Ingatlah bahwa Elastic Stack didasarkan pada basis data Elasticsearch yang non-relasional, antarmuka web Kibana, dan pengumpul data (Logstash paling terkenal, berbagai Beats, APM, dan lainnya). Salah satu tambahan yang bagus untuk seluruh tumpukan produk yang terdaftar adalah analisis data menggunakan algoritma pembelajaran mesin. Dalam artikel tersebut, kami memahami apa itu algoritma ini. Kami meminta kucing.
Pembelajaran mesin adalah fitur berbayar dari shareware Elastic Stack dan merupakan bagian dari X-Pack. Untuk mulai menggunakannya, cukup setelah aktivasi untuk mengaktifkan uji coba 30 hari. Setelah masa uji coba berakhir, Anda dapat meminta dukungan untuk perpanjangannya atau membeli langganan. Biaya berlangganan dihitung bukan dari jumlah data, tetapi dari jumlah node yang digunakan. Tidak, jumlah data mempengaruhi, tentu saja, jumlah simpul yang dibutuhkan, tetapi pendekatan perizinan ini lebih manusiawi dalam kaitannya dengan anggaran perusahaan. Jika tidak perlu untuk kinerja tinggi - Anda dapat menyimpan.
ML dalam Elastic Stack ditulis dalam C ++ dan bekerja di luar JVM, yang menjalankan Elasticsearch sendiri. Yaitu, proses (yang, omong-omong, disebut autodetect) mengkonsumsi semua yang tidak ditelan JVM. Pada demo stand, ini tidak terlalu kritis, tetapi dalam lingkungan yang produktif penting untuk menyoroti node yang terpisah untuk tugas ML.
Algoritma pembelajaran mesin dibagi menjadi dua kategori -
dengan dan
tanpa guru . Dalam Elastic Stack, algoritma ini berasal dari kategori “no teacher”.
Tautan ini memungkinkan Anda untuk melihat peralatan matematika dari algoritma pembelajaran mesin.
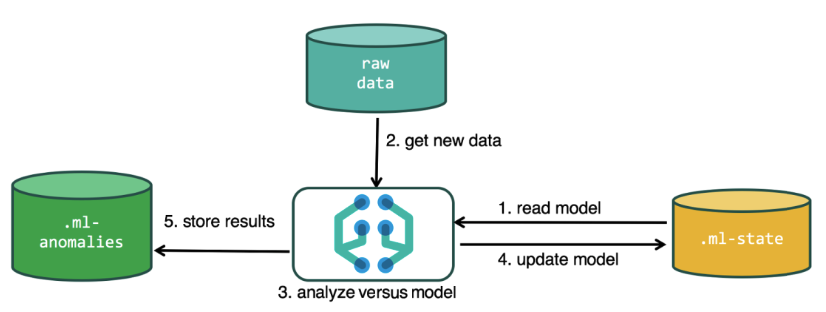
Untuk melakukan analisis, algoritma pembelajaran mesin menggunakan data yang disimpan dalam indeks Elasticsearch. Anda dapat membuat tugas untuk analisis baik dari antarmuka Kibana dan melalui API. Jika Anda melakukan ini melalui Kibana, maka beberapa hal tidak perlu diketahui. Misalnya, indeks tambahan yang digunakan algoritma dalam proses.
Indeks tambahan digunakan dalam proses analisis.ml-state - informasi tentang model statistik (pengaturan analisis);
.ml-anomaly- * - hasil kerja algoritma ML;
.ml-notification - pengaturan notifikasi berdasarkan hasil analisis.
Struktur data dalam database Elasticsearch terdiri dari indeks dan dokumen yang disimpan di dalamnya. Jika dibandingkan dengan database relasional, maka indeks dapat dibandingkan dengan skema basis data, dan dokumen dengan entri dalam tabel. Perbandingan ini bersifat kondisional dan disediakan untuk menyederhanakan pemahaman materi lebih lanjut bagi mereka yang hanya mendengar tentang Elasticsearch.
Fungsionalitas yang sama tersedia melalui API seperti melalui antarmuka web, jadi untuk kejelasan dan pemahaman konsep, kami akan menunjukkan cara mengkonfigurasi melalui Kibana. Ada bagian Machine Learning di menu di sebelah kiri di mana Anda dapat membuat pekerjaan baru. Di antarmuka Kibana, terlihat seperti gambar di bawah ini. Sekarang kita akan menganalisis setiap jenis tugas dan menunjukkan jenis analisis yang dapat dibangun di sini.
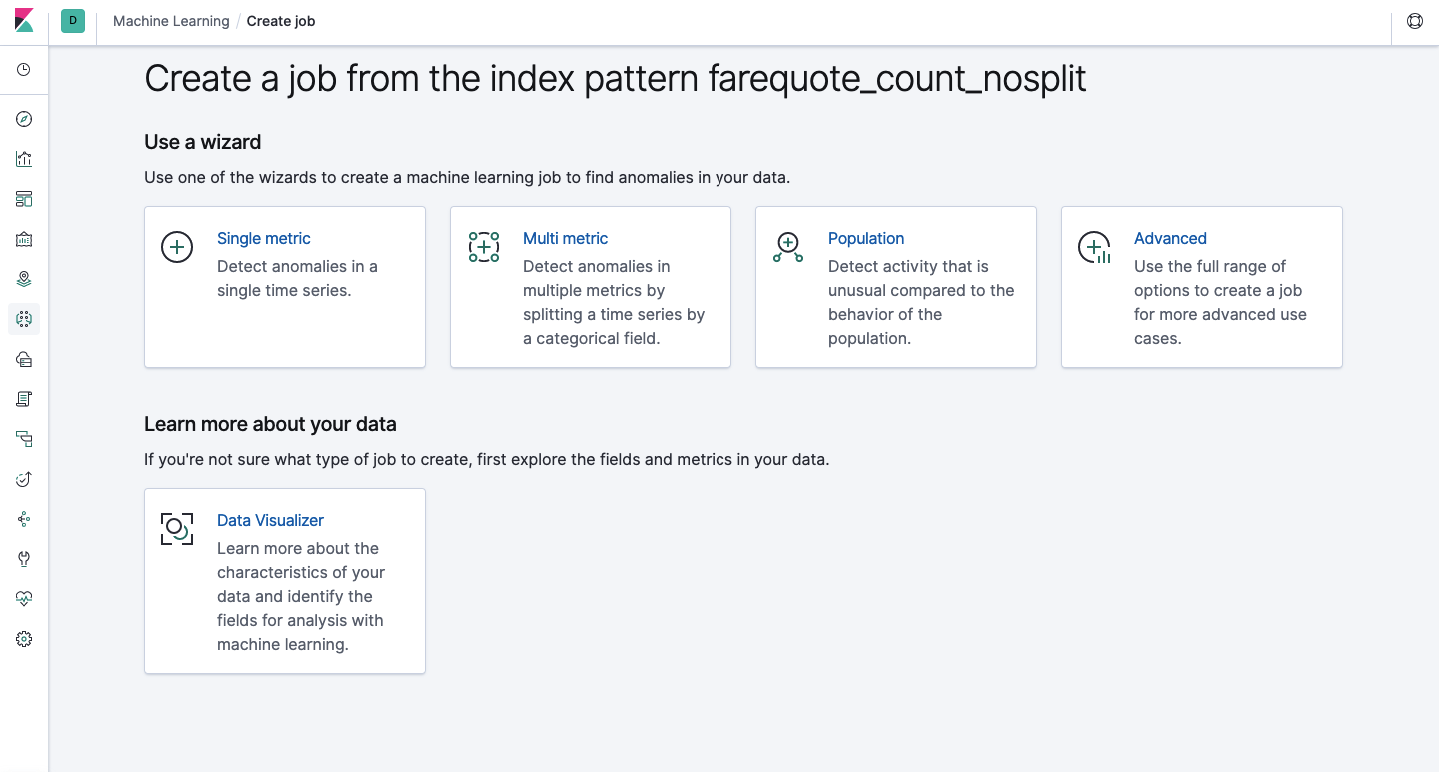
Metrik Tunggal - analisis satu metrik, Multi Metrik - analisis dua atau lebih metrik. Dalam kedua kasus, setiap metrik dianalisis dalam lingkungan yang terisolasi, yaitu Algoritme tidak memperhitungkan perilaku metrik yang dianalisis secara paralel karena mungkin terlihat dalam kasus Multi Metrik. Untuk melakukan perhitungan dengan mempertimbangkan korelasi berbagai metrik, Anda dapat menerapkan analisis Populasi. Dan Advanced adalah penyempurnaan algoritma dengan opsi tambahan untuk tugas-tugas tertentu.
Metrik tunggal
Analisis perubahan dalam satu metrik tunggal adalah hal paling sederhana yang dapat Anda lakukan di sini. Setelah mengklik Create Job, algoritme akan mencari anomali.
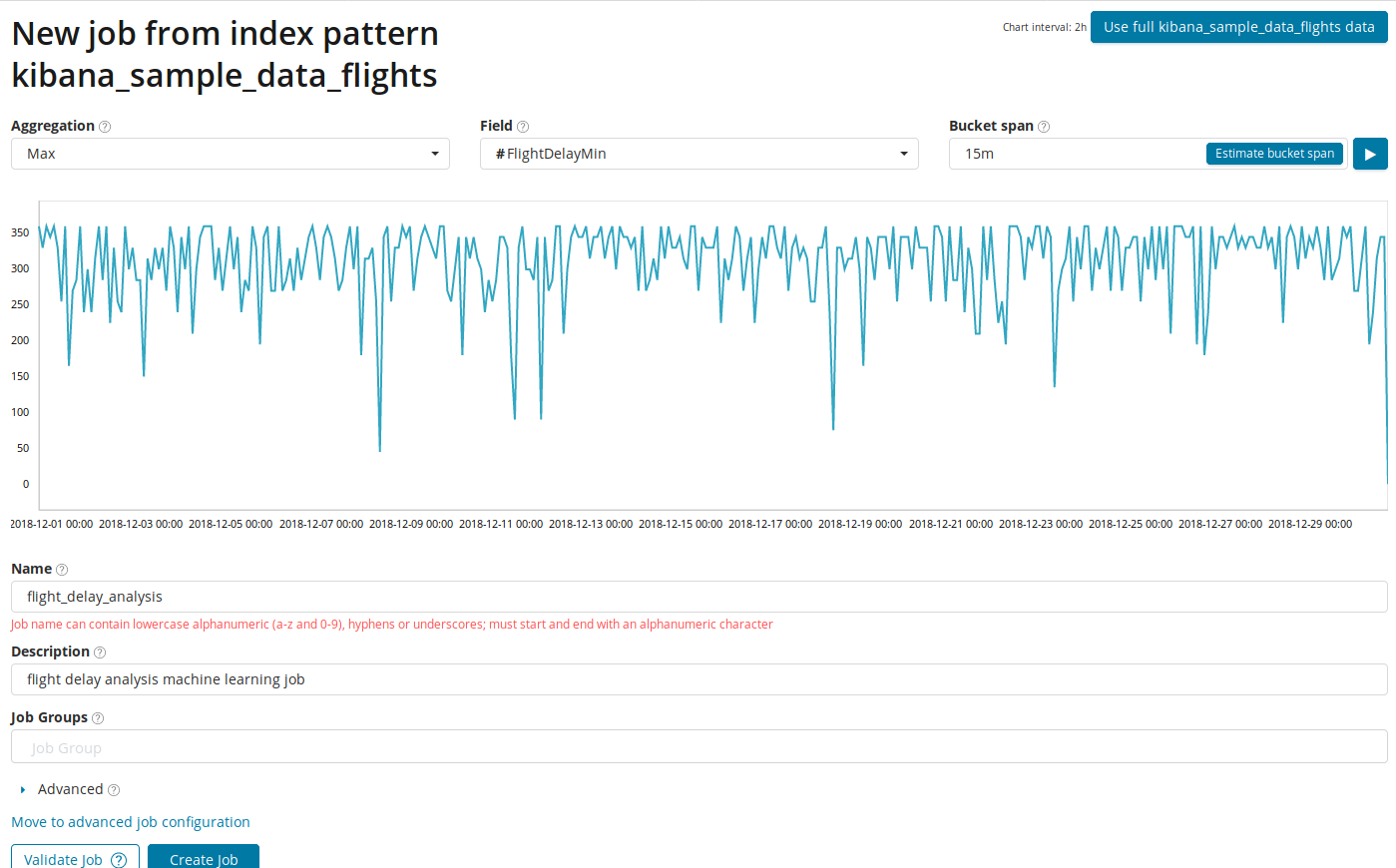
Di bidang
Agregasi , Anda dapat memilih pendekatan untuk mencari anomali. Misalnya, dengan
Min nilai abnormal akan dianggap lebih rendah dari tipikal. Ada
Max, Hign Mean, Low, Mean, Distinct dan lainnya. Deskripsi semua fungsi dapat ditemukan di
sini .
Kolom Bidang menunjukkan bidang numerik dalam dokumen yang akan kami analisis.
Di bidang
rentang Bucket , rincian interval pada garis waktu di mana analisis akan dilakukan. Anda dapat mempercayai otomatisasi atau memilih secara manual. Gambar di bawah ini menunjukkan contoh granularity terlalu rendah - Anda dapat melewati anomali. Dengan menggunakan pengaturan ini, Anda dapat mengubah sensitivitas algoritme menjadi anomali.

Durasi data yang dikumpulkan adalah hal utama yang memengaruhi efektivitas analisis. Dalam analisis, algoritma menentukan interval berulang, menghitung interval kepercayaan (baseline) dan mengidentifikasi anomali - penyimpangan atipikal dari perilaku metrik yang biasa. Sebagai contoh saja:
Baseline dengan rentang data kecil:
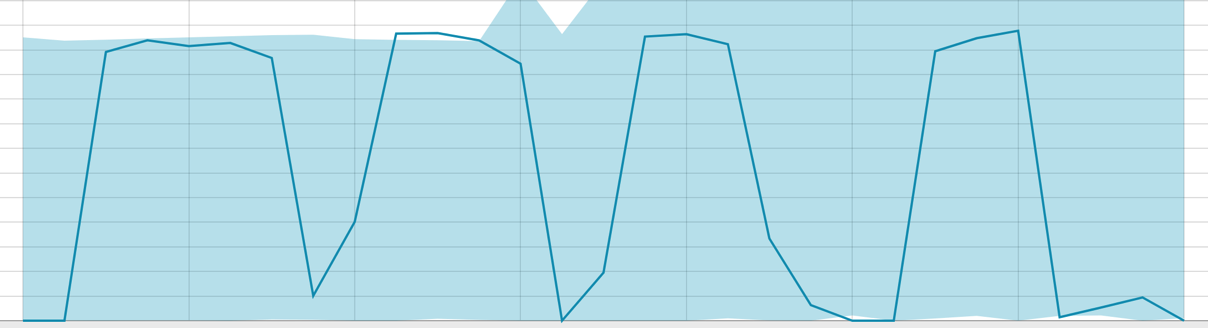
Ketika algoritma memiliki sesuatu untuk dipelajari, garis dasarnya terlihat seperti ini:
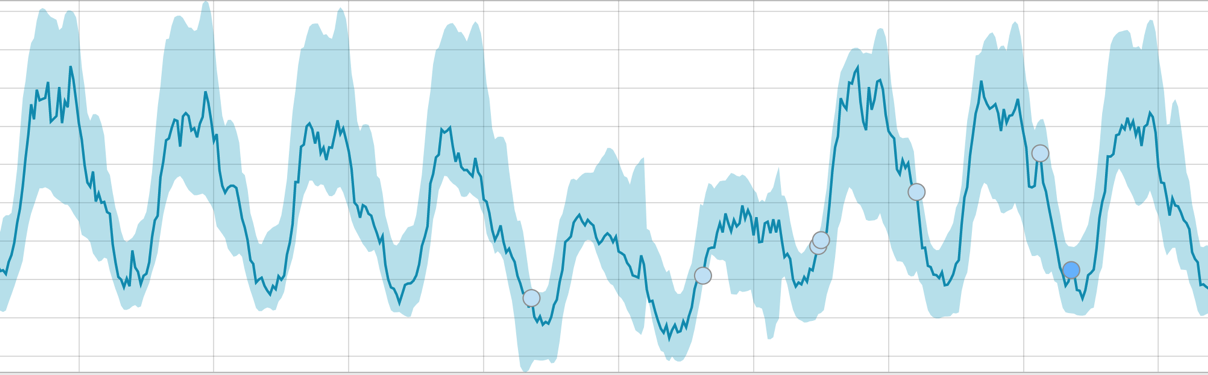
Setelah memulai tugas, algoritma menentukan penyimpangan anomali dari norma dan memeringkatnya dengan probabilitas anomali (warna label yang sesuai ditunjukkan dalam tanda kurung):
Peringatan (cyan): kurang dari 25
Kecil (kuning): 25-50
Mayor (oranye): 50-75
Kritis (merah): 75-100
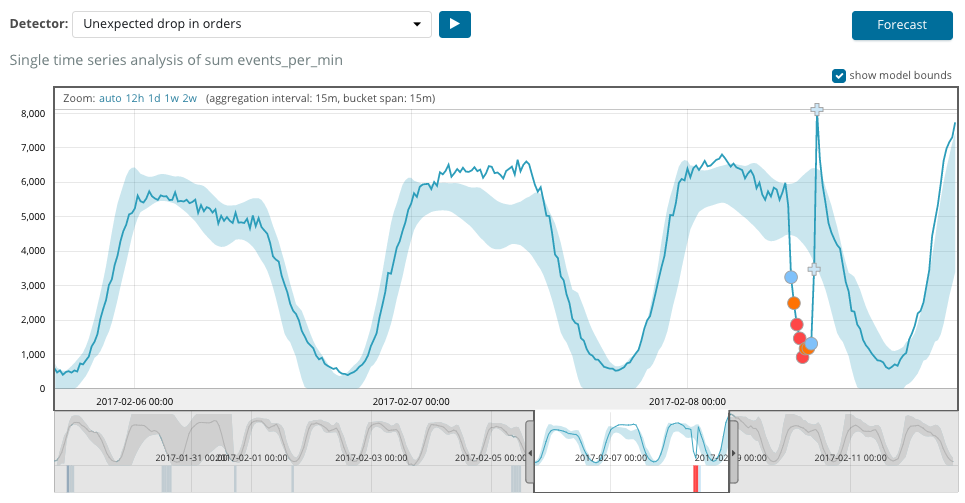
Bagan di bawah ini menunjukkan contoh anomali yang ditemukan.
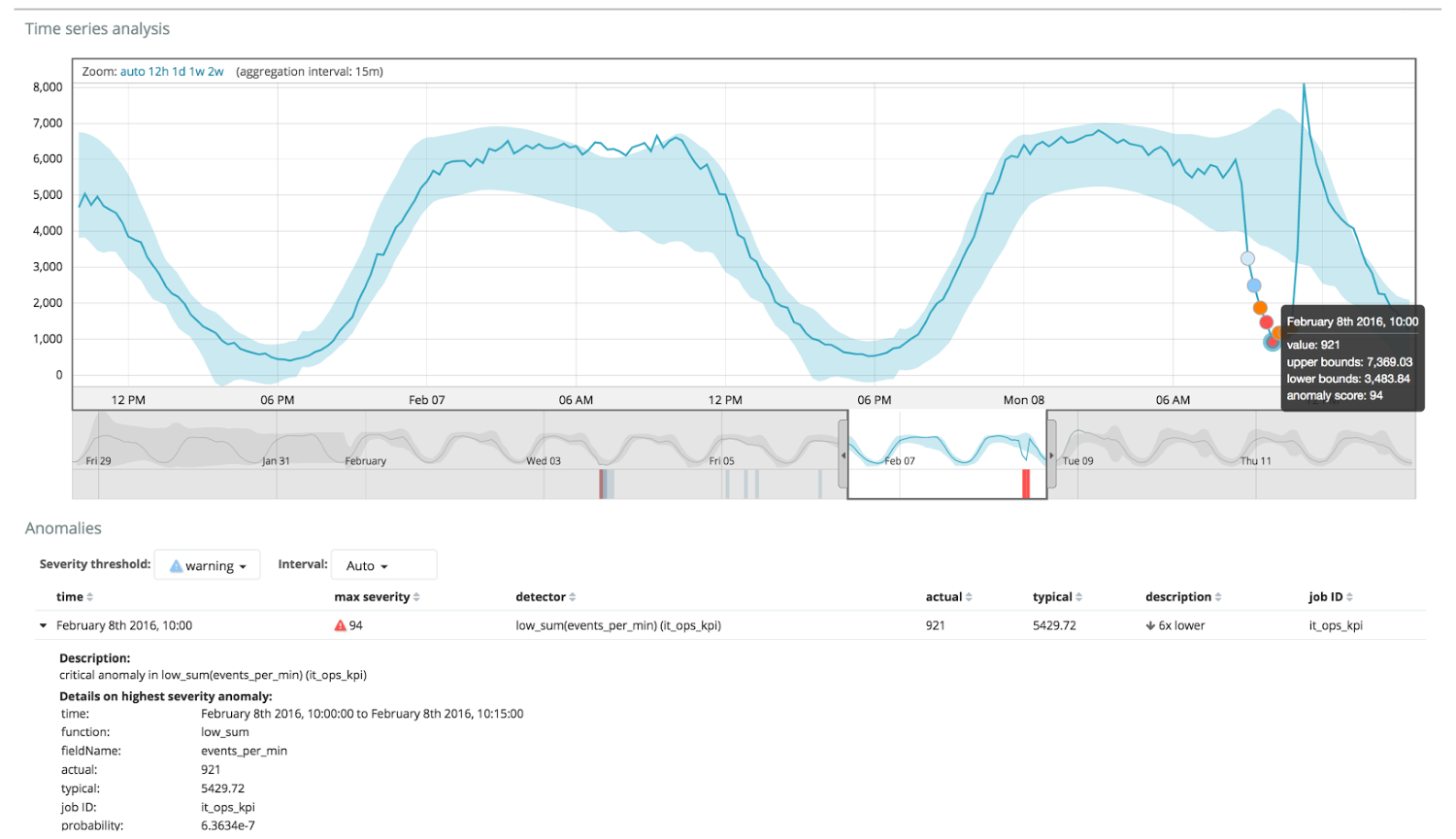
Di sini Anda dapat melihat angka 94, yang menunjukkan kemungkinan anomali. Jelas bahwa karena nilainya mendekati 100, itu berarti anomali. Kolom di bawah grafik menunjukkan probabilitas penurunan 0,000063634% dari kemunculan nilai metrik di sana.
Selain mencari anomali di Kibana, Anda dapat menjalankan perkiraan. Ini dilakukan dengan cara dasar dan dari tampilan yang sama dengan anomali - tombol
Forecast di sudut kanan atas.

Perkiraan ini didasarkan pada maksimum 8 minggu sebelumnya. Bahkan jika Anda benar-benar ingin, Anda tidak dapat lagi dengan desain.
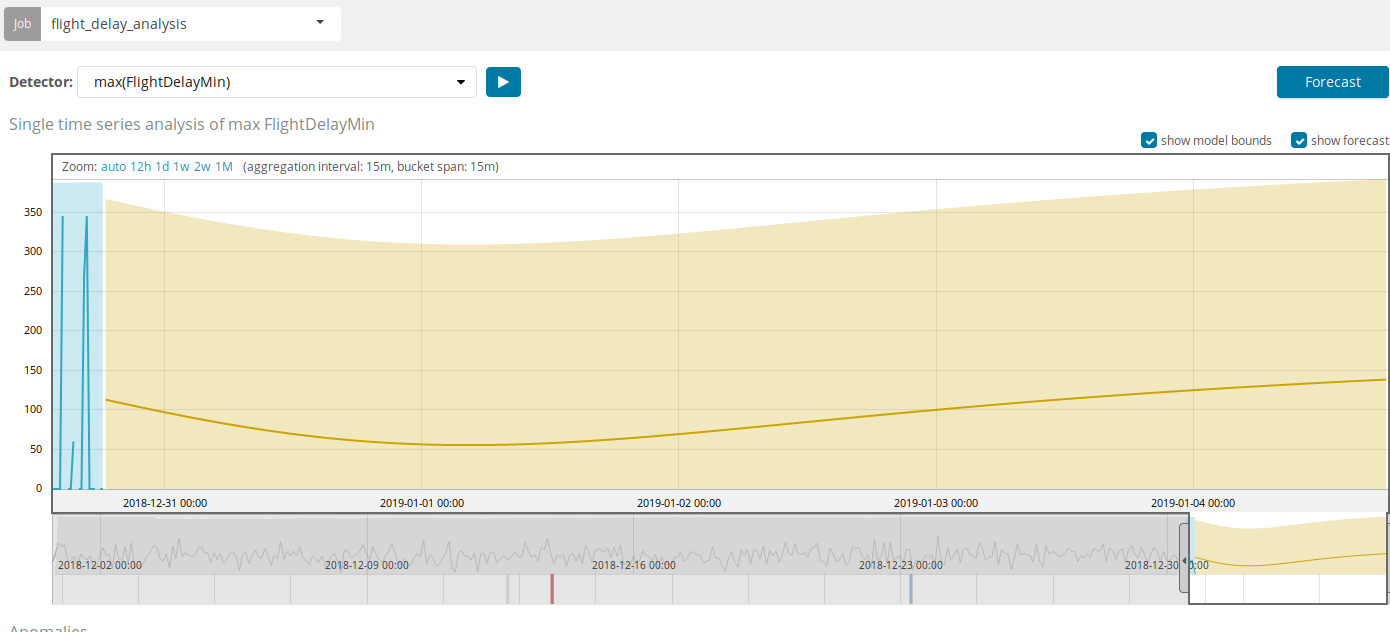
Dalam beberapa situasi, ramalan akan sangat berguna, misalnya, ketika beban pengguna pada infrastruktur dimonitor.
Multi metrik
Kami beralih ke fitur ML berikutnya di Elastic Stack - analisis beberapa metrik dalam satu bundel. Tetapi ini tidak berarti bahwa ketergantungan satu metrik pada metrik lainnya akan dianalisis. Ini sama dengan Metrik Tunggal dengan hanya banyak metrik pada satu layar untuk memudahkan perbandingan efek satu pada lainnya. Kami akan berbicara tentang analisis ketergantungan satu metrik pada yang lain di bagian Populasi.
Setelah mengklik kotak dengan Multi Metric, jendela pengaturan akan muncul. Kami akan membahasnya lebih terinci.
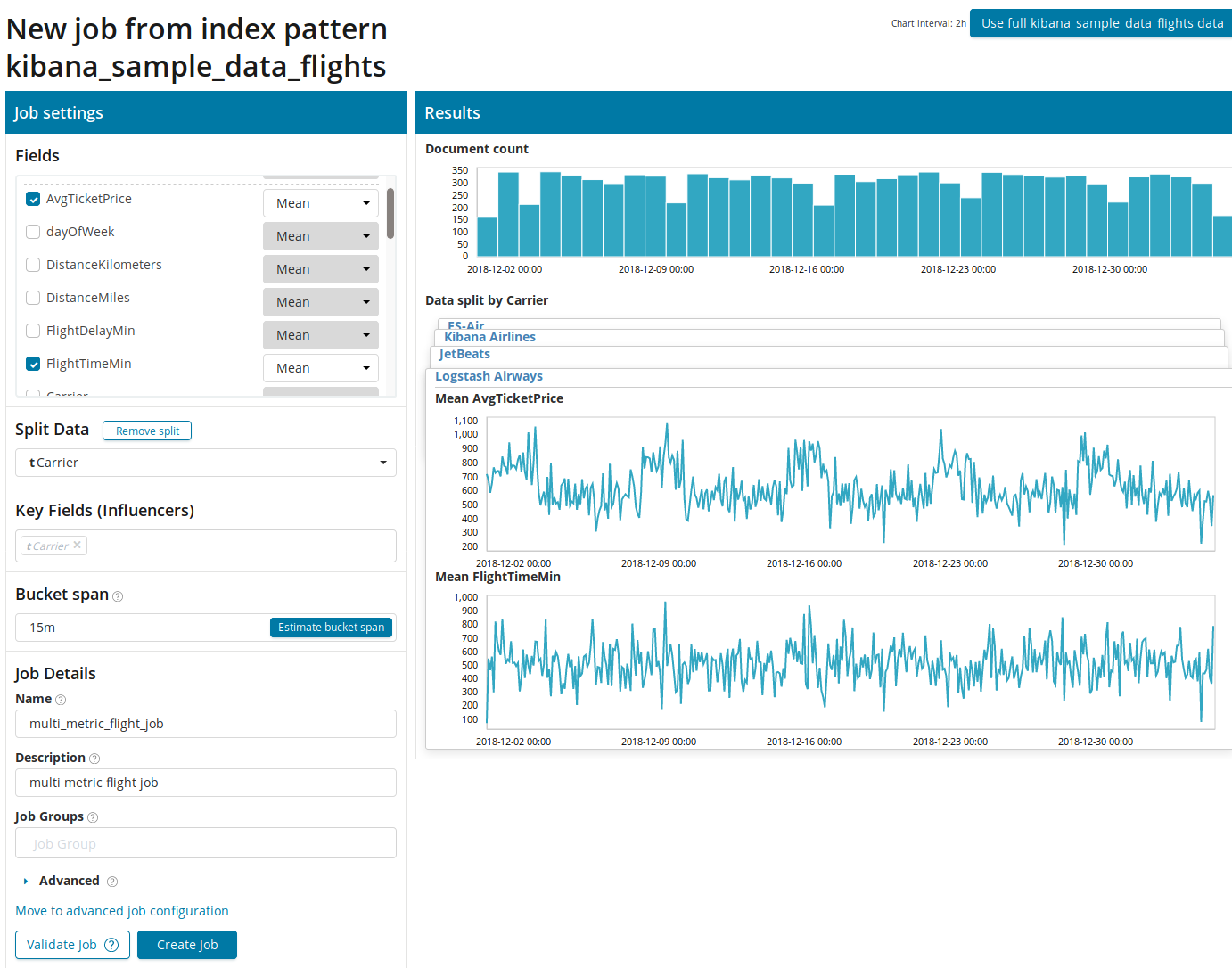
Pertama, Anda perlu memilih bidang untuk analisis dan agregasi data. Opsi agregasi di sini sama dengan untuk Metrik Tunggal (
Max, Hign Mean, Rendah, Mean, Distinct, dan lainnya). Selanjutnya, data secara opsional dibagi menjadi salah satu bidang (bidang
Data Terpisah ). Dalam contoh, kami melakukan ini menggunakan bidang
OriginAirportID . Perhatikan bahwa grafik metrik di sebelah kanan sekarang disajikan sebagai beberapa grafik.
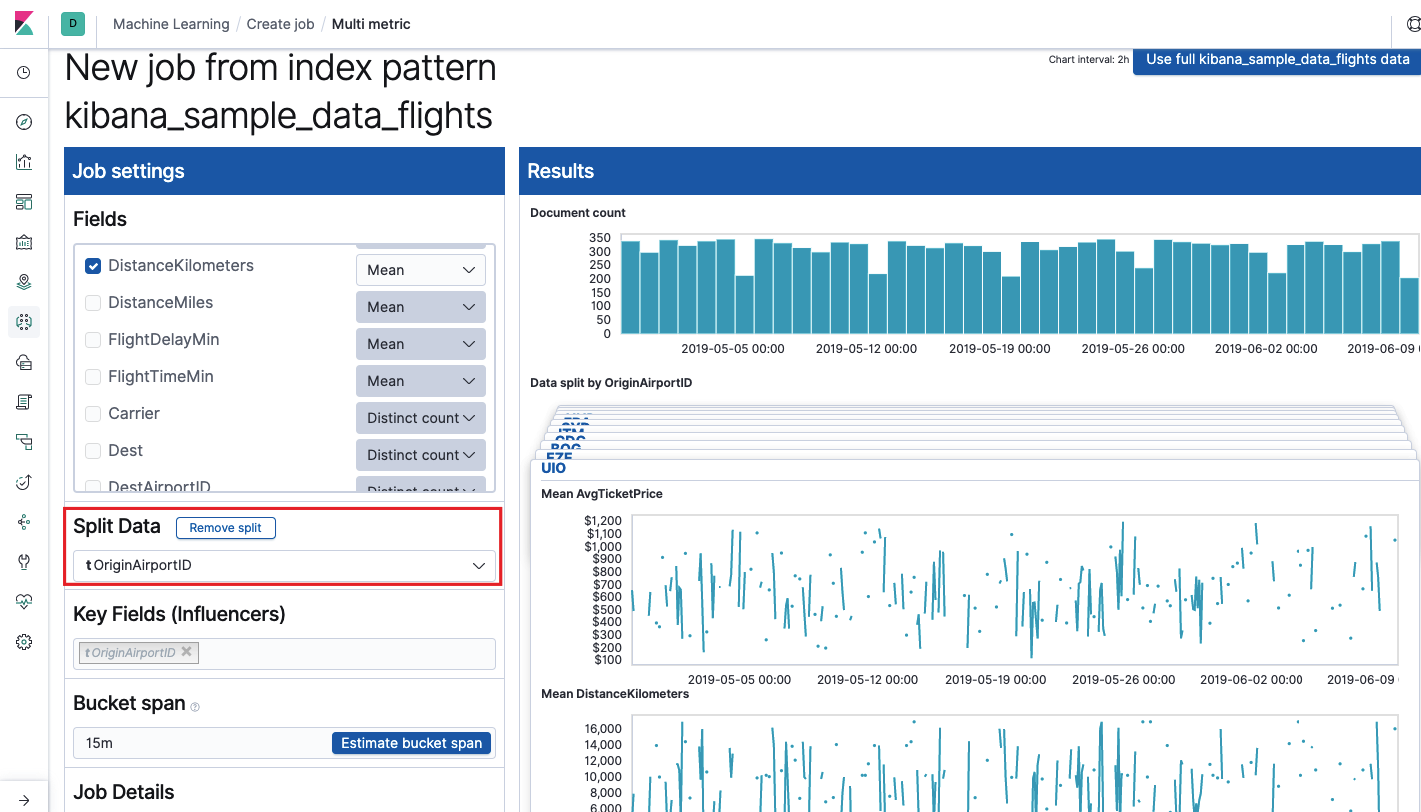 Bidang Kunci (Influencer)
Bidang Kunci (Influencer) secara langsung memengaruhi anomali yang ditemukan. Secara default, akan selalu ada setidaknya satu nilai, dan Anda dapat menambahkan yang lainnya. Algoritme akan memperhitungkan pengaruh bidang-bidang ini dalam analisis dan menunjukkan nilai-nilai yang paling "berpengaruh".
Setelah diluncurkan, gambar berikut akan muncul di antarmuka Kibana.
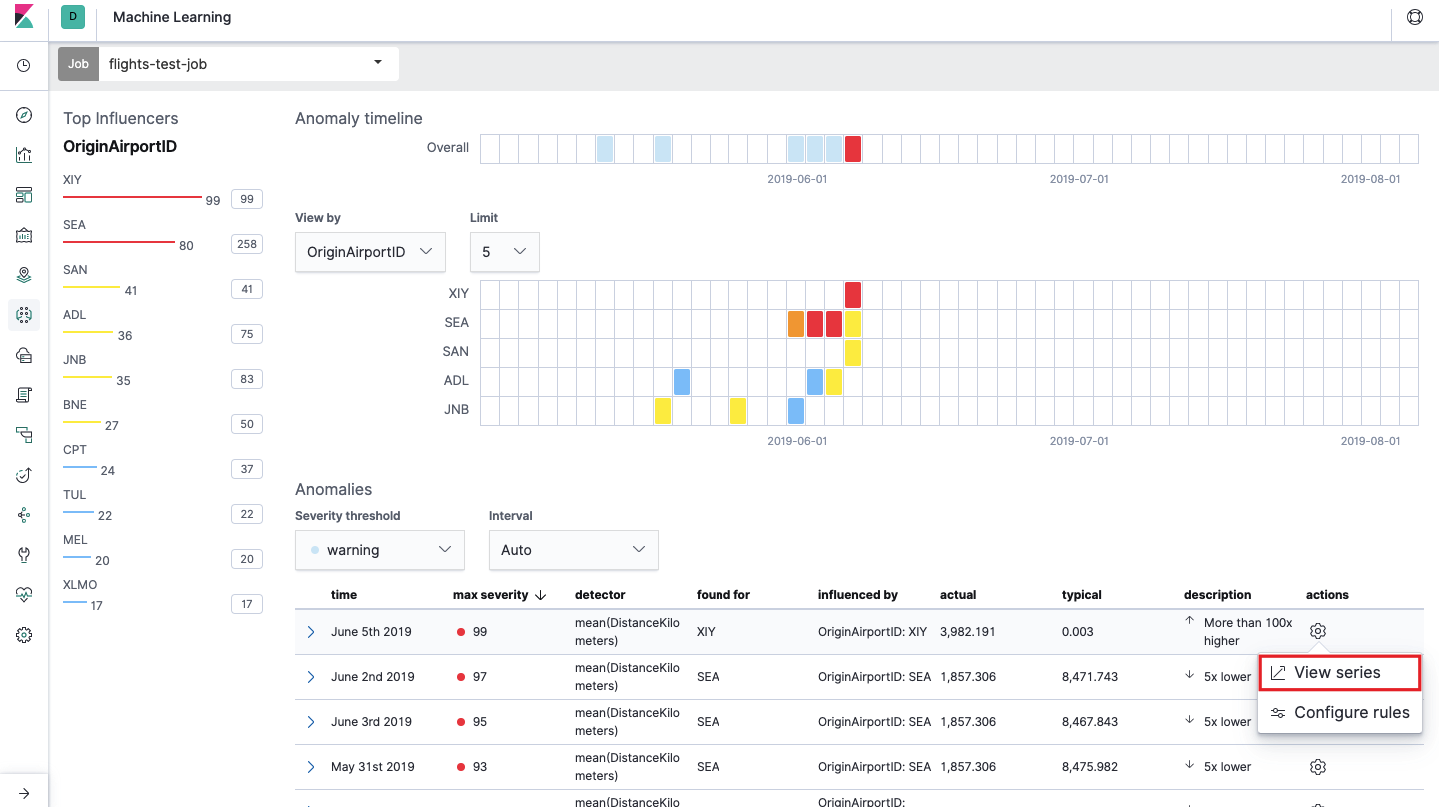
Inilah yang disebut heat map of anomaly untuk setiap nilai bidang
OriginAirportID yang kami tentukan di
Split Data . Seperti dengan Metrik Tunggal, warna menunjukkan tingkat penyimpangan abnormal. Lebih mudah untuk melakukan analisis serupa, misalnya, pada workstation untuk melacak orang-orang di mana ada banyak otorisasi yang mencurigakan, dll Kami sudah menulis
tentang peristiwa mencurigakan di EventLog Windows , yang juga dapat dikumpulkan dan dianalisis di sini.
Di bawah peta panas adalah daftar anomali, dari masing-masing Anda dapat pergi ke tampilan Satu Metrik untuk analisis terperinci.
Populasi
Untuk mencari anomali di antara korelasi antara metrik yang berbeda, Elastic Stack memiliki analisis Populasi khusus. Dengan bantuannya Anda dapat mencari nilai-nilai tidak normal dalam kinerja server dibandingkan dengan yang lain, misalnya dengan peningkatan jumlah permintaan ke sistem target.
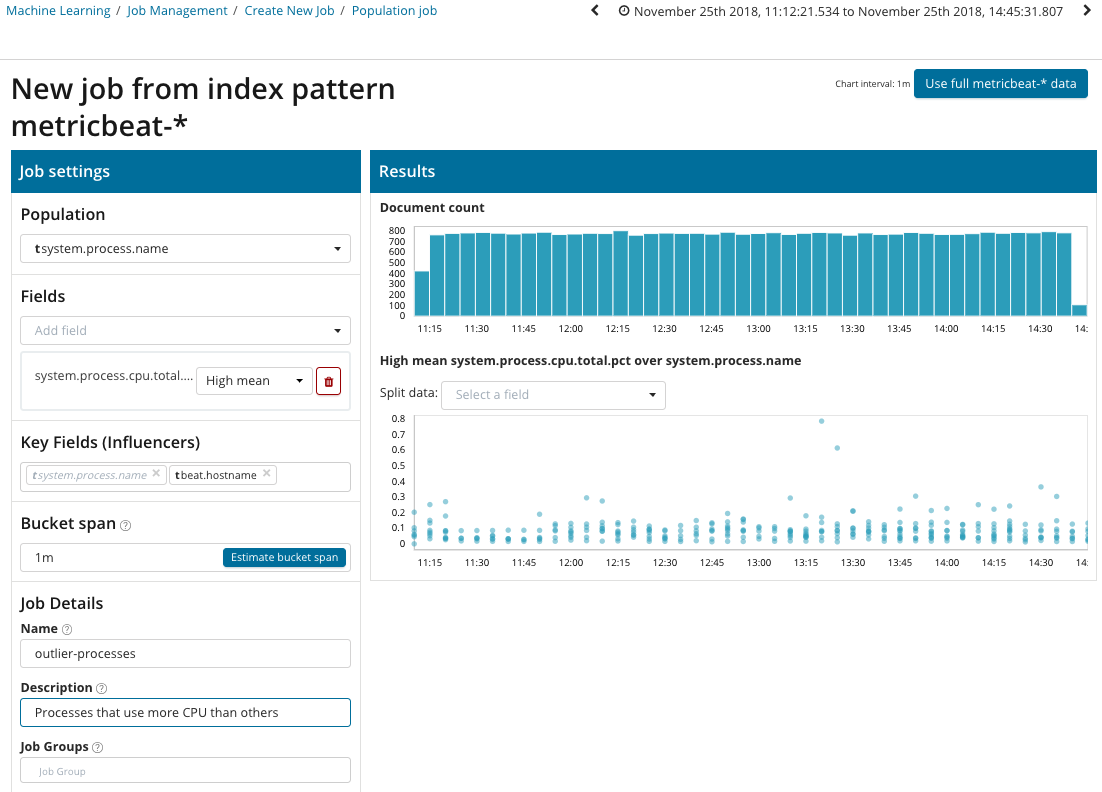
Dalam ilustrasi ini, bidang Populasi menunjukkan nilai yang terkait dengan metrik yang dianalisis. Ini adalah nama prosesnya. Sebagai hasilnya, kita akan melihat bagaimana pemuatan prosesor oleh masing-masing proses saling memengaruhi.
Harap dicatat bahwa grafik dari data yang dianalisis berbeda dari kasing dengan Metrik Tunggal dan Multi Metrik. Ini dilakukan di Kibana oleh desain untuk persepsi yang lebih baik dari distribusi nilai-nilai data yang dianalisis.

Grafik menunjukkan bahwa proses
stres (by the way, yang dihasilkan oleh utilitas khusus) pada server
poipu berperilaku tidak normal , yang mempengaruhi (atau berubah menjadi influencer) terjadinya anomali ini.
Mahir
Analitik yang disesuaikan. Dengan Analisis Lanjut, pengaturan tambahan muncul di Kibana. Setelah mengklik pada menu buat pada ubin Tingkat Lanjut, jendela tab seperti itu muncul. Tab
Detail Pekerjaan sengaja dilewati, di sana pengaturan dasar tidak terkait langsung dengan pengaturan analisis.
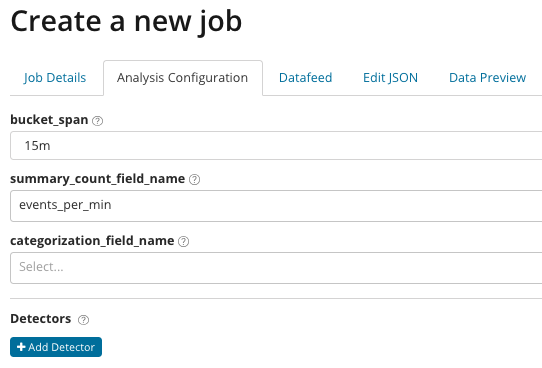
Di
summary_count_field_name, Anda bisa menentukan nama bidang dari dokumen yang berisi nilai gabungan. Dalam contoh ini, jumlah acara per menit.
Kategorisasi_field_name menunjukkan nama nilai bidang dari dokumen, yang berisi beberapa jenis nilai variabel. Dengan mask pada bidang ini, Anda dapat memecah data yang dianalisis menjadi himpunan bagian. Perhatikan tombol
Tambahkan detektor pada ilustrasi sebelumnya. Di bawah ini adalah hasil dari mengklik tombol ini.

Berikut ini adalah blok pengaturan tambahan untuk mengatur detektor anomali untuk tugas tertentu. Kami berencana untuk menganalisis kasus penggunaan khusus (terutama untuk keamanan) di artikel berikut. Sebagai contoh,
lihat salah satu kasing yang dibongkar. Ini dikaitkan dengan pencarian nilai-nilai yang jarang muncul dan diimplementasikan
oleh fungsi langka .
Di bidang
fungsi , Anda dapat memilih fungsi tertentu untuk mencari anomali. Selain
langka , ada beberapa fungsi menarik -
time_of_day dan time_of_week . Mereka mengidentifikasi anomali dalam perilaku metrik sepanjang hari atau minggu, masing-masing. Fungsi analisis lainnya
ada di dokumentasi .
Field_name menunjukkan bidang dokumen yang akan dianalisis.
By_field_name dapat digunakan untuk memisahkan hasil analisis untuk setiap nilai individu dari bidang dokumen yang ditentukan di sini. Jika Anda mengisi
over_field_name Anda mendapatkan analisis populasi, yang kami periksa di atas. Jika Anda menentukan nilai di
partition_field_name , maka pada bidang dokumen ini, setiap baseline untuk setiap nilai akan dihitung (misalnya, nama server atau proses di server dapat memainkan peran nilai). Dalam
exclude_frequent, Anda dapat memilih
semua atau
tidak sama sekali , yang berarti pengecualian (atau penyertaan) dari nilai-nilai bidang dokumen yang sering dijumpai.
Dalam artikel yang kami coba berikan ide paling ringkas tentang kemungkinan pembelajaran mesin di Elastic Stack, masih ada banyak detail di balik layar. Beri tahu kami di komentar kasus mana yang berhasil Anda selesaikan dengan bantuan Elastic Stack dan untuk tugas apa Anda menggunakannya. Untuk menghubungi kami, Anda dapat menggunakan pesan pribadi di Habré atau
formulir umpan balik di situs .