Jika artikel sebelumnya lebih mungkin diunggulkan, sekarang saatnya untuk menguji kemampuan paralelisasi Julia di mesinnya.
Pemrosesan multi-core atau terdistribusi
Implementasi komputasi paralel dengan memori terdistribusi disediakan oleh modul Distributed sebagai bagian dari perpustakaan standar yang disertakan dengan Julia. Sebagian besar komputer modern memiliki lebih dari satu prosesor, dan beberapa komputer dapat dikelompokkan. Menggunakan kekuatan beberapa prosesor ini memungkinkan Anda untuk melakukan banyak perhitungan lebih cepat. Kinerja dipengaruhi oleh dua faktor utama: kecepatan prosesor itu sendiri dan kecepatan akses memori mereka. Di cluster, jelas bahwa CPU ini akan memiliki akses tercepat ke RAM di komputer (node) yang sama. Mungkin bahkan lebih mengejutkan, masalah seperti itu relevan pada laptop multi-core khas karena perbedaan kecepatan memori utama dan cache. Oleh karena itu, lingkungan multiprosesor yang baik harus memungkinkan Anda untuk mengontrol "kepemilikan" sebagian memori oleh prosesor tertentu. Julia menyediakan lingkungan multiprosesor berbasis pesan yang memungkinkan program untuk berjalan secara bersamaan pada beberapa proses dalam domain memori yang berbeda.
Implementasi pengiriman pesan Julia berbeda dari lingkungan lain, seperti MPI [1] . Komunikasi dalam Julia biasanya "satu arah", yang berarti bahwa programmer perlu secara eksplisit mengendalikan hanya satu proses dalam operasi dua proses. Selain itu, operasi ini biasanya tidak terlihat seperti "mengirim pesan" dan "menerima pesan," tetapi lebih menyerupai operasi tingkat yang lebih tinggi, seperti panggilan ke fungsi yang ditentukan pengguna.
Pemrograman terdistribusi di Julia dibangun pada dua primitif: tautan jarak jauh dan panggilan jarak jauh . Tautan jarak jauh adalah objek yang dapat digunakan dari proses apa pun untuk merujuk ke objek yang disimpan dalam proses tertentu. Panggilan jarak jauh adalah permintaan dari satu proses untuk memanggil fungsi tertentu sesuai dengan argumen tertentu dari proses lain (mungkin sama).
Tautan jarak jauh datang dalam dua bentuk: Masa Depan dan Remote Saluran .
Panggilan jarak jauh mengembalikan Future dan segera melakukannya; proses yang membuat panggilan dilanjutkan ke operasi berikutnya, sementara panggilan jarak jauh terjadi di tempat lain. Anda bisa menunggu panggilan jarak jauh untuk menyelesaikan dengan perintah tunggu untuk Future dikembalikan, dan Anda juga bisa mendapatkan nilai penuh dari hasil menggunakan fetch .
Di sisi lain, kami memiliki RemoteChannels yang ditulis ulang. Misalnya, beberapa proses dapat mengoordinasikan pemrosesan mereka, mengacu pada saluran jarak jauh yang sama. Setiap proses memiliki pengidentifikasi terkait. Proses yang menyediakan prompt interaktif Julia selalu memiliki pengidentifikasi 1. Proses yang digunakan secara default untuk operasi bersamaan disebut "pekerja." Ketika hanya ada satu proses, proses 1 dianggap bekerja. Kalau tidak, semua proses selain proses 1 dianggap pekerja.

Mari kita mulai. julia -pn dengan julia -pn postscript menyediakan n alur kerja di komputer lokal. Biasanya masuk akal bahwa n sama dengan jumlah utas CPU (core logis) pada mesin. Perhatikan bahwa argumen -p secara implisit memuat modul Terdistribusi.
Bagaimana cara memulai postscript?Operasi konsol harus langsung bagi pengguna Linux, termasuk. Program pendidikan ini ditujukan untuk pengguna Windows yang tidak berpengalaman.
Terminal Julia (REPL) menyediakan kemampuan untuk menggunakan perintah sistem:
julia> pwd() # "C:\\Users\\User\\AppData\\Local\\Julia-1.1.0" julia> cd("C:/Users/User/Desktop") # julia> run(`calc`) # # Windows. # Process(`calc`, ProcessExited(0))
menggunakan perintah ini, Anda dapat memulai Julia dari Julia, tetapi lebih baik tidak terbawa suasana
Akan lebih benar untuk menjalankan cmd dari julia / bin / dan menjalankan perintah julia -p 2 sana atau opsi untuk pecinta meluncurkan dari pintasan: pada desktop, buat dokumen notepad dengan konten berikut C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4 ( tentukan alamat dan jumlah proses ) dan simpan sebagai dokumen teks dengan nama run.bat . Di sini, sekarang di desktop Anda ada file sistem peluncuran Julia untuk 4 core.
Anda dapat menggunakan metode lain (terutama yang relevan untuk Jupyter ):
using Distributed addprocs(2)
$ ./julia -p 2 julia> r = remotecall(rand, 2, 2, 2) Future(2, 1, 4, nothing) julia> s = @spawnat 2 1 .+ fetch(r) Future(2, 1, 5, nothing) julia> fetch(s) 2×2 Array{Float64,2}: 1.18526 1.50912 1.16296 1.60607
Argumen pertama yang melakukan remotecall adalah fungsi yang dipanggil.
Sebagian besar program bersamaan di Julia tidak merujuk ke proses tertentu atau jumlah proses yang tersedia, tetapi panggilan jarak jauh dianggap sebagai antarmuka tingkat rendah yang menyediakan kontrol yang lebih tepat.
Argumen kedua untuk remotecall adalah pengidentifikasi proses yang akan melakukan pekerjaan, dan argumen yang tersisa akan diteruskan ke fungsi yang disebut. Seperti yang Anda lihat, di baris pertama kami meminta proses 2 untuk membangun matriks 2 demi 2 secara acak, dan di baris kedua kami meminta untuk menambahkan 1 ke dalamnya. Hasil dari kedua perhitungan tersedia dalam dua futures, r dan s. Makro spawnat mengevaluasi ekspresi dalam argumen kedua untuk proses yang ditentukan dalam argumen pertama. Terkadang Anda mungkin membutuhkan nilai yang dihitung dari jarak jauh. Ini biasanya terjadi ketika Anda membaca dari objek jarak jauh untuk mendapatkan data yang diperlukan untuk operasi lokal berikutnya. Ada fungsi remotecall_fetch untuk remotecall_fetch . Ini sama dengan fetch (remotecall (...)) , tetapi lebih efisien.
Ingat bahwa getindex(r, 1,1) setara dengan r[1,1] , jadi panggilan ini mengambil elemen pertama dari r akan datang.
remotecall panggilan jarak jauh panggilan remot tidak terlalu nyaman. Makro @spawn membuat @spawn lebih mudah. Ini berfungsi dengan ekspresi, bukan fungsi, dan memilih tempat untuk melakukan operasi untuk Anda:
julia> r = @spawn rand(2,2) Future(2, 1, 4, nothing) julia> s = @spawn 1 .+ fetch(r) Future(3, 1, 5, nothing) julia> fetch(s) 2×2 Array{Float64,2}: 1.38854 1.9098 1.20939 1.57158
Perhatikan bahwa kami menggunakan 1 .+ Fetch(r) alih-alih 1 .+ r Ini karena kami tidak tahu di mana kode akan dieksekusi, jadi dalam kasus umum mungkin perlu untuk mengambil r pindah ke dalam proses penambahan. Dalam hal ini, @spawn cukup pintar untuk melakukan perhitungan untuk proses yang memiliki r , jadi pengambilan akan menjadi non-operasional (tidak ada pekerjaan yang dilakukan). (Perlu dicatat bahwa spawn tidak built-in, tetapi didefinisikan dalam Julia sebagai makro. Anda dapat mendefinisikan konstruksi seperti itu sendiri.)
Penting untuk diingat bahwa setelah ekstraksi, Future akan men-cache nilainya secara lokal. Panggilan lebih lanjut untuk mengambil tidak memerlukan lompatan jaringan. Setelah semua berjangka referensi dipilih, nilai tersimpan yang dihapus dihapus.
@async mirip dengan @spawn , tetapi hanya menjalankan tugas dalam proses lokal. Kami menggunakannya untuk membuat tugas "umpan" untuk setiap proses. Setiap tugas memilih indeks berikutnya, yang harus dihitung, kemudian menunggu selesainya proses dan mengulangi sampai kita kehabisan indeks.
Harap dicatat bahwa tugas pengumpan tidak mulai dijalankan sampai tugas utama mencapai akhir blok @sync , setelah itu melewati kontrol dan menunggu untuk menyelesaikan semua tugas lokal sebelum kembali dari fungsi.
Sedangkan untuk v0.7 dan lebih tinggi, tugas pengumpan dapat berbagi status melalui nextidx, karena semuanya dijalankan dalam proses yang sama. Bahkan jika tugas direncanakan bersama, memblokir mungkin diperlukan dalam beberapa konteks, seperti dengan I / O yang tidak sinkron. Ini berarti bahwa pengalihan konteks hanya terjadi pada titik yang ditentukan dengan baik: dalam kasus ini, ketika remotecall_fetch . Ini adalah kondisi implementasi saat ini, dan mungkin berubah dalam versi Julia yang akan datang, karena dirancang untuk dapat menyelesaikan hingga tugas-tugas N dalam proses M, atau M: N Threading . Maka kita memerlukan model untuk mendapatkan / melepaskan kunci untuk nextidx , karena tidak aman untuk memungkinkan beberapa proses membaca dan menulis sumber daya pada saat yang sama.
Kode Anda harus tersedia untuk setiap proses yang menjalankannya. Misalnya, pada prompt Julia, ketikkan yang berikut:
julia> function rand2(dims...) return 2*rand(dims...) end julia> rand2(2,2) 2×2 Array{Float64,2}: 0.153756 0.368514 1.15119 0.918912 julia> fetch(@spawn rand2(2,2)) ERROR: RemoteException(2, CapturedException(UndefVarError(Symbol("#rand2")) Stacktrace: [...]
Proses 1 tahu tentang fungsi rand2, tetapi proses 2 tidak. Paling sering, Anda akan mengunduh kode dari file atau paket, dan Anda akan memiliki fleksibilitas yang signifikan dalam mengendalikan proses mana yang memuat kode. Pertimbangkan file DummyModule.jl berisi kode berikut:
module DummyModule export MyType, f mutable struct MyType a::Int end f(x) = x^2+1 println("loaded") end
Untuk referensi MyType di semua proses, DummyModule.jl harus dimuat di setiap proses. Panggilan untuk include ('DummyModule.jl') memuatnya hanya untuk satu proses. Untuk memuatnya ke setiap proses, gunakan makro @everywhere (jalankan Julia dengan julia -p 2):
julia> @everywhere include("DummyModule.jl") loaded From worker 3: loaded From worker 2: loaded
Seperti biasa, ini tidak membuat DummyModule dapat diakses oleh proses apa pun yang membutuhkan penggunaan atau impor. Selain itu, ketika DummyModule termasuk dalam ruang lingkup satu proses, itu tidak termasuk dalam yang lain:
julia> using .DummyModule julia> MyType(7) MyType(7) julia> fetch(@spawnat 2 MyType(7)) ERROR: On worker 2: UndefVarError: MyType not defined ⋮ julia> fetch(@spawnat 2 DummyModule.MyType(7)) MyType(7)
Namun, masih mungkin, misalnya, untuk mengirim MyType ke proses yang memuat DummyModule, bahkan jika itu tidak dalam cakupan:
julia> put!(RemoteChannel(2), MyType(7)) RemoteChannel{Channel{Any}}(2, 1, 13)
File juga dapat dimuat ke dalam beberapa proses saat startup dengan flag -L, dan skrip driver dapat digunakan untuk mengontrol perhitungan:
julia -p <n> -L file1.jl -L file2.jl driver.jl
Proses Julia yang menjalankan skrip driver dalam contoh di atas memiliki pengidentifikasi 1, sama seperti proses yang menyediakan prompt interaktif. Akhirnya, jika DummyModule.jl bukan file terpisah, tetapi sebuah paket, maka menggunakan DummyModule akan memuat DummyModule.jl dalam semua proses, tetapi hanya mentransfernya ke lingkup proses yang digunakan untuk memanggil.
Meluncurkan dan mengelola alur kerja
Instalasi dasar Julia memiliki dukungan bawaan untuk dua jenis klaster:
- Cluster lokal yang ditentukan dengan opsi -p, seperti yang ditunjukkan di atas.
- Mesin cluster menggunakan opsi --machine-file. Ini menggunakan login ssh tanpa kata sandi untuk memulai alur kerja Julia (sepanjang jalur yang sama dengan host saat ini) pada mesin yang ditentukan.

Fungsi addprocs , rmprocs , pekerja, dan lainnya tersedia sebagai alat perangkat lunak untuk menambah, menghapus, dan memproses pertanyaan dalam sebuah cluster.
julia> using Distributed julia> addprocs(2) 2-element Array{Int64,1}: 2 3
Modul Distributed harus secara eksplisit dimuat ke dalam proses utama sebelum memanggil addprocs . Secara otomatis menjadi tersedia untuk alur kerja. Perhatikan bahwa pekerja tidak menjalankan skrip startup ~/.julia/config/startup.jl juga tidak menyinkronkan keadaan global mereka (seperti variabel global, definisi metode baru, dan modul yang dimuat) dengan salah satu dari proses yang berjalan lainnya. Jenis-jenis cluster lainnya dapat didukung dengan menulis ClusterManager Anda sendiri, seperti yang dijelaskan di bawah ini di bagian ClusterManager .
Tindakan Data
Mengirim pesan dan memindahkan data membentuk sebagian besar overhead dalam program terdistribusi. Mengurangi jumlah pesan dan jumlah data yang dikirim sangat penting untuk mencapai kinerja dan skalabilitas. Untuk ini, penting untuk memahami pergerakan data yang dilakukan oleh berbagai konstruksi pemrograman terdistribusi Julia.
fetch dapat dianggap sebagai operasi perpindahan data yang eksplisit, karena ia secara langsung meminta perpindahan objek ke mesin lokal. @spawn (dan beberapa konstruk terkait) juga memindahkan data, tetapi ini tidak begitu jelas, sehingga dapat disebut operasi perpindahan data implisit. Pertimbangkan dua pendekatan ini untuk membangun dan mengkuadratkan matriks acak:
Waktu cara:
julia> A = rand(1000,1000); julia> Bref = @spawn A^2; [...] julia> fetch(Bref);
metode dua:
julia> Bref = @spawn rand(1000,1000)^2; [...] julia> fetch(Bref);
Perbedaannya nampak sepele, tetapi sebenarnya ini cukup signifikan karena perilaku @spawn . Dalam metode pertama, matriks acak dibangun secara lokal, dan kemudian dikirim ke proses lain, di mana itu kuadrat. Dalam metode kedua, matriks acak dibangun dan dikuadratkan pada proses lain. Oleh karena itu, metode kedua mengirimkan lebih sedikit data daripada yang pertama. Dalam contoh mainan ini, dua metode mudah dibedakan dan dipilih. Namun, dalam program nyata, merancang pergerakan data bisa sangat mahal dan mungkin beberapa pengukuran.
Misalnya, jika proses pertama membutuhkan matriks A, maka metode pertama mungkin lebih baik. Atau, jika komputasi A mahal dan hanya menggunakan proses saat ini, maka memindahkannya ke proses lain mungkin tidak terhindarkan. Atau, jika proses saat ini memiliki sangat sedikit kesamaan antara spawn dan fetch(Bref) , mungkin lebih baik untuk sepenuhnya menghilangkan konkurensi. Atau bayangkan rand(1000, 1000) digantikan oleh operasi yang lebih mahal. Maka mungkin masuk akal untuk menambahkan pernyataan spawn lain hanya untuk langkah ini.
Variabel global
Ekspresi yang dijalankan dari jarak jauh melalui spawn, atau penutupan yang ditentukan untuk eksekusi jarak jauh menggunakan remotecall jarak jauh, dapat merujuk ke variabel global. Binding Global dalam modul Main ditangani sedikit berbeda dari binding global pada modul lainnya. Pertimbangkan potongan kode berikut:
A = rand(10,10) remotecall_fetch(()->sum(A), 2)
Dalam hal ini, sum HARUS didefinisikan dalam proses jarak jauh. Perhatikan bahwa A adalah variabel global yang didefinisikan dalam ruang kerja lokal. Pekerja 2 tidak memiliki variabel bernama A di bagian Main . Mengirim fungsi penutupan () -> sum(A) untuk pekerja 2 menyebabkan Main.A didefinisikan pada 2. Main.A terus ada pada pekerja 2 bahkan setelah mengembalikan panggilan remotecall_fetch .

Panggilan jarak jauh dengan referensi global tertanam (hanya dalam modul utama) mengelola variabel global sebagai berikut:
- Binding global baru dibuat di workstation tujuan jika mereka dirujuk sebagai bagian dari panggilan jarak jauh.
- Konstanta global juga dinyatakan sebagai konstanta pada node jarak jauh.
- Global dikirimkan kembali ke karyawan target hanya dalam konteks panggilan jarak jauh dan hanya jika nilainya telah berubah. Selain itu, cluster tidak menyinkronkan binding global antar node. Sebagai contoh:
A = rand(10,10) remotecall_fetch(()->sum(A), 2)
Eksekusi fragmen di atas mengarah pada fakta bahwa Main.A pada karyawan 2 memiliki nilai yang berbeda dari Main.A pada karyawan 3, sedangkan nilai Main.A pada node 1 adalah nol.
Seperti yang mungkin Anda pahami, meskipun memori yang terkait dengan variabel global dapat dikumpulkan ketika mereka dipindahkan ke perangkat master, tindakan seperti itu tidak diambil untuk pekerja, karena binding terus bekerja. jelas! dapat digunakan untuk secara manual menetapkan ulang variabel global tertentu menjadi nothing jika mereka tidak lagi diperlukan. Ini akan membebaskan memori yang terkait dengannya sebagai bagian dari siklus pengumpulan sampah normal. Karena itu, program harus berhati-hati ketika mengakses variabel global dalam panggilan jarak jauh. Bahkan, jika memungkinkan, lebih baik menghindari mereka sama sekali. Jika Anda harus referensi variabel global, pertimbangkan untuk menggunakan blok let untuk melokalisasi variabel global. Sebagai contoh:
julia> A = rand(10,10); julia> remotecall_fetch(()->A, 2); julia> B = rand(10,10); julia> let B = B remotecall_fetch(()->B, 2) end; julia> @fetchfrom 2 InteractiveUtils.varinfo() name size summary ––––––––– ––––––––– –––––––––––––––––––––– A 800 bytes 10×10 Array{Float64,2} Base Module Core Module Main Module
Mudah untuk melihat bahwa variabel global A didefinisikan pada pekerja 2, tetapi B ditulis sebagai variabel lokal, dan oleh karena itu pengikatan untuk B tidak ada pada pekerja 2.
Loop paralel

Untungnya, banyak perhitungan konkurensi berguna tidak memerlukan perpindahan data. Contoh khas adalah simulasi Monte Carlo, di mana beberapa proses dapat secara bersamaan memproses tes simulasi independen. Kita dapat menggunakan @spawn untuk membalik koin menjadi dua proses. Pertama, tulis fungsi berikut di count_heads.jl :
function count_heads(n) c::Int = 0 for i = 1:n c += rand(Bool) end c end
Fungsi count_heads hanya menambahkan n bit acak. Inilah cara kami dapat melakukan beberapa pengujian pada dua mesin dan menambahkan hasilnya:
julia> @everywhere include_string(Main, $(read("count_heads.jl", String)), "count_heads.jl") julia> a = @spawn count_heads(100000000) Future(2, 1, 6, nothing) julia> b = @spawn count_heads(100000000) Future(3, 1, 7, nothing) julia> fetch(a)+fetch(b) 100001564
Contoh ini menunjukkan pola pemrograman paralel yang kuat dan sering digunakan. Banyak iterasi dilakukan secara independen dalam beberapa proses, dan kemudian hasilnya digabungkan menggunakan beberapa fungsi. Proses penyatuan disebut reduksi, karena biasanya mengurangi peringkat tensor: vektor angka direduksi menjadi satu angka, atau matriks direduksi menjadi satu baris atau kolom, dll. Dalam kode, ini biasanya terlihat seperti ini: pola x = f(x, v [i]) , di mana x adalah baterai, f adalah fungsi reduksi, dan v[i] adalah elemen yang harus dikurangi.
Diharapkan bahwa f menjadi asosiatif sehingga tidak masalah di mana urutan operasi dilakukan. Harap perhatikan bahwa penggunaan kami atas template ini dengan count_heads dapat digeneralisasi. Kami menggunakan dua pernyataan spawn eksplisit, yang membatasi konkurensi untuk dua proses. Untuk berjalan pada sejumlah proses, kita dapat menggunakan paralel for operasi loop dalam memori terdistribusi, yang dapat ditulis ke Julia menggunakan terdistribusi , misalnya:
nheads = @distributed (+) for i = 1:200000000 Int(rand(Bool)) end
( (+) ). . .
, for , . , , , . , , . , :
a = zeros(100000) @distributed for i = 1:100000 a[i] = i end
, . , . , Shared Arrays , , :
using SharedArrays a = SharedArray{Float64}(10) @distributed for i = 1:10 a[i] = i end
«» , :
a = randn(1000) @distributed (+) for i = 1:100000 f(a[rand(1:end)]) end
f , . , , . , Future , . Future , fetch , , @sync , @sync distributed for .
, (, , ). , , Julia pmap . , :
julia> M = Matrix{Float64}[rand(1000,1000) for i = 1:10]; julia> pmap(svdvals, M);
pmap , . , distributed for , , , . pmap , distributed . distributed for .
(Shared Arrays)

Shared Arrays . DArray , SharedArray . DArray , ; , SharedArray .
SharedArray — , , . Shared Array SharedArrays , . SharedArray ( ) , , . SharedArray , . , Array , SharedArray , sdata . AbstractArray sdata , sdata Array . :
SharedArray{T,N}(dims::NTuple; init=false, pids=Int[])
N - T dims , pids . , , pids ( , ).
init initfn(S :: SharedArray) , . , init , .
:
julia> using Distributed julia> addprocs(3) 3-element Array{Int64,1}: 2 3 4 julia> @everywhere using SharedArrays julia> S = SharedArray{Int,2}((3,4), init = S -> S[localindices(S)] = myid()) 3×4 SharedArray{Int64,2}: 2 2 3 4 2 3 3 4 2 3 4 4 julia> S[3,2] = 7 7 julia> S 3×4 SharedArray{Int64,2}: 2 2 3 4 2 3 3 4 2 7 4 4
SharedArrays.localindices . , , :
julia> S = SharedArray{Int,2}((3,4), init = S -> S[indexpids(S):length(procs(S)):length(S)] = myid()) 3×4 SharedArray{Int64,2}: 2 2 2 2 3 3 3 3 4 4 4 4
, , . Sebagai contoh:
@sync begin for p in procs(S) @async begin remotecall_wait(fill!, p, S, p) end end end
. pid , , ( S ), pid .
«»:
q[i,j,t+1] = q[i,j,t] + u[i,j,t]
, , , , , : q [i,j,t] , q[i,j,t+1] , , , q[i,j,t] , q[i,j,t+1] . . . , (irange, jrange) , :
julia> @everywhere function myrange(q::SharedArray) idx = indexpids(q) if idx == 0
:
julia> @everywhere function advection_chunk!(q, u, irange, jrange, trange) @show (irange, jrange, trange)
SharedArray
julia> @everywhere advection_shared_chunk!(q, u) = advection_chunk!(q, u, myrange(q)..., 1:size(q,3)-1)
, :
julia> advection_serial!(q, u) = advection_chunk!(q, u, 1:size(q,1), 1:size(q,2), 1:size(q,3)-1);
@distributed :
julia> function advection_parallel!(q, u) for t = 1:size(q,3)-1 @sync @distributed for j = 1:size(q,2) for i = 1:size(q,1) q[i,j,t+1]= q[i,j,t] + u[i,j,t] end end end q end;
, :
julia> function advection_shared!(q, u) @sync begin for p in procs(q) @async remotecall_wait(advection_shared_chunk!, p, q, u) end end q end;
SharedArray , ( julia -p 4 ):
julia> q = SharedArray{Float64,3}((500,500,500)); julia> u = SharedArray{Float64,3}((500,500,500));
JIT- @time :
julia> @time advection_serial!(q, u); (irange,jrange,trange) = (1:500,1:500,1:499) 830.220 milliseconds (216 allocations: 13820 bytes) julia> @time advection_parallel!(q, u); 2.495 seconds (3999 k allocations: 289 MB, 2.09% gc time) julia> @time advection_shared!(q,u); From worker 2: (irange,jrange,trange) = (1:500,1:125,1:499) From worker 4: (irange,jrange,trange) = (1:500,251:375,1:499) From worker 3: (irange,jrange,trange) = (1:500,126:250,1:499) From worker 5: (irange,jrange,trange) = (1:500,376:500,1:499) 238.119 milliseconds (2264 allocations: 169 KB)
advection_shared! , , .
, . , , .
, , , .
- Julia
, , , .
, , -. , dimana — . - , .. , .
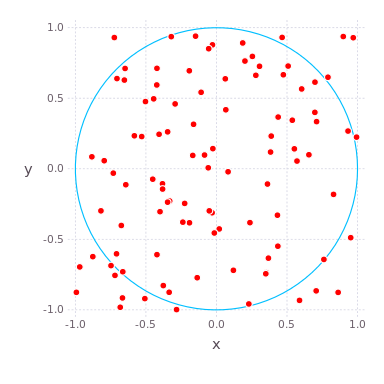
( , ) ( ) , , , . , , . compute_pi (N) , , .
function compute_pi(N::Int)
, , . : , , 25 .
Julia Pi.jl ( Sublime Text , ):
C:\Users\User\AppData\Local\Julia-1.1.0\bin\julia -p 4 julia> include("C:/Users/User/Desktop/Pi.jl")
using Distributed addprocs(4)
Jupyter
Pi.jl @everywhere function compute_pi(N::Int) n_landed_in_circle = 0
, :
julia> @time parallel_pi_computation(1000000000, ncores = 1) 6.818123 seconds (1.96 M allocations: 99.838 MiB, 0.42% gc time) 3.141562892 julia> @time parallel_pi_computation(1000000000, ncores = 1) 5.081638 seconds (1.12 k allocations: 62.953 KiB) 3.141657252 julia> @time parallel_pi_computation(1000000000, ncores = 2) 3.504871 seconds (1.84 k allocations: 109.382 KiB) 3.1415942599999997 julia> @time parallel_pi_computation(1000000000, ncores = 4) 3.093918 seconds (1.12 k allocations: 71.938 KiB) 3.1416889400000003 julia> pi ? = 3.1415926535897...
JIT - — . , Julia . , ( Multi-Threading, Atomic Operations, Channels Coroutines).
, , . MPI.jl MPI ,
DistributedArrays.jl .
GPU, :
- ( C) OpenCL.jl CUDAdrv.jl OpenCL CUDA.
- ( Julia) CUDAnative.jl CUDA .
- , , CuArrays.jl CLArrays.jl
- , ArrayFire.jl GPUArrays.jl
- -
- Kynseed
, , . !