
Mesin pencari tidak memiliki banyak logika, ini fakta. Tetapi mereka berusaha. Dan spesialis SEO sedang mencoba dalam menanggapi - mereka berusaha untuk mencapai relevansi maksimum dari halaman, berdasarkan dugaan dan eksperimen.
Google baru-baru ini senang dengan faktor peringkat baru - Pencocokan Saraf. Kami membaca bahwa para ahli menulis tentang ini, dan mengumpulkan beberapa trik yang akan membantu Anda menulis lebih banyak teks yang relevan untuk permintaan.
Omong-omong, NM bukan LSI untuk Anda, itu sedikit lebih rumit.
Pada bulan September 2018, Danny Sullivan tweeted bahwa dalam beberapa bulan terakhir, Google telah menggunakan metode AI Neural Matching untuk lebih mengaitkan kata dengan konsep. Algoritma ini memengaruhi hasil 30% permintaan di seluruh dunia.

Kami tidak terburu-buru untuk menulis tentang algoritma baru, kami sedang menunggu klarifikasi dari Google dan penelitian di bidang ini. Tetapi semuanya masih ada - kebanyakan komentator menunjukkan tangkapan layar yang sama dan berbicara tentang transisi dari pencarian dengan kata-kata menjadi pencarian dengan niat. Mereka juga merujuk ke Deep Relevance Matching Model (DRMM) .
Mari kita coba mencari tahu hewan seperti apa Pencocokan Saraf ini dan bagaimana menyesuaikan konten di situs untuk itu.
Contoh Pencocokan Saraf
Danny Sullivan menguraikan apa itu Neural Matching. Dia memberi contoh mengeluarkan pertanyaan "mengapa TV saya terlihat aneh". Pengguna memasukkan pertanyaan seperti itu ketika dia belum tahu apa efek opera sabun itu. Tetapi Google, berkat algoritma baru, tahu persis apa yang Anda butuhkan:

Di Rusia, cerita serupa:

Contoh lain. Anda bertemu serangga "cantik" di apartemen dan tidak tahu apa namanya:

Kami pergi ke Google, memasukkan serangkaian fitur dan di posisi pertama kami mendapatkan jawaban yang relevan:

Implementasi Neural Matching disebabkan oleh fakta bahwa pengguna tidak selalu tahu apa yang mereka cari dan tidak selalu merumuskan permintaan dengan benar. Danny Sullivan menunjukkan beberapa pertanyaan "salah" seperti itu:

Tugas Neural Matching adalah untuk menentukan maksud pencarian yang sebenarnya (niat) dan menghasilkan hasil yang benar.

Untuk menentukan niat, tidak digunakan kata-kata yang terpisah, tetapi esensi dan hubungan di antara mereka. Lihat cara kerjanya - pada contoh pertanyaan "mabuk apa yang harus dilakukan" dan "mabuk pada malam hari".
Setiap permintaan mengandung entitas yang sama - "mabuk". Tetapi menggabungkannya dengan esensi "semalam" memberi sinyal pada mesin pencari bahwa pengguna berarti makan berlebihan. Dan esensi "apa yang harus dilakukan" kemungkinan besar terkait dengan keracunan.

Bagaimana cara Google mendefinisikan niat - apakah semantik serupa? Mesin pencari membandingkan seberapa sering entitas yang digabungkan dalam permintaan ditemukan berdampingan pada halaman. Selain itu, statistik tentang permintaan diperhitungkan (pengguna saat memasukkan permintaan "mabuk pada malam hari" lebih sering mengklik artikel khusus tentang makan berlebihan).
Contoh lain. Pengguna memasukkan frasa "put windows." Ini hanya permintaan "salah" yang dibicarakan oleh Danny Sullivan. Google memahami bahwa seseorang dengan "menempatkan" berarti sesuatu selain instalasi sederhana windows, dan menampilkan di TOP hasil yang benar dari sudut pandangnya:
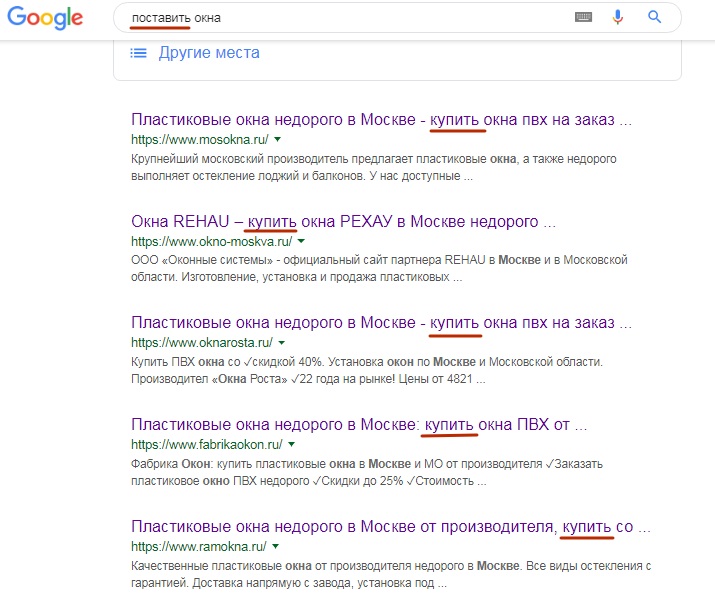
Dalam hal ini, hanya satu halaman dari TOP-6 yang mengandung kata “deliver” (dalam arti “penyedia jendela”, dan bukan “instal windows sendiri”). Di halaman-halaman TOP-6 yang tersisa tidak ada kata "put", atau bahkan kata dasar. Meskipun hasil seperti "Bagaimana cara menginstal windows sendiri", dll, sudah dicampur di bawah ini.
Ini mengarah pada kesimpulan yang tampaknya paradoks: untuk menempati posisi tinggi dalam banyak kata, tidak perlu menjenuhkan teks dengan semantik yang mirip dengan permintaan pencarian. Relevansi konten dievaluasi oleh seperangkat entitas (frasa penanda), yang sangat mungkin untuk memenuhi maksud pencarian.
Ini mengubah pendekatan untuk menulis teks SEO: sebelumnya kuncinya adalah titik rujukan, sekarang yang dibutuhkan khalayak.
Peringkat Relevansi Dokumen dan Pencocokan Neural - Bagaimana ini akan memengaruhi SEO?
Roger Montti menyarankan dalam sebuah artikel untuk Search Engine Journal bahwa algoritma Neural Matching dapat bekerja berdasarkan metode Document Relevance Ranking (DRR). Metode ini dijelaskan dalam artikel " Peringkat Relevansi Mendalam menggunakan Interaksi Kueri Dokumen yang Ditingkatkan " yang diterbitkan di Google AI.
Inti dari metode PRB adalah ketika menentukan relevansi suatu dokumen, teksnya digunakan secara eksklusif. Faktor-faktor lain - tautan, jangkar, sebutan, SEO halaman - tidak masalah.
Apa, tautan tidak lagi dibutuhkan sama sekali? Tidak terlalu seperti itu. Pemeringkatan berdasarkan metode PRB yang dijelaskan adalah bagian dari algoritma pemeringkatan umum. Pada tahap pertama, penerbitan dibentuk dengan mempertimbangkan semua faktor peringkat (tautan, kunci, "mobilitas", geolokasi, dll.). Jadi mesin pencari menghilangkan konten dasar dan mengidentifikasi situs-situs terkemuka. Pada tahap kedua, PRB memasuki pekerjaan - di antara hasil terbaik, ia memilih yang paling relevan (tetapi hanya memperhitungkan teks).
Dalam praktiknya, mungkin terlihat seperti ini. Ada dua situs: yang sangat terkenal dan muda. Situs muda ini berisi konten super yang tidak memiliki analog di ceruk, penuh detail dan spesifik. Tetapi karena ada lebih banyak tautan ke situs resmi, halamannya mengambil posisi pertama, dan halaman situs muda mengambil kesepuluh. Dan di sini PRB mulai beroperasi - mesin pencari memindai teks dan menyadari bahwa konten situs muda lebih bermakna daripada konten yang berwibawa. Konsekuensinya adalah perpindahan situs muda ke posisi yang lebih tinggi.
Bagaimana cara melakukan konten di bawah Pencocokan Saraf
Apakah Neural Matching berfungsi berdasarkan DRR atau tidak, itu tidak penting. Penting bahwa maksud pencarian "drive" di sini. Tidak panjang "footcloths", bukan kepadatan kata kunci, bukan sinonim.

Sebelum membuat konten, putuskan:
- untuk siapa dia (yang terbaik adalah melakukan penelitian, membuat potret pengguna dan menulis untuk mereka);
- mengapa itu dibutuhkan (tugas apa yang ditutupnya);
- apa yang ada di dalamnya yang tidak dimiliki pesaing (nilai apa yang dibawanya).
Untuk meningkatkan relevansi teks, di samping pertanyaan dasar, gunakan entitas yang terkait erat. Jika teks ditulis oleh seorang ahli, maka entitas tersebut kemungkinan besar akan ada dalam teks. Ini masalah lain ketika copywriter diberi TK - dalam hal ini perlu untuk menentukan entitas dan menunjukkannya dalam tugas.
Mari kita pertimbangkan metode pengumpulan entitas menggunakan contoh kategori toko online "Generator Bensin".
1. Cari pertanyaan / jawaban
Anda dapat mengidentifikasi kebutuhan pengguna menggunakan forum, komentar pada artikel blog, dan diskusi di jejaring sosial. Semuanya bekerja. Tetapi lebih mudah untuk pergi ke Answers@Mail.ru (atau mitra barat - Quora ), memasukkan permintaan pencarian, menelusuri pertanyaan dan menyoroti entitas yang terkait dengan kunci utama.
Atas permintaan "generator bensin" mail.ru mengeluarkan 1624 pertanyaan. Kami menelusuri daftar dan memilih entitas yang menjadi ciri kebutuhan audiens target.


Setelah memilih entitas, kami pikir konten apa yang cocok untuk mereka. Misalnya, konsumsi bensin per 1 jam dan metode penggunaan generator (untuk pengelasan, untuk boiler, untuk penerangan, dll.) Harus ditunjukkan dalam deskripsi barang tertentu. Dalam uraian rubrik “Generator Bensin”, Anda dapat menjelaskan secara singkat perbedaan perbedaan antara generator bensin dengan gas, inverter, dll. Masalah dengan pengoperasian generator dijelaskan dalam artikel untuk blog.
Memproses pertanyaan dalam layanan QA sungguh melelahkan, tetapi memungkinkan Anda untuk menyoroti kebutuhan nyata audiens, yang mungkin tidak Anda duga.
Anda dapat mencoba menyederhanakan pekerjaan menggunakan Answer The Public service . Ia mengumpulkan pertanyaan, perbandingan, dan berbagai formulasi yang terjadi pada jaringan dengan kemunculan frasa tertentu.

Satu-satunya kelemahan adalah layanan berbahasa Inggris. Terjemahan dari frasa yang diinginkan sebagian memecahkan masalah. Tetapi dalam segmen komersial, perlu diingat tentang kekhasan pasar (yang dikhawatirkan orang India mungkin tidak berguna bagi Rusia).
2. Mengurai frase asosiasi
Di bawah hasil pencarian, blok "Bersama dengan ... sering dicari" ditampilkan - frasa yang dikaitkan mesin pencari itu dengan frasa asli ("generator bensin") dikumpulkan di sini.

Analisis frase asosiasi memungkinkan Anda untuk mengidentifikasi entitas terkait: 5 kW, 3 kW, 10 kW, inverter, 1 kW.
Masih memikirkan bagaimana memasukkan mereka ke dalam konten. Misalnya, dalam uraian kolom “generator yang digerakkan bensin”, patut diceritakan untuk keperluan apa generator dengan daya berbeda (1, 3, 5, 10 kW) dan jenis (inverter, konvensional, dll.) Cocok.
Jika Anda memiliki banyak permintaan awal, kumpulkan asosiasi secara manual untuk waktu yang lama - gunakan pengurai .
3. Memilah petunjuk pencarian
Petunjuk adalah sumber lain untuk mencocokkan entitas terkait.

Kami mengisi kembali daftar entitas yang dikumpulkan dari asosiasi: dengan autorun, diesel, 380 volt, diam. Ini adalah kata-kata yang menggambarkan masalah pengguna dengan baik.
Ada juga parser untuk mengumpulkan petunjuk.
Pada prinsipnya, metode yang dibahas cukup untuk mendapatkan gambaran tentang kebutuhan audiens. Tetapi jika Anda ingin mempelajari semantik lebih dalam lagi, berikut adalah dua cara opsional.
4. Pemilihan kuasi-sinonim
Sinonim semu (asosiasi semantik) adalah kata-kata yang hampir memiliki makna, tetapi tidak dapat dipertukarkan dalam konteks yang berbeda. Misalnya, kata "generator" dan "generator otomatis" adalah sinonim dalam teks pada suku cadang mobil, tetapi tidak akan seperti itu dalam teks pada jenis generator.
Sinonim semu ditentukan berdasarkan frekuensi kemunculannya dalam teks. Untuk mengatasi masalah ini, ada layanan RusVecto (bagian "Kata-kata yang mirip"). Masukkan kata yang menarik, tandai semua model dan bagian pidato yang tersedia, dan mulai pencarian.

Akibatnya, Anda akan mendapatkan 10 rekan paling signifikan untuk setiap model pencarian. Membabi buta menggunakannya dalam pembentukan TK tidak layak - akan ada banyak "sampah" di sini (parsing asosiasi berdasarkan data dari mesin pencari masih lebih disukai). Meskipun demikian, Anda dapat mengidentifikasi kata-kata yang menarik. Misalnya, kita melihat bahwa kata "generator gas", "inverter", "generator gas", "kontaktor", dll. Dikaitkan dengan kata "generator".
5. Parsing teks pesaing
Untuk mengidentifikasi kebutuhan audiens, metode ini bukan yang terbaik. Pertama, tidak diketahui kapan konten dibuat di situs web pesaing (selama waktu ini, preferensi pencarian dapat berubah). Kedua, tidak ada jaminan bahwa pesaing telah dengan cermat menganalisis masalah audiens dan membuat teks berdasarkan masalah tersebut.
Di sisi lain, jika Anda menggunakan metode ini sebagai alat bantu, maka ada peluang untuk mengidentifikasi entitas yang mungkin Anda lewatkan.
Jadi, kami memasukkan permintaan utama "generator bensin" dalam pencarian, menyalin teks yang relevan dari situs ke TOP-10 dan memilih semantik menggunakan Advego :

Kami melengkapi daftar entitas yang relevan: 4-stroke, darurat, otonom, tidak terputus, untuk pondok musim panas, untuk alam, dll.
Menyatukan semuanya dan mendapatkan TK yang dioptimalkan untuk Pencocokan Saraf.
TK untuk lirik: make Neural Matching, bukan LSI
Setelah entitas yang relevan dikumpulkan, Anda harus menulis teks. Tapi itu tidak cukup hanya dengan menentukan kunci dan daftar sinonim dan kata-kata terkait dalam TOR, seperti yang biasanya dilakukan ketika memesan teks LSI .

Contoh TK untuk teks LSI
Atas dasar TK semacam itu - cukup dengan daftar kata - terkadang teks yang cukup aneh diperoleh.
Praktik umum di antara copywriter adalah menulis teks, dan hanya kemudian memasukkan kata-kata yang diberikan ke dalamnya. Ini lebih mudah, karena Anda tidak perlu mengganggu pemilihan dan penyisipan kata-kata dalam proses penulisan teks. Tetapi penyisipan semacam itu secara surut dapat mematahkan - dan seringkali mematahkan - logika dan gaya teks.
Teks di bawah Neural Matching adalah tentang pengguna dan kebutuhan mereka, bukan tentang kunci dan kata-kata plus. Oleh karena itu, fitur pemasaran murni muncul di TK: deskripsi konsumen dan motifnya. Kunci dan kata-tambah menghilang ke latar belakang - mereka digunakan sebagai penanda, dan bukan sebagai elemen wajib. Tempat mereka ditempati oleh kebutuhan informasi audiens.

Contoh TK dalam Pencocokan Saraf
TK semacam itu memungkinkan penulis untuk memahami dengan jelas untuk siapa teks itu, mengapa, dan dalam keadaan apa teks itu akan dibaca. TK semacam itu tidak hanya mengeja kata-kata yang akan digunakan, tetapi memberikan arahan - apa yang harus ditulis untuk menggunakan kata-kata ini.
Pencocokan Saraf, saat mengoptimalkan halaman untuk pencarian, menggeser penekanan dari murni mekanika SEO ke pemasaran. Bahkan, tren ini telah diamati selama beberapa tahun. Pencocokan Saraf hanya satu langkah lagi menuju pengoptimalan mesin pencari dengan wajah manusia.
Mengoptimalkan konten untuk Pencocokan Saraf membutuhkan waktu dan kerja keras. Jauh lebih mudah untuk memasukkan kunci dari AX ke TK, mengurai kata-kata plus dan mengatakan kepada copywriter: "Menulis untuk orang-orang." Tetapi dengan perkembangan pencarian AI, pendekatan ini akan semakin tidak efektif.