
Artikel ini lebih teknis daripada tentang bisnis, tetapi kami juga akan menarik beberapa kesimpulan dari sudut pandang bisnis. Sebagian besar perhatian akan diberikan pada perbandingan otomatis barang dari berbagai sumber.
Pekerjaan toko online terdiri dari sejumlah komponen yang cukup besar. Dan apa pun rencananya, untuk mendapatkan untung saat ini, atau untuk tumbuh dan mencari investor, atau, misalnya, untuk mengembangkan bidang terkait, setidaknya Anda harus menutup pertanyaan ini:
- Bekerja dengan pemasok. Untuk menjual sesuatu yang tidak perlu, Anda harus terlebih dahulu membeli sesuatu yang tidak perlu.
- Manajemen Direktori. Seseorang memiliki spesialisasi yang sempit, sementara seseorang menjual ratusan ribu barang yang berbeda.
- Manajemen harga eceran. Di sini Anda harus mempertimbangkan harga pemasok, dan harga pesaing, dan instrumen keuangan yang terjangkau.
- Bekerja dengan gudang. Pada prinsipnya, adalah mungkin untuk tidak memiliki gudang sendiri, tetapi untuk mengambil barang dari gudang mitra, tetapi dengan satu atau lain cara pertanyaannya adalah.
- Pemasaran. Di sini situs diisi dengan konten, penempatan di situs, iklan (online dan offline), promosi, dan banyak lagi.
- Penerimaan dan pemrosesan pesanan. Pusat panggilan, keranjang di situs, pesanan melalui kurir instan, pesanan melalui platform dan pasar.
- Pengiriman
- Akuntansi dan sistem internal lainnya.
Toko, yang akan kita bicarakan, tidak memiliki spesialisasi yang sempit, tetapi menawarkan banyak hal mulai dari kosmetik hingga traktor mini. Saya akan memberi tahu Anda bagaimana kami bekerja dengan pemasok, memantau pesaing, manajemen katalog dan harga (grosir dan eceran), bekerja dengan pelanggan grosir. Sedikit sentuhan pada topik gudang.
Untuk lebih memahami beberapa solusi teknis, tidak akan berlebihan untuk mengetahui hal itu
pada titik tertentu kami memutuskan bahwa hal-hal teknologi, jika mungkin, akan dilakukan bukan untuk diri kita sendiri, tetapi universal. Dan, mungkin, setelah beberapa upaya, akan keluar untuk mengembangkan bisnis baru. Ternyata, secara kondisional, sebuah startup di dalam perusahaan.
Jadi kami mempertimbangkan sistem terpisah, yang kurang lebih bersifat universal, yang dengannya seluruh infrastruktur perusahaan terintegrasi.
Apa masalah bekerja dengan pemasok?
Dan sebenarnya ada banyak dari mereka. Hanya untuk memberi beberapa:
- Ada banyak pemasok per se. Kami punya sekitar 400 orang. Setiap orang perlu waktu.
- Tidak ada cara tunggal untuk mendapatkan penawaran dari pemasok. Seseorang mengirim surat sesuai jadwal, seseorang atas permintaan, seseorang mengunggah ke hosting, seseorang menempatkan di situs. Ada banyak cara, hingga mengirim file melalui skype.
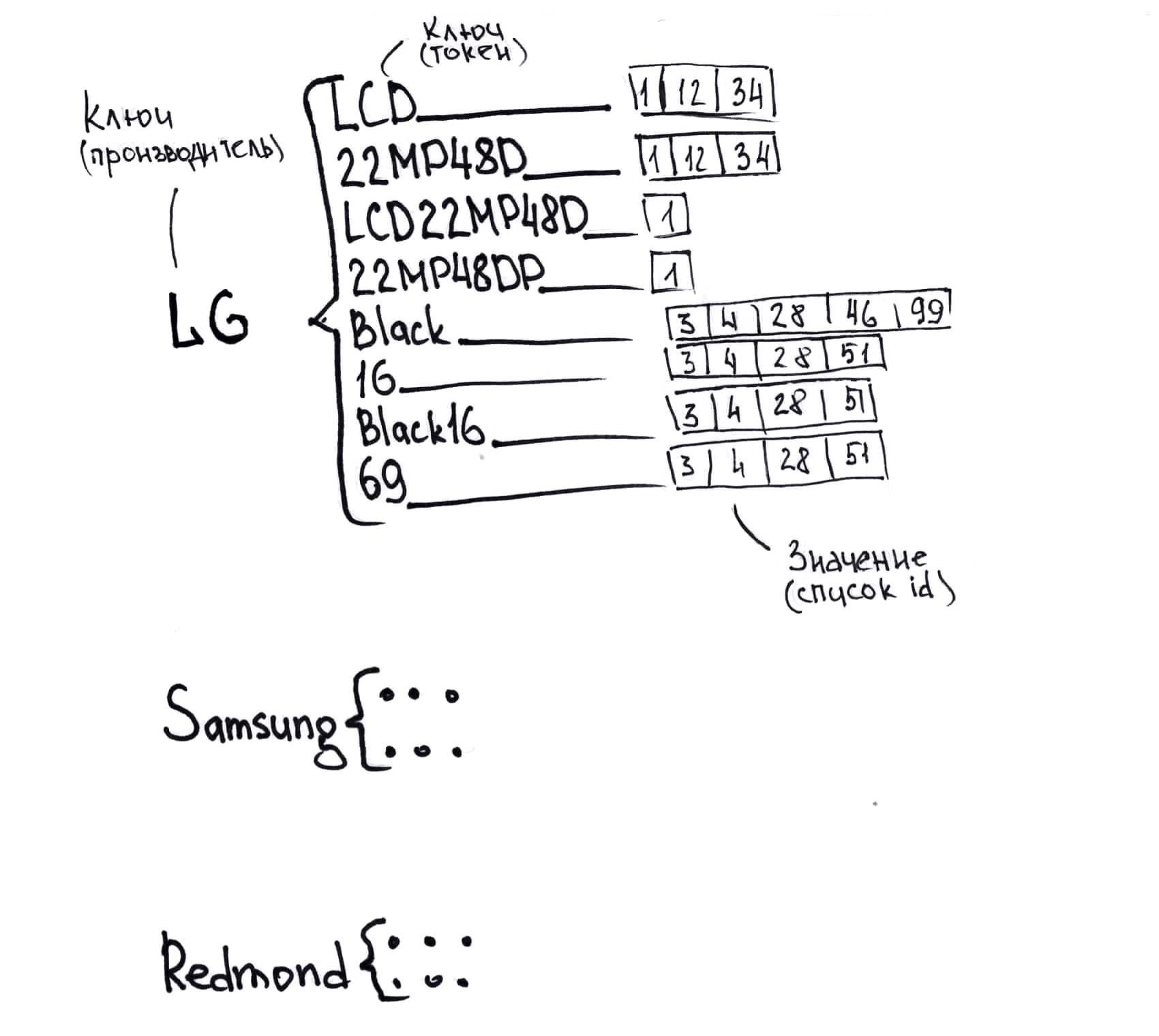
- Tidak ada format data tunggal. Saya bahkan menggambar gambar tentang subjek ini (lebih rendah, tabel melambangkan format yang berbeda).
- Ada konsep minimum eceran dan harga grosir minimum yang harus diperhatikan agar dapat terus bekerja dengan pemasok. Seringkali mereka disediakan dalam format mereka sendiri.
- Nomenklatur masing-masing pemasok berbeda. Akibatnya, produk yang sama disebut secara berbeda, dan tidak ada kunci unik yang dengannya mereka dapat dengan mudah dibandingkan. Karena itu, kami membandingkannya dengan sulit.
- Sistem penempatan pesanan dengan pemasok tidak otomatis. Kami memesan dari seseorang di Skype, dari seseorang di akun Anda, ke seseorang yang kami kirim file exel setiap malam dengan daftar pesanan.

Kami telah belajar untuk mengatasi masalah ini. Selain yang terakhir, bekerja pada yang terakhir sedang berlangsung. Sekarang akan ada detail teknis, dan kemudian pertimbangkan daftar berikut.
Mengumpulkan data
Seperti dulu
File pemasok dikumpulkan secara manual dari berbagai sumber dan disiapkan. Persiapan termasuk penggantian nama sesuai dengan templat tertentu dan konten pengeditan. Tergantung pada file, perlu untuk menghapus barang yang tidak standar, barang yang tidak tersedia, mengganti nama kolom atau mengonversi mata uang, mengumpulkan data dari berbagai tab pada satu.
Bagaimana bisa?
Pertama-tama, kami belajar memeriksa surat dan mengambil surat dengan lampiran dari sana. Kemudian mereka mengotomatiskan pekerjaan dengan tautan langsung dan tautan ke drive Yandex dan Google. Ini menyelesaikan masalah penerimaan penawaran dari sekitar 75% pemasok kami. Kami juga memperhatikan bahwa melalui saluran inilah penawaran lebih sering diperbarui, sehingga persentase otomatisasi sesungguhnya lebih banyak. Kami masih mendapatkan beberapa harga dari kurir.
Kedua, kami tidak lagi memproses file secara manual. Untuk melakukan ini, kami telah memasukkan profil pemasok, di mana Anda dapat menentukan kolom dan tab mana yang akan digunakan, cara menentukan mata uang dan ketersediaan, waktu pengiriman, dan jadwal kerja pemasok.
Ternyata fleksibel. Secara alami, kami tidak mempertimbangkan segalanya untuk pertama kalinya, tetapi sekarang ada cukup fleksibilitas untuk mengonfigurasi pemrosesan 400 penyedia, mengingat setiap orang memiliki format file yang berbeda.
Adapun format file, kami memahami xls, xlsx, csv, xml (yml). Dalam kasus kami, ini sudah cukup.
Mereka juga menemukan cara untuk memfilter catatan. Kami membuat daftar kata-kata berhenti, dan jika penawaran pemasok berisi itu, maka kami tidak memprosesnya. Rincian teknis adalah sebagai berikut: pada daftar kecil Anda dapat dan bahkan lebih baik "langsung", pada daftar besar filter Bloom lebih cepat. Kami bereksperimen dengannya dan meninggalkan semuanya apa adanya, karena untungnya dirasakan dalam daftar urutan besarnya lebih besar dari kita.
Hal penting lainnya adalah jadwal kerja pemasok. Pemasok kami mengerjakan jadwal yang berbeda, di samping itu, mereka berlokasi di berbagai negara, di mana akhir pekan tidak bersamaan. Dan waktu pengiriman biasanya ditunjukkan sebagai angka atau kisaran angka dalam hari kerja. Ketika kita membentuk harga eceran dan grosir, kita harus entah bagaimana mengevaluasi waktu kapan kita dapat mengirimkan barang kepada klien. Untuk melakukan ini, kami membuat kalender yang dapat dikonfigurasi, dan dalam pengaturan masing-masing penyedia Anda dapat menentukan kalender mana yang berfungsi.
Saya harus membuat konfigurasi diskon dan margin tergantung pada kategori dan produsen. Kebetulan pemasok memiliki file umum untuk semua mitra, tetapi ada perjanjian diskon dengan beberapa mitra. Berkat ini, masih mungkin untuk menambah atau mengurangi PPN jika perlu.
Omong-omong, konfigurasi diskon dan aturan mark-up membawa kita ke topik berikutnya. Lagi pula, sebelum menggunakannya Anda perlu mencari tahu apa jenis produk itu.
Bagaimana pemetaan bekerja
Contoh kecil tentang bagaimana produk yang sama dapat dipanggil dari pemasok yang berbeda, untuk memahami apa yang harus Anda kerjakan:
Monitor LG LCD 22MP48D-P
21.5 "LG 22MP48D-P Black (16: 9, 1920x1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Peripheral Komputer - Monitor LG 22MP48D-P
hingga 22 "termasuk Monitor LG LG 22MP48D-P (21.5", hitam, IPS LED 5ms 16: 9 DVI matte 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Monitor LG 22 "LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) Monitor
Monitor LCD Monitor LCD LG 22 "IPS 22MP48D-P LG 22MP48D-P
LG Monitor 21.5 "LG 22MP48D-P gl. Hitam IPS, 1920x1080, 5ms, 250 cd / m2, 1000: 1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
LG Monitor LG 22MP48D-P Hitam 22MP48D-P.ARUZ
Monitor LG 22MP48D-P 22MP48D-P
Monitor LG 22MP48D-P Glossy-Hitam 22MP48D-P
Monitor 21.5 "LG Flatron 22MP48D-P gl.Hitam (IPS, 1920x1080, 16: 9, 178/178, 250cd / m2, 1000: 1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Monitor 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5 "22MP48D-P IPS LED, 1920x1080, 5ms, 250cd / m2, 5Mln: 1, 178 ° / 178 °, D-Sub, DVI, Miring, VESA, Hitam Mengkilap 22MP48D-P
LG 21.5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Monitor 21,5`` LG 22MP48D-P Black
LG MONITOR 21.5 "LG 22MP48D-P Glossy-Hitam (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) 22MP48D-P
Monitor LCD LG 21,5 '' [16: 9] 1920x1080 (FHD) IPS, nonGLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16,7M Warna, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D -P
LCD LG 21.5 "22MP48D-P hitam {IPS LED 1920x1080 5ms 16: 9 250cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22 "LCD 22MP48D 22MP48D-P
21.5 "16x9 LG Monitor LG 21.5" 22MP48D-P hitam IPS LED 5ms 16: 9 DVI matte 250cd 1920x1080 D-Sub FHD 2.7kg 22MP48D-P.ARUZ
Monitor 21,5 "LG 22MP48D-P [Hitam]; 5ms; 1920x1080, DVI, IPS
Seperti dulu
Perbandingan melibatkan 1C (modul bayaran pihak ketiga). Sedangkan untuk kenyamanan / kecepatan / ketepatan, sistem seperti itu memungkinkan untuk memelihara katalog dengan 60 ribu produk yang tersedia di level ini oleh 6 orang. Artinya, setiap hari, ketinggalan zaman dan menghilang dari penawaran pemasok, sebanyak mungkin barang yang cocok dengan yang baru dibuat. Sangat kira-kira - 0,5% dari ukuran katalog, mis. 300 produk.
Bagaimana itu menjadi: gambaran umum dari pendekatan tersebut
Sedikit lebih tinggi, saya memberi contoh tentang apa yang harus kita cocokkan. Menjelajahi topik pencocokan, saya sedikit terkejut bahwa ElasticSearch populer untuk tugas pencocokan, menurut pendapat saya, itu memiliki batasan konseptual. Adapun tumpukan teknologi kami, kami menggunakan MS SQL Server untuk penyimpanan data, tetapi perbandingannya bekerja pada infrastruktur kami sendiri, dan karena ada banyak data dan kami perlu memprosesnya dengan cepat, kami menggunakan struktur data yang dioptimalkan untuk tugas tertentu dan mencoba untuk tidak mengakses disk atau basis data tanpa perlu. dan sistem lambat lainnya.
Jelas, masalah perbandingan dapat dipecahkan dengan banyak cara, dan jelas, tidak ada dari mereka yang akan memberikan akurasi absolut. Oleh karena itu, ide utamanya adalah mencoba menggabungkan metode-metode ini, memberi peringkat berdasarkan akurasi dan kecepatan dan menerapkannya dalam urutan akurasi yang menurun, dengan mempertimbangkan kecepatan akun.
Rencana eksekusi untuk setiap algoritme kami (dengan reservasi tentang kasus degenerasi) dapat secara singkat diwakili oleh urutan umum berikut:
Tokenisasi Kami memecah baris sumber menjadi bagian independen yang bermakna. Ini dapat dilakukan sekali dan selanjutnya digunakan dalam semua algoritma.
Normalisasi token. Dalam cara yang baik, Anda perlu membawa kata-kata bahasa alami ke angka umum dan kemerosotan, dan pengidentifikasi seperti "ABC15MX" (ini adalah Cyrillic, jika itu) harus dikonversi ke bahasa Latin. Dan membawa semuanya ke register yang sama.
Kategorisasi token. Mencoba memahami arti setiap bagian. Misalnya, Anda dapat memilih kategori, pabrikan, warna, dan sebagainya.
Cari kandidat terbaik untuk sebuah pertandingan.
Perkiraan kemungkinan garis asli dan kandidat terbaik menunjukkan produk yang sama.
Dua poin pertama adalah umum untuk semua algoritma yang saat ini tersedia, dan kemudian improvisasi dimulai.
Tokenisasi Di sini kami melakukan hal itu, kami memecah garis menjadi beberapa bagian sesuai dengan karakter khusus seperti spasi, garis miring, dan sebagainya. Set karakter dari waktu ke waktu ternyata signifikan, tetapi kami tidak menggunakan sesuatu yang rumit dalam algoritma itu sendiri.
Maka kita perlu menormalkan token. Konversikan menjadi huruf kecil. Alih-alih mengarahkan semuanya ke kasus nominatif, kami hanya memotong ujungnya. Kami juga memiliki kamus kecil, dan kami menerjemahkan token kami ke dalam bahasa Inggris. Antara lain, terjemahan menyelamatkan kita dari sinonim, serupa artinya kata-kata Rusia diterjemahkan ke dalam bahasa Inggris dengan cara yang sama. Di mana kami gagal menerjemahkan, kami mengubah karakter Cyrillic seperti ejaan ke alfabet Latin. (Ternyata sama sekali tidak berlebihan, ternyata. Bahkan di mana Anda tidak mengharapkan trik kotor, misalnya, di baris "Samsung UE43NU7100U" Cyrillic E mungkin terjadi).

Kategorisasi token. Kita dapat menyoroti kategori, pabrikan, model, artikel, EAN, warna. Kami memiliki direktori tempat data disusun. Kami memiliki data tentang pesaing yang disediakan platform perdagangan kepada kami. Saat memprosesnya, jika memungkinkan, kami menyusun data. Kita dapat memperbaiki kesalahan atau kesalahan ketik, misalnya, pabrikan atau warna, yang terjadi hanya sekali di semua sumber kami, tidak untuk masing-masing mempertimbangkan pabrikan dan warna. Akibatnya, kami memiliki kamus besar kemungkinan produsen, model, artikel, warna, dan kategorisasi token hanyalah pencarian kamus untuk O (1). Secara teoritis, Anda dapat memiliki daftar kategori terbuka dan beberapa jenis algoritma klasifikasi pintar, tetapi pendekatan dasar kami berfungsi dengan baik, dan kategorisasi bukanlah hambatan.
Perlu dicatat bahwa kadang-kadang pemasok menyediakan data yang sudah terstruktur, misalnya, artikel berada di sel yang terpisah dalam tabel, atau pemasok membuat diskon pada ritel pada penjualan grosir, dan harga eceran dapat diperoleh dalam format yml (xml). Kemudian kami menyimpan struktur data, dan secara heuristik membagi token ke dalam kategori hanya dari data yang tidak terstruktur.
Dan sekarang tentang algoritma apa dan dalam urutan apa kita gunakan.
Pencocokan tepat dan hampir persis
Kasus paling sederhana. Garis-garis dibagi menjadi token, mereka membawanya ke satu bentuk. Kemudian mereka datang dengan fungsi hash yang tidak sensitif terhadap urutan token. Selain itu, dengan mencocokkan dengan hash, kita dapat menyimpan semua data dalam memori, kita dapat membeli 16 megabyte bersyarat per kamus dengan sejuta tombol. Dalam praktiknya, algoritma ini bekerja lebih baik daripada perbandingan string sederhana.
Adapun hashing, penggunaan "eksklusif atau" menunjukkan dirinya, dan fungsi seperti ini:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
Hal yang paling menarik pada tahap ini adalah mendapatkan hash dari satu baris. Dalam prakteknya, ternyata 32 bit kecil, banyak tabrakan yang didapat. Dan juga - bahwa Anda tidak bisa hanya mengambil kode sumber fungsi dari kerangka kerja dan mengubah jenis nilai kembali, ada lebih sedikit tabrakan untuk setiap baris, tetapi setelah "eksklusif atau" mereka masih terjadi, jadi kami menulis sendiri. Bahkan, mereka hanya menambahkan fungsi dari kerangka nonlinier dari data input. Itu jelas lebih baik, dengan fungsi baru dengan tabrakan, kami hanya bertemu sekali dalam jutaan rekaman kami, direkam dan ditunda hingga waktu yang lebih baik.
Dengan demikian, kami mencari pasangan tanpa memperhitungkan urutan kata dan bentuknya. Pencarian seperti itu berfungsi untuk O (1).
Sayangnya, jarang, tetapi itu juga terjadi: "ABC 42 Type 16" dan "ABC 16 Type 42", dan ini adalah dua produk yang berbeda. Kami juga belajar menangani hal-hal seperti itu, tetapi lebih banyak tentang itu nanti.
Mencocokkan Produk yang Dikonfirmasi Manusia
Kami memiliki produk yang dicocokkan secara manual (paling sering ini adalah produk yang dicocokkan secara otomatis, tetapi yang telah diperiksa secara manual). Faktanya, kami melakukan hal yang sama dalam kasus ini, hanya sekarang kami telah menambahkan kamus hash yang cocok, pencarian yang tidak mengubah kompleksitas waktu dari algoritma.
Baris yang cocok secara manual terletak pada basis data, untuk berjaga-jaga, data mentah tersebut akan memungkinkan Anda untuk mengubah algoritma hashing di masa mendatang, menghitung ulang semuanya dan tidak kehilangan apa pun.
Pemetaan Atribut
Dua algoritma pertama cepat dan akurat, tetapi tidak cukup. Selanjutnya kita menerapkan pencocokan atribut.
Sebelumnya, kami sudah mempresentasikan data dalam bentuk token yang dinormalisasi dan bahkan mengurutkannya ke dalam kategori. Dalam bab ini, saya memanggil atribut kategori token.
Atribut yang paling dapat diandalkan adalah EAN (https://ru.wikipedia.org/wiki/European_Article_Number). Pertandingan EAN memberi Anda jaminan hampir 100% bahwa mereka adalah produk yang sama. Namun, ketidaksesuaian EAN tidak mengatakan apa-apa, karena satu produk mungkin memiliki EAN yang berbeda. Semuanya akan baik-baik saja, tetapi dalam data kami EAN jarang terjadi, oleh karena itu pengaruhnya terhadap perbandingan pada tingkat kesalahan.
Artikel itu kurang bisa diandalkan. Sesuatu yang aneh sering didapat langsung dari data terstruktur pemasok, tetapi dalam kasus apa pun pada tahap ini kami menggunakannya.
Seperti pada tahap terakhir, di sini kita menggunakan kamus (mencari O (1)), dan hash dari (produsen + model + artikel) digunakan sebagai kunci. Hashing memungkinkan Anda untuk melakukan semua operasi dalam memori. Dalam hal ini, kami juga memperhitungkan warna, jika cocok atau tidak ada, maka kami percaya bahwa barang tersebut bertepatan.
Cari yang paling cocok
Langkah-langkah sebelumnya sederhana, cepat, dan cukup dapat diandalkan, tetapi sayangnya mereka mencakup kurang dari setengah perbandingan.
Dalam mencari yang paling cocok, ada ide sederhana: kebetulan token langka memiliki bobot besar, kebetulan token sering kecil. Token yang berisi angka dinilai lebih dari token surat. Token yang cocok dengan urutan yang sama dihargai lebih dari token yang disusun ulang. Pertandingan panjang lebih baik daripada pertandingan pendek.
Sekarang tetap dengan struktur data cepat yang dapat mengambil semua ini pada saat yang sama dan sesuai dengan memori direktori beberapa juta catatan.
Kami datang dengan ide menghadirkan katalog kami dalam bentuk kamus kamus, pada tingkat pertama, kuncinya adalah hash dari pabrikan (data dalam katalog terstruktur, kami tahu pabrikan), nilainya adalah kamus. Sekarang level kedua. Kunci di tingkat kedua adalah hash dari token, nilainya adalah daftar item id dari katalog tempat token ini ditemukan. Dan dalam hal ini, kami menggunakan termasuk token kombinasi dalam urutan di mana mereka muncul dalam katalog kami. Kami memutuskan apa yang akan digunakan sebagai kombinasi, dan apa yang tidak, tergantung pada jumlah token, panjangnya dan sebagainya, ini adalah kompromi antara kecepatan, akurasi dan memori yang diperlukan. Dalam gambar, saya menyederhanakan struktur ini, tanpa hash dan tanpa normalisasi.
Jika rata-rata 20 token digunakan untuk setiap produk, maka dalam daftar kami, yang memiliki nilai kamus terlampir, tautan ke produk akan terjadi rata-rata 20 kali. Tidak akan ada lebih dari 20 kali token yang berbeda dari yang ada dalam katalog. Kira-kira, Anda dapat menghitung memori yang diperlukan untuk katalog sejuta catatan: 20 juta kunci, masing-masing 4 byte, masing-masing 20 juta id produk, masing-masing byte di atas kepala, untuk mengatur kamus dan daftar (urutannya sama, tetapi karena ukuran daftar dan kamus kami tidak tahu sebelumnya, tetapi meningkat saat bepergian, kalikan dua). Total - 480 megabita. Pada kenyataannya, ternyata sedikit lebih banyak token untuk barang, dan kami membutuhkan hingga 800 megabyte per katalog dalam sejuta barang. Apa yang bisa diterima, kemampuan besi modern memungkinkan Anda untuk secara bersamaan menyimpan dalam memori lebih dari seratus direktori ukuran ini.
Kembali ke algoritme. Memiliki string yang harus dicocokkan, kita dapat menentukan pabrikan (kami memiliki algoritme kategorisasi), dan kemudian mendapatkan token menggunakan algoritme yang sama dengan barang dari katalog. Maksud saya, termasuk kombinasi token.
Maka semuanya relatif sederhana. Untuk setiap token, kami dapat dengan cepat menemukan semua produk yang ada di dalamnya, memperkirakan berat setiap pertandingan, memperhitungkan semua yang kami bicarakan sebelumnya - panjang, frekuensi, keberadaan angka atau karakter khusus, dan mengevaluasi "kesamaan" dari semua kandidat yang ditemukan. Pada kenyataannya, ada juga optimasi di sini, kami tidak mempertimbangkan semua kandidat, pertama kami membuat daftar kecil kecocokan token dengan bobot besar, dan kami tidak menerapkan kecocokan token dengan bobot rendah untuk semua produk, tetapi hanya pada daftar ini.
Kami memilih yang paling cocok, melihat kebetulan dari token yang ternyata dikategorikan dan mempertimbangkan skor perbandingan. Selanjutnya, kami memiliki dua nilai ambang P1 dan P2, P1 <P2. Jika penilaian ternyata lebih dari nilai ambang P2 - partisipasi manusia tidak diperlukan, semuanya terjadi secara otomatis. Jika antara dua nilai - kami menawarkan untuk melihat perbandingan secara manual, sebelum itu ia tidak akan berpartisipasi dalam penentuan harga. Jika kurang dari P1 - kemungkinan besar, produk seperti itu tidak ada dalam katalog, kami tidak mengembalikan apa pun.
Kembali ke baris "ABC 42 Type 16" dan "ABC 16 Type 42". Solusinya sangat sederhana - jika beberapa produk memiliki hash yang sama, maka kami tidak mencocokkannya dengan hash. Dan algoritma terakhir akan memperhitungkan urutan token. Secara teoritis, garis-garis seperti itu dalam daftar harga pemasok tidak dapat dicocokkan dengan apa pun yang sewenang-wenang, di mana angka 16 dan 42 tidak muncul sama sekali. Faktanya, kami tidak menemukan kebutuhan seperti itu.
Kecepatan dan ketepatan
Sekarang untuk kecepatan semuanya. Waktu yang diperlukan untuk menyiapkan kamus secara linear tergantung pada ukuran katalog. Waktu yang diperlukan secara langsung untuk perbandingan, secara linier tergantung pada jumlah barang yang dibandingkan. Semua struktur data yang terlibat dalam pencarian tidak berubah setelah pembuatan. Ini memberi kami kesempatan untuk menggunakan multithreading pada tahap pencocokan. Pekerjaan persiapan untuk katalog sejuta catatan membutuhkan waktu sekitar 40-80 detik. Perbandingannya bekerja pada kecepatan 20-40 ribu catatan per detik dan tidak tergantung pada ukuran direktori. Namun, Anda harus menyimpan hasilnya. Pendekatan yang dipilih umumnya bermanfaat untuk volume besar, tetapi file dengan selusin catatan akan panjang tidak proporsional. Karena itu, kami menggunakan cache dan menceritakan kembali struktur pencarian kami setiap 15 menit sekali.
Benar, data untuk perbandingan perlu dibaca di suatu tempat (paling sering ini adalah file excel), dan kalimat yang cocok perlu disimpan di suatu tempat, dan ini juga membutuhkan waktu. Jadi jumlah totalnya adalah 2-4 ribu catatan per detik.
Untuk mengevaluasi akurasi, kami menyiapkan serangkaian uji sekitar 20.000 perbandingan yang diverifikasi secara manual dari berbagai pemasok dari berbagai kategori. Setelah setiap perubahan, algoritma diuji pada data ini. Hasilnya adalah sebagai berikut:
- barang ada di katalog dan dibandingkan dengan benar - 84%
- produk ada di katalog, tetapi belum cocok, pencocokan manual diperlukan - 16%
- barang ada di katalog dan dibandingkan secara tidak benar - 0,2%
- produk tidak ada dalam katalog, dan program mengidentifikasinya dengan benar - 98.5%
- produk tidak ada dalam katalog, tetapi program mencocokkannya dengan salah satu produk - 1,5%
Dalam 80% kasus ketika produk tersebut cocok, konfirmasi manual tidak diperlukan (kami secara otomatis mengkonfirmasi perbandingan), di antara penawaran yang dikonfirmasi secara otomatis tersebut adalah 0,1% kesalahan.
Omong-omong, 0,1% kesalahan banyak, ternyata. Untuk sejuta catatan yang cocok, ini adalah seribu catatan yang cocok secara salah. Dan ini banyak karena pembeli menemukan catatan seperti itu terbaik. Nah, bagaimana tidak memesan traktor untuk harga lampu depan dari traktor ini. Namun, ribuan kesalahan ini pada awal pengerjaan atas sejuta proposal, secara bertahap diperbaiki. Karantina untuk harga yang mencurigakan, yang menutup masalah ini, muncul kemudian, beberapa bulan pertama kami bekerja tanpa itu.
Ada kategori kesalahan lain yang tidak terkait dengan perbandingan, ini adalah harga yang salah dari pemasok kami. Ini adalah sebagian alasan mengapa kami tidak mempertimbangkan harga sebagai perbandingan. Kami memutuskan bahwa karena kami memiliki informasi tambahan dalam bentuk harga, kami akan menggunakannya untuk mencoba menentukan tidak hanya kesalahan kami sendiri, tetapi juga kesalahan orang lain.
Cari harga yang salah
Ini adalah bagian yang kami coba secara aktif. Versi dasarnya adalah, dan itu tidak memungkinkan Anda untuk menjual ponsel dengan harga sebuah case, tapi saya merasa lebih baik.
Untuk setiap produk kami menemukan batasan harga pemasok yang dapat diterima. Bergantung pada data apa yang tersedia, kami memperhitungkan harga pemasok untuk produk ini, harga pesaing, harga pemasok barang dari produsen ini dalam kategori ini. Harga-harga yang tidak termasuk dalam perbatasan dikarantina dan diabaikan dalam semua algoritme kami. Secara manual, Anda dapat menandai harga yang mencurigakan seperti biasa, maka kami ingat ini untuk produk ini dan menceritakan batas-batas harga yang dapat diterima.
Algoritma langsung untuk menghitung harga maksimum dan minimum yang dapat diterima sekarang terus berubah, kami mencari kompromi antara jumlah positif palsu dan jumlah harga yang salah terdeteksi.
Kami menggunakan nilai median dalam perhitungan (rata-rata memberikan hasil terburuk) dan belum menganalisis formulir distribusi. Analisis bentuk distribusi hanyalah tempat di mana, menurut saya, algoritme dapat ditingkatkan.
Bekerja dengan basis data
Dari semua hal di atas, kita dapat menyimpulkan bahwa kita sering memperbarui data tentang pemasok dan pesaing dan dalam banyak hal, dan bekerja dengan basis data dapat menjadi hambatan. Pada prinsipnya, kami awalnya memperhatikan hal ini dan mencoba mencapai kinerja maksimal. Saat bekerja dengan sejumlah besar catatan, kami melakukan hal berikut:
- kami menghapus indeks dari tabel tempat kami bekerja
- nonaktifkan pengindeksan teks lengkap pada tabel ini
- hapus semua rekaman dengan kondisi tertentu (misalnya, semua penawaran pemasok tertentu yang sedang kami proses)
- masukkan catatan baru dengan BULK COPY
- buat kembali indeks
- aktifkan pengindeksan teks lengkap
Salinan massal beroperasi pada kecepatan 10-40 ribu catatan per detik, mengapa penyebaran yang begitu besar masih harus dilihat, tetapi sangat dapat diterima.
Menghapus catatan membutuhkan waktu yang hampir bersamaan dengan memasukkan. Masih diperlukan waktu untuk membuat ulang indeks.
Omong-omong, untuk setiap direktori kami memiliki basis data yang terpisah. Kami membuatnya dengan cepat. Dan sekarang saya akan memberi tahu Anda mengapa kami memiliki lebih dari satu katalog.
Apa masalah katalogisasi?
Dan ada banyak dari mereka juga. Sekarang kita akan daftar:
- Katalog berisi sekitar 400 ribu produk dari kategori yang sangat berbeda. Tidak mungkin untuk memahami secara profesional setiap kategori.
- Anda perlu mengikuti gaya tertentu, mengikuti aturan umum untuk nama katalog, menamai subkategori, dan sebagainya. Jadi kami berusaha untuk mencapai struktur direktori yang koheren dan logis.
- Anda dapat membuat produk yang sama beberapa kali, dan ini merupakan masalah. Tanpa alat yang menganalisis nama yang mirip, duplikat terus-menerus dibuat.
- Masuk akal untuk menambah katalog barang-barang yang ada dalam persediaan oleh pemasok. Dalam hal ini, Anda perlu memiliki prioritas untuk kategori produk.
- Kami membutuhkan beberapa direktori. Salah satu dari kami sendiri, kami melakukannya sendiri, yang lain - katalog agregator, kami memperbaruinya dengan api. Arti katalog kedua adalah bahwa platform agregator hanya berfungsi dengan katalognya sendiri, dan, karenanya, menerima penawaran dalam nomenklaturnya. Ini adalah tempat lain di mana ternyata Anda perlu perbandingan.
Kami pikir logis dan benar untuk mempertahankan direktori di tempat yang sama dengan perbandingan. Jadi kami dapat memberi tahu pengguna yang mengelola direktori apa yang dimiliki pemasok, tetapi tidak di direktori.
Bagaimana cara kita menyimpan katalog
Ini akan tentang katalog tanpa karakteristik rinci, karakteristik adalah cerita besar yang terpisah, tentang itu lain waktu.
Sebagai properti dasar, kami memilih yang berikut:
- produser
- kategori
- model
- nomor barang
- warna
- Ean
Pertama, kami membuat api untuk mendapatkan katalog dari sumber eksternal, dan kemudian kami bekerja pada kenyamanan membuat, mengedit, dan menghapus catatan.
Cara kerja pencarian
Kenyamanan mengelola katalog, pertama-tama, adalah kemampuan untuk dengan cepat menemukan produk dalam katalog atau penawaran pemasok, dan ada nuansa. Misalnya, Anda harus dapat mencari baris "LG 21.5" 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P "untuk" 2MP48 ".
Pencarian sql server teks lengkap di luar kotak tidak sesuai, karena tidak tahu bagaimana melakukannya, dan pencarian dengan LIKE '% 2MP48%' terlalu lambat.
Solusi kami cukup standar, kami menggunakan N-gram. Lebih tepatnya, lalu trigram. Dan sudah oleh trigram kami membangun indeks teks lengkap dan melakukan pencarian teks lengkap. Saya tidak yakin bahwa kami menggunakan ruang dengan sangat rasional dalam kasus ini, tetapi dalam hal kecepatan solusi ini muncul, tergantung pada permintaan, ia bekerja dari 50 hingga 500 milidetik, kadang-kadang hingga satu detik dengan susunan tiga juta rekaman.
Biarkan saya jelaskan, baris “LG 21.5” 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P ”dikonversi ke baris“ lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22 ”, yang disimpan dalam bidang terpisah yang berpartisipasi dalam indeks teks lengkap.
Ngomong-ngomong, trigram masih berguna bagi kita.
Buat produk baru
Sebagian besar, produk dalam katalog dibuat atas saran pemasok. Artinya, kami sudah memiliki informasi bahwa pemasok menawarkan "LG Monitor LCD 21.5 '' [16: 9] 1920x1080 (FHD) IPS, nonGLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Warna, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P ”dengan harga $ 120, dan ia memiliki stok 5 hingga 10 unit.
Saat membuat produk, pertama-tama, kita perlu memastikan bahwa produk tersebut belum dibuat dalam katalog. Kami memecahkan masalah ini dalam empat tahap.
Pertama, jika kita memiliki produk di katalog, sangat mungkin bahwa proposal pemasok akan dicocokkan dengan produk ini secara otomatis.
Kedua, sebelum menunjukkan kepada pengguna formulir untuk membuat produk baru, kami akan melakukan pencarian dengan trigram dan menunjukkan hasil yang paling relevan. (secara teknis ini dilakukan dengan menggunakan CONTAINSTABLE).
Ketiga, saat kami mengisi kolom untuk produk baru, kami akan menunjukkan produk yang sama yang sudah ada. Ini memecahkan dua masalah: membantu menghindari duplikat dan mempertahankan gaya dalam nama, produk serupa dapat digunakan sebagai model.
Dan keempat, ingat, kita memecah garis menjadi token, menormalkannya, menghitung hash? Kami akan melakukan hal yang sama dan tidak akan membiarkan membuat barang dengan hash yang sama.
Pada tahap ini, kami mencoba membantu pengguna. Pada baris yang ada dalam daftar harga, kami akan mencoba menentukan produsen, kategori, artikel, EAN dan warna barang. Pertama, dengan token (kami dapat membaginya ke dalam kategori), lalu, jika tidak berhasil, kami akan menemukan produk yang paling mirip dengan trigram. Dan, jika cukup mirip, isikan pabrikan dan kategorinya.
Pengeditan produk bekerja hampir sama, hanya saja tidak semuanya berlaku.
Bagaimana kami menetapkan harga kami
Tugasnya adalah ini: untuk menjaga keseimbangan antara kuantitas dan margin penjualan, pada kenyataannya - untuk mencapai laba maksimum. Semua aspek lain dari pekerjaan toko juga tentang hal ini, tetapi apa yang terjadi pada tahap penetapan harga memiliki dampak terbesar.
Paling tidak, kita akan memerlukan informasi tentang penawaran dari pemasok dan pesaing. Juga layak mempertimbangkan harga eceran dan grosir minimum dan biaya pengiriman, serta instrumen keuangan - pinjaman dan angsuran.
Kami mengumpulkan harga pesaing
Untuk mulai dengan, kami memiliki banyak profil harga kami sendiri. Ada profil untuk ritel, ada beberapa untuk pelanggan grosir. Semuanya dibuat dan dikonfigurasi dalam sistem kami.
Dengan demikian, pesaing untuk setiap profil berbeda. Dalam ritel - toko ritel lain, dalam penjualan grosir - pemasok kami yang sama.
Semuanya jelas dengan pemasok, tetapi untuk ritel kami mengumpulkan data pesaing dalam beberapa cara. Pertama, beberapa agregator memberikan informasi tentang semua harga untuk semua barang yang ada di situs. Dalam nomenklatur kita sendiri, tetapi kita dapat mencocokkan produk, sehingga itu bekerja secara otomatis. Dan ini hampir cukup untuk saat ini. Kedua, kami memiliki parser pesaing. Karena belum otomatis dan ada dalam bentuk aplikasi konsol (yang terkadang macet), kami jarang menggunakannya.
Kustomisasi profil Anda
Dalam profil, kami memiliki peluang untuk mengkonfigurasi rentang margin yang berbeda tergantung pada harga barang dari pemasok, kategori, pabrikan, pemasok.
Masih dimungkinkan untuk menunjukkan dengan pemasok mana dalam kategori atau produsen mana kami bekerja, dan dengan siapa - tidak, pesaing mana yang kami perhitungkan.Kemudian kami menyiapkan instrumen keuangan, menunjukkan cicilan mana yang tersedia dan berapa banyak bank akan mengambil sendiri.Dan sudah dalam margin margin, kami membentuk harga kami sendiri, berusaha mempertahankan keseimbangan yang sama di tempat pertama, dan membuat barang gudang kami menjual lebih baik di tempat kedua. Singkatnya, tetapi sebenarnya saya tidak berani menjelaskan dengan kata-kata sederhana apa yang terjadi di sana.Saya dapat memberi tahu Anda apa yang tidak terjadi. Sayangnya, kami belum tahu bagaimana memperkirakan permintaan dan memperhitungkan biaya penyimpanan barang di gudang.Integrasi dengan sistem pihak ketiga
Bagian penting dari sudut pandang bisnis, tetapi tidak menarik dari sudut pandang teknis. Singkatnya, saya akan mengatakan bahwa kami dapat mengirim data ke sistem pihak ketiga (termasuk yang inkremental, yaitu, kami memahami apa yang telah berubah sejak pertukaran terakhir) dan kami dapat melakukan milis.Nawala dapat disesuaikan, jadi (dan tidak hanya itu) kami memberikan penawaran kami kepada pelanggan grosir.Cara lain untuk bekerja dengan pelanggan grosir adalah portal b2b. Masih dalam pengembangan aktif, itu akan bekerja secara harfiah dalam sebulan.Akun, ubah logging
Pertanyaan lain yang tidak menarik dari sudut pandang teknis. Setiap pengguna memiliki akun.Singkatnya, berikut ini dapat dikatakan: jika ORM digunakan, maka ia memiliki mekanisme pelacakan perubahan bawaan. Jika Anda masuk ke dalamnya (dan dalam kasus kami ini adalah EF Core dan bahkan ada API di sana), maka Anda dapat masuk hampir dua baris.Untuk histori perubahan, kami membuat antarmuka, dan sekarang Anda dapat melacak siapa yang mengubah apa yang ada di pengaturan sistem, siapa yang mengedit atau membandingkan produk tertentu, dan sebagainya.Menurut log, statistik dapat dipertimbangkan, yang kami lakukan. Kami tahu siapa yang membuat atau mengedit berapa banyak produk, berapa perbandingan yang dikonfirmasi secara manual dan berapa banyak yang ditolak, Anda dapat melihat setiap perubahan.Sedikit tentang struktur umum sistem
Kami memiliki satu database untuk akun dan hal-hal yang tidak tergantung pada katalog, satu database untuk log, dan database untuk setiap direktori. Ini membuat kueri direktori lebih mudah, dan analisis data lebih mudah, dan kode lebih mudah dimengerti.Omong-omong, sistem logging ini ditulis sendiri, kita benar-benar perlu mengelompokkan log terkait dengan satu permintaan atau satu tugas berat, di samping itu, kita memerlukan fungsionalitas dasar untuk analisis mereka. Dengan solusi turnkey, ini ternyata sulit, ditambah lagi ini adalah ketergantungan yang perlu didukung.Antarmuka web dibuat pada ASP.NET Core dan bootstrap, dan operasi berat dilakukan oleh layanan Windows.Fitur lain yang menguntungkan proyek ini, menurut saya, adalah model yang berbeda untuk membaca dan menulis data. Kami tidak menerapkan CQRS sepenuhnya, tetapi kami mengambil salah satu konsep dari sana. Kami menulis ke database melalui repositori, tetapi objek yang digunakan untuk merekam tidak pernah meninggalkan metode update / create / delete. Pembaruan massal dilakukan melalui BULK COPY. Model terpisah dan lapisan akses data yang terpisah dibuat untuk membaca, jadi kami hanya membaca apa yang kami butuhkan pada saat tertentu. Ternyata Anda dapat menggunakan ORM, sambil menghindari pertanyaan berat, mengakses database pada waktu yang tidak pasti (seperti dengan pemuatan malas), masalah N + 1. Dan kami juga menggunakan model untuk membaca sebagai DTO.Dari dependensi utama, kami memiliki ASP.NET Core, beberapa paket nuget pihak ketiga, dan MS SQL Server. Meskipun mungkin, kami berusaha untuk tidak bergantung pada banyak sistem pihak ketiga. Untuk sepenuhnya menyebarkan proyek secara lokal, cukup instal SQL Server, ambil kode sumber dari sistem kontrol versi dan bangun proyek. Basis data yang diperlukan akan dibuat secara otomatis, tetapi tidak ada lagi yang diperlukan. Anda mungkin harus mengubah satu atau dua baris dalam konfigurasi.Apa yang tidak
Kami belum membuat sistem pengetahuan proyek. Kami ingin melakukan wiki dan tips di tempat. Mereka tidak membuat antarmuka intuitif yang sederhana, antarmuka yang tidak buruk, tetapi sedikit bingung untuk orang yang tidak siap. CI / CD sejauh ini hanya dalam rencana.Tidak menangani detail karakteristik barang. Kami juga berencana, tetapi belum ada tenggat waktu yang spesifik.
Ringkasan Bisnis
Dari awal pengembangan aktif hingga peluncuran produksi, dua orang bekerja di proyek selama 7 bulan. Pada awalnya, kami memiliki prototipe yang dibuat di waktu luang kami. Integrasi yang paling sulit diberikan kepada sistem yang ada.Selama tiga bulan kami dalam produksi, jumlah barang yang tersedia untuk pelanggan grosir telah berkembang dari 70 ribu menjadi 230 ribu, jumlah barang di situs - dari 60 ribu menjadi 140 ribu. Situs ini selalu terlambat karena membutuhkan fitur, gambar, deskripsi produk. Kami menurunkan 106 ribu penawaran pada agregator, bukan 40 ribu tiga bulan lalu. Jumlah orang yang bekerja dengan katalog tidak berubah.Kami bekerja dengan 425 pemasok, jumlah ini hampir dua kali lipat dalam tiga bulan. Kami melacak harga lebih dari seribu pesaing. Yah, saat kami melacaknya - kami memiliki sistem untuk parsing, tetapi dalam kebanyakan kasus kami mengambil data yang sudah jadi dari mereka yang secara teratur menyediakannya.Sayangnya, saya tidak bisa memberi tahu Anda tentang penjualan, saya sendiri tidak memiliki data yang dapat diandalkan. Permintaan bersifat musiman, dan tidak mungkin untuk langsung membandingkan bulan ke bulan sebelumnya. Dan dalam satu tahun terlalu banyak yang terjadi untuk menyoroti pengaruh sistem kami dari semua faktor. Sangat, sangat kondisional, plus atau minus satu kilometer, pertumbuhan katalog, harga yang lebih fleksibel dan kompetitif dan pertumbuhan penjualan terkait telah membayar untuk pengembangan dan implementasi.Hasil lain - kami mendapatkan proyek yang pada dasarnya tidak terkait dengan infrastruktur toko tertentu, dan Anda dapat membuat layanan publik darinya. Itu dikandung sejak awal, dan rencana ini hampir berhasil. Sayangnya, solusi kotak gagal. Untuk menawarkan proyek sebagai layanan tempat Anda dapat mendaftar, centang kotak "Saya setuju", dan yang berfungsi "apa adanya", tanpa beradaptasi dengan klien, Anda perlu mendesain ulang antarmuka, menambah fleksibilitas dan membuat wiki. Dan untuk membuat infrastruktur mudah terukur dan menghilangkan satu titik kegagalan. Sekarang kami hanya memiliki cadangan reguler dari cara memastikan keandalan. Sebagai solusi perusahaan, saya pikir kami siap untuk menyelesaikan masalah bisnis. Usaha kecil adalah mencari bisnis.Omong-omong, kami telah menarik satu klien pihak ketiga, yang memiliki fungsi paling dasar. Orang-orang membutuhkan alat untuk membandingkan barang, dan ketidaknyamanan yang terkait dengan pengembangan aktif tidak menakuti mereka.