Karya ilmiah yang signifikan dari 2012 mengubah bidang perangkat lunak pengenalan gambar

Hari ini saya dapat, misalnya, membuka Foto Google, menulis "pantai", dan melihat banyak foto saya dari berbagai pantai yang saya kunjungi dalam dekade terakhir. Dan saya tidak pernah menandatangani foto saya - Google mengenali pantai berdasarkan konten mereka. Fitur yang tampaknya membosankan ini didasarkan pada teknologi yang disebut "deep nevolute neural network", yang memungkinkan program memahami gambar menggunakan metode kompleks yang tidak tersedia untuk teknologi generasi sebelumnya.
Dalam beberapa tahun terakhir, para peneliti telah menemukan bahwa keakuratan perangkat lunak menjadi lebih baik karena mereka membangun jaringan saraf yang lebih dalam (NS) dan melatih mereka pada set data yang semakin besar. Ini menciptakan kebutuhan yang tak terpuaskan untuk daya komputasi, dan produsen GPU yang diperkaya seperti Nvidia dan AMD. Beberapa tahun yang lalu, Google mengembangkan chip khusus untuk Majelis Nasional, sementara perusahaan lain berusaha mengikutinya.
Di Tesla, misalnya, Andrei Karpati, seorang ahli pembelajaran yang mendalam, telah ditunjuk sebagai kepala proyek Autopilot. Sekarang pembuat mobil mengembangkan chip sendiri untuk mempercepat pekerjaan NS di versi autopilot di masa depan. Atau gunakan Apple: chip A11 dan A12, yang merupakan pusat dari iPhone terbaru, memiliki "
prosesor saraf " Neural Engine yang mempercepat NS dan memungkinkan aplikasi untuk pengenalan gambar dan suara bekerja lebih baik.
Para ahli yang saya wawancarai untuk artikel ini melacak dimulainya booming pembelajaran yang mendalam ke pekerjaan tertentu: AlexNet, dinamai menurut penulis utama, Alex Krizhevsky. "Saya percaya bahwa 2012 adalah tahun yang penting ketika pekerjaan AlexNet keluar," kata Sean Gerrish, seorang pakar pertahanan dan penulis buku "
How Smart Cars Think ".
Hingga 2012, jaringan saraf dalam (GNS) sedikit terbelakang di dunia Wilayah Moskow. Tetapi kemudian Krizhevsky dan rekan-rekannya dari University of Toronto mengambil bagian dalam kompetisi bergengsi untuk pengenalan gambar, dan program mereka secara dramatis melampaui keakuratan segala sesuatu yang dikembangkan sebelumnya. Hampir seketika, STS menjadi teknologi terkemuka dalam pengenalan gambar. Peneliti lain yang menggunakan teknologi ini segera menunjukkan peningkatan lebih lanjut dalam akurasi pengenalan.
Dalam artikel ini, kita akan mempelajari pembelajaran yang mendalam. Saya akan menjelaskan apa itu NS, bagaimana mereka dilatih, dan mengapa mereka membutuhkan sumber daya komputasi seperti itu. Dan kemudian saya akan menjelaskan mengapa tipe tertentu dari NS - jaringan konvolusi yang mendalam - memahami gambar dengan sangat baik. Jangan khawatir, akan ada banyak gambar.
Contoh sederhana dengan satu neuron
Konsep "jaringan saraf" mungkin tampak tidak jelas bagi Anda, jadi mari kita mulai dengan contoh sederhana. Misalkan Anda ingin Majelis Nasional memutuskan apakah akan mengendarai mobil berdasarkan sinyal lalu lintas hijau, kuning dan merah. NS dapat mengatasi masalah ini dengan satu neuron.

Neuron menerima data input (1 aktif, 0 mati), dikalikan dengan bobot yang sesuai, dan menambahkan semua nilai bobot. Kemudian neuron menambahkan offset yang mendefinisikan nilai ambang untuk "aktivasi" neuron. Dalam hal ini, jika output positif, kami percaya bahwa neuron telah diaktifkan - dan sebaliknya. Neuron setara dengan ketimpangan "hijau - merah - 0,5> 0". Jika ternyata benar - yaitu, hijau menyala dan merah tidak menyala - maka mobil harus pergi.
Di NS nyata, neuron buatan mengambil langkah lain. Dengan menambahkan input tertimbang dan menambahkan offset, neuron menggunakan fungsi aktivasi nonlinear. Sering digunakan adalah sigmoid, fungsi berbentuk S, selalu menghasilkan nilai dari 0 hingga 1.
Menggunakan fungsi aktivasi tidak akan mengubah hasil model lampu lalu lintas sederhana kami (kami hanya perlu menggunakan nilai ambang 0,5, bukan 0). Tetapi nonlinearitas fungsi aktivasi diperlukan agar NS dapat memodelkan fungsi yang lebih kompleks. Tanpa fungsi aktivasi, setiap NS kompleks yang sewenang-wenang direduksi menjadi kombinasi linier dari data input. Fungsi linear tidak dapat mensimulasikan fenomena kompleks di dunia nyata. Fungsi aktivasi nonlinier memungkinkan NS untuk memperkirakan
fungsi matematika apa pun .
Contoh jaringan
Tentu saja, ada banyak cara untuk memperkirakan suatu fungsi. NS menonjol dengan fakta bahwa kita tahu bagaimana "melatih" mereka menggunakan aljabar kecil, sekelompok data, dan lautan kekuatan komputasi. Alih-alih mengarahkan programmer untuk mengembangkan NS untuk tugas tertentu, kita dapat membuat perangkat lunak yang dimulai dengan NS yang cukup umum, mempelajari banyak contoh yang ditandai, dan kemudian mengubah NS sehingga memberikan label yang benar untuk sebanyak mungkin contoh. Harapannya adalah bahwa NS akhir akan meringkas data dan akan menghasilkan label yang benar untuk contoh-contoh yang sebelumnya tidak ada dalam database.
Proses menuju tujuan ini dimulai jauh sebelum AlexNet. Pada tahun 1986, trio peneliti menerbitkan
karya tengara tentang backpropagation, sebuah teknologi yang membantu menjadikan pembelajaran matematika NS kompleks menjadi kenyataan.
Untuk membayangkan cara kerja backpropagation, mari kita lihat NS sederhana yang dijelaskan oleh Michael Nielsen di
buku teks GO online yang sangat baik. Tujuan jaringan adalah untuk memproses gambar angka yang ditulis tangan dalam resolusi 28x28 piksel dan menentukan dengan benar apakah angka 0, 1, 2, dll. Ditulis.
Setiap gambar adalah 28 * 28 = 784 jumlah input, yang masing-masing merupakan bilangan real dari 0 hingga 1, menunjukkan seberapa banyak pixel tersebut terang atau gelap. Nielsen menciptakan NA seperti ini:
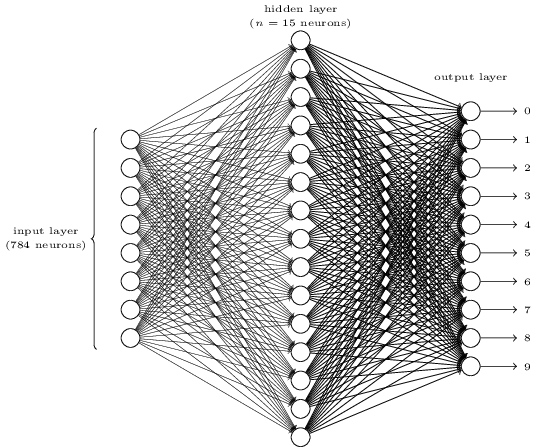
Setiap lingkaran di tengah dan di kolom kanan adalah neuron yang mirip dengan yang kita periksa di bagian sebelumnya. Setiap neuron mengambil rata-rata tertimbang dari input, menambahkan offset, dan menerapkan fungsi aktivasi. Lingkaran di sebelah kiri bukan neuron, mereka mewakili data input jaringan. Dan meskipun gambar hanya menunjukkan 8 lingkaran input, sebenarnya ada 784 di antaranya - satu untuk setiap piksel.
Masing-masing dari 10 neuron di sebelah kanan harus "memicu" nomornya sendiri: yang teratas akan menyala ketika tulisan tangan 0 dimasukkan (dan hanya dalam kasus ini), yang kedua ketika jaringan melihat tulisan tangan 1 (dan hanya itu), dan seterusnya.
Setiap neuron merasakan input dari masing-masing neuron dari lapisan sebelumnya. Jadi masing-masing dari 15 neuron di tengah menerima 784 nilai input. Masing-masing dari 15 neuron ini memiliki parameter bobot untuk masing-masing nilai input 784. Ini berarti bahwa hanya lapisan ini yang memiliki parameter berat 15 * 784 = 11 760. Demikian pula, lapisan output berisi 10 neuron, yang masing-masing menerima input dari semua 15 neuron dari lapisan tengah, yang menambahkan 15 * 10 = 150 parameter berat lainnya. Selain itu, jaringan memiliki 25 variabel perpindahan - satu untuk masing-masing dari 25 neuron.
Pelatihan jaringan saraf
Tujuan dari pelatihan ini adalah untuk menyempurnakan 11.935 parameter ini untuk memaksimalkan kemungkinan bahwa neuron output yang diinginkan - dan hanya itu - diaktifkan ketika jaringan memberikan gambar dari digit tulisan tangan. Kita dapat melakukan ini dengan set gambar MNIST yang terkenal, di mana ada 60.000 gambar yang ditandai dengan resolusi 28x28 piksel.
 160 dari 60.000 gambar dari set MNIST
160 dari 60.000 gambar dari set MNISTNielsen menunjukkan cara melatih jaringan menggunakan 74 baris kode python biasa - tanpa perpustakaan untuk MO. Belajar dimulai dengan memilih nilai acak untuk masing-masing 11.935 parameter ini, bobot dan offset. Kemudian program melewati contoh gambar, melewati dua tahap dengan masing-masing gambar:
- Langkah propagasi maju menghitung output jaringan berdasarkan pada gambar input dan parameter saat ini.
- Langkah backpropagation menghitung penyimpangan hasil dari data output yang benar dan mengubah parameter jaringan sehingga sedikit meningkatkan efisiensinya pada gambar ini.
Sebuah contoh Katakanlah jaringan menerima gambar berikut:
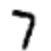
Jika dikalibrasi dengan baik, maka pin "7" harus menuju ke 1, dan sembilan kesimpulan lainnya harus ke 0. Tapi, katakanlah sebaliknya, jaringan pada output "0" memberikan nilai 0,8. Ini terlalu banyak! Algoritma pelatihan mengubah bobot input neuron yang bertanggung jawab untuk "0" sehingga menjadi lebih dekat dengan 0 saat gambar ini diproses.
Untuk ini, algoritma backpropagation menghitung gradien kesalahan untuk setiap bobot input. Ini adalah ukuran bagaimana kesalahan output akan berubah untuk perubahan bobot input yang diberikan. Kemudian algoritma menggunakan gradien untuk memutuskan berapa banyak mengubah setiap bobot input - semakin besar gradien, semakin kuat perubahan.
Dengan kata lain, proses pelatihan “melatih” neuron pada lapisan output untuk kurang memperhatikan input tersebut (neuron di lapisan tengah) yang mendorong mereka ke jawaban yang salah, dan lebih ke input yang mendorong ke arah yang benar.
Algoritme mengulangi langkah ini untuk semua neuron output lainnya. Ini mengurangi bobot input untuk neuron "1", "2", "3", "4", "5", "6", "8" dan "9" (tetapi tidak "7") untuk menurunkan nilai ini. neuron keluaran. Semakin tinggi nilai output, semakin besar gradien kesalahan output sehubungan dengan bobot input - dan semakin berat akan berkurang.
Dan sebaliknya, algoritma meningkatkan bobot data input untuk output "7", yang membuat neuron menghasilkan nilai yang lebih tinggi saat berikutnya diberikan gambar ini. Sekali lagi, input dengan nilai yang lebih besar akan menambah bobot lebih banyak, yang akan membuat neuron output “7” lebih memperhatikan input ini di lain waktu.
Kemudian, algoritma harus melakukan perhitungan yang sama untuk lapisan tengah: ubah setiap bobot input ke arah yang akan mengurangi kesalahan jaringan - lagi-lagi, membawa output "7" lebih dekat ke 1, dan sisanya menjadi 0. Tetapi setiap neuron tengah memiliki koneksi dengan semua 10 hari libur, yang memperumit masalah dalam dua aspek.
Pertama, gradien kesalahan untuk setiap neuron rata-rata tidak hanya bergantung pada nilai input, tetapi juga pada gradien kesalahan di lapisan berikutnya. Algoritma ini disebut backpropagation karena gradien kesalahan dari lapisan kemudian dari jaringan merambat dalam arah yang berlawanan dan digunakan untuk menghitung gradien di lapisan sebelumnya.
Juga, setiap neuron tengah merupakan input untuk semua sepuluh hari libur. Oleh karena itu, algoritma pelatihan harus menghitung gradien kesalahan, yang mencerminkan bagaimana perubahan dalam bobot input tertentu mempengaruhi kesalahan rata-rata untuk semua output.
Backpropagation adalah algoritme memanjat bukit: setiap lintasan membawa nilai output lebih dekat ke nilai yang benar untuk gambar yang diberikan, tetapi hanya sedikit. Semakin banyak contoh yang dilihat algoritme, semakin tinggi ia memanjat ke arah set parameter optimal yang secara benar mengklasifikasikan jumlah maksimum contoh pelatihan. Untuk mencapai akurasi tinggi, diperlukan ribuan contoh, dan algoritme mungkin perlu menelusuri setiap gambar dalam rangkaian ini puluhan kali sebelum efektivitasnya berhenti tumbuh.
Nielsen menunjukkan bagaimana mengimplementasikan 74 baris ini dengan python. Anehnya, jaringan yang dilatih dengan program yang begitu sederhana dapat mengenali lebih dari 95% angka tulisan tangan dari basis data MNIST. Dengan peningkatan tambahan, jaringan dua lapis yang sederhana dapat mengenali lebih dari 98% angka.
Terobosan AlexNet
Anda mungkin berpikir bahwa pengembangan tema backpropagation seharusnya terjadi pada 1980-an, dan memunculkan kemajuan pesat dalam MO berdasarkan pada Majelis Nasional - tetapi ini tidak terjadi. Pada 1990-an dan awal 2000-an, beberapa orang bekerja pada teknologi ini, tetapi minat pada Majelis Nasional tidak mendapatkan momentum sampai awal 2010-an.
Ini dapat ditelusuri kembali ke
kompetisi ImageNet , sebuah kompetisi MO tahunan yang diselenggarakan oleh Stanford Fay Fay Lee, seorang spesialis IT. Setiap tahun, saingan diberi set lebih dari satu juta gambar untuk pelatihan, yang masing-masing secara manual dilabeli dalam kategori lebih dari 1000 - dari "truk pemadam kebakaran" dan "jamur" ke "cheetah". Perangkat lunak peserta dinilai berdasarkan kemungkinan mengklasifikasikan gambar lain yang tidak ada dalam set. Suatu program dapat memberikan beberapa tebakan, dan pekerjaannya dianggap berhasil jika setidaknya satu dari lima tebakan pertama cocok dengan nilai yang diberikan oleh seseorang.
Kompetisi dimulai pada 2010, dan NSs dalam tidak memainkan peran besar di dalamnya dalam dua tahun pertama. Tim terbaik menggunakan berbagai teknik MO, dan mencapai hasil yang cukup rata-rata. Pada 2010, tim menang dengan persentase kesalahan sama dengan 28. Pada 2011 - dengan kesalahan 25%.
Dan kemudian datang tahun 2012. Sebuah tim dari University of Toronto mengajukan
tawaran - yang kemudian dijuluki AlexNet untuk menghormati penulis utama, Alex Krizhevsky - dan meninggalkan para pesaing jauh di belakang. Menggunakan NS mendalam, tim mencapai tingkat kesalahan 16%. Untuk pesaing terdekat, angka ini adalah 26.
NS yang dijelaskan dalam artikel untuk pengenalan tulisan tangan memiliki dua lapisan, 25 neuron dan hampir 12.000 parameter. AlexNet jauh lebih besar dan lebih kompleks: delapan lapisan terlatih, 650.000 neuron dan 60 juta parameter.
Diperlukan kekuatan pemrosesan yang sangat besar untuk melatih NS seukuran ini, dan AlexNet dirancang untuk memanfaatkan paralelisasi masif yang tersedia dengan GPU modern. Para peneliti menemukan cara membagi kerja melatih jaringan menjadi dua GPU, yang menggandakan kekuatan. Dan tetap, meskipun optimasi ketat, pelatihan jaringan membutuhkan 5-6 hari pada perangkat keras yang tersedia pada tahun 2012 (pada sepasang Nvidia GTX 580 dengan memori 3 Gb).
Penting untuk mempelajari contoh-contoh hasil AlexNet untuk memahami seberapa serius terobosan ini. Berikut adalah gambar dari makalah ilmiah yang menunjukkan contoh gambar dan lima tebakan pertama jaringan berdasarkan klasifikasi mereka:

AlexNet mampu mengenali tanda centang di gambar pertama, meskipun hanya ada bentuk kecil di sudut itu. Perangkat lunak ini tidak hanya mengidentifikasi macan tutul dengan benar, tetapi juga memberikan opsi penutupan lainnya - jaguar, cheetah, macan tutul salju, Mau Mesir. AlexNet menandai foto hornbeam sebagai "agaric". Hanya "jamur" adalah versi kedua dari jaringan.
"Kesalahan" AlexNet juga mengesankan. Dia menandai foto itu dengan Dalmatian berdiri di belakang sekelompok ceri sebagai "Dalmatian," meskipun label resminya adalah "ceri." AlexNet mengakui bahwa ada semacam berry di foto - di antara lima opsi pertama adalah "anggur" dan "elderberry" - itu tidak mengenali ceri. Dalam foto lemur Madagaskar yang duduk di pohon, AlexNet memberikan daftar mamalia kecil yang hidup di pohon. Saya pikir banyak orang (termasuk saya) akan menaruh tanda tangan yang salah di sini.
Kualitas karya itu mengesankan, dan menunjukkan bahwa perangkat lunak ini mampu mengenali objek biasa dalam berbagai orientasi dan lingkungan mereka. GNS dengan cepat menjadi teknik yang paling populer untuk pengenalan gambar, dan sejak itu dunia MO tidak meninggalkannya.
“Setelah keberhasilan metode berbasis GO 2012, sebagian besar peserta kompetisi 2013 beralih ke jaringan saraf convolutional yang mendalam,” tulis sponsor ImageNet. Pada tahun-tahun berikutnya, tren ini berlanjut, dan kemudian para pemenang bekerja berdasarkan teknologi dasar, pertama kali diterapkan oleh tim AlexNet. Pada 2017, rival, menggunakan NS lebih dalam, secara serius mengurangi tingkat kesalahan menjadi kurang dari tiga. Mengingat kompleksitas tugas, komputer harus belajar untuk menyelesaikannya lebih baik daripada banyak orang.
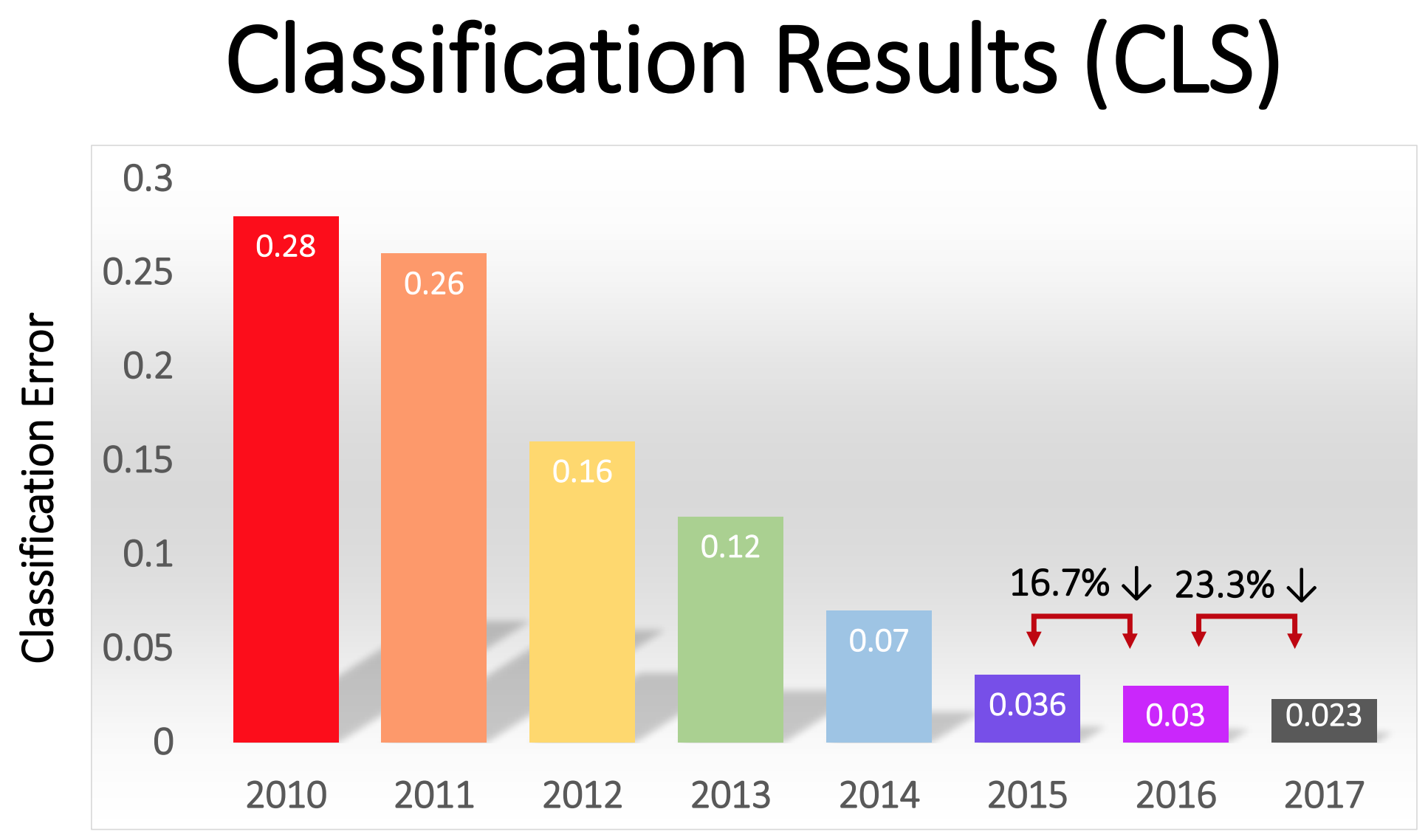 Persentase kesalahan dalam klasifikasi gambar di tahun yang berbeda
Persentase kesalahan dalam klasifikasi gambar di tahun yang berbedaJaringan Konvolusi: Konsep
Secara teknis, AlexNet adalah NS konvolusional. Pada bagian ini, saya akan menjelaskan apa yang dilakukan oleh jaringan saraf convolutional (SNA), dan mengapa teknologi ini menjadi sangat penting untuk algoritma pengenalan pola modern.
Jaringan sederhana yang sebelumnya dibahas untuk pengenalan tulisan tangan sepenuhnya terhubung: setiap neuron dari lapisan pertama adalah input untuk setiap neuron dari lapisan kedua. Struktur seperti itu bekerja sangat baik pada tugas-tugas sederhana dengan pengenalan angka dalam gambar 28x28 piksel. Tapi itu tidak skala dengan baik.
Dalam database digit tulisan tangan MNIST, semua karakter dipusatkan. Ini sangat menyederhanakan pembelajaran, karena, katakanlah, ketujuh akan selalu memiliki beberapa piksel gelap di bagian atas dan kanan, dan sudut kiri bawah selalu putih. Nol hampir selalu memiliki titik putih di piksel tengah dan gelap di tepinya. Jaringan yang sederhana dan terhubung sepenuhnya dapat mengenali pola semacam itu dengan cukup mudah.
Tapi katakanlah Anda ingin membuat NS yang mampu mengenali angka yang dapat ditemukan di mana saja pada gambar yang lebih besar. Jaringan yang sepenuhnya terhubung tidak akan berfungsi dengan baik dengan tugas ini, karena tidak memiliki cara yang efektif untuk mengenali fitur serupa dalam bentuk yang terletak di berbagai bagian gambar. Jika dalam dataset pelatihan Anda sebagian besar tujuh terletak di sudut kiri atas, maka jaringan Anda akan lebih baik dalam mengenali tujuh di sudut kiri atas daripada di bagian lain dari gambar.
Secara teoritis, masalah ini dapat diselesaikan dengan memastikan bahwa set Anda memiliki banyak contoh setiap digit di setiap posisi yang memungkinkan. Namun dalam praktiknya ini akan menjadi pemborosan sumber daya yang besar. Dengan meningkatnya ukuran gambar dan kedalaman jaringan, jumlah tautan - dan jumlah parameter berat - akan meningkat secara eksplosif. Anda akan membutuhkan lebih banyak gambar pelatihan (dan daya komputasi) untuk mencapai akurasi yang memadai.
Ketika jaringan saraf belajar untuk mengenali bentuk yang terletak di satu tempat gambar, itu harus dapat menerapkan pengetahuan ini untuk mengenali bentuk yang sama di bagian lain dari gambar. SNA memberikan solusi yang elegan untuk masalah ini."Ini seperti Anda akan mengambil stensil dan melampirkannya ke semua tempat di gambar," kata peneliti AI Jai Teng. - Anda memiliki stensil dengan gambar seekor anjing, dan pertama-tama Anda memasangnya di sudut kanan atas gambar untuk melihat apakah ada anjing di sana? Jika tidak, Anda menggeser stensil sedikit. Dan untuk seluruh gambar. Tidak masalah di mana gambar anjing itu. Stensil akan cocok dengannya. Anda tidak perlu setiap bagian dari jaringan untuk mempelajari klasifikasi anjingnya sendiri. ”Bayangkan kami mengambil gambar besar dan membaginya menjadi kotak 28x28 piksel. Kemudian kita akan dapat memberi makan setiap kotak dari jaringan yang sepenuhnya terhubung yang mengenali tulisan tangan yang telah kita pelajari sebelumnya. Jika output "7" dipicu di setidaknya satu kotak, ini akan menjadi tanda bahwa ada tujuh di seluruh gambar. Inilah yang dilakukan oleh jaringan konvolusional.Bagaimana jaringan konvolusional bekerja di AlexNet
Dalam jaringan konvolusional, "stensil" semacam itu dikenal sebagai fitur pendeteksi, dan area yang mereka pelajari dikenal sebagai bidang reseptif. Detektor fitur nyata bekerja dengan bidang yang jauh lebih kecil dari persegi dengan sisi 28 piksel. Di AlexNet, fitur detektor pada lapisan konvolusional pertama bekerja dengan bidang reseptif berukuran 11x11 piksel. Pada lapisan berikutnya, bidang reseptif adalah lebar 3-5 unit.Selama traversal, detektor tanda-tanda gambar input menghasilkan peta tanda-tanda: kisi dua dimensi, yang mencatat seberapa kuat detektor diaktifkan di berbagai bagian gambar. Lapisan konvolusional biasanya memiliki lebih dari satu detektor, dan masing-masing dari mereka memindai gambar untuk mencari pola yang berbeda. AlexNet memiliki 96 fitur detektor pada lapisan pertama, memberikan 96 kartu fitur. Untuk lebih memahami hal ini, pertimbangkan representasi visual dari pola yang dipelajari oleh masing-masing dari 96 detektor lapisan pertama AlexNet setelah melatih jaringan. Ada detektor yang mencari garis horizontal atau vertikal, transisi dari terang ke gelap, pola catur dan banyak bentuk lainnya.Gambar berwarna biasanya direpresentasikan sebagai peta piksel dengan tiga angka untuk setiap piksel: nilai merah, hijau, dan biru. Lapisan pertama AlexNet mengambil tampilan ini dan mengubahnya menjadi tampilan menggunakan 96 angka. Setiap "pixel" dalam gambar ini memiliki 96 nilai, satu untuk setiap detektor fitur.Dalam contoh ini, yang pertama dari 96 nilai menunjukkan apakah beberapa titik pada gambar cocok dengan pola ini:
Untuk lebih memahami hal ini, pertimbangkan representasi visual dari pola yang dipelajari oleh masing-masing dari 96 detektor lapisan pertama AlexNet setelah melatih jaringan. Ada detektor yang mencari garis horizontal atau vertikal, transisi dari terang ke gelap, pola catur dan banyak bentuk lainnya.Gambar berwarna biasanya direpresentasikan sebagai peta piksel dengan tiga angka untuk setiap piksel: nilai merah, hijau, dan biru. Lapisan pertama AlexNet mengambil tampilan ini dan mengubahnya menjadi tampilan menggunakan 96 angka. Setiap "pixel" dalam gambar ini memiliki 96 nilai, satu untuk setiap detektor fitur.Dalam contoh ini, yang pertama dari 96 nilai menunjukkan apakah beberapa titik pada gambar cocok dengan pola ini: Nilai kedua menunjukkan apakah beberapa titik gambar bertepatan dengan pola seperti itu:
Nilai kedua menunjukkan apakah beberapa titik gambar bertepatan dengan pola seperti itu: Nilai ketiga menunjukkan apakah beberapa titik gambar bertepatan dengan pola seperti itu:
Nilai ketiga menunjukkan apakah beberapa titik gambar bertepatan dengan pola seperti itu: Dan seterusnya untuk 93 fitur detektor di lapisan AlexNet pertama. Lapisan pertama menghasilkan representasi baru dari gambar, di mana setiap piksel adalah vektor dalam 96 dimensi (saya akan menjelaskan nanti bahwa representasi ini berkurang sebanyak 4 kali).Ini adalah lapisan pertama AlexNet. Lalu ada empat lapisan konvolusional lagi, yang masing-masing mengambil output dari yang sebelumnya sebagai input.Seperti yang kita lihat, lapisan pertama mengungkapkan pola dasar, seperti garis horizontal dan vertikal, transisi dari terang ke gelap dan kurva. Tingkat kedua menggunakannya sebagai blok bangunan untuk mengenali bentuk yang sedikit lebih kompleks. Sebagai contoh, lapisan kedua dapat memiliki fitur detektor yang menemukan lingkaran menggunakan kombinasi output dari fitur detektor dari lapisan pertama yang menemukan kurva. Lapisan ketiga menemukan bentuk yang lebih kompleks dengan menggabungkan fitur dari lapisan kedua. Yang keempat dan kelima menemukan pola yang lebih kompleks.Peneliti Matthew Zeiler dan Rob Fergus menerbitkan karya yang sangat baik pada tahun 2014 , yang menyediakan cara yang sangat berguna untuk memvisualisasikan pola yang dikenali oleh jaringan saraf lima lapis yang mirip dengan ImageNet.
Dan seterusnya untuk 93 fitur detektor di lapisan AlexNet pertama. Lapisan pertama menghasilkan representasi baru dari gambar, di mana setiap piksel adalah vektor dalam 96 dimensi (saya akan menjelaskan nanti bahwa representasi ini berkurang sebanyak 4 kali).Ini adalah lapisan pertama AlexNet. Lalu ada empat lapisan konvolusional lagi, yang masing-masing mengambil output dari yang sebelumnya sebagai input.Seperti yang kita lihat, lapisan pertama mengungkapkan pola dasar, seperti garis horizontal dan vertikal, transisi dari terang ke gelap dan kurva. Tingkat kedua menggunakannya sebagai blok bangunan untuk mengenali bentuk yang sedikit lebih kompleks. Sebagai contoh, lapisan kedua dapat memiliki fitur detektor yang menemukan lingkaran menggunakan kombinasi output dari fitur detektor dari lapisan pertama yang menemukan kurva. Lapisan ketiga menemukan bentuk yang lebih kompleks dengan menggabungkan fitur dari lapisan kedua. Yang keempat dan kelima menemukan pola yang lebih kompleks.Peneliti Matthew Zeiler dan Rob Fergus menerbitkan karya yang sangat baik pada tahun 2014 , yang menyediakan cara yang sangat berguna untuk memvisualisasikan pola yang dikenali oleh jaringan saraf lima lapis yang mirip dengan ImageNet., , , , . , . – . – , . , , , , .
 –
– –
– , ,
, , Lapisan keempat mampu membedakan bentuk yang kompleks, seperti wajah anjing atau kaki burung.
Lapisan keempat mampu membedakan bentuk yang kompleks, seperti wajah anjing atau kaki burung. Lapisan kelima dapat mengenali bentuk yang sangat kompleks.Dengan melihat gambar, Anda dapat melihat bagaimana setiap lapisan berikutnya mampu mengenali pola yang semakin kompleks. Lapisan pertama mengenali pola-pola sederhana yang tidak seperti apa pun. Yang kedua mengenali tekstur dan bentuk sederhana. Pada lapisan ketiga, bentuk-bentuk yang dapat dikenali seperti roda dan bola merah-oranye (tomat, kepik, sesuatu yang lain) menjadi terlihat.Di lapisan pertama, sisi bidang reseptif adalah 11, dan di yang berikutnya, dari tiga menjadi lima. Tapi ingat, nanti lapisan mengenali peta fitur yang dihasilkan oleh lapisan sebelumnya, sehingga masing-masing "piksel" menunjukkan beberapa piksel dari gambar asli. Oleh karena itu, bidang reseptif dari setiap lapisan termasuk bagian yang lebih besar dari gambar pertama dari lapisan sebelumnya. Ini adalah bagian dari alasan bahwa thumbnail di lapisan yang lebih baru terlihat lebih kompleks daripada yang sebelumnya.Kelima, lapisan terakhir dari jaringan mampu mengenali sejumlah besar elemen yang mengesankan. Misalnya, lihat gambar ini yang saya pilih dari sudut kanan atas gambar yang sesuai dengan lapisan kelima:
Lapisan kelima dapat mengenali bentuk yang sangat kompleks.Dengan melihat gambar, Anda dapat melihat bagaimana setiap lapisan berikutnya mampu mengenali pola yang semakin kompleks. Lapisan pertama mengenali pola-pola sederhana yang tidak seperti apa pun. Yang kedua mengenali tekstur dan bentuk sederhana. Pada lapisan ketiga, bentuk-bentuk yang dapat dikenali seperti roda dan bola merah-oranye (tomat, kepik, sesuatu yang lain) menjadi terlihat.Di lapisan pertama, sisi bidang reseptif adalah 11, dan di yang berikutnya, dari tiga menjadi lima. Tapi ingat, nanti lapisan mengenali peta fitur yang dihasilkan oleh lapisan sebelumnya, sehingga masing-masing "piksel" menunjukkan beberapa piksel dari gambar asli. Oleh karena itu, bidang reseptif dari setiap lapisan termasuk bagian yang lebih besar dari gambar pertama dari lapisan sebelumnya. Ini adalah bagian dari alasan bahwa thumbnail di lapisan yang lebih baru terlihat lebih kompleks daripada yang sebelumnya.Kelima, lapisan terakhir dari jaringan mampu mengenali sejumlah besar elemen yang mengesankan. Misalnya, lihat gambar ini yang saya pilih dari sudut kanan atas gambar yang sesuai dengan lapisan kelima: Sembilan gambar di sebelah kanan mungkin tidak sama. Tetapi jika Anda melihat sembilan peta panas di sebelah kiri, Anda akan melihat bahwa fitur detektor ini tidak fokus pada objek di latar depan foto. Sebaliknya, ia berkonsentrasi pada rumput di latar belakang masing-masing!Jelas, detektor rumput berguna jika salah satu kategori yang Anda coba identifikasi adalah "rumput," tetapi itu bisa berguna untuk banyak kategori lainnya. Setelah lima lapisan konvolusional, AlexNet memiliki tiga lapisan yang terhubung sepenuhnya, seperti jaringan kami untuk pengenalan tulisan tangan. Lapisan-lapisan ini memeriksa setiap peta fitur yang dikeluarkan oleh lima lapisan konvolusional, mencoba untuk mengklasifikasikan gambar dalam salah satu dari 1000 kategori yang mungkin.Jadi jika ada rumput di latar belakang, maka dengan probabilitas tinggi akan ada binatang liar di gambar. Di sisi lain, jika ada rumput di latar belakang, kecil kemungkinannya untuk menjadi gambar furnitur di rumah. Detektor fitur lapisan kelima ini dan lainnya memberikan banyak informasi tentang kemungkinan konten foto. Lapisan terakhir dari jaringan mensintesis informasi ini untuk memberikan dugaan yang didukung fakta tentang apa yang umumnya digambarkan dalam gambar.
Sembilan gambar di sebelah kanan mungkin tidak sama. Tetapi jika Anda melihat sembilan peta panas di sebelah kiri, Anda akan melihat bahwa fitur detektor ini tidak fokus pada objek di latar depan foto. Sebaliknya, ia berkonsentrasi pada rumput di latar belakang masing-masing!Jelas, detektor rumput berguna jika salah satu kategori yang Anda coba identifikasi adalah "rumput," tetapi itu bisa berguna untuk banyak kategori lainnya. Setelah lima lapisan konvolusional, AlexNet memiliki tiga lapisan yang terhubung sepenuhnya, seperti jaringan kami untuk pengenalan tulisan tangan. Lapisan-lapisan ini memeriksa setiap peta fitur yang dikeluarkan oleh lima lapisan konvolusional, mencoba untuk mengklasifikasikan gambar dalam salah satu dari 1000 kategori yang mungkin.Jadi jika ada rumput di latar belakang, maka dengan probabilitas tinggi akan ada binatang liar di gambar. Di sisi lain, jika ada rumput di latar belakang, kecil kemungkinannya untuk menjadi gambar furnitur di rumah. Detektor fitur lapisan kelima ini dan lainnya memberikan banyak informasi tentang kemungkinan konten foto. Lapisan terakhir dari jaringan mensintesis informasi ini untuk memberikan dugaan yang didukung fakta tentang apa yang umumnya digambarkan dalam gambar.Apa yang membuat lapisan konvolusional berbeda: bobot input umum
Kami melihat bahwa fitur detektor pada lapisan convolutional menunjukkan pengenalan pola yang mengesankan, tetapi sejauh ini saya belum menjelaskan bagaimana sebenarnya jaringan convolutional bekerja.Lapisan convolutional (SS) terdiri dari neuron. Mereka, seperti neuron lainnya, mengambil rata-rata tertimbang pada input dan menggunakan fungsi aktivasi. Parameter dilatih menggunakan teknik propagasi balik.Tetapi, tidak seperti NS sebelumnya, SS tidak sepenuhnya terhubung. Setiap neuron menerima input dari sebagian kecil neuron dari lapisan sebelumnya. Dan, yang penting, neuron jaringan konvolusional memiliki bobot input yang sama.Mari kita lihat neuron pertama dari AlexNet SS pertama secara lebih rinci. Bidang reseptif dari lapisan ini memiliki ukuran 11x11 piksel, jadi neuron pertama mempelajari kuadrat 11x11 piksel di salah satu sudut gambar. Neuron ini menerima input dari 121 piksel ini, dan setiap piksel memiliki tiga nilai - merah, hijau, dan biru. Oleh karena itu, secara umum, neuron memiliki 363 parameter input. Seperti neuron apa pun, neuron ini mengambil rata-rata tertimbang 363 parameter, dan menerapkan fungsi aktivasi padanya. Dan, karena parameter input adalah 363, parameter bobot juga perlu 363.Neuron kedua pada lapisan pertama mirip dengan yang pertama. Dia juga mempelajari kuadrat dari 11x11 piksel, tetapi bidang reseptifnya digeser oleh empat piksel relatif terhadap yang pertama. Kedua bidang memiliki tumpang tindih 7 piksel, sehingga jaringan tidak kehilangan pola menarik yang jatuh ke persimpangan dua kotak. Neuron kedua juga mengambil 363 parameter yang menggambarkan bujur sangkar 11x11, mengalikan masing-masing dengan berat, menambah dan menerapkan fungsi aktivasi.Tetapi alih-alih menggunakan set bobot 363 yang terpisah, neuron kedua menggunakan bobot yang sama dengan yang pertama. Pixel kiri atas neuron pertama menggunakan bobot yang sama dengan piksel kiri atas yang kedua. Oleh karena itu, kedua neuron mencari pola yang sama; bidang reseptifnya hanya bergeser 4 piksel relatif satu sama lain.Secara alami, ada lebih dari dua neuron: di kisi 55x55 ada 3025 neuron. Masing-masing dari mereka menggunakan set yang sama dari 363 bobot seperti dua yang pertama. Bersama-sama, semua neuron membentuk detektor fitur yang "memindai" gambar untuk pola yang diinginkan, yang dapat ditemukan di mana saja.Ingat bahwa lapisan AlexNet pertama memiliki 96 fitur detektor. 3025 neuron yang baru saja saya sebutkan merupakan salah satu dari 96 detektor ini. Masing-masing dari 95 sisanya adalah kelompok terpisah dari 3.025 neuron. Setiap kelompok 3025 neuron menggunakan satu set umum bobot 363 - namun, untuk masing-masing dari 95 kelompok itu memiliki sendiri.HF dilatih menggunakan backpropagation yang sama yang digunakan untuk jaringan yang terhubung penuh, tetapi struktur convolutional membuat proses pembelajaran lebih efisien dan efektif."Menggunakan konvolusi sangat membantu - parameternya dapat digunakan kembali," kata Sean Gerrish, pakar pertahanan dan otorisasi. Ini secara drastis mengurangi jumlah bobot input yang harus dipelajari jaringan, yang memungkinkannya menghasilkan hasil yang lebih baik dengan contoh pelatihan yang lebih sedikit.Belajar pada satu bagian gambar menghasilkan peningkatan pengenalan pola yang sama di bagian lain gambar. Ini memungkinkan jaringan untuk mencapai kinerja tinggi pada contoh pelatihan yang jauh lebih sedikit.Orang-orang dengan cepat menyadari kekuatan jaringan konvolusional yang dalam.
Pekerjaan AlexNet menjadi sensasi di komunitas akademik Wilayah Moskow, tetapi kepentingannya dengan cepat dipahami dalam industri TI. Google sangat tertarik padanya.
Pada 2013, Google mengakuisisi startup yang didirikan oleh penulis AlexNet. Perusahaan menggunakan teknologi ini untuk menambahkan fitur pencarian foto baru ke Foto Google. "Kami mengambil penelitian lanjutan dan mulai beroperasi sedikit lebih dari enam bulan kemudian," tulis Chuck Rosenberg dari Google.
Sementara itu, pada 2013, dijelaskan bagaimana Google menggunakan GSS untuk mengenali alamat dari foto Google Street View. "Sistem kami membantu kami mengekstrak hampir 100 juta alamat fisik dari gambar-gambar ini," tulis para penulis.
Para peneliti menemukan bahwa efektivitas NS tumbuh dengan meningkatnya kedalaman. "Kami menemukan bahwa efektivitas pendekatan ini meningkat seiring dengan kedalaman SNA, dan arsitektur terdalam yang kami latih menunjukkan hasil terbaik," tulis tim Google Street View. "Eksperimen kami menunjukkan bahwa arsitektur yang lebih dalam dapat menghasilkan akurasi yang lebih besar, tetapi dengan penurunan efisiensi."
Jadi setelah AlexNet, jaringan mulai semakin dalam. Tim Google mengajukan penawaran di kompetisi pada 2014 - hanya dua tahun setelah AlexNet menang pada 2012. Itu juga didasarkan pada SNA yang mendalam, tetapi Goolge menggunakan jaringan 22 lapisan yang lebih dalam untuk mencapai tingkat kesalahan 6,7% - ini adalah peningkatan besar dibandingkan dengan 16% AlexNet.
Tetapi pada saat yang sama, jaringan yang lebih dalam hanya berfungsi lebih baik dengan set data pelatihan yang lebih besar. Oleh karena itu, Gerrish mengatakan bahwa dataset dan kompetisi ImageNet memainkan peran utama dalam keberhasilan SNA. Ingatlah bahwa pada kompetisi ImageNet, peserta diberikan satu juta gambar dan diminta untuk mengurutkannya menjadi 1.000 kategori.
"Jika Anda memiliki sejuta gambar untuk pelatihan, maka setiap kelas menyertakan 1.000 gambar," kata Gerrish. Tanpa dataset yang begitu besar, katanya, "Anda akan memiliki terlalu banyak opsi untuk melatih jaringan."
Dalam beberapa tahun terakhir, para ahli semakin berkonsentrasi pada pengumpulan sejumlah besar data untuk melatih jaringan yang lebih dalam dan lebih akurat. Itulah sebabnya perusahaan yang mengembangkan mobil robot berkonsentrasi untuk berjalan di jalan umum - gambar dan video dari perjalanan ini dikirim ke kantor pusat dan digunakan untuk melatih NS perusahaan.
Komputasi Boom Pembelajaran yang Mendalam
Penemuan fakta bahwa jaringan yang lebih dalam dan kumpulan data yang lebih besar dapat meningkatkan kinerja NS telah menciptakan kehausan yang tak pernah terpuaskan untuk kekuatan komputasi yang semakin besar. Salah satu komponen utama keberhasilan AlexNet adalah gagasan bahwa pelatihan matriks digunakan dalam pelatihan NS, yang dapat dilakukan secara efisien pada GPU yang dapat diparalelkan dengan baik.
"NSs diparalelkan dengan baik," kata Jai Ten, seorang peneliti MO. Kartu grafis - memberikan kekuatan pemrosesan paralel yang luar biasa untuk permainan video - telah terbukti bermanfaat bagi NS.
"Bagian utama dari pekerjaan GPU, perkalian matriks yang sangat cepat, ternyata menjadi bagian utama dari pekerjaan Majelis Nasional," kata Ten.
Semua ini telah berhasil bagi produsen GPU, Nvidia dan AMD terkemuka. Kedua perusahaan telah mengembangkan chip baru yang khusus dirancang untuk kebutuhan aplikasi MO, dan sekarang aplikasi AI bertanggung jawab atas sebagian besar penjualan GPU perusahaan-perusahaan ini.
Pada 2016, Google mengumumkan pembuatan chip khusus, Tensor Processing Unit (TPU), yang dirancang untuk beroperasi di Majelis Nasional. "Meskipun Google sedang mempertimbangkan kemungkinan membuat sirkuit terpadu tujuan khusus (ASICs) pada tahun 2006, situasi ini menjadi mendesak pada 2013," tulis seorang perwakilan perusahaan tahun lalu. "Pada saat itulah kami menyadari bahwa persyaratan Majelis Nasional untuk daya komputasi yang tumbuh cepat mungkin mengharuskan kami menggandakan jumlah pusat data yang kami miliki."
Pada awalnya, hanya layanan Google sendiri yang memiliki akses ke TPU, tetapi kemudian perusahaan mengizinkan semua orang untuk menggunakan teknologi ini melalui platform cloud computing.
Tentu saja, Google bukan satu-satunya perusahaan yang bekerja pada chip AI. Hanya beberapa contoh: dalam versi terbaru dari chip iPhone
ada "neural core" dioptimalkan untuk operasi dengan NS. Intel
mengembangkan lini chipnya sendiri yang dioptimalkan untuk GO. Tesla baru-baru ini
mengumumkan penolakan chip dari Nvidia yang mendukung chip NS-nya sendiri. Amazon juga dikabarkan sedang
mengerjakan chip AI-nya.
Mengapa jaringan saraf yang dalam sulit dipahami
Saya menjelaskan bagaimana jaringan saraf bekerja, tetapi saya tidak menjelaskan mengapa mereka bekerja dengan baik. Tidak jelas bagaimana tepatnya jumlah besar perhitungan matriks memungkinkan sistem komputer untuk membedakan jaguar dari cheetah, dan elderberry dari kismis.
Mungkin kualitas Majelis Nasional yang paling luar biasa adalah mereka tidak. Konvolusi memungkinkan NS untuk memahami tanda hubung - mereka dapat mengetahui apakah gambar dari sudut kanan atas gambar mirip dengan gambar di sudut kiri atas gambar lain.
Tetapi pada saat yang sama, SNA tidak memiliki gagasan tentang geometri. Mereka tidak dapat mengenali kesamaan dari dua gambar jika diputar 45 derajat atau dua kali lipat. SNA tidak mencoba memahami struktur objek tiga dimensi, dan tidak dapat memperhitungkan kondisi pencahayaan yang berbeda.
Tetapi pada saat yang sama, NS dapat mengenali foto-foto anjing yang diambil baik dari depan maupun dari samping, dan tidak masalah apakah anjing tersebut menempati sebagian kecil dari gambar, atau yang besar. Bagaimana mereka melakukannya? Ternyata jika ada cukup data, pendekatan statistik dengan penghitungan langsung dapat mengatasi tugas tersebut. SNA tidak dirancang sehingga dapat "membayangkan" bagaimana gambar tertentu akan terlihat dari sudut yang berbeda atau dalam kondisi yang berbeda, tetapi dengan jumlah contoh berlabel yang cukup, ia dapat mempelajari semua variasi gambar yang mungkin dengan pengulangan sederhana.
Ada bukti bahwa sistem visual orang bekerja dengan cara yang sama. Lihatlah beberapa gambar - pertama pelajari dengan seksama yang pertama, lalu buka yang kedua.
 Foto pertama
Foto pertamaPencipta gambar mengambil foto seseorang dan membalikkan mata dan mulutnya. Gambar tampak relatif normal ketika Anda melihatnya terbalik, karena sistem visual manusia digunakan untuk melihat mata dan mulut pada posisi ini. Tetapi jika Anda melihat gambar dalam orientasi yang benar, Anda dapat segera melihat bahwa wajah anehnya terdistorsi.
Ini menunjukkan bahwa sistem visual manusia didasarkan pada teknik pengenalan pola kasar yang sama dengan NS. Jika kita melihat sesuatu yang hampir selalu terlihat dalam satu orientasi - mata manusia - kita dapat mengenalinya dengan lebih baik dalam orientasi normalnya.
NS dengan baik mengenali gambar menggunakan semua konteks yang tersedia pada mereka. Misalnya, mobil biasanya melaju di jalan. Gaun biasanya dikenakan di tubuh wanita atau digantung di lemari. Pesawat biasanya ditembakkan ke langit atau mereka berkuasa di landasan. Tidak ada yang secara spesifik mengajarkan kepada NS korelasi-korelasi ini, tetapi dengan jumlah contoh berlabel yang memadai, jaringan itu sendiri dapat mempelajarinya.
Pada 2015, peneliti dari Google mencoba untuk lebih memahami NS, "menjalankannya mundur." Alih-alih menggunakan gambar untuk pelatihan NS, mereka menggunakan NS terlatih untuk mengubah gambar. Sebagai contoh, mereka mulai dengan gambar yang mengandung noise acak, dan kemudian secara bertahap mengubahnya sehingga sangat mengaktifkan salah satu neuron output NS - pada kenyataannya, mereka meminta NS untuk "menggambar" salah satu kategori yang diajarkan untuk dikenali. Dalam satu kasus yang menarik, mereka memaksa NS untuk menghasilkan gambar yang mengaktifkan NS, dilatih untuk mengenali halter.

"Tentu saja, ada dumbbell di sini, tetapi tidak satu pun gambar dumbbell tampak lengkap tanpa kehadiran gulungan otot berotot yang mengangkatnya," catat para peneliti Google.
Sepintas memang terlihat aneh, tetapi kenyataannya tidak jauh berbeda dengan apa yang dilakukan orang. Jika kita melihat objek kecil atau buram dalam gambar, kita mencari petunjuk di sekitarnya untuk memahami apa yang bisa terjadi di sana. Orang, tentu saja, berbicara tentang gambar secara berbeda, menggunakan pemahaman konseptual yang kompleks tentang dunia di sekitar mereka. Tetapi pada akhirnya, STS mengenali gambar dengan baik, karena mereka mengambil keuntungan penuh dari seluruh konteks yang digambarkan pada mereka, dan ini tidak jauh berbeda dari bagaimana orang melakukannya.