
Halo pembaca Habr! Topik artikel ini adalah penerapan toleransi bencana dalam sistem penyimpanan Engine AERODISK. Awalnya, kami ingin menulis dalam satu artikel tentang kedua cara: replikasi dan metro cluster, tetapi, sayangnya, artikel itu ternyata terlalu besar, jadi kami membagi artikel menjadi dua bagian. Mari kita beralih dari yang sederhana ke rumit. Pada artikel ini, kami akan mengonfigurasi dan menguji replikasi sinkron - taruh satu pusat data, dan juga putuskan saluran komunikasi antara pusat data dan lihat apa yang terjadi.
Pelanggan kami sering mengajukan pertanyaan berbeda tentang replikasi, oleh karena itu, sebelum beralih ke pengaturan dan pengujian implementasi replika, kami akan memberi tahu Anda sedikit tentang replikasi apa yang ada dalam sistem penyimpanan.
Sedikit teori
Replikasi ke penyimpanan adalah proses berkelanjutan untuk memastikan identitas data di berbagai sistem penyimpanan secara bersamaan. Secara teknis, replikasi dilakukan dengan dua metode.
Replikasi sinkron adalah penyalinan data dari sistem penyimpanan utama ke sistem cadangan, diikuti oleh konfirmasi wajib dari kedua sistem penyimpanan bahwa data dicatat dan dikonfirmasi. Setelah konfirmasi dari kedua belah pihak (pada kedua sistem penyimpanan) bahwa data dianggap direkam, dan Anda dapat bekerja dengannya. Ini memastikan identitas data yang dijamin pada semua sistem penyimpanan yang berpartisipasi dalam replika.
Kelebihan dari metode ini:
- Data selalu identik pada semua sistem penyimpanan.
Cons:
- Biaya solusi yang tinggi (saluran komunikasi cepat, serat mahal, transceiver gelombang panjang, dll.)
- Pembatasan jarak (dalam beberapa puluh kilometer)
- Tidak ada perlindungan terhadap kerusakan data logis (jika data rusak (disengaja atau tidak sengaja) pada sistem penyimpanan utama, maka secara otomatis dan langsung akan menjadi rusak pada penyimpanan cadangan, karena data selalu identik (ini adalah paradoks)
Replikasi asinkron juga menyalin data dari penyimpanan utama ke cadangan, tetapi dengan penundaan tertentu dan tanpa perlu mengkonfirmasi catatan di sisi lain. Anda dapat bekerja dengan data segera setelah menulis ke penyimpanan utama, dan pada penyimpanan cadangan, data akan tersedia setelah beberapa saat. Identitas data dalam hal ini, tentu saja, tidak disediakan sama sekali. Data pada penyimpanan cadangan selalu sedikit "di masa lalu".
Plus dari replikasi asinkron:
- Biaya solusi rendah (semua saluran komunikasi, optik opsional)
- Tidak ada batasan jarak
- Data pada penyimpanan cadangan tidak rusak jika rusak pada utama (setidaknya untuk beberapa waktu), jika data menjadi rusak, Anda selalu dapat menghentikan replika untuk mencegah korupsi data pada penyimpanan cadangan
Cons:
- Data di pusat data yang berbeda selalu tidak identik
Dengan demikian, pilihan mode replikasi tergantung pada tugas-tugas bisnis. Jika penting bagi Anda bahwa pusat data cadangan memiliki data yang sama persis dengan data utama (mis. Persyaratan bisnis untuk RPO = 0), Anda harus membayar dan memasang dengan batasan replika sinkron. Dan jika keterlambatan dalam keadaan data diizinkan atau tidak ada uang, maka, pasti, Anda harus menggunakan metode asinkron.
Kami juga secara terpisah membedakan rezim seperti itu (lebih tepatnya, sudah menjadi topologi) sebagai metro cluster. Mode Metrocluster menggunakan replikasi sinkron, tetapi, tidak seperti replika biasa, metrocluster memungkinkan kedua sistem penyimpanan bekerja dalam mode aktif. Yaitu Anda tidak memiliki pemisahan pusat data siaga-aktif. Aplikasi bekerja secara bersamaan dengan dua sistem penyimpanan yang secara fisik terletak di pusat data yang berbeda. Downtime kecelakaan dalam topologi seperti itu sangat kecil (RTO, biasanya menit). Dalam artikel ini, kami tidak akan mempertimbangkan penerapan cluster metro kami, karena ini adalah topik yang sangat besar dan luas, jadi kami akan mencurahkan artikel terpisah, berikut untuk melanjutkannya.
Juga sangat sering, ketika kita berbicara tentang replikasi menggunakan sistem penyimpanan, banyak yang memiliki pertanyaan yang masuk akal:> "Banyak aplikasi memiliki alat replikasi sendiri, mengapa menggunakan replikasi pada sistem penyimpanan? Apakah ini lebih baik atau lebih buruk? "
Tidak ada jawaban tunggal, jadi inilah pro dan kontra:
Argumen UNTUK replikasi penyimpanan:
- Kesederhanaan solusinya. Dengan satu cara, Anda dapat mereplikasi seluruh larik data, apa pun jenis atau aplikasinya. Jika Anda menggunakan replika aplikasi, maka Anda harus mengkonfigurasi setiap aplikasi secara terpisah. Jika ada lebih dari 2 dari mereka, maka itu sangat memakan waktu dan mahal (replikasi aplikasi mensyaratkan, sebagai lisensi terpisah dan tidak gratis untuk setiap aplikasi. Tetapi lebih lanjut tentang itu di bawah).
- Anda dapat mereplikasi apa saja - aplikasi apa saja, data apa saja - dan mereka akan selalu konsisten. Banyak (sebagian besar) aplikasi tidak memiliki fasilitas replikasi, dan replika dari sisi penyimpanan adalah satu-satunya cara untuk memberikan perlindungan terhadap bencana.
- Tidak perlu membayar lebih untuk fungsionalitas replikasi aplikasi. Sebagai aturan, biayanya banyak, seperti halnya lisensi untuk sistem penyimpanan replika. Tetapi Anda perlu membayar lisensi replikasi penyimpanan hanya sekali, dan Anda perlu membeli lisensi untuk replika aplikasi untuk setiap aplikasi secara terpisah. Jika ada banyak aplikasi seperti itu, maka harganya cukup mahal dan biaya lisensi untuk replikasi penyimpanan menjadi setetes dalam ember.
Argumen TERHADAP replikasi penyimpanan:
- Replika menggunakan alat aplikasi memiliki lebih banyak fungsi dari sudut pandang aplikasi itu sendiri, aplikasi mengetahui datanya lebih baik (yang jelas), jadi ada lebih banyak pilihan untuk bekerja dengannya.
- Pembuat beberapa aplikasi tidak menjamin konsistensi data mereka jika replikasi dilakukan oleh alat pihak ketiga. *
* - tesis kontroversial. Sebagai contoh, sebuah perusahaan manufaktur DBMS yang terkenal, untuk waktu yang sangat lama secara resmi menyatakan bahwa DBMS mereka biasanya dapat direplikasi hanya dengan cara mereka, dan sisa replikasi (termasuk SHD-shnaya) adalah "tidak benar". Tetapi hidup telah menunjukkan bahwa ini tidak benar. Kemungkinan besar (tapi ini tidak akurat) ini sama sekali bukan upaya yang paling jujur untuk menjual lebih banyak lisensi kepada pelanggan.
Akibatnya, dalam banyak kasus, replikasi dari sisi penyimpanan lebih baik, karena Ini adalah pilihan yang lebih sederhana dan lebih murah, tetapi ada kasus kompleks ketika Anda membutuhkan fungsionalitas aplikasi spesifik, dan Anda perlu bekerja dengan replikasi tingkat aplikasi.
Dengan teori selesai, sekarang berlatih
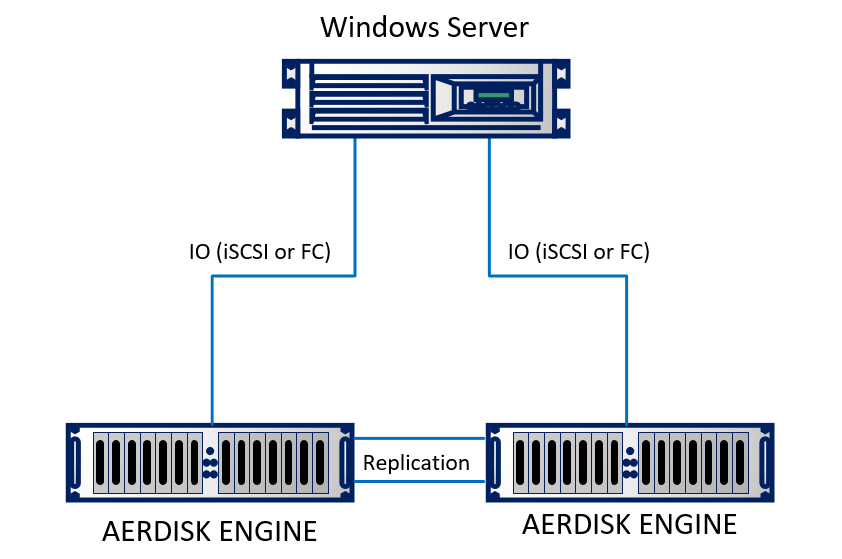
Kami akan membuat replika di lab kami. Di laboratorium, kami meniru dua pusat data (pada kenyataannya, dua rak yang berdekatan yang tampaknya berada di gedung yang berbeda). Dudukan terdiri dari dua sistem penyimpanan Engine N2, yang saling terhubung oleh kabel optik. Server fisik yang menjalankan Windows Server 2016 menggunakan 10Gb Ethernet terhubung ke kedua sistem penyimpanan. Dudukannya cukup sederhana, tetapi tidak mengubah esensinya.
Secara skematis, tampilannya seperti ini:
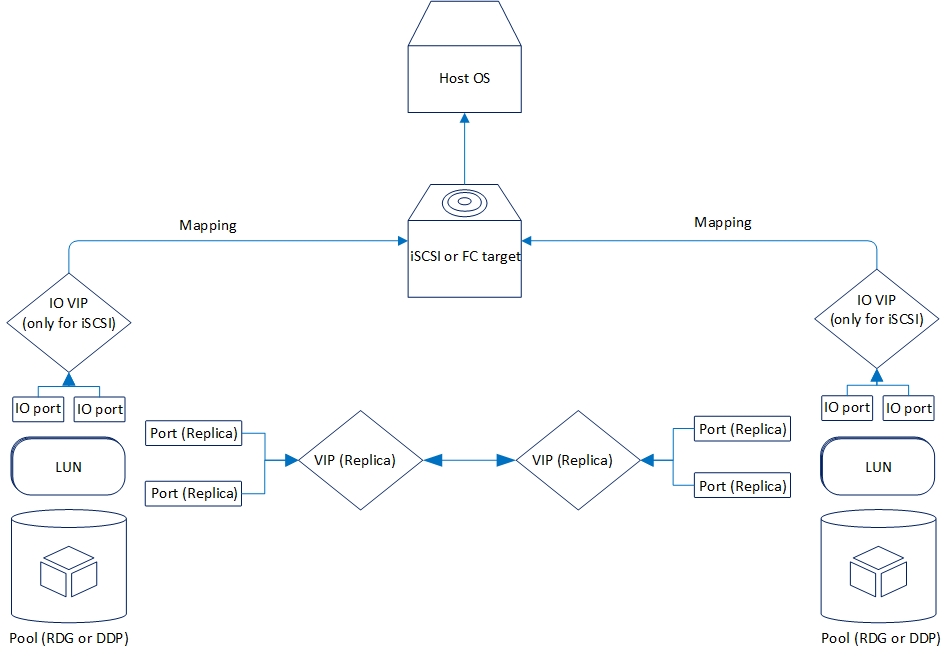
Replikasi logis diatur sebagai berikut:
Sekarang mari kita lihat fungsi replikasi yang kita miliki sekarang.
Dua mode didukung: asinkron dan sinkron. Adalah logis bahwa mode sinkron dibatasi oleh jarak dan saluran komunikasi. Secara khusus, mode sinkron memerlukan penggunaan serat sebagai fisika dan 10 gigabit Ethernet (atau lebih tinggi).
Jarak yang didukung untuk replikasi sinkron adalah 40 kilometer, penundaan saluran optik antara pusat data hingga 2 milidetik. Secara umum, ini akan bekerja dengan penundaan besar, tetapi kemudian akan ada rem yang kuat saat merekam (yang juga logis), jadi jika Anda mempertimbangkan replikasi sinkron antara pusat data, Anda harus memeriksa kualitas optik dan penundaan.
Persyaratan replikasi asinkron tidak begitu serius. Lebih tepatnya, mereka sama sekali tidak. Koneksi Ethernet yang berfungsi cocok.
Saat ini, penyimpanan AERODISK ENGINE mendukung replikasi untuk perangkat blok (LUN) menggunakan protokol Ethernet (tembaga atau optik). Untuk proyek-proyek yang perlu direplikasi melalui pabrik Fibre Channel SAN, kami sekarang menyelesaikan solusi yang sesuai, tetapi sejauh ini belum siap, jadi dalam kasus kami hanya Ethernet.
Replikasi dapat bekerja di antara sistem penyimpanan seri ENGINE (N1, N2, N4) dari sistem yang lebih rendah ke yang lebih lama dan sebaliknya.
Fungsionalitas kedua mode replikasi benar-benar identik. Di bawah ini lebih lanjut tentang apa itu:
- Replikasi "satu ke satu" atau "satu ke satu", yaitu, versi klasik dengan dua pusat data, utama dan cadangan
- Replikasi adalah "satu ke banyak" atau "satu ke banyak", yaitu satu LUN dapat direplikasi ke beberapa sistem penyimpanan sekaligus
- Aktivasi, deaktivasi, dan "pembalikan" replikasi, masing-masing, untuk mengaktifkan, menonaktifkan atau mengubah arah replikasi
- Replikasi tersedia untuk kelompok RDG (Raid Distributed Group) dan DDP (Dynamic Disk Pool). Namun, RDG pool LUN hanya dapat direplikasi ke RDG lain. C DDP serupa.
Ada banyak fitur yang lebih kecil, tetapi daftar mereka tidak masuk akal, kami akan menyebutkannya selama pengaturan.
Setup replikasi
Proses pengaturannya cukup sederhana dan terdiri dari tiga tahap.
- Pengaturan jaringan
- Pengaturan Penyimpanan
- Menyiapkan aturan (tautan) dan pemetaan
Poin penting dalam mengonfigurasi replikasi adalah bahwa dua tahap pertama harus diulang pada sistem penyimpanan jarak jauh, tahap ketiga - hanya pada tahap utama.
Konfigurasi Sumber Daya Jaringan
Langkah pertama adalah mengkonfigurasi port jaringan di mana lalu lintas replikasi akan dikirimkan. Untuk melakukan ini, Anda perlu mengaktifkan port dan mengatur alamat IP pada port tersebut di bagian Adapter front-end.
Setelah itu kita perlu membuat kumpulan (dalam kasus kami RDG) dan IP virtual untuk replikasi (VIP). VIP adalah alamat IP mengambang yang terikat pada dua alamat "fisik" pengontrol penyimpanan (port yang baru saja kami konfigurasikan). Ini akan menjadi antarmuka replikasi utama. Anda juga dapat beroperasi bukan dengan VIP, tetapi dengan VLAN jika Anda perlu bekerja dengan lalu lintas yang ditandai.
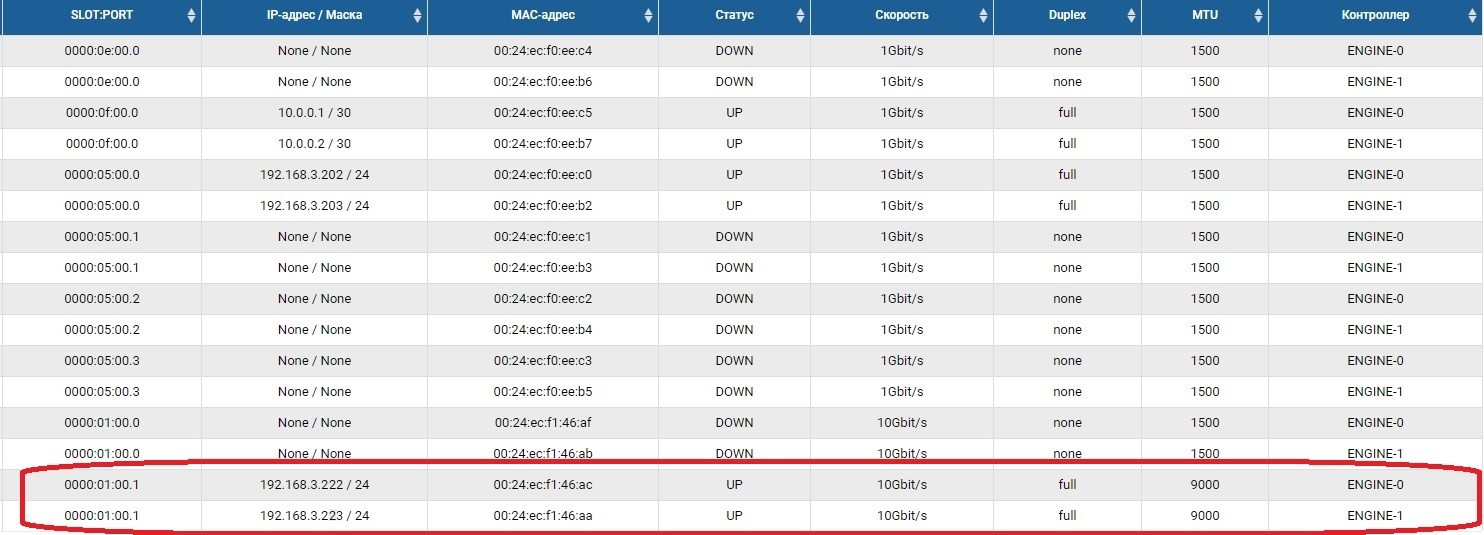
Proses membuat VIP untuk replika tidak jauh berbeda dari membuat VIP untuk I / O (NFS, SMB, iSCSI). Dalam hal ini, kami membuat VIP (tanpa VLAN), tetapi pastikan untuk menunjukkan bahwa itu untuk replikasi (tanpa penunjuk ini, kami tidak akan dapat menambahkan VIP ke aturan di langkah berikutnya).
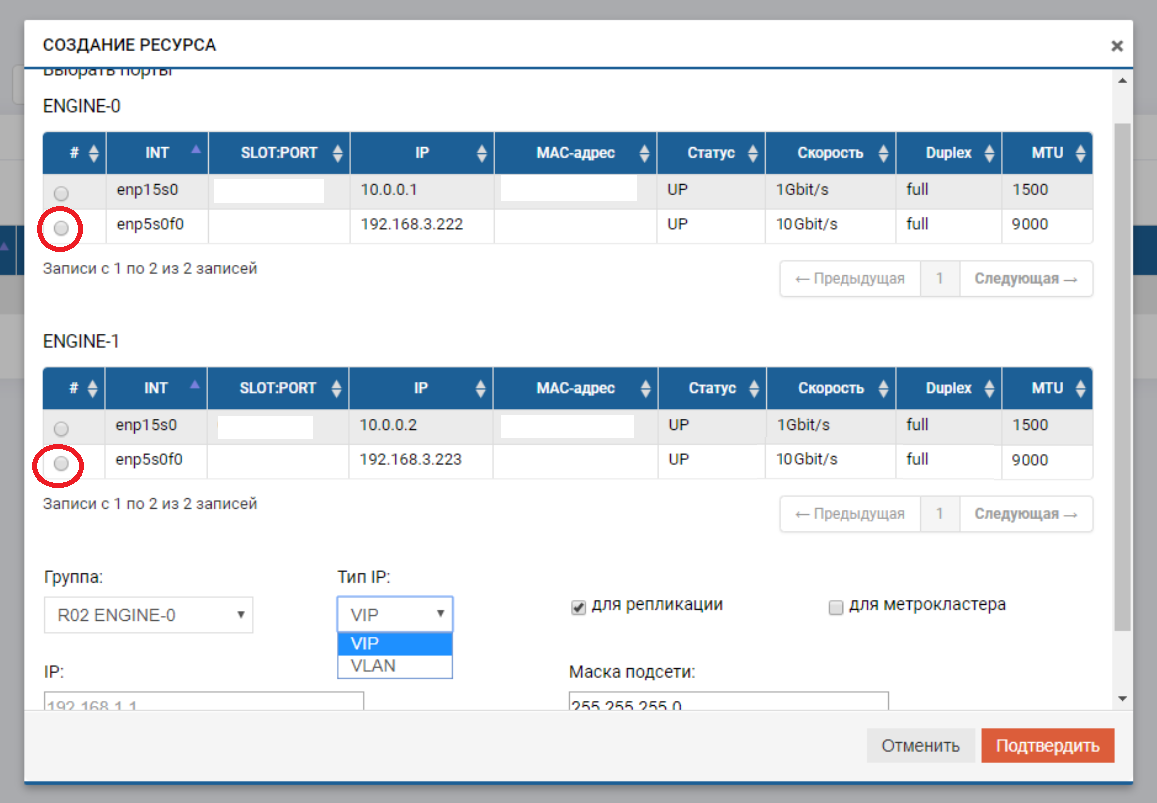
VIP harus berada di subnet yang sama dengan port IP di mana ia "mengapung".

Kami ulangi pengaturan ini pada sistem penyimpanan jarak jauh, dengan IP-shnik lain, dengan sendirinya.
VIP dari sistem penyimpanan yang berbeda dapat berada di subnet yang berbeda, yang utama adalah harus ada perutean di antara mereka. Dalam kasus kami, contoh ini baru saja ditampilkan (192.168.3.XX dan 192.168.2.XX)

Pada ini, persiapan bagian jaringan selesai.
Konfigurasikan penyimpanan
Mengkonfigurasi penyimpanan untuk replika berbeda dari yang biasa hanya dalam hal kita melakukan pemetaan melalui menu khusus “Pemetaan replikasi”. Kalau tidak, semuanya sama dengan pengaturan biasa. Sekarang sudah beres.
Di kumpulan R02 yang sebelumnya dibuat, Anda harus membuat LUN. Buat, sebut saja LUN1.
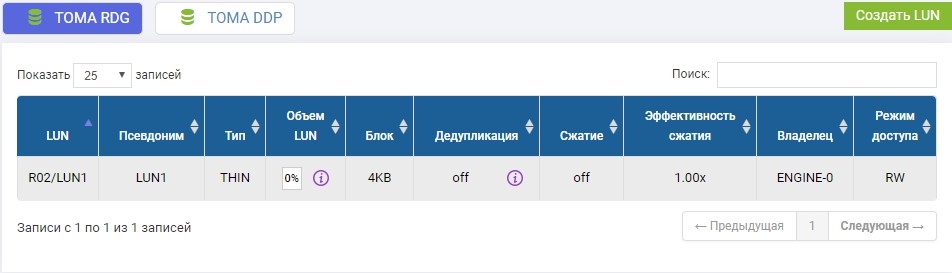
Kita juga perlu membuat LUN yang sama pada sistem penyimpanan jarak jauh dengan volume yang sama. Kami menciptakan. Untuk menghindari kebingungan, LUN jarak jauh akan disebut LUN1R
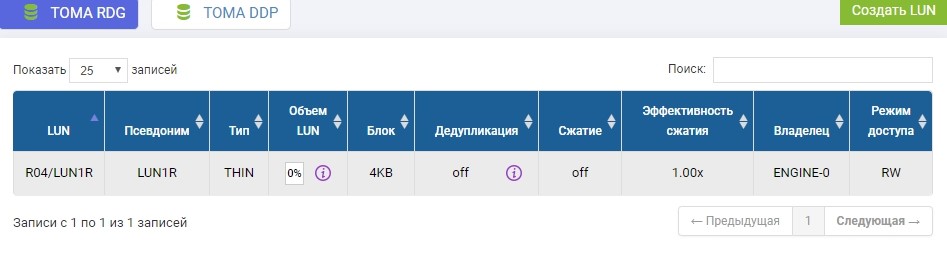
Jika kita perlu mengambil LUN yang sudah ada, maka pada saat setup replika, LUN yang produktif ini harus dilepas dari host, dan pada sistem penyimpanan jarak jauh cukup buat LUN kosong dengan ukuran yang sama.
Pengaturan penyimpanan selesai, kami melanjutkan ke pembuatan aturan replikasi.
Konfigurasikan aturan replikasi atau tautan replikasi
Setelah membuat LUN pada penyimpanan, yang akan menjadi yang utama saat ini, kami mengkonfigurasi aturan replikasi LUN1 pada SHD1 di LUN1R pada SHD2.
Konfigurasi dilakukan di menu Replikasi Jarak Jauh.
Buat aturan. Untuk melakukan ini, tentukan penerima replika. Kami juga menentukan nama koneksi dan jenis replikasi (sinkron atau asinkron).
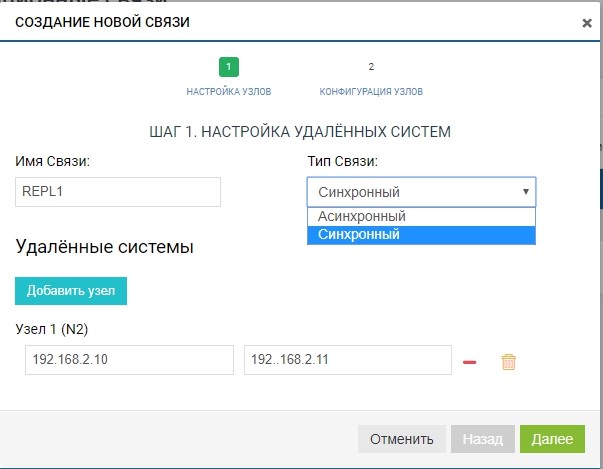
Di bidang "sistem jarak jauh", tambahkan SHD2 kami. Untuk menambahkan, Anda perlu menggunakan penyimpanan IP pengelolaan (MGR) dan nama LUN jarak jauh yang akan kami tiru (dalam kasus kami, LUN1R). Mengelola IP diperlukan hanya pada tahap penambahan komunikasi, lalu lintas replikasi melalui mereka tidak akan ditransmisikan, untuk ini, VIP yang sebelumnya dikonfigurasi akan digunakan.
Sudah pada tahap ini, kita dapat menambahkan lebih dari satu sistem jarak jauh untuk topologi "satu ke banyak": klik tombol "tambahkan simpul", seperti pada gambar di bawah ini.
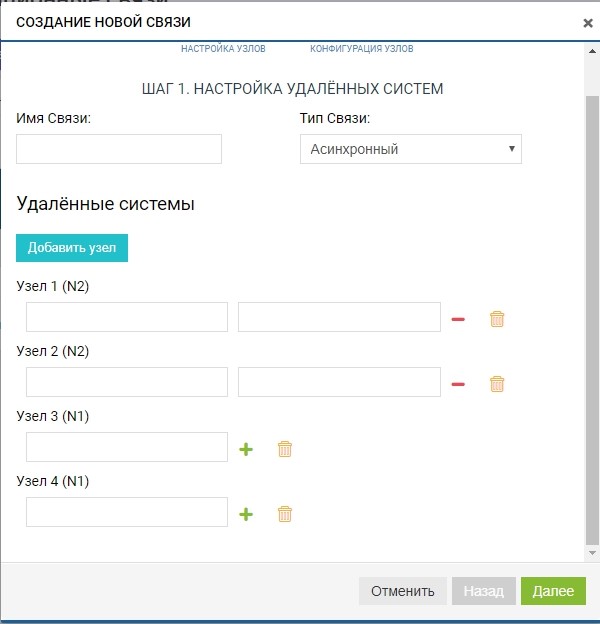
Dalam kasus kami, sistem jarak jauh adalah satu, jadi kami terbatas pada ini.
Aturannya sudah siap. Perhatikan bahwa itu secara otomatis ditambahkan ke semua peserta replikasi (dalam kasus kami, ada dua dari mereka). Anda dapat membuat aturan sebanyak yang Anda suka, untuk sejumlah LUN dan ke arah mana pun. Misalnya, untuk menyeimbangkan beban, kita dapat mereplikasi bagian LUN dari SHD1 ke SHD2, dan bagian lain, sebaliknya, dari SHD2 ke SHD1.
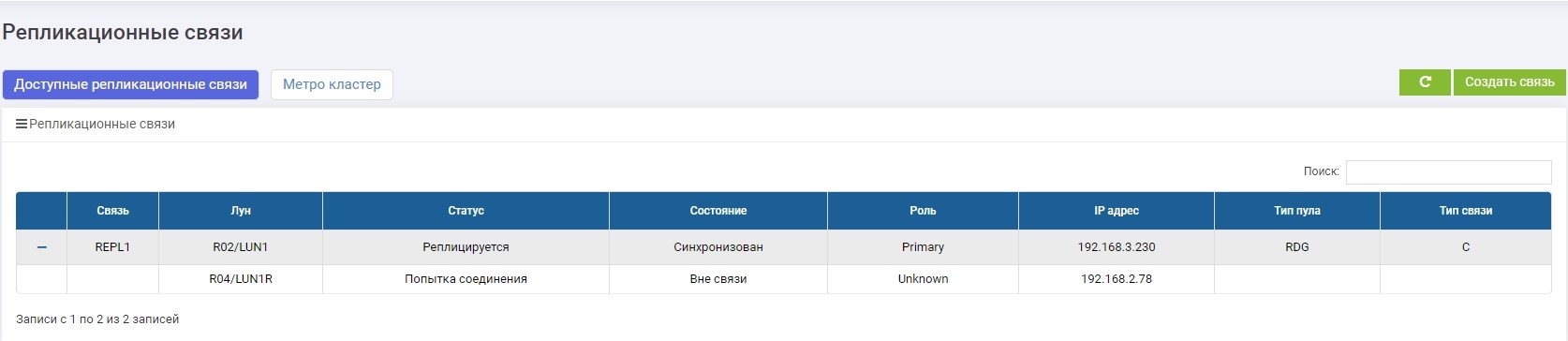
SHD1. Segera setelah pembuatan, sinkronisasi dimulai.
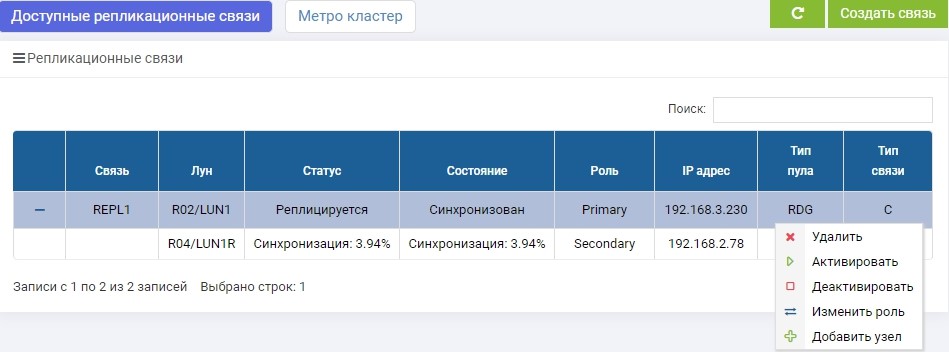
SHD2. Kami melihat aturan yang sama, tetapi sinkronisasi sudah berakhir.
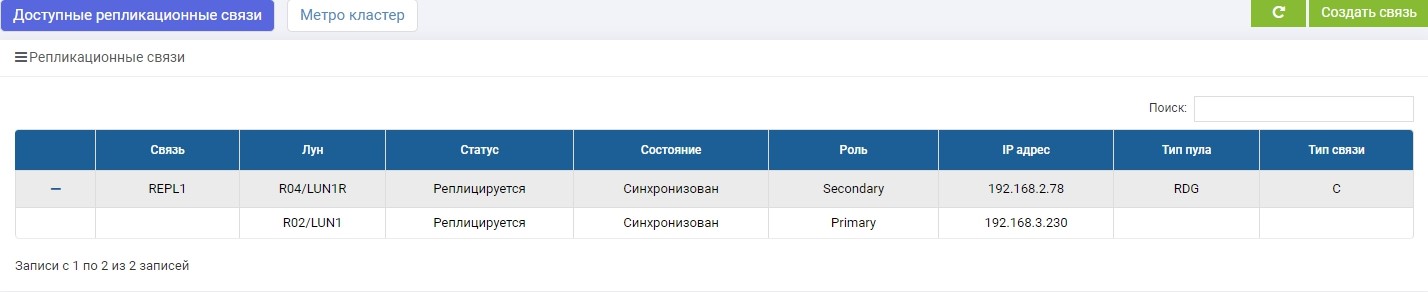
LUN1 pada SHD1 adalah dalam peran Pratama, yaitu aktif. LUN1R pada SHD2 adalah dalam peran Sekunder, yaitu ditahan, dalam kasus kegagalan SHD1.
Sekarang kita dapat menghubungkan LUN kita ke host.
Kami akan melakukan koneksi melalui iSCSI, meskipun itu dapat dilakukan melalui FC. Menyiapkan pemetaan untuk iSCSI LUN dalam replika praktis tidak berbeda dari skenario yang biasa, jadi kami tidak akan membahas ini secara rinci di sini. Jika ada, proses ini dijelaskan dalam artikel Pengaturan Cepat .
Satu-satunya perbedaan adalah kami membuat pemetaan di menu “Pemetaan replikasi”.
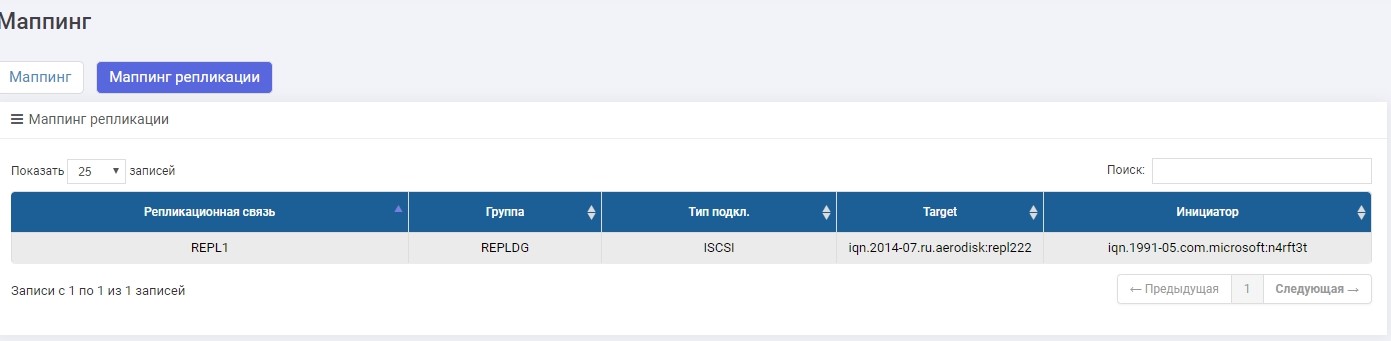
Atur pemetaan, berikan LUN ke tuan rumah. Tuan rumah melihat LUN.
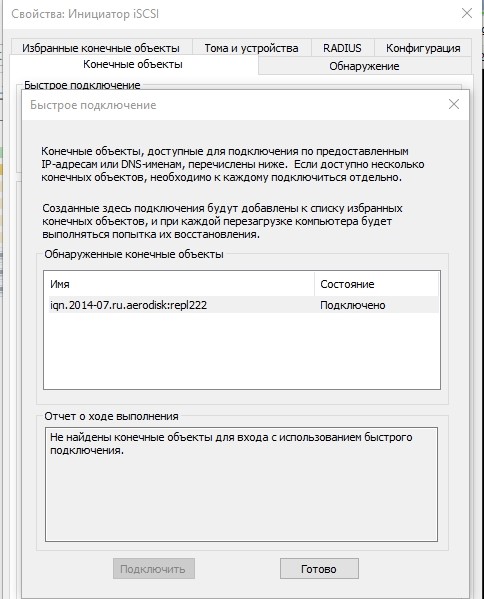
Memformatnya ke sistem file lokal.
Itu dia, setup sudah selesai. Selanjutnya akan pergi tes.
Pengujian
Kami akan menguji tiga skenario utama.
- Pergantian peran staf Sekunder> Primer. Pergantian peran rutin diperlukan jika, misalnya, kami terutama membutuhkan pusat data untuk melakukan beberapa operasi pencegahan, dan selama waktu ini, agar data tersedia, kami mentransfer beban ke pusat data cadangan.
- Kegagalan peran Sekunder> Primer (kegagalan pusat data). Ini adalah skenario utama yang ada replikasi, yang dapat membantu bertahan dari kegagalan pusat data yang lengkap tanpa menghentikan perusahaan untuk waktu yang lama.
- Saluran komunikasi terputus antara pusat data. Memeriksa perilaku yang benar dari dua sistem penyimpanan dalam kondisi ketika karena suatu alasan saluran komunikasi antara pusat data tidak tersedia (misalnya, excavator menggali di tempat yang salah dan merobek melalui optik gelap).
Untuk memulainya, kita akan mulai menulis data ke LUN kita (kita menulis file dengan data acak). Kami segera melihat bahwa saluran komunikasi antara sistem penyimpanan sedang digunakan. Ini mudah dimengerti jika Anda membuka pemantauan port yang bertanggung jawab untuk replikasi.
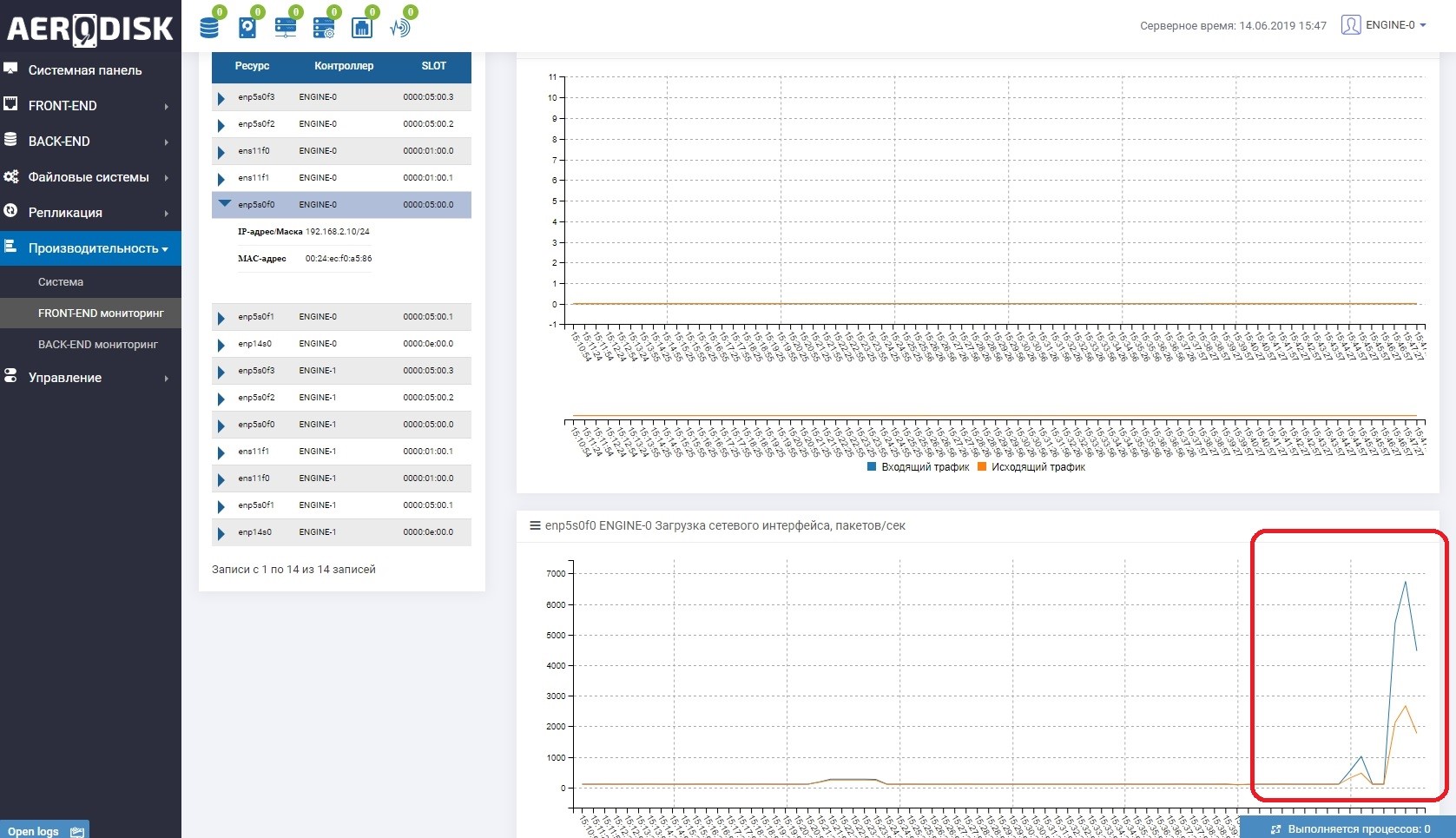
Pada kedua sistem penyimpanan sekarang ada data "berguna", kita dapat memulai tes.
Untuk berjaga-jaga, mari kita lihat jumlah hash dari salah satu file dan tuliskan.
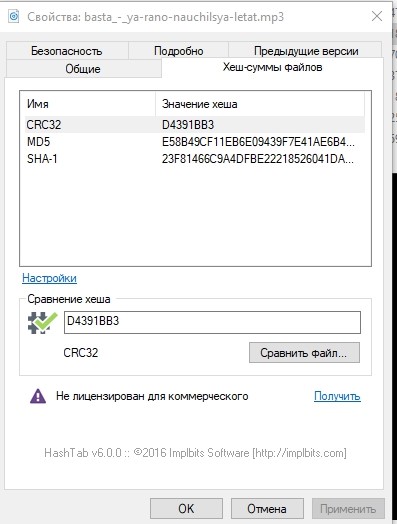
Pergantian Peran Staf
Pengoperasian peran switching (mengubah arah replikasi) dapat dilakukan dari sistem penyimpanan apa pun, tetapi Anda masih harus menuju keduanya, karena Anda harus menonaktifkan pemetaan pada Primary, dan mengaktifkannya pada Secondary (yang akan menjadi Primary).
Mungkin sekarang muncul pertanyaan yang masuk akal: mengapa tidak mengotomatiskan ini? Kami menjawab: semuanya sederhana, replikasi adalah alat toleransi bencana sederhana yang hanya didasarkan pada operasi manual. Untuk mengotomatiskan operasi ini, ada mode cluster metro, ini sepenuhnya otomatis, tetapi konfigurasinya jauh lebih rumit. Kami akan menulis tentang pengaturan metro cluster di artikel selanjutnya.
Nonaktifkan pemetaan pada penyimpanan utama untuk memastikan perekaman dihentikan.
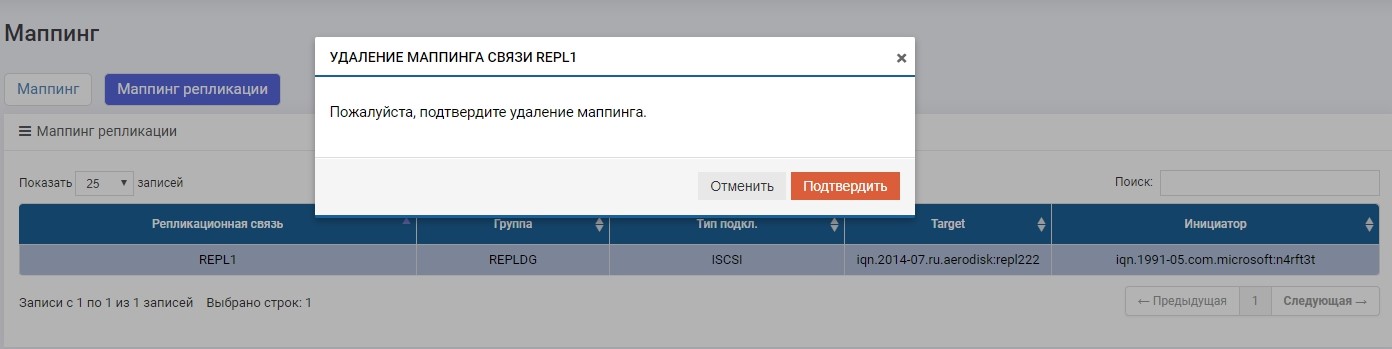
Kemudian pada salah satu sistem penyimpanan (tidak masalah, pada primer atau cadangan) di menu Replikasi Jarak Jauh, pilih koneksi REPL1 kami dan klik "Ubah Peran".
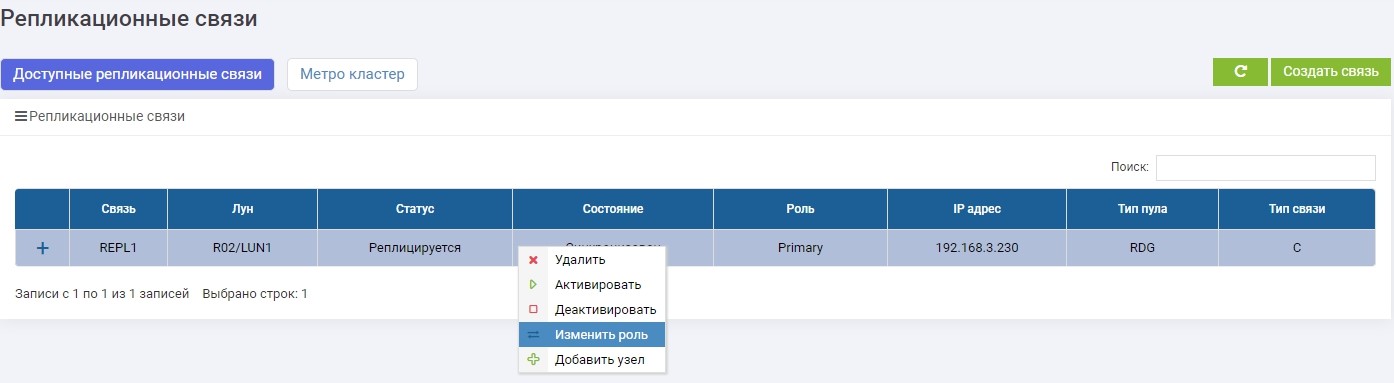
Setelah beberapa detik, LUN1R (penyimpanan cadangan) menjadi Utama.
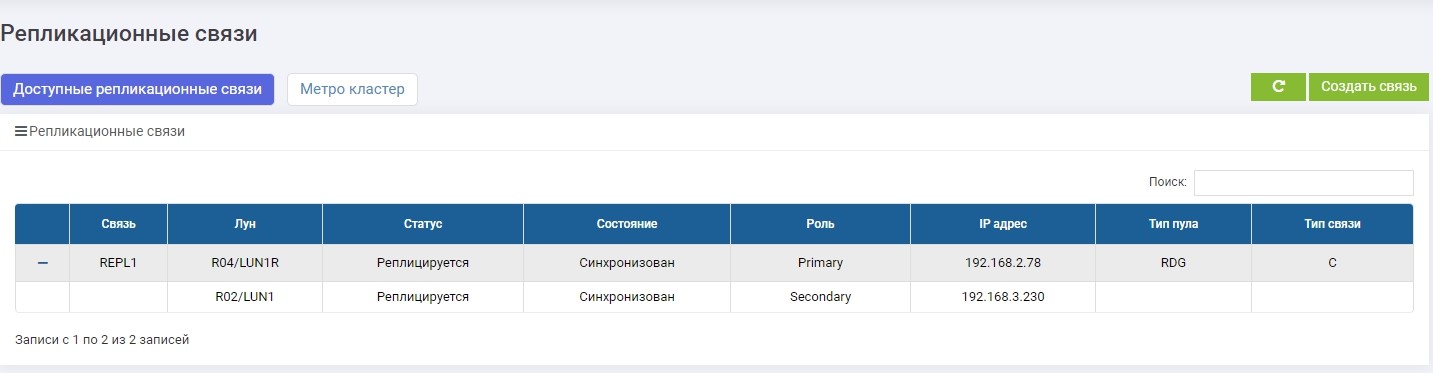
Kami membuat pemetaan LUN1R dengan SHD2.
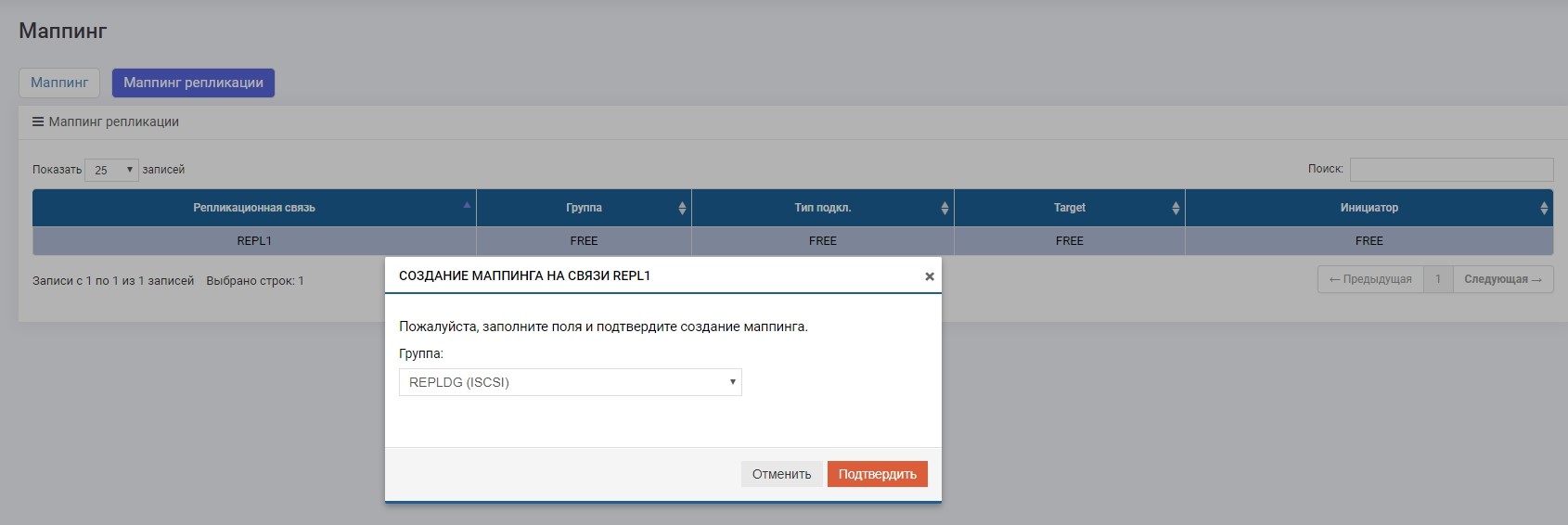
Setelah itu, drive E: kami secara otomatis menempel pada host, hanya saja kali ini "terbang" dengan LUN1R.
Untuk jaga-jaga, bandingkan jumlah hash.
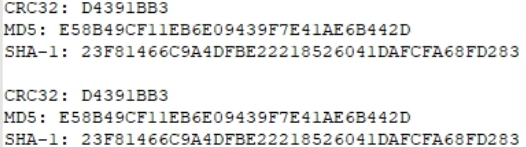
Identik Tes berlalu.
Kegagalan Kegagalan Pusat Data
Saat ini, penyimpanan utama setelah switching reguler adalah SHD2 dan LUN1R, masing-masing. Untuk mensimulasikan kecelakaan, kami mematikan daya pada kedua kontroler SHD2.
Akses ke sana tidak lagi.
Kami melihat apa yang terjadi pada penyimpanan 1 (cadangan saat ini).

Kami melihat bahwa LUN Primer (LUN1R) tidak tersedia. Pesan kesalahan muncul di log, di panel informasi, serta di aturan replikasi itu sendiri. Karenanya, data dari tuan rumah saat ini tidak tersedia.
Ubah peran LUN1 menjadi Utama.
Urusan pemetaan ke tuan rumah.

Pastikan drive E muncul di host.
Periksa hash.
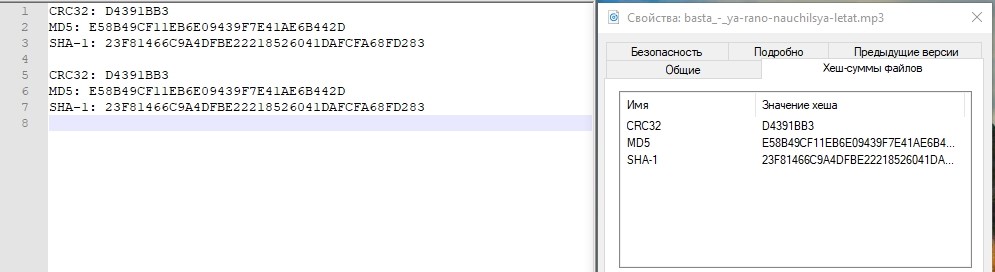
Semuanya baik-baik saja. Pusat penyimpanan mengalami penurunan di pusat data, yang aktif. Perkiraan waktu yang kami habiskan untuk menghubungkan "pembalikan" replikasi dan menghubungkan LUN dari pusat data cadangan adalah sekitar 3 menit. Jelas bahwa dalam produk nyata semuanya jauh lebih rumit, dan di samping tindakan dengan sistem penyimpanan, Anda perlu melakukan lebih banyak operasi pada jaringan, pada host, dalam aplikasi. Dan dalam hidup, periode waktu ini akan jauh lebih lama.
Di sini saya ingin menulis bahwa semuanya, tes selesai dengan sukses, tapi jangan terburu-buru. Penyimpanan utama "terletak", kita tahu bahwa ketika dia "jatuh", dia berperan sebagai Pratama. Apa yang terjadi jika dia tiba-tiba hidup? Akan ada dua peran utama, yang sama dengan korupsi data? Kami akan memeriksanya sekarang.
Kami tiba-tiba akan mengaktifkan penyimpanan yang mendasarinya.
Ini memuat selama beberapa menit dan setelah itu kembali beroperasi setelah sinkronisasi singkat, tetapi sudah dalam peran Sekunder.

Semuanya baik-baik saja. Otak yang terbelah tidak terjadi. Kami memikirkan hal ini, dan selalu setelah jatuhnya sistem penyimpanan naik dalam peran Sekunder, terlepas dari apa perannya "dalam kehidupan". Sekarang kita dapat mengatakan dengan pasti bahwa uji kegagalan pusat data berhasil.
Kegagalan saluran komunikasi antara pusat data
Tugas utama dari tes ini adalah untuk memastikan bahwa sistem penyimpanan tidak akan mulai panik jika sementara itu kehilangan saluran komunikasi antara kedua sistem penyimpanan dan kemudian muncul kembali.
Jadi Kami mencabut kabel antara sistem penyimpanan (bayangkan bahwa sebuah excavator menggali mereka).
Di Pratama kita melihat bahwa tidak ada hubungan dengan Sekunder.
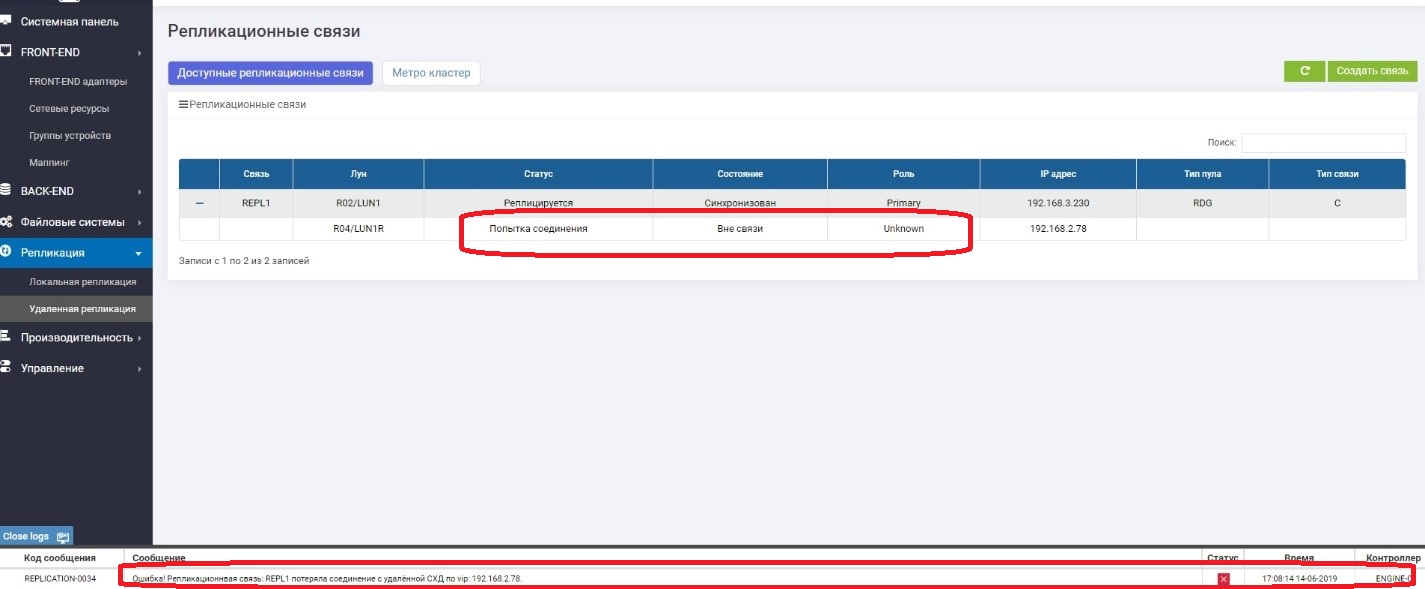
Pada Sekunder, kita melihat bahwa tidak ada koneksi dengan Pratama.
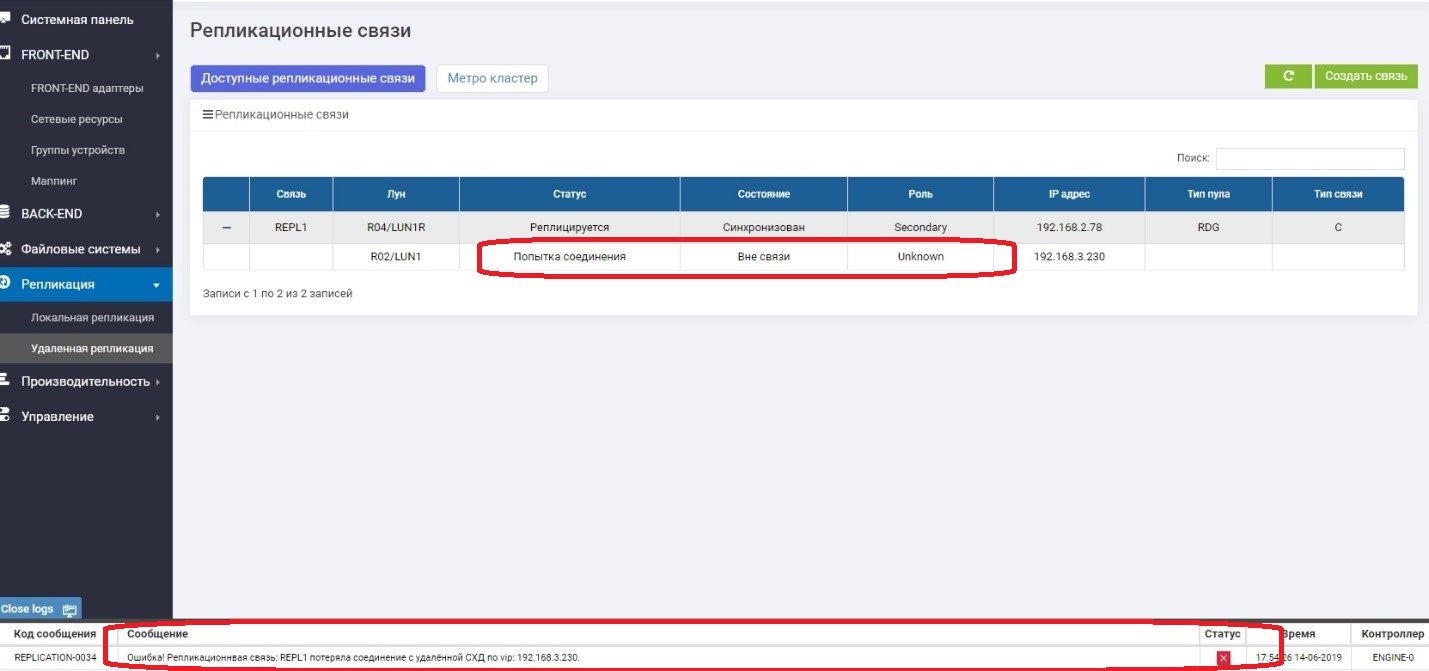
Semuanya berfungsi dengan baik, dan kami terus menulis data ke sistem penyimpanan utama, yaitu, mereka sudah dijamin berbeda dari yang cadangan, yaitu, mereka telah "pergi".
Dalam beberapa menit kami memperbaiki saluran komunikasi. Segera setelah sistem penyimpanan saling melihat, sinkronisasi data dihidupkan secara otomatis. Tidak ada yang diperlukan dari administrator.

.
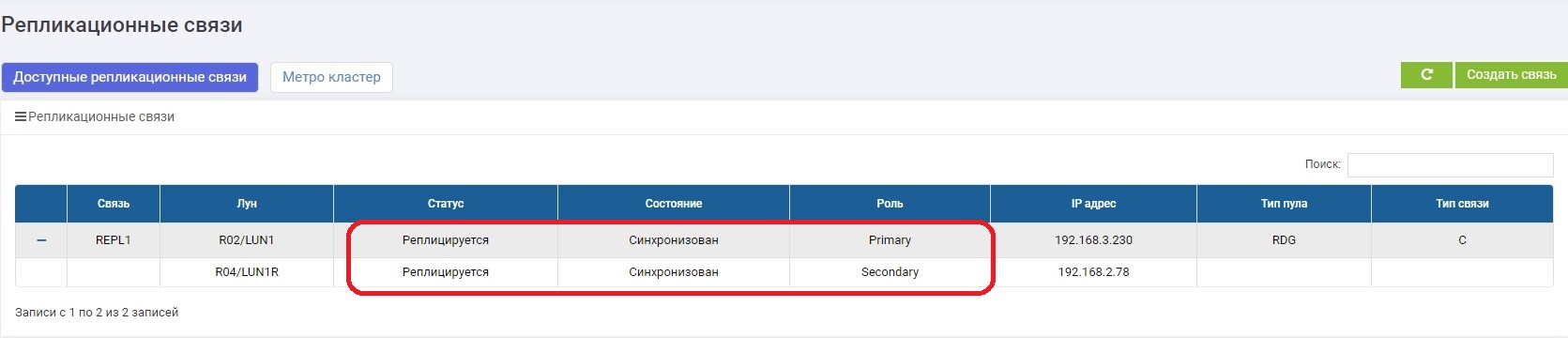
, , .
– , , . .
, - . . , .
active-active, , .
, .
.