Banyak yang telah bekerja dengan Spark ML tahu bahwa beberapa hal yang telah mereka lakukan di sana "tidak sepenuhnya berhasil."
atau tidak dilakukan sama sekali. Posisi pengembang Spark adalah bahwa SparkML adalah platform dasar, dan semua ekstensi harus merupakan paket terpisah. Tapi ini tidak selalu nyaman, karena Data Scientist dan analis ingin bekerja dengan alat yang sudah dikenal (Jupter, Zeppelin), di mana ada sebagian besar dari apa yang dibutuhkan. Mereka tidak ingin mengumpulkan file JAR 500 megabyte dengan perakitan-maven atau mengunduh dependensi di tangan mereka dan menambahkannya ke parameter startup Spark. Pekerjaan yang lebih baik dengan sistem pembangunan proyek-JVM mungkin memerlukan banyak upaya tambahan dari analis dan DataScientists yang terbiasa dengan Jupyter / Zeppelin. Meminta DevOps dan administrator cluster untuk meletakkan banyak paket pada node komputasi jelas merupakan ide yang buruk. Siapa pun yang memiliki ekstensi tertulis untuk SparkML secara independen tahu berapa banyak kesulitan tersembunyi yang ada dengan kelas dan metode penting (yang karena alasan pribadi [ml]), pembatasan pada jenis parameter yang disimpan, dll.
Dan tampaknya sekarang, dengan perpustakaan MMLSpark, hidup akan sedikit lebih mudah, dan ambang batas untuk memasuki pembelajaran mesin yang skalabel dengan SparkML dan Scala sedikit lebih rendah.
Pendahuluan
Karena sejumlah kesulitan, serta serangkaian metode dan solusi yang sudah jadi di SparkML, banyak perusahaan menulis ekstensi mereka untuk Spark. Salah satu contoh adalah PravdaML , yang sedang dikembangkan di Odnoklassniki dan yang, dilihat dari penilaian cepat tentang apa yang ada di GitHub, terlihat sangat menjanjikan. Sayangnya, sebagian besar solusi ini tertutup atau terbuka sama sekali, tetapi mereka tidak memiliki kemampuan untuk menginstal melalui Maven / sbt dan dokumentasi API, yang membuatnya sangat sulit untuk bekerja dengannya.
Hari ini kita melihat perpustakaan MMLSpark .
Kami akan mempertimbangkan, seperti biasa, contoh tugas mengklasifikasikan penumpang Titanic. Tujuannya adalah untuk menunjukkan sebanyak mungkin fitur perpustakaan MMLSpark, bukan nonaktifkan SOTA di ImageNet tunjukkan pembelajaran mesin keren. Jadi Titanic akan melakukannya.

Perpustakaan itu sendiri memiliki API asli untuk Scala ( dokumentasi ), Python API ( dokumentasi ), dan, dilihat dari beberapa tempat dalam repositori GitHub, perpustakaan itu akan segera memiliki API untuk R.
Ada contoh laptop yang bagus dalam proyek GitHub (PySpark + Jupyter) , tetapi kita akan pergi ke arah lain. Seperti yang ditulis Dmitry Bugaychenko, jika Anda mengembangkan untuk Spark, yaitu, Anda punya alasan untuk menggunakan Scala untuk ini, apalagi, Scala memungkinkan Anda untuk mendefinisikan Transformer dan Estimator Anda sendiri dengan lebih efisien dan lebih fleksibel untuk menanamkannya dalam SparkML Pipeline, tetapi seberapa lambat ia bekerja dengan lamban / kode panda dalam UDF (dipanggil executable dari JVM) telah banyak ditulis.
Instalasi Singkat
Seluruh laptop tersedia di sini . Untuk bekerja dengan Titanic, gambar Docker dari Zeppelin berjalan secara lokal pada laptop dengan pengaturan default sudah cukup untuk mata. Docker dapat ditemukan di sini . Perpustakaan MMLSpark bukan di Maven Central, tetapi dalam paket-percikan, dan untuk menambahkannya ke Zeppelin, Anda harus menjalankan blok berikut di awal laptop:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
Perlu dikatakan bahwa perpustakaan memiliki kompatibilitas ke belakang yang sangat baik: tidak seperti, misalnya, XGBoost4j-spark, yang membutuhkan minimal Spark 2.3+, hal ini masuk ke Spark 2.2.1, yang datang dengan gambar Zeppelin Docker, dan kesulitan apa pun. Saya tidak memperhatikan.
Catatan: sebagian besar pustaka MMLSpark didedikasikan untuk inferensi kisi-kisi pada sebuah cluster, di mana CNTK hadir (yang, dilihat dari dokumentasi, harus membaca model cntk yang sudah jadi) dan blok OpenCV yang besar. Kami akan fokus pada tugas yang lebih duniawi dan mencoba untuk "memodelkan" kasus ketika kami memiliki array besar data tabular yang terletak di HDFS dalam bentuk .csv, tabel atau dalam format lain. Jadi, kita perlu pra-proses dan membangun model, sementara data ini tidak sesuai dengan memori satu mesin. Karena itu, kami akan melakukan semua tindakan pada cluster.
Analisis Membaca dan Kecerdasan
Secara umum, Spark + Zeppelin tidak buruk sama sekali dan dapat mengatasi tugas EDA, tetapi kami akan mencoba untuk memperluas kemampuan mereka. Pertama, kita mengimpor kelas yang kita butuhkan:
- Semua dari spark.sql.types untuk mendeklarasikan skema dan membaca data dengan benar
- Semua dari fungsi spark.sql. untuk mengakses kolom dan menggunakan fungsi bawaan
- com.microsoft.ml.spark.SummarizeData , yang bisa disebut analog panda. DataFrame.description
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
Kami membaca file kami:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
Dan sekarang mari kita lihat data itu sendiri, serta ukurannya:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
Catatan: Benar-benar tidak perlu menggunakan createOrReplaceTempView ketika Anda bisa menulis .show (5). Tetapi pertunjukan memiliki masalah: ketika data "lebar", maka representasi tekstual dari pelat "mengapung", dan tidak ada yang menjadi jelas sama sekali.
Dapatkan ukuran data kami: Train shape is: 891 x 12
Dan sekarang di sel sql kita bisa melihat 5 baris pertama:
%sql select * from trainHead
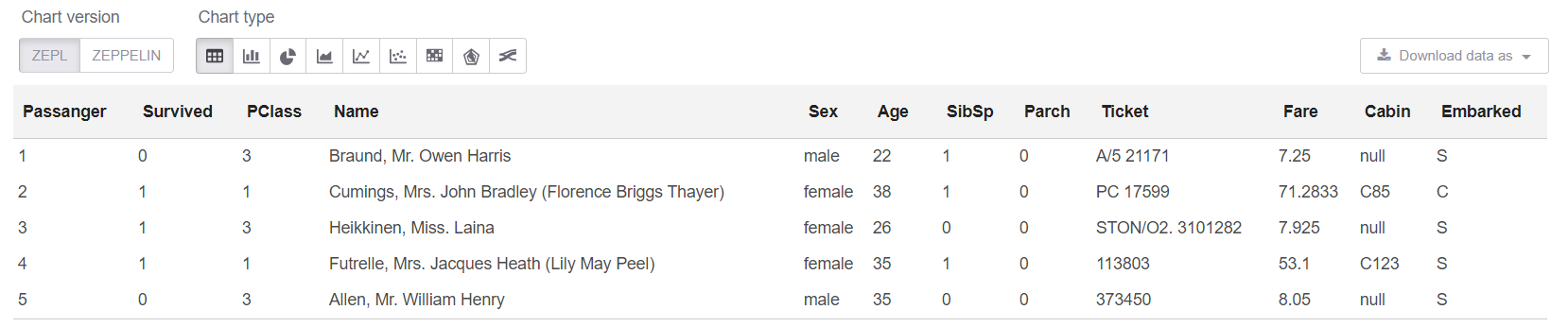
Baiklah, mari kita lihat Ringkasan di meja kami:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
Kelas SummarizeData memiliki beberapa keunggulan dibandingkan Dataset.description sederhana, karena memungkinkan Anda untuk menghitung jumlah nilai yang hilang dan unik, dan juga memungkinkan Anda untuk menentukan keakuratan penghitungan kuantil. Ini bisa sangat penting untuk data yang sangat besar.

Beberapa pemikiran pribadiSecara umum, bagi saya pribadi bahwa Odnoklassniki di PravdaML memiliki implementasi yang lebih baik dari analog SummarizeData. Microsoft berjalan dengan mudah dan menggunakan org.apache.spark.sql.functions , hanya saja semuanya dengan mudah dibungkus dalam satu kelas. Untuk Odnoklassniki, ini diterapkan melalui VectorStatCollector mereka, yang memerlukan kode yang sedikit lebih rumit saat memanggil (Anda harus terlebih dahulu menambahkan semua fitur ke dalam vektor) dan mungkin memerlukan operasi tambahan (misalnya, VectorAssembler biasanya menolak untuk mencerna DecimalType ). Tetapi saya memiliki asumsi berdasarkan pengalaman saya dengan Spark bahwa SummarizeData dari MMLSpark mungkin macet dengan kesalahan seperti StackOverflow di org.apache.spark.sql.catalyst jika ada banyak kolom, dan grafik perhitungannya tidak kecil pada saat dimulai ( meskipun khusus untuk penggemar "ekstrim" seperti itu di Spark 2.4 mereka menambahkan kemampuan untuk mengurangi pengoptimal grafik Catalyst ). Nah, tampaknya dengan jumlah kolom yang sangat besar , versi dari Microsoft akan lebih lambat. Tetapi ini, tentu saja, harus diperiksa secara terpisah.
Pembersihan data
Di Titanic, semuanya seperti biasa - sekelompok kolom string adalah nilai yang hilang. Dan beberapa jenis cant dalam data (sepertinya versi data ini tidak terlalu spesifik) - 25 baris dari nilai yang hilang. Pertama, perbaiki ini:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
Pemrosesan data string
Sejauh yang saya ingat, atribut yang dibawa keluar dari bidang Name dan Cabin adalah yang terbaik dibawa di Titanic. Anda dapat memasok mereka banyak, tetapi kami akan membatasi diri hanya sedikit, hanya agar tidak memberikan contoh kode yang hampir sama.
Biasanya nyaman untuk menggunakan ekspresi reguler untuk hal-hal seperti itu.
Tapi kami ingin dalam hal ini:
- semuanya didistribusikan, data diproses di tempat yang sama;
- semuanya dirancang sebagai SpakrML Transformer atau Spark ML Estimator, sehingga nantinya bisa dirakit di Pipeline.
Catatan: Pipeline, pertama, menjamin kami bahwa kami selalu menerapkan transformasi yang sama untuk kereta dan tes, dan juga memungkinkan kami untuk menangkap kesalahan "melihat ke masa depan" dalam validasi silang. Dan itu juga memberi kita kemampuan sederhana untuk menghemat, memuat, dan memperkirakan menggunakan saluran pipa kami.
SparkML memiliki kelas "hampir universal" untuk tugas-tugas tersebut - SQLTranformer , tetapi menulis dalam SQL jelas lebih buruk daripada menulis di Scala, jika hanya karena dimungkinkan untuk menangkap sintaks atau kesalahan khas selama kompilasi dan penyorotan sintaks dalam Ide. Dan di sini MMLSpark datang untuk membantu kami, di mana UDFTransformer yang benar-benar universal diterapkan :
import com.microsoft.ml.spark.UDFTransformer
Untuk memulainya, kami akan membuat fungsi transformasi kami, yang sangat sederhana hingga batasnya, tetapi tujuan kami sekarang adalah untuk menunjukkan proses pembuatan UDFTransformer. Pada prinsipnya, berdasarkan contoh sederhana seperti itu, siapa pun dapat menambahkan logika ke tingkat kompleksitas apa pun.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(Anda dapat segera melihat betapa nyamannya Scala untuk bekerja dengan nilai yang hilang, yang, omong-omong, tidak hanya null , tetapi juga Double.NaN , tetapi ada lelucon seperti itu hal yang jarang terjadi seperti kelalaian dalam variabel BooleanType , dll.)
Sekarang nyatakan UserDefinedFunction kami dan segera buat Transformer berdasarkan itu:
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
Catatan: Di laptop Zeppelin, semuanya sama saja, tetapi ketika semuanya datang bersamaan dalam kode produksi, penting bahwa semua UDF berada di kelas atau objek yang extends Serializable . Hal yang jelas bahwa Anda kadang-kadang bisa melupakan dan kemudian mempelajari untuk waktu yang lama adalah apa yang salah dengan membaca jejak tumpukan panjang kesalahan Spark.
Sekarang kami masih memiliki bidang Cabin . Mari kita lihat lebih dekat:

Kami melihat bahwa ada banyak nilai yang hilang, ada huruf, angka, kombinasi berbeda, dll. Mari kita ambil jumlah kabin (jika lebih dari satu), dan juga jumlahnya - mereka mungkin memiliki semacam logika, misalnya, jika penomorannya dari satu ujung kapal, maka kabin pada haluan memiliki peluang lebih kecil. Kami juga akan membuat fungsi, dan kemudian berdasarkan padanya UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
Sekarang mari kita mulai dengan nilai-nilai yang hilang, yaitu usia. Pertama, mari manfaatkan kemampuan visualisasi Zeppelin:
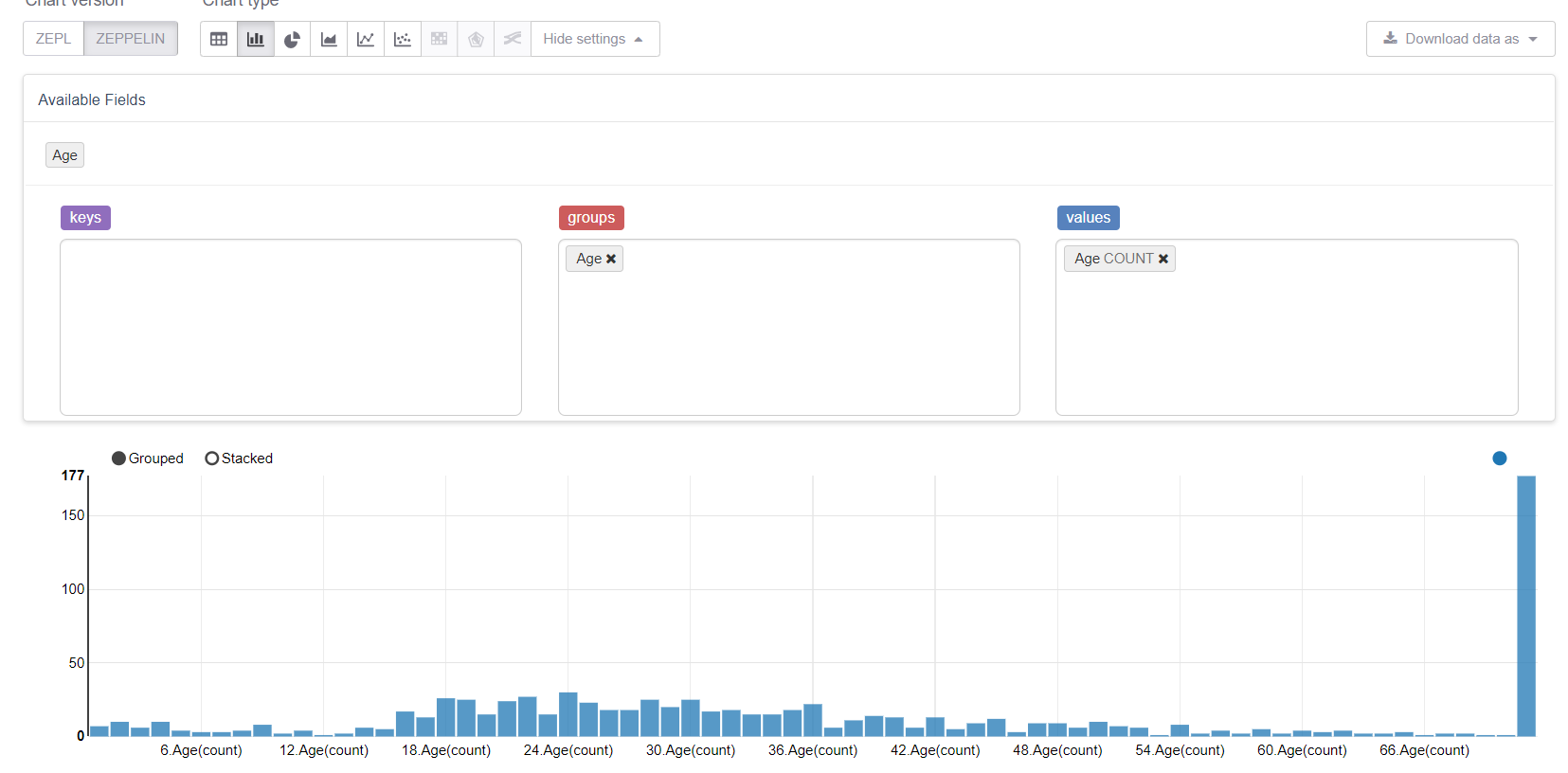
Dan lihat bagaimana nilai-nilai yang hilang merusak segalanya. Adalah logis untuk menggantinya dengan nilai tengah (atau median), tetapi tujuan kami adalah untuk mempertimbangkan semua fitur perpustakaan MMLSpark. Oleh karena itu, kami akan menulis Estimator kami sendiri, yang akan mempertimbangkan kelompok / rata-rata pada sampel pelatihan dan menggantinya dengan kesenjangan yang sesuai.
Kami akan membutuhkan:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
Mari kita perhatikan ConstructorWritable , yang sangat menyederhanakan kehidupan. Jika Model kami adalah Model "terlatih" yang mengembalikan metode fit(), , yang sepenuhnya ditentukan oleh konstruktornya (dan ini mungkin 99% kasus), maka kami tidak dapat menulis serialisasi dengan tangan kami sama sekali. Ini sangat menyederhanakan dan mempercepat pengembangan, menghilangkan kesalahan, dan juga menurunkan ambang entri untuk DataScientist dan analis yang biasanya bukan programmer profesional.
Tentukan kelas Estimator kami. Padahal, yang terpenting di sini adalah metode fit , sisanya adalah poin teknis:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
Catatan: Saya tidak menggunakan defaultCopy, karena ketika saya menelepon, untuk beberapa alasan, bersumpah bahwa saya tidak memiliki konstruktor. \ <init> (java.lang.String), walaupun sepertinya ini seharusnya tidak terjadi. Nah, bagaimanapun, menerapkan copy mudah.
Sekarang Anda perlu mengimplementasikan Model - kelas yang menggambarkan model yang terlatih dan mengimplementasikan metode transform . Kami akan membangunnya berdasarkan fungsi coalesce dibangun ke dalam fungsi org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
Objek terakhir yang perlu kita deklarasikan adalah Reader , yang kami implementasikan menggunakan kelas MMLSpark ConstructorReadable :
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
Pembuatan Pipa
Di Pipeline, saya ingin menunjukkan kelas SparkML yang biasa dan hal yang sangat nyaman dari MMLSpark - MultiColumnAdapter , yang memungkinkan Anda untuk menerapkan transformator SparkML ke banyak kolom sekaligus (untuk referensi, misalnya, StringIndexer dan OneHotEncoder mengambil tepat satu kolom ke input, yang mengubahnya) iklan kesakitan):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
Pertama, kami akan mendeklarasikan kolom mana yang kami miliki:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
Sekarang buat string encoder:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
Catatan: Tidak seperti scikit-learn di SparkML, StringIndexer bekerja berdasarkan prinsip frequency-encoder, dan itu dapat digunakan untuk menentukan hubungan pesanan (mis. Kategori 0 <kategori 1, dan ini masuk akal) - pendekatan ini sering bekerja dengan baik untuk pohon yang menentukan.
Imputer kami:
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
Dan VectorAssembler , karena pengklasifikasi SparkML lebih nyaman bekerja dengan VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
Sekarang kita akan menggunakan peningkatan gradien yang disertakan dengan MMLSpark - LightGBM, yang termasuk dalam "Tiga Besar" implementasi terbaik dari algoritma ini bersama dengan XGBoost dan CatBoost. Ini berfungsi berkali-kali lebih cepat, lebih baik dan lebih stabil daripada implementasi GBM yang dimiliki SparkML (bahkan dengan mempertimbangkan bahwa port JVM masih dalam pengembangan aktif):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
Catatan: LightGBM mendukung kerja dengan variabel kategorikal (hampir seperti catboost), jadi kami menunjukkannya terlebih dahulu di mana atribut kategori ada di vektor kami, dan dia sendiri akan mencari tahu apa yang harus dilakukan dengan mereka dan bagaimana cara menyandikannya.
Lebih lanjut tentang fitur LightGBM untuk Spark- Pada node yang menjalankan RadHat LightGBM, versi apa pun kecuali yang terbaru akan macet karena fakta bahwa ia tidak menyukai versi
glibc . Ini diperbaiki baru-baru ini , namun, ketika menginstal melalui Maven, MMLSpark menarik versi kedua dari LightGBM ketika menginstal melalui Maven, jadi Anda perlu menambahkan ketergantungan versi terbaru pada RadHat dengan tangan Anda. - LightGBM dalam pekerjaannya menciptakan soket pada driver untuk komunikasi dengan para eksekutif, dan ia melakukan ini menggunakan
new java.net.ServerSocket(0) , dan oleh karena itu port acak dari port sesaat OS digunakan. Jika kisaran port fana berbeda dari kisaran port yang dibuka oleh firewall, maka dapat membakar banyak Anda bisa mendapatkan efek yang menarik ketika LightGBM terkadang berhasil (ketika saya memilih port yang bagus), dan terkadang tidak. Dan akan ada kesalahan di sana seperti ConnectionTimeOut , yang juga dapat menunjukkan, misalnya, opsi ketika GC bergantung pada eksekutif atau sesuatu seperti itu. Secara umum, jangan ulangi kesalahan saya.
Yah, akhirnya, nyatakan Pipeline kami:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
Pelatihan
Kami akan mematahkan set pelatihan kami menjadi kereta api dan tes dan memeriksa Pipa kami. Di sini, hanya mungkin untuk mengevaluasi kenyamanan pipa, karena sepenuhnya independen terhadap partisi dan menjamin kami bahwa kami akan menerapkan transformasi yang sama untuk melatih dan menguji, dan semua parameter transformasi akan "dipelajari" di kereta:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
Untuk perhitungan metrik yang nyaman, kami akan menggunakan kelas lain dari MMLSpark - ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
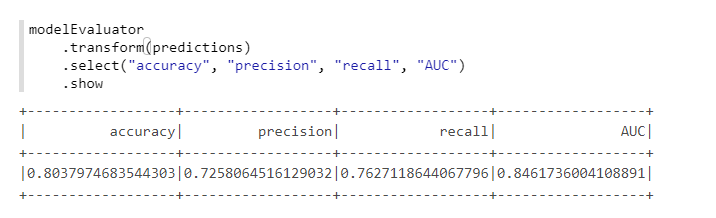
Tidak buruk, mengingat bahwa kami tidak mengubah pengaturan default.
Pemilihan hiperparameter
Untuk memilih hyperparameters di MMLSpark ada hal keren yang terpisah TuneHyperparameters , yang mengimplementasikan pencarian acak di grid. Namun, sayangnya, itu belum mendukung Pipeline , jadi kami akan menggunakan SparkML CrossValidator biasa:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
Sayangnya, saya tidak menemukan cara yang nyaman bagaimana Anda bisa melihat hasilnya bersama dengan parameter yang didapat. Karena itu, perlu menggunakan desain "mengerikan":
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
Yang memberi kita sesuatu seperti ini:
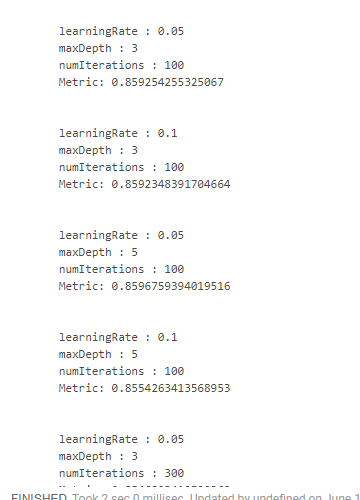
Kami mendapatkan hasil terbaik dengan mengurangi kecepatan belajar dan meningkatkan kedalaman pohon. Atas dasar ini, akan dimungkinkan untuk menyesuaikan ruang pencarian dan mencapai hasil yang lebih optimal, tetapi kami tidak memiliki tujuan seperti itu.
Kesimpulan
Bahkan, sementara MMLSpark memiliki versi 0.17 dan masih mengandung bug terpisah. Namun dari semua ekstensi Spark yang saya lihat, MMLSpark menurut saya memiliki dokumentasi yang paling komprehensif dan proses instalasi dan implementasi yang paling mudah dipahami. Microsoft belum benar-benar mempromosikannya, hanya ada laporan tentang Databricks , tetapi ada lebih banyak tentang DeepLearning, dan bukan tentang hal-hal rutin yang saya tulis.
Secara pribadi, dalam tugas kami, perpustakaan ini banyak membantu, memungkinkan saya mendapatkan sedikit lebih sedikit melalui hutan sumber Spark dan tidak menggunakan reflek untuk mengakses metode pribadi [ml], dan seorang rekan menemukan perpustakaan hampir secara kebetulan. Pada saat yang sama, karena fakta bahwa perpustakaan sedang dalam pengembangan aktif, struktur file sumber bubur penuh agak membingungkan. Nah, karena kenyataan bahwa tidak ada contoh khusus atau dokumentasi lain (kecuali untuk skaladoc telanjang), pada awalnya kami harus merangkak ke kode sumber terus-menerus.
Oleh karena itu, saya sangat berharap bahwa tutorial mini ini (terlepas dari semua kejelasan dan kesederhanaannya) akan bermanfaat bagi seseorang dan akan membantu menghemat banyak waktu dan usaha!