Semakin banyak pengguna layanan Anda, semakin tinggi kemungkinan mereka akan membutuhkan bantuan. Dukungan teknis obrolan adalah solusi yang jelas tapi agak mahal. Tetapi jika Anda menggunakan teknologi pembelajaran mesin, Anda dapat menghemat uang.
Bot sekarang dapat menjawab pertanyaan sederhana. Selain itu, chatbot dapat diajarkan untuk menentukan niat pengguna dan untuk menangkap konteks sehingga ia dapat menyelesaikan sebagian besar masalah pengguna tanpa campur tangan manusia. Bagaimana melakukan ini, Vladislav Blinov dan Valery Baranova, pengembang asisten populer Oleg, akan membantu mengetahuinya.
Beralih dari metode sederhana ke metode yang lebih rumit dalam tugas mengembangkan bot obrolan, kami akan menganalisis masalah implementasi praktis dan melihat kualitas yang dapat Anda peroleh dan berapa biayanya.
Vladislav Blinov adalah pengembang senior sistem dialog di
Tinkoff , sering melempar singkatan: ML, NLP, DL, dll. Selain itu, sekolah pascasarjana memeriksa pemodelan humor melalui pembelajaran mesin dan jaringan saraf.
Valeria Baranova telah menulis hal-hal keren di bidang NLP dengan Python selama lebih dari 5 tahun. Sekarang, dalam tim sistem interaktif, Tinkoff membuat bot obrolan dan mengajarkan kursus Pembelajaran Mesin untuk siswa. Dia juga terlibat dalam penelitian di bidang humor komputasi, yaitu, dia mengajarkan AI untuk memahami lelucon dan membuat lelucon baru - Valeria dan Vladislav
akan membicarakan hal ini di UseData Conf.
Layanan Tinkoff Bank digunakan oleh jutaan orang. Untuk memberikan dukungan sepanjang waktu bagi sejumlah pengguna, diperlukan staf besar, yang mengarah pada biaya layanan yang tinggi. Tampaknya logis bahwa pertanyaan populer pengguna dapat dijawab secara otomatis menggunakan bot obrolan.
Niat atau niat pengguna
Hal pertama yang diperlukan chatbot adalah memahami
apa yang diinginkan pengguna . Tugas ini disebut klasifikasi niat atau niat. Selanjutnya, semua model dan pendekatan akan dipertimbangkan dalam kerangka tugas ini.
Mari kita lihat contoh klasifikasi niat. Jika Anda menulis: "Transfer seratus Lera," obrolan bot Oleg akan mengerti bahwa ini adalah tujuan transfer uang, yaitu, niat pengguna untuk mentransfer uang. Atau lebih tepatnya, bahwa Lera perlu mentransfer jumlah 100 rubel.
Kami akan membandingkan metode dan menguji kualitas pekerjaan mereka pada sampel uji, yang terdiri dari dialog nyata dengan pengguna. Sampel kami berisi lebih dari 30.000 contoh yang ditandai dan 170 niat, misalnya: pergi ke bioskop, mencari restoran, membuka atau menutup deposit, dll. Oleg juga memiliki pendapatnya sendiri tentang banyak hal, dan dia hanya bisa mengobrol dengan Anda.
Klasifikasi Kamus
Hal paling sederhana yang dapat dilakukan dalam tugas mengklasifikasikan maksud adalah
menggunakan kamus . Misalnya, jika kata "terjemahkan" muncul dalam frasa pengguna, pertimbangkan bahwa pengiriman uang harus dilakukan.
Mari kita lihat kualitas dari pendekatan yang begitu sederhana.
Jika penggolong hanya mendefinisikan niat pengguna sebagai "transfer uang" dengan kata "menerjemahkan", maka kualitasnya sudah cukup tinggi. Presisi - 88%, sementara kelengkapannya rendah, sama dengan hanya 23%. Ini bisa dimengerti: kata "menerjemahkan" tidak menggambarkan semua kemungkinan untuk mengatakan "mentransfer uang kepada seseorang".
Namun, pendekatan ini memiliki kelebihan:
- Tidak diperlukan pengambilan sampel berlabel (jika Anda tidak mempelajari modelnya, maka pengambilan sampel tidak diperlukan).
- Anda bisa mendapatkan akurasi tinggi jika Anda menyusun kamus dengan baik (tetapi akan membutuhkan waktu dan sumber daya).
Namun, kelengkapan solusi semacam itu kemungkinan rendah, karena semua variasi kelas apa pun sulit untuk dijelaskan.
Pertimbangkan contoh berlawanan. Jika selain maksud pengiriman uang, "transfer" juga dapat mencakup maksud kedua - "transfer ke operator". Ketika kami menambahkan maksud terjemahan baru ke operator, kami mendapatkan hasil yang berbeda.
Akurasi turun 18 poin, sementara, tentu saja, kelengkapannya tidak bertambah. Ini menunjukkan bahwa diperlukan pendekatan yang lebih maju.
Analisis teks
Sebelum menggunakan pembelajaran mesin, Anda perlu memahami cara menyajikan teks sebagai vektor. Salah satu pendekatan termudah adalah dengan
menggunakan vektor tf-idf .
Vektor tf-idf memperhitungkan kemunculan setiap kata dalam frasa pengguna dan memperhitungkan total kemunculan kata dalam koleksi. Kata-kata yang sering ditemukan dalam teks yang berbeda memiliki bobot lebih sedikit dalam representasi vektor ini.
Mari kita lihat kualitas model linear pada representasi tf-idf (dalam kasus kami, regresi logistik).
Akibatnya,
kelengkapan meningkat tajam, dan akurasi tetap sebanding dengan penggunaan kamus, ukuran f1 (bobot harmonik rata-rata antara akurasi dan kelengkapan) juga meningkat. Artinya, model itu sendiri sudah memahami kata-kata mana yang penting untuk maksud mana - Anda tidak perlu menciptakan apa pun sendiri.
Visualisasi data
Visualisasi data membantu untuk memahami bagaimana niat terlihat, seberapa baik mereka dikelompokkan dalam ruang. Tetapi kami tidak dapat secara langsung memvisualisasikan representasi tf-idf karena dimensi yang besar, jadi kami akan menggunakan
metode kompresi dimensi - t-SNE .
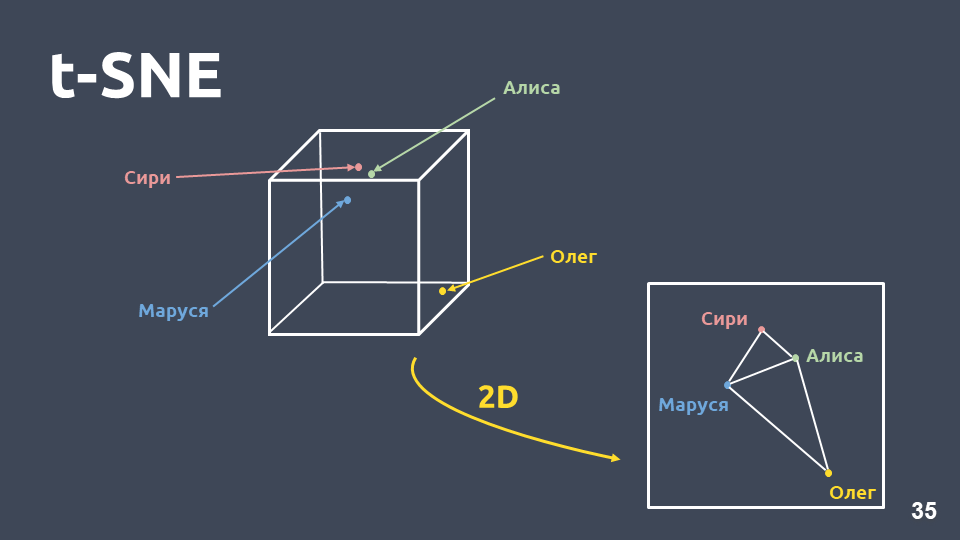
Perbedaan utama antara metode ini dan PCA adalah bahwa ketika dipindahkan ke ruang dua dimensi,
jarak relatif antara objek dipertahankan .
t-SNE pada tf-idf (top 10 intents), skor F1 0,9210 niat teratas menurut kemunculan dalam koleksi kami disajikan di atas. Ada titik-titik hijau yang bukan milik niat apa pun, dan 10 gugus yang ditandai dengan warna berbeda adalah niat berbeda. Dapat dilihat bahwa beberapa dari mereka dikelompokkan dengan sangat baik.
Ukuran f1 tertimbang
adalah 0,92 - ini cukup banyak, Anda sudah bisa menggunakannya.
Jadi dengan classifier linier di atas tf-idf:
- kelengkapan jauh lebih tinggi daripada menggunakan kamus, dengan akurasi yang sebanding;
- tidak perlu memikirkan kata mana yang sesuai dengan maksud mana.
Namun ada juga kelemahannya:
- kosakata terbatas, Anda bisa mendapatkan bobot hanya untuk kata-kata yang ada dalam sampel pelatihan;
- penyusunan ulang tidak diperhitungkan;
- urutan kata-kata tersebut muncul dalam teks tidak diperhitungkan.
Mengulangi
Mari kita pertimbangkan secara lebih terperinci masalah pengulangan kata-kata.
Vektor Tf-idf hanya dapat ditutup untuk teks yang berpotongan dalam kata-kata. Kedekatan antara vektor dapat dihitung melalui kosinus sudut di antara mereka. Kedekatan cosinus dalam representasi vektor tf-idf dihitung untuk contoh spesifik.
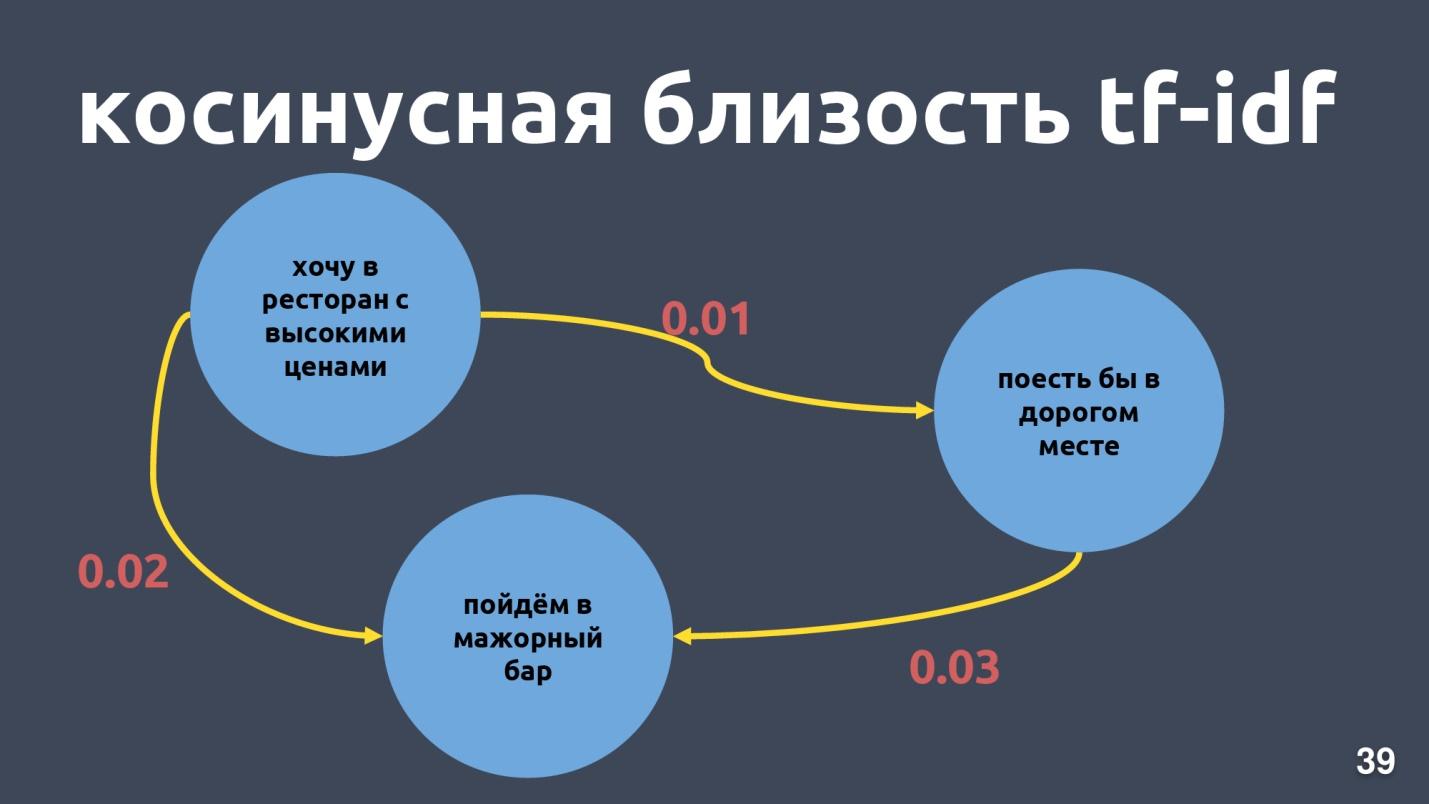
Ini bukan frase yang sangat dekat untuk representasi vektor tf-idf, meskipun bagi kami itu adalah niat yang sama dan kelas yang sama.
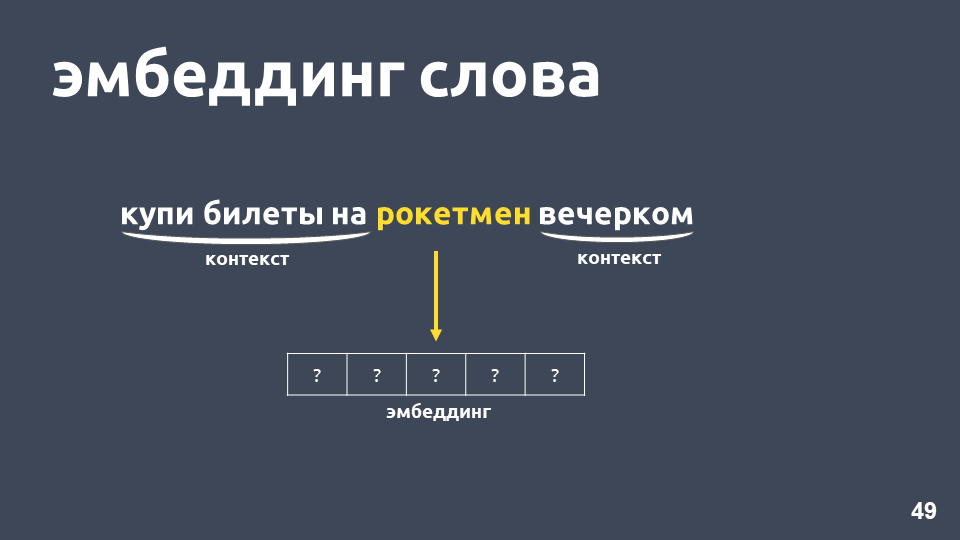
Apa yang bisa dilakukan tentang ini? Misalnya, alih-alih angka, Anda dapat mewakili kata sebagai vektor keseluruhan - ini disebut "embedding kata."
Salah satu model paling populer untuk menyelesaikan masalah ini diusulkan pada tahun 2013. Ini disebut
word2vec dan telah banyak digunakan sejak saat itu.
Salah satu cara belajar Word2vec bekerja kira-kira sebagai berikut: kita mengambil teks, kita mengambil beberapa kata dari konteks dan membuangnya, lalu kita mengambil kata acak lain dari konteks dan menyajikan kedua kata sebagai vektor satu-panas. Vektor satu-panas adalah vektor menurut dimensi kamus, di mana hanya koordinat yang sesuai dengan indeks kata dalam kamus yang memiliki nilai 1, sisanya 0.
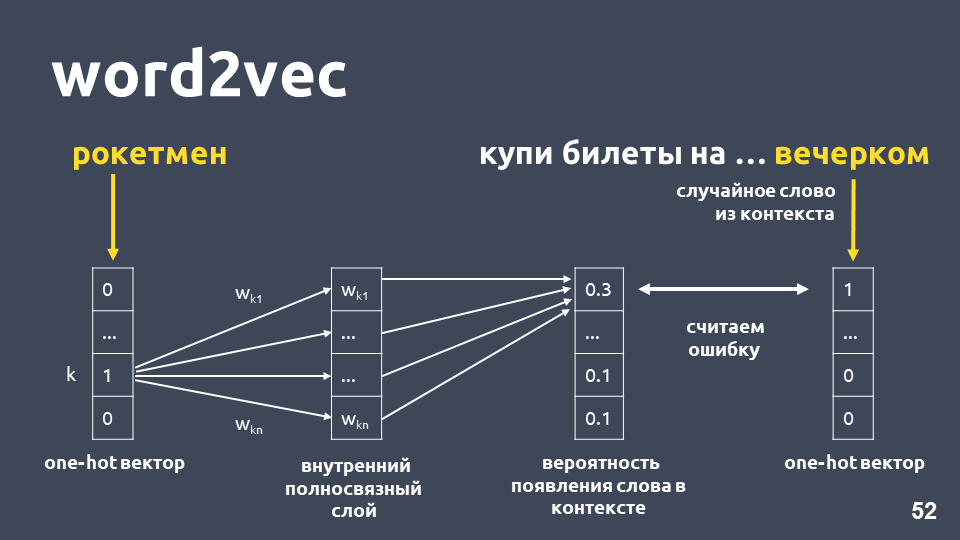
Selanjutnya, kami melatih jaringan saraf single-layer sederhana tanpa aktivasi pada lapisan dalam untuk memprediksi kata berikutnya dalam konteks, yaitu, untuk memprediksi kata "di malam hari" menggunakan kata "rocketman". Pada output, kami memperoleh distribusi probabilitas untuk semua kata dari kamus menjadi sebagai berikut. Karena kita tahu apa sebenarnya kata itu, kita dapat menghitung kesalahan, memperbarui bobot, dll.

Bobot yang diperbarui yang diperoleh sebagai hasil pelatihan sampel kami adalah kata embedding.
Keuntungan menggunakan embedding bukan angka, pertama,
konteks itu diperhitungkan . Contoh yang populer: Trump dan Putin dekat dengan word2vec karena keduanya adalah presiden dan sering digunakan bersama dalam teks.
Untuk kata-kata yang ditemukan dalam sampel pelatihan, Anda hanya mengambil matriks embedding, mengambil vektornya dengan indeks kata, dan mendapatkan embedding.
Tampaknya semuanya baik-baik saja, kecuali bahwa beberapa kata dalam matriks Anda mungkin tidak, karena model tidak melihatnya selama pelatihan. Untuk menangani masalah kata-kata asing (out-of-vocabulary), pada tahun 2014 mereka datang dengan modifikasi word2vec -
fasttext .
Fasttext berfungsi sebagai berikut: jika kata tersebut tidak ada dalam kamus, maka kata tersebut dibagi menjadi simbol n-gram, untuk setiap n-gram embedding diambil dari matriks embeddings n-gram (yang dilatih seperti word2vec), embedding dirata-ratakan, dan vektor diperoleh.
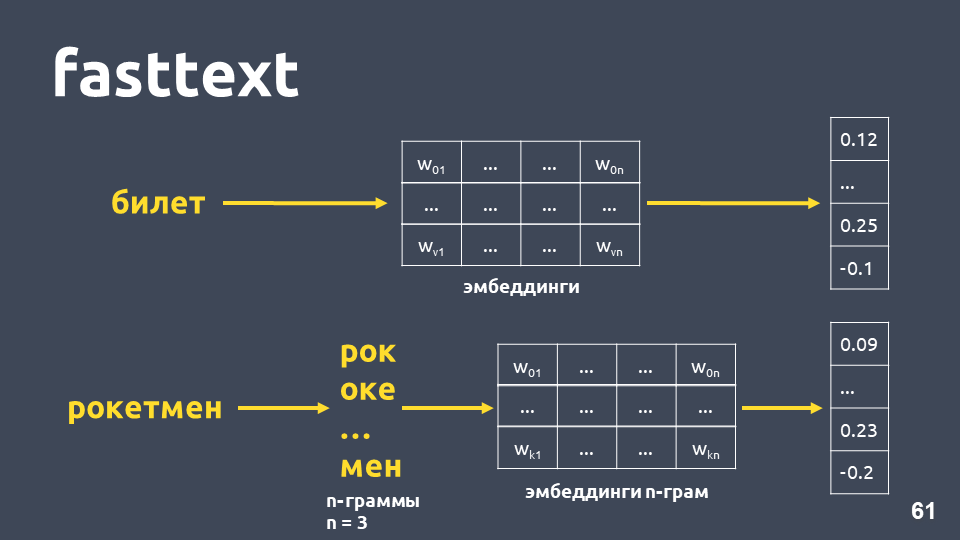
Total, kami mendapatkan vektor untuk kata-kata yang tidak ada dalam kamus kami. Sekarang kita dapat
menghitung kesamaan bahkan untuk kata-kata yang tidak dikenal . Dan, yang cukup penting, ada model terlatih untuk bahasa Rusia, Inggris dan Cina, misalnya, Facebook dan proyek
DeepPavlov , sehingga Anda dapat dengan cepat memasukkan ini ke dalam saluran pipa Anda.
Namun kerugiannya tetap:- Model ini tidak digunakan untuk seluruh vektor teks. Untuk mendapatkan vektor teks biasa, Anda perlu memikirkan sesuatu: rata-rata, atau rata-rata dengan perkalian dengan bobot idf, dan ini dapat bekerja secara berbeda dalam tugas yang berbeda.
- Vektor untuk satu kata masih satu, terlepas dari konteksnya. Word2vec melatih satu vektor kata untuk konteks apa pun di mana kata itu muncul. Untuk kata-kata multi-nilai (seperti, misalnya, bahasa) akan ada satu dan vektor yang sama.
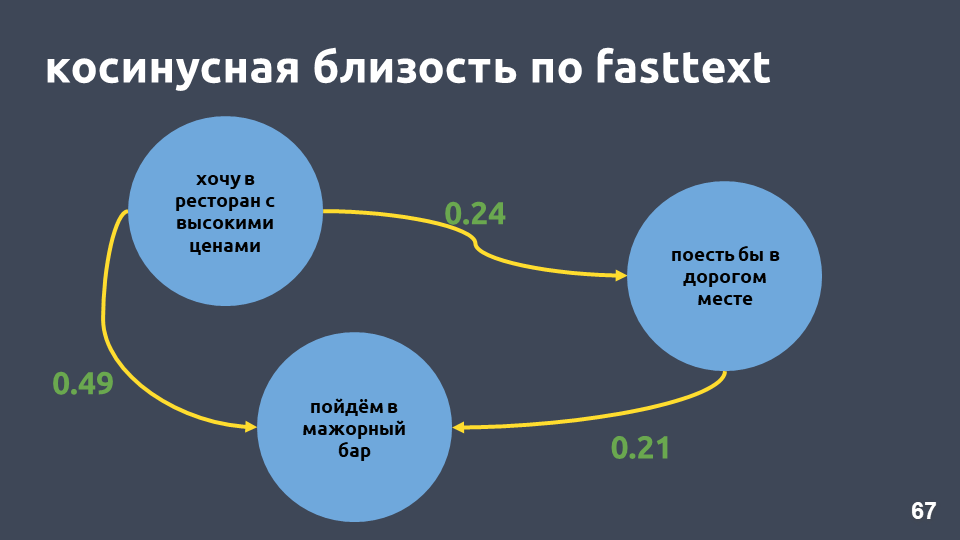
Memang, kedekatan cosinus dalam contoh kita dalam fasttext lebih tinggi daripada kedekatan cosinus di tf-idf, meskipun frasa dalam frasa ini hanya "dalam."
t-SNE pada fasttext (top 10 intents), skor F1: 0,86Namun, ketika memvisualisasikan hasil teks cepat pada dekomposisi t-SNE, cluster maksud jauh lebih buruk daripada untuk tf-idf. Ukuran F1 di sini adalah 0,86 bukannya 0,92.
Kami melakukan percobaan: gabungan tf-idf dan vektor fasttext. Kualitasnya benar-benar sama seperti ketika hanya menggunakan tf-idf. Ini tidak benar untuk semua tugas, ada masalah di mana tf-idf dan fasttext gabungan bekerja lebih baik daripada hanya tf-idf, atau di mana fasttext bekerja lebih baik daripada tf-idf. Anda perlu bereksperimen dan mencoba.
Mari kita coba untuk meningkatkan jumlah niat (ingat bahwa kita memiliki 170 di antaranya). Di bawah ini adalah kelompok untuk 30 maksud teratas pada vektor tf-idf.
t-SNE di tf-idf (30 niat teratas), skor F1 0, 85 (pada 10 itu 0,92)Kualitas turun 7 poin, dan sekarang kita tidak melihat struktur klaster yang diucapkan.
Mari kita lihat contoh-contoh teks yang mulai membingungkan, karena lebih banyak maksud ditambahkan yang berpotongan semantik dan kata-kata.
Misalnya: "Dan jika Anda membuka deposito, apa bunganya?" dan "Dan saya ingin membuka kontribusi sebesar 7 persen." Ungkapan yang sangat mirip, tetapi ini adalah niat yang berbeda. Dalam kasus pertama, seseorang ingin mengetahui kondisi untuk setoran, dan dalam kasus kedua, untuk membuka setoran. Untuk memisahkan teks-teks tersebut ke dalam kelas yang berbeda, kita membutuhkan sesuatu yang lebih kompleks -
pembelajaran yang mendalam .
Model bahasa
Kami ingin mendapatkan vektor teks dan, khususnya, vektor kata, yang akan tergantung pada konteks penggunaan. Cara standar untuk mendapatkan vektor semacam itu adalah dengan
menggunakan embeddings dari model bahasa .
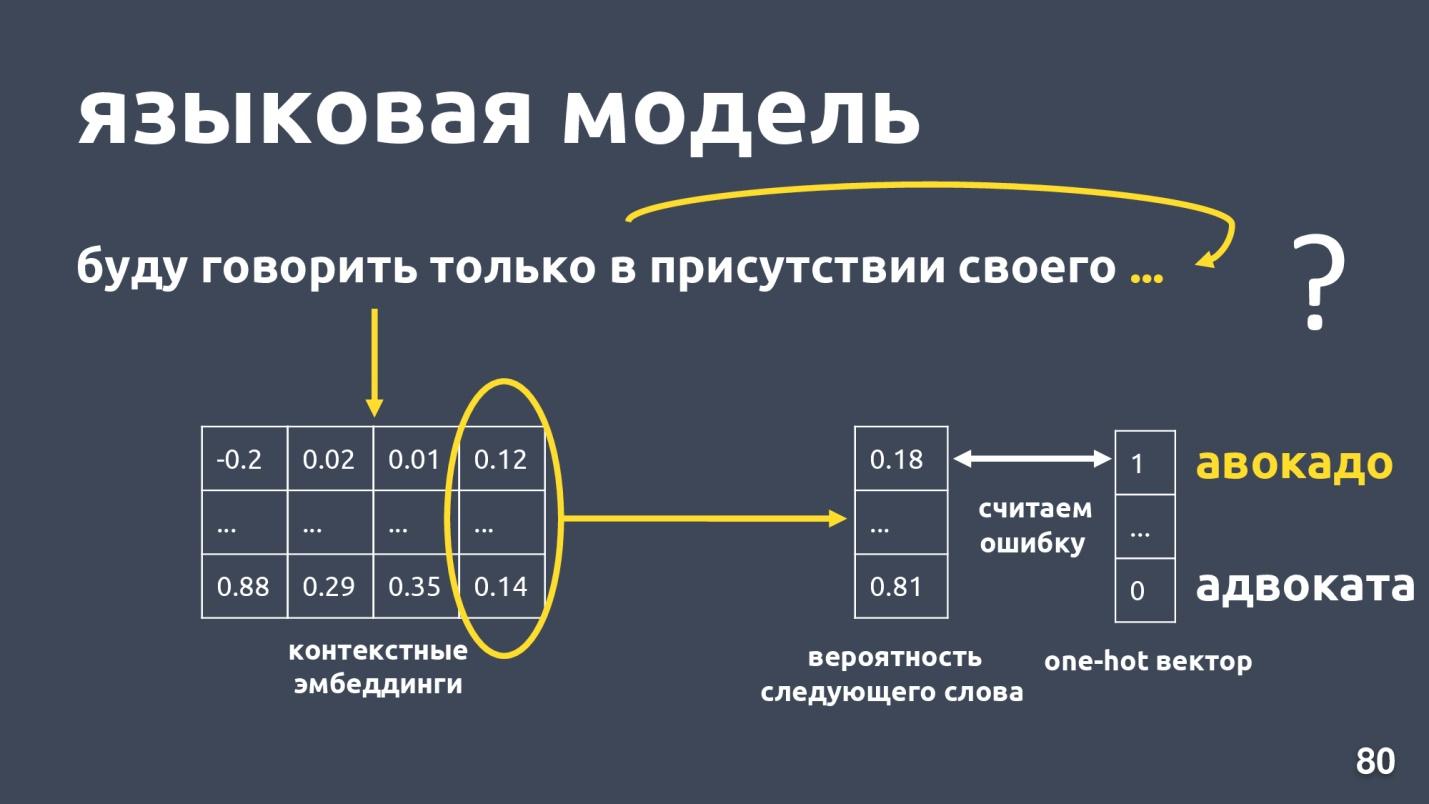
Model bahasa memecahkan masalah pemodelan bahasa. Dan apa tugas ini? Misalkan ada urutan kata-kata, misalnya: "Saya hanya akan berbicara di hadapan saya sendiri ...", dan kami mencoba untuk memprediksi kata berikutnya dalam urutan. Model bahasa menyediakan konteks untuk embeddings. Setelah memperoleh embeddings dan vektor kontekstual untuk setiap kata, seseorang dapat memprediksi probabilitas kata berikutnya.
Ada vektor dimensi kamus, dan setiap kata diberi peluang untuk menjadi yang berikutnya. Kita lagi tahu apa kata itu dalam kenyataan, mempertimbangkan kesalahan dan melatih modelnya.
Ada beberapa model bahasa, apakah ada booming tahun lalu? dan banyak arsitektur berbeda telah diusulkan. Salah satunya adalah
ELMo .
ELMo
Gagasan model ELMo adalah untuk pertama-tama membangun kata simbolik yang disematkan untuk setiap kata dalam teks, dan kemudian menerapkan
jaringan LSTM untuk mereka sedemikian rupa sehingga embeddings diperhitungkan yang memperhitungkan konteks di mana kata itu muncul.
Mari kita periksa bagaimana embedding simbolik diperoleh: kita memecah kata menjadi simbol, menerapkan lapisan embedding untuk setiap simbol dan memperoleh matriks embedding. Ketika hanya menyangkut simbol, dimensi matriks semacam itu kecil. Kemudian, konvolusi satu dimensi diterapkan pada matriks penyematan, seperti yang biasanya dilakukan dalam NLP, dengan penyatuan maksimum pada akhirnya, satu vektor diperoleh.
Jaringan jalan raya dua lapis yang disebut diterapkan pada vektor ini, yang menghitung
vektor umum suatu kata .
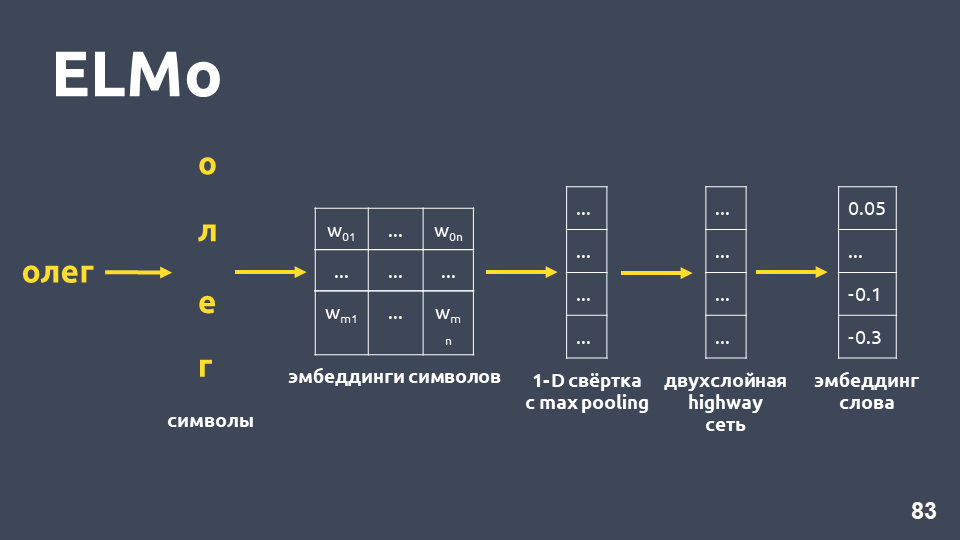
Selain itu, model ini akan membangun semacam hipotesis penanaman bahkan untuk kata yang tidak ditemukan dalam set pelatihan.
Setelah kami menerima embedding simbolis untuk setiap kata, kami menerapkan jaringan BiLSTM dua-lapisan untuk mereka.
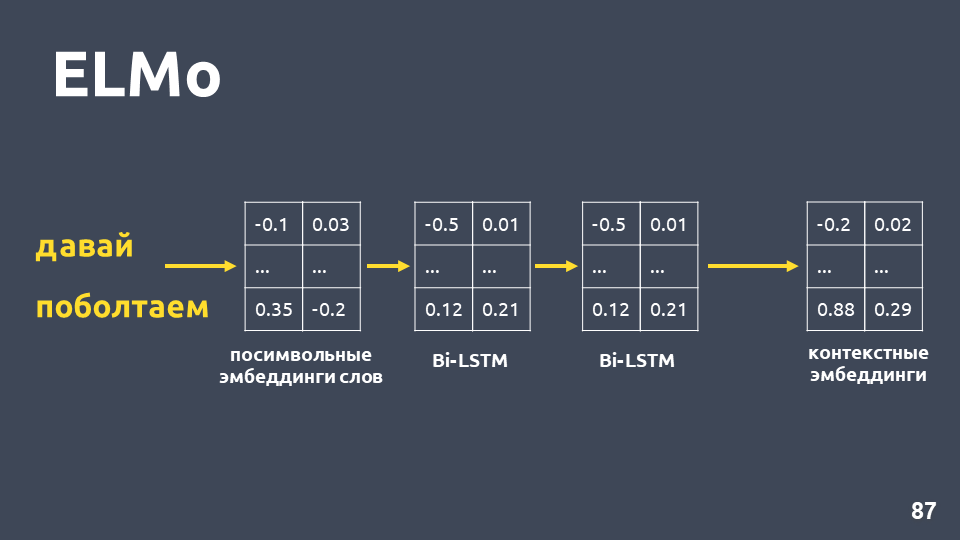
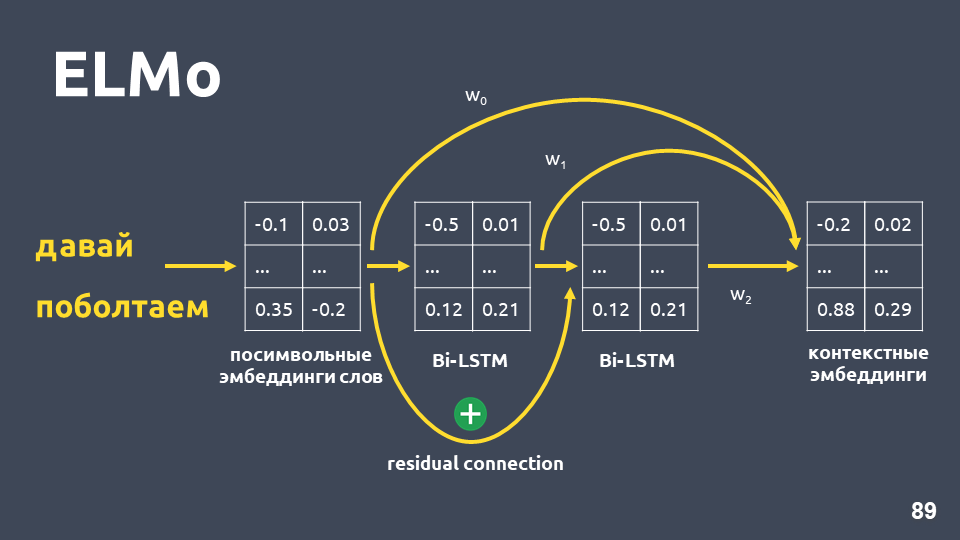
Setelah menerapkan jaringan dua lapis BiLSTM, biasanya status tersembunyi dari lapisan terakhir biasanya diambil, dan diyakini bahwa ini adalah penyematan kontekstual. Tetapi ELMo memiliki dua fitur:
- Koneksi residual antara input dari lapisan LSTM pertama dan outputnya. Input LSTM ditambahkan ke output untuk menghindari masalah gradien fading.
- Para penulis ELMo mengusulkan menggabungkan embedding simbolik untuk setiap kata, output dari lapisan LSTM pertama dan output dari lapisan LSTM kedua dengan beberapa bobot yang dipilih untuk setiap tugas. Ini diperlukan untuk mempertimbangkan fitur level rendah dan level tinggi yang memberikan LSTM lapisan pertama dan kedua.
Dalam masalah kami, kami menggunakan rata-rata sederhana dari ketiga embeddings ini dan dengan demikian memperoleh embedding kontekstual untuk setiap kata.
Model bahasa memberikan manfaat berikut:
- Vektor kata tergantung pada konteks di mana kata tersebut digunakan. Misalnya, untuk kata "bahasa" dalam arti bagian tubuh dan istilah linguistik, kita mendapatkan vektor yang berbeda.
- Seperti dalam kasus word2vec dan fasttext, ada banyak model yang terlatih, misalnya, dari proyek DeepPavlov . Anda dapat mengambil model yang sudah jadi dan mencoba menerapkannya dalam tugas Anda.
- Anda tidak perlu lagi memikirkan cara rata-rata vektor kata. Model ELMo segera menghasilkan vektor semua teks.
- Anda dapat melatih ulang model bahasa untuk tugas Anda, ada berbagai cara untuk ini, misalnya, ULMFiT.
Satu-satunya minus tetap -
model bahasa tidak menjamin bahwa teks-teks yang berasal dari kelas yang sama, yaitu, dengan satu maksud, akan dekat dalam ruang vektor.
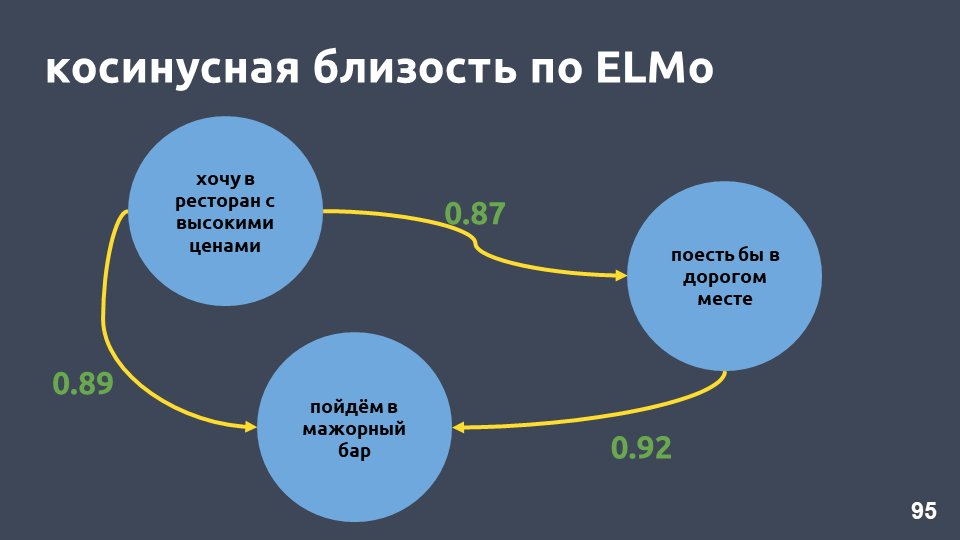
Dalam contoh restoran kami, nilai-nilai kosinus sesuai dengan model ELMo benar-benar menjadi lebih tinggi.
t-SNE pada ELMo (10 niat teratas), skor F1 0,93 (0,92 oleh tf-idf)Cluster dengan niat 10 besar juga lebih jelas. Pada gambar di atas, semua 10 kluster terlihat jelas, sementara akurasinya sedikit meningkat.
t-SNE pada ELMo (30 niat teratas) Skor F1 0,86 (0,85 oleh tf-idf)Untuk 30 niat teratas, struktur kluster masih dipertahankan, dan ada juga peningkatan kualitas sebesar satu poin.
Tetapi dalam model seperti itu tidak ada jaminan bahwa proposal "Dan jika Anda membuka deposito, apa yang menarik bagi mereka?" dan "Dan aku ingin membuka sumbangan dengan 7 persen" akan jauh dari satu sama lain, meskipun mereka berada di kelas yang berbeda. Dengan ELMo, kita cukup mempelajari model bahasa, dan jika teksnya mirip secara semantik, maka mereka akan dekat.
ELMo tidak tahu apa-apa tentang kelas kami , tetapi Anda dapat menyatukan vektor teks dengan maksud yang sama di ruang menggunakan label kelas.
Jaringan siam
Ambil arsitektur jaringan saraf favorit Anda untuk vektorisasi teks dan dua contoh niat. Untuk masing-masing contoh kita mendapatkan embeddings, dan kemudian kita menghitung jarak cosinus di antara mereka.
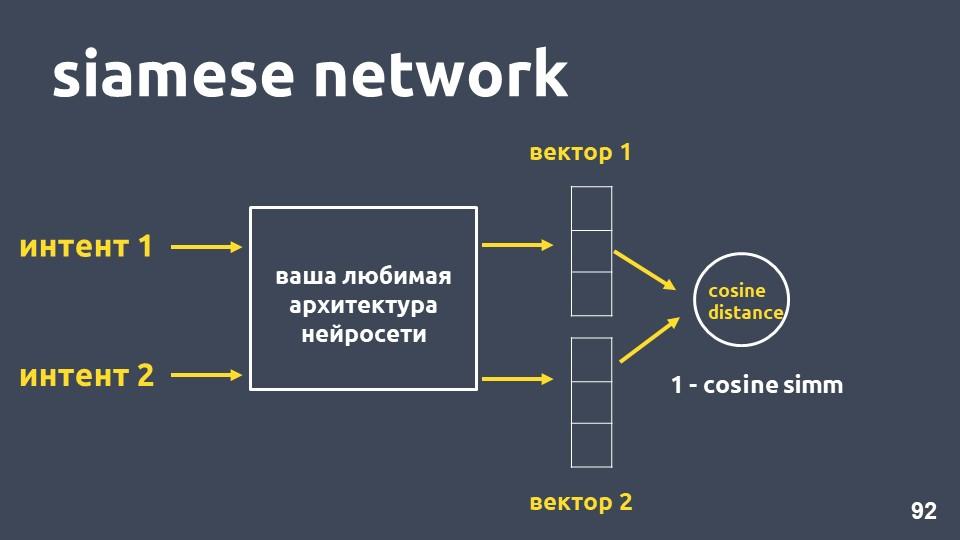
Jarak cosinus sama dengan satu minus kedekatan cosinus yang kita temui sebelumnya.
Pendekatan ini disebut
jaringan siam .
Kami ingin teks dari kelas yang sama, misalnya, "melakukan transfer" dan "membuang uang," untuk diletakkan dekat di ruang angkasa. Artinya, jarak cosinus antara vektor-vektor mereka harus sekecil mungkin, idealnya nol. Dan teks-teks yang berkaitan dengan niat yang berbeda harus terletak sejauh mungkin.
Namun dalam praktiknya, metode pelatihan ini tidak berfungsi dengan baik, karena objek dari kelas yang berbeda tidak cukup jauh satu sama lain. Fungsi kerugian yang disebut
"triplet loss" bekerja jauh lebih baik. Ini menggunakan tiga kali lipat benda yang disebut kembar tiga.
Ilustrasi menunjukkan triplet: objek jangkar dalam lingkaran biru, objek positif berwarna hijau dan objek negatif dalam lingkaran merah. Objek negatif dan jangkar berada di kelas yang berbeda, dan positif dan jangkar berada dalam satu kelas.

Kami ingin memastikan bahwa setelah pelatihan objek positif lebih dekat ke jangkar daripada yang negatif. Untuk melakukan ini, kami mempertimbangkan jarak kosinus antara pasangan benda dan memasukkan hyperparameter - "margin" - jarak yang kami harapkan berada antara benda positif dan negatif.

Fungsi kerugian terlihat seperti ini:
Dengan kata lain, selama pelatihan, kami mencapai bahwa objek positif lebih dekat ke jangkar daripada negatif, setidaknya margin. Jika fungsi kerugian adalah nol, maka berfungsi, dan kami menyelesaikan pelatihan, jika tidak kami terus meminimalkan fungsi tujuan.
Setelah kami melatih model, kami masih belum mendapatkan classifier, itu hanya metode untuk memperoleh embeddings sedemikian rupa sehingga objek yang terletak pada maksud yang sama cenderung memiliki vektor yang dekat.
Ketika kami mendapatkan model, kami dapat menggunakan metode klasifikasi yang berbeda di atas embeddings.
KNN sangat cocok, karena kami telah mencapai bahwa embeddings memiliki struktur cluster yang berbeda.
Ingat bagaimana kNN bekerja untuk teks: ambil elemen dari teks tersebut, dapatkan embedding untuknya, terjemahkan ke dalam ruang vektor, dan kemudian lihat siapa tetangganya. Di antara tetangga, kami mempertimbangkan kelas yang paling sering dan menyimpulkan bahwa objek baru milik kelas ini.
Dimensi embedding yang kami gunakan adalah 300, dan dalam sampel pelatihan ada sekitar 500.000 objek. Metode standar untuk menemukan tetangga terdekat tidak sesuai dengan kami dalam hal kinerja. Kami menggunakan metode
HNSW -
Hierarchical Navigable Small World .
Navigable Small World adalah grafik yang terhubung di mana ada beberapa tepi antara simpul yang berada pada jarak yang jauh, dan banyak tepi antara simpul terdekat. Dalam kasus kami, panjang tepi akan ditentukan oleh jarak cosinus, mis. , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
Ringkasan
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .