Manajemen klaster yang efisien dan andal pada skala apa pun dengan Tupperware

Hari ini di konferensi Systems @Scale, kami memperkenalkan Tupperware, sistem manajemen kluster kami yang mengatur wadah di jutaan server, tempat hampir semua layanan kami bekerja. Kami pertama kali meluncurkan Tupperware pada tahun 2011, dan sejak itu infrastruktur kami telah berkembang dari 1 pusat data menjadi sebanyak 15 pusat data yang didistribusikan secara geografis . Selama ini Tupperware tidak berdiri diam dan berkembang bersama kami. Kami akan memberi tahu Anda dalam situasi apa Tupperware menyediakan manajemen klaster kelas satu, termasuk dukungan yang mudah untuk layanan stateful, panel kontrol tunggal untuk semua pusat data dan kemampuan untuk mendistribusikan daya antar layanan secara real time. Dan kami akan membagikan pelajaran yang kami pelajari saat infrastruktur kami berkembang.
Tupperware melakukan berbagai tugas. Pengembang aplikasi menggunakannya untuk mengirim dan mengelola aplikasi. Ini mengemas kode dan dependensi aplikasi ke dalam gambar dan mengirimkannya ke server dalam bentuk wadah. Kontainer menyediakan isolasi antara aplikasi pada server yang sama sehingga pengembang sibuk dengan logika aplikasi dan tidak memikirkan cara menemukan server atau mengontrol pembaruan. Tupperware juga memonitor kinerja server, dan jika menemukan kegagalan, ia mentransfer kontainer dari server yang bermasalah.
Insinyur Perencanaan Kapasitas menggunakan Tupperware untuk mendistribusikan kapasitas server ke dalam tim sesuai anggaran dan kendala. Mereka juga menggunakannya untuk meningkatkan pemanfaatan server. Operator pusat data beralih ke Tupperware untuk mendistribusikan kontainer dengan benar di antara pusat data dan menghentikan atau memindahkan kontainer selama perawatan. Karena itu, pemeliharaan server, jaringan, dan peralatan membutuhkan keterlibatan manusia yang minimal.
Arsitektur Tupperware
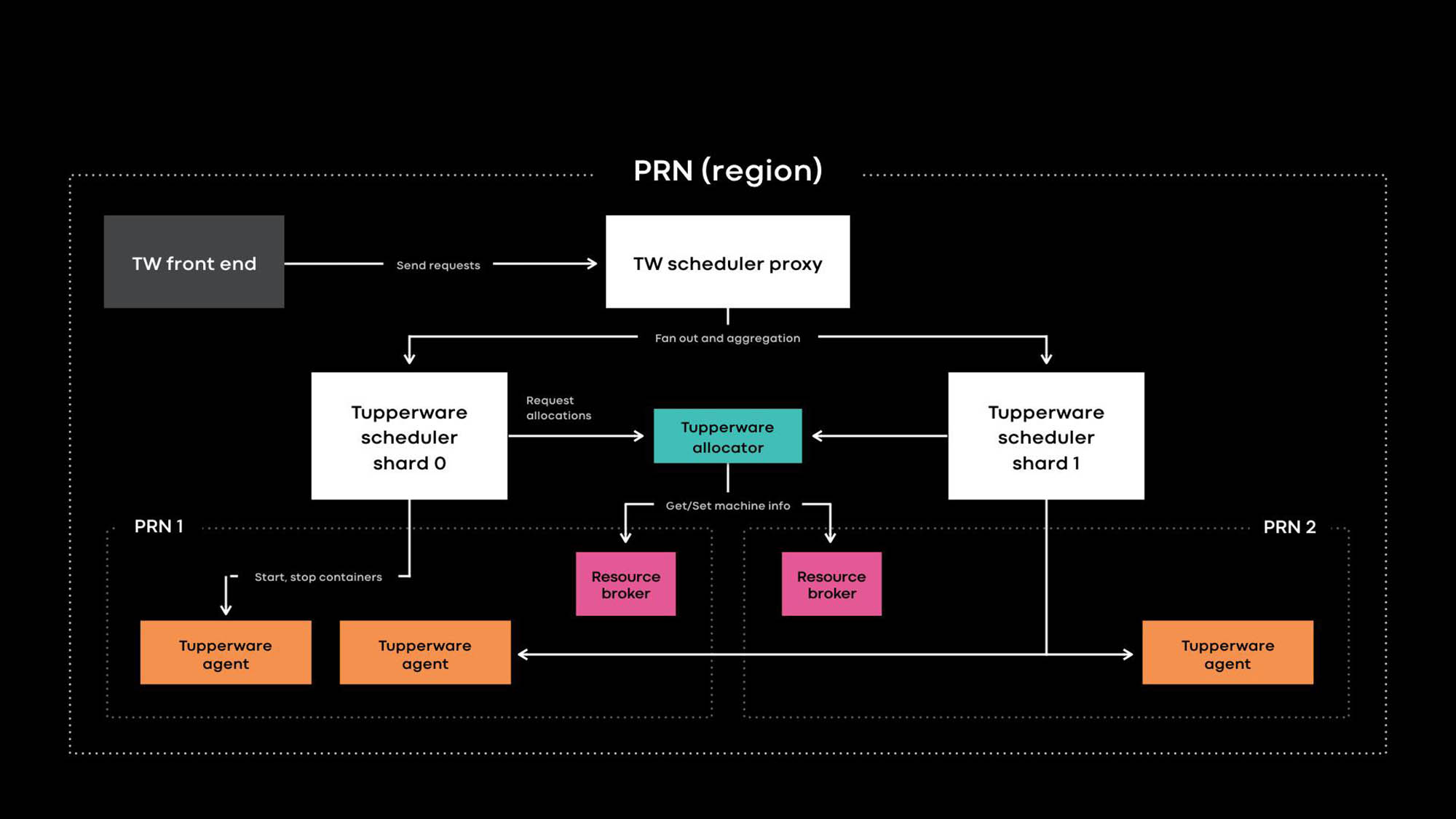
Arsitektur Tupperware PRN adalah salah satu wilayah pusat data kami. Wilayah ini terdiri dari beberapa bangunan pusat data (PRN1 dan PRN2) yang terletak di dekatnya. Kami berencana untuk membuat satu panel kontrol yang akan mengelola semua server di satu wilayah.
Pengembang aplikasi memberikan layanan dalam bentuk pekerjaan Tupperware. Tugas terdiri dari beberapa kontainer, dan semuanya biasanya menjalankan kode aplikasi yang sama.
Tupperware bertanggung jawab atas penyediaan wadah dan manajemen siklus hidup. Ini terdiri dari beberapa komponen:
- Frontend Tupperware menyediakan API untuk antarmuka pengguna, CLI, dan alat otomatisasi lainnya di mana Anda dapat berinteraksi dengan Tupperware. Mereka menyembunyikan seluruh struktur internal dari pemilik pekerjaan Tupperware.
- Penjadwal Tupperware adalah panel kontrol yang bertanggung jawab untuk mengelola wadah dan siklus kehidupan pekerjaan. Ini dikerahkan di tingkat regional dan global, di mana penjadwal regional mengelola server di satu wilayah, dan penjadwal global mengelola server dari berbagai wilayah. Penjadwal dibagi menjadi pecahan, dan setiap pecahan mengontrol satu set tugas.
- Proxy scheduler di Tupperware menyembunyikan sharding internal dan menyediakan panel kontrol terpadu yang nyaman bagi pengguna Tupperware.
- Distributor Tupperware memberikan kontainer ke server. Penjadwal bertanggung jawab untuk menghentikan, memulai, memperbarui, dan gagal wadah. Saat ini, satu distributor dapat mengelola seluruh wilayah tanpa membaginya menjadi pecahan. (Perhatikan perbedaan dalam terminologi. Misalnya, scheduler di Tupperware sesuai dengan panel kontrol di Kubernetes , dan distributor Tupperware disebut scheduler di Kubernetes.)
- Broker sumber daya menyimpan sumber kebenaran untuk acara server dan layanan. Kami menjalankan satu broker sumber daya untuk setiap pusat data, dan menyimpan semua informasi server di pusat data ini. Broker sumber daya dan sistem manajemen kapasitas, atau sistem alokasi sumber daya, secara dinamis memutuskan persediaan penjadwal mana yang mengendalikan server mana. Layanan pemeriksaan kesehatan memonitor server dan menyimpan data tentang kesehatan mereka di broker sumber daya. Jika server memiliki masalah atau perlu pemeliharaan, broker sumber daya memberi tahu distributor dan penjadwal untuk menghentikan kontainer atau mentransfernya ke server lain.
- Tupperware Agent adalah daemon yang berjalan di setiap server yang menyiapkan dan menghapus kontainer. Aplikasi bekerja di dalam wadah, yang memberi mereka lebih banyak isolasi dan reproduktifitas. Pada konferensi Systems @Scale tahun lalu, kami telah menjelaskan bagaimana masing-masing wadah Tupperware dibuat menggunakan gambar, btrfs, cgroupv2, dan systemd.
Fitur khas Tupperware
Tupperware sangat mirip dengan sistem manajemen cluster lainnya, seperti Kubernetes dan Mesos , tetapi ada beberapa perbedaan:
- Dukungan asli untuk layanan stateful.
- Panel kontrol tunggal untuk server di berbagai pusat data untuk mengotomatiskan pengiriman kontainer berdasarkan maksud, dekomisioning kluster, dan pemeliharaan.
- Hapus pemisahan panel kontrol untuk zoom.
- Perhitungan fleksibel memungkinkan Anda untuk mendistribusikan daya antar layanan secara real time.
Kami merancang fitur-fitur keren ini untuk mendukung berbagai aplikasi tanpa status dan stateful di taman server bersama global yang besar.
Dukungan asli untuk layanan stateful.
Tupperware mengelola banyak layanan penting yang menyimpan data produk persisten untuk Facebook, Instagram, Messenger dan WhatsApp. Ini bisa berupa pasangan nilai kunci yang besar (misalnya, ZippyDB ) dan memantau penyimpanan data (misalnya, ODS Gorilla dan Scuba ). Mempertahankan layanan stateful tidak mudah, karena sistem harus memastikan bahwa pengiriman kontainer dapat menahan kegagalan skala besar, termasuk pemadaman listrik atau pemadaman listrik. Meskipun metode konvensional, seperti mendistribusikan kontainer di seluruh domain kegagalan, sangat cocok untuk layanan stateless, layanan stateful membutuhkan dukungan tambahan.
Sebagai contoh, jika sebagai akibat dari kegagalan server satu replika dari database menjadi tidak tersedia, apakah perlu untuk memungkinkan pemeliharaan otomatis yang akan memperbarui kernel pada 50 server dari kumpulan 10 ribu? Itu tergantung situasi. Jika pada salah satu dari 50 server ini terdapat replika lain dari database yang sama, lebih baik menunggu dan tidak kehilangan 2 replika sekaligus. Untuk membuat keputusan dinamis tentang pemeliharaan dan kesehatan sistem, Anda memerlukan informasi tentang replikasi data internal dan logika lokasi setiap layanan stateful.
Antarmuka TaskControl memungkinkan layanan stateful untuk mempengaruhi keputusan yang mempengaruhi ketersediaan data. Menggunakan antarmuka ini, penjadwal memberi tahu aplikasi eksternal dari operasi wadah (restart, perbarui, migrasi, pemeliharaan). Layanan Stateful mengimplementasikan pengontrol yang memberi tahu Tupperware ketika setiap operasi dapat dilakukan dengan aman, dan operasi ini dapat ditukar atau ditunda sementara. Dalam contoh di atas, pengontrol basis data dapat memerintahkan Tupperware untuk memutakhirkan 49 dari 50 server, tetapi sejauh ini tidak menyentuh server tertentu (X). Akibatnya, jika periode pembaruan kernel berlalu, dan database masih tidak dapat mengembalikan replika masalah, Tupperware masih akan meningkatkan server X.

Banyak layanan stateful di Tupperware tidak menggunakan TaskControl secara langsung, tetapi melalui ShardManager, platform umum untuk membuat layanan stateful di Facebook. Dengan Tupperware, pengembang dapat menunjukkan niat mereka tentang bagaimana kontainer harus didistribusikan di seluruh pusat data. Dengan ShardManager, pengembang menunjukkan niat mereka tentang bagaimana seharusnya pecahan data didistribusikan di seluruh wadah. ShardManager menyadari hosting data dan replikasi aplikasi dan berinteraksi dengan Tupperware melalui antarmuka TaskControl untuk merencanakan operasi kontainer tanpa keterlibatan aplikasi langsung. Integrasi ini sangat menyederhanakan pengelolaan layanan stateful, tetapi TaskControl mampu melakukan lebih. Misalnya, tingkat web kami yang luas tidak memiliki kewarganegaraan dan menggunakan TaskControl untuk secara dinamis menyesuaikan kecepatan pembaruan dalam wadah. Akibatnya, tier web dapat dengan cepat menyelesaikan beberapa rilis perangkat lunak per hari tanpa mengurangi ketersediaan.
Manajemen server di pusat data
Ketika Tupperware pertama kali muncul pada 2011, scheduler terpisah mengendalikan setiap server cluster. Kemudian cluster Facebook adalah sekelompok rak server yang terhubung ke satu switch jaringan, dan pusat data berisi beberapa cluster. Penjadwal dapat mengelola server hanya dalam satu cluster, yaitu tugas tidak dapat diperluas ke beberapa cluster. Infrastruktur kami tumbuh, kami semakin menghapus cluster. Karena Tupperware tidak dapat mentransfer tugas dari cluster yang dinonaktifkan ke kluster lain tanpa perubahan, diperlukan banyak upaya dan koordinasi yang cermat antara pengembang aplikasi dan operator pusat data. Proses ini menyebabkan pemborosan sumber daya ketika server menganggur selama berbulan-bulan karena prosedur dekomisioning.
Kami menciptakan broker sumber daya untuk menyelesaikan masalah dekomisioning cluster dan mengoordinasikan jenis tugas pemeliharaan lainnya. Broker sumber daya memantau semua informasi fisik yang terkait dengan server, dan secara dinamis memutuskan penjadwal mana yang mengelola setiap server. Pengikatan dinamis server ke penjadwal memungkinkan penjadwal untuk mengelola server di pusat data yang berbeda. Karena pekerjaan Tupperware tidak lagi terbatas pada satu cluster, pengguna Tupperware dapat menentukan bagaimana kontainer harus didistribusikan di seluruh domain kegagalan. Misalnya, pengembang dapat menyatakan niatnya (misalnya: "jalankan tugas saya di 2 domain gagal di wilayah PRN") tanpa menentukan zona ketersediaan khusus. Tupperware sendiri akan menemukan server yang tepat untuk mewujudkan maksud ini bahkan dalam kasus menonaktifkan cluster atau layanan.
Penskalaan untuk mendukung seluruh sistem global
Secara historis, infrastruktur kami telah dibagi menjadi ratusan kumpulan server khusus untuk masing-masing tim. Karena fragmentasi dan kurangnya standar, kami memiliki biaya transaksi yang tinggi, dan server idle lebih sulit untuk digunakan lagi. Pada konferensi Systems @Scale tahun lalu, kami memperkenalkan Infrastruktur sebagai Layanan (IaaS) , yang harus mengintegrasikan infrastruktur kami ke dalam armada server besar dan terpadu. Tetapi armada server tunggal memiliki kesulitan sendiri. Itu harus memenuhi persyaratan tertentu:
- Skalabilitas. Infrastruktur kami tumbuh dengan penambahan pusat data di setiap wilayah. Server menjadi lebih kecil dan lebih hemat energi, sehingga di setiap wilayah ada lebih banyak. Akibatnya, satu penjadwal untuk suatu wilayah tidak dapat mengatasi jumlah kontainer yang dapat dijalankan pada ratusan ribu server di setiap wilayah.
- Keandalan Bahkan jika skala penjadwal dapat ditingkatkan, karena cakupan yang besar dari penjadwal, risiko kesalahan akan lebih tinggi, dan seluruh wilayah kontainer mungkin menjadi tidak terkelola.
- Toleransi kesalahan. Jika terjadi kegagalan infrastruktur yang besar (misalnya, karena gangguan jaringan atau pemadaman listrik, server tempat penjadwal berjalan akan gagal), hanya sebagian dari server wilayah akan memiliki konsekuensi negatif.
- Kemudahan penggunaan. Tampaknya Anda perlu menjalankan beberapa penjadwal independen di satu wilayah. Namun dalam hal kenyamanan, satu titik masuk ke kolam bersama di wilayah ini menyederhanakan kapasitas dan manajemen pekerjaan.
Kami membagi penjadwal menjadi pecahan untuk memecahkan masalah dengan mendukung kumpulan bersama yang besar. Setiap penjadwal scheduler mengelola serangkaian tugasnya di wilayah tersebut, dan ini mengurangi risiko yang terkait dengan penjadwal. Saat jumlah total bertambah, kita dapat menambahkan lebih banyak pecahan penjadwal. Untuk pengguna Tupperware, pecahan dan penjadwal proksi terlihat seperti satu panel kontrol. Mereka tidak harus bekerja dengan sekelompok pecahan yang mengatur tugas. Pecahan scheduler pada dasarnya berbeda dari penjadwal cluster yang kami gunakan sebelumnya, ketika panel kontrol dibagi tanpa pemisahan statis dari kumpulan server umum sesuai dengan topologi jaringan.
Meningkatkan pemanfaatan dengan komputasi elastis
Semakin besar infrastruktur kami, semakin penting untuk menggunakan server kami secara efisien untuk mengoptimalkan biaya infrastruktur dan mengurangi beban. Ada dua cara untuk meningkatkan pemanfaatan server:
- Komputasi yang fleksibel - mengurangi skala layanan online selama jam-jam tenang dan menggunakan server yang dibebaskan untuk beban offline, misalnya, untuk pembelajaran mesin dan tugas-tugas MapReduce.
- Beban berlebihan - layanan online host dan beban kerja batch pada server yang sama sehingga beban batch dieksekusi dengan prioritas rendah.
Hambatan di pusat data kami adalah konsumsi energi . Oleh karena itu, kami lebih memilih server kecil yang hemat energi yang bersama-sama memberikan daya pemrosesan yang lebih besar. Sayangnya, pada server kecil dengan sejumlah kecil sumber daya prosesor dan memori, pemuatan berlebihan kurang efisien. Tentu saja, kita dapat menempatkan beberapa wadah layanan kecil di satu server kecil hemat energi yang menggunakan sedikit sumber daya prosesor dan memori, tetapi layanan besar akan memiliki kinerja rendah dalam situasi ini. Oleh karena itu, kami menyarankan pengembang layanan besar kami untuk mengoptimalkannya sehingga mereka menggunakan seluruh server.
Pada dasarnya, kami meningkatkan pemanfaatan dengan komputasi elastis. Intensitas penggunaan banyak layanan besar kami, misalnya, umpan berita, fitur pesan, dan level web front-end, tergantung pada waktu hari. Kami sengaja mengurangi skala layanan online selama jam-jam tenang dan menggunakan server yang dibebaskan untuk beban offline, misalnya, untuk pembelajaran mesin dan tugas MapReduce.
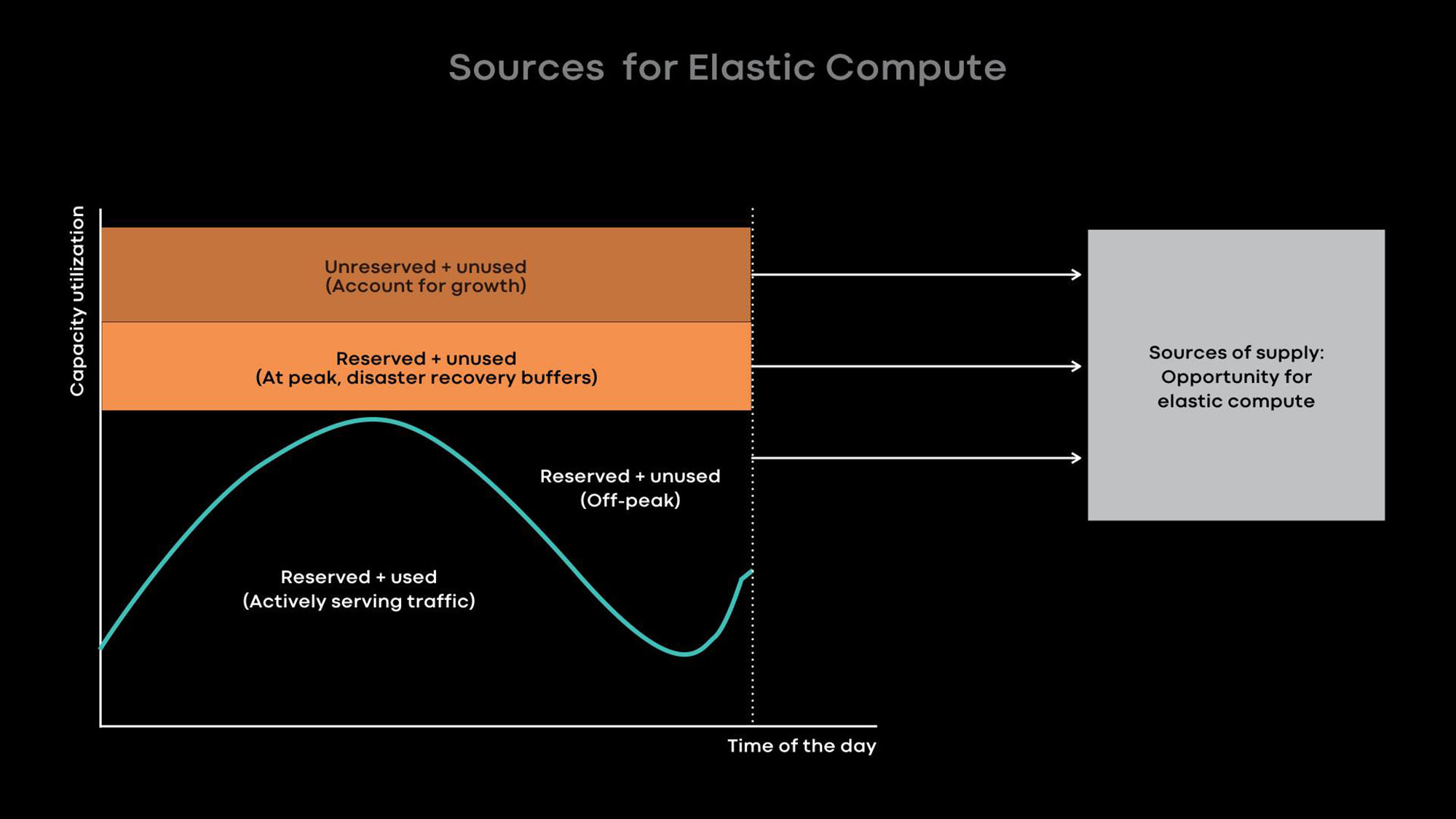
Dari pengalaman, kami tahu bahwa yang terbaik adalah menyediakan seluruh server sebagai unit daya elastis, karena layanan besar adalah donor utama dan konsumen utama daya elastis, dan mereka dioptimalkan untuk penggunaan seluruh server. Ketika server dibebaskan dari layanan online dalam jam-jam tenang, broker sumber daya memberikan server ke penjadwal untuk penggunaan sementara sehingga menjalankan beban offline di atasnya. Jika puncak beban terjadi dalam layanan online, broker sumber daya dengan cepat memanggil kembali server yang dipinjamkan dan, bersama dengan penjadwal, mengembalikannya ke layanan online.
Pelajaran yang Dipetik dan Rencana Mendatang
Selama 8 tahun terakhir, kami telah mengembangkan Tupperware untuk mengimbangi perkembangan pesat Facebook. Kami berbicara tentang apa yang telah kami pelajari dan berharap itu membantu orang lain mengelola infrastruktur yang berkembang pesat:
- Atur komunikasi fleksibel antara panel kontrol dan server yang dikelolanya. Fleksibilitas ini memungkinkan panel kontrol untuk mengelola server di berbagai pusat data, membantu mengotomatiskan dekomisioning dan pemeliharaan cluster, dan menyediakan distribusi daya dinamis menggunakan komputasi fleksibel.
- Dengan panel kontrol tunggal di wilayah ini, menjadi lebih mudah untuk bekerja dengan tugas dan lebih mudah untuk mengelola armada server besar yang umum. Harap dicatat bahwa panel kontrol mendukung satu titik masuk, bahkan jika struktur internalnya dibagi karena alasan skala atau toleransi kesalahan.
- Menggunakan model plug-in, panel kontrol dapat memberi tahu aplikasi eksternal dari operasi kontainer yang akan datang. Selain itu, layanan stateful dapat menggunakan antarmuka plugin untuk mengkonfigurasi manajemen kontainer. Menggunakan model plug-in ini, panel kontrol memberikan kesederhanaan dan secara efektif melayani berbagai layanan stateful.
- Kami percaya bahwa komputasi elastis, di mana kami mengambil seluruh server untuk pekerjaan batch, pembelajaran mesin dan layanan tidak mendesak lainnya dari layanan donor, adalah cara terbaik untuk meningkatkan efisiensi penggunaan server kecil dan hemat energi.
Kami baru mulai menerapkan taman server global tunggal yang umum . Sekarang sekitar 20% dari server kami berada di kolam renang umum. Untuk mencapai 100%, Anda perlu menyelesaikan banyak masalah, termasuk mendukung kumpulan umum untuk sistem penyimpanan, mengotomatisasi pemeliharaan, mengelola persyaratan klien yang berbeda, meningkatkan pemanfaatan server dan meningkatkan dukungan untuk beban kerja pembelajaran mesin. Kami tidak sabar untuk menangani tugas-tugas ini dan berbagi kesuksesan kami.