Dalam implementasi ML nyata, belajar itu sendiri membutuhkan seperempat upaya. Tiga perempat sisanya adalah persiapan data melalui rasa sakit dan birokrasi, penyebaran yang kompleks seringkali dalam lingkaran tertutup tanpa akses Internet, pengaturan infrastruktur, pengujian dan pemantauan. Dokumen pada ratusan lembar, mode manual, konflik versi model, open source, dan perusahaan keras - semua ini menunggu seorang ilmuwan data. Tapi dia tidak tertarik dengan masalah operasional yang "membosankan" seperti itu, dia ingin mengembangkan algoritma, mencapai kualitas tinggi, memberikan kembali dan tidak lagi ingat.
Mungkin, di suatu tempat ML diterapkan lebih mudah, lebih sederhana, lebih cepat dan dengan satu tombol, tetapi kita belum melihat contoh seperti itu. Semua yang di atas adalah pengalaman Front Tier dalam fintech dan telekomunikasi. Sergey Vinogradov, seorang ahli dalam arsitektur sistem yang sangat dimuat, dalam penyimpanan besar dan dalam analisis data berat, berbicara tentang dia di
HighLoad ++ .

Model siklus hidup
Biasanya siklus hidup di area subjek kami terdiri dari tiga bagian. Pada awalnya
, tugas datang dari bisnis . Pada tahap kedua, seorang
insinyur data dan / atau ilmuwan data menyiapkan data , membangun sebuah model. Di bagian ketiga,
kekacauan dimulai. Dalam dua yang terakhir, berbagai situasi menarik terjadi.
Jack dari semua perdagangan
Situasi pertama yang sering terjadi adalah seorang ilmuwan data atau insinyur data memiliki akses ke produk, jadi mereka berkata kepadanya: "Anda melakukan semua ini, Anda bertaruh."
Seseorang mengambil
Notebook Jupyter atau satu bundel notebook, menganggapnya secara eksklusif sebagai artefak penyebaran, dan mulai mereplikasi dengan gembira di beberapa server.
Segalanya tampak baik-baik saja, tetapi tidak selalu. Saya akan memberi tahu Anda nanti mengapa.
Eksploitasi tanpa ampun
Kisah kedua lebih rumit, dan biasanya terjadi di perusahaan-perusahaan di mana eksploitasi telah mencapai tingkat kegilaan ringan. Ilmuwan data membawa solusi untuk operasi. Mereka membuka kotak hitam ini dan melihat sesuatu yang mengerikan:
- notebook
- acar dari berbagai versi;
- tumpukan skrip: tidak jelas di mana dan kapan harus menjalankannya, di mana menyimpan data yang mereka hasilkan.
Dalam teka-teki ini, eksploitasi menemukan ketidakcocokan versi. Misalnya, seorang ilmuwan data tidak menentukan versi tertentu dari perpustakaan, dan operasi mengambil yang terbaru. Setelah beberapa saat, ilmuwan data resor:
- Anda mengatur scikit-belajar ke versi yang salah, sekarang semua metrik hilang! Perlu memutar kembali ke versi sebelumnya.Ini benar-benar memecah prod, dan eksploitasi menderita.
Birokrasi
Di perusahaan dengan logo hijau, ketika ilmuwan data mulai beroperasi dan membawa model, biasanya ia menerima dokumen 800 lembar sebagai tanggapan: "Ikuti instruksi ini, jika tidak produk Anda tidak akan pernah melihat cahaya hari".
Ilmuwan data yang menyedihkan pergi, membuang segalanya di tengah jalan, dan kemudian berhenti - dia tidak tertarik melakukan ini.
Sebarkan
Misalkan seorang ilmuwan data telah melalui semua kalangan dan pada akhirnya semuanya telah dikerahkan. Tapi dia tidak akan bisa mengerti bahwa semuanya berjalan sebagaimana mestinya. Dalam pengalaman saya, di bank yang sama diberkati tidak ada pemantauan produk ilmu data.
Adalah baik jika spesialis menulis hasil karyanya dalam database. Setelah beberapa saat, ia akan menerimanya dan melihat apa yang terjadi di dalam. Tetapi ini tidak selalu terjadi. Ketika seorang bisnis dan ilmuwan data hanya percaya bahwa semuanya bekerja dengan baik dan luar biasa, itu diterjemahkan menjadi kasus yang tidak berhasil.
LKM
Entah bagaimana kami mengembangkan mesin penilaian untuk satu organisasi keuangan mikro besar. Mereka tidak membiarkan mereka pergi ke prod, tetapi hanya mengambil kaskade model dari kami, menginstal dan meluncurkannya. Hasil tes model memuaskan mereka. Tetapi setelah 6 bulan mereka kembali:
- Semuanya buruk. Bisnis tidak berjalan, kita semakin buruk. Tampaknya model-modelnya sangat baik, tetapi hasilnya menurun, penipuan dan standar semakin banyak, dan lebih sedikit uang. Untuk apa kami membayar Anda? Mari kita perbaiki.Pada saat yang sama, akses ke model tidak lagi diberikan. Log dibongkar selama sebulan, apalagi, enam bulan lalu. Kami mempelajari pembongkaran selama satu bulan lagi dan sampai pada kesimpulan bahwa pada titik tertentu departemen TI dari LKM mengubah data input, dan alih-alih dokumen di json, mereka mulai mengirim dokumen dalam xml. Model itu diharapkan json, tetapi menerima xml, sedih dan berpikir bahwa tidak ada data pada input.
Jika tidak ada data, maka penilaian tentang apa yang terjadi berbeda. Tanpa pemantauan, ini tidak dapat dideteksi.
Versi baru, kaskade, dan tes
Seringkali kita dihadapkan dengan kenyataan bahwa model tersebut bekerja dengan baik, tetapi untuk beberapa alasan
versi baru telah dikembangkan. Model itu lagi-lagi perlu dibawa masuk entah bagaimana, dan lagi untuk melewati semua lingkaran neraka. Baik jika versi pustaka sama seperti pada model sebelumnya, dan jika tidak, penyebaran akan dimulai lagi ...
Kadang-kadang sebelum menempatkan versi baru ke pertempuran, kami ingin
mengujinya - letakkan di prod, lihat arus lalu lintas yang sama, pastikan itu baik. Lagi-lagi ini adalah rantai penyebaran penuh. Selain itu, kami mengatur sistem sehingga menurut model ini, hasil nyata tidak terjadi, jika kita berbicara tentang penilaian, tetapi hanya ada pemantauan dan analisis hasil untuk analisis lebih lanjut.
Ada situasi ketika
kaskade model digunakan. Ketika hasil dari model-model berikut bergantung pada yang sebelumnya, entah bagaimana Anda perlu membangun interaksi di antara mereka dan di suatu tempat lagi semua ini harus disimpan.
Bagaimana mengatasi masalah seperti itu?
Seringkali, satu orang memecahkan masalah
secara manual , terutama di perusahaan kecil. Dia tahu bagaimana semuanya berjalan, ingat semua versi model dan perpustakaan, tahu di mana dan skrip mana yang bekerja, etalase mana yang mereka bangun. Ini semua luar biasa. Yang sangat indah adalah kisah-kisah yang ditinggalkan oleh mode manual.
Kisah tentang warisan . Seorang pria yang baik bekerja di satu bank kecil. Suatu hari dia pergi ke negara selatan dan tidak kembali. Setelah itu, kami mendapat warisan: sekelompok kode yang menghasilkan etalase tempat model bekerja. Kode ini indah, berfungsi, tetapi kami tidak tahu versi pasti dari skrip yang menghasilkan etalase ini atau itu. Dalam pertempuran semua jendela toko hadir, dan semuanya diluncurkan. Kami menghabiskan dua bulan mencoba untuk mencari jalinan rumit ini dan entah bagaimana menyusunnya.
Dalam perusahaan yang keras, orang tidak mau repot dengan segala macam Python, Jupiters, dll. Mereka berkata:
- Mari kita beli IBM SPSS, instal dan semuanya akan bagus. Masalah dengan versi, dengan sumber data, dengan penyebaran di sana entah bagaimana diselesaikan.Pendekatan ini memiliki hak untuk hidup, tetapi tidak semua orang mampu membelinya. Bagaimanapun, ini adalah jarum bergerigi berkualitas tinggi. Mereka duduk di atasnya, tetapi tidak berhasil turun - takik. Dan biasanya biayanya banyak.
Open Source adalah kebalikan dari pendekatan sebelumnya. Para pengembang menjelajahi Internet, menemukan banyak solusi Open Source yang menyelesaikan tugas-tugas mereka dengan berbagai tingkat. Ini adalah cara yang hebat, tetapi bagi kami sendiri kami tidak menemukan solusi yang akan memenuhi persyaratan kami 100%.
Karena itu, kami telah memilih opsi klasik -
keputusan kami . Ini kruk, sepeda, semua milik mereka sendiri, asli.
Apa yang kita inginkan dari keputusan kita?
Jangan menulis semuanya sendiri . Kami ingin mengambil komponen, terutama yang infrastruktur, yang telah membuktikan diri dengan baik dan akrab dengan operasi di lembaga tempat kami bekerja. Kami hanya menulis sebuah lingkungan yang akan dengan mudah mengisolasi karya ilmuwan data dari karya DevOps.
Memproses data dalam dua mode: keduanya dalam mode batch - Batch, dan waktu nyata . Tugas kami mencakup kedua mode operasi.
Kemudahan penyebaran, dan dalam perimeter tertutup . Saat bekerja dengan data pribadi yang sensitif, tidak ada koneksi internet. Pada saat ini, semuanya harus dengan cepat dan akurat mencapai produksi. Oleh karena itu, kami mulai melihat ke arah Gitlab, pipa CI / CD di dalamnya dan Docker.
Model bukanlah tujuan itu sendiri. Kami tidak memecahkan masalah membangun model, kami memecahkan masalah bisnis.
Di dalam pipa, harus ada aturan dan konglomerasi model dengan dukungan untuk
versi semua komponen pipa.
Apa yang dimaksud dengan pipa? Di Rusia, Undang-Undang Federal 115 tentang penanggulangan pencucian uang dan pendanaan terorisme berlaku. Hanya daftar isi rekomendasi Bank Sentral yang menempati 16 layar. Ini adalah aturan sederhana yang dapat dipenuhi bank jika memiliki data seperti itu, atau tidak bisa jika tidak memiliki data.
Evaluasi peminjam, transaksi keuangan atau proses bisnis lainnya adalah aliran data yang kami proses. Aliran harus melalui aturan semacam ini. Aturan-aturan ini dijelaskan dengan cara yang mudah oleh analis. Dia bukan ilmuwan data, tetapi dia tahu hukum atau instruksi lainnya dengan baik. Analis duduk dan, dalam bahasa sederhana, menjelaskan pemeriksaan untuk data.
Membangun kaskade model . Seringkali situasi muncul ketika model berikutnya menggunakan untuk pekerjaannya nilai-nilai yang diperoleh dalam model sebelumnya.
Uji hipotesis dengan cepat. Saya ulangi tesis sebelumnya: seorang ilmuwan data membuat semacam model, itu berputar dalam pertempuran dan bekerja dengan baik. Untuk beberapa alasan, spesialis datang dengan solusi yang lebih baik, tetapi tidak ingin merusak alur kerja yang ada. Ilmuwan data menggantung model baru pada lalu lintas tempur yang sama dalam sistem pertempuran. Dia tidak berpartisipasi langsung dalam pengambilan keputusan, tetapi melayani lalu lintas yang sama, mempertimbangkan beberapa kesimpulan dan kesimpulan ini disimpan di suatu tempat.
Fitur penggunaan kembali yang mudah. Banyak tugas memiliki jenis komponen yang sama, terutama yang terkait dengan ekstraksi fitur atau aturan. Kami ingin menyeret komponen ini ke jaringan pipa lain.
Apa yang Anda putuskan untuk lakukan?
Pertama, kami ingin pemantauan. Dan dua jenisnya.
Pemantauan
Pemantauan teknis. Jika ada komponen pipa yang digunakan, dalam operasi mereka akan melihat apa yang terjadi pada komponen: bagaimana ia mengkonsumsi memori, CPU, disk.
Pengawasan bisnis. Ini adalah alat ilmuwan data yang memungkinkan Anda untuk abstrak dari nuansa teknis implementasi. Pada tingkat desain, konstruksi membantu menentukan metrik model mana yang harus tersedia dalam pemantauan, misalnya, distribusi fitur atau hasil penilaian layanan.
Seorang ilmuwan data mendefinisikan metrik dan tidak perlu khawatir tentang bagaimana mereka masuk ke sistem pemantauan. Satu-satunya hal yang penting adalah ia mendefinisikan metrik ini dan tampilan dasbor tempat metrik akan ditampilkan. Kemudian spesialis meluncurkan semuanya pada produksi, dikerahkan, dan setelah beberapa saat metrik mengalir ke pemantauan. Jadi seorang ilmuwan data tanpa akses ke produk dapat melihat apa yang terjadi di dalam model.
Pengujian
Uji
pipa untuk konsistensi . Mengingat kekhasan pipa, ini adalah semacam grafik komputasi. Kami ingin memahami bahwa kami menerapkan grafik, kami dapat memintasnya dan menemukan jalan keluar darinya.
Grafik memiliki komponen - modul. Semua modul harus lulus pengujian unit dan integrasi. Prosesnya harus transparan dan mudah bagi seorang ilmuwan data.
Pengembang menjelaskan model dan tes sendiri atau dengan bantuan orang lain. Letakkan semuanya di Gitlab, jalur pipa yang dikonfigurasi oleh Continuous Integration, tes, dan lihat hasilnya. Jika semuanya baik - itu lebih jauh, tidak - itu mulai lagi.
Ilmuwan data berfokus pada model dan tidak tahu apa yang ada di bawah tenda. Untuk ini, dia diberikan beberapa hal.
- API untuk integrasi dengan inti sistem itu sendiri melalui bus data - bus pesan. Dalam hal ini, spesialis perlu menggambarkan apa yang terjadi dan apa yang keluar dari modelnya, titik masuk dan persimpangan dengan berbagai komponen di dalam pipa.
- Setelah melatih model, sebuah artefak muncul - file XGBoost atau acar . Ilmuwan data memiliki pelaksana untuk bekerja dengan artefak - ia harus mengintegrasikan komponen pipa di dalamnya.
- API yang mudah dan transparan untuk ilmuwan data untuk memantau operasi komponen pipa - pemantauan teknis dan bisnis.
- Infrastruktur yang sederhana dan transparan untuk diintegrasikan dengan sumber data dan menjaga hasil kerja.
Seringkali model bekerja untuk kita, dan setelah beberapa saat audit tiba yang ingin meningkatkan seluruh sejarah layanan. Audit ingin memeriksa kebenaran pekerjaan, tidak adanya kecurangan di pihak kami. Alat-alat sederhana diperlukan agar setiap auditor yang mengetahui SQL dapat masuk ke repositori khusus dan melihat bagaimana semuanya bekerja, keputusan apa yang dibuat dan mengapa.
Kami meletakkan dasar bagi dua kisah penting bagi kami.
Perjalanan Pelanggan. Ini adalah kesempatan untuk menggunakan mekanisme untuk menjaga seluruh sejarah pelanggan - apa yang terjadi pada klien sebagai bagian dari proses bisnis yang diterapkan pada sistem ini.
Kami mungkin memiliki sumber data eksternal, misalnya, platform DMP. Dari mereka, kami mendapatkan informasi tentang perilaku manusia di jaringan dan di perangkat seluler. Ini mungkin memiliki efek pada LTV dan model penilaian modelnya. Jika peminjam terlambat membayar, kami dapat memperkirakan bahwa ini bukan niat jahat - hanya ada masalah. Dalam hal ini, kami menerapkan metode eksposur lunak kepada peminjam. Ketika masalah diselesaikan, klien akan menutup pinjaman. Ketika dia datang lain kali, kita akan tahu seluruh ceritanya. Ilmuwan data akan mendapatkan sejarah visual dari model dan melakukan penilaian dalam mode cahaya.
Identifikasi anomali . Kita terus dihadapkan pada dunia yang sangat kompleks. Misalnya, titik lemah dalam percepatan evaluasi LKM dapat menjadi sumber penipuan otomatis.
Customer Journey adalah konsep akses cepat dan mudah ke aliran data yang melewati model. Model ini memudahkan untuk mendeteksi anomali yang merupakan karakteristik penipuan pada saat kemunculannya yang masal.
Bagaimana semuanya diatur?
Tanpa ragu, kami mengambil
Kafka sebagai patch Pesan Bus. Ini adalah solusi yang baik yang digunakan oleh banyak pelanggan kami, operasi ini dapat bekerja dengannya.
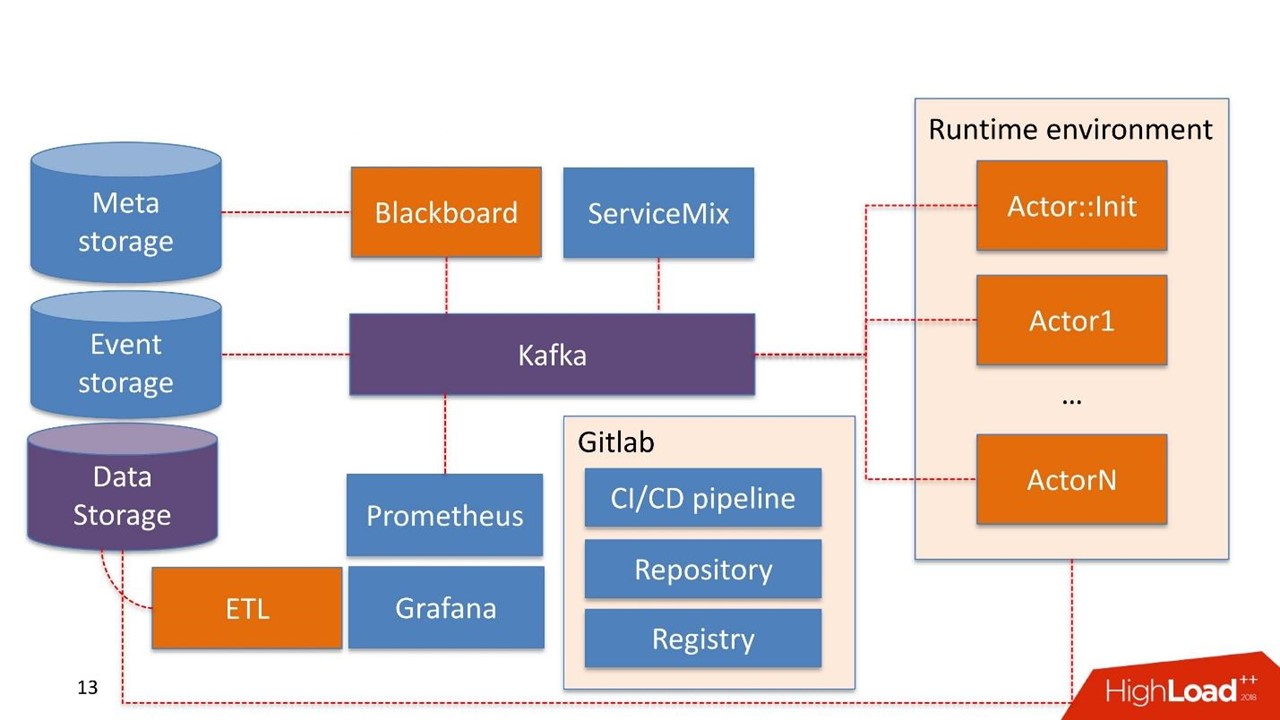
Beberapa komponen sistem mungkin sudah digunakan di perusahaan itu sendiri. Kami tidak membangun sistem lagi, tetapi menggunakan kembali apa yang sudah mereka miliki.
Penyimpanan Data dalam hal ini adalah penyimpanan yang biasanya sudah dimiliki klien. Ini bisa menjadi Hadoop, database relasional dan non-relasional. Kita dapat bekerja di luar kotak dengan HDFS, Hive, Impala, Greenplum dan PostgreSQL. Kami menganggap penyimpanan ini sebagai sumber untuk jendela toko.
Data tiba di gudang, melewati ETL kami atau ETL pelanggan, jika ia memilikinya. Kami sedang membangun jendela toko yang selanjutnya digunakan di dalam model. Penyimpanan Data digunakan dalam mode hanya baca.
Perkembangan kami
Papan tulis Nama ini diambil dari salah satu praktik matematika yang agak aneh dari 30-40-an. Ini adalah manajer jalur pipa yang tinggal di sistem admin. Blackboard memiliki semacam Meta Storage. Ini menyimpan pipa sendiri dan konfigurasi yang diperlukan untuk menginisialisasi semua komponen.
Semua pekerjaan sistem dimulai dengan Blackboard. Dengan beberapa keajaiban, pipa berakhir di Meta Storage, Blackboard setelah beberapa saat memahami ini, mengeluarkan versi pipa saat ini, menginisialisasi dan mengirimkan sinyal ke dalam Kafka.
Ada
lingkungan runtime . Itu dibangun di Dockers dan dapat direplikasi ke server, termasuk di cloud pribadi pelanggan.
Keluar dari kotak muncul
Aktor utama
:: Init - ini adalah inisialisasi. Ini adalah jin yang hanya dapat melakukan dua hal:
membangun dan
menghancurkan komponen . Dia menerima perintah dari Blackboard: "Ini pipeline, perlu diluncurkan pada server ini dan itu dengan sumber daya ini dan itu dalam jumlah ini dan itu - bekerja!" Kemudian aktor memulai semuanya.
Secara matematis, aktor adalah fungsi yang mengambil satu atau lebih objek sebagai input, mengubah keadaan objek menggunakan algoritma di dalam, menghasilkan objek baru di output, atau mengubah keadaan objek yang sudah ada.
Secara teknis, aktor adalah program Python. Berjalan di wadah Docker dengan lingkungannya.
Aktor tidak tahu tentang keberadaan aktor lain. Satu-satunya entitas yang tahu bahwa selain aktor ada seluruh pipa secara keseluruhan - ini adalah Blackboard. Ini memantau status eksekusi semua aktor dalam sistem dan mempertahankan keadaan saat ini, yang dinyatakan dalam pemantauan sebagai gambaran dari seluruh proses bisnis secara keseluruhan.
Aktor :: Init memunculkan banyak wadah Docker. Selain itu, aktor dapat bekerja dengan penyimpanan data.
Sistem itu sendiri memiliki komponen
Penyimpanan Acara . Sebagai Penyimpanan Acara, kami menggunakan
ClickHouse . Tugasnya sederhana: semua informasi yang dipertukarkan antara aktor melalui Kafka disimpan di ClickHouse. Ini dilakukan
untuk audit lebih lanjut . Ini adalah log operasi pipa.
Aktor juga dapat dikembangkan untuk
Perjalanan Pelanggan . Mereka melihat perubahan dalam log pipa, dan dapat dengan cepat membangun kembali jendela yang diperlukan untuk model atau komponen untuk bekerja dengan aturan, sudah ada di dalam pipa. Ini adalah proses perubahan data yang sedang berlangsung.
Pemantauan agak primitif dibangun di atas
Prometheus . Aktor ini diberikan API dasar, dan dalam mode tertutup, tetapi cukup transparan bagi pengembang, ia mengirim pesan dengan metrik ke Kafka. Prometheus membaca metrik dari Kafka dan menyimpannya di repositori.
Untuk visualisasi kami menggunakan
Grafana .
Dua titik integrasi
Yang pertama adalah titik integrasi dengan sumber data yang melewati ETL ke gudang data. Titik integrasi kedua ketika layanan sudah digunakan oleh konsumen data, misalnya, layanan penilaian.
Kami mengambil
Apache ServiceMix. Dari pengalaman, titik-titik integrasi ini memiliki tipe yang sama dengan jenis protokol yang sama: SOAP, ISTIRAHAT, kurang sering antrian. Setiap kali kita tidak ingin mengembangkan konstruktor atau layanan kita sendiri untuk menghasilkan layanan SOAP berikutnya. Oleh karena itu, kami mengambil ServiceMix, menggambarkannya di SDL, di mana model data layanan ini dan metode yang ada di dalamnya dibangun. Kemudian kami mendorong melalui router di dalam ServiceMix, dan itu menghasilkan layanan itu sendiri.
Dari diri kami sendiri, kami menambahkan konversi sinkron-asinkron yang rumit. Semua permintaan yang hidup di dalam sistem asinkron dan masuk melalui Bus Pesan.
Sebagian besar layanan penilaian bersifat sinkron. Permintaan ServiceMix datang melalui REST atau SOAP. Pada titik ini, ia melewati Gateway kami, yang mempertahankan pengetahuan tentang sesi HTTP. Lalu ia mengirim pesan ke Kafka, itu berjalan melalui beberapa pipa, dan solusi dihasilkan.
Namun, mungkin masih belum ada solusi. Misalnya, ada sesuatu yang jatuh, atau ada SLA yang sulit untuk mengambil keputusan, dan Gateway memantau: "Oke, saya menerima permintaan, dia datang kepada saya dalam topik Kafka lain, atau tidak ada yang datang kepada saya, tetapi pemicu waktu habis saya berhasil." Kemudian lagi, konversi dari sinkron ke asinkron berjalan, dan dalam sesi HTTP yang sama, ada respons kepada konsumen dengan hasil kerja. Ini mungkin kesalahan atau perkiraan normal.
Ngomong-ngomong, kami makan seekor anjing hambar berkat Open Source yang hebat dan kuat. Kami menggunakan ServiceMix dari salah satu versi terbaru, dan Kafka dari versi sebelumnya dan semuanya bekerja dengan sempurna. Kami menulis di Gateway ini, berdasarkan kubus-kubus yang sudah ada di ServiceMix. Ketika versi baru Kafka keluar, kami dengan senang hati mengambilnya, tetapi ternyata dukungan untuk kepala bagian dalam pesan di Kafka yang sebelumnya ada telah berubah. Gateway di dalam ServiceMix tidak bisa lagi bekerja dengan mereka. Untuk memahami ini, kami menghabiskan banyak waktu. Sebagai hasilnya, kami membangun Gateway kami, yang dapat bekerja dengan versi baru Kafka. Kami menulis tentang masalah kepada pengembang ServiceMix dan menerima jawabannya: "Terima kasih, kami pasti akan membantu Anda dalam versi berikutnya!"
Karena itu, kami dipaksa untuk memantau pembaruan dan secara teratur mengubah sesuatu.
Infrastruktur adalah Gitlab. Kami menggunakan hampir semua yang ada di dalamnya.
- Repositori kode.
- Melanjutkan Integrasi / Melanjutkan pengiriman Pipa.
- Registri untuk memelihara daftar kontainer Docker.
Komponen
Kami telah mengembangkan 5 komponen:
- Blackboard - manajemen siklus hidup pipa. Di mana, apa dan dengan parameter apa yang harus dijalankan dari pipa.
- Extractor fitur berfungsi sederhana - kami memberi tahu Extractor fitur bahwa kami mendapatkan model data ini dan itu pada input, pilih bidang yang diperlukan dari data, memetakannya ke nilai-nilai tertentu. Misalnya, kami mendapatkan tanggal lahir klien, mengubahnya menjadi usia, menggunakannya sebagai fitur dalam model kami. Extractor fitur bertanggung jawab untuk pengayaan data.
- Mesin berbasis aturan - memeriksa data sesuai aturan. Ini adalah bahasa deskripsi sederhana yang memungkinkan orang yang terbiasa dengan konstruksi <code> jika, selain itu <code /> blok untuk menggambarkan aturan untuk memeriksa dalam sistem.
- Mesin pembelajaran mesin - memungkinkan Anda untuk menjalankan eksekutor, menginisialisasi model yang terlatih dan mengirimkannya ke data input. Pada output, model mengambil data.
- Mesin pengambilan keputusan - mesin pengambilan keputusan, keluar dari grafik. Memiliki kaskade model, misalnya, cabang yang berbeda dari penilaian peminjam, Anda harus memutuskan masalah uang di suatu tempat. Seperangkat aturan untuk solusi harus sederhana. , LTV- — , , .
. — , . — , .
pipeline .
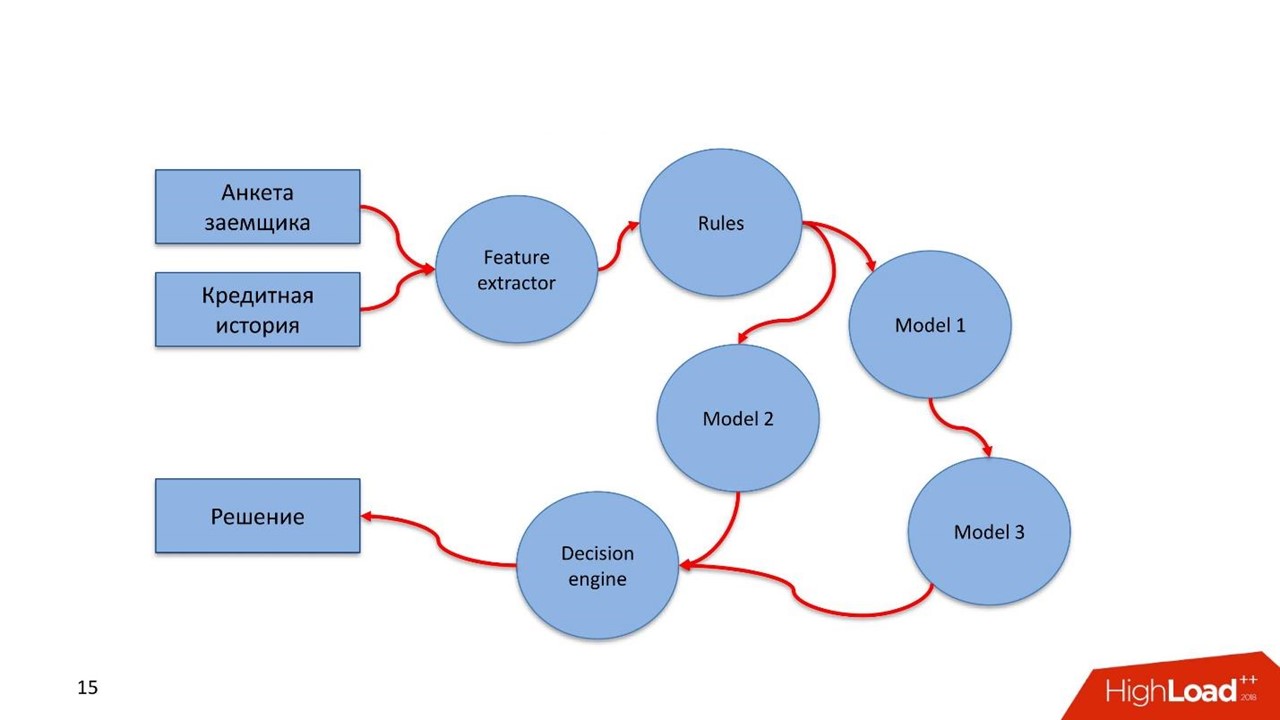
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
Saluran pipa
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
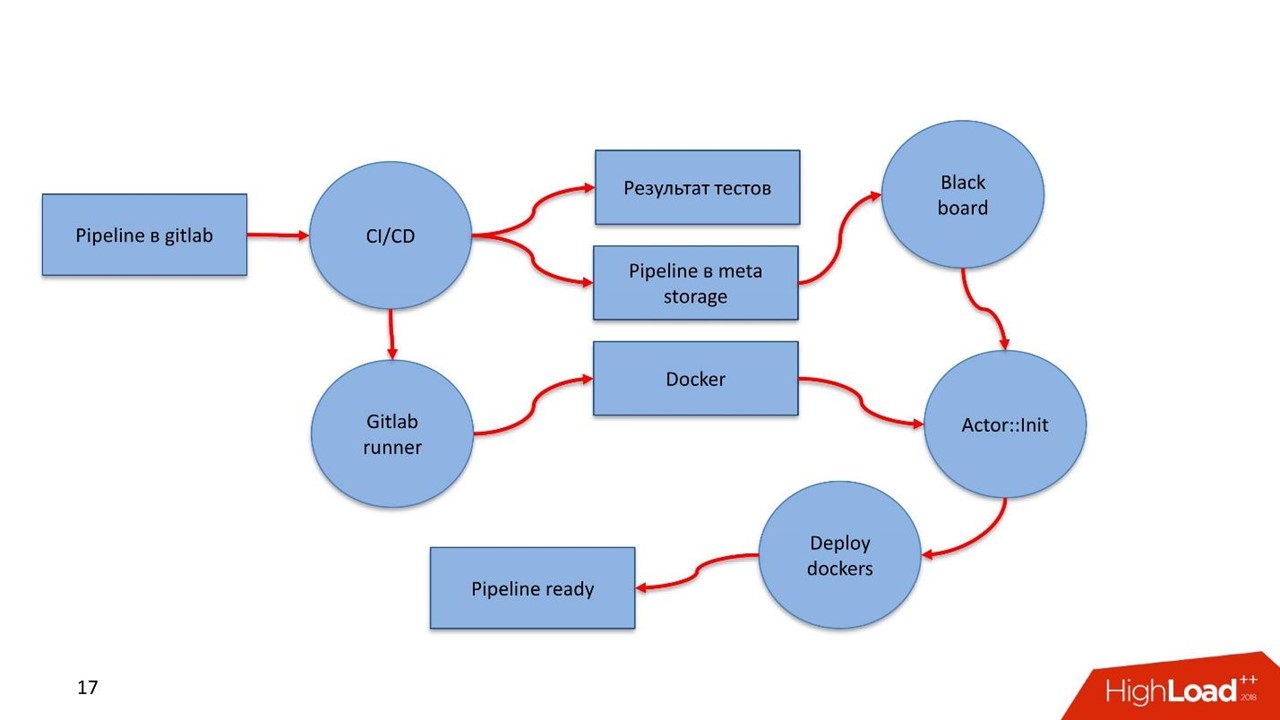
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
Apa hasilnya?
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .