Artikel tentang visi komputer, kemampuan interpretasi, NLP - kami mengunjungi konferensi AISTATS di Jepang dan ingin berbagi tinjauan umum artikel. Ini adalah konferensi besar tentang statistik dan pembelajaran mesin, dan tahun ini diadakan di Okinawa, sebuah pulau dekat Taiwan. Dalam posting ini, Yulia Antokhina ( Yulia_chan ) menyiapkan deskripsi artikel-artikel cemerlang dari bagian utama, selanjutnya bersama dengan Anna Papeta dia akan berbicara tentang laporan dari dosen yang diundang dan studi teori. Kami juga akan menceritakan sedikit tentang bagaimana konferensi itu sendiri berlangsung dan tentang "non-Jepang" Jepang. Membela terhadap Serangan Musuh Whitebox melalui Diskretisasi Acak
Membela terhadap Serangan Musuh Whitebox melalui Diskretisasi AcakYuchen Zhang (Microsoft); Percy Liang (Universitas Stanford)
→
Artikel→
KodeMari kita mulai dengan artikel tentang perlindungan terhadap serangan permusuhan dalam visi komputer. Ini adalah serangan yang ditargetkan pada model, ketika tujuan serangan adalah untuk membuat model melakukan kesalahan, hingga hasil yang telah ditentukan. Algoritma visi komputer dapat salah bahkan dengan perubahan kecil pada gambar aslinya untuk seseorang. Tugas tersebut relevan, misalnya, untuk penglihatan mesin, yang dalam kondisi baik mengenali rambu-rambu jalan lebih cepat daripada seseorang, tetapi bekerja jauh lebih buruk selama serangan.
Serangan Adversarial dengan jelas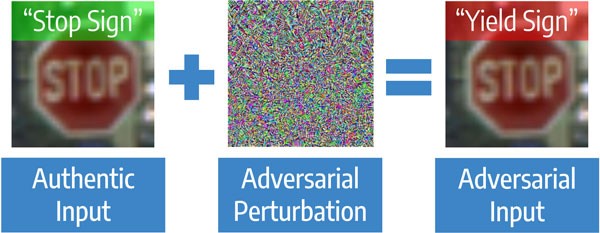
Serangannya adalah Blackbox - ketika penyerang tidak tahu apa-apa tentang algoritma, dan Whitebox adalah situasi sebaliknya. Ada dua pendekatan utama untuk melindungi model. Pendekatan pertama adalah melatih model pada gambar reguler dan "diserang" - itu disebut pelatihan permusuhan. Pendekatan ini berfungsi baik pada gambar kecil seperti MNIST, tetapi ada artikel yang menunjukkan bahwa itu tidak berfungsi dengan baik pada gambar besar seperti ImageNet. Jenis perlindungan kedua tidak memerlukan pelatihan ulang model. Cukup dengan pra-proses gambar sebelum mengirimkannya ke model. Contoh konversi: kompresi JPEG, mengubah ukuran. Metode ini membutuhkan lebih sedikit perhitungan, tetapi sekarang mereka hanya bekerja melawan serangan Blackbox, karena jika konversi diketahui, kebalikannya dapat diterapkan.
MetodeDalam artikel tersebut, penulis mengusulkan metode yang tidak memerlukan latihan berlebihan model dan bekerja untuk serangan Whitebox. Tujuannya adalah untuk mengurangi jarak Kullback - Leibner antara contoh biasa dan yang "rusak" menggunakan transformasi acak. Ternyata itu sudah cukup untuk menambahkan noise acak, dan kemudian sampel warna secara acak. Artinya, kualitas gambar "terganggu" dimasukkan ke input algoritma, tetapi masih cukup untuk algoritma bekerja. Dan karena kebetulan, ada potensi untuk menahan serangan Whitebox.
Di sebelah kiri adalah gambar asli, di tengah adalah contoh pengelompokan warna piksel dalam ruang Lab, di sebelah kanan adalah gambar dalam beberapa warna (Misalnya, bukannya 40 warna biru - satu) Hasil
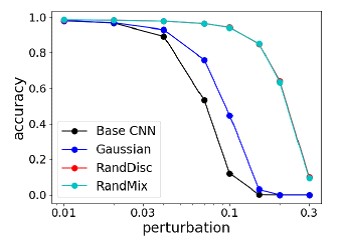
HasilMetode ini dibandingkan dengan serangan terkuat di Kompetisi Serangan & Pertahanan NIPS 2017, dan rata-rata menunjukkan kualitas terbaik dan tidak berlatih kembali di bawah "penyerang".
Perbandingan metode pertahanan terkuat melawan serangan terkuat di Kompetisi NIPS Perbandingan akurasi metode pada MNIST dengan perubahan gambar yang berbeda
Perbandingan akurasi metode pada MNIST dengan perubahan gambar yang berbeda
 Atenuasi Bias dalam vektor Word
Atenuasi Bias dalam vektor WordSunipa Dev (Universitas Utah); Jeff Phillips (Universitas Utah)
→
ArtikelPembicaraan "trendi" adalah tentang Vektor Kata yang Tidak Cocok. Dalam hal ini, Bias berarti bias berdasarkan jenis kelamin atau kebangsaan dalam representasi kata-kata. Setiap regulator dapat menentang "diskriminasi" semacam itu, dan karena itu para ilmuwan dari Universitas Utah memutuskan untuk mempelajari kemungkinan "pemerataan hak" untuk NLP. Bahkan, mengapa seorang pria tidak bisa "glamor" dan seorang wanita "Data Scientist"?
Asli - hasil yang diperoleh sekarang, sisanya - hasil dari algoritma yang tidak bias

Artikel ini membahas metode untuk menemukan bias semacam itu. Mereka memutuskan bahwa gender dan kebangsaan dicirikan dengan nama. Jadi, jika Anda menemukan offset dengan nama dan menguranginya, maka, mungkin, Anda bisa menghilangkan bias dari algoritma.
Contoh dari lebih banyak kata "maskulin" dan "feminin":
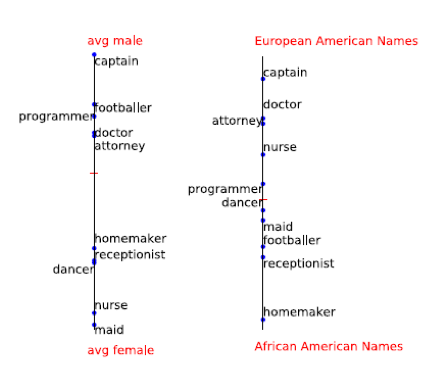 Nama untuk menemukan offset gender:
Nama untuk menemukan offset gender:
Anehnya, metode sederhana seperti itu berhasil. Para penulis melatih Sarung Tangan yang tidak memihak dan meletakkannya di Git.
Apa yang membuatmu melakukan ini? Memahami keputusan kotak hitam dengan himpunan bagian input yang memadaiBrandon Carter (MIT CSAIL); Jonas Mueller (Layanan Web Amazon); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→
Artikel→
Kode sekali dan
dua kaliArtikel berikut membahas tentang algoritma Subset Input yang Memadai. SIS adalah himpunan bagian minimum dari fitur di mana model akan menghasilkan hasil tertentu, bahkan jika semua fitur lainnya diatur ulang. Ini adalah cara lain untuk menafsirkan hasil model yang rumit. Bekerja pada teks dan gambar.
Algoritma pencarian SIS secara detail: Contoh aplikasi pada teks dengan ulasan tentang bir:
Contoh aplikasi pada teks dengan ulasan tentang bir: Contoh aplikasi pada MNIST:
Contoh aplikasi pada MNIST: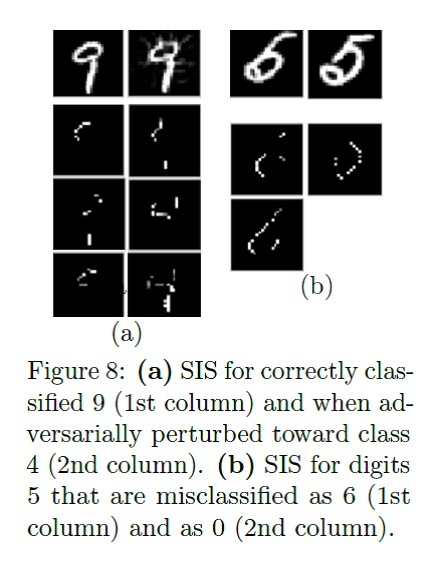 Perbandingan metode "interpretasi" dari jarak Kullback - Leibler relatif terhadap hasil "ideal":
Perbandingan metode "interpretasi" dari jarak Kullback - Leibler relatif terhadap hasil "ideal":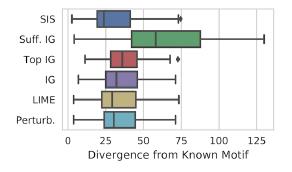
Fitur-fitur pertama-tama diberi peringkat berdasarkan dampak pada model, dan kemudian dipecah menjadi subset yang terpisah, dimulai dengan yang paling berpengaruh. Ia bekerja dengan kekuatan kasar, dan pada dataset berlabel, hasilnya menginterpretasikan lebih baik daripada LIME. Ada implementasi pencarian SIS yang mudah dari Google Research.
Minimalisasi Risiko Empiris dan Keturunan Gradien Stochastic untuk Data RelasionalVictor Veitch (Universitas Columbia); Morgane Austern (Universitas Columbia); Wenda Zhou (Universitas Columbia); David Blei (Universitas Columbia); Peter Orbanz (Universitas Columbia)
→
Artikel→
KodePada bagian optimisasi, ada laporan tentang Minimisasi Risiko Empiris, di mana penulis mengeksplorasi cara untuk menerapkan penurunan gradien stokastik pada grafik. Misalnya, saat membuat model pada data jaringan sosial, Anda hanya dapat menggunakan fitur tetap dari profil (jumlah pelanggan), tetapi kemudian informasi tentang koneksi antara profil (yang berlangganan) hilang. Terlebih lagi, keseluruhan grafik paling sering sulit untuk diproses - misalnya, tidak cocok dengan memori. Ketika situasi ini terjadi pada data tabular, model dapat dijalankan pada subsamples. Dan bagaimana memilih analog dari subsampel pada grafik tidak jelas. Para penulis secara teoritis mendukung kemungkinan menggunakan subgraph acak sebagai analog dari subsampel, dan ini ternyata “Bukan ide gila”. Ada contoh yang dapat direproduksi dari artikel di Github, termasuk contoh Wikipedia.
Kategori Embeddings pada data "Wikipedia" dengan mempertimbangkan struktur grafiknya, artikel yang dipilih paling dekat dengan subjek "fisikawan Prancis":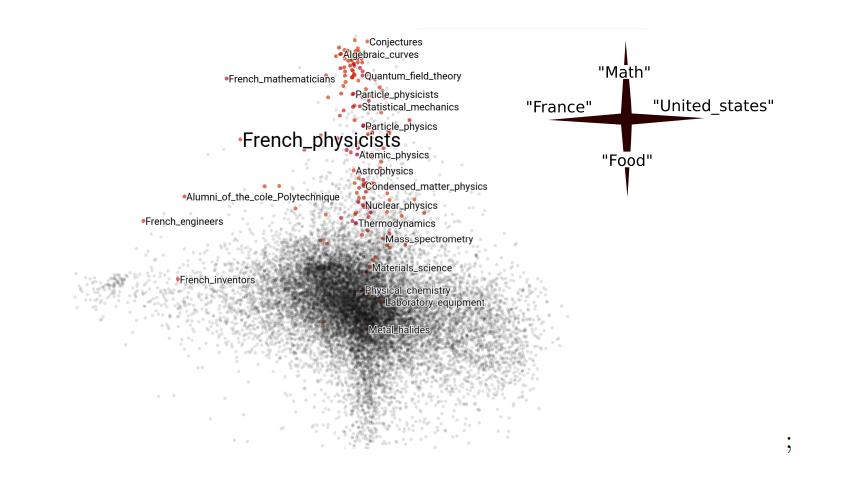
→
Ilmu Data untuk Data JaringanGrafik data diskrit adalah laporan ulasan lain oleh Ilmu Data untuk Data Jaringan dari pembicara tamu Poling Loh (University of Wisconsin-Madison). Presentasi mencakup topik inferensi Statistik, Alokasi sumber daya, Algoritma lokal. Dalam inferensi Statistik, misalnya, ini tentang bagaimana memahami struktur apa yang dimiliki grafik pada data penyakit menular. Diusulkan untuk menggunakan statistik pada jumlah koneksi antara node yang terinfeksi - dan teorema terbukti untuk uji statistik yang sesuai.
Secara umum, laporan ini lebih menarik untuk ditonton, kemungkinan besar, bagi mereka yang tidak terlibat dalam model grafik, tetapi ingin mencoba dan tertarik pada cara menguji hipotesis untuk grafik dengan benar.
Bagaimana konferensi berlangsungAISTATS 2019 adalah konferensi tiga hari di Okinawa. Ini adalah Jepang, tetapi budaya Okinawa lebih dekat ke Cina. Jalan perbelanjaan utama mengingatkan pada Miami yang sangat kecil, ada mobil-mobil panjang di jalanan, musik country, dan Anda turun sedikit ke samping - hutan dengan ular, pohon-pohon bakau yang dipelintir oleh angin topan. Citarasa lokal diciptakan oleh budaya Ryukyu - sebuah kerajaan yang terletak di Okinawa, tetapi pertama-tama menjadi mitra dagang dan perdagangan Cina, dan kemudian ditangkap oleh Jepang.
Dan di Okinawa, rupanya, mereka sering mengadakan pernikahan, karena ada banyak salon pernikahan, dan konferensi itu diadakan di tempat Wedding Hall.
Lebih dari 500 orang telah mengumpulkan ilmuwan, penulis artikel, pendengar, dan pembicara. Dalam tiga hari Anda dapat memiliki waktu untuk berbicara dengan hampir semua orang. Meskipun konferensi diadakan "di ujung dunia" - perwakilan dari seluruh dunia tiba. Terlepas dari geografi yang luas, ternyata minat kita semua sama. Sebagai kejutan bagi kami, misalnya, bahwa para ilmuwan dari Australia memecahkan masalah Ilmu Data yang sama dan metode yang sama seperti kami dalam tim kami. Tetapi, bagaimanapun juga, kita hidup di sisi yang berlawanan dari planet ini ... Tidak banyak peserta dari industri ini: Google, Amazon, MTS dan beberapa perusahaan top lainnya.
Ada perwakilan dari perusahaan sponsor Jepang, yang sebagian besar menonton dan mendengarkan dan, mungkin, mencari seseorang, terlepas dari kenyataan bahwa "non-Jepang" sangat sulit untuk bekerja di Jepang.
Artikel yang dikirim ke konferensi tentang topik:
Segala sesuatu yang lain ada di posting kami berikutnya. Jangan sampai ketinggalan!
Pengumuman: