
Pada 14 Mei, ketika Trump bersiap untuk meluncurkan semua anjing di Huawei, saya duduk dengan tenang di Shenzhen pada Huawei STW 2019 - sebuah konferensi besar untuk 1000 peserta - yang termasuk laporan oleh
Philip Wong , wakil presiden penelitian TSMC tentang prospek komputasi non-von Neumann arsitektur, dan Heng Liao, Huawei Fellow, Kepala Ilmuwan Huawei 2012 Lab, pada pengembangan arsitektur baru prosesor tensor dan neuroprosesor. TSMC, jika Anda tahu, membuat akselerator saraf untuk Apple dan Huawei menggunakan teknologi 7 nm (yang
dimiliki beberapa orang ), dan Huawei siap bersaing dengan Google dan NVIDIA dalam hal neuroprosesor.
Google di China dilarang, saya tidak repot-repot menaruh VPN di tablet, jadi saya
patriot menggunakan Yandex untuk melihat bagaimana situasinya dengan produsen besi yang serupa, dan apa yang umumnya terjadi. Secara umum, saya mengamati situasi, tetapi hanya setelah laporan-laporan ini saya menyadari betapa besar skala revolusi sedang dipersiapkan di perut perusahaan dan keheningan ruang ilmiah.
Tahun lalu saja, lebih dari $ 3 miliar diinvestasikan dalam topik ini. Google telah lama menyatakan jaringan saraf sebagai area strategis, secara aktif membangun dukungan perangkat keras dan perangkat lunak mereka. NVIDIA, merasakan bahwa takhta itu mengejutkan, membuat upaya luar biasa dalam perpustakaan akselerasi jaringan saraf dan perangkat keras baru. Intel pada 2016 menghabiskan 0,8 miliar untuk membeli dua perusahaan yang terlibat dalam akselerasi perangkat keras jaringan saraf. Dan ini terlepas dari kenyataan bahwa pembelian utama belum dimulai, dan jumlah pemain telah melebihi lima puluh dan berkembang pesat.
TPU, VPU, IPU, DPU, NPU, RPU, NNP - apa artinya semua ini dan siapa yang akan menang? Mari kita coba mencari tahu. Siapa yang peduli - Selamat datang ke kucing!
Penafian: Penulis harus sepenuhnya menulis ulang algoritma pemrosesan video untuk implementasi yang efektif pada ASIC, dan klien melakukan prototyping pada FPGA, sehingga ada gagasan tentang perbedaan kedalaman arsitektur. Namun, penulis belum bekerja secara langsung dengan besi baru-baru ini. Tetapi dia mengantisipasi bahwa dia harus menyelidiki hal itu.
Latar belakang masalah
Jumlah perhitungan yang dibutuhkan tumbuh dengan cepat, orang akan senang untuk mengambil lebih banyak lapisan, lebih banyak opsi arsitektur, bermain lebih aktif dengan hyperparameter, tapi ... itu tergantung pada kinerja. Pada saat yang sama, misalnya, dengan pertumbuhan produktivitas prosesor lama yang baik - masalah besar. Semua hal baik berakhir: Hukum Moore, seperti yang Anda tahu, hampir habis dan tingkat pertumbuhan kinerja prosesor turun:
Perhitungan kinerja nyata operasi integer pada SPECint dibandingkan dengan VAX11-780 , selanjutnya sering skala logaritmikJika dari pertengahan 80-an hingga pertengahan 2000-an - di tahun-tahun penuh berkah dari masa kejayaan komputer - pertumbuhan berada pada tingkat rata-rata 52% per tahun, dalam beberapa tahun terakhir ini telah menurun hingga 3% per tahun. Dan ini adalah masalah (terjemahan dari artikel terbaru oleh Patriark John Hennessey tentang masalah dan prospek arsitektur modern
ada di Habré ).
Ada banyak alasan, misalnya, frekuensi prosesor berhenti tumbuh:
Menjadi lebih sulit untuk mengurangi ukuran transistor. Kemalangan terakhir yang secara drastis mengurangi produktivitas (termasuk kinerja CPU yang sudah dirilis) adalah (drum roll) ... benar, aman.
Meltdown ,
Spectre dan
kerentanan lainnya menyebabkan kerusakan yang sangat besar pada tingkat pertumbuhan daya pemrosesan CPU (
contoh menonaktifkan hyperthreading (!)). Topik ini menjadi populer, dan kerentanan baru semacam ini ditemukan
hampir setiap bulan . Dan ini semacam mimpi buruk, karena menyakitkan dalam hal kinerja.
Pada saat yang sama, pengembangan banyak algoritma terkait erat dengan pertumbuhan kekuatan prosesor yang sudah dikenal. Misalnya, banyak peneliti saat ini tidak khawatir tentang kecepatan algoritma - mereka akan menemukan sesuatu. Dan alangkah baiknya ketika belajar - jaringan menjadi besar dan "sulit" digunakan. Ini khususnya jelas dalam video, yang sebagian besar pendekatannya, pada prinsipnya, tidak berlaku pada kecepatan tinggi. Dan mereka sering masuk akal hanya dalam waktu nyata. Ini juga masalah.
Demikian juga, standar kompresi baru sedang dikembangkan yang menyiratkan peningkatan daya decoder. Dan jika kekuatan prosesor tidak tumbuh? Generasi yang lebih tua ingat bagaimana pada tahun 2000-an ada masalah memutar video definisi tinggi di
H.264 yang baru pada komputer lama. Ya, kualitasnya lebih baik dengan ukuran yang lebih kecil, tetapi pada adegan cepat gambar digantung atau suara robek. Saya harus berkomunikasi dengan pengembang
VVC / H.266 baru (rilis direncanakan untuk tahun depan). Anda tidak akan iri pada mereka.
Jadi, apa yang disiapkan abad mendatang bagi kita mengingat penurunan tingkat pertumbuhan kinerja prosesor sebagaimana diterapkan pada jaringan saraf?
CPU
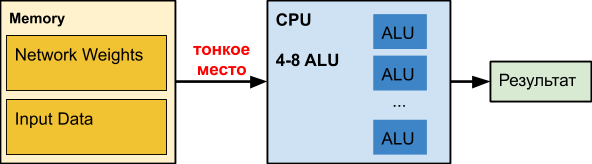 CPU
CPU biasa adalah penghancur angka besar yang telah disempurnakan selama beberapa dekade. Sial, untuk tugas lain.
Ketika kita bekerja dengan jaringan saraf, terutama jaringan yang dalam, jaringan kita sendiri dapat menempati ratusan megabita. Misalnya, persyaratan memori jaringan
deteksi objek adalah sebagai berikut:
Dalam pengalaman kami, koefisien dari jaringan saraf yang dalam untuk memproses
batas tembus cahaya dapat menempati 150-200 MB. Kolega di jaringan saraf menentukan usia dan jenis kelamin dari ukuran koefisien urutan 50 MB. Dan selama optimasi untuk versi seluler akurasi berkurang - sekitar 25 MB (float32⇒float16).
Pada saat yang sama, grafik tunda saat mengakses memori tergantung pada ukuran data yang didistribusikan
kira-kira seperti ini (skala horizontal adalah logaritmik):
Yaitu dengan peningkatan volume data lebih dari 16 MB, penundaan meningkat hingga 50 kali atau lebih, yang secara fatal mempengaruhi kinerja. Bahkan, sebagian besar waktu CPU, ketika bekerja dengan jaringan saraf yang dalam,
bodoh menunggu data.
Data Intel tentang akselerasi berbagai jaringan menarik, di mana, pada kenyataannya, akselerasi hanya terjadi ketika jaringan menjadi kecil (misalnya, sebagai hasil kuantisasi bobot), untuk memulai setidaknya sebagian memasukkan cache bersama dengan data yang diproses. Perhatikan bahwa cache dari CPU modern menghabiskan hingga setengah energi prosesor. Dalam kasus jaringan saraf yang berat, itu tidak efektif dan bekerja dengan pemanas yang tidak masuk akal.
Untuk penganut jaringan saraf pada CPUMenurut pengujian internal kami, bahkan
Intel OpenVINO kehilangan implementasi kerangka multiplikasi + NNPACK pada banyak arsitektur jaringan (terutama pada arsitektur sederhana di mana bandwidth penting untuk pemrosesan data waktu nyata dalam mode single-threaded). Skenario seperti itu relevan untuk berbagai pengklasifikasi objek dalam gambar (di mana jaringan saraf perlu dijalankan sejumlah besar kali - 50-100 dalam hal jumlah objek dalam gambar) dan overhead untuk memulai OpenVINO menjadi terlalu tinggi.
Pro:- “Semua orang memilikinya,” dan biasanya menganggur, mis. harga masuk yang relatif rendah untuk penagihan dan implementasi.
- Ada jaringan non-CV terpisah yang cocok dengan CPU, panggilan rekan, misalnya, Wide & Deep dan GNMT.
Minus:- CPU tidak efisien ketika bekerja dengan jaringan saraf yang dalam (ketika jumlah lapisan jaringan dan ukuran data input besar), semuanya bekerja sangat lambat.
GPU

Topiknya sudah terkenal, jadi kami menguraikan secara singkat hal utama. Dalam kasus jaringan saraf,
GPU memiliki keunggulan kinerja yang signifikan dalam tugas paralel besar-besaran:
Perhatikan bagaimana 72-core
Xeon Phi 7290 dianil, sementara "biru" juga merupakan server Xeon, mis. Intel tidak menyerah begitu saja, yang akan dibahas di bawah ini. Tetapi yang lebih penting, memori kartu video pada awalnya dirancang untuk kinerja sekitar 5 kali lebih tinggi. Dalam jaringan saraf, komputasi dengan data sangat sederhana. Beberapa tindakan elementer, dan kami membutuhkan data baru. Akibatnya, kecepatan akses data sangat penting untuk operasi jaringan saraf yang efisien. Memori berkecepatan tinggi "on board" GPU dan sistem manajemen cache yang lebih fleksibel daripada pada CPU dapat memecahkan masalah ini:
Tim Detmers telah mendukung ulasan menarik
“GPU mana yang perlu untuk Deep Learning: Pengalaman dan Saran Saya untuk Menggunakan GPU dalam Deep Learning” selama beberapa tahun sekarang. Jelas bahwa Tesla dan Titans berkuasa untuk pelatihan, meskipun perbedaan dalam arsitektur dapat menyebabkan ledakan yang menarik, misalnya, dalam kasus jaringan saraf berulang (dan pemimpin secara umum adalah TPU, perhatikan untuk masa depan):
Namun, ada grafik kinerja yang sangat berguna untuk dolar, di mana pada kuda
RTX (kemungkinan besar karena
core Tensor mereka ), jika Anda memiliki cukup memori untuk itu, tentu saja:
Tentu saja, biaya komputasi itu penting. Tempat kedua dari peringkat pertama dan terakhir dari yang kedua -
Tesla V100 dijual seharga 700 ribu rubel, seperti 10 komputer "biasa" (+ sakelar Infiniband yang mahal, jika Anda ingin berlatih di beberapa node). Benar V100 dan bekerja selama sepuluh. Orang-orang rela membayar lebih untuk akselerasi pembelajaran yang nyata.
Total, rangkum!
Pro:- Kardinal - 10-100 kali - akselerasi dibandingkan dengan CPU.
- Sangat efektif untuk pelatihan (dan agak kurang efektif untuk digunakan).
Minus:- Biaya kartu video top-end (yang memiliki cukup memori untuk melatih jaringan besar) melebihi biaya komputer lainnya ...
FPGA
 FPGA
FPGA sudah lebih menarik. Ini adalah jaringan beberapa juta blok yang dapat diprogram, yang juga dapat kita interkoneksi secara terprogram. Jaringan dan blok
terlihat seperti ini (bottleneck adalah bottleneck, perhatikan, lagi di depan memori chip, tetapi lebih mudah, yang akan dijelaskan di bawah):
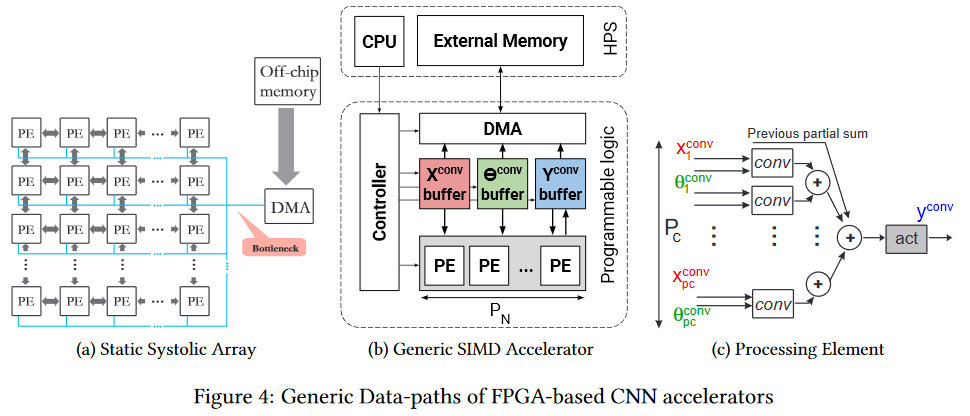
Tentu, masuk akal untuk menggunakan FPGA sudah pada tahap menggunakan jaringan saraf (dalam banyak kasus, tidak ada cukup memori untuk pelatihan). Selain itu, topik eksekusi pada FPGA kini telah mulai berkembang secara aktif. Sebagai contoh, di sini adalah
kerangka kerja fpgaConvNet , yang secara signifikan dapat mempercepat penggunaan CNN pada FPGA dan mengurangi konsumsi daya.
Kunci plus dari FPGA adalah bahwa kita dapat menyimpan jaringan secara langsung di dalam sel, mis. titik tipis dalam bentuk ratusan megabyte dari data yang sama ditransfer 25 kali per detik (untuk video) dalam arah yang sama secara ajaib menghilang. Ini memungkinkan kecepatan clock yang lebih rendah dan tidak adanya cache alih-alih kinerja yang lebih rendah untuk mendapatkan peningkatan yang nyata. Ya, dan secara dramatis mengurangi konsumsi energi
pemanasan global per unit perhitungan.
Intel secara aktif bergabung dengan proses tersebut, merilis
OpenVINO Toolkit dalam open source tahun lalu, yang mencakup
Deep Learning Deployment Toolkit (bagian dari
OpenCV ). Selain itu, kinerja pada FPGA pada grid yang berbeda terlihat cukup menarik, dan keuntungan FPGA dibandingkan dengan GPU (meskipun Intel GPU terintegrasi) cukup signifikan:
Yang terutama menghangatkan jiwa penulis - FPS dibandingkan, mis. bingkai per detik adalah metrik paling praktis untuk video. Mengingat Intel membeli
Altera , pemain terbesar kedua di pasar FPGA, pada 2015, bagan tersebut memberikan makanan yang baik untuk dipikirkan.
Dan, jelas, penghalang masuk ke arsitektur seperti itu lebih tinggi, sehingga beberapa waktu harus berlalu sebelum alat yang mudah muncul yang secara efektif memperhitungkan arsitektur FPGA yang berbeda secara fundamental. Namun meremehkan potensi teknologi tidak sepadan. Itu menyakitkan banyak tempat tipis dia menyulam.
Akhirnya, kami menekankan bahwa
pemrograman FPGA adalah seni tersendiri. Dengan demikian, program tidak dijalankan di sana, dan semua perhitungan dilakukan dalam hal aliran data, penundaan aliran (yang memengaruhi kinerja) dan gerbang yang digunakan (yang selalu kurang). Oleh karena itu, untuk memulai pemrograman secara efektif, Anda perlu
mengubah firmware Anda sendiri secara menyeluruh (di jaringan saraf yang ada di antara telinga Anda). Dengan efisiensi yang baik, ini tidak diperoleh sama sekali. Namun, kerangka kerja baru akan segera menyembunyikan perbedaan eksternal dari para peneliti.
Pro:- Eksekusi jaringan yang berpotensi lebih cepat.
- Konsumsi daya yang secara signifikan lebih rendah dibandingkan dengan CPU dan GPU (ini sangat penting untuk solusi seluler).
Cons:- Kebanyakan mereka membantu mempercepat eksekusi, pelatihan pada mereka, tidak seperti GPU, terasa kurang nyaman.
- Pemrograman lebih kompleks dibandingkan dengan opsi sebelumnya.
- Spesialis jauh lebih sedikit.
ASIC

Berikutnya adalah
ASIC , yang merupakan kependekan dari Sirkuit Terpadu Khusus Aplikasi, yaitu sirkuit terpadu untuk tugas kami. Misalnya, mewujudkan jaringan saraf yang diletakkan di atas besi. Namun, sebagian besar node komputasi dapat bekerja secara paralel. Faktanya, hanya dependensi data dan komputasi yang tidak merata di berbagai level jaringan yang dapat mencegah kita untuk terus-menerus menggunakan semua ALU yang berfungsi.
Mungkin penambangan cryptocurrency telah membuat iklan ASIC terbesar di antara masyarakat umum dalam beberapa tahun terakhir. Pada awalnya, penambangan pada CPU cukup menguntungkan, kemudian saya harus membeli GPU, kemudian FPGA, dan kemudian mengkhususkan ASIC, karena orang-orang (baca-pasar) jatuh tempo untuk pesanan di mana produksi mereka menjadi menguntungkan.
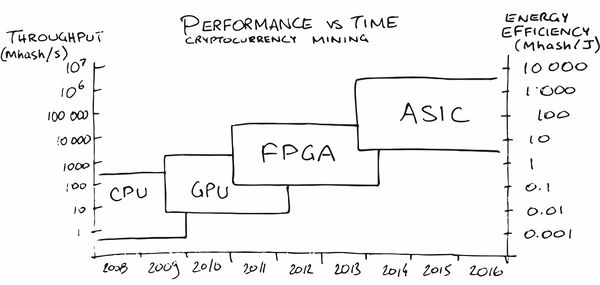
Di daerah kami,
layanan juga telah muncul (secara alami!)
Itu membantu menempatkan jaringan saraf pada besi dengan karakteristik yang diperlukan untuk konsumsi energi, FPS, dan harga. Ajaib, setuju!
TAPI! Kami kehilangan kustomisasi jaringan. Dan, tentu saja, orang juga memikirkannya. Sebagai contoh, berikut adalah artikel dengan pepatah, “
Dapatkah arsitektur yang dapat dikonfigurasi ulang mengalahkan ASIC sebagai akselerator CNN? ” (“Dapatkah arsitektur yang dapat dikonfigurasi mengalahkan ASIC seperti akselerator CNN?”). Ada cukup banyak pekerjaan pada topik ini, karena pertanyaannya tidak menganggur. Kerugian utama ASIC adalah bahwa setelah kami menggerakkan jaringan ke perangkat keras, menjadi sulit bagi kami untuk mengubahnya. Mereka paling menguntungkan untuk kasus ketika kita sudah membutuhkan jaringan yang berfungsi baik dengan jutaan chip dengan konsumsi daya yang rendah dan kinerja tinggi. Dan situasi ini secara bertahap berkembang di pasar mobil autopilot, misalnya. Atau di kamera pengintai. Atau di ruang penyedot debu robot. Atau di kamar-kamar kulkas rumah. Atau di ruang pembuat kopi.
Atau di ruang besi. Singkatnya , Anda mengerti idenya!
Adalah penting bahwa dalam produksi massal chip itu murah, ia bekerja dengan cepat dan mengkonsumsi energi minimum.
Pro:- Biaya chip terendah dibandingkan dengan semua solusi sebelumnya.
- Konsumsi daya terendah per unit operasi.
- Kecepatan sangat tinggi (termasuk, jika diinginkan, catatan).
Cons:- Kemampuan yang sangat terbatas untuk memperbarui jaringan dan logika.
- Biaya pengembangan tertinggi dibandingkan dengan semua solusi sebelumnya.
- Menggunakan ASIC hemat biaya terutama untuk operasi besar.
TPU
Ingatlah bahwa ketika bekerja dengan jaringan, ada dua tugas - pelatihan dan eksekusi (inferensi). Jika FPGA / ASICs terutama difokuskan pada mempercepat eksekusi (termasuk beberapa jaringan tetap), maka TPU (Tensor Processing Unit atau prosesor tensor) adalah akselerasi pembelajaran berbasis perangkat keras atau akselerasi yang relatif universal dari jaringan arbitrer. Namanya cantik, setuju, meskipun pada kenyataannya, peringkat 2
tensor dengan Mixed Multiply Unit (MXU) yang terhubung ke High-Bandwidth Memory (HBM) masih digunakan. Di bawah ini adalah diagram arsitektur dari TPU Google versi 2 dan 3:
TPU Google
Secara umum, Google membuat iklan untuk nama TPU, mengungkapkan perkembangan internal pada tahun 2017:
Mereka memulai pekerjaan pendahuluan pada prosesor khusus untuk jaringan saraf dengan kata-kata mereka kembali pada tahun 2006, pada tahun 2013 mereka menciptakan sebuah proyek dengan pendanaan yang baik, dan pada tahun 2015 mereka mulai bekerja dengan chip pertama yang banyak membantu dengan jaringan saraf untuk layanan cloud Google Translate dan banyak lagi. Dan kami menekankan, ini adalah percepatan jaringan. Keuntungan penting bagi pusat data adalah dua urutan besarnya efisiensi energi TPU dibandingkan dengan CPU (grafik untuk TPU v1):
Juga, sebagai aturan, dibandingkan dengan GPU,
kinerja jaringan adalah 10-30 kali lebih baik menjadi lebih baik:
Perbedaannya bahkan 10 kali signifikan. Jelas bahwa perbedaan dengan GPU dalam 20-30 kali menentukan perkembangan arah ini.
Dan, untungnya, Google tidak sendirian.
TPU Huawei
Hari ini, Huawei yang lama menderita juga mulai mengembangkan TPU beberapa tahun yang lalu dengan nama Huawei Ascend, dan dalam dua versi sekaligus - untuk pusat data (seperti Google) dan untuk perangkat seluler (yang juga mulai dilakukan Google baru-baru ini). Jika Anda yakin bahan-bahan Huawei, mereka mengambil alih Google TPU v3 baru dengan FP16 2,5 kali dan NVIDIA V100 2 kali:

Seperti biasa, pertanyaan yang bagus: bagaimana chip ini akan berperilaku pada tugas nyata. Karena pada grafik, seperti yang Anda lihat, kinerja puncak. Selain itu, Google TPU v3 baik dalam banyak hal karena dapat bekerja secara efektif dalam kelompok 1024 prosesor. Huawei juga mengumumkan cluster server untuk Ascend 910, tetapi tidak ada rincian. Secara umum, insinyur Huawei telah menunjukkan diri mereka sangat kompeten selama 10 tahun terakhir, dan ada kemungkinan bahwa kinerja puncak 2,8 kali lebih besar dibandingkan dengan Google TPU v3, ditambah dengan teknologi proses 7 nm terbaru, akan digunakan dalam kasus ini.
Memory dan data bus sangat penting untuk kinerja, dan slide menunjukkan bahwa perhatian yang cukup besar diberikan kepada komponen-komponen ini (termasuk kecepatan berkomunikasi dengan memori jauh lebih cepat daripada GPU):
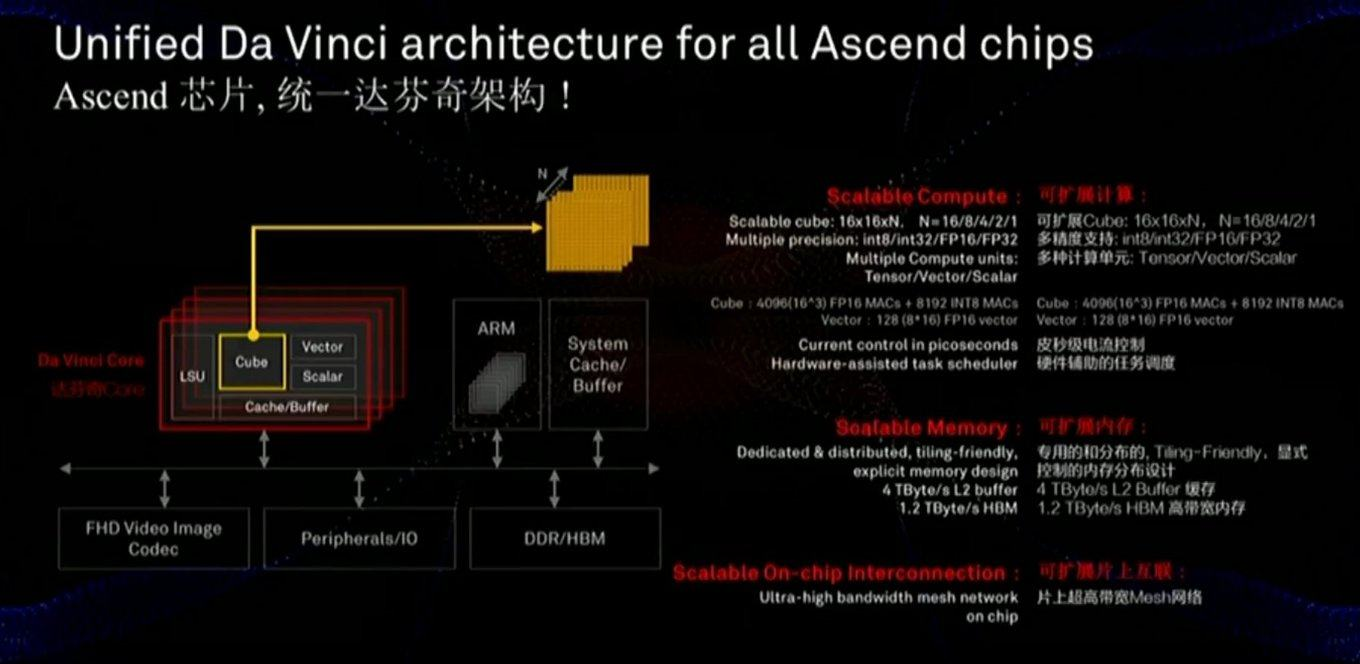
Chip ini juga menggunakan pendekatan yang sedikit berbeda - bukan skala MXU 128x128 dua dimensi, tetapi perhitungan dalam kubus tiga dimensi dengan ukuran lebih kecil 16x16xN, di mana N = {16,8,4,2,1}. Oleh karena itu, pertanyaan kuncinya adalah seberapa baik itu akan terletak pada akselerasi nyata dari jaringan tertentu (misalnya, perhitungan dalam kubus nyaman untuk gambar). Juga, penelitian yang cermat terhadap slide menunjukkan bahwa, tidak seperti Google, chip tersebut segera menggabungkan kerja dengan video FullHD terkompresi. Bagi penulis, ini terdengar
sangat menggembirakan!
Seperti disebutkan di atas, pada baris yang sama, prosesor dikembangkan untuk perangkat seluler yang efisiensi energinya sangat penting, dan di mana jaringan akan dijalankan (mis., Secara terpisah - prosesor untuk pembelajaran cloud dan secara terpisah - untuk eksekusi): Dan dengan parameter ini, semuanya Ini terlihat baik dibandingkan dengan NVIDIA setidaknya (perhatikan bahwa mereka tidak membawa perbandingan dengan Google, namun, Google tidak memberikan cloud TPU ke tangan). Dan chip ponsel mereka akan bersaing dengan prosesor dari Apple, Google dan perusahaan lain, tetapi masih terlalu dini untuk mengambil stok di sini.Jelas terlihat bahwa chip Nano, Tiny dan Lite yang baru seharusnya lebih baik. Menjadi jelas
Dan dengan parameter ini, semuanya Ini terlihat baik dibandingkan dengan NVIDIA setidaknya (perhatikan bahwa mereka tidak membawa perbandingan dengan Google, namun, Google tidak memberikan cloud TPU ke tangan). Dan chip ponsel mereka akan bersaing dengan prosesor dari Apple, Google dan perusahaan lain, tetapi masih terlalu dini untuk mengambil stok di sini.Jelas terlihat bahwa chip Nano, Tiny dan Lite yang baru seharusnya lebih baik. Menjadi jelas mengapa Trump takut mengapa banyak pabrikan dengan cermat memeriksa keberhasilan Huawei (yang mengungguli semua perusahaan besi AS dalam hal pendapatan, termasuk Intel pada 2018).Jaringan dalam analog
Seperti yang Anda ketahui, teknologi sering berkembang secara spiral, ketika pendekatan lama dan terlupakan menjadi relevan di babak baru.Sesuatu yang mirip bisa terjadi pada jaringan saraf. Anda mungkin pernah mendengar bahwa sekali operasi penggandaan dan penambahan dilakukan oleh tabung elektron dan transistor (misalnya, konversi ruang warna - perkalian khas dari matriks - ada di setiap TV berwarna hingga pertengahan 90-an)? Sebuah pertanyaan bagus muncul: jika jaringan saraf kita relatif tahan terhadap perhitungan yang tidak akurat di dalam, bagaimana jika kita mengubah perhitungan ini menjadi bentuk analog? Kami segera mendapatkan akselerasi perhitungan yang nyata dan potensi pengurangan konsumsi energi yang dramatis untuk satu operasi:Dengan pendekatan ini, DNN (Deep Neural Network) dihitung dengan cepat dan hemat energi. Tetapi ada masalah - ini adalah DAC / ADC (DAC / ADC) - konverter dari digital ke analog dan sebaliknya, yang mengurangi efisiensi energi dan akurasi proses.Namun, pada tahun 2017, IBM Research mengusulkan CMOS analog untuk RPU ( Unit Pemrosesan Resistif ), yang memungkinkan Anda untuk menyimpan data yang diproses juga dalam bentuk analog dan secara signifikan meningkatkan efisiensi keseluruhan dari pendekatan:Selain itu, selain memori analog, mengurangi keakuratan jaringan saraf dapat sangat membantu - ini adalah kunci untuk miniaturisasi RPU, yang berarti meningkatkan jumlah sel komputasi pada sebuah chip. Dan di sini, IBM juga merupakan pemimpin, dan khususnya, baru-baru ini tahun ini mereka cukup berhasil memperkuat jaringan hingga akurasi 2-bit dan akan membawa akurasi menjadi satu-bit (dan dua-bit selama pelatihan), yang berpotensi akan meningkatkan 100 kali lipat (!) Kinerja dibandingkan dengan GPU modern:Masih terlalu dini untuk membicarakan neurochip analog secara terperinci, karena sejauh ini semuanya telah diuji pada tingkat prototipe awal:Namun, arah potensial dari komputasi analog terlihat
sangat menarik.
Satu-satunya hal yang membingungkan adalah bahwa itu adalah IBM,
yang telah mengajukan puluhan paten pada subjek . Menurut pengalaman, karena kekhasan budaya perusahaan, mereka bekerja sama secara relatif lemah dengan perusahaan lain dan, memiliki beberapa teknologi, lebih mungkin memperlambat perkembangannya di antara yang lain daripada secara efektif membagikannya. Sebagai contoh, IBM pada suatu waktu menolak untuk melisensikan kompresi aritmatika untuk JPEG ke komite
ISO , meskipun fakta bahwa rancangan standar adalah opsi dengan kompresi aritmatika. Akibatnya, JPEG menjadi hidup dengan kompresi Huffman dan menyengat 10-15% lebih buruk dari yang seharusnya. Situasi yang sama dengan standar kompresi video. Dan industri secara besar-besaran beralih ke kompresi aritmatika dalam codec hanya ketika 5 paten IBM berakhir 12 tahun kemudian ... Mari kita berharap bahwa IBM akan lebih cenderung untuk bekerja sama saat ini, dan, oleh karena itu, kami
berharap keberhasilan maksimum di lapangan untuk semua orang yang tidak terkait dengan IBM , manfaat
orang-orang dan perusahaan seperti itu banyak .
Jika berhasil,
itu akan menjadi revolusi dalam penggunaan jaringan saraf dan revolusi di banyak bidang ilmu komputer.Lain-lain Surat Lainnya
Secara umum, topik percepatan jaringan saraf telah menjadi mode, semua perusahaan besar dan puluhan startup terlibat di dalamnya, dan
setidaknya 5 di antaranya telah menarik lebih dari $ 100 juta investasi pada awal 2018. Secara total, pada 2017, $ 1,5 MILIAR diinvestasikan dalam startup yang terkait dengan pengembangan chip. Terlepas dari kenyataan bahwa investor tidak melihat pembuat chip selama 15 tahun yang baik (karena tidak ada yang menangkap di sana dengan latar belakang raksasa). Secara umum - sekarang ada peluang nyata untuk revolusi besi kecil. Selain itu, sangat sulit untuk memprediksi arsitektur mana yang akan menang, kebutuhan akan revolusi telah matang, dan kemungkinan untuk meningkatkan produktivitas sangat besar. Situasi revolusioner klasik telah matang:
Moore tidak bisa lagi, dan
Dean belum siap.
Yah, karena hukum pasar yang paling penting - berbeda, ada banyak surat baru, misalnya:
- Neural Processing Unit ( NPU ) - Sebuah neuroprosesor, kadang-kadang indah - sebuah chip neuromorfik - secara umum, nama umum untuk akselerator jaringan saraf, yang disebut chip Samsung , Huawei dan selanjutnya dalam daftar ...
Selanjutnya dalam bagian ini, sebagian besar slide presentasi perusahaan akan diberikan sebagai contoh nama teknologi
Jelas bahwa perbandingan langsung bermasalah, tetapi di sini ada beberapa data menarik yang membandingkan chip dengan neuroprosesor dari Apple dan Huawei, yang diproduksi oleh TSMC yang disebutkan di awal. Dapat dilihat bahwa persaingan sangat sulit, generasi baru menunjukkan peningkatan produktivitas 2-8 kali dan kompleksitas proses teknologi:
- Neural Network Processor (NNP) - Prosesor jaringan saraf.
Ini adalah nama keluarga chip-nya, misalnya, Intel (awalnya itu adalah perusahaan Nervana Systems , yang dibeli Intel pada 2016 seharga $ 400 + juta). Namun, dalam artikel dan buku, nama NNP juga cukup umum.
- Intelligence Processing Unit (IPU) - prosesor cerdas - nama chip yang dipromosikan oleh Graphcore (omong-omong, yang telah menerima investasi $ 310 juta).
Ini menghasilkan kartu khusus untuk komputer, tetapi diarahkan untuk melatih jaringan saraf, dengan kinerja pelatihan RNN 180-240 kali lebih tinggi daripada NVIDIA P100.
- Dataflow Processing Unit (DPU) - prosesor pemrosesan data - nama ini dipromosikan oleh WAVE Computing , yang telah menerima investasi $ 203 juta. Ini menghasilkan tentang akselerator yang sama dengan Graphcore:
Karena mereka menerima kurang dari 100 juta, mereka menyatakan pelatihan hanya 25+ kali lebih cepat daripada pada GPU (meskipun mereka berjanji akan 1000 kali lebih cepat). Ayo lihat ...
- Unit Pemrosesan Visi ( VPU ) - Pengolah Visi Komputer:
Istilah ini digunakan dalam produk-produk dari beberapa perusahaan, misalnya, Myriad X VPU dari Movidius (juga dibeli oleh Intel pada 2016).
- Salah satu pesaing IBM (yang, kita ingat, menggunakan istilah RPU ) - Mythic - bergerak Analog DNN , yang juga menyimpan jaringan dalam chip dan eksekusi yang relatif cepat. Sejauh ini mereka hanya memiliki janji, meskipun serius :
Dan ini hanya mencantumkan area terbesar dalam pengembangan yang telah diinvestasikan ratusan juta (ini penting dalam pengembangan besi).
Secara umum, seperti yang kita lihat, semua bunga mekar dengan cepat. Secara bertahap, perusahaan akan mencurahkan investasi miliaran dolar (biasanya dibutuhkan 1,5-3 tahun untuk menghasilkan chip), debu akan mengendap, pemimpin akan menjadi jelas, para pemenang akan, seperti biasa, menulis cerita, dan nama teknologi paling sukses di pasar akan diterima secara umum. Ini sudah terjadi lebih dari sekali ("IBM PC", "Smartphone", "Xerox", dll.).
Beberapa kata tentang perbandingan yang benar
Seperti yang sudah disebutkan di atas, membandingkan kinerja jaringan saraf dengan benar tidaklah mudah. Inilah sebabnya mengapa Google menerbitkan grafik di mana TPU v1 membuat NVIDIA V100. NVIDIA, melihat aib seperti itu, menerbitkan jadwal di mana Google TPU v1 kehilangan V100. (Jadi!) Google menerbitkan bagan berikut, di mana V100 kalah di Google TPU v2 & v3. Dan akhirnya, Huawei adalah jadwal di mana semua orang kalah di Huawei Ascend, tetapi V100 lebih baik dari TPU v3. Sirkus, singkatnya. Apa karakteristiknya -
setiap bagan
memiliki kebenarannya
sendiri !
Akar penyebab situasi ini jelas:
- Anda dapat mengukur kecepatan belajar atau kecepatan eksekusi (mana yang lebih nyaman).
- Dimungkinkan untuk mengukur jaringan saraf yang berbeda, karena kecepatan eksekusi / pelatihan jaringan saraf yang berbeda pada arsitektur tertentu dapat berbeda secara signifikan karena arsitektur jaringan dan jumlah data yang diperlukan.
- Dan Anda dapat mengukur kinerja puncak akselerator (mungkin yang paling abstrak dari semua yang di atas).
Sebagai upaya untuk menertibkan di kebun binatang ini, tes
MLPerf muncul , yang sekarang memiliki versi 0,5 tersedia, mis. dia sedang dalam proses mengembangkan metodologi perbandingan, yang rencananya akan dibawa ke rilis pertama pada
kuartal ke -
3 tahun ini :
Karena penulis ada salah satu kontributor utama untuk TensorFlow, ada setiap kesempatan untuk mengetahui apa cara terbaik untuk melatih dan mungkin menggunakannya (karena versi seluler TF kemungkinan besar juga akan dimasukkan dalam tes ini dari waktu ke waktu).
Baru-baru ini, organisasi internasional
IEEE , yang menerbitkan bagian ketiga dari literatur teknis dunia tentang elektronik radio, komputer dan teknik listrik,
melarang Huawei dari wajah seorang anak, dan segera, bagaimanapun,
membatalkan larangan tersebut. Huawei belum berada dalam peringkat MLPerf
saat ini , sementara Huawei TPU adalah pesaing serius untuk kartu Google TPU dan NVIDIA (yaitu, selain yang politis, terus terang ada alasan ekonomi untuk mengabaikan Huawei). Dengan minat terselubung kami akan mengikuti perkembangan acara!
Semua ke surga! Lebih dekat ke awan!
Dan, karena ini tentang pelatihan, ada baiknya mengatakan beberapa kata tentang spesifiknya:
- Dengan meluasnya penelitian ke jaringan saraf dalam (dengan puluhan dan ratusan lapisan yang benar-benar merobek semua orang), perlu untuk menggiling ratusan megabyte koefisien, yang segera membuat semua cache prosesor dari generasi sebelumnya tidak efektif. Pada saat yang sama, ImageNet klasik membahas korelasi ketat antara ukuran jaringan dan akurasinya (semakin tinggi semakin baik, kanan, semakin besar jaringan, sumbu horizontal adalah logaritmik):
- Proses perhitungan di dalam jaringan saraf mengikuti skema tetap, yaitu di mana semua "percabangan" dan "transisi" (dalam hal abad terakhir) akan terjadi di sebagian besar kasus, tepatnya diketahui sebelumnya, yang meninggalkan eksekusi spekulatif dari instruksi tanpa pekerjaan, yang sebelumnya secara signifikan meningkatkan produktivitas:
Ini membuat mekanisme prediksi superscalar yang menumpuk untuk percabangan dan perhitungan awal dekade sebelumnya dari peningkatan prosesor tidak efektif (sayangnya, bagian dari chip ini, juga berkontribusi terhadap pemanasan global seperti DNN pada cache DNN).
- Selain itu, pelatihan jaringan saraf relatif lemah secara horizontal . Yaitu kita tidak bisa mengambil 1000 komputer yang kuat dan belajar akselerasi 1000 kali. Dan bahkan pada usia 100 kita tidak bisa (setidaknya sampai masalah teoritis dari penurunan kualitas pelatihan pada sejumlah besar batch diselesaikan). Secara umum, cukup sulit bagi kami untuk mendistribusikan sesuatu di beberapa komputer, karena begitu kecepatan akses ke memori terpadu di mana jaringan berada berkurang, kecepatan pembelajarannya menurun drastis. Oleh karena itu, jika seorang peneliti memiliki akses ke 1000 komputer yang kuat
secara gratis , ia pasti akan mengambil semuanya segera, tetapi kemungkinan besar (jika tidak ada infiniband + RDMA), akan ada banyak jaringan saraf dengan parameter hiper yang berbeda. Yaitu total waktu pelatihan hanya akan beberapa kali kurang dari dengan 1 komputer. Ada kemungkinan untuk bermain dengan ukuran batch, dan pendidikan lebih lanjut, dan teknologi fashion baru lainnya, tetapi kesimpulan utamanya adalah ya, dengan peningkatan jumlah komputer, efisiensi kerja dan kemungkinan mencapai hasil akan meningkat, tetapi tidak secara linear. Dan hari ini, waktu seorang peneliti Ilmu Data mahal dan sering jika Anda dapat menghabiskan banyak mobil (walaupun tidak masuk akal), tetapi dapatkan akselerasi - ini dilakukan (lihat contoh dengan 1, 2 dan 4 V100 mahal di awan tepat di bawah).
Tepatnya poin-poin ini menjelaskan mengapa begitu banyak orang bergegas menuju pengembangan zat besi khusus untuk jaringan saraf yang dalam. Dan mengapa mereka mendapatkan miliaran mereka. Benar-benar ada cahaya tampak di ujung terowongan dan tidak hanya Graphcore (yang, ingat, 240 kali pelatihan RNN dipercepat).
Sebagai contoh, bapak-bapak dari IBM Research
optimis bahwa mengembangkan chip khusus yang akan meningkatkan efisiensi perhitungan dengan urutan magnitude setelah 5 tahun (dan setelah 10 tahun dengan 2 order magnitude, mencapai peningkatan 1000 kali dibandingkan dengan level 2016 pada grafik ini, meskipun , dalam efisiensi per watt, tetapi daya inti juga akan meningkat):
Semua ini berarti munculnya potongan-potongan besi, pelatihan yang akan relatif cepat, tetapi yang akan mahal, yang secara alami mengarah pada gagasan berbagi waktu menggunakan sepotong besi yang mahal di antara para peneliti. Dan ide ini hari ini tidak kurang secara alami membawa kita ke cloud computing. Dan transisi belajar ke awan telah lama berjalan secara aktif.
Perhatikan bahwa sekarang pelatihan model yang sama dapat berbeda dalam waktu berdasarkan urutan besarnya layanan cloud yang berbeda. Amazon memimpin, dan Google Colab gratis menjadi yang terakhir. Harap perhatikan bagaimana hasil dari jumlah V100 berubah di antara para pemimpin - peningkatan jumlah kartu sebanyak 4 kali (!) Meningkatkan produktivitas kurang dari sepertiga (!!!) dari biru menjadi ungu, dan Google bahkan memiliki lebih sedikit:
Tampaknya di tahun-tahun mendatang perbedaan akan tumbuh menjadi dua urutan besarnya. Tuhan! Memasak uang! Kami secara damai akan mengembalikan investasi miliaran ke investor paling sukses ...
Singkatnya
Mari kita coba merangkum poin-poin utama dalam tablet:
Beberapa kata tentang akselerasi perangkat lunak
Dalam keadilan, kami menyebutkan bahwa hari ini topik utama adalah percepatan perangkat lunak dari eksekusi dan pelatihan jaringan saraf yang dalam. Eksekusi dapat dipercepat secara signifikan terutama karena apa yang disebut kuantisasi jaringan. Mungkin ini adalah, pertama, karena rentang bobot yang digunakan tidak begitu besar dan sering kali memungkinkan untuk menyamakan bobot dari nilai titik-mengambang 4-byte menjadi integer 1 byte (dan, mengingat keberhasilan IBM, bahkan lebih kuat). Kedua, jaringan terlatih secara keseluruhan cukup tahan terhadap kebisingan komputasi dan keakuratan transisi ke
int8 turun sedikit. Pada saat yang sama, terlepas dari kenyataan bahwa jumlah operasi bahkan dapat meningkat (karena penskalaan saat menghitung), fakta bahwa jaringan dikurangi ukurannya sebanyak 4 kali dan dapat dianggap operasi vektor cepat secara signifikan meningkatkan kecepatan keseluruhan eksekusi. Ini sangat penting untuk aplikasi seluler, tetapi juga berfungsi di cloud (contoh eksekusi yang dipercepat di cloud Amazon):
Ada cara lain untuk
mempercepat eksekusi jaringan secara algoritmik dan bahkan lebih banyak cara untuk
mempercepat pembelajaran . Namun, ini adalah topik besar yang terpisah tentang yang kali ini tidak.
Alih-alih sebuah kesimpulan
Dalam ceramahnya, investor dan penulis
Tony Ceba memberikan contoh yang luar biasa: pada tahun 2000, superkomputer No. 1 dengan kapasitas 1 teraflop menempati 150 meter persegi, biaya $ 46 juta dan dikonsumsi 850 kW:
15 tahun kemudian, GPU NVIDIA dengan kinerja 2,3 teraflops (2 kali lebih banyak) pas di tangan, biaya $ 59 (peningkatan sekitar satu juta kali) dan dikonsumsi 15 watt (peningkatan 56 ribu kali):
Pada bulan Maret tahun ini,
Google memperkenalkan TPU Pods , yang sebenarnya superkomputer berpendingin cair berdasarkan TPU v3, fitur utamanya adalah mereka dapat bekerja bersama dalam sistem 1024 TPU. Mereka terlihat sangat mengesankan:
Data pasti tidak diberikan, tetapi dikatakan bahwa sistem ini sebanding dengan superkomputer Top-5 di dunia. TPU Pod dapat secara dramatis meningkatkan kecepatan belajar jaringan saraf. Untuk meningkatkan kecepatan interaksi, TPU dihubungkan oleh garis berkecepatan tinggi ke dalam struktur toroidal:

Tampaknya setelah 15 tahun, neuroprosesor dua kali lebih kuat ini juga akan dapat pas di tangan Anda, seperti
prosesor Skynet (Anda
harus mengakui, ini mirip)
Mengambil gambar dari versi film "Terminator 2"Mengingat laju peningkatan akselerator perangkat keras dari jaringan saraf dalam saat ini dan contoh di atas, ini benar-benar nyata. Ada beberapa peluang dalam beberapa tahun untuk mengambil chip dengan kinerja seperti TPU Pod hari ini.
Ngomong-ngomong, lucu bahwa di film pembuat chip (tampaknya, membayangkan di mana jaringan pelatihan mandiri mungkin) mematikan pelatihan ulang secara default. Secara karakteristik,
T-800 sendiri tidak dapat mengaktifkan mode pelatihan dan bekerja dalam mode inferensi (lihat
versi directorial yang lebih panjang). Selain itu,
prosesor neural-netenya canggih dan ketika menyalakan pelatihan ulang itu bisa menggunakan data yang terakumulasi sebelumnya untuk memperbarui model. Tidak buruk untuk 1991.
Teks ini dimulai di 13 juta Shenzhen panas. Saya duduk di salah satu dari 27.000 taksi listrik kota dan memandangi 4 layar kristal cair mobil dengan penuh minat. Satu kecil - di antara perangkat di depan pengemudi, dua - di tengah di dashboard dan yang terakhir - transparan - di kaca spion, dikombinasikan dengan DVR, kamera pengintai interior dan android di papan (dilihat dari garis atas dengan tingkat pengisian dan koneksi jaringan). Ini menampilkan data pengemudi (siapa yang mengeluh, jika itu), ramalan cuaca segar, dan tampaknya ada koneksi dengan armada taksi. Pengemudi itu tidak tahu bahasa Inggris, dan tidak berhasil bertanya kepadanya tentang kesan mesin listrik itu. Karena itu, dia malas menekan pedal, sedikit menggerakkan mobil dalam kemacetan. Dan saya melihat jendela dengan tampilan futuristik dengan penuh minat - orang Cina dengan jaket mereka sedang berkendara dari bekerja dengan skuter listrik dan monowheel ... dan bertanya-tanya bagaimana semua akan terlihat dalam 15 tahun ...
Sebenarnya, sudah hari ini, kaca spion, menggunakan data dari kamera DVR dan
akselerasi perangkat keras dari jaringan saraf , cukup mampu mengendalikan mobil dalam lalu lintas dan meletakkan rute. Paling tidak pada sore hari). Setelah 15 tahun, sistem ini jelas tidak hanya dapat mengendarai mobil, tetapi juga akan senang memberi saya karakteristik kendaraan listrik China yang segar. Dalam bahasa Rusia, secara alami (sebagai pilihan: Inggris, Cina ... Albania, akhirnya). Pengemudi di sini berlebihan, tidak terlatih, tautan.
Tuhan!
SANGAT MENARIK 15 tahun menunggu kami!
Tetap disini!
Saya akan kembali! )))
 UPD:
UPD: Komentar paling menarik:
Tentang kuantisasi dan percepatan perhitungan pada FPGA
Komentar @Mirn
Pada FPGA, tidak hanya aritmatika presisi sewenang-wenang yang tersedia, tetapi juga kemampuan penting untuk menyimpan dan memproses data bit sewenang-wenang. Misalnya, ada terlalu banyak koefisien dalam MobileNetV2 W dan B yang menjengkelkan dan Anda dapat menghitungnya tanpa kehilangan banyak keakuratan hingga hanya 16 bit, atau Anda harus berlatih ulang. Tetapi jika Anda melihat ke dalam dan mengumpulkan statistik pada saluran dan lapisan, maka Anda dapat melihat bahwa semua 16 bit hanya digunakan pada input dari koefisien 1000 W pertama, sisanya secara pointwise memiliki 8-11 bit, yang mana hanya 2-3 bit paling signifikan dan tanda sangat penting, dan statistik tentang penggunaan saluran sehingga ada banyak saluran di mana umumnya nol, atau nilai kecil, atau saluran di mana hampir semua nilai 8-11 bit, mis. adalah mungkin untuk memaku peserta pameran di paku dalam waktu kompilasi dan tidak menyimpan i.e. pada kenyataannya, dimungkinkan untuk menyimpan dalam memori ROM bukan nilai 16-bit tetapi 4-bit, dan Anda bahkan dapat menyimpan seluruh jaringan saraf pada FPGA murah tanpa kehilangan akurasi (kurang dari 1%), dan juga memproses dengan kecepatan hingga puluhan ribu FPS dengan latensi sehingga kami mendapatkan respons jaringan saraf segera Bagaimana penerimaan frame berakhir.
Tentang kuantisasi: ide saya adalah jika pada sejumlah tahap komputasi W, koefisien untuk saluran No. 0 hanya berubah dari +50 ke -50, maka masuk akal untuk mengompresi bitness ke 7, dan jika dari -123 ke +124 misalnya, kemudian ke 8 (termasuk tanda )Bagaimanapun, di dalam FPGA, semua saluran dihitung secara paralel per siklus, dan blok memori 7, 8, dll ini digabungkan menjadi satu bagian paralel besar dari memori ROM dengan ukuran bit urutan beberapa puluh ribu bit. Baik dan lebih jauh, jika bit orde rendah dari mereka tidak sangat mempengaruhi hasil atau akurasi, maka mereka juga berbaring di tempat.
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! karena dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
Tentang kompilasi model optimal otomatis pada GPU, FPGA, ASIC dan perangkat keras lainnyaKomentar oleh @BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
Tentang pengumuman inovasi dalam arsitektur FPGA, penggunaan Microsoft FPGA dan optimalisasi otomatis jaringan sarafKomentar bagus @ Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . Yaitu - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
Tentang ekonomi pembangunan FPGA versus ASICKomentar oleh @Mirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
Ucapan Terima Kasih:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !