Secara teori, penggunaan pembelajaran mesin (ML) membantu mengurangi keterlibatan manusia dalam proses dan operasi, merealokasi sumber daya, dan mengurangi biaya. Bagaimana cara kerjanya di perusahaan dan industri tertentu? Seperti yang ditunjukkan oleh pengalaman kami, itu berhasil.
Pada tahap pengembangan tertentu, kami di VTB Capital dihadapkan dengan kebutuhan mendesak untuk mengurangi waktu yang dibutuhkan untuk memproses permintaan dukungan teknis. Setelah menganalisis opsi, diputuskan untuk menggunakan teknologi ML untuk mengkategorikan panggilan dari pengguna bisnis Calypso, platform investasi utama perusahaan. Pemrosesan cepat permintaan semacam itu sangat penting untuk kualitas tinggi layanan TI. Kami meminta mitra utama kami,
EPAM, untuk membantu menyelesaikan masalah ini.

Jadi, permintaan dukungan diterima melalui email dan diubah menjadi tiket di Jira. Kemudian, spesialis dukungan secara manual mengklasifikasikan mereka, memprioritaskan mereka, memasukkan data tambahan (misalnya, dari departemen dan lokasi mana permintaan diterima, unit fungsional mana dari sistem miliknya) dan menunjuk pelaku. Secara total, sekitar 10 kategori permintaan digunakan. Ini, misalnya, dapat berupa permintaan untuk menganalisis beberapa data dan memberikan informasi kepada pemohon, menambah pengguna baru, dll. Selain itu, tindakan dapat berupa standar atau non-standar, sehingga sangat penting untuk segera menentukan dengan tepat jenis permintaan dan menetapkan eksekusi ke spesialis yang tepat.
Penting untuk dicatat: VTB Capital ingin tidak hanya mengembangkan solusi teknologi terapan, tetapi juga untuk mengevaluasi kemampuan berbagai alat dan teknologi di pasar. Satu tugas, dua pendekatan berbeda, dua platform teknologi dan tiga setengah minggu: apa hasilnya?
Prototipe No. 1: teknologi dan model
Dasar untuk pengembangan prototipe adalah pendekatan yang diusulkan oleh tim EPAM, dan data historis - sekitar 10.000 tiket dari Jira. Perhatian utama difokuskan pada 3 bidang yang diperlukan yang berisi setiap tiket tersebut: Jenis Masalah (jenis masalah), Ringkasan ("header" surat atau subjek permintaan) dan Deskripsi (deskripsi). Dalam kerangka kerja proyek, itu direncanakan untuk menyelesaikan masalah menganalisis teks dari bidang Ringkasan dan Deskripsi dan secara otomatis menentukan jenis permintaan berdasarkan hasil-hasilnya.
Ini adalah fitur teks dalam dua bidang tiket ini yang menjadi kesulitan teknis utama dalam menganalisis data dan mengembangkan model ML. Jadi, bidang Ringkasan mungkin berisi teks yang cukup "bersih", tetapi termasuk kata-kata dan istilah tertentu (misalnya,
laporan CWS tidak berjalan). Sebaliknya, bidang Deskripsi ditandai oleh teks yang lebih "kotor" dengan banyak karakter khusus, simbol, garis miring terbalik, dan sisa elemen non-teks:
Rekan Dera,
Bisakah Anda jelaskan kepada kami apa perbedaan antara FX_Opt_delta_all dan FX_Opt_delta_cash ukuran risiko?
! 01D39C59.62374C90_image001.png! )
Selain itu, teks sering menggabungkan beberapa bahasa (terutama, secara alami, Rusia dan Inggris), terminologi bisnis, bahasa gaul ruglish dan programmer dapat ditemukan. Dan tentu saja, karena permintaan sering ditulis dengan tergesa-gesa, dalam kedua kasus kesalahan ketik dan ejaan tidak dikesampingkan.
Teknologi yang dipilih oleh tim EPAM termasuk Python 3.5 untuk pengembangan prototipe, NLTK + Gensim + Re untuk pemrosesan teks, Pandas + Sklearn untuk analisis data dan pengembangan model, dan Keras + Tensorflow sebagai kerangka pembelajaran dan backend yang dalam.
Dengan mempertimbangkan fitur-fitur yang mungkin dari data awal, tiga representasi dibangun untuk ekstraksi karakter dari bidang Ringkasan: pada tingkat simbol, kombinasi simbol, dan kata-kata individual. Masing-masing representasi digunakan sebagai pintu masuk ke jaringan saraf berulang.
Pada gilirannya, statistik karakter layanan (penting untuk memproses teks menggunakan tanda seru, garis miring, dll.) Dan nilai rata-rata string setelah memfilter karakter layanan dan sampah (untuk pelestarian struktur teks) dipilih sebagai representasi untuk bidang Deskripsi; serta representasi tingkat kata setelah memfilter kata berhenti. Setiap representasi berfungsi sebagai pintu masuk ke jaringan saraf: statistik dalam sepenuhnya terhubung, baris demi baris dan pada tingkat kata - dalam yang rekursif.
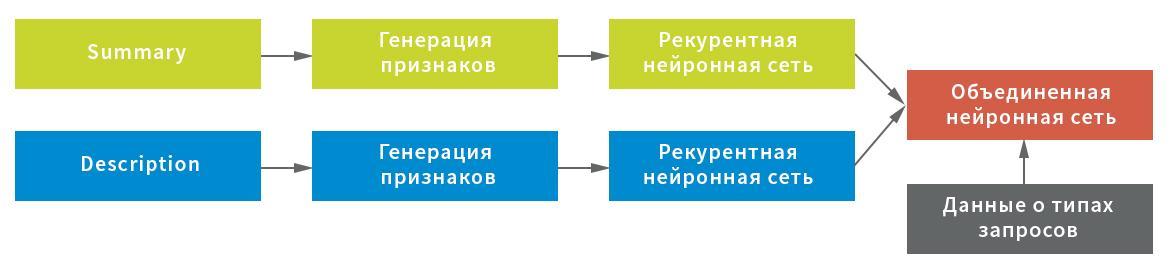
Dalam skema ini, jaringan saraf digunakan sebagai jaringan berulang, yang terdiri dari lapisan GRU dua arah dengan putus sekolah yang normal dan berulang, kumpulan keadaan tersembunyi dari jaringan berulang menggunakan lapisan GlobalMaxPool1D dan lapisan dropout yang terhubung penuh (rapat). Untuk setiap input, "kepala" sendiri dari jaringan saraf dibangun, dan kemudian mereka digabungkan melalui penggabungan dan dikunci ke variabel target.
Untuk mendapatkan hasil akhir, jaringan saraf gabungan mengembalikan probabilitas permintaan tertentu milik masing-masing jenis. Data dibagi menjadi lima blok tanpa persimpangan: model dibangun pada empat dari mereka dan diuji pada kelima. Karena setiap permintaan hanya dapat ditetapkan satu jenis permintaan, aturan untuk membuat keputusan sederhana - dengan nilai probabilitas maksimum.
Prototipe No. 2: algoritma dan prinsip kerja
Prototipe kedua, yang diambil proposalnya oleh tim Capital VTB, adalah aplikasi pada Microsoft .NET Core dengan perpustakaan Microsoft.ML untuk mengimplementasikan algoritma pembelajaran mesin dan SDK Atlassian.Net untuk berinteraksi dengan Jira melalui REST API. Dasar untuk membangun model-ML juga menjadi data historis - 50.000 tiket Jira. Seperti dalam kasus pertama, pembelajaran mesin mencakup bidang Ringkasan dan Deskripsi. Sebelum digunakan, kedua bidang itu juga "dibersihkan". Salam, tanda tangan, riwayat korespondensi, dan elemen non-tekstual (misalnya, gambar) dihapus dari surat pengguna. Selain itu, dengan menggunakan fungsionalitas bawaan di Microsoft ML, kata-kata berhenti yang tidak relevan untuk memproses dan menganalisis teks dihapus dari teks bahasa Inggris.
Averaged Perceptron (klasifikasi biner) dipilih sebagai algoritma pembelajaran mesin, yang dilengkapi dengan metode One Versus All untuk menyediakan klasifikasi multiclass
Evaluasi hasil
Tidak ada model ML yang dapat (mungkin, belum) memberikan akurasi hasil 100%.
Algoritma Prototipe No. 1 menyediakan pangsa klasifikasi yang benar (Akurasi), sama dengan 0,8003 dari jumlah total permintaan, atau 80%. Selain itu, nilai metrik yang sama dalam situasi di mana diasumsikan bahwa jawaban yang benar akan dipilih oleh orang dari dua yang disajikan oleh solusi mencapai 0,901, atau 90%. Tentu saja, ada kasus di mana solusi yang dikembangkan bekerja lebih buruk atau tidak dapat memberikan jawaban yang benar - sebagai suatu peraturan, karena serangkaian kata yang sangat pendek atau kekhususan informasi dalam permintaan itu sendiri. Peran masih dimainkan oleh sejumlah besar data yang digunakan dalam proses pembelajaran. Menurut perkiraan awal, peningkatan volume informasi yang diproses akan memungkinkan untuk meningkatkan akurasi klasifikasi dengan 0,01-0,03 poin lainnya.
Hasil model terbaik dalam metrik akurasi (Presisi) dan kelengkapan (Ingat) dievaluasi sebagai berikut:

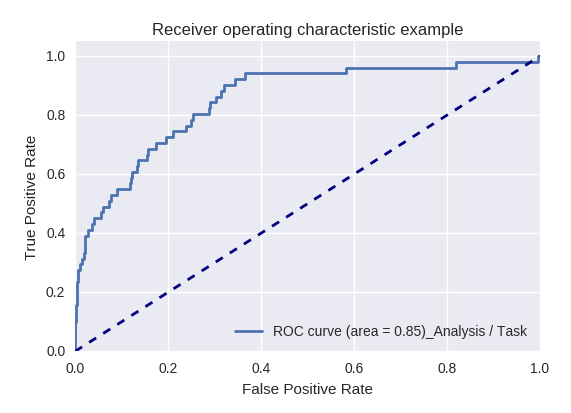
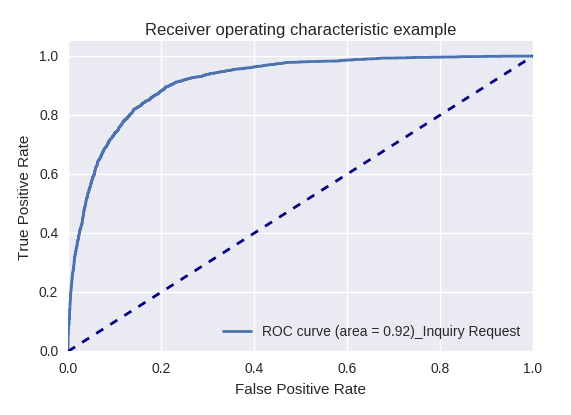
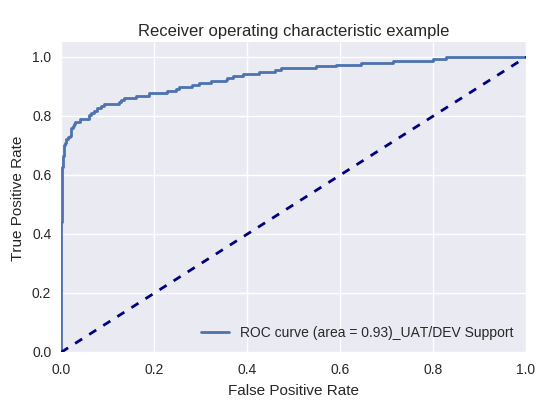
Jika kami mengevaluasi kualitas model secara keseluruhan untuk berbagai jenis kueri menggunakan kurva ROC-AUC, hasilnya adalah sebagai berikut.
Permintaan tindakan (Permintaan Tindakan) dan analisis informasi (Analisis / Permintaan Tugas)
 Permintaan untuk perubahan dalam data bisnis (Permintaan Data Bisnis) dan untuk perubahan (Ubah Permintaan)
Permintaan untuk perubahan dalam data bisnis (Permintaan Data Bisnis) dan untuk perubahan (Ubah Permintaan)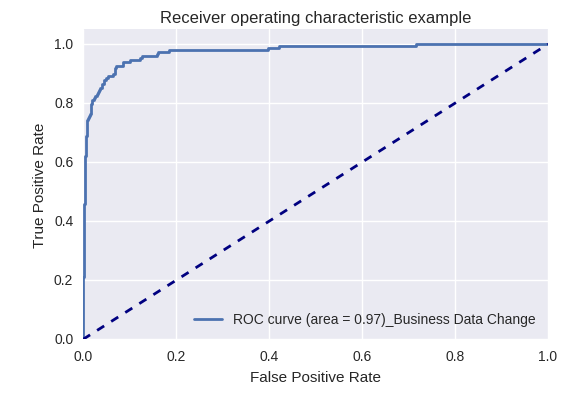
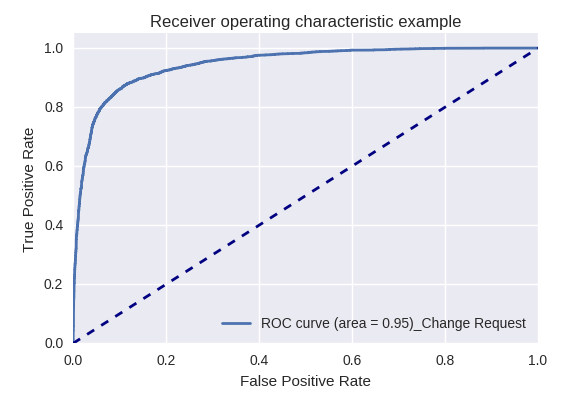 Permintaan Pengembangan dan Permintaan Permintaan
Permintaan Pengembangan dan Permintaan Permintaan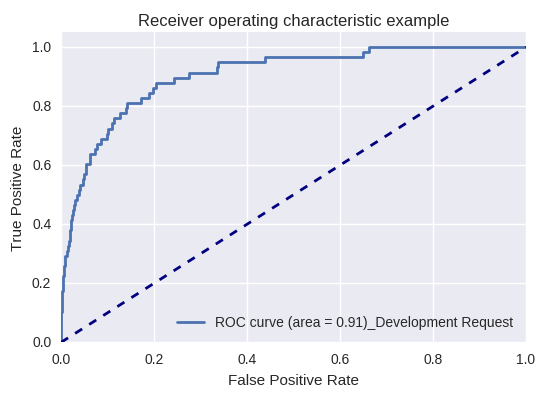
 Permintaan untuk membuat objek baru (Permintaan Objek Baru) dan menambahkan pengguna baru (Permintaan Pengguna Baru)
Permintaan untuk membuat objek baru (Permintaan Objek Baru) dan menambahkan pengguna baru (Permintaan Pengguna Baru)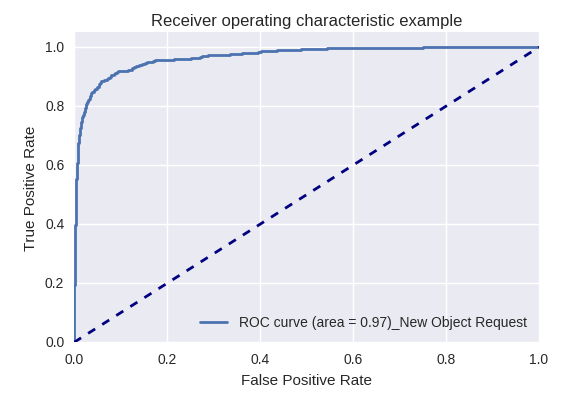
 Permintaan Produksi dan Permintaan Dukungan UAT / DEV (Permintaan Dukungan UAT / Dev)
Permintaan Produksi dan Permintaan Dukungan UAT / DEV (Permintaan Dukungan UAT / Dev)
Contoh klasifikasi yang benar dan salah untuk beberapa jenis pertanyaan diberikan di bawah ini:
Permintaan Pertanyaan
Ubah Permintaan
Klasifikasi yang benar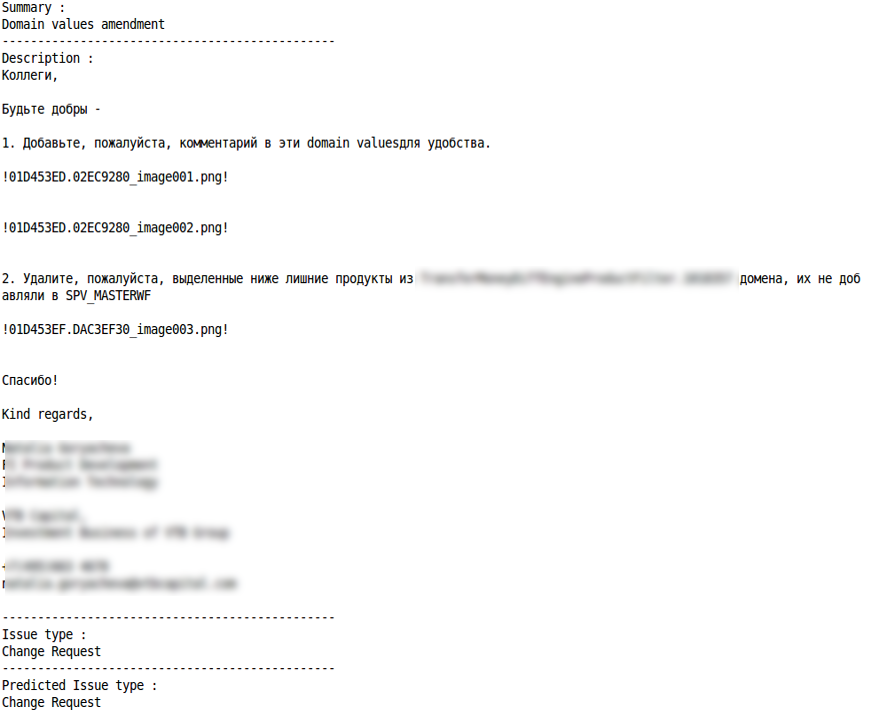 Kesalahan klasifikasi
Kesalahan klasifikasi Permintaan tindakanKlasifikasi yang benar
Permintaan tindakanKlasifikasi yang benar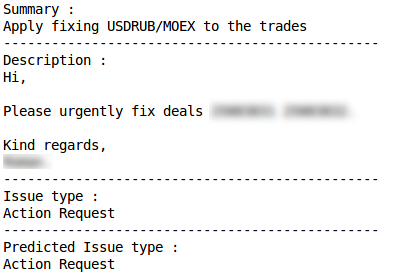 Kesalahan klasifikasiMasalah produksiKlasifikasi yang benar
Kesalahan klasifikasiMasalah produksiKlasifikasi yang benar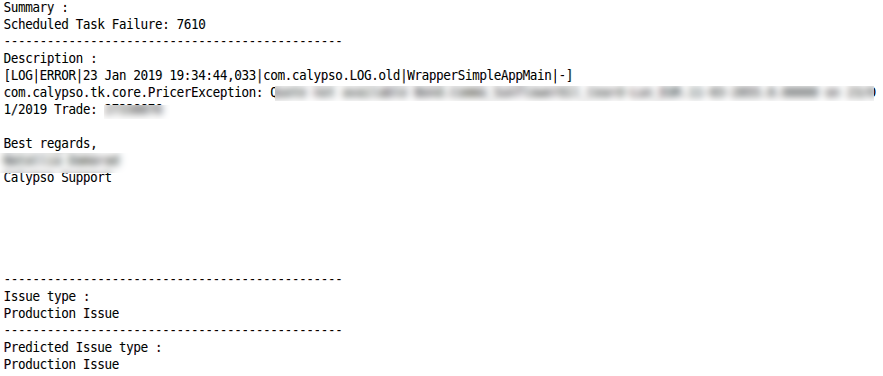 Kesalahan klasifikasi
Kesalahan klasifikasi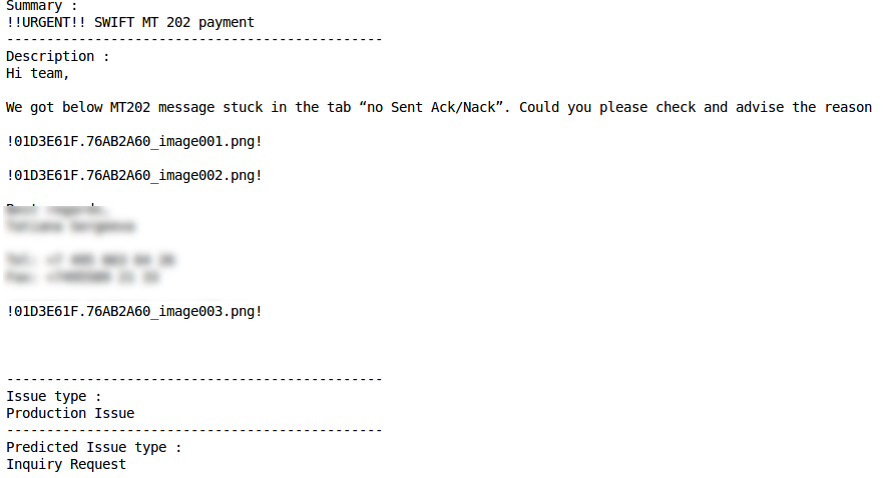
Prototipe kedua juga menunjukkan hasil yang baik: dalam sekitar 75% kasus, ML dengan benar menentukan jenis kueri (Metrik Akurasi). Peluang untuk meningkatkan indikator dikaitkan dengan peningkatan kualitas data sumber, khususnya, menghilangkan kasus-kasus di mana pertanyaan yang sama ditugaskan untuk berbagai jenis.
Untuk meringkas
Masing-masing prototipe yang diimplementasikan telah menunjukkan keefektifannya, dan sekarang kombinasi dari dua prototipe yang dikembangkan telah diluncurkan ke dalam produksi awal di VTB Capital. Eksperimen kecil dengan ML dalam waktu kurang dari sebulan dan dengan biaya minimal memungkinkan perusahaan untuk berkenalan dengan alat pembelajaran mesin dan menyelesaikan masalah aplikasi penting untuk mengklasifikasikan permintaan pengguna.
Pengalaman yang diperoleh oleh pengembang EPAM dan VTB Capital - selain menggunakan algoritma yang diimplementasikan untuk memproses permintaan pengguna untuk pengembangan lebih lanjut - dapat digunakan kembali dalam memecahkan berbagai masalah terkait dengan aliran pemrosesan informasi. Pergerakan dalam iterasi kecil dan cakupan dari satu proses ke proses yang lain memungkinkan Anda untuk secara bertahap menguasai dan menggabungkan berbagai alat dan teknologi, memilih opsi yang terbukti baik dan mengabaikan yang kurang efektif. Ini menarik bagi tim TI dan pada saat yang sama membantu memperoleh hasil yang penting bagi manajemen dan bisnis.