Saya membawa perhatian Anda pada terjemahan laporan Alexander Kuzmenko (sejak April tahun ini ia secara resmi bekerja sebagai pengembang kompiler Haxe) tentang perubahan dalam bahasa Haxe yang telah terjadi sejak rilis Haxe 3.4.

Lebih dari dua setengah tahun telah berlalu sejak rilis Haxe 3.4. Selama waktu ini, 7 rilis patch, 5 rilis preview Haxe 4 dan 2 kandidat rilis Haxe 4. dirilis. Ini masih jauh dari versi baru dan hampir siap ( sekitar 20 masalah masih harus diselesaikan).

Alexander berterima kasih kepada komunitas Haxe karena melaporkan bug, atas keinginan mereka untuk berpartisipasi dalam pengembangan bahasa. Berkat proyek evolusi haxe , hal-hal seperti Haxe 4 akan muncul dengan:
- markup inline
- fungsi inlining di lokasi panggilan
- fungsi panah

Juga, dalam kerangka kerja proyek ini, diskusi sedang diadakan tentang inovasi yang mungkin terjadi seperti: Janji , ini polimorfik, dan tipe standar (parameter tipe default).
Selanjutnya, Alexander berbicara tentang perubahan dalam sintaksis bahasa .

Yang pertama adalah sintaks baru untuk menggambarkan sintaks tipe fungsi. Sintaksis lama agak aneh.
Haxe adalah bahasa pemrograman multi-paradigma, ia selalu memiliki dukungan untuk fungsi kelas satu, tetapi sintaks untuk menggambarkan tipe fungsi diwarisi dari bahasa fungsional (dan berbeda dari yang diadopsi dalam paradigma lain). Dan programmer yang akrab dengan pemrograman fungsional mengharapkan fungsi dengan sintaks ini untuk mendukung currying otomatis. Tetapi di Haxe hal ini tidak terjadi.
Kelemahan utama dari sintaksis lama, menurut Alexander, adalah ketidakmampuan untuk menentukan nama-nama argumen, itulah sebabnya Anda harus menulis komentar anotasi panjang dengan deskripsi argumen.
Tapi sekarang kami memiliki sintaks baru untuk menggambarkan tipe fungsi (yang, omong-omong, ditambahkan ke bahasa sebagai bagian dari inisiatif haxe-evolution), di mana ada kesempatan seperti itu (meskipun ini opsional, tetapi disarankan). Sintaks baru lebih mudah dibaca dan bahkan dapat dianggap sebagai bagian dari dokumentasi untuk kode.
Kelemahan lain dari sintaks lama untuk menggambarkan tipe fungsi adalah inkonsistensi - kebutuhan untuk menentukan tipe argumen fungsi bahkan ketika fungsi tidak menerima argumen: Void->Void (fungsi ini tidak mengambil argumen dan tidak mengembalikan apa-apa).
Dalam sintaks baru, ini diterapkan lebih elegan: ()->Void

Yang kedua adalah fungsi panah atau ekspresi lambda - bentuk singkat untuk menggambarkan fungsi anonim. Komunitas telah lama meminta untuk menambahkannya ke bahasa, dan akhirnya itu terjadi!
Dalam fungsi tersebut, alih-alih kata kunci return , urutan karakter -> (maka nama sintaksnya adalah "fungsi panah").
Dalam sintaks baru, masih dimungkinkan untuk mengatur tipe argumen (karena sistem inferensi tipe otomatis tidak selalu dapat melakukan seperti yang diinginkan programmer, misalnya, kompiler dapat memutuskan untuk menggunakan Float daripada Int ).
Satu-satunya batasan sintaks baru adalah ketidakmampuan untuk secara eksplisit mengatur tipe pengembalian. Jika perlu, maka Anda memiliki pilihan untuk menggunakan sintaks lama atau menggunakan sintaks tipe-centang di badan fungsi, yang akan memberi tahu kompilator jenis pengembalian.

Fungsi panah tidak memiliki representasi khusus di pohon sintaksis, mereka diproses dengan cara yang sama seperti fungsi anonim biasa. Urutan -> diganti oleh kata kunci return .

Perubahan ketiga - final sekarang final menjadi kata kunci (di Haxe 3 final adalah salah satu dari meta tag yang ada di kompiler).
Jika Anda menerapkannya ke kelas, itu akan melarang warisan darinya, hal yang sama berlaku untuk antarmuka. Menerapkan kualifikasi final untuk metode kelas akan mencegahnya ditimpa di kelas anak-anak.
Namun, di Haxe, ada cara untuk mengatasi pembatasan yang diberlakukan oleh kata kunci final - Anda dapat menggunakan tag meta @:hack untuk ini (tetapi Anda hanya harus melakukan ini jika benar-benar diperlukan).
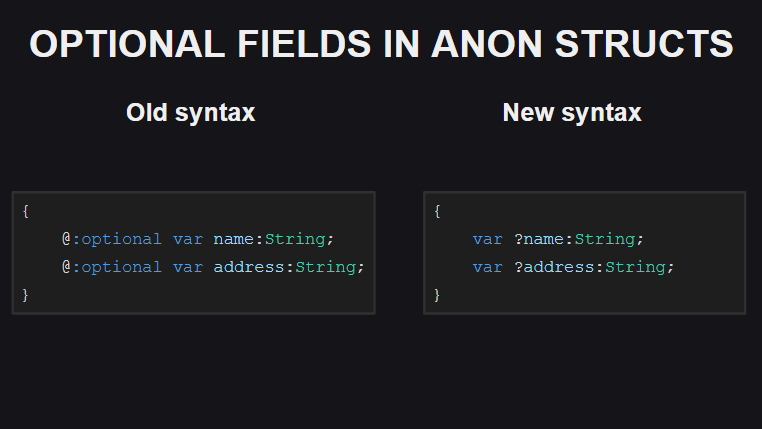
Perubahan keempat adalah cara untuk mendeklarasikan bidang opsional dalam struktur anonim. Sebelumnya, tag meta @:optional digunakan untuk ini, sekarang tambahkan saja tanda tanya di depan nama bidang.

Kelima, enumerasi abstrak telah menjadi anggota penuh dari keluarga tipe Haxe, dan alih-alih tag meta @:enum kata kunci @:enum sekarang digunakan untuk mendeklarasikannya.
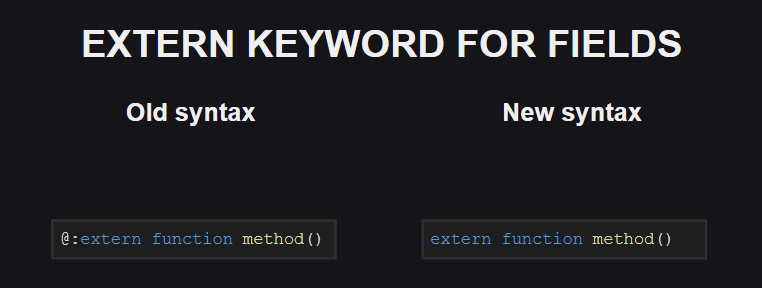
Perubahan serupa memengaruhi tag meta @:extern .

Ketujuh adalah sintaks persimpangan tipe baru yang lebih baik mencerminkan esensi dari struktur yang meluas.
Sintaks baru yang sama digunakan untuk membatasi batasan parameter tipe, lebih akurat menyampaikan batasan yang dikenakan pada suatu jenis. Untuk seseorang yang tidak terbiasa dengan Haxe, sintaksis lama MyClass<T:(Type1, Type2)> dapat dianggap sebagai persyaratan untuk jenis parameter T baik Type1 atau Type2 . Sintaks baru secara eksplisit memberitahu kita bahwa T harus menjadi Type1 dan Type2 bersamaan.
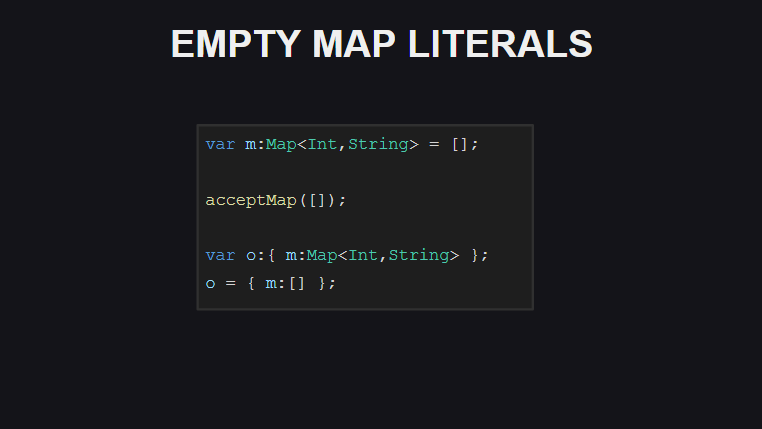
Kedelapan adalah kemampuan untuk menggunakan [] untuk mendeklarasikan wadah Map kosong (namun, jika Anda tidak secara eksplisit menentukan jenis variabel, kompiler akan menampilkan jenis sebagai array untuk kasus ini).
Setelah berbicara tentang perubahan dalam sintaksis, mari kita beralih ke deskripsi fungsi baru dalam bahasa .
Mari kita mulai dengan iterator nilai kunci yang baru
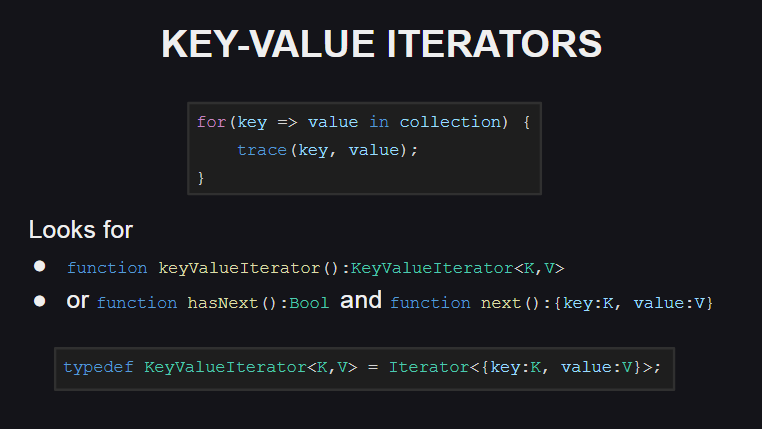
Sintaks baru telah ditambahkan untuk penggunaannya.
Untuk mendukung iterator tersebut, tipe harus mengimplementasikan metode keyValueIterator():KeyValueIterator<K, V> , atau metode hasNext():Bool dan next():{key:K, value:V} . Pada saat yang sama, tipe KeyValueIterator<K, V> adalah sinonim untuk iterator reguler dalam struktur anonim Iterator<{key:K, value:V}> .
Iterator nilai kunci diimplementasikan untuk beberapa jenis dari pustaka standar Haxe ( String , Map , DynamicAccess ), dan pekerjaan juga sedang berlangsung untuk mengimplementasikannya untuk array.
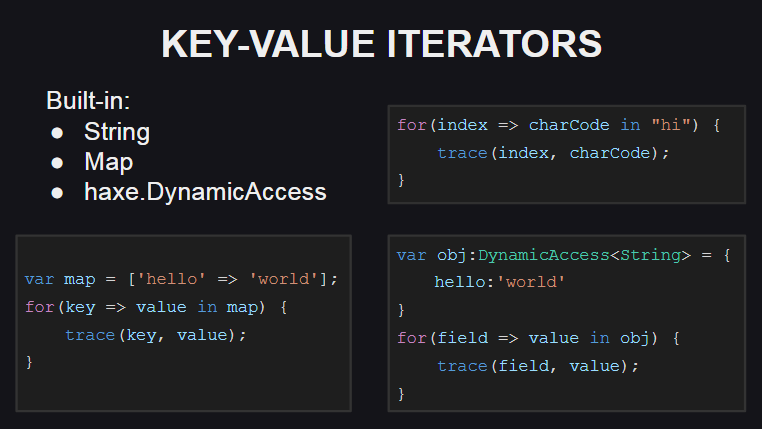
Untuk string, indeks karakter dalam string digunakan sebagai kunci, dan kode karakter pada indeks yang diberikan digunakan sebagai nilai (jika karakter itu sendiri diperlukan, maka metode String.fromCharCode() dapat digunakan).
Untuk wadah Map , iterator baru bekerja sama dengan metode iterasi lama, yaitu, menerima array kunci dalam wadah dan melewatinya, meminta nilai untuk masing-masing kunci.
Untuk DynamicAccess (pembungkus untuk objek anonim), iterator bekerja menggunakan refleksi (untuk mendapatkan daftar bidang objek menggunakan metode Reflect.fields() dan untuk mendapatkan nilai bidang dengan namanya menggunakan metode Reflect.field() ).

Haxe 4 menggunakan penerjemah makro yang sepenuhnya baru, "eval". Simon Krajewski, penulis penerjemah, menggambarkannya secara terperinci di blog resmi Haxe , dan juga dalam laporan perkembangannya tahun lalu .
Perubahan utama dalam pekerjaan juru bahasa:
- beberapa kali lebih cepat dari penerjemah makro yang lama (rata-rata 4 kali)
- mendukung debugging interaktif (sebelumnya, untuk makro, hanya output konsol yang dapat digunakan)
- digunakan untuk menjalankan compiler dalam mode interpreter (sebelumnya neko digunakan untuk ini. Omong-omong, eval juga melampaui neko dalam kecepatan).

Dukungan Unicode untuk semua platform (dengan pengecualian neko) adalah salah satu perubahan terbesar dalam Haxe 4. Simon membicarakan hal ini secara rinci tahun lalu . Tapi di sini adalah gambaran singkat dari keadaan saat ini dukungan string Unicode di Haxe:
- untuk dukungan unicode penuh Lua, PHP, Python dan eval (penerjemah makro) diimplementasikan (pengkodean UTF8)
- untuk platform lain (JavaScript, C #, Java, Flash, HashLink dan C ++), digunakan pengkodean UTF16.
Dengan demikian, garis-garis di Haxe bekerja dengan cara yang sama untuk karakter yang termasuk dalam bidang multibahasa utama , tetapi untuk karakter di luar bidang ini (misalnya, untuk emoji), kode untuk bekerja dengan garis dapat menghasilkan hasil yang berbeda tergantung pada platform (tetapi ini masih lebih baik, daripada situasi yang kita miliki di Haxe 3, ketika setiap platform memiliki perilaku sendiri).

Untuk string Unicode-encoded (baik dalam UTF8 dan UTF16), iterator khusus telah ditambahkan ke perpustakaan standar Haxe yang bekerja sama pada SEMUA platform untuk semua karakter (baik dalam bidang multibahasa utama dan seterusnya):
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

Karena kenyataan bahwa penerapan string bervariasi dari platform ke platform, perlu diingat beberapa nuansa pekerjaan mereka. Di UTF16, setiap karakter membutuhkan 2 byte, jadi mengakses karakter dalam string dengan indeks cepat, tetapi hanya di dalam bidang multibahasa utama. Di sisi lain, di UTF8 semua karakter didukung, tetapi ini dicapai dengan mengorbankan pencarian lambat untuk karakter dalam string (karena karakter dapat menempati jumlah byte yang berbeda dalam memori, mengakses karakter berdasarkan indeks memerlukan pengulangan melalui garis setiap kali dari awal). Oleh karena itu, ketika bekerja dengan string besar dalam Lua dan PHP, Anda harus ingat bahwa akses ke karakter sewenang-wenang bekerja cukup lambat (juga pada platform ini, panjang string dihitung lagi setiap kali).
Namun, meskipun dukungan Unicode penuh dinyatakan untuk Python, pembatasan ini tidak berlaku untuk itu karena garis-garis di dalamnya diimplementasikan dalam cara yang sedikit berbeda: untuk karakter dalam bidang multibahasa utama, itu menggunakan pengkodean UTF16, dan untuk karakter yang lebih luas (3 dan lebih banyak byte) Python menggunakan UTF32.
Optimalisasi tambahan diterapkan untuk penerjemah makro eval: string "tahu" apakah itu berisi karakter Unicode. Jika tidak mengandung karakter seperti itu, string diinterpretasikan sebagai terdiri dari karakter ASCII (di mana setiap karakter membutuhkan 1 byte). Akses berurutan menurut indeks dalam eval juga dioptimalkan: posisi karakter terakhir yang diakses di-cache dalam baris. Jadi jika Anda pertama kali beralih ke karakter ke-10 dalam string, maka ketika Anda selanjutnya beralih ke karakter ke-20, eval akan mencarinya bukan dari awal baris, tetapi mulai dari 10. Selain itu, panjang string dalam eval di-cache, yaitu, itu dihitung hanya pada permintaan pertama.
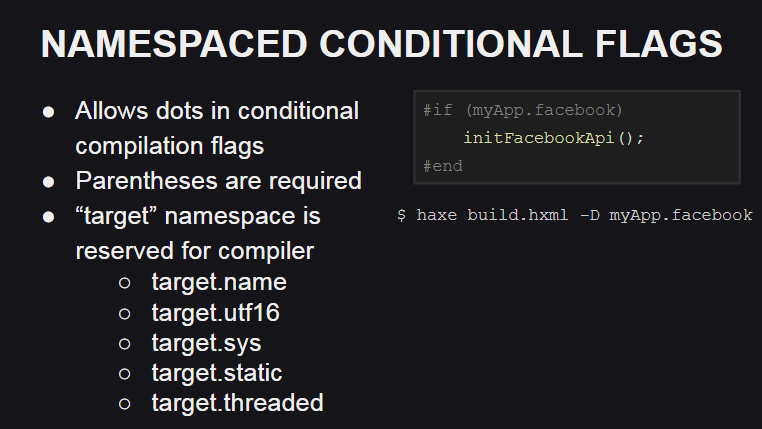
Haxe 4 memperkenalkan dukungan untuk ruang nama untuk flag kompilasi, yang dapat berguna, misalnya, untuk mengatur kode saat menulis pustaka kustom.
Juga, namespace yang disediakan untuk bendera kompilasi muncul - target , yang digunakan oleh kompiler untuk menggambarkan platform target dan perilakunya:
target.name - nama platform (js, cpp, php, dll.)target.utf16 - mengatakan bahwa dukungan Unicode diimplementasikan menggunakan UTF16target.sys - menunjukkan apakah kelas dari paket sys tersedia (misalnya, untuk bekerja dengan sistem file)target.static - menunjukkan apakah platform statis (pada platform statis, tipe dasar Int , Float dan Bool tidak boleh memiliki null sebagai nilainya)target.threaded - menunjukkan apakah platform mendukung multithreading
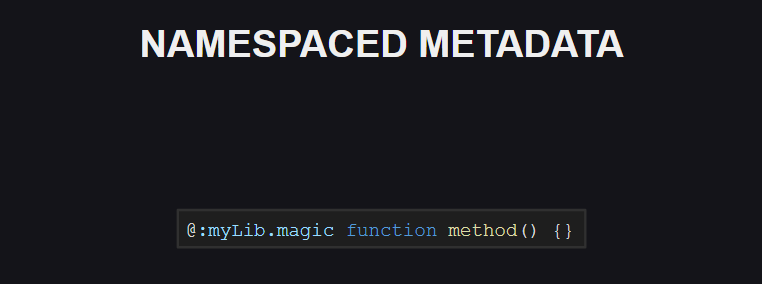
Demikian pula, dukungan namespace untuk tag meta telah muncul. Sejauh ini tidak ada ruang nama yang dicadangkan untuk tag meta dalam bahasa, tetapi situasinya mungkin berubah di masa mendatang.

Tipe ReadOnlyArray ditambahkan ke pustaka standar Haxe - abstraksi atas array biasa, di mana metode hanya tersedia untuk membaca data dari array.

Inovasi lain dalam bahasa ini adalah bidang terakhir dan variabel lokal.
Jika final digunakan sebagai pengganti kata kunci var ketika mendeklarasikan bidang kelas atau variabel lokal, ini berarti bahwa bidang atau variabel ini tidak dapat dipindahkan (kompiler akan memberikan kesalahan ketika mencoba melakukan ini). Tetapi pada saat yang sama, keadaannya dapat diubah, sehingga bidang terakhir atau variabel tidak konstan.
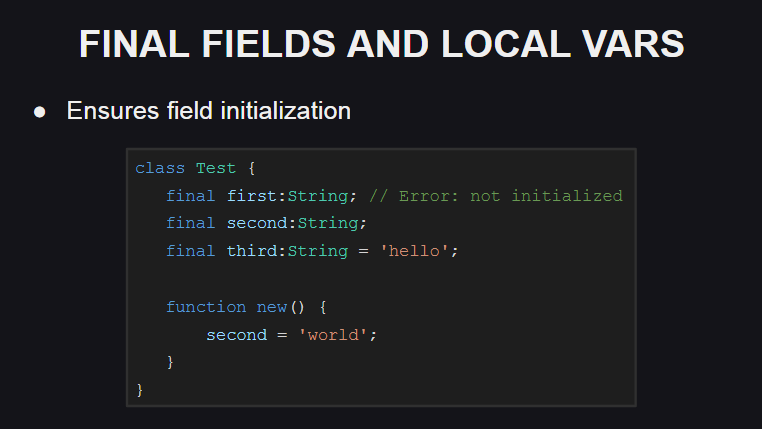
Nilai-nilai dari bidang terakhir harus diinisialisasi ketika mereka dideklarasikan, atau dalam konstruktor, jika tidak, kompiler akan melempar kesalahan.

HashLink adalah platform baru dengan mesin virtualnya sendiri, dibuat khusus untuk Haxe. HashLink mendukung apa yang disebut "kompilasi ganda" - kode dapat dikompilasi baik dalam bytecode (yang sangat cepat, mempercepat proses debugging aplikasi yang dikembangkan), atau dalam C-code (yang ditandai dengan peningkatan kinerja). Nicholas mendedikasikan HashLink untuk beberapa posting blog Haxe dan juga membicarakannya di konferensi Seattle tahun lalu . Teknologi HashLink digunakan dalam gim populer seperti Dead Cells dan Northgard.

Fitur baru yang menarik dari Haxe 4 adalah keamanan Null, yang masih dalam tahap percobaan (karena positif palsu dan tidak cukupnya pemeriksaan keamanan kode).
Apa itu keamanan nol? Jika fungsi Anda tidak secara eksplisit menyatakan bahwa ia dapat menerima null sebagai nilai parameter, maka ketika Anda mencoba untuk meneruskannya, kompiler akan melempar kesalahan yang sesuai. Selain itu, untuk parameter fungsi yang dapat mengambil null sebagai nilai, kompiler akan meminta Anda untuk menulis kode tambahan untuk memverifikasi dan menangani kasus-kasus tersebut.
Fungsionalitas ini dinonaktifkan secara default, tetapi tidak memengaruhi kecepatan eksekusi kode (jika Anda mengaktifkannya), karena pemeriksaan yang dijelaskan hanya dilakukan pada tahap kompilasi. Itu dapat diaktifkan untuk semua kode, serta secara bertahap diaktifkan untuk masing-masing bidang, kelas, dan paket (sehingga memberikan transisi bertahap ke kode yang lebih aman). Anda dapat menggunakan meta tag dan makro khusus untuk ini.
Mode-mode di mana Null-security dapat bekerja adalah: Strict (paling ketat), Loose (mode default) dan Off (digunakan untuk menonaktifkan pemeriksaan untuk paket dan tipe individual).

Untuk fungsi yang ditunjukkan pada slide, pemeriksaan keamanan Null diaktifkan. Kita melihat bahwa fungsi ini memiliki parameter opsional s , yaitu, kita dapat memasukkan null ke dalamnya sebagai nilai parameter. Saat mencoba mengkompilasi kode dengan fungsi seperti itu, kompiler akan menghasilkan sejumlah kesalahan:
- ketika mencoba mengakses beberapa bidang objek
s (karena mungkin null ) - ketika mencoba untuk menetapkan str variabel, yang, seperti yang kita lihat, tidak boleh
null (kalau tidak kita seharusnya menyatakan itu bukan sebagai String , tetapi sebagai Null<String> ) - ketika mencoba mengembalikan objek
s dari suatu fungsi (karena fungsi seharusnya tidak mengembalikan null )
Bagaimana cara memperbaiki kesalahan ini?
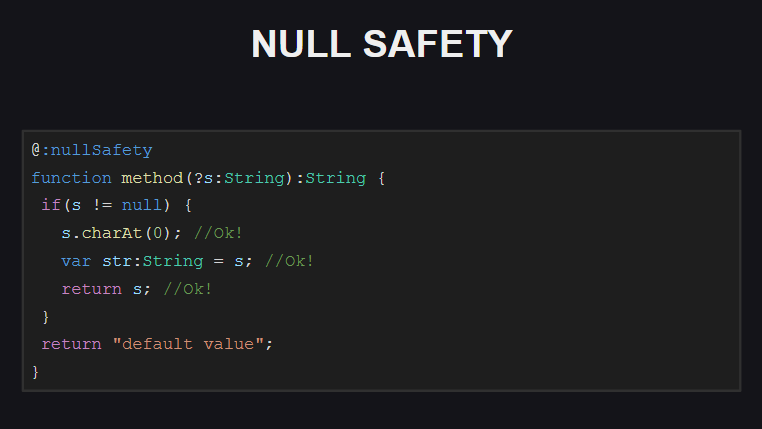
Kita hanya perlu menambahkan pemeriksaan null ke kode (di dalam blok dengan pemeriksaan null , kompiler "tahu" bahwa s tidak dapat null dan dapat digunakan dengan aman dengannya), dan juga memastikan bahwa fungsi tersebut tidak mengembalikan null !

Selain itu, ketika melakukan pemeriksaan untuk keamanan Null, kompiler memperhitungkan urutan di mana program dijalankan. Sebagai contoh, jika setelah memeriksa nilai parameter s ke null untuk menghentikan fungsi (atau melempar pengecualian), kompiler akan "tahu" bahwa setelah pemeriksaan seperti itu, parameter s tidak bisa lagi menjadi null , dan dapat digunakan dengan aman.

Jika kompiler mengaktifkan mode pemeriksaan ketat untuk keamanan Null, itu akan memerlukan pemeriksaan tambahan untuk null dalam kasus di mana antara pemeriksaan awal dari nilai untuk null dan upaya untuk mengakses bidang objek kode apa pun yang dieksekusi kode yang dapat mengaturnya ke null .
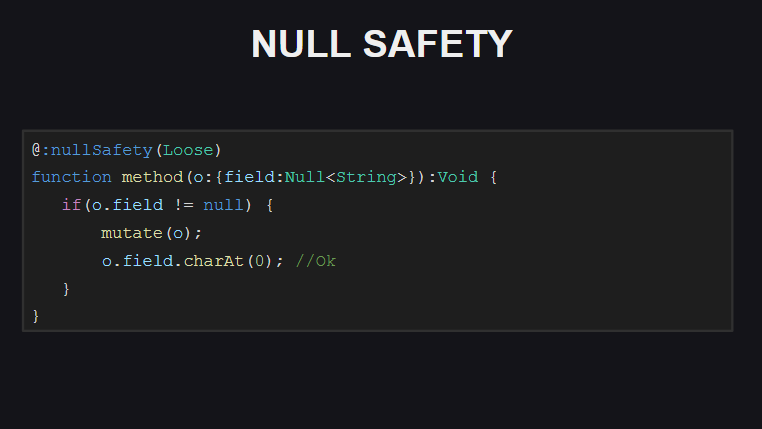
Dalam mode Loose (digunakan secara default), kompiler tidak akan memerlukan pemeriksaan seperti itu (omong-omong, perilaku ini juga digunakan secara default dalam TypeScript).

Juga, ketika pemeriksaan untuk keamanan Null dihidupkan, kompiler memeriksa apakah bidang di kelas diinisialisasi (langsung ketika mereka dinyatakan atau dalam konstruktor). Jika tidak, kompiler akan melempar kesalahan ketika mencoba untuk melewatkan objek dari kelas seperti itu, serta ketika mencoba memanggil metode pada objek tersebut, sampai semua bidang objek diinisialisasi. Pemeriksaan tersebut dapat dimatikan untuk masing-masing bidang kelas dengan menandai mereka dengan tag meta @:nullSafety(Off)
Alexander berbicara lebih banyak tentang keamanan Null di Haxe Oktober lalu .

Haxe 4 memperkenalkan kemampuan untuk menghasilkan kelas ES6 untuk JavaScript, ini diaktifkan menggunakan flag kompilasi js-es=6 .
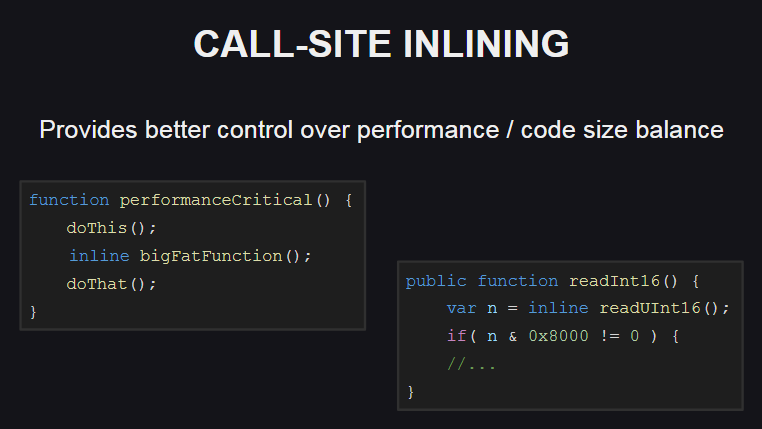
Menanamkan fungsi di tempat panggilan (panggilan-situs inlining) menyediakan lebih banyak opsi untuk mengontrol keseimbangan antara kinerja kode dan ukuran. Fungsi ini juga digunakan di perpustakaan standar Haxe.
Seperti apa dia? Ini memungkinkan Anda untuk menyematkan badan fungsi (menggunakan inline ) hanya di tempat-tempat di mana ia diperlukan untuk memastikan kinerja tinggi (misalnya, jika perlu, memanggil metode yang cukup produktif dalam loop), sementara di tempat lain badan fungsi tidak tertanam. Akibatnya, ukuran kode yang dihasilkan akan sedikit meningkat.
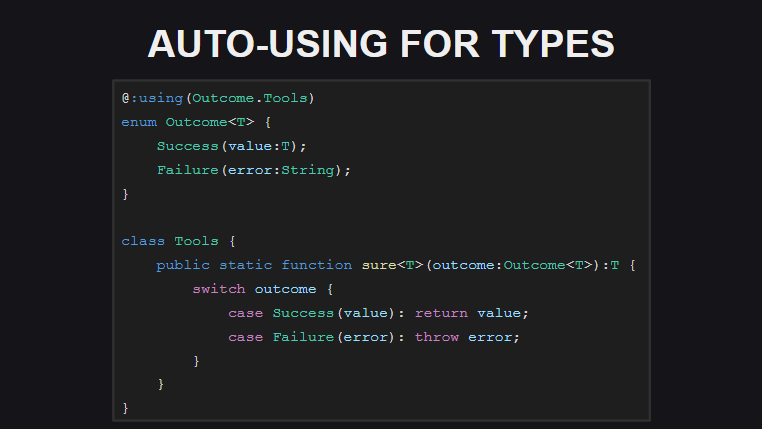
Penggunaan otomatis (ekstensi otomatis untuk tipe) berarti sekarang untuk tipe Anda dapat mendeklarasikan ekstensi statis di tempat deklarasi tipe. Ini menghilangkan kebutuhan untuk using type; konstruk using type; setiap kali using type; di setiap modul di mana jenis dan metode ekstensi digunakan. Saat ini, ekstensi jenis ini hanya diterapkan untuk transfer, tetapi pada rilis final (dan pada build malam) dapat digunakan tidak hanya untuk transfer.

Dalam Haxe 4, dimungkinkan untuk mendefinisikan ulang operator untuk mengakses bidang objek untuk tipe abstrak (hanya untuk bidang yang tidak ada dalam tipe). Untuk melakukan ini, gunakan metode yang ditandai dengan tag meta @:op(ab) .

Markup bawaan adalah fitur eksperimental lain di Haxe. Kode markup bawaan tidak diproses oleh kompiler sebagai dokumen xml - kompilator melihatnya sebagai string yang dibungkus dengan tag meta @:markup . .
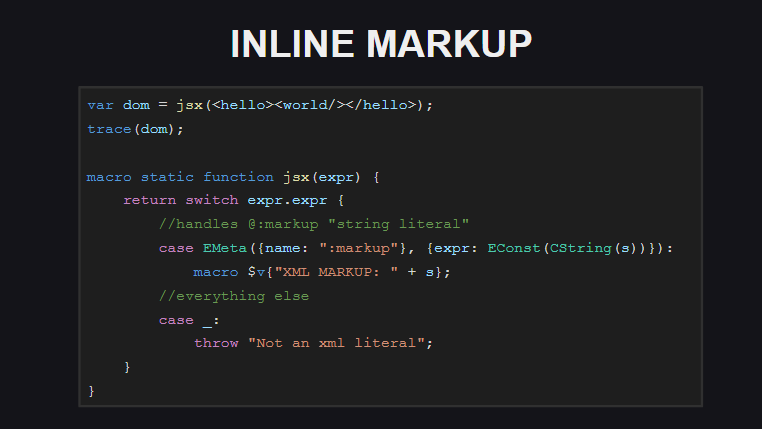
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
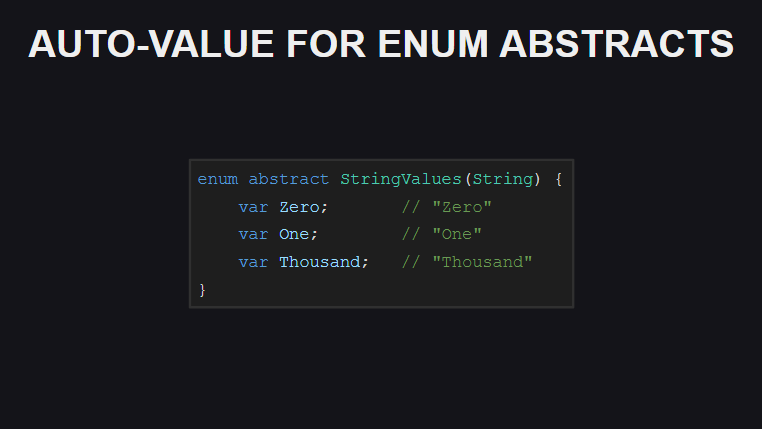
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !