Menurut Anda siapa yang lebih baik mengkonfigurasi algoritma PostgreSQL - DBA atau ML? Dan jika yang kedua, maka sudah saatnya bagi kita untuk memikirkan apa yang harus dilakukan ketika mobil menggantikan kita. Atau tidak akan sampai di situ, dan keputusan penting masih harus dibuat oleh orang-orang. Mungkin, tingkat isolasi dan persyaratan untuk stabilitas transaksi harus tetap dengan administrator. Tetapi indeks dapat segera dipercaya untuk menentukan mesin sendiri.

Andy Pavlo di
HighLoad ++ berbicara tentang DBMS masa depan, yang dapat Anda "sentuh" sekarang. Jika Anda melewatkan pidato ini atau lebih suka menerima informasi dalam bahasa Rusia - di bawah cut adalah terjemahan pidato.
Ini akan tentang proyek Universitas Carnegie Mellon tentang penciptaan DBMS otonom. Istilah "otonom" berarti sistem yang dapat secara otomatis menggunakan, mengkonfigurasi, mengkonfigurasi sendiri tanpa campur tangan manusia. Diperlukan waktu sekitar sepuluh tahun untuk mengembangkan sesuatu seperti ini, tetapi itulah yang dilakukan Andy dan murid-muridnya. Tentu saja, algoritma pembelajaran mesin diperlukan untuk membuat DBMS yang otonom, namun, dalam artikel ini kita akan fokus hanya pada sisi teknik dari topik. Pertimbangkan cara mendesain perangkat lunak untuk membuatnya mandiri.
Tentang pembicara: Andy Pavlo, associate professor di Carnegie Mellon University, di bawah kepemimpinannya menciptakan
PelotonDB DBMS yang "dikelola sendiri" , serta
ottertune , yang membantu menyempurnakan PostgreSQL dan konfigurasi MySQL menggunakan pembelajaran mesin. Andy dan timnya sekarang menjadi pemimpin sejati dalam database yang dikelola sendiri.
Alasan kami ingin membuat DBMS yang otonom sudah jelas. Mengelola alat-alat DBMS ini adalah proses yang sangat mahal dan memakan waktu. Gaji DBA rata-rata di Amerika Serikat adalah sekitar 89 ribu dolar per tahun. Diterjemahkan ke dalam rubel, 5,9 juta rubel per tahun diperoleh. Jumlah yang sangat besar ini Anda bayar orang hanya untuk mengawasi perangkat lunak Anda. Sekitar 50% dari total biaya penggunaan database dibayar oleh pekerjaan administrator dan staf terkait.
Ketika datang ke proyek yang sangat besar, seperti kita bahas di HighLoad ++ dan yang menggunakan puluhan ribu database, kompleksitas struktur mereka melampaui persepsi manusia. Semua orang mendekati masalah ini secara dangkal dan mencoba mencapai kinerja maksimal dengan menginvestasikan upaya minimal dalam memperbaiki sistem.
Anda dapat menyimpan jumlah bulat jika Anda mengkonfigurasi DBMS di tingkat aplikasi dan lingkungan untuk memastikan kinerja maksimum.
Database adaptif sendiri, 1970-1990
Gagasan DBMS otonom bukanlah hal baru, sejarah mereka kembali ke tahun 1970-an, ketika database relasional pertama kali mulai dibuat. Kemudian mereka disebut database self-adaptive (Self-Adaptive Databases), dan dengan bantuan mereka, mereka mencoba memecahkan masalah klasik dari desain basis data, di mana orang masih berjuang sampai hari ini. Ini adalah pilihan indeks, partisi dan konstruksi skema database, serta penempatan data. Pada saat itu, alat dikembangkan yang membantu administrator database menyebarkan DBMS. Alat-alat ini, pada kenyataannya, bekerja seperti yang dilakukan rekan-rekan modern mereka saat ini.
Administrator melacak permintaan yang dijalankan oleh aplikasi. Mereka kemudian meneruskan tumpukan query ini ke algoritma tuning, yang membangun model internal tentang bagaimana aplikasi harus menggunakan database.
Jika Anda membuat alat yang membantu Anda secara otomatis memilih indeks, maka buatlah bagan dari mana Anda bisa melihat seberapa sering setiap kolom diakses. Kemudian meneruskan informasi ini ke algoritma pencarian, yang akan melihat melalui berbagai lokasi - akan mencoba untuk menentukan kolom mana yang dapat diindeks dalam database. Algoritme akan menggunakan model biaya internal untuk menunjukkan bahwa yang satu ini akan memberikan kinerja yang lebih baik dibandingkan dengan indeks lainnya. Kemudian algoritma akan memberikan saran tentang perubahan indeks apa yang harus dilakukan. Pada saat ini, sudah waktunya untuk berpartisipasi dalam orang tersebut, mempertimbangkan proposal ini dan tidak hanya memutuskan apakah itu benar, tetapi juga memilih waktu yang tepat untuk pelaksanaannya.

DBA harus tahu bagaimana aplikasi digunakan ketika ada penurunan aktivitas pengguna. Misalnya, pada hari Minggu pukul 3:00 pagi, tingkat terendah dari permintaan basis data, sehingga saat ini Anda dapat memuat ulang indeks.
Seperti yang saya katakan, semua alat desain waktu bekerja dengan cara yang sama -
ini adalah
masalah yang sangat lama . Pengawas ilmiah dari pengawas ilmiah saya menulis artikel tentang pemilihan indeks otomatis pada tahun 1976.
Database self-tuning, 1990-2000
Pada 1990-an, orang, pada kenyataannya, bekerja pada masalah yang sama, hanya namanya yang berubah dari database adaptif ke self-tuning.
Algoritma menjadi sedikit lebih baik, alat menjadi sedikit lebih baik, tetapi pada tingkat tinggi mereka bekerja dengan cara yang sama seperti sebelumnya. Satu-satunya perusahaan di garis depan pergerakan sistem self-tuning adalah Microsoft Research dengan proyek administrasi otomatis mereka. Mereka mengembangkan solusi yang benar-benar luar biasa, dan pada akhir 90-an dan awal 00-an mereka sekali lagi mempresentasikan serangkaian rekomendasi untuk menyiapkan basis data mereka.
Gagasan kunci yang diajukan Microsoft berbeda dari apa yang ada di masa lalu - alih-alih memiliki alat penyesuaian mendukung model mereka sendiri, mereka sebenarnya hanya menggunakan kembali model biaya pengoptimal permintaan untuk membantu menentukan manfaat dari satu indeks terhadap yang lain. Jika Anda memikirkannya, itu masuk akal. Ketika Anda perlu tahu apakah satu indeks benar-benar dapat mempercepat kueri, tidak masalah seberapa besar jika pengoptimal tidak memilihnya. Oleh karena itu, pengoptimal digunakan untuk mencari tahu apakah ia benar-benar akan memilih sesuatu.

Pada tahun 2007, Microsoft Research menerbitkan
sebuah artikel yang menetapkan retrospektif penelitian selama sepuluh tahun. Dan itu mencakup dengan baik semua tugas kompleks yang muncul di setiap segmen jalan.
Tugas lain yang telah disorot dalam era self-tuning database adalah
bagaimana membuat penyesuaian otomatis ke regulator. Pengontrol basis data adalah semacam parameter konfigurasi yang mengubah perilaku sistem basis data saat runtime. Misalnya, parameter yang ada di hampir setiap basis data adalah ukuran buffer. Atau, misalnya, Anda dapat mengelola pengaturan seperti kebijakan pemblokiran, frekuensi pembersihan disk, dan sejenisnya. Karena peningkatan signifikan dalam kompleksitas regulator DBMS dalam beberapa tahun terakhir, topik ini menjadi relevan.
Untuk menunjukkan betapa buruknya hal itu, saya akan memberikan ulasan yang dilakukan siswa saya setelah mempelajari banyak rilis PostgreSQL dan MySQL.
Selama 15 tahun terakhir, jumlah regulator di PostgreSQL telah meningkat 5 kali, dan untuk MySQL - 7 kali.
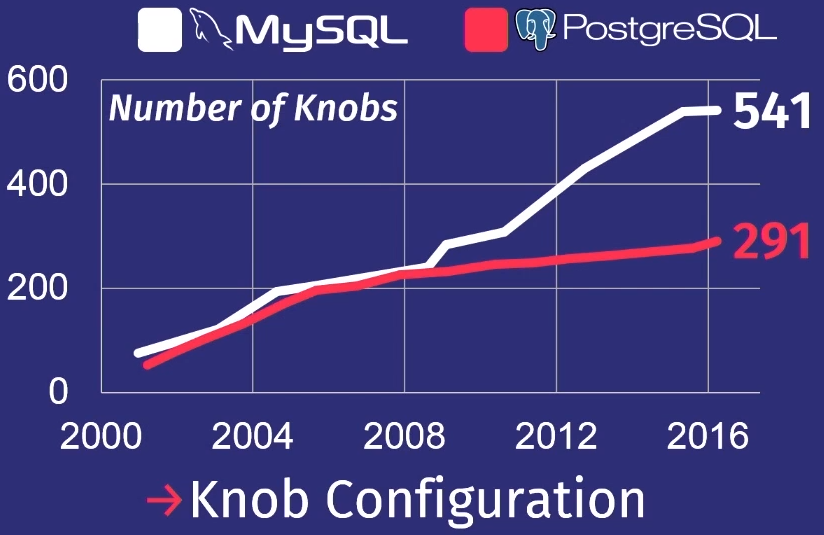
Tentu saja, tidak semua regulator benar-benar mengendalikan proses pelaksanaan tugas. Beberapa, misalnya, berisi jalur file atau alamat jaringan, jadi hanya seseorang yang dapat mengonfigurasinya. Tetapi beberapa dari mereka benar-benar dapat mempengaruhi kinerja. Tidak ada orang yang bisa memegang begitu banyak di kepalanya.
Cloud DB, 2010–…
Selanjutnya kita menemukan diri kita di era 2010-an, di mana kita berada hingga hari ini. Saya menyebutnya era basis data cloud. Selama waktu ini, banyak pekerjaan telah dilakukan untuk mengotomatiskan penyebaran sejumlah besar database di cloud.
Hal utama yang mengkhawatirkan penyedia cloud utama adalah bagaimana meng-host penyewa atau bermigrasi dari satu ke yang lain. Bagaimana menentukan berapa banyak sumber daya yang dibutuhkan masing-masing penyewa, dan kemudian mencoba mendistribusikannya di antara alat berat untuk memaksimalkan produktivitas atau mencocokkan SLA dengan biaya minimal.
Amazon, Microsoft dan Google menyelesaikan masalah ini, tetapi terutama di tingkat operasional. Baru-baru ini, penyedia layanan cloud mulai berpikir tentang perlunya mengkonfigurasi sistem basis data individual. Pekerjaan ini tidak terlihat oleh pengguna biasa, tetapi menentukan tingkat tinggi perusahaan.
Kesimpulan penelitian 40 tahun dari basis data dengan sistem otonom dan non-otonom, kita dapat menyimpulkan bahwa pekerjaan ini masih belum cukup.
Mengapa hari ini kita tidak dapat memiliki sistem pemerintahan sendiri yang benar-benar otonom? Ada tiga alasan untuk ini.

Pertama, semua alat ini, kecuali untuk distribusi beban kerja dari penyedia layanan cloud, hanya bersifat
saran . Yaitu, berdasarkan opsi yang dihitung, seseorang harus membuat keputusan akhir yang subyektif, apakah proposal seperti itu benar. Selain itu, perlu untuk mengamati operasi sistem untuk beberapa waktu untuk memutuskan apakah keputusan yang dibuat tetap benar ketika layanan berkembang. Dan kemudian terapkan pengetahuan itu pada model pengambilan keputusan internal Anda sendiri di masa depan. Ini bisa dilakukan untuk satu database, tetapi tidak untuk puluhan ribu.
Masalah selanjutnya adalah bahwa
tindakan apa pun hanyalah reaksi terhadap sesuatu . Dalam semua contoh yang kami periksa, pekerjaan dilakukan dengan data tentang beban kerja sebelumnya. Ada masalah, catatan tentang itu ditransfer ke instrumen, dan dia berkata: "Ya, saya tahu bagaimana menyelesaikan masalah ini." Tetapi solusinya hanya menyangkut masalah yang sudah terjadi. Alat ini tidak memprediksi peristiwa masa depan dan karenanya tidak menawarkan tindakan persiapan. Seseorang dapat melakukan ini, dan melakukannya secara manual, tetapi alat tidak bisa.
Alasan terakhir adalah bahwa tidak ada solusi yang
ada transfer pengetahuan . Inilah yang saya maksud: misalnya, mari kita ambil alat yang berfungsi dalam satu aplikasi pada instance database pertama, jika Anda meletakkannya di aplikasi lain yang sama pada instance database lain, itu bisa, berdasarkan pengetahuan yang diperoleh saat bekerja dengan database pertama data membantu mengatur basis data kedua. Bahkan, semua alat mulai bekerja dari awal, mereka perlu mendapatkan kembali semua data tentang apa yang terjadi. Manusia bekerja dengan cara yang sangat berbeda. Jika saya tahu cara mengkonfigurasi satu aplikasi dengan cara tertentu, saya dapat melihat pola yang sama di aplikasi lain dan, mungkin, mengkonfigurasinya jauh lebih cepat. Tetapi tidak satu pun dari algoritma ini, tidak satu pun dari alat ini yang masih bekerja dengan cara ini.
Mengapa saya yakin ini saatnya untuk berubah? Jawaban untuk pertanyaan ini hampir sama dengan pertanyaan mengapa super-array data atau pembelajaran mesin menjadi populer.
Peralatan menjadi kualitas yang lebih baik : sumber daya produksi meningkat, kapasitas penyimpanan tumbuh, kapasitas perangkat keras meningkat, yang mempercepat perhitungan untuk model pembelajaran mesin pembelajaran.
Alat perangkat lunak canggih telah tersedia bagi kami. Sebelumnya, Anda harus menjadi ahli dalam MATLAB atau aljabar linier tingkat rendah untuk menulis beberapa algoritma pembelajaran mesin. Sekarang kami memiliki Torch dan Tenso Flow, yang membuat ML tersedia, dan, tentu saja, kami telah belajar untuk lebih memahami data. Orang tahu jenis data apa yang mungkin diperlukan untuk pengambilan keputusan di masa depan, oleh karena itu mereka tidak membuang data sebanyak sebelumnya.
Tujuan dari penelitian kami adalah untuk menutup lingkaran ini dalam DBMS otonom. Kita dapat, seperti alat-alat sebelumnya, mengusulkan solusi, tetapi alih-alih mengandalkan orang tersebut - apakah solusinya tepat ketika Anda perlu menggunakannya secara spesifik - algoritma akan melakukan ini secara otomatis. Dan kemudian dengan bantuan umpan balik, ia akan belajar dan menjadi lebih baik seiring waktu.
Saya ingin berbicara tentang proyek yang saat ini kami kerjakan di Universitas Carnegie Mellon. Di dalamnya, kami mendekati masalah dengan dua cara berbeda.
Dalam yang pertama - OtterTune - kami mencari cara untuk menyempurnakan database, memperlakukannya sebagai kotak hitam. Yaitu, cara untuk
menyempurnakan DBMS yang ada tanpa mengendalikan bagian internal sistem dan hanya mengamati responsnya.
Proyek Peloton adalah tentang
menciptakan database baru dari awal , dari awal, mengingat fakta bahwa sistem harus bekerja secara mandiri. Penyesuaian dan algoritme optimasi apa yang perlu ditetapkan - yang tidak dapat diterapkan pada sistem yang ada.
Mari kita pertimbangkan kedua proyek secara berurutan.
Ottertune
Proyek penyesuaian sistem yang ada yang telah kami kembangkan disebut OtterTune.
Bayangkan bahwa basis data dikonfigurasikan sebagai sebuah layanan. Idenya adalah Anda mengunduh metrik runtime dari operasi basis data berat yang menghabiskan semua sumber daya, dan konfigurasi regulator yang direkomendasikan datang sebagai tanggapan, yang, menurut pendapat kami, akan meningkatkan produktivitas. Ini dapat berupa waktu tunda, bandwidth, atau karakteristik lain apa pun yang Anda tentukan - kami akan mencoba menemukan opsi terbaik.

Hal utama yang baru dalam proyek OtterTune adalah
kemampuan untuk menggunakan data dari sesi tuning
sebelumnya dan meningkatkan efisiensi sesi berikutnya. Sebagai contoh, ambil konfigurasi PostgreSQL, yang memiliki aplikasi yang belum pernah kita lihat sebelumnya. Tetapi jika memiliki karakteristik tertentu atau menggunakan database dengan cara yang sama seperti database yang telah kita lihat di aplikasi kita, maka kita sudah tahu cara mengkonfigurasi aplikasi ini lebih efisien.
Pada level yang lebih tinggi, algoritma pekerjaan adalah sebagai berikut.
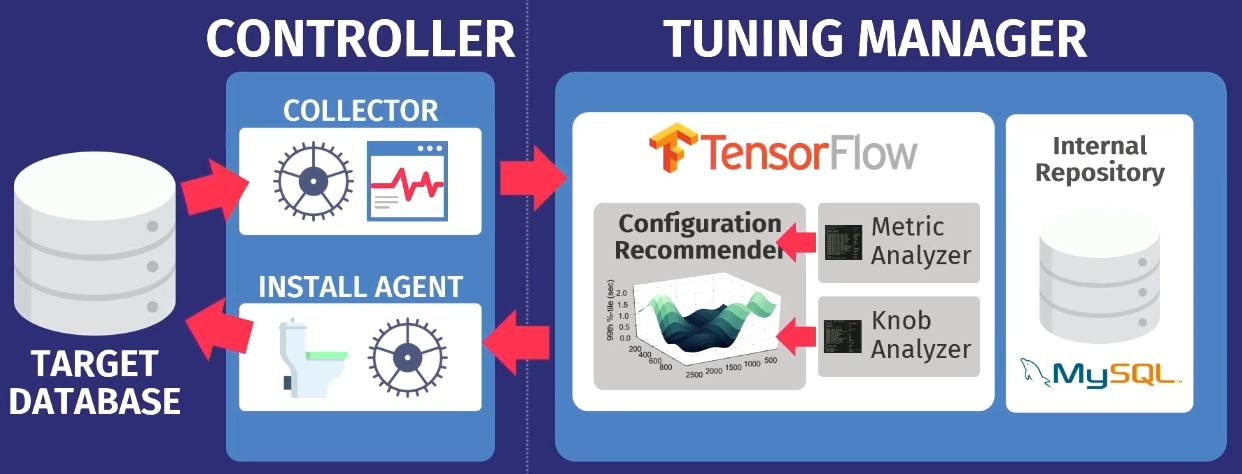
Katakanlah ada database target: PostgreSQL, MySQL, atau VectorWise. Anda harus menginstal controller di domain yang sama, yang akan melakukan dua tugas.
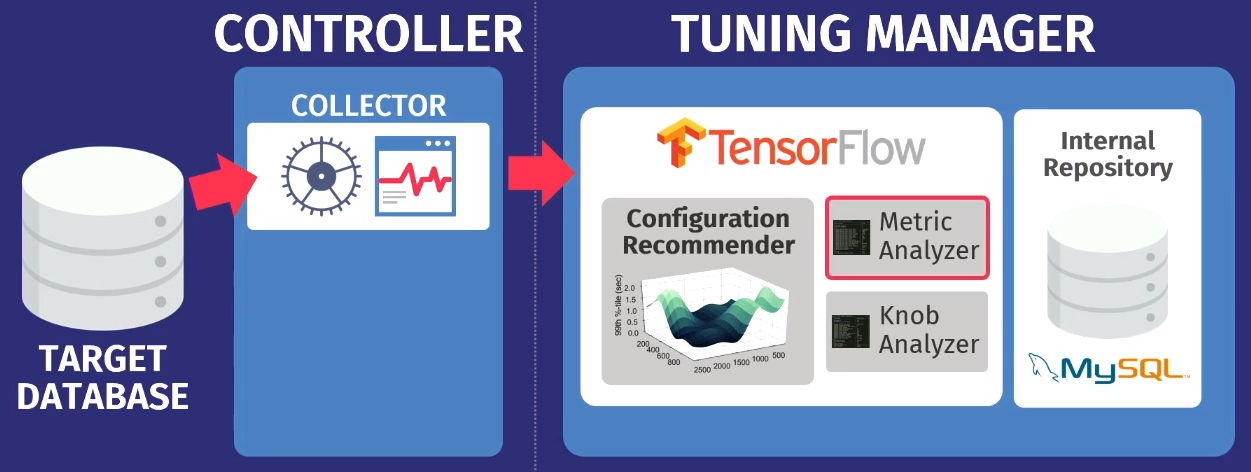
Yang pertama dilakukan oleh apa yang disebut collector - alat yang mengumpulkan data tentang konfigurasi saat ini, mis. metrik waktu eksekusi permintaan dari aplikasi ke database. Data yang dikumpulkan oleh kolektor dimuat ke Tuning Manager, layanan tuning. Tidak masalah jika database berfungsi secara lokal atau di cloud. Setelah mengunduh, data disimpan dalam repositori internal kami sendiri, yang menyimpan semua sesi pengaturan pengujian yang pernah dibuat.
Sebelum memberikan rekomendasi, Anda perlu melakukan dua langkah. Pertama, Anda perlu melihat metrik runtime dan mencari tahu mana yang sebenarnya penting. Contoh berikut menunjukkan metrik yang dikembalikan oleh MySQL tetapi
SHOW_GLOBAL_STATUS pada InnoDB. Tidak semuanya berguna untuk analisis kami. Diketahui bahwa dalam pembelajaran mesin sejumlah besar data tidak selalu baik. Karena dengan itu diperlukan lebih banyak data untuk memisahkan gandum dari sekam. Seperti dalam kasus ini,
penting untuk menyingkirkan entitas yang tidak terlalu penting .
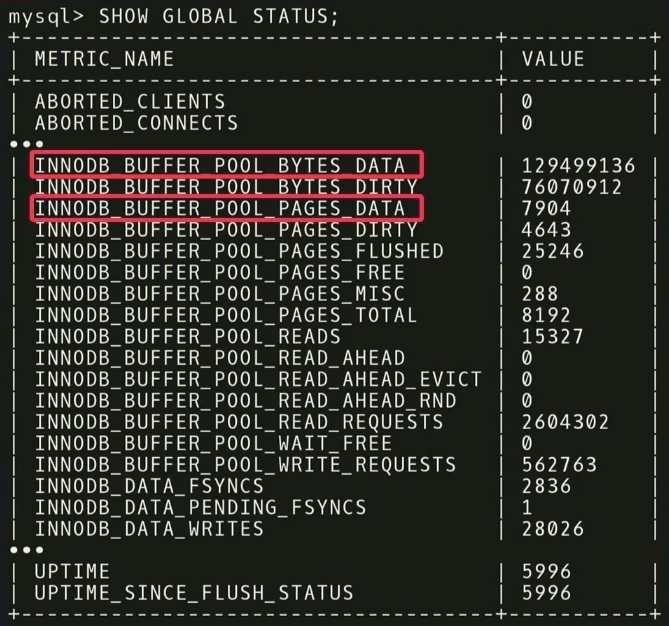
Misalnya, ada dua metrik:
INNODB_BUFFER_POOL_BYTES_DATA dan
INNODB_BUFFER_POOL_PAGES_DATA . Sebenarnya, ini adalah metrik yang sama, tetapi dalam unit yang berbeda. Anda dapat melakukan analisis statistik, melihat bahwa metrik sangat berkorelasi, dan menyimpulkan bahwa menggunakan keduanya berlebihan untuk analisis. Jika Anda membuang salah satunya, dimensi tugas belajar akan berkurang dan waktu untuk menerima jawaban akan berkurang.
Pada tahap kedua, kami melakukan hal yang sama, hanya berkaitan dengan regulator.
Ada 500 regulator di MySQL , dan, tentu saja, tidak semuanya benar-benar signifikan, tetapi aplikasi yang berbeda penting untuk aplikasi yang berbeda. Penting untuk melakukan analisis statistik lain untuk mengetahui regulator mana yang benar-benar memengaruhi fungsi target.
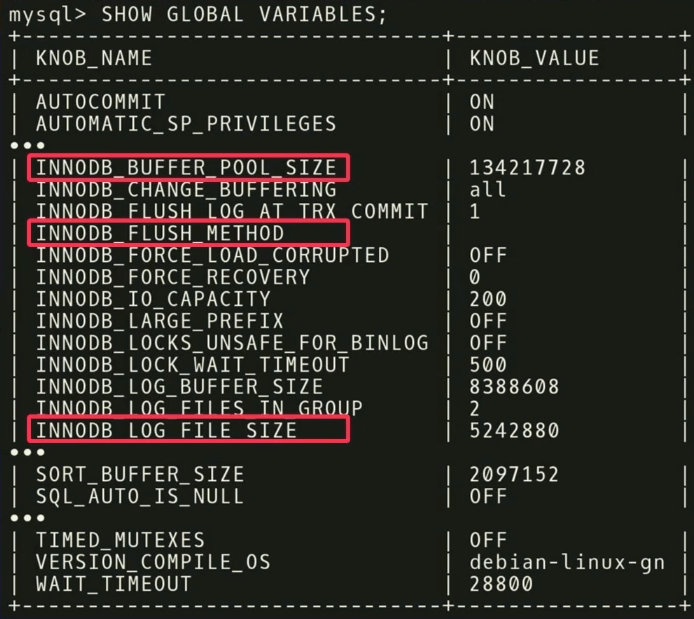
Dalam contoh kami, kami menemukan bahwa ketiga
INNODB_BUFFER_POOL_SIZE ,
FLUSH_METHOD dan
LOG_FILE_SIZE memiliki dampak terbesar pada kinerja. Mereka mengurangi waktu tunda untuk beban kerja transaksional.
Ada poin menarik lain terkait dengan regulator. Di tangkapan layar ada regulator bernama
TIMED_MUTEXES . Jika Anda merujuk pada dokumentasi kerja MySQL, pada bagian 45.7 itu akan diindikasikan bahwa regulator ini kedaluwarsa. Tetapi
algoritma pembelajaran mesin tidak dapat membaca dokumentasi , sehingga tidak mengetahuinya. Dia tahu bahwa ada regulator yang bisa dinyalakan atau dimatikan, dan akan butuh waktu lama untuk memahami bahwa ini tidak mempengaruhi apa pun. Tetapi Anda dapat membuat perhitungan di muka dan mengetahui bahwa regulator tidak melakukan apa-apa, dan jangan buang waktu untuk mengaturnya.
Setelah analisis, data ditransfer ke algoritma konfigurasi kami menggunakan
model proses Gaussian - metode yang agak lama. Anda mungkin pernah mendengar pembelajaran yang mendalam, kami melakukan hal yang serupa, tetapi tanpa jaringan yang dalam. Kami menggunakan
GPflow , paket untuk bekerja dengan model proses Gaussian yang dikembangkan di Rusia berdasarkan TensorFlow. Algoritme mengeluarkan rekomendasi yang harus meningkatkan fungsi objektif; data ini ditransfer kembali ke agen instalasi yang bekerja di dalam pengontrol. Agen menerapkan perubahan dengan melakukan reset - sayangnya, itu harus me-restart database - dan kemudian proses berulang kembali. Beberapa metrik runtime lebih banyak dikumpulkan, ditransfer ke algoritma, analisis kemungkinan peningkatan dan peningkatan produktivitas dilakukan, rekomendasi dikeluarkan, dan seterusnya, lagi dan lagi.
Fitur utama dari OtterTune adalah algoritma hanya memerlukan informasi tentang metrik runtime sebagai input. Kami tidak perlu melihat data dan permintaan pengguna Anda. Kami hanya perlu melacak operasi baca dan tulis. Ini adalah argumen yang kuat - data milik Anda atau pelanggan Anda tidak akan diungkapkan kepada pihak ketiga. Kami tidak perlu melihat permintaan apa pun, algoritme hanya berfungsi berdasarkan metrik runtime, karena memberikan rekomendasi untuk regulator, dan bukan untuk desain fisik.
Mari kita lihat demo OtterTune. Di situs web proyek, kami akan menjalankan Postgres 9.6 dan memuat sistem dengan tes TPC-C. Mari kita mulai dengan konfigurasi PostgreSQL awal, yang digunakan ketika diinstal pada Ubuntu.
Pertama, jalankan tes TPC-C selama lima menit, kumpulkan metrik runtime yang diperlukan, unggah ke layanan OtterTune, dapatkan rekomendasi, terapkan perubahannya, lalu ulangi prosesnya. Kami akan kembali ke sini nanti. Sistem database berjalan di satu komputer, layanan Tensor Flow di komputer lain, dan memuat data di sini.
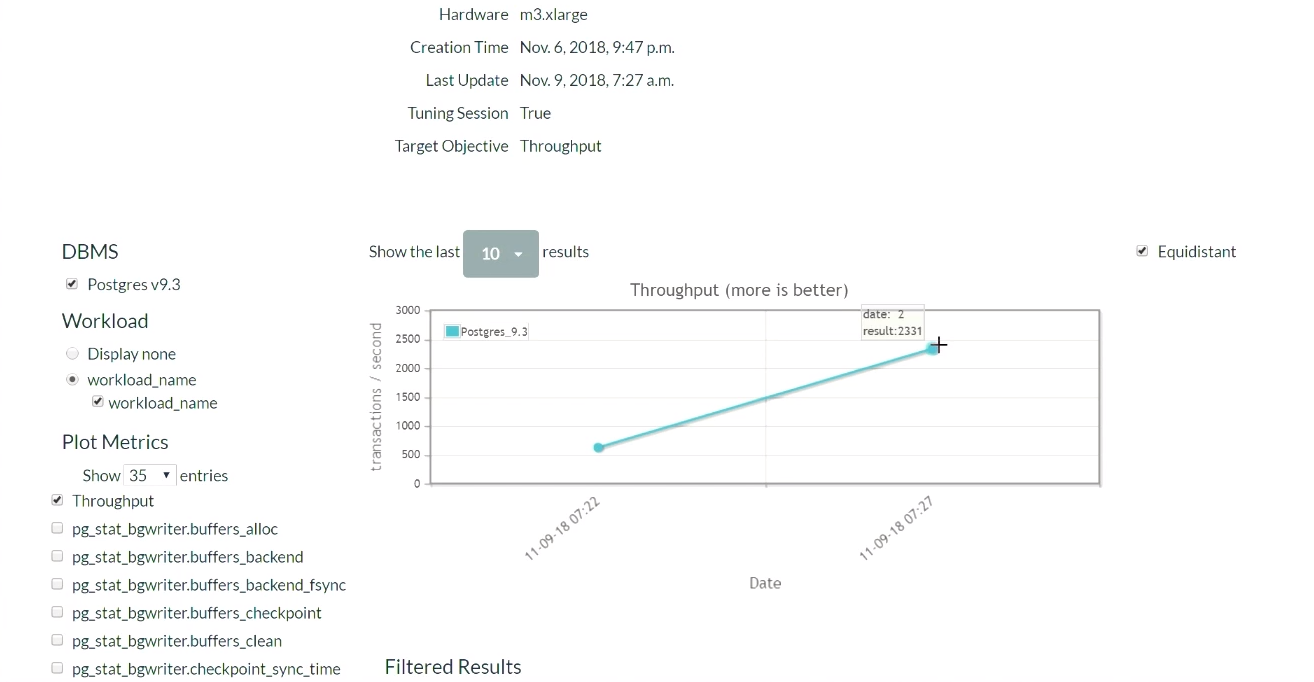
Lima menit kemudian, kami me-refresh halaman (demonstrasi dari bagian hasil ini dimulai saat
ini ). Ketika kami pertama kali mulai, dalam konfigurasi default untuk PostgreSQL, ada 623 transaksi per detik. Kemudian, setelah menerima rekomendasi dan menerapkan perubahan sekali, jumlah transaksi
meningkat menjadi 2300 per detik . Perlu diakui bahwa demonstrasi ini telah diluncurkan beberapa kali, sehingga sistem sudah memiliki satu set data yang dikumpulkan sebelumnya. Itu sebabnya solusinya sangat cepat. Apa yang akan terjadi jika sistem tidak memiliki data yang dikumpulkan sebelumnya? Algoritma ini adalah semacam fungsi langkah-demi-langkah, dan secara bertahap akan mencapai tingkat ini.

Setelah beberapa waktu dan lima iterasi, hasil terbaik adalah 2600. Kami beralih dari 600 transaksi per detik, dan mampu mencapai nilai 2600. Penurunan kecil muncul karena algoritma memutuskan untuk mencoba cara berbeda menyesuaikan regulator setelah mencapai hasil yang baik. Hasilnya adalah margin, jadi penurunan besar dalam kinerja tidak terjadi. Setelah menerima hasil negatif, algoritma dikonfigurasi ulang dan mulai mencari cara regulasi lainnya.
Kami menyimpulkan bahwa Anda tidak perlu takut memulai strategi yang buruk, karena algoritma akan menjelajahi ruang solusi dan mencoba berbagai konfigurasi untuk mencapai kondisi perjanjian SLA. Meskipun Anda selalu dapat mengkonfigurasi layanan sehingga algoritme memilih hanya meningkatkan solusi. Dan seiring waktu, Anda akan menerima semua hasil terbaik dan terbaik.
Sekarang kembali ke topik pembicaraan kita. Saya akan memberi tahu Anda tentang hasil yang ada dari sebuah
artikel yang diterbitkan di Sigmod. Kami mengkonfigurasi MySQL dan PostgreSQL untuk TPC-C menggunakan OtterTune, untuk meningkatkan throughput.
Bandingkan konfigurasi DBMS ini, yang digunakan secara default saat instalasi pertama di Ubuntu. Selanjutnya, jalankan beberapa skrip konfigurasi sumber terbuka yang bisa Anda dapatkan dari Percona dan beberapa perusahaan konsultan lain yang bekerja dengan PostgreSQL. Skrip ini menggunakan prosedur heuristik, seperti aturan bahwa Anda harus menetapkan ukuran buffer tertentu untuk perangkat keras Anda. Kami juga memiliki konfigurasi dari Amazon RDS, yang sudah memiliki preset Amazon untuk peralatan yang sedang Anda kerjakan. Kemudian bandingkan ini dengan hasil secara manual menyiapkan DBA mahal, tetapi dengan ketentuan bahwa mereka memiliki 20 menit dan kemampuan untuk mengatur parameter apa pun yang Anda inginkan. Dan langkah terakhir adalah meluncurkan OtterTune.
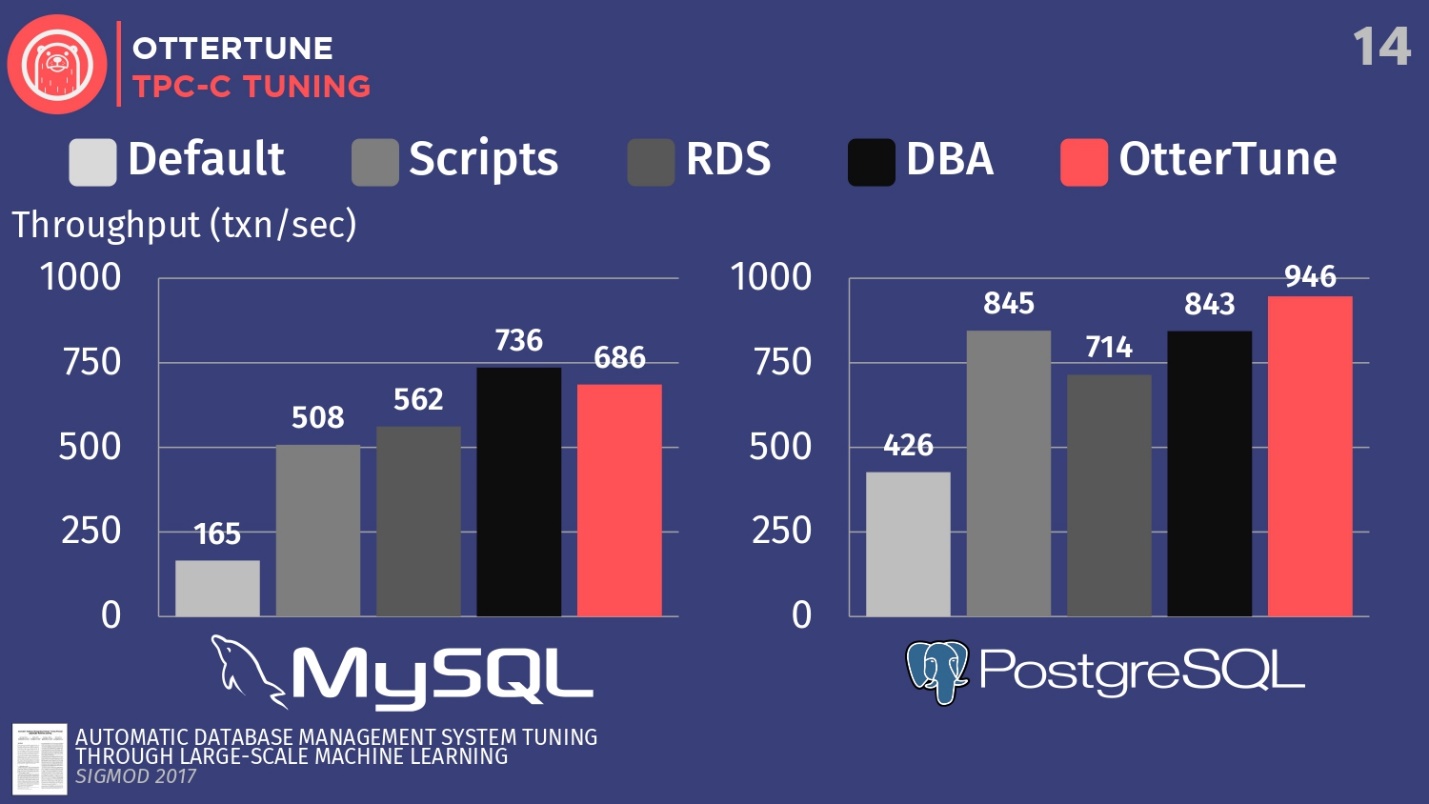
Untuk MySQL, Anda dapat melihat bahwa konfigurasi default jauh di belakang, skrip bekerja sedikit lebih baik, RDS sedikit lebih baik. Dalam hal ini, hasil terbaik ditunjukkan oleh administrator basis data - administrator MySQL terkemuka dari Facebook.
OtterTune hilang dari manusia . Tetapi kenyataannya adalah bahwa ada regulator tertentu yang menonaktifkan sinkronisasi pembersihan log, dan ini tidak penting untuk Facebook. Namun, kami telah menolak akses ke regulator OtterTune ini karena algoritme tidak tahu apakah Anda setuju untuk kehilangan lima milidetik data terakhir. Menurut pendapat kami, keputusan ini harus diambil oleh seseorang. Mungkin Facebook setuju dengan kerugian seperti itu, kita tidak tahu ini. Jika kita menyesuaikan regulator ini dengan cara yang sama, kita dapat bersaing dengan orang tersebut.
Contoh ini menunjukkan bagaimana kita mencoba bersikap konservatif karena keputusan akhir harus diambil oleh orang tersebut. Karena ada aspek-aspek tertentu dari database yang algoritma ML tidak sadari.
Dalam kasus PostgreSQL, skrip konfigurasi berfungsi dengan baik. RDS sedikit lebih buruk. Tetapi, perlu dicatat bahwa indikator OtterTune dalam hal ini melampaui orang tersebut. Histogram menunjukkan hasil yang diperoleh setelah database diatur oleh Wisconsin Senior PostgreSQL Expert Advisor. Dalam contoh ini, OtterTune dapat menemukan keseimbangan optimal antara ukuran file log dan ukuran kumpulan buffer, menyeimbangkan jumlah memori yang digunakan oleh dua komponen ini dan memastikan kinerja terbaik.
Kesimpulan utama adalah bahwa layanan OtterTune menggunakan algoritma dan pembelajaran mesin sedemikian rupa sehingga kami dapat mencapai kinerja yang sama atau lebih baik dibandingkan dengan DBA yang sangat, sangat mahal. Dan ini tidak hanya berlaku untuk satu contoh dari basis data, kita dapat mengatur skala pekerjaan hingga puluhan ribu salinan, karena ini hanya perangkat lunak, hanya data.
Peloton
Proyek kedua yang ingin saya bicarakan disebut Peloton. Ini adalah sistem data yang sama sekali baru yang kami bangun dari awal di Carnegie Mellon. Kami menyebutnya DBMS yang dikelola sendiri.
Idenya adalah untuk mengetahui perubahan apa yang menjadi lebih baik yang dapat dilakukan jika Anda mengontrol seluruh tumpukan perangkat lunak. Cara membuat pengaturan lebih baik daripada yang dapat dilakukan OtterTune, karena pengetahuan tentang setiap fragmen sistem, tentang seluruh siklus program.

Cara kerjanya: kami mengintegrasikan
komponen pembelajaran mesin dengan penguatan ke dalam sistem basis data, dan kami dapat mengamati semua aspek perilakunya pada saat runtime, dan kemudian memberikan rekomendasi. Dan kami tidak terbatas pada rekomendasi untuk menyesuaikan regulator, seperti yang terjadi di layanan OtterTune, kami ingin melakukan seluruh rangkaian tindakan standar yang saya bicarakan sebelumnya: memilih indeks, memilih skema partisi, skala vertikal dan horizontal, dll.
Nama sistem Peloton kemungkinan akan berubah. Saya tidak tahu caranya di Rusia, tetapi di AS, istilah " peloton" berarti "tanpa rasa takut" dan "selesai", dan dalam bahasa Prancis itu berarti "peleton". Namun di AS ada perusahaan sepeda olahraga Peloton yang memiliki banyak uang. Setiap kali disebutkan tentang mereka, misalnya, pembukaan toko baru, atau iklan baru di TV, semua teman saya menulis kepada saya: "Lihat, mereka mencuri ide Anda, mencuri nama Anda." Iklan menunjukkan orang-orang cantik yang mengendarai sepeda olahraga mereka, dan kami tidak bisa bersaing dengan ini. Dan baru-baru ini, Uber mengumumkan perencana sumber daya baru bernama Peloton, sehingga kami tidak lagi dapat menyebutnya sistem kami. Tapi kami belum memiliki nama baru, jadi dalam cerita ini saya masih akan menggunakan versi nama saat ini.Pertimbangkan bagaimana sistem ini bekerja pada level tinggi. Sebagai contoh, ambil database target, saya ulangi, ini adalah perangkat lunak kami, ini yang kami kerjakan. Kami mengumpulkan riwayat beban kerja yang sama dengan yang saya tunjukkan sebelumnya. Perbedaannya adalah bahwa kita akan menghasilkan model peramalan yang memungkinkan kita untuk memprediksi siklus kerja di masa depan, seperti apa persyaratan beban kerja di masa depan. Itu sebabnya kami menyebut sistem ini DBMS yang dikelola sendiri.
Ide dasar DBMS yang dikelola sendiri mirip dengan ide mobil dengan kontrol otomatis.
Sebuah kendaraan tak berawak terlihat di depannya dan dapat melihat apa yang ada di depannya di jalan, dapat memprediksi cara mencapai tujuannya. Sistem database yang berdiri sendiri bekerja dengan cara yang sama. Anda harus dapat melihat ke masa depan dan membuat kesimpulan tentang seperti apa beban kerjanya dalam seminggu atau satu jam. Lalu kami meneruskan data prediksi ini ke komponen perencanaan - kami menyebutnya otak-berjalan di Tensor Flow.
Proses ini menggemakan karya AlphaGo dari London sebagai bagian dari proyek Google Deep Mind, di tingkat atas semuanya bekerja dalam skenario yang sama: Monte Carlo mencari pohon, hasil pencarian adalah berbagai tindakan yang harus dilakukan untuk mencapai tujuan yang diinginkan.
Algoritme berikut kira-kira menentukan skema operasi:
- Data sumber adalah serangkaian tindakan yang diperlukan, misalnya, menghapus indeks, menambahkan indeks, penskalaan vertikal dan horizontal, dan sejenisnya.
- Urutan tindakan dihasilkan, yang pada akhirnya mengarah pada pencapaian fungsi tujuan maksimum.
- Semua kriteria kecuali yang pertama dibuang, dan perubahan diterapkan.
- Sistem melihat efek yang dihasilkan, kemudian proses berulang-ulang.

Jangan terus-menerus menggunakan metafora mobil tak berawak, tetapi itulah cara mereka bekerja. Ini disebut horizon perencanaan.
Setelah melihat cakrawala di jalan, kami menempatkan diri kami pada titik imajiner untuk dicapai, dan kemudian kami mulai merencanakan serangkaian tindakan untuk mencapai titik ini di cakrawala: mempercepat, memperlambat, belok kiri, belok kanan, dll. Kemudian kami secara mental membuang semua tindakan kecuali yang pertama yang perlu dilakukan, lakukan, dan kemudian ulangi proses itu lagi. UAV menjalankan algoritme seperti itu 30 kali per detik. Untuk basis data, proses ini sedikit lebih lambat, tetapi idenya tetap sama.
Kami memutuskan untuk membuat sistem database kami sendiri
dari awal, daripada membangun sesuatu di atas PostgreSQL atau MySQL , karena, jujur saja, mereka terlalu lambat dibandingkan dengan apa yang ingin kami lakukan. PostgreSQL itu indah, saya suka dan menggunakannya di kursus universitas saya, tetapi butuh terlalu banyak waktu untuk membuat indeks, karena semua data berasal dari disk.
Dalam analogi dengan mobil, DBMS otonom pada PostgreSQL dapat dibandingkan dengan gerbong tak berawak. Truk akan dapat mengenali anjing di depan jalan dan mengelilinginya, tetapi tidak jika ia berlari ke jalan langsung di depan mobil. Maka tabrakan tidak bisa dihindari, karena truk tidak cukup bermanuver. Kami memutuskan untuk membuat sistem dari awal agar dapat menerapkan perubahan secepat mungkin dan mencari tahu apa konfigurasi yang benar.
Sekarang kami telah memecahkan masalah pertama dan menerbitkan
sebuah artikel tentang kombinasi pembelajaran yang mendalam dan regresi linier klasik untuk seleksi otomatis dan prediksi beban kerja.
Tetapi ada masalah yang lebih besar, di mana kami belum memiliki solusi yang baik -
katalog tindakan . Pertanyaannya bukan bagaimana memilih tindakan, karena orang-orang dari Microsoft sudah melakukan ini. Pertanyaannya adalah bagaimana menentukan apakah satu tindakan lebih baik daripada yang lain, dalam hal apa yang terjadi sebelum penempatan dan setelah penempatan. Cara membalikkan tindakan jika indeks yang dibuat oleh perintah seseorang tidak optimal, bagaimana Anda dapat membatalkan tindakan ini dan menunjukkan alasan pembatalan. Selain itu, ada sejumlah tugas lain dalam hal interaksi sistem kita sendiri dengan dunia luar, di mana kita belum memiliki solusi, tetapi kita sedang mengusahakannya.
Ngomong-ngomong, saya akan menceritakan kisah yang menghibur tentang perusahaan basis data yang terkenal. Perusahaan ini memiliki alat pemilihan indeks otomatis, dan alat itu punya masalah. Satu klien secara konstan membatalkan semua indeks yang direkomendasikan dan diterapkan oleh alat. Pembatalan ini sering terjadi sehingga alat digantung. Dia tidak tahu apa strategi perilaku selanjutnya, karena solusi apa pun yang ditawarkan kepada seseorang menerima penilaian negatif. Ketika pengembang beralih ke klien dan bertanya: "Mengapa Anda membatalkan semua rekomendasi dan saran pada indeks?", Klien menjawab bahwa ia sama sekali tidak menyukai nama mereka. Orang bodoh, tetapi Anda harus berurusan dengan mereka. Dan untuk masalah ini, saya juga tidak punya solusi.Merancang DBMS yang otonom
Diberikan dua pendekatan berbeda untuk membuat sistem basis data otonom, mari kita bicara sekarang tentang bagaimana merancang DBMS sehingga otonom.
Mari kita bahas tiga topik:
- cara menyesuaikan regulator,
- cara mengumpulkan metrik internal,
- bagaimana merancang aksi.
Sekali lagi, kembali ke poin utama: sistem database harus memberikan informasi yang benar ke algoritma pembelajaran mesin untuk adopsi selanjutnya dari keputusan yang lebih baik. Jumlah data tidak berguna yang kami kirimkan harus dikurangi untuk meningkatkan kecepatan penerimaan tanggapan.
Saya sudah mengatakan bahwa regulator mana pun yang mengharuskan seseorang untuk membuat penilaian penilaian dalam komponen otonom harus ditandai sebagai dilarang. Kita perlu menandai parameter ini di pengaturan PG_SETTINGSatau file konfigurasi lainnya untuk mencegah algoritma mengakses pengontrol ini.Berkenaan dengan parameter seperti jalur file, tingkat isolasi, persyaratan stabilitas transaksi, dll. keputusan harus dibuat oleh manusia, bukan oleh algoritma.
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , .

, , , .
, , open source. , .
, ,
. MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — ., , , Oracle. , .
,
— , , , - .
—
, . , , , 2000- . , Oracle , . , : , — - .
, . , , .
—
. , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .