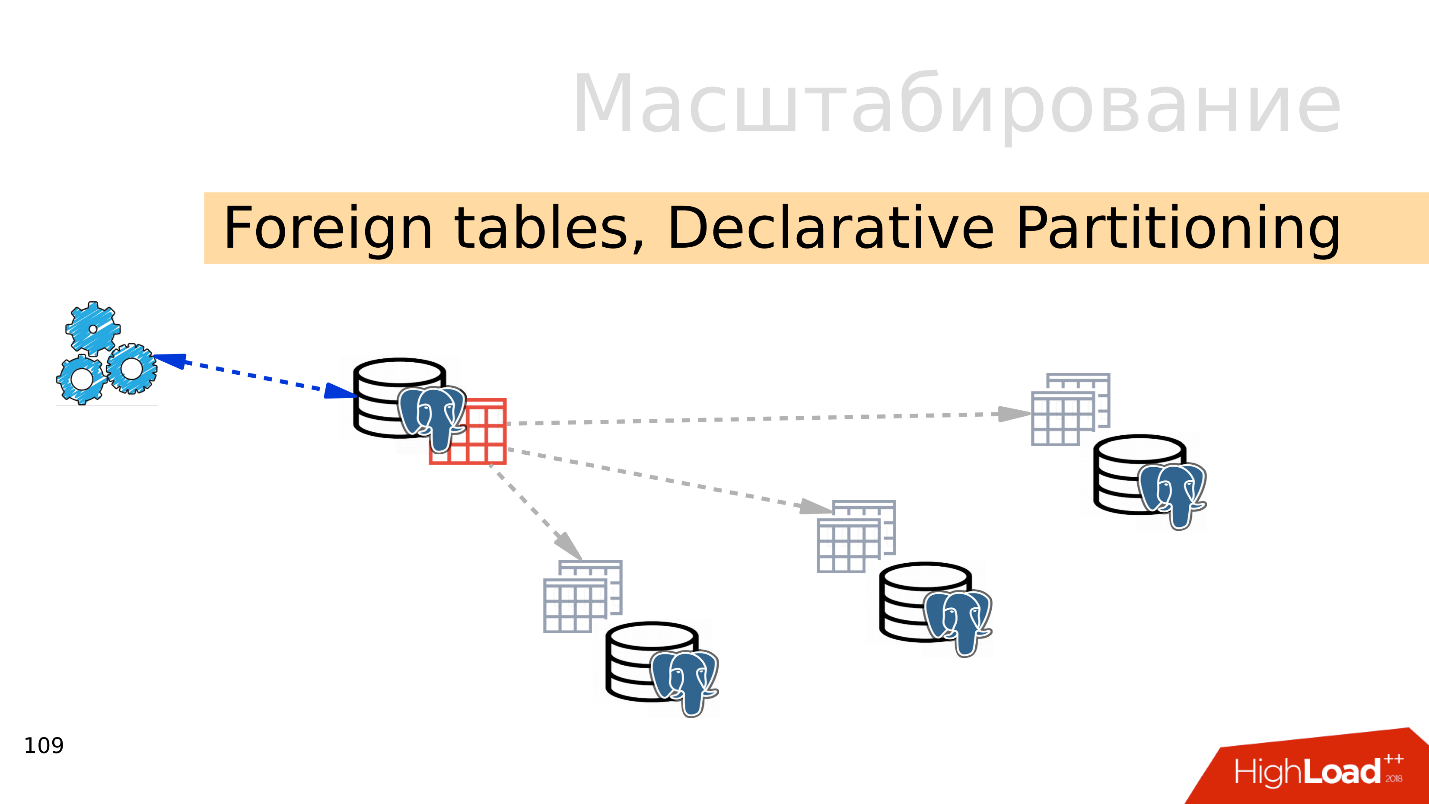
Menggunakan mekanisme tabel eksternal, Anda dapat menggabungkan semua database ini dalam bentuk tabel dipartisi dalam PostgreSQL terpisah. Aplikasi mungkin sudah berfungsi dengan tabel partisi ini, tetapi sebenarnya itu akan membaca data dari partisi jarak jauh. Ketika volume data lebih dari kemampuan satu server, maka ini sharding.

Semua ini dapat digabungkan ke dalam penyebaran konfigurasi, untuk menghasilkan topologi replikasi PostgreSQL yang berbeda, tetapi bagaimana semuanya bekerja dan bagaimana mengelolanya adalah topik dari laporan terpisah.
Di mana untuk memulai?
Opsi termudah adalah
dengan replikasi . Langkah pertama adalah menyebarkan beban membaca dan menulis. Yaitu, menulis kepada master, dan membaca dari replika. Jadi kami skala beban dan melakukan pembacaan dari penyihir. Selain itu, jangan lupakan analis. Kueri analitik bekerja untuk waktu yang lama, mereka membutuhkan replika terpisah dengan pengaturan terpisah sehingga kueri analitik yang panjang tidak dapat mengganggu sisanya.
Langkah selanjutnya adalah
menyeimbangkan . Kami masih memiliki baris yang sama dalam konfigurasi yang dioperasikan pengembang. Dia membutuhkan tempat di mana dia akan menulis dan membaca. Ada beberapa opsi di sini.
Ideal adalah menerapkan penyeimbangan
pada tingkat aplikasi , ketika aplikasi itu sendiri tahu dari mana membaca data, dan tahu bagaimana memilih replika. Misalkan saldo akun selalu mutakhir dan perlu dibaca dari master, dan gambar produk atau informasi tentangnya dapat dibaca dengan penundaan dan dilakukan dari replika.
- DNS Round Robin , menurut pendapat saya, bukan implementasi yang sangat nyaman, karena kadang-kadang itu bekerja untuk waktu yang lama dan tidak memberikan waktu yang diperlukan ketika berpindah peran wizard antara server dalam kasus failover.
- Opsi yang lebih menarik adalah menggunakan Keepalived dan HAProxy . Alamat virtual untuk master dan set replika dilemparkan antara server HAProxy, dan HAProxy sudah menyeimbangkan lalu lintas.
- Patroni, DCS bersamaan dengan sesuatu seperti ZooKeeper, etcd, Consul - opsi yang paling menarik, menurut saya. Artinya, penemuan layanan bertanggung jawab atas informasi siapa yang menjadi master sekarang dan siapa yang merupakan replika. Patroni mengelola sekelompok PostgreSQL, melakukan switching - jika topologi telah berubah, informasi ini akan muncul dalam penemuan layanan, dan aplikasi dapat dengan cepat mengetahui topologi saat ini.
Dan ada nuansa dengan replikasi, yang paling umum adalah
lag replikasi . Anda dapat melakukannya seperti GitLab, dan ketika lag terakumulasi, cukup jatuhkan basis. Tapi kami memiliki pemantauan komprehensif - kami melihatnya dan melihat transaksi panjang.
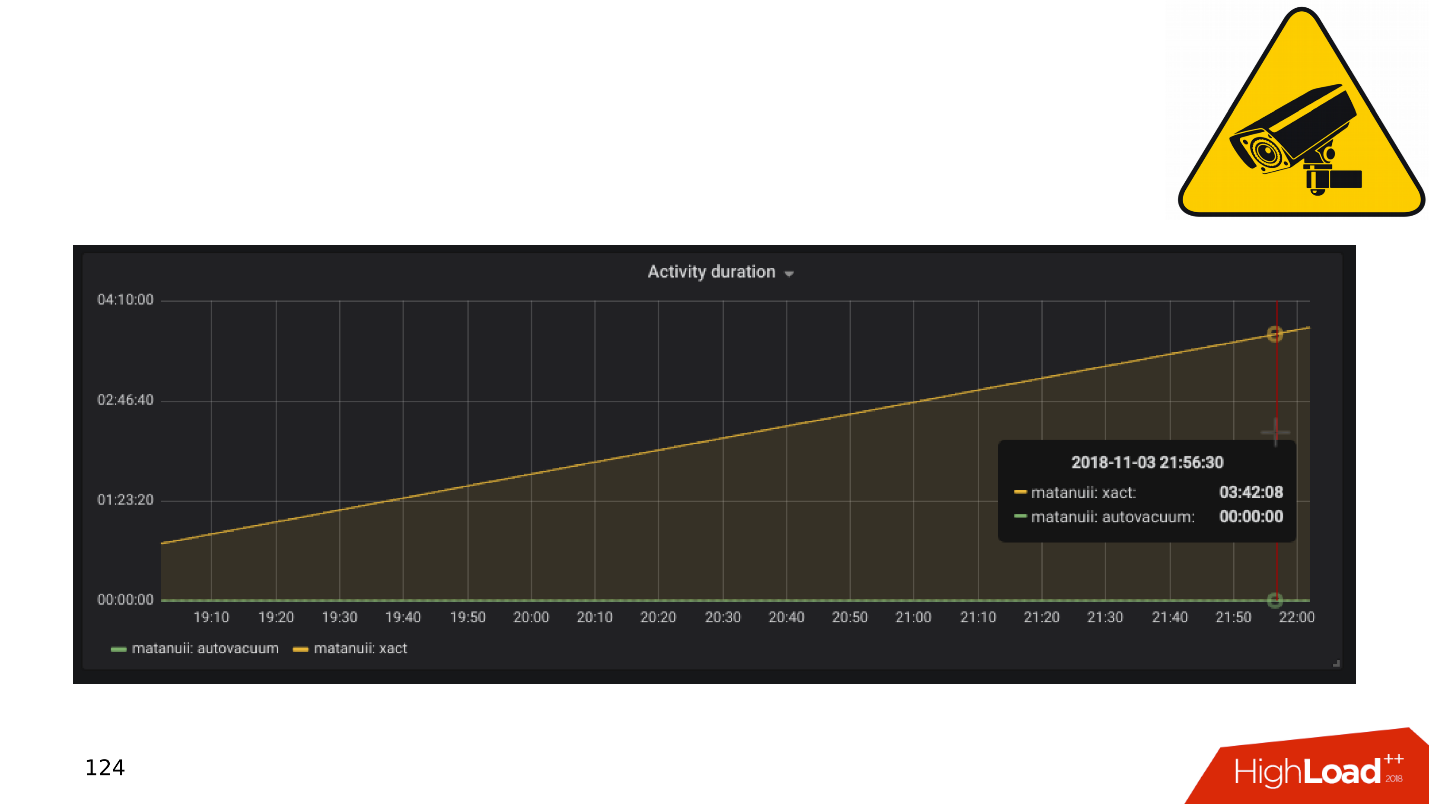
Aplikasi dan Transaksi DBMS
Secara umum, transaksi lambat dan menganggur menghasilkan:
- penurunan produktivitas - bukan karena spasmodik yang tajam, tetapi halus;
- kunci dan kebuntuan , karena transaksi lama menahan kunci pada baris dan mencegah transaksi lainnya bekerja;
- 50 * Kesalahan HTTP pada backend , kesalahan antarmuka, atau di tempat lain.
Mari kita lihat sedikit teori tentang bagaimana masalah ini muncul, dan mengapa mekanisme transaksi yang lama dan tak berguna itu berbahaya.
PostgreSQL memiliki MVCC - secara relatif, mesin basis data. Ini memungkinkan pelanggan untuk bekerja secara kompetitif dengan data tanpa mengganggu satu sama lain: pembaca tidak mengganggu pembaca, dan penulis tidak mengganggu penulis. Tentu saja, ada beberapa pengecualian, tetapi dalam hal ini tidak penting.
Ternyata dalam database untuk satu baris ada beberapa versi untuk transaksi yang berbeda. Klien terhubung, basis data memberi mereka snapshot data, dan di dalam snapshot ini versi yang berbeda dari garis yang sama mungkin ada. Dengan demikian, dalam siklus hidup basis data, transaksi digeser, diganti satu sama lain, dan versi baris muncul yang tidak diperlukan oleh siapa pun.
Jadi ada
kebutuhan untuk pengumpul sampah - vakum otomatis . Transaksi lama ada dan mencegah vakum otomatis dari membersihkan versi baris yang tidak perlu. Data sampah ini mulai mengembara dari memori ke disk, dari disk ke memori. Untuk menyimpan sampah ini, sumber daya CPU dan memori terbuang sia-sia.
Semakin lama transaksi, semakin banyak sampah dan kinerja yang lebih rendah.
Dari sudut pandang "Siapa yang harus disalahkan?", Aplikasi ini harus disalahkan atas penampilan transaksi panjang. Jika basis data akan ada dengan sendirinya, lama, transaksi apa pun tidak akan diambil dari mana pun. Dalam praktiknya, ada opsi berikut untuk penampilan transaksi idle.
"Ayo pergi ke sumber eksternal .
" Aplikasi membuka transaksi, melakukan sesuatu dalam database, kemudian memutuskan untuk beralih ke sumber eksternal, misalnya, Memcached atau Redis, dengan harapan akan kembali ke database, terus bekerja dan menutup transaksi. Tetapi jika kesalahan terjadi pada sumber eksternal, aplikasi crash dan transaksi tetap ditutup sampai seseorang memperhatikan dan membunuhnya.
Tidak ada penanganan kesalahan . Di sisi lain, mungkin ada masalah dalam menangani kesalahan. Ketika, sekali lagi, aplikasi membuka transaksi, memecahkan beberapa masalah dalam database, kembali ke eksekusi kode, melakukan beberapa fungsi dan perhitungan, untuk terus bekerja dalam transaksi dan menutupnya. Ketika pada perhitungan ini operasi aplikasi terganggu dengan kesalahan, kode kembali ke awal siklus, dan transaksi tetap tidak tertutup.
Faktor manusia . Misalnya, administrator, pengembang, analis, bekerja di beberapa pgAdmin atau di DBeaver - membuka transaksi, melakukan sesuatu di dalamnya. Kemudian orang itu terganggu, dia beralih ke tugas lain, lalu ke yang ketiga, lupa tentang transaksi, pergi untuk akhir pekan, dan transaksi terus menggantung. Kinerja dasar menderita.
Mari kita lihat apa yang harus dilakukan dalam kasus ini.
- Kami memiliki pemantauan, oleh karena itu, kami membutuhkan peringatan dalam pemantauan . Setiap transaksi yang hang lebih dari satu jam dan tidak melakukan apa-apa adalah kesempatan untuk melihat dari mana asalnya dan memahami apa yang salah.
- Langkah selanjutnya adalah menembak transaksi seperti itu melalui tugas di mahkota (pg_terminate_backend (pid)) atau mengkonfigurasi dalam konfigurasi PostgreSQL. Diperlukan ambang batas 10-30 menit, setelah itu transaksi diselesaikan secara otomatis.
- Aplikasi refactoring . Tentu saja, Anda perlu mencari tahu dari mana transaksi idle berasal, mengapa mereka terjadi dan menghilangkan tempat-tempat tersebut.
Hindari transaksi lama dengan segala cara, karena sangat memengaruhi kinerja basis data.
Semuanya menjadi lebih menarik ketika tugas yang tertunda muncul, misalnya, Anda perlu menghitung unit dengan hati-hati. Dan kita sampai pada masalah konstruksi sepeda.
Konstruksi sepeda
Topik sakit. Bisnis di sisi aplikasi perlu melakukan pemrosesan latar belakang acara. Misalnya, untuk menghitung agregat: minimum, maksimum, nilai rata-rata, mengirim pemberitahuan kepada pengguna, mengeluarkan faktur kepada pelanggan, mengatur akun pengguna setelah mendaftar atau mendaftar di layanan tetangga - lakukan pemrosesan yang tertunda.
Esensi dari tugas-tugas tersebut adalah sama - mereka ditunda untuk nanti. Tabel muncul di database yang hanya menjalankan antrian.

Berikut adalah pengidentifikasi tugas, waktu ketika tugas dibuat, saat diperbarui, pawang yang mengambilnya, jumlah upaya yang harus diselesaikan. Jika Anda memiliki tabel yang bahkan jauh menyerupai yang ini, maka Anda memiliki
antrian yang ditulis sendiri .
Semua ini berfungsi dengan baik sampai transaksi panjang muncul. Setelah itu,
tabel yang berfungsi dengan ukuran antrian membengkak . Pekerjaan baru ditambahkan setiap saat, yang lama dihapus, pembaruan terjadi - sebuah tabel dengan perekaman intensif diperoleh. Ini harus dibersihkan secara teratur dari versi string yang usang sehingga kinerja tidak menderita.
Waktu pemrosesan bertambah - transaksi panjang menahan kunci pada versi baris yang sudah ketinggalan zaman atau mencegah kekosongan untuk membersihkannya. Ketika tabel bertambah besar, waktu pemrosesan juga meningkat, karena Anda perlu membaca banyak halaman dengan sampah. Waktu meningkat, dan
antrian di beberapa titik berhenti berfungsi sama sekali .
Di bawah ini adalah contoh bagian atas dari salah satu pelanggan kami, yang memiliki antrian. Semua permintaan hanya terkait dengan antrian.

Perhatikan waktu eksekusi permintaan ini - semuanya kecuali satu di antaranya bekerja lebih dari dua puluh detik.
Untuk mengatasi masalah ini,
Skytools PgQ , manajer antrian untuk PostgreSQL, telah ditemukan sejak lama. Jangan menemukan kembali sepeda Anda - ambil PgQ, atur sekali dan lupakan garisnya.
Benar, dia juga punya fitur. Skytools PgQ memiliki
sedikit dokumentasi . Setelah membaca halaman resmi, orang merasa bahwa dia tidak mengerti apa-apa. Perasaan itu tumbuh ketika Anda mencoba melakukan sesuatu. Semuanya berfungsi, tetapi
cara kerjanya tidak jelas . Semacam sihir Jedi. Tetapi banyak informasi dapat ditemukan di
milis . Ini bukan format yang sangat nyaman, tetapi ada banyak hal menarik di sana, dan Anda harus membaca lembar ini.
Meskipun kontra, Skytools PgQ bekerja pada prinsip "mengatur dan melupakan." , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
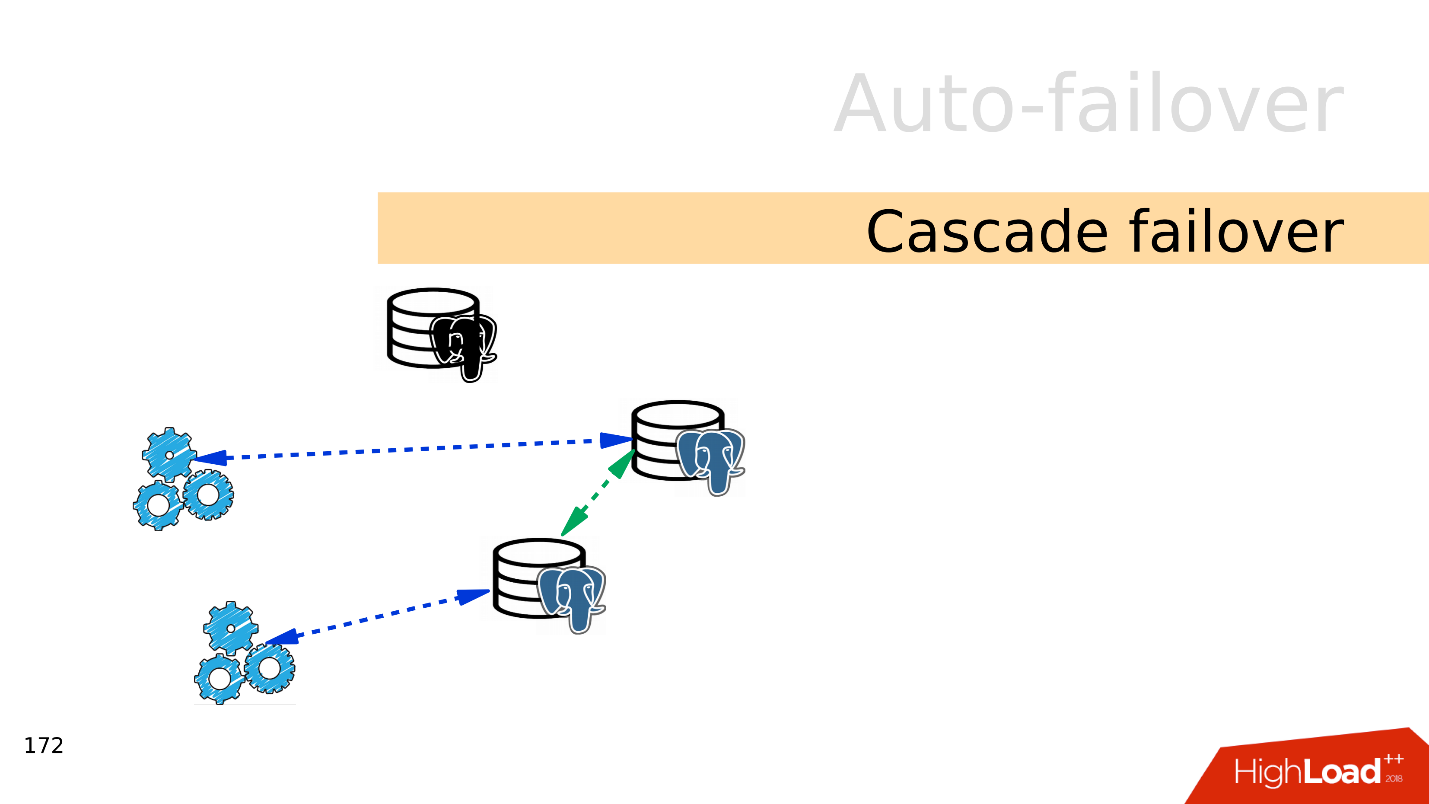
, . , .
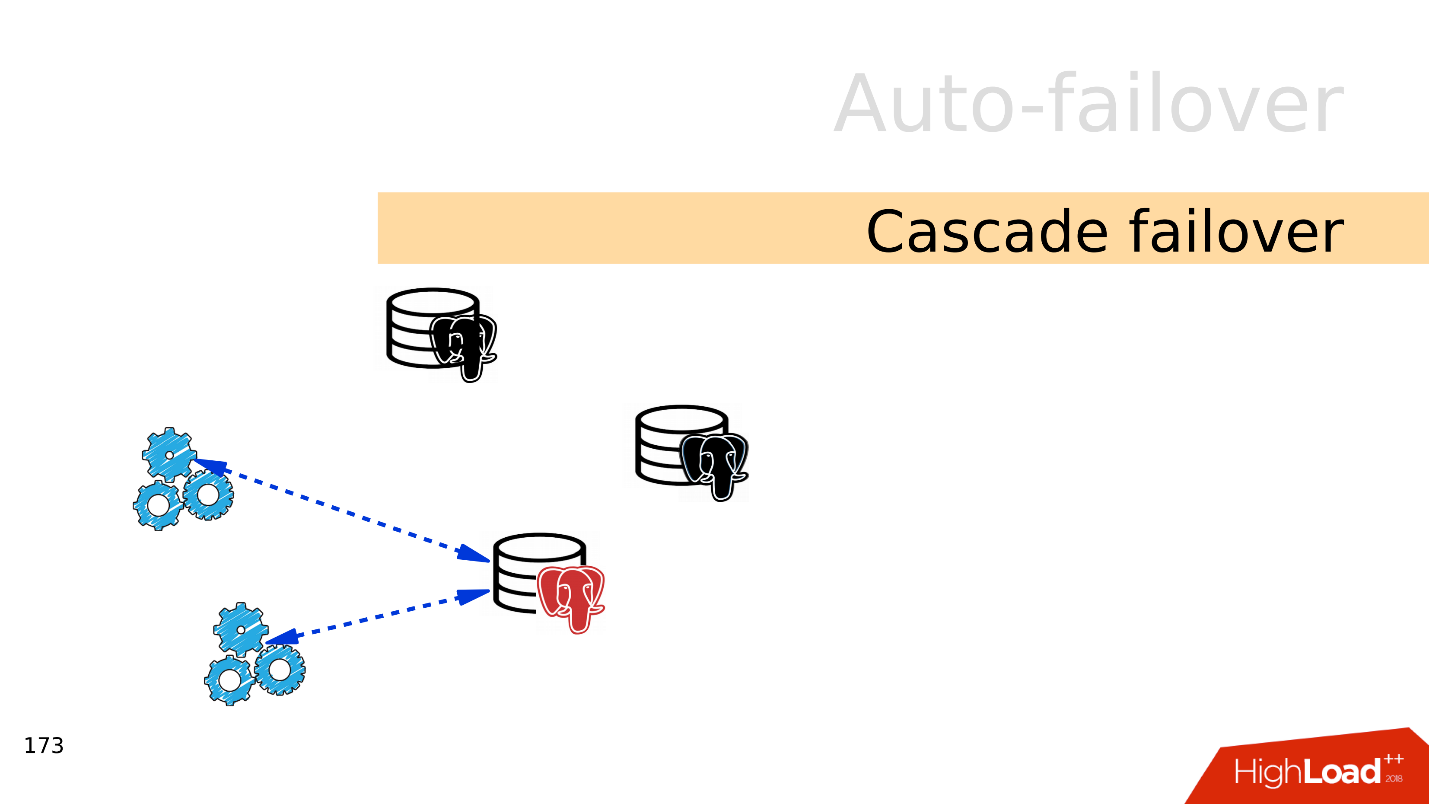
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
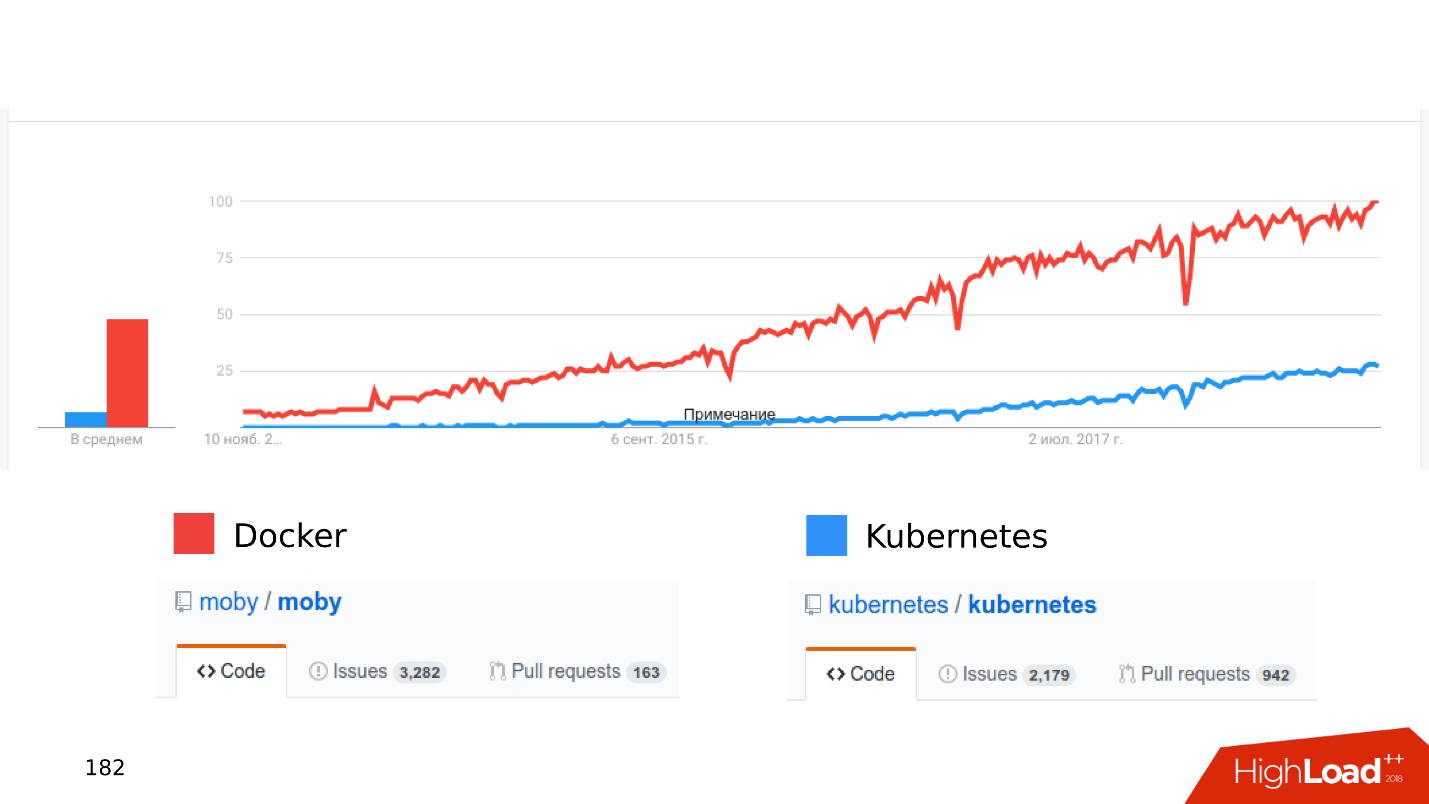
, .
« Kubernetes...» .
— stateful , - . Dimana? . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
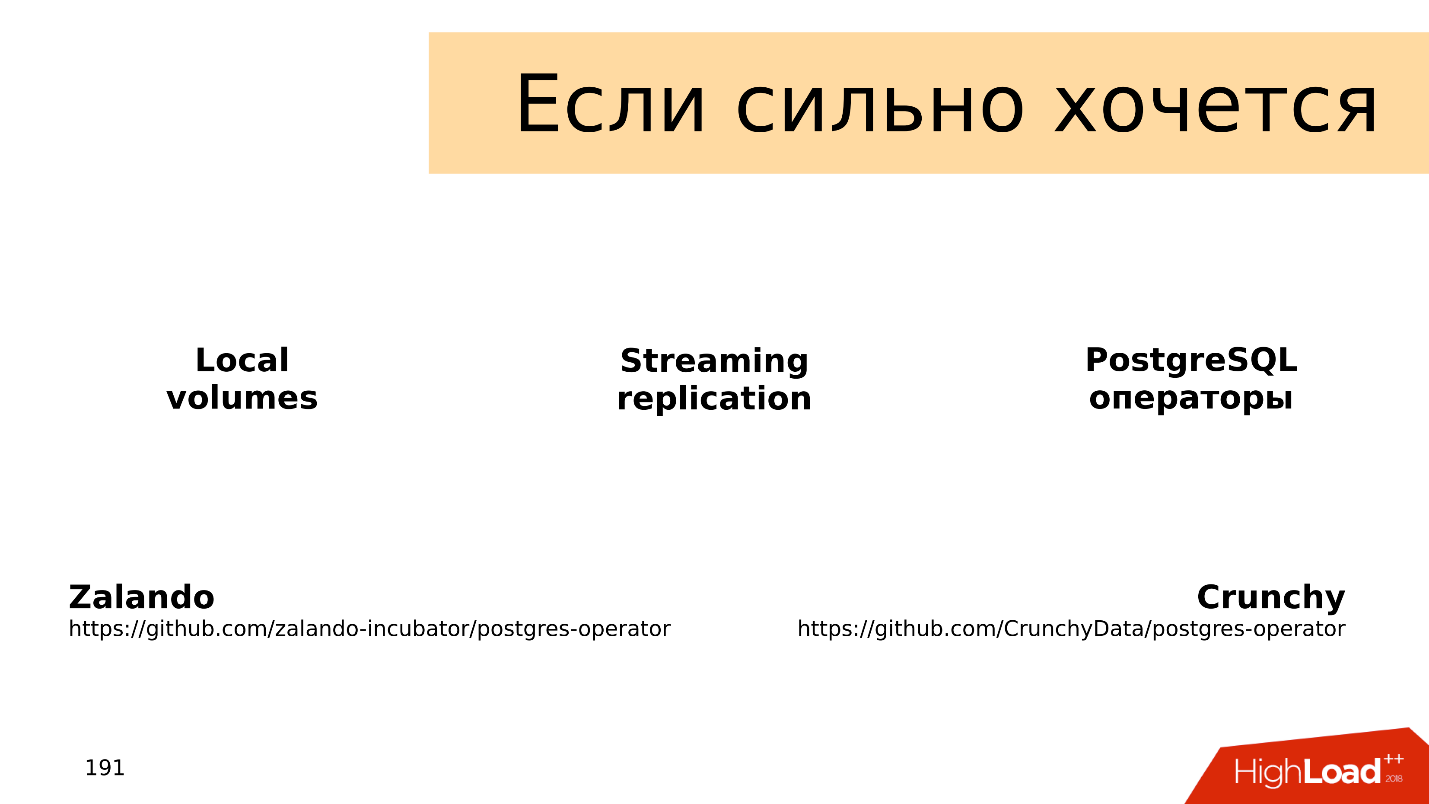
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
Ringkasan
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !