Baru-baru ini, produsen FPGA dan perusahaan pihak ketiga telah secara aktif mengembangkan metode pengembangan untuk FPGA yang berbeda dari pendekatan konvensional menggunakan alat pengembangan tingkat tinggi.
Sebagai pengembang FPGA, saya menggunakan bahasa deskripsi perangkat keras Verilog (
HDL ) sebagai alat utama, tetapi semakin populernya metode baru membangkitkan minat besar saya, jadi dalam artikel ini saya memutuskan untuk mencari tahu apa yang terjadi.
Artikel ini bukan panduan atau instruksi untuk digunakan, ini adalah ulasan dan kesimpulan saya tentang apa yang dapat diberikan berbagai alat pengembangan tingkat tinggi kepada pengembang atau programmer FPGA yang ingin terjun ke dunia FPGA. Untuk membandingkan alat pengembangan yang paling menarik menurut saya, saya menulis beberapa tes dan menganalisis hasilnya. Di bawah luka - apa yang terjadi.
Mengapa Anda membutuhkan alat pengembangan tingkat tinggi untuk FPGA?
- Mempercepat pengembangan proyek
- karena penggunaan kembali kode yang sudah ditulis dalam bahasa tingkat tinggi;
- Melalui penggunaan semua keunggulan bahasa tingkat tinggi, saat menulis kode dari awal;
- dengan mengurangi waktu kompilasi dan verifikasi kode.
- Kemampuan untuk membuat kode universal yang akan bekerja pada keluarga FPGA apa pun.
- Kurangi ambang pengembangan untuk FPGA, misalnya, menghindari konsep "frekuensi clock" dan entitas tingkat rendah lainnya. Kemampuan menulis kode untuk FPGA ke pengembang yang tidak terbiasa dengan HDL.
Dari mana datangnya alat pengembangan tingkat tinggi?
Sekarang banyak yang tertarik dengan gagasan pembangunan tingkat tinggi. Kedua penggemar, seperti, misalnya,
Quokka dan pembuat
kode Python , dan perusahaan, seperti
Mathworks , dan produsen FPGA
Intel dan
Xilinx terlibat dalam hal ini.
Setiap orang menggunakan metode dan alatnya untuk mencapai tujuannya. Penggemar dalam perjuangan untuk dunia yang sempurna dan indah menggunakan bahasa pengembangan favorit mereka, seperti Python atau C #. Perusahaan, berusaha menyenangkan klien, menawarkan alat mereka sendiri atau mengadaptasi yang ada. Mathworks menawarkan alat pembuat kode HDL sendiri untuk menghasilkan kode HDL dari model m-scripts dan Simulink, sementara Intel dan Xilinx menawarkan kompiler untuk C / C ++ yang umum.
Saat ini, perusahaan dengan sumber daya keuangan dan sumber daya manusia yang signifikan telah mencapai kesuksesan yang lebih besar, sementara penggemar agak di belakang. Artikel ini akan dikhususkan untuk pertimbangan produk HDL coder dari Mathworks dan HLS Compiler dari Intel.
Bagaimana dengan XilinxDalam artikel ini, saya tidak mempertimbangkan HIL dari Xilinx, karena arsitektur yang berbeda dan sistem CAD dari Intel dan Xilinx, yang membuatnya tidak mungkin untuk membuat perbandingan hasil yang jelas. Tetapi saya ingin mencatat bahwa Xilinx HLS, seperti Intel HLS, menyediakan kompiler C / C ++ dan secara konsep keduanya mirip.
Mari kita mulai membandingkan koder HDL dari Mathworks dan Intel HLS Compiler, setelah memecahkan beberapa masalah menggunakan pendekatan yang berbeda.
Perbandingan alat pengembangan tingkat tinggi
Tes satu. “Dua pengganda dan satu penambah”
Solusi untuk masalah ini tidak memiliki nilai praktis, tetapi sangat cocok sebagai tes pertama. Fungsi ini mengambil 4 parameter, mengalikan yang pertama dengan yang kedua, yang ketiga dengan yang keempat dan menambahkan hasil perkalian. Tidak ada yang rumit, tetapi mari kita lihat bagaimana subjek kita mengatasi hal ini.
HDL coder oleh Mathworks
Untuk mengatasi masalah ini, skrip-m terlihat sebagai berikut:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
Mari kita lihat apa yang ditawarkan Mathworks untuk mengubah kode menjadi HDL.
Saya tidak akan mempertimbangkan secara rinci pekerjaan dengan HDL-coder, saya hanya akan fokus pada pengaturan yang akan saya ubah di masa depan untuk mendapatkan hasil yang berbeda dalam FPGA, dan perubahannya harus dipertimbangkan oleh programmer MATLAB yang perlu menjalankan kodenya dalam FPGA.
Jadi, hal pertama yang harus dilakukan adalah mengatur jenis dan rentang nilai input. Tidak ada char, int, float, double di FPGA. Kedalaman bit angka dapat berupa apa saja, logis untuk memilihnya, berdasarkan rentang nilai input yang Anda rencanakan untuk digunakan.
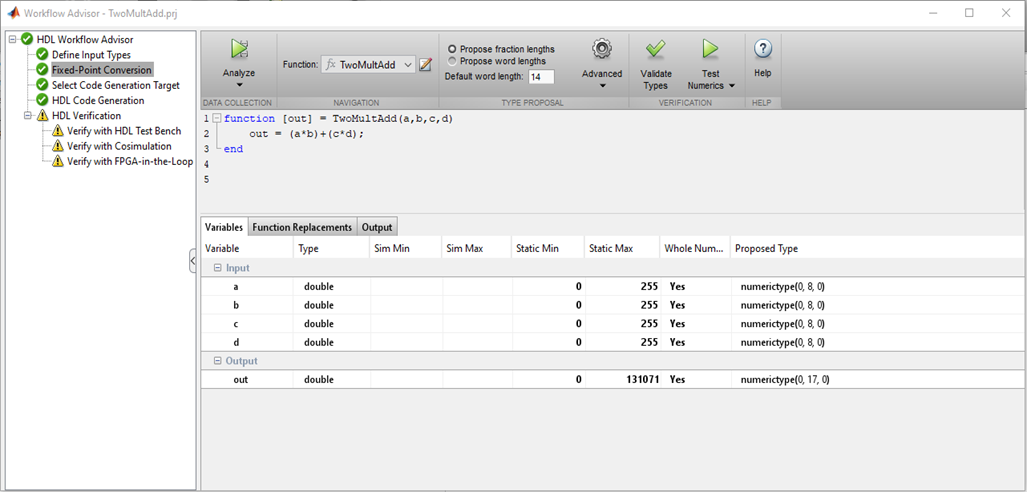 Gambar 1
Gambar 1MATLAB memeriksa jenis variabel, nilainya dan memilih ukuran bit yang benar untuk bus dan register, yang benar-benar nyaman. Jika tidak ada masalah dengan kedalaman bit dan pengetikan, Anda dapat melanjutkan ke poin-poin berikut.
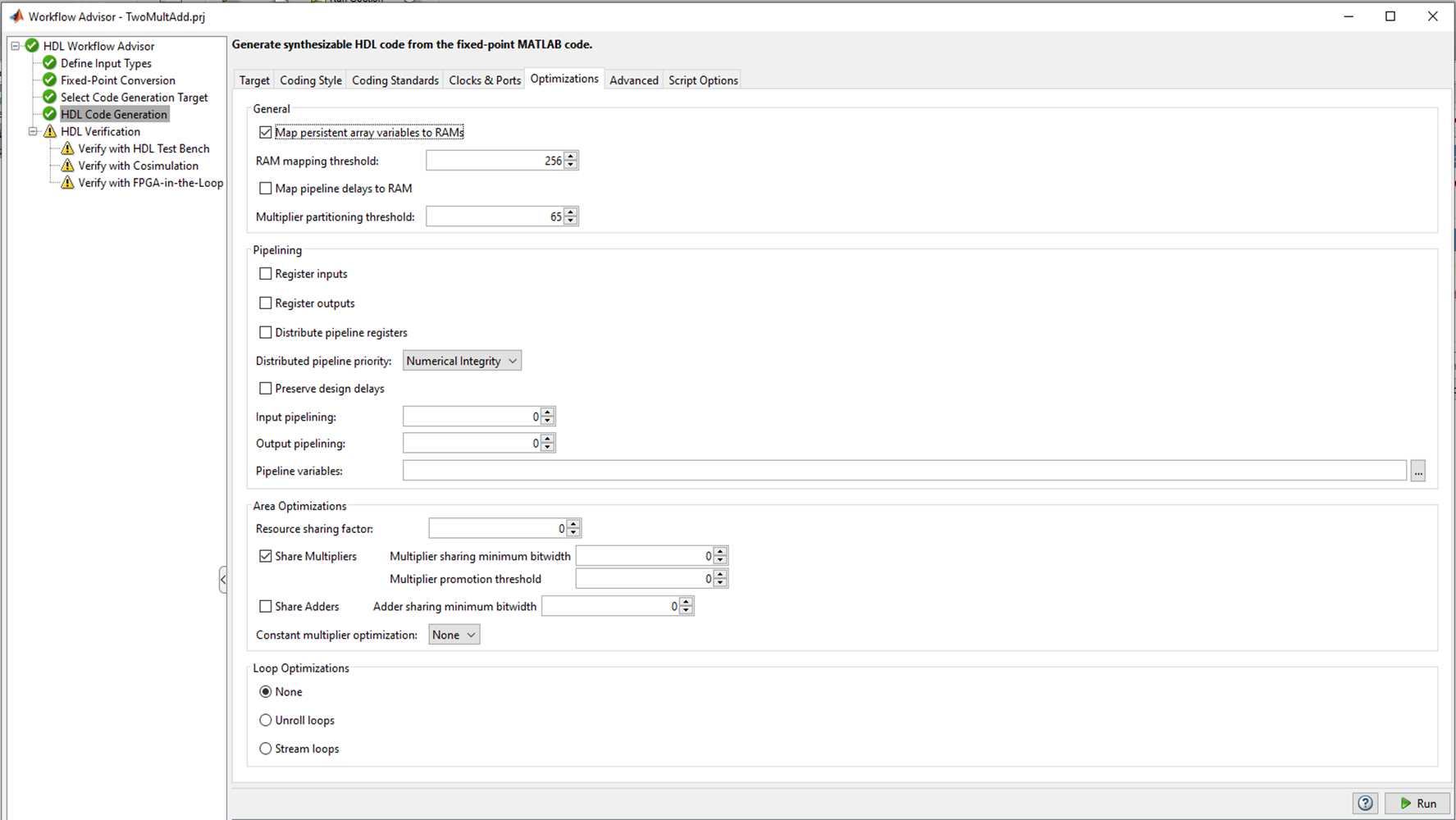 Gambar 2
Gambar 2Ada beberapa tab dalam Pembuatan Kode HDL tempat Anda dapat memilih bahasa yang akan dikonversi (Verilog atau VHDL); gaya kode nama-nama sinyal. Tab yang paling menarik, menurut saya, adalah Optimasi, dan saya akan bereksperimen dengannya, tetapi nanti, untuk sekarang, mari kita tinggalkan semua default dan lihat apa yang terjadi dengan HDL coder “out of the box”.
Tekan tombol Run dan dapatkan kode berikut:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
Kode terlihat bagus. MATLAB memahami bahwa menulis seluruh ekspresi pada satu baris di Verilog adalah praktik yang buruk. Membuat
kabel terpisah untuk pengganda dan penambah, tidak ada yang perlu dikeluhkan.
Sangat mengkhawatirkan bahwa deskripsi register tidak ada. Ini terjadi karena kami tidak meminta HDL-coder tentang ini, dan membiarkan semua bidang dalam pengaturan ke nilai standarnya.
Inilah yang disintesis Quartus dari kode tersebut.
 Gambar 3
Gambar 3Tidak masalah, semuanya sesuai rencana.
Dalam FPGA kami menerapkan sirkuit sinkron, dan saya masih ingin melihat register. HDL-coder menawarkan mekanisme untuk menempatkan register, tetapi di mana menempatkannya tergantung pada pengembang. Kita dapat menempatkan register pada input pengganda, pada keluaran pengganda di depan penambah, atau pada keluaran penambah.
Untuk mensintesis contoh, saya memilih keluarga FPGA Cyclone V, di mana blok DSP khusus dengan built-in adders dan multipliers digunakan untuk mengimplementasikan operasi aritmatika. Blok DSP terlihat seperti ini:
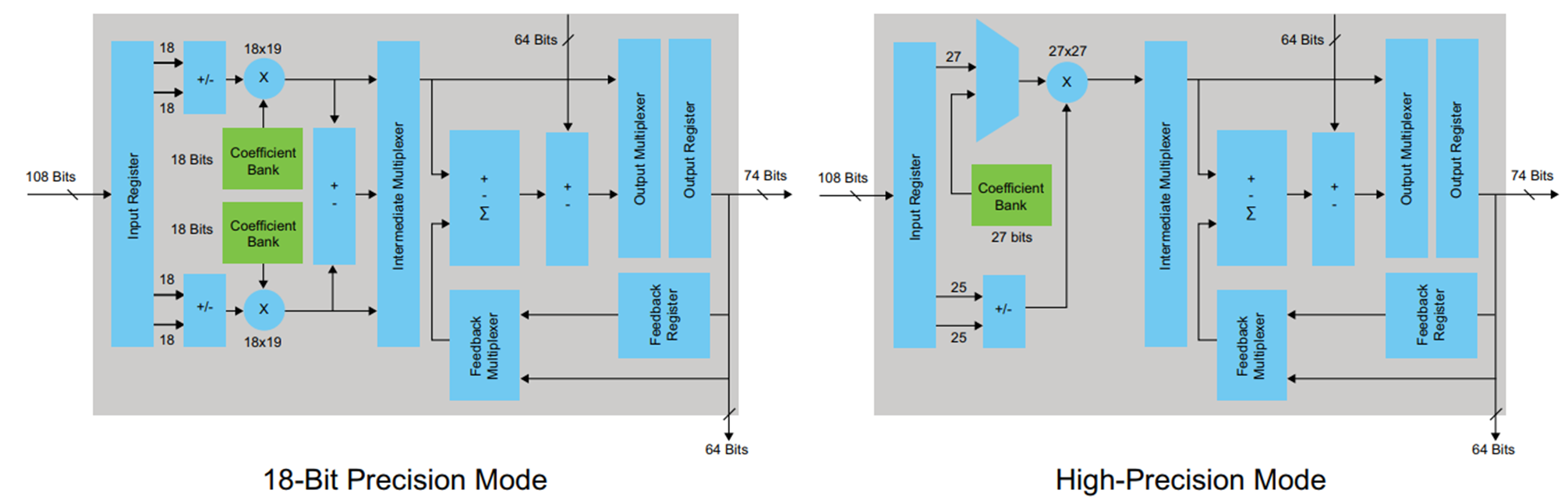 Gambar 4
Gambar 4Blok DSP memiliki register input dan output. Tidak perlu mencoba menjepret hasil perkalian dalam register sebelum penambahan, ini hanya akan melanggar arsitektur (dalam kasus tertentu, opsi ini mungkin dan bahkan diperlukan). Terserah pengembang untuk memutuskan bagaimana menangani input dan output register berdasarkan pada persyaratan latensi dan frekuensi maksimum yang diperlukan. Saya memutuskan untuk hanya menggunakan register keluaran. Agar register ini dijelaskan dalam kode yang dihasilkan oleh HDL-coder, pada tab Options di HDL coder Anda perlu memeriksa kotak centang Register output dan memulai kembali konversi.
Ternyata kode berikut:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
Seperti yang Anda lihat, kode memiliki perbedaan mendasar dibandingkan dengan versi sebelumnya. Blok selalu muncul, yang merupakan deskripsi register (hanya apa yang kita inginkan). Untuk operasi selalu-blok, input dari modul CLK (frekuensi clock) dan reset (reset) juga muncul. Dapat dilihat bahwa output dari penambah terkunci pada pemicu yang dijelaskan dalam selalu. Ada juga beberapa sinyal izin ena, tetapi mereka tidak terlalu menarik bagi kami.
Mari kita lihat diagram yang sekarang disintesis Quartus.
 Gambar 5
Gambar 5Dan lagi, hasilnya bagus dan diharapkan.
Tabel di bawah ini menunjukkan tabel sumber daya yang digunakan - kami selalu mengingatnya.
 Gambar 6
Gambar 6Untuk pencarian pertama ini, Mathworks menerima kredit. Semuanya tidak rumit, dapat diprediksi dan dengan hasil yang diinginkan.
Saya menjelaskan secara rinci contoh sederhana, memberikan diagram blok DSP, dan menjelaskan kemungkinan menggunakan pengaturan penggunaan register dalam HDL-coder, yang berbeda dari pengaturan "default". Ini dilakukan karena suatu alasan. Dengan ini saya ingin menekankan bahwa bahkan dalam contoh sederhana seperti itu, ketika menggunakan HDL-coder, pengetahuan tentang arsitektur FPGA dan dasar-dasar sirkuit digital diperlukan, dan pengaturan harus diubah secara sadar.
Intel HLS Compiler
Mari kita coba mengkompilasi kode dengan fungsi yang sama yang ditulis dalam C ++ dan melihat apa yang akhirnya disintesis dalam FPGA menggunakan kompiler HLS.
Jadi kode C ++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
Saya memilih tipe data untuk menghindari variabel yang meluap.
Ada metode canggih untuk mengatur kedalaman bit, tetapi tujuan kami adalah menguji kemampuan untuk merakit fungsi yang ditulis dalam gaya C / C ++ di bawah FPGA tanpa membuat perubahan apa pun, semuanya keluar dari kotak.
Karena kompiler HLS adalah alat asli Intel, kami mengumpulkan kode dengan kompiler khusus dan segera memeriksa hasilnya di Quartus.
Mari kita lihat sirkuit yang disintesis Quartus.
 Gambar 7
Gambar 7Kompiler membuat register pada input dan output, tetapi esensinya tersembunyi dalam modul wrapper. Kami mulai menggunakan bungkus dan ... melihat lebih banyak, lebih banyak modul bersarang.
Struktur proyek terlihat seperti ini.
 Gambar 8
Gambar 8Petunjuk yang jelas dari Intel adalah "jangan lakukan itu!". Tapi kami akan coba, terutama fungsinya tidak rumit.
Di perut pohon proyek | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 adalah modul yang Anda cari.
Kita dapat melihat diagram dari modul yang diinginkan yang disintesis oleh Quartus.
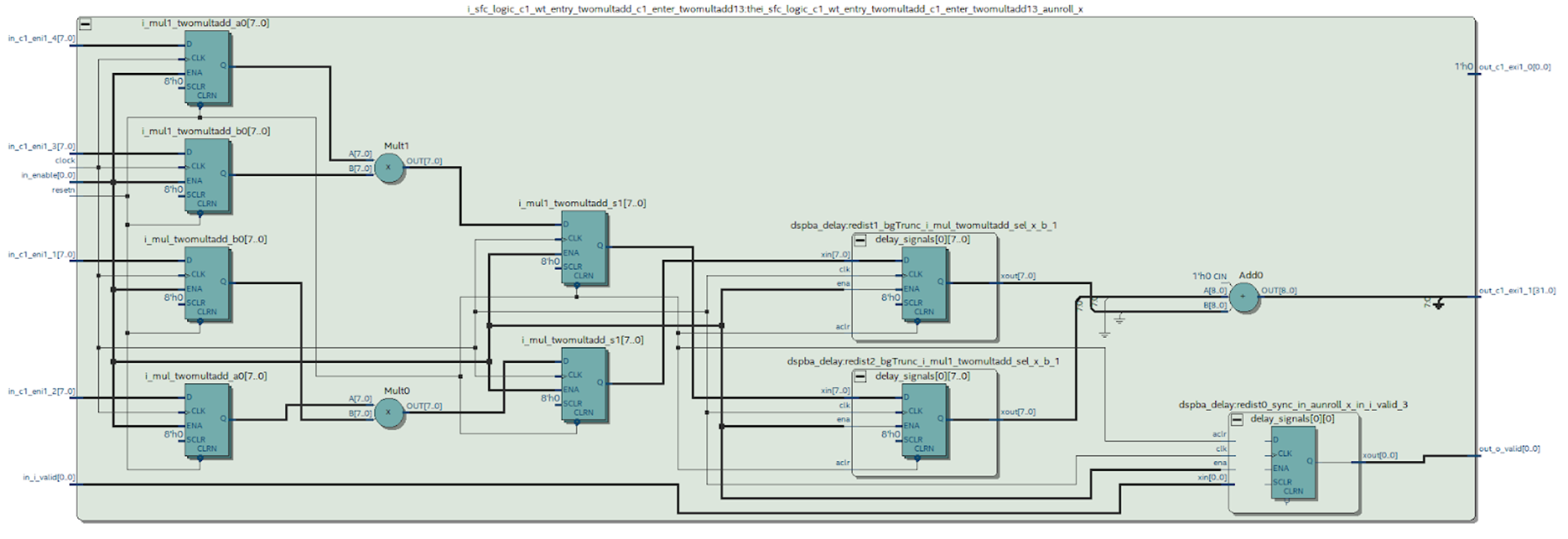 Gambar 9
Gambar 9Kesimpulan apa yang bisa ditarik dari skema ini.
Jelaslah bahwa sesuatu terjadi yang kami coba hindari ketika bekerja di MATLAB: kasing pada keluaran dari pengali disintesis - ini tidak terlalu baik. Dapat dilihat dari diagram blok DSP (Gambar 4) bahwa hanya ada satu register pada outputnya, yang berarti bahwa setiap perkalian harus dilakukan dalam blok yang terpisah.
Tabel sumber daya yang digunakan menunjukkan apa yang menyebabkan hal ini.
 Gambar 10
Gambar 10Bandingkan hasilnya dengan tabel koder HDL (Gambar 6).
Jika menggunakan register dalam jumlah yang lebih besar, maka menghabiskan blok DSP yang berharga untuk fungsi sederhana seperti itu sangat tidak menyenangkan.
Tetapi ada nilai tambah besar di Intel HLS dibandingkan dengan HDL coder. Dengan pengaturan default, kompiler HLS mengembangkan desain sinkron dalam FPGA, meskipun menghabiskan lebih banyak sumber daya. Arsitektur seperti itu mungkin, jelas bahwa Intel HLS dikonfigurasikan untuk mencapai kinerja maksimum, dan bukan untuk menghemat sumber daya.
Mari kita lihat bagaimana subjek kita berperilaku dengan proyek yang lebih kompleks.
Tes kedua. “Penggandaan matriks secara elemen dengan penjumlahan dari hasil”
Fungsi ini banyak digunakan dalam pemrosesan gambar: yang disebut
"filter matriks" . Kami menjualnya menggunakan alat tingkat tinggi.
HDL coder oleh Mathwork
Pekerjaan segera dimulai dengan batasan. HDL Coder tidak dapat menerima fungsi matriks 2-D sebagai input. Mengingat bahwa MATLAB adalah alat untuk bekerja dengan matriks, ini merupakan pukulan serius untuk seluruh kode yang diwarisi, yang dapat menjadi masalah serius. Jika kode ditulis dari awal, ini adalah fitur yang tidak menyenangkan yang harus dipertimbangkan. Jadi, Anda harus menggunakan semua matriks ke dalam vektor dan mengimplementasikan fungsi dengan memperhitungkan vektor input.
Kode untuk fungsi di MATLAB adalah sebagai berikut
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
Kode HDL yang dihasilkan ternyata sangat membengkak dan berisi ratusan baris, jadi saya tidak akan memberikannya di sini. Mari kita lihat skema apa yang disintesis Quartus dari kode ini.
 Gambar 11
Gambar 11Skema ini terlihat tidak berhasil. Secara formal, ini berfungsi, tetapi saya berasumsi bahwa itu akan bekerja pada frekuensi yang sangat rendah, dan hampir tidak dapat digunakan pada perangkat keras nyata. Tetapi asumsi apa pun harus diverifikasi. Untuk melakukan ini, kami akan menempatkan register pada input dan output dari rangkaian ini dan dengan bantuan Timing Analyzer kami akan mengevaluasi situasi sebenarnya. Untuk melakukan analisis, Anda harus menentukan frekuensi operasi yang diinginkan dari sirkuit sehingga Quartus tahu apa yang harus diperjuangkan ketika kabel, dan jika terjadi kegagalan, memberikan laporan pelanggaran.
Kami mengatur frekuensinya menjadi 100 MHz, mari kita lihat apa yang bisa Quartus peras dari rangkaian yang diusulkan.
 Gambar 12
Gambar 12Dapat dilihat bahwa ternyata sedikit: 33 MHz terlihat sembrono. Keterlambatan dalam rantai pengganda dan pengaya adalah sekitar 30 ns. Untuk menghilangkan "bottleneck" ini, Anda perlu menggunakan conveyor: masukkan register setelah operasi aritmatika, sehingga mengurangi jalur kritis.
HDL coder memberi kita kesempatan ini. Di tab Opsi, Anda bisa mengatur variabel Pipeline. Karena kode yang dimaksud ditulis dalam gaya MATLAB, tidak ada cara untuk menyalurkan variabel (kecuali variabel mult dan jumlah), yang tidak sesuai dengan kita. Penting untuk memasukkan register ke sirkuit perantara yang tersembunyi dalam kode HDL kami.
Apalagi situasi dengan optimasi bisa lebih buruk. Misalnya, tidak ada yang mencegah kita dari menulis kode
out = (sum(target.*kernel))/len;
ini cukup memadai untuk MATLAB, tetapi benar-benar menghalangi kita dari kemungkinan mengoptimalkan HDL.
Jalan keluar selanjutnya adalah mengedit kode dengan tangan. Ini adalah poin yang sangat penting, karena kami menolak untuk mewarisi dan mulai menulis ulang skrip-m, dan BUKAN dengan gaya MATLAB.
Kode baru adalah sebagai berikut
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
Di Quartus, kami mengumpulkan kode yang dihasilkan oleh HDL Coder. Dapat dilihat bahwa jumlah lapisan dengan primitif telah menurun, dan skema terlihat jauh lebih baik.
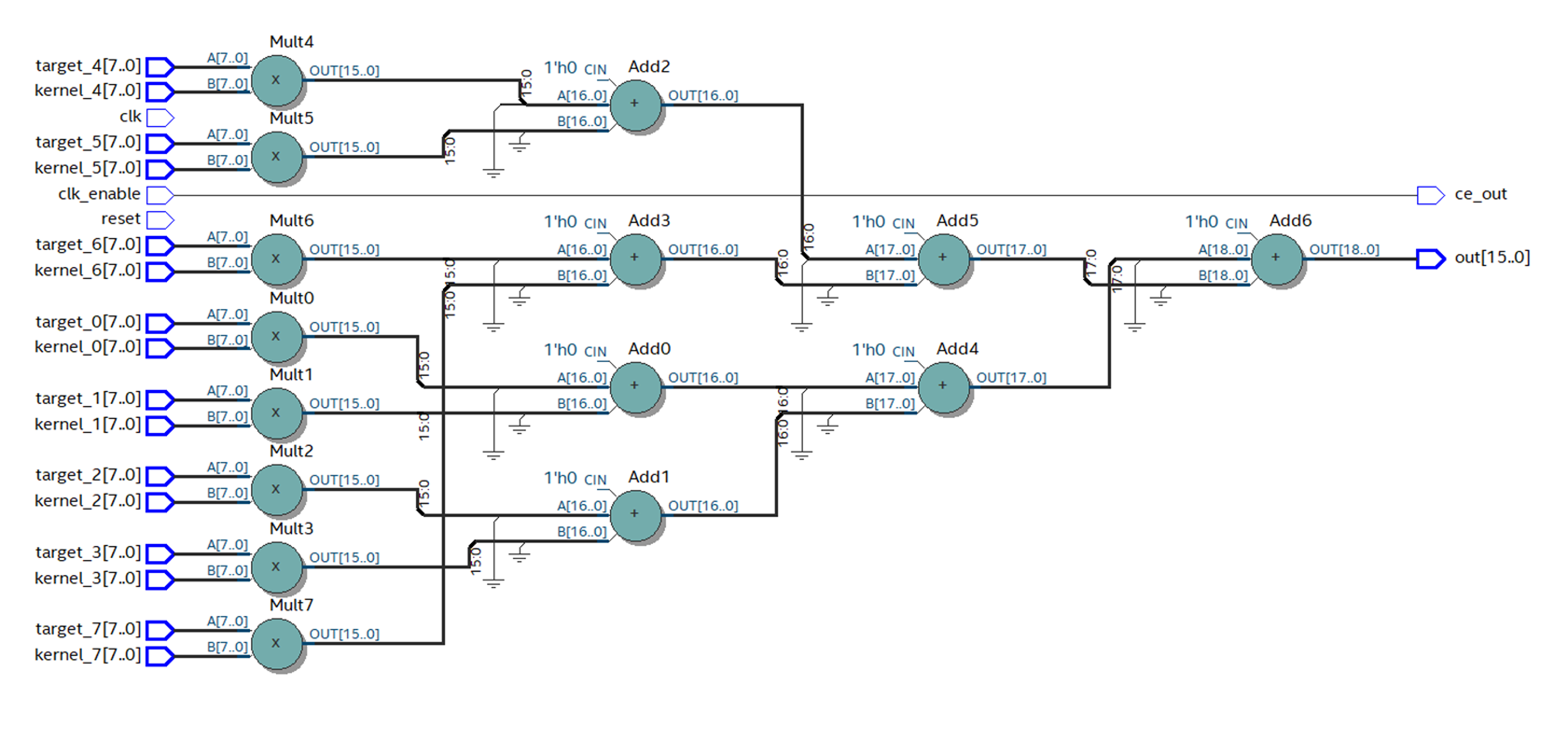 Gambar 12
Gambar 12Dengan tata letak primitif yang benar, frekuensi tumbuh hampir 3 kali, hingga 88 MHz.
 Gambar 13
Gambar 13Sekarang sentuhan terakhir: di pengaturan Optimasi, tentukan sum_1, summ_2 dan summ_3 sebagai elemen dari pipeline. Kami mengumpulkan kode yang dihasilkan di Quartus. Skema berubah sebagai berikut:
 Gambar 14
Gambar 14Frekuensi maksimum meningkat lagi dan sekarang nilainya sekitar 195 MHz.
 Gambar 15
Gambar 15Berapa banyak sumber daya pada chip akan mengambil desain seperti itu? Gambar 16 menunjukkan tabel sumber daya yang digunakan untuk kasus yang dijelaskan.
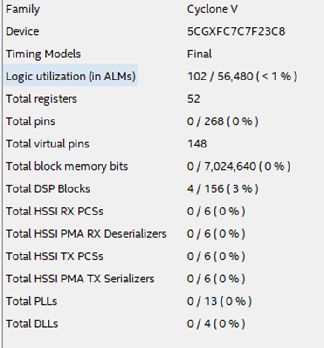 Gambar 16
Gambar 16Kesimpulan apa yang bisa ditarik setelah mempertimbangkan contoh ini?
Kerugian utama dari HDL coder adalah tidak mungkin menggunakan kode MATLAB dalam bentuk murni.
Tidak ada dukungan untuk matriks sebagai input fungsi, tata letak kode dalam gaya MATLAB biasa-biasa saja.
Bahaya utama adalah kurangnya register dalam kode yang dihasilkan tanpa pengaturan tambahan. Tanpa register-register ini, bahkan setelah menerima kode HDL yang berfungsi secara resmi tanpa kesalahan sintaksis, penggunaan kode semacam itu dalam realitas dan perkembangan modern tidak diinginkan.
Dianjurkan untuk segera menulis kode yang dipertajam untuk konversi ke HDL. Dalam hal ini, Anda bisa mendapatkan hasil yang cukup dapat diterima dalam hal kecepatan dan intensitas sumber daya.
Jika Anda seorang pengembang MATLAB, jangan buru-buru mengklik tombol Jalankan dan kompilasi kode Anda di bawah FPGA, ingatlah bahwa kode Anda akan disintesis menjadi rangkaian nyata. =)
Intel HLS Compiler
Untuk fungsi yang sama, saya menulis kode C / C ++ berikut
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
Hal pertama yang menarik perhatian Anda adalah jumlah sumber daya yang digunakan.
 Gambar 17
Gambar 17Dapat dilihat dari tabel bahwa hanya 1 blok DSP yang digunakan, sehingga terjadi kesalahan, dan perkalian tidak dilakukan secara paralel. Jumlah register yang digunakan juga mengejutkan, dan bahkan melibatkan memori, tetapi kami akan menyerahkan ini kepada hati nurani dari kompiler HLS.
Perlu dicatat bahwa kompiler HLS telah mengembangkan sub-optimal, menggunakan sejumlah besar sumber daya tambahan, tetapi masih merupakan sirkuit kerja yang, menurut laporan Quartus, akan bekerja pada frekuensi yang dapat diterima, dan kegagalan seperti koder HDL tidak akan.
 Gambar 18
Gambar 18Mari kita coba untuk memperbaiki situasi. Apa yang dibutuhkan untuk ini? Itu benar, tutup mata Anda untuk warisan dan merangkak ke dalam kode, tetapi untuk saat ini, hanya sedikit.
HLS memiliki arahan khusus untuk mengoptimalkan kode untuk FPGA. Kami memasukkan arahan membuka gulungan, yang akan memperluas loop kami secara paralel:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
Mari kita lihat bagaimana reaksi Quartus terhadapnya
 Gambar 19
Gambar 19Pertama-tama, perhatikan jumlah blok DSP - ada 16 di antaranya, yang berarti bahwa perkalian dilakukan secara paralel.
Hore! membuka gulungan bekerja! Tetapi sudah sulit untuk bertahan dengan seberapa banyak pemanfaatan sumber daya lain telah tumbuh. Sirkuit menjadi benar-benar tidak dapat dibaca.
 Gambar 20
Gambar 20Saya percaya ini karena fakta bahwa tidak ada yang menunjukkan kepada kompiler bahwa perhitungan dalam angka-angka tetap cukup cocok untuk kita, dan dia dengan jujur menerapkan semua matematika titik-mengambang pada logika dan register. Kita perlu menjelaskan kepada kompiler apa yang diperlukan, dan untuk ini kita kembali memasukkan kode.
Untuk tujuan menggunakan titik tetap, kelas template diimplementasikan.
 Gambar 21
Gambar 21Berbicara dengan kata-kata kami sendiri, kami dapat menggunakan variabel yang kedalaman bitnya diatur secara manual hingga sedikit. Bagi mereka yang menulis dalam HDL, Anda tidak dapat membiasakan diri dengannya, tetapi para programmer C / C ++ mungkin akan berusaha keras. Kedalaman bit, seperti pada MATLAB, dalam hal ini, tidak ada yang akan memberi tahu, dan pengembang sendiri harus menghitung jumlah bit.
Mari kita lihat tampilannya dalam praktik.
Kami mengedit kode sebagai berikut:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
Dan alih-alih pasta menyeramkan dari Gambar 20, kita mendapatkan keindahan ini:
 Gambar 22
Gambar 22Sayangnya, sesuatu yang aneh terus terjadi dengan sumber daya yang digunakan.
 Gambar 23
Gambar 23Tetapi tinjauan terperinci atas laporan menunjukkan bahwa modul yang menarik bagi kita secara langsung terlihat lebih dari cukup:
 Gambar 24
Gambar 24Konsumsi register dan memori blok yang sangat besar dikaitkan dengan sejumlah besar modul periferal. Saya masih belum sepenuhnya memahami makna mendalam dari keberadaan mereka, dan ini perlu diselesaikan, tetapi masalahnya selesai. Dalam kasus ekstrem, Anda dapat dengan hati-hati memotong satu modul yang menarik bagi kami dari struktur umum proyek, yang akan menyelamatkan kami dari modul periferal yang menghabiskan sumber daya.
Tes ketiga. “Transisi dari RGB ke HSV”
Mulai menulis artikel ini, saya tidak berharap itu menjadi sangat produktif. Tapi saya tidak bisa menolak yang ketiga dan terakhir dalam kerangka artikel ini, contohnya.
Pertama, ini adalah contoh nyata dari praktik saya, dan karena itulah saya mulai mencari alat pengembangan tingkat tinggi.
Kedua, dari dua contoh pertama, kita dapat membuat asumsi bahwa semakin kompleks desain, semakin buruk alat tingkat tinggi mengatasi tugas tersebut.
Saya ingin menunjukkan bahwa penilaian ini keliru, dan pada kenyataannya, semakin kompleks tugasnya, semakin banyak keuntungan dari alat pengembangan tingkat tinggi terwujud.
Tahun lalu, ketika mengerjakan salah satu proyek, saya tidak suka kamera yang dibeli di Aliexpress, yaitu, warnanya tidak cukup jenuh. Salah satu cara populer untuk memvariasikan saturasi warna adalah beralih dari ruang warna RGB ke ruang HSV, di mana salah satu parameternya adalah saturasi. Saya ingat bagaimana saya membuka formula transisi dan mengambil napas dalam-dalam ... Menerapkan perhitungan seperti itu di FPGA bukanlah sesuatu yang luar biasa, tetapi tentu saja akan memakan waktu untuk menulis kode. Jadi, rumus untuk beralih dari RGB ke HSV adalah sebagai berikut:
 Gambar 25
Gambar 25Implementasi algoritma seperti itu di FPGA tidak akan memakan waktu berhari-hari, tetapi berjam-jam, dan semua ini harus dilakukan dengan sangat hati-hati karena spesifikasi HDL, dan implementasi dalam C ++ atau di MATLAB akan memakan waktu, saya pikir, beberapa menit.
Di C ++, Anda dapat menulis kode langsung di dahi dan masih mendapatkan hasil yang baik.
Saya menulis opsi berikut di C ++
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
Dan Quartus berhasil mengimplementasikan hasilnya, seperti dapat dilihat dari tabel sumber daya yang digunakan.
 Gambar 26
Gambar 26Frekuensinya sangat bagus.
 Gambar 27
Gambar 27Dengan HDL coder, segalanya menjadi sedikit lebih rumit.
Agar tidak mengembang artikel, saya tidak akan menyediakan skrip-m untuk tugas ini, seharusnya tidak menyebabkan kesulitan. Sebuah m-script yang ditulis di dahi hampir tidak dapat berhasil digunakan, tetapi jika Anda mengedit kode dan menentukan tempat pipelining dengan benar, kami mendapatkan hasil yang baik. Ini, tentu saja, akan memakan waktu beberapa puluh menit, tetapi bukan jam.
Dalam C ++, juga diinginkan untuk mengatur arahan dan menerjemahkan perhitungan ke titik tetap, yang juga akan memakan waktu sangat sedikit.Jadi, menggunakan alat pengembangan tingkat tinggi, kami menghemat waktu, dan semakin kompleks algoritme, semakin banyak waktu yang dihemat - ini akan terus berlanjut hingga kami mengalami batas sumber daya FPGA atau batas kecepatan komputasi yang ketat di mana Anda harus menangani HDL.Kesimpulan
Apa yang bisa dikatakan sebagai kesimpulan.Jelas, palu emas belum ditemukan, tetapi ada alat tambahan yang dapat digunakan dalam pengembangan.Keuntungan utama alat tingkat tinggi, menurut pendapat saya, adalah kecepatan pengembangan. Adalah kenyataan untuk mendapatkan kualitas yang cukup dalam hal waktu, terkadang urutan besarnya lebih kecil daripada ketika mengembangkan menggunakan HDL.Saya waspada terhadap keuntungan seperti menggunakan kode lama untuk FPGA dan menghubungkan ke pengembangan untuk programmer FPGA tanpa persiapan awal. Untuk mendapatkan hasil yang memuaskan, Anda harus meninggalkan banyak teknik pemrograman yang sudah dikenal.Sekali lagi, saya ingin mencatat bahwa artikel ini hanyalah tampilan dangkal pada alat pengembangan tingkat tinggi untuk FPGA.Kompiler HLS memiliki peluang besar untuk optimasi: pragma, perpustakaan khusus dengan fungsi yang dioptimalkan, deskripsi antarmuka, banyak artikel di Internet tentang “praktik terbaik”, dll. Chip MATLAB, yang belum dipertimbangkan, adalah kemampuan untuk secara langsung menghasilkan, misalnya, filter dari GUI tanpa menulis satu baris kode, hanya menunjukkan karakteristik yang diinginkan, yang selanjutnya mempercepat waktu pengembangan.Siapa yang memenangkan studi hari ini? Pendapat saya adalah kompiler HLS Intel. Ini menghasilkan desain yang berfungsi bahkan dari kode yang tidak dioptimalkan. HDL coder tanpa analisis yang cermat dan pemrosesan kode saya akan takut untuk menggunakannya. Saya juga ingin mencatat bahwa HDL coder adalah alat yang cukup lama, tetapi seperti yang saya tahu, itu belum mendapatkan pengakuan luas. Tapi HLS, meskipun muda, jelas bahwa produsen FPGA bertaruh, saya pikir kita akan melihat perkembangan lebih lanjut dan pertumbuhan popularitas.Perwakilan Xilinx memastikan bahwa pengembangan dan implementasi alat tingkat tinggi adalah satu-satunya peluang di masa depan untuk mengembangkan chip FPGA yang lebih besar dan lebih besar. Alat tradisional tidak akan mampu mengatasinya, dan Verilog / VHDL mungkin ditakdirkan untuk assembler, tetapi ini di masa depan. Dan sekarang kita memiliki alat pengembangan tangan (dengan pro dan kontra), yang harus kita pilih berdasarkan tugas.Apakah saya akan menggunakan alat pengembangan tingkat tinggi dalam pekerjaan saya? Sebaliknya, ya, sekarang perkembangan mereka berjalan dengan cepat, jadi kita setidaknya harus mengikuti, tetapi saya tidak melihat alasan obyektif untuk segera meninggalkan HDL.Pada akhirnya, saya ingin mencatat sekali lagi bahwa pada tahap pengembangan alat desain tingkat tinggi ini, pengguna tidak boleh lupa sejenak bahwa ia menulis sebuah program yang tidak dapat dieksekusi dalam prosesor, tetapi membuat sirkuit dengan kabel, pemicu, dan elemen logika nyata.