Baru-baru ini,
sebuah artikel telah dirilis yang menunjukkan tren pembelajaran mesin yang bagus dalam beberapa tahun terakhir. Singkatnya: jumlah startup di bidang pembelajaran mesin telah menurun tajam dalam dua tahun terakhir.
Baiklah apa. Mari kita analisis "apakah gelembung itu pecah", "bagaimana melanjutkan hidup" dan berbicara tentang dari mana keributan itu berasal.
Pertama, mari kita bicara tentang apa yang menjadi pendorong kurva ini. Dari mana asalnya. Mungkin semua orang akan mengingat
kemenangan pembelajaran mesin pada 2012 di kontes ImageNet. Bagaimanapun, ini adalah acara global pertama! Namun kenyataannya tidak demikian. Dan pertumbuhan kurva dimulai sedikit lebih awal. Saya akan memecahnya menjadi beberapa poin.
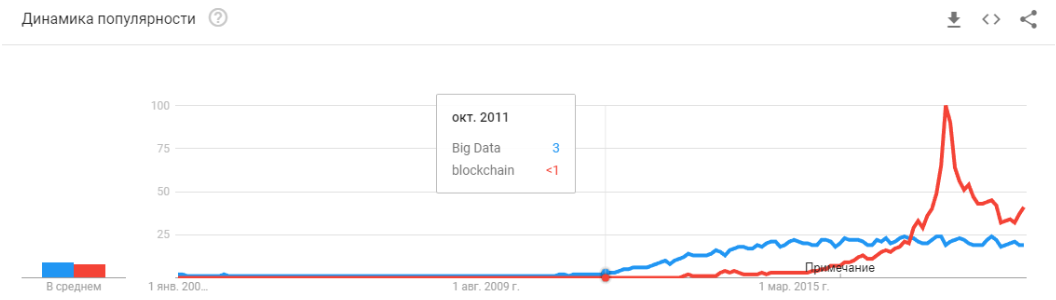
- 2008 adalah munculnya istilah "data besar." Produk nyata mulai muncul pada 2010. Data besar terkait langsung dengan pembelajaran mesin. Tanpa data besar, operasi stabil dari algoritma yang ada pada saat itu tidak mungkin. Dan ini bukan jaringan saraf. Hingga 2012, jaringan saraf adalah banyak minoritas marginal. Tetapi kemudian algoritma yang benar-benar berbeda mulai bekerja, yang telah ada selama bertahun-tahun, atau bahkan beberapa dekade: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... Permulaan tahun-tahun tersebut terutama terkait dengan pemrosesan otomatis data terstruktur : kantor tiket, pengguna, iklan, banyak lagi.
Turunan dari gelombang pertama ini adalah serangkaian kerangka kerja seperti XGBoost, CatBoost, LightGBM, dll.
- Pada 2011-2012, jaringan saraf convolutional memenangkan serangkaian kontes pengenalan gambar. Penggunaan sebenarnya agak tertunda. Saya akan mengatakan bahwa startup dan solusi yang sangat berarti mulai muncul pada tahun 2014. Butuh dua tahun untuk mencerna bahwa neuron masih bekerja, untuk membuat kerangka kerja yang nyaman yang dapat dipasang dan dijalankan dalam jumlah waktu yang wajar, untuk mengembangkan metode yang akan menstabilkan dan mempercepat waktu konvergensi.
Jaringan konvolusional memungkinkan untuk menyelesaikan masalah penglihatan mesin: klasifikasi gambar dan objek dalam gambar, deteksi objek, pengenalan objek dan orang, peningkatan gambar, dll., Dll. - 2015-2017 tahun. Boom algoritma dan proyek terkait dengan jaringan berulang atau analognya (LSTM, GRU, TransformerNet, dll.). Algoritme ucapan-ke-teks yang berfungsi dengan baik dan sistem terjemahan mesin telah muncul. Sebagian, mereka didasarkan pada jaringan konvolusional untuk menyoroti fitur dasar. Sebagian karena fakta bahwa mereka belajar mengumpulkan kumpulan data yang sangat besar dan bagus.
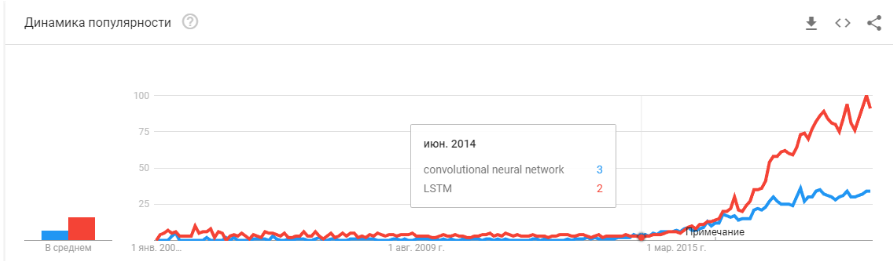
"Apakah gelembungnya pecah?" Apakah Hype terlalu panas? Apakah mereka mati seperti blockchain? "
Baiklah kalau begitu! Besok Siri akan berhenti bekerja di ponsel Anda, dan lusa Tesla tidak akan membedakan belokan dari kanguru.
Jaringan saraf sudah bekerja. Mereka ada di puluhan perangkat. Mereka benar-benar memungkinkan Anda untuk menghasilkan, mengubah pasar dan dunia di sekitar Anda. Hype terlihat sedikit berbeda:
Hanya saja jaringan saraf tidak lagi menjadi sesuatu yang baru. Ya, banyak orang memiliki harapan tinggi. Tetapi sejumlah besar perusahaan telah belajar untuk menggunakan neuron mereka dan membuat produk berdasarkan pada mereka. Neuron memberikan fungsionalitas baru, dapat mengurangi pekerjaan, mengurangi harga layanan:
- Perusahaan manufaktur mengintegrasikan algoritma untuk analisis penolakan pada konveyor.
- Peternakan ternak membeli sistem untuk mengendalikan sapi.
- Pemanen otomatis.
- Pusat Panggilan Otomatis.
- Filter di Snapchat. (
Yah, setidaknya sesuatu yang masuk akal! )
Tetapi yang utama, dan bukan yang paling jelas: "Tidak ada lagi ide baru, atau mereka tidak akan membawa modal instan." Jaringan saraf telah memecahkan banyak masalah. Dan mereka akan memutuskan lebih banyak lagi. Semua ide nyata yang - banyak melahirkan startup. Tapi semua yang ada di permukaan sudah dikumpulkan. Selama dua tahun terakhir, saya belum menemukan satu ide baru untuk penggunaan jaringan saraf. Bukan satu pendekatan baru (well, ok, ada beberapa masalah dengan GAN).
Dan setiap startup berikutnya semakin rumit. Tidak perlu lagi dua orang yang melatih neuron pada data terbuka. Ini membutuhkan programmer, server, tim penulis, dukungan kompleks, dll.
Akibatnya, ada lebih sedikit startup. Tetapi produksinya lebih. Perlu melampirkan pengenalan plat nomor? Ada ratusan profesional dengan pengalaman yang relevan di pasar. Anda dapat merekrut dan dalam beberapa bulan karyawan Anda akan membuat sistem. Atau beli yang sudah jadi. Tetapi melakukan startup baru? .. Kegilaan!
Kami perlu membuat sistem untuk melacak pengunjung - mengapa membayar banyak lisensi, ketika Anda bisa melakukannya sendiri selama 3-4 bulan, pertajam untuk bisnis Anda.
Sekarang jaringan saraf berjalan dengan cara yang sama seperti puluhan teknologi lainnya.
Ingat bagaimana konsep "pengembang situs" telah berubah sejak 1995? Sementara pasar tidak jenuh dengan spesialis. Hanya ada sedikit profesional. Tapi saya bisa bertaruh bahwa dalam 5-10 tahun tidak akan ada banyak perbedaan antara seorang programmer Java dan pengembang jaringan saraf. Dan itu dan spesialis itu akan cukup di pasar.
Hanya akan ada kelas tugas yang diselesaikan oleh neuron. Ada tugas - menyewa spesialis.
"Lalu apa? Di mana kecerdasan buatan yang dijanjikan? "Dan di sini ada neponyatchka kecil tapi menarik :)
Tumpukan teknologi yang ada saat ini, tampaknya, masih tidak akan menuntun kita ke kecerdasan buatan. Ide-ide, kebaruan mereka, sebagian besar telah melelahkan diri mereka sendiri. Mari kita bicara tentang apa yang memegang tingkat perkembangan saat ini.
Keterbatasan
Mari kita mulai dengan drone otomatis. Tampaknya dipahami bahwa dimungkinkan untuk membuat mobil yang sepenuhnya otonom dengan teknologi saat ini. Tetapi setelah berapa tahun ini akan terjadi tidak jelas. Tesla percaya bahwa ini akan terjadi dalam beberapa tahun -
Ada banyak
spesialis lain yang menilai ini berusia 5-10 tahun.
Kemungkinan besar, menurut saya, setelah 15 tahun, infrastruktur kota itu sendiri akan berubah sehingga munculnya mobil otonom menjadi tak terhindarkan, akan menjadi kelanjutannya. Namun ini tidak bisa dianggap kecerdasan. Tesla modern adalah saluran pipa yang sangat kompleks untuk memfilter data, mencari mereka dan melatih kembali. Ini adalah aturan, aturan, aturan, pengumpulan data, dan filter di atasnya (di
sini saya menulis lebih banyak tentang itu, atau melihat dari titik
ini ).
Masalah pertama
Dan di sinilah kita melihat
masalah mendasar pertama . Data besar. Inilah yang menghasilkan gelombang saat ini dari jaringan saraf dan pembelajaran mesin. Sekarang, untuk melakukan sesuatu yang kompleks dan otomatis, Anda memerlukan banyak data. Bukan hanya banyak, tetapi sangat, sangat banyak. Kami membutuhkan algoritma otomatis untuk pengumpulan, markup, penggunaannya. Kami ingin membuat mobil melihat truk melawan matahari - kita harus terlebih dahulu mengumpulkan jumlah yang cukup. Kami ingin mobil tidak menjadi gila dengan sepeda yang dikencangkan ke bagasi - lebih banyak sampel.
Apalagi satu contoh saja tidak cukup. Ratusan? Ribuan

Masalah kedua
Masalah kedua adalah visualisasi dari apa yang dipahami jaringan saraf kita. Ini adalah tugas yang sangat sepele. Sampai sekarang, hanya sedikit orang yang mengerti bagaimana memvisualisasikan ini. Artikel-artikel ini sangat baru, ini hanya beberapa contoh, bahkan yang jauh:
Visualisasi fiksasi pada tekstur. Ini menunjukkan dengan baik apa yang cenderung terjadi dalam siklus + apa yang dia rasakan sebagai informasi awal.
 Visualisasi
Visualisasi redaman selama
terjemahan . Sungguh, redaman seringkali dapat digunakan secara tepat untuk menunjukkan apa yang menyebabkan reaksi jaringan semacam itu. Saya bertemu hal-hal seperti itu untuk debug dan untuk solusi produk. Ada banyak artikel tentang topik ini. Tetapi semakin kompleks data, semakin sulit untuk memahami bagaimana mencapai visualisasi berkelanjutan.

Yah dan ya, perangkat lama yang bagus dari "lihat apa yang ada di dalam kotak di
filter ." Foto-foto ini populer sekitar 3-4 tahun yang lalu, tetapi semua orang dengan cepat menyadari bahwa gambar-gambar itu indah, tetapi tidak ada banyak artinya di dalamnya.

Saya tidak menyebutkan lusinan lotion lain, metode, retas, studi tentang cara menampilkan bagian dalam jaringan. Apakah alat ini berfungsi? Apakah mereka membantu Anda dengan cepat memahami apa masalahnya dan men-debug jaringan? .. Tarik keluar persen terakhir? Nah, kira-kira seperti ini:

Anda dapat menonton kontes apa pun di Kaggle. Dan deskripsi tentang bagaimana orang membuat keputusan akhir. Kami tiba model mulenov 100-500-800 dan berhasil!
Tentu saja, saya melebih-lebihkan. Tetapi pendekatan ini tidak memberikan jawaban yang cepat dan langsung.
Memiliki pengalaman yang cukup, setelah menyodok pilihan yang berbeda, Anda dapat mengeluarkan putusan tentang mengapa sistem Anda membuat keputusan semacam itu. Tetapi memperbaiki perilaku sistem akan sulit. Masukkan kruk, pindahkan ambang, tambahkan dataset, ambil jaringan backend lainnya.
Masalah ketiga
Masalah mendasar ketiga adalah bahwa grid tidak mengajarkan logika, tetapi statistik. Secara statistik
orang ini:

Secara logis - tidak terlalu mirip. Jaringan saraf tidak mempelajari sesuatu yang rumit jika tidak dipaksa. Mereka selalu mempelajari gejala yang paling sederhana. Punya mata, hidung, kepala? Jadi wajah ini! Atau berikan contoh di mana mata tidak akan berarti wajah. Dan lagi, jutaan contoh.
Ada banyak ruang di bawah
Saya akan mengatakan bahwa ketiga masalah global inilah yang saat ini membatasi pengembangan jaringan saraf dan pembelajaran mesin. Dan di mana masalah ini tidak terbatas sudah digunakan secara aktif.
Apakah ini akhirnya? Jaringan saraf bangun?Tidak dikenal Tapi, tentu saja, semua orang berharap tidak.
Ada banyak pendekatan dan arahan untuk memecahkan masalah mendasar yang telah saya bahas di atas. Namun sejauh ini, tidak satu pun dari pendekatan ini yang memungkinkan kami untuk melakukan sesuatu yang secara fundamental baru, untuk menyelesaikan sesuatu yang belum terselesaikan. Sejauh ini, semua proyek mendasar dilakukan berdasarkan pendekatan stabil (Tesla), atau tetap menguji proyek lembaga atau perusahaan (Google Brain, OpenAI).
Secara kasar, arah utama adalah penciptaan beberapa representasi data input tingkat tinggi. Dalam arti tertentu, "memori." Contoh paling sederhana dari memori adalah berbagai representasi "Embedding" dari gambar. Sebagai contoh, semua sistem pengenalan wajah. Jaringan belajar untuk mendapatkan dari wajah ide stabil tertentu yang tidak bergantung pada rotasi, pencahayaan, resolusi. Bahkan, jaringan meminimalkan metrik "wajah yang berbeda - jauh" dan "identik - dekat".

Pelatihan semacam itu membutuhkan puluhan dan ratusan ribu contoh. Tetapi hasilnya membawa beberapa dasar "Pembelajaran Satu Kali". Sekarang kita tidak perlu ratusan wajah untuk mengingat seseorang. Hanya satu wajah, dan hanya itu - kita akan
mencari tahu !
Hanya di sinilah masalahnya ... Grid hanya dapat mempelajari objek yang cukup sederhana. Ketika mencoba untuk membedakan bukan wajah, tetapi, misalnya, "orang dengan pakaian" (
tugas identifikasi ulang ), kualitas gagal oleh banyak urutan besarnya. Dan jaringan tidak bisa lagi belajar perubahan sudut yang cukup jelas.
Dan belajar dari jutaan contoh juga merupakan hiburan yang begitu-begitu saja.
Ada pekerjaan untuk mengurangi pemilu secara signifikan. Misalnya, Anda dapat segera mengingat salah satu karya
Google OneShot Learning pertama:
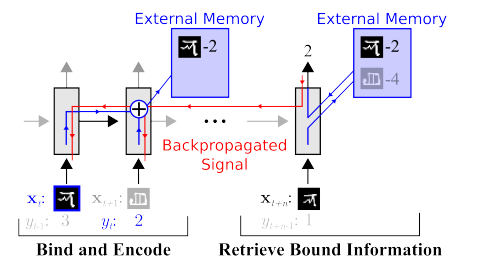
Ada banyak karya seperti itu, misalnya
1 atau
2 atau
3 .
Ada satu minus - biasanya pelatihan bekerja dengan baik pada beberapa contoh sederhana, "contoh MNIST'ovskie". Dan dalam transisi ke tugas-tugas kompleks - Anda memerlukan basis besar, model objek, atau semacam sihir.
Secara umum, bekerja pada pelatihan One-Shot adalah topik yang sangat menarik. Anda menemukan banyak ide. Tetapi untuk sebagian besar, dua masalah yang saya daftarkan (pra-pelatihan pada dataset besar / ketidakstabilan pada data yang kompleks) sangat menghambat pembelajaran.
Di sisi lain, GAN - jaringan yang kompetitif secara generatif - mendekati Embedding. Anda mungkin membaca banyak artikel tentang topik ini di Habré. (
1 ,
2 ,
3 )
Fitur GAN adalah pembentukan beberapa ruang keadaan internal (pada dasarnya Embedding yang sama), yang memungkinkan Anda untuk menggambar. Bisa jadi
orang , bisa ada
aksi .
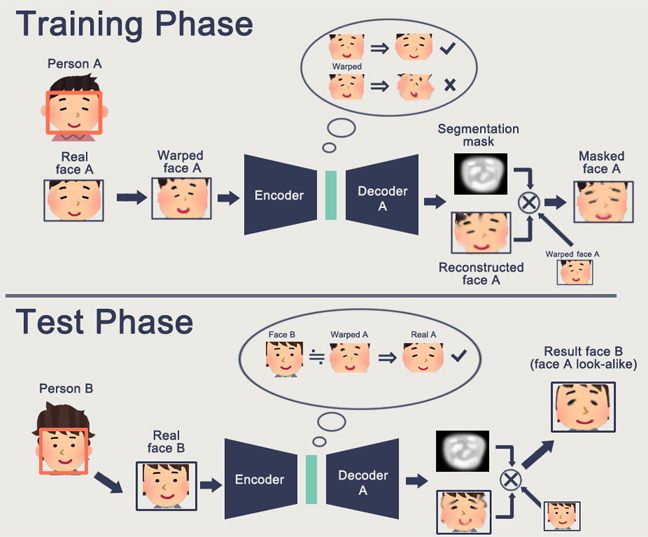
Masalah GAN adalah bahwa semakin kompleks objek yang dihasilkan, semakin sulit untuk menggambarkannya dalam logika "generator-diskriminator". Akibatnya, dari aplikasi nyata GAN, yang hanya terdengar DeepFake, yang, sekali lagi, memanipulasi representasi individu (yang ada basis besar).
Saya telah menemui sangat sedikit aplikasi berguna lainnya. Biasanya semacam peluit palsu dengan menggambar gambar.
Dan lagi. Tidak ada yang memiliki pemahaman tentang bagaimana ini akan memungkinkan kita untuk bergerak menuju masa depan yang lebih cerah. Representasi logika / ruang dalam jaringan saraf adalah baik. Tetapi kita membutuhkan banyak contoh, kita tidak mengerti bagaimana neuron ini mewakili dirinya sendiri, kita tidak mengerti bagaimana membuat neuron mengingat beberapa ide yang sangat rumit.
Pembelajaran penguatan adalah pendekatan yang sama sekali berbeda. Tentunya Anda ingat bagaimana Google mengalahkan semua orang di Go. Kemenangan terbaru di Starcraft dan Dota. Tapi di sini semuanya jauh dari begitu cerah dan menjanjikan. Hal terbaik tentang RL dan kompleksitasnya adalah
artikel ini .
Untuk meringkas secara singkat apa yang penulis tulis:
- Model di luar kotak tidak cocok / bekerja dengan buruk dalam banyak kasus
- Tugas praktis lebih mudah diselesaikan dengan cara lain. Boston Dynamics tidak menggunakan RL karena kompleksitasnya / ketidakpastiannya / kompleksitas komputasinya
- Agar RL berfungsi, Anda memerlukan fungsi yang kompleks. Seringkali sulit untuk membuat / menulis.
- Sulit untuk melatih model. Kita harus menghabiskan banyak waktu untuk berayun dan keluar dari optima lokal
- Akibatnya, sulit untuk mengulang model, ketidakstabilan model pada perubahan sekecil apa pun
- Ini sering melebihi batas pada beberapa pola kiri, hingga generator nomor acak
Poin kuncinya adalah bahwa RL belum berfungsi dalam produksi. Google memiliki beberapa jenis eksperimen (
1 ,
2 ). Tapi saya belum melihat satu sistem kelontong.
Memori Kelemahan dari semua yang dijelaskan di atas tidak terstruktur. Salah satu pendekatan untuk mencoba merapikan semua ini adalah menyediakan jaringan saraf dengan akses ke memori terpisah. Sehingga dia dapat merekam dan menulis ulang hasil langkahnya di sana. Maka jaringan saraf dapat ditentukan oleh keadaan memori saat ini. Ini sangat mirip dengan prosesor dan komputer klasik.
Artikel paling terkenal dan populer adalah dari DeepMind:
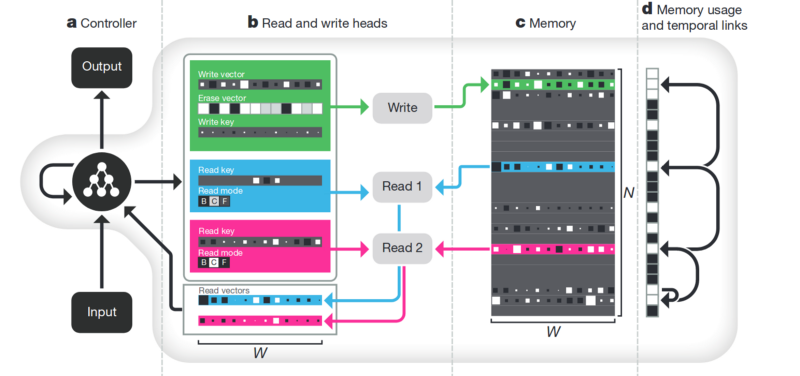
Tampaknya ini dia, kunci untuk memahami kecerdasan? Melainkan, tidak. Sistem masih membutuhkan sejumlah besar data untuk pelatihan. Dan itu bekerja terutama dengan data tabel terstruktur. Pada saat yang sama, ketika Facebook
memecahkan masalah yang sama, mereka pergi sepanjang jalan "melihat memori, hanya membuat neuron lebih rumit, tetapi lebih banyak contoh - dan itu akan belajar sendiri."
Penguraian . Cara lain untuk menciptakan memori yang bermakna adalah dengan mengambil embeddings yang sama, tetapi ketika belajar memperkenalkan kriteria tambahan yang memungkinkan mereka untuk menyoroti "makna" di dalamnya. Sebagai contoh, kami ingin melatih jaringan saraf untuk membedakan antara perilaku seseorang di toko. Jika kita mengikuti jalur standar, kita harus membuat selusin jaringan. Seseorang mencari seseorang, yang kedua menentukan apa yang dia lakukan, yang ketiga adalah usianya, yang keempat adalah jenis kelamin. Logika yang terpisah melihat bagian toko di mana ia melakukan / mempelajarinya. Yang ketiga menentukan lintasannya, dll.
Atau, jika ada banyak data, maka mungkin untuk melatih satu jaringan untuk semua jenis hasil (jelas bahwa array data seperti itu tidak dapat diketik).
Pendekatan disenthelment memberi tahu kita - dan mari kita latih jaringan sehingga ia dapat dengan sendirinya membedakan antar konsep. Agar dia membentuk embedding dalam video, di mana satu area akan menentukan tindakan, satu - posisi di lantai tepat waktu, satu - ketinggian orang, dan lainnya - jenis kelaminnya. Pada saat yang sama, selama pelatihan, saya ingin hampir tidak pernah menyarankan konsep-konsep kunci seperti itu ke jaringan, tetapi agar itu sendiri mengidentifikasi dan mengelompokkan area. Ada beberapa artikel semacam itu (beberapa di antaranya adalah
1 ,
2 ,
3 ) dan secara umum cukup teoretis.
Tetapi arah ini, setidaknya secara teoritis, harus mencakup masalah yang terdaftar di awal.
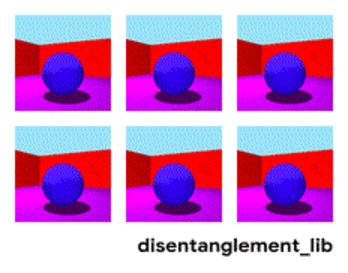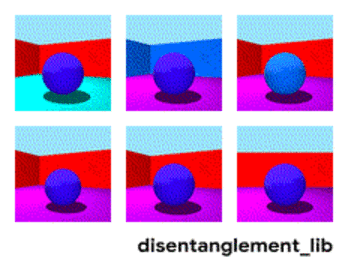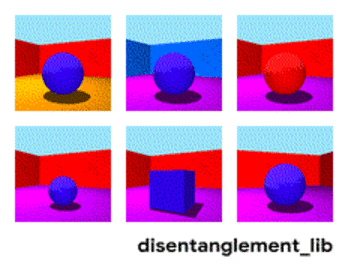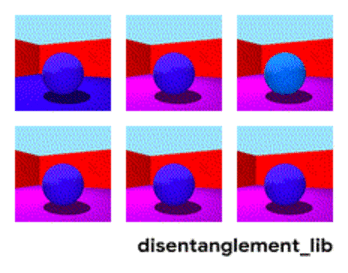
Dekomposisi gambar sesuai dengan parameter “warna dinding / warna lantai / bentuk objek / warna objek / dll.”

Dekomposisi wajah sesuai dengan parameter “ukuran, alis, orientasi, warna kulit, dll.”
Lainnya
Ada banyak petunjuk lain yang tidak terlalu global yang memungkinkan kita untuk mengurangi basis, bekerja dengan data yang lebih heterogen, dll.
Perhatian . Mungkin tidak masuk akal untuk mengisolasi ini sebagai metode terpisah. Hanya sebuah pendekatan yang memperkuat orang lain. Banyak artikel yang ditujukan kepadanya (
1 ,
2 ,
3 ). Arti Perhatian adalah untuk memperkuat respons jaringan terhadap benda-benda penting selama pelatihan. Seringkali oleh beberapa penunjukan target eksternal, atau jaringan eksternal kecil.
Simulasi 3D . Jika Anda membuat mesin 3D yang baik, Anda sering dapat menutup 90% dari data pelatihan dengan itu (saya bahkan melihat contoh di mana hampir 99% dari data ditutup dengan mesin yang baik). Ada banyak ide dan peretasan tentang cara membuat jaringan yang terlatih pada mesin 3D bekerja pada data nyata (Penyetelan halus, transfer gaya, dll.). Tetapi sering membuat mesin yang bagus beberapa kali lipat lebih sulit daripada mengumpulkan data. Contoh saat membuat mesin:
Pelatihan robot (
google ,
braingarden )
Belajar
mengenali barang di toko (tetapi dalam dua proyek yang kami lakukan, kami dengan tenang menghilangkan ini).
Pelatihan di Tesla (sekali lagi, video yang ada di atas).
Kesimpulan
Seluruh artikel dalam arti tertentu kesimpulan. Mungkin pesan utama yang ingin saya lakukan adalah "freebie selesai, neuron tidak memberikan solusi yang lebih sederhana." Sekarang kita harus bekerja keras untuk membangun solusi yang kompleks. Atau bekerja keras melakukan laporan ilmiah yang rumit.
Secara umum, topik ini masih bisa diperdebatkan. Mungkin pembaca punya contoh lebih menarik?