Kursus lengkap dalam bahasa Rusia dapat ditemukan di tautan ini .
Kursus bahasa Inggris asli tersedia di tautan ini .

Kuliah baru dijadwalkan setiap 2-3 hari.
Isi
- Wawancara dengan Sebastian Trun
- Pendahuluan
- Dataset Anjing dan Kucing
- Gambar berbagai ukuran
- Gambar berwarna. Bagian 1
- Gambar berwarna. Bagian 2
- Operasi konvolusi pada gambar berwarna
- Pengoperasian subsampling dengan nilai maksimum dalam gambar berwarna
- CoLab: kucing dan anjing
- Softmax dan sigmoid
- Periksa
- Ekstensi gambar
- Pengecualian
- CoLab: anjing dan kucing. Pengulangan
- Teknik lain untuk mencegah pelatihan ulang
- Latihan: klasifikasi gambar berwarna
- Solusi: klasifikasi gambar warna
- Ringkasan
Wawancara dengan Sebastian Trun
- Jadi, hari ini kita di sini lagi, bersama dengan Sebastian dan kita akan berbicara tentang pelatihan ulang. Topik ini sangat menarik bagi kami, terutama di bagian praktis dari kursus saat ini tentang bekerja dengan TensorFlow.
- Sebastian, apakah Anda pernah mengalami overfitting - over, fit? Jika Anda mengatakan bahwa Anda belum menemukan, maka saya pasti akan mengatakan bahwa saya tidak dapat mempercayai Anda!
- Jadi, alasan pelatihan ulang adalah apa yang disebut trade-off bias-variance (kompromi antara nilai-nilai parameter bias dan penyebarannya). Sebuah jaringan saraf di mana sejumlah kecil bobot tidak dapat mempelajari cukup banyak contoh, situasi serupa dalam pembelajaran mesin disebut distorsi.
- Ya.
- Jaringan saraf dengan begitu banyak parameter dapat secara sewenang-wenang memilih solusi yang tidak Anda sukai, hanya karena begitu banyak parameter ini. Hasil memilih solusi jaringan saraf tergantung pada variabilitas sumber data. Dengan demikian, aturan sederhana dapat dirumuskan: semakin banyak parameter dalam jaringan mengenai ukuran (jumlah) data, semakin besar kemungkinan untuk mendapatkan solusi acak dan bukan yang benar. Misalnya, Anda bertanya pada diri sendiri, "Siapa pria di ruangan ini dan siapa wanita itu?" Jaringan saraf yang kompleks dapat memberi tahu Anda bahwa, misalnya, semua yang namanya dimulai dengan T adalah laki-laki dan tidak pernah berlatih lagi. Ada dua solusi. Yang pertama menggunakan set data penghentian (sejumlah kecil dari set pelatihan untuk memvalidasi keakuratan model). Anda dapat mengambil data, membaginya menjadi dua bagian - 90% untuk pelatihan, dan 10% untuk menguji dan melakukan apa yang disebut cross-validation, di mana Anda memeriksa keakuratan model pada data yang tidak dilihat oleh jaringan saraf - segera setelah nilai kesalahan dimulai untuk tumbuh setelah siklus pelatihan tertentu - sekarang saatnya untuk berhenti belajar. Solusi kedua adalah memperkenalkan pembatasan ke dalam jaringan saraf. Misalnya, untuk membatasi nilai parameter perpindahan dan bobot, menjadikannya lebih dekat dan lebih dekat ke nol. Semakin terbatas bobotnya, semakin sedikit model yang akan dilatih ulang.
- Saya mengerti benar bahwa kita dapat memiliki kumpulan data untuk pelatihan dan pengujian serta validasi, bukan?
- Benar. Jika Anda memiliki dataset untuk validasi, maka Anda harus memiliki dataset yang belum pernah Anda sentuh atau tunjukkan ke jaringan saraf Anda. Jika Anda menunjukkan model tersebut kumpulan data tertentu berkali-kali, maka, tentu saja, proses pelatihan ulang akan dimulai, yang sangat buruk bagi kami.
- Mungkin Anda akan mengingat kasus-kasus paling menarik ketika model Anda dilatih ulang?
- Ah, ya ... ada kejadian seperti itu di masa muda saya ketika saya sedang mengembangkan jaringan saraf untuk bermain catur. Itu pada tahun 1993. Yang menarik adalah bahwa dari data catur di mana jaringan saraf dilatih, jaringan dengan cepat menentukan bahwa jika seorang ahli memindahkan ratu ke tengah papan catur, maka ada peluang 60% untuk menang. Yang mulai dia lakukan adalah membuka "lorong" dengan bidak dan memindahkan ratu ke tengah papan catur. Itu adalah keputusan yang bodoh untuk setiap pemain catur, yang dengan jelas memberikan kesaksian tentang pelatihan ulang model.
- Hebat! Jadi, kami telah membahas beberapa teknik mengenai cara meningkatkan model kami. Menurut Anda apa sisi pembelajaran yang paling diremehkan?
- 90% pekerjaan Anda diremehkan, karena 90% pekerjaan Anda terdiri dari pembersihan data.
- Di sini saya sepenuhnya setuju dengan Anda!
- Seperti yang ditunjukkan oleh praktik, kumpulan data apa pun mengandung beberapa jenis sampah. Sangat sulit untuk membawa data ke jenis yang tepat, untuk membuatnya konsisten, itu adalah proses yang sangat memakan waktu.
- Ya, bahkan jika Anda bekerja dengan set data seperti gambar atau video, di mana, tampaknya, semua informasi sudah ada di sana, di dalam, masih ada kebutuhan untuk pra-proses gambar.
- Satu-satunya orang yang datanya ideal adalah profesor, karena mereka memiliki kesempatan untuk berpura-pura dalam presentasi di PowerPoint bahwa semuanya berjalan sebagaimana mestinya dan semuanya sempurna! Pada kenyataannya, 90% dari waktu Anda akan ditempati oleh pembersihan data.
- Luar biasa. Jadi, mari cari tahu lebih banyak tentang pelatihan ulang dan teknik yang memungkinkan kita meningkatkan model pembelajaran mendalam kami.
Pendahuluan
- hai! Dan lagi, selamat datang di kursus!
“Dalam pelajaran terakhir, kami mengembangkan jaringan saraf convolutional kecil untuk mengklasifikasikan gambar item pakaian dalam nuansa abu-abu dari dataset FASHION MNIST. Kami telah melihat dalam praktiknya bahwa jaringan saraf kecil kami dapat mengklasifikasikan gambar yang masuk dengan akurasi yang cukup tinggi. Namun, di dunia nyata kita harus bekerja dengan gambar resolusi tinggi dan berbagai ukuran. Salah satu keuntungan besar SNA adalah kenyataan bahwa mereka dapat bekerja sama baiknya dengan gambar berwarna. Oleh karena itu, kami akan memulai pelajaran kami saat ini dengan mengeksplorasi bagaimana SNA bekerja dengan gambar berwarna.
- Kemudian, dalam frekuensi yang sama, Anda akan membangun jaringan saraf convolutional yang dapat mengklasifikasikan gambar kucing dan anjing. Dalam perjalanan ke implementasi jaringan saraf convolutional yang mampu mengklasifikasikan gambar kucing dan anjing, kita juga akan belajar bagaimana menggunakan berbagai teknik untuk memecahkan salah satu masalah paling umum dengan jaringan saraf - pelatihan ulang. Dan pada akhir pelajaran ini, pada bagian praktis, Anda akan mengembangkan jaringan saraf convolutional Anda sendiri untuk mengklasifikasikan gambar warna. Ayo mulai!
Dataset Kucing dan Anjing
Sampai saat itu, kami hanya bekerja dengan gambar skala abu-abu dan ukuran 28x28 dari dataset FASHION MNIST.

Dalam aplikasi nyata, kami terpaksa menjumpai gambar dengan berbagai ukuran, misalnya yang ditunjukkan di bawah ini:

Seperti yang kami sebutkan di awal pelajaran ini, dalam pelajaran ini kami akan mengembangkan jaringan saraf convolutional yang dapat mengklasifikasikan gambar warna anjing dan kucing.
Untuk mengimplementasikan rencana kami, kami akan menggunakan gambar kucing dan anjing dari kumpulan data Microsoft Asirra. Setiap gambar dalam set data ini diberi label 1 atau 0 jika masing-masing ada anjing atau kucing.

Terlepas dari kenyataan bahwa dataset Microsoft Asirra berisi lebih dari 3 juta gambar yang ditandai untuk kucing dan anjing, hanya 25.000 yang tersedia untuk umum. Pelatihan jaringan saraf convolutional kami pada 25.000 gambar ini akan memakan banyak waktu. Itulah sebabnya kami akan menggunakan sejumlah kecil gambar untuk melatih jaringan saraf convolutional kami dari 25.000 yang tersedia.
Subset gambar pelatihan kami terdiri dari 2.000 PC dan 1.000 PC gambar untuk validasi model. Dalam dataset pelatihan, 1.000 gambar berisi kucing dan 1.000 gambar lainnya berisi anjing. Kami akan berbicara tentang kumpulan data untuk validasi sedikit kemudian di bagian pelajaran ini.
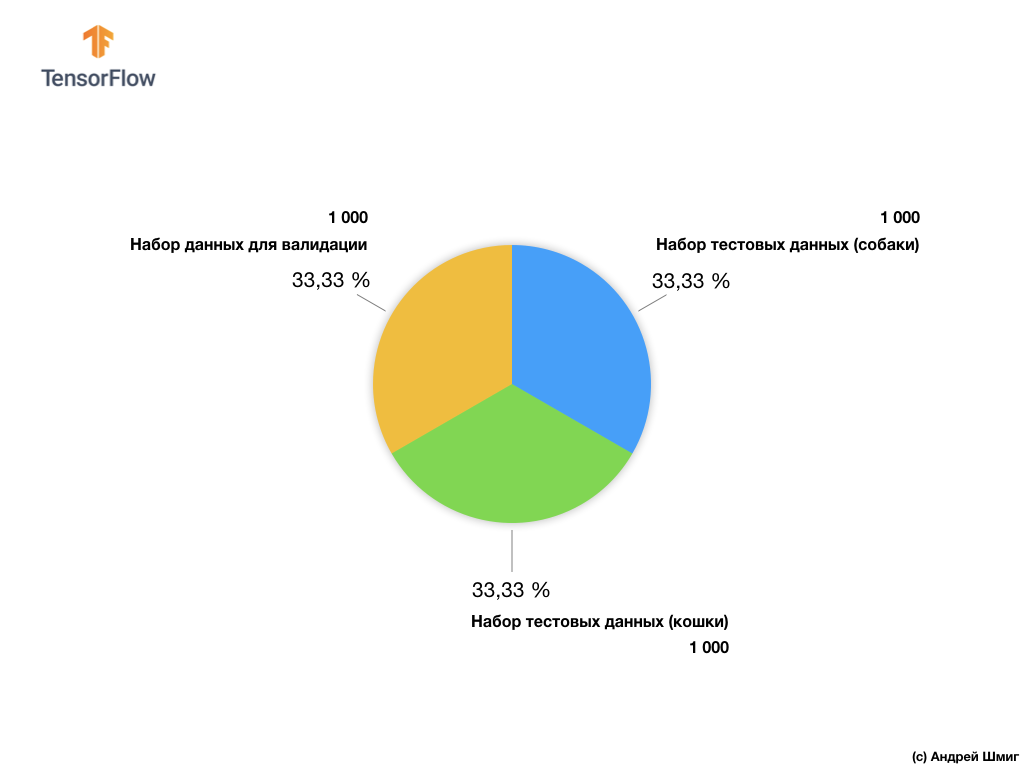
Bekerja dengan kumpulan data ini, kita akan menghadapi dua kesulitan utama - bekerja dengan gambar dengan ukuran berbeda dan bekerja dengan gambar berwarna.
Mari kita mulai mengeksplorasi cara bekerja dengan gambar berbagai ukuran.
Gambar berbagai ukuran
Tes pertama kami adalah menyelesaikan masalah pemrosesan gambar dengan berbagai ukuran. Itu karena jaringan saraf pada input membutuhkan data berukuran tetap.
Sebagai contoh, Anda dapat mengingat dari bagian kami sebelumnya menggunakan parameter input_shape saat membuat layer Flatten :

Sebelum mengirimkan gambar elemen pakaian ke jaringan saraf, kami mengonversinya menjadi array 1D dengan ukuran tetap - 28x28 = 784 elemen (piksel). Karena gambar dalam dataset Fashion MNIST adalah ukuran yang sama, array satu dimensi yang dihasilkan adalah ukuran yang sama dan terdiri dari 784 elemen.
Namun, bekerja dengan gambar berbagai ukuran (tinggi dan lebar) dan mengubahnya menjadi array satu dimensi, kami mendapatkan array dengan ukuran yang berbeda.
Karena jaringan saraf pada input membutuhkan data dengan ukuran yang sama, itu tidak cukup untuk hanya pergi dengan konversi ke array satu dimensi dari nilai piksel.
Memecahkan masalah klasifikasi gambar, kami selalu menggunakan salah satu opsi untuk menyatukan data input - mengurangi ukuran gambar ke nilai umum (mengubah ukuran).
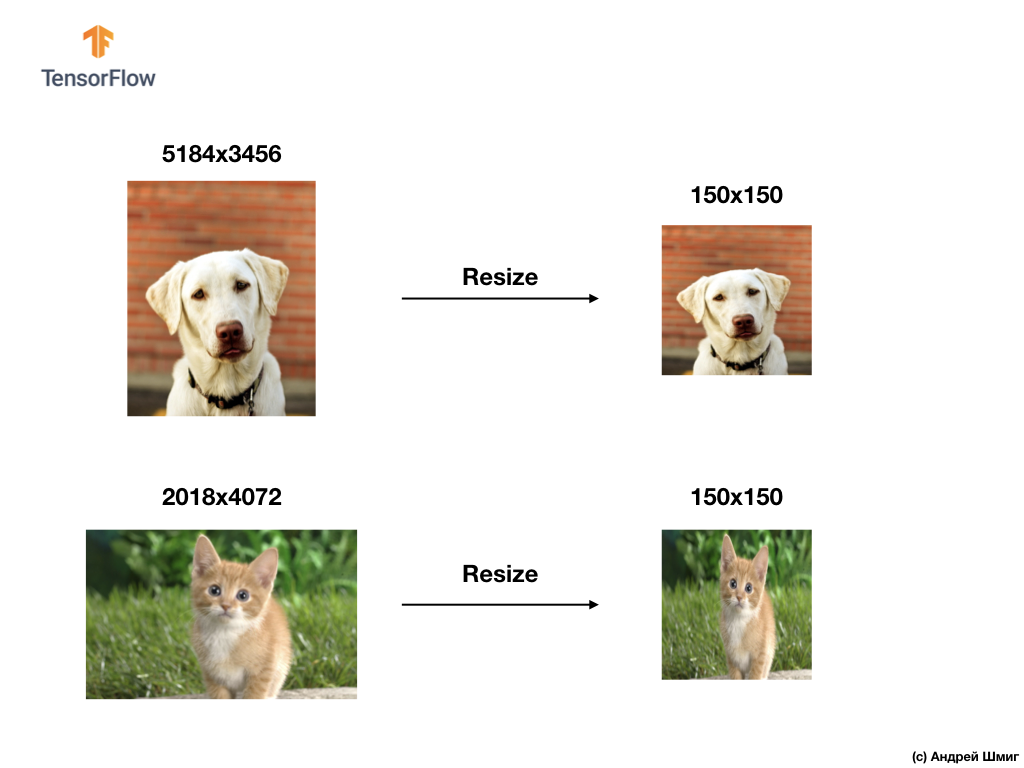
Dalam tutorial ini, kami akan mengubah ukuran semua gambar dengan ukuran tinggi 150 piksel dan lebar 150 piksel. Mengkonversi gambar ke ukuran tunggal, dengan demikian kami menjamin bahwa gambar dengan ukuran yang tepat akan tiba di input jaringan saraf dan, ketika ditransfer ke lapisan flatten , kami mendapatkan array satu dimensi dengan ukuran yang sama.
tf.keras.layers.Flatten(input_shape(150,150,1))
Hasilnya, kami mendapat array satu dimensi yang terdiri dari 150x150 = 22.500 nilai (piksel).
Masalah selanjutnya yang akan kita hadapi adalah masalah warna - warna gambar. Kita akan membicarakannya di bagian selanjutnya.
Gambar berwarna. Bagian 1
Untuk memahami dan memahami bagaimana jaringan saraf konvolusional bekerja dengan gambar berwarna, kita harus mempelajari bagaimana SNA bekerja secara umum. Mari menyegarkan apa yang sudah kita ketahui.
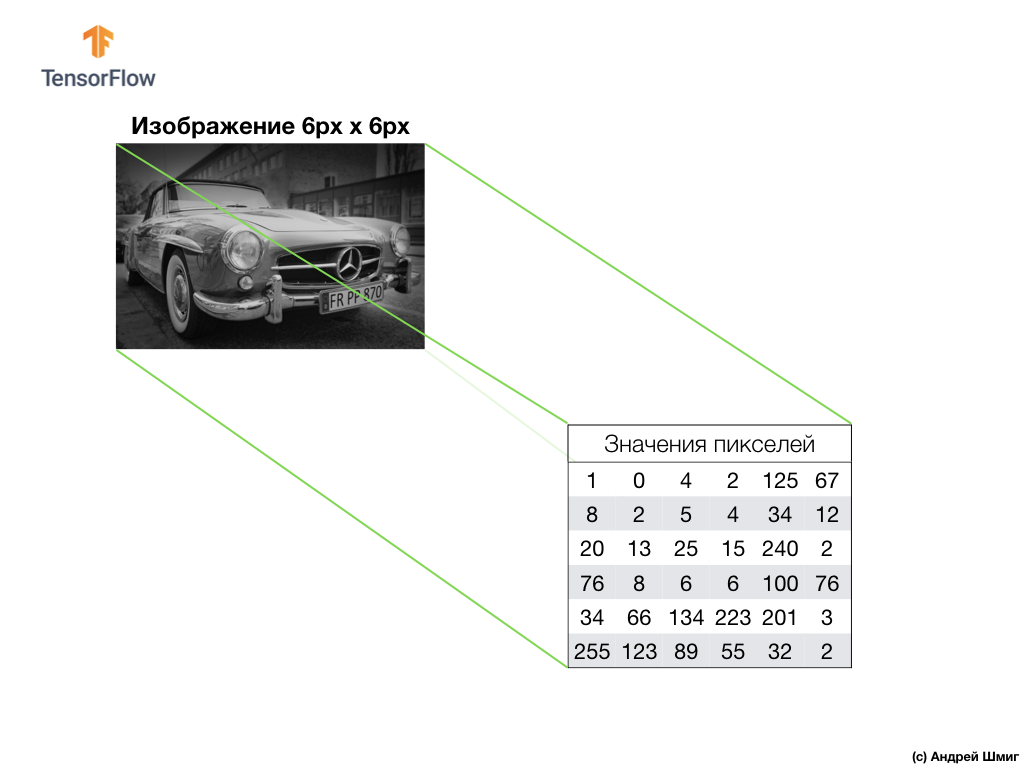
Contoh di atas adalah gambar skala abu-abu dan bagaimana komputer mengartikannya sebagai array dua dimensi dari nilai piksel.
Contoh di bawah ini adalah gambar, kali ini berwarna, dan bagaimana komputer mengartikannya sebagai array nilai piksel tiga dimensi.
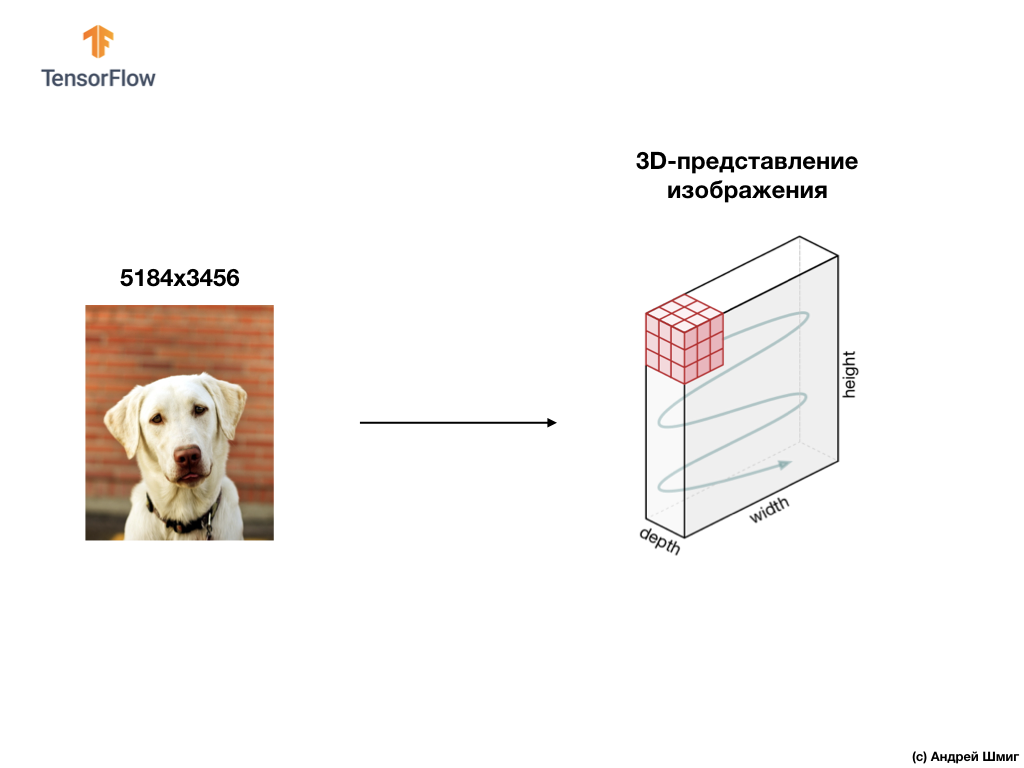
Tinggi dan lebar array 3D akan ditentukan oleh tinggi dan lebar gambar, dan kedalaman (kedalaman) menentukan jumlah saluran warna gambar.
Sebagian besar gambar berwarna dapat direpresentasikan oleh tiga saluran warna - merah (merah), hijau (hijau) dan biru (biru).

Gambar yang terdiri dari saluran merah, hijau, dan biru disebut gambar RGB. Kombinasi dari ketiga saluran ini menghasilkan gambar berwarna. Di masing-masing gambar RGB, setiap saluran diwakili oleh array dua dimensi piksel yang terpisah.
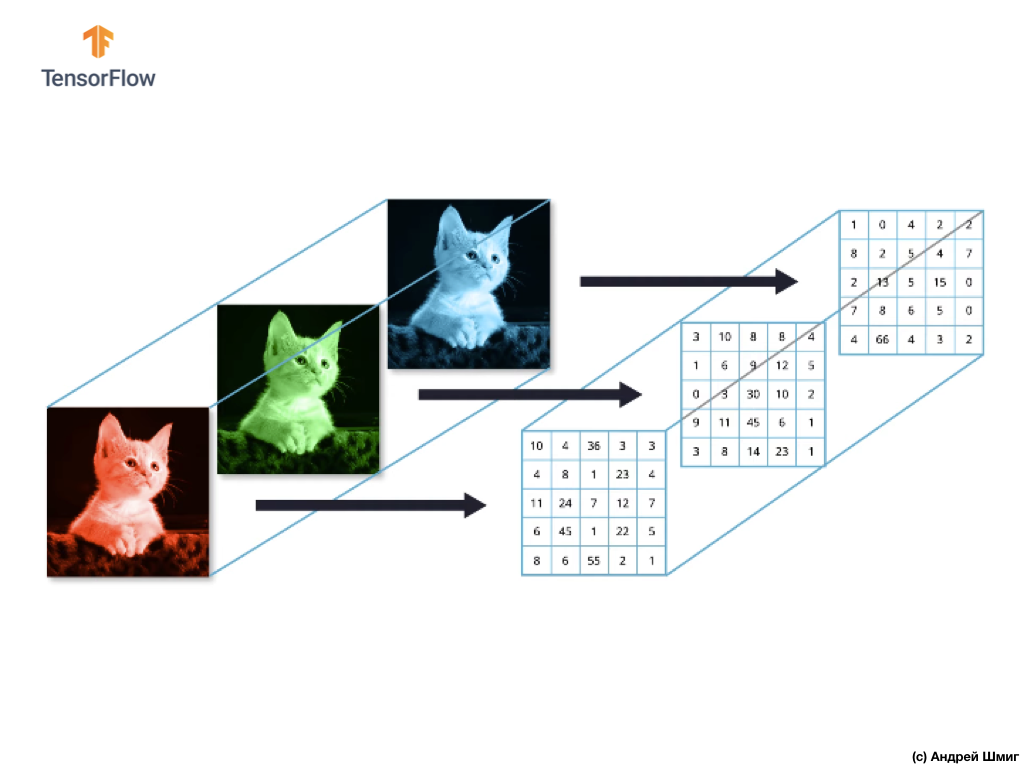
Karena jumlah saluran yang kita miliki adalah tiga, maka sebagai hasilnya kita akan memiliki tiga array dua dimensi. Dengan demikian, gambar berwarna yang terdiri dari 3 saluran warna akan memiliki representasi berikut:

Gambar berwarna. Bagian 2
Jadi, karena gambar kita sekarang akan terdiri dari 3 warna, yang berarti akan menjadi array nilai piksel tiga dimensi, maka kode kita perlu diubah sesuai.
Jika Anda melihat kode yang kami gunakan dalam pelajaran terakhir kami ketika kami memecahkan masalah mengklasifikasikan elemen pakaian dalam gambar, kita dapat melihat bahwa kami menunjukkan dimensi dari data input:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
Dua parameter pertama dari tuple (28,28,1) adalah nilai tinggi dan lebar gambar. Gambar-gambar dalam dataset Fashion MNIST berukuran 28x28 piksel. Parameter terakhir dalam tuple (28,28,1) menunjukkan jumlah saluran warna. Dalam dataset Fashion MNIST, gambar hanya dalam nuansa saluran abu-abu-1 warna.
Sekarang tugasnya menjadi sedikit lebih rumit, dan gambar kucing dan anjing kita menjadi berbeda ukuran (tetapi dikonversi menjadi satu - 150x150 piksel) dan berisi 3 saluran warna, maka tupel nilai juga harus berbeda:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
Pada bagian selanjutnya, kita akan melihat bagaimana konvolusi dihitung dengan adanya tiga saluran warna pada gambar.
Operasi konvolusi pada gambar berwarna
Dalam pelajaran sebelumnya, kami belajar bagaimana melakukan operasi konvolusi pada gambar skala abu-abu. Tetapi bagaimana cara melakukan operasi konvolusi pada gambar berwarna? Mari kita mulai dengan mengulangi bagaimana operasi konvolusi dilakukan pada gambar skala abu-abu.
Semuanya dimulai dengan filter (inti) dengan ukuran tertentu.
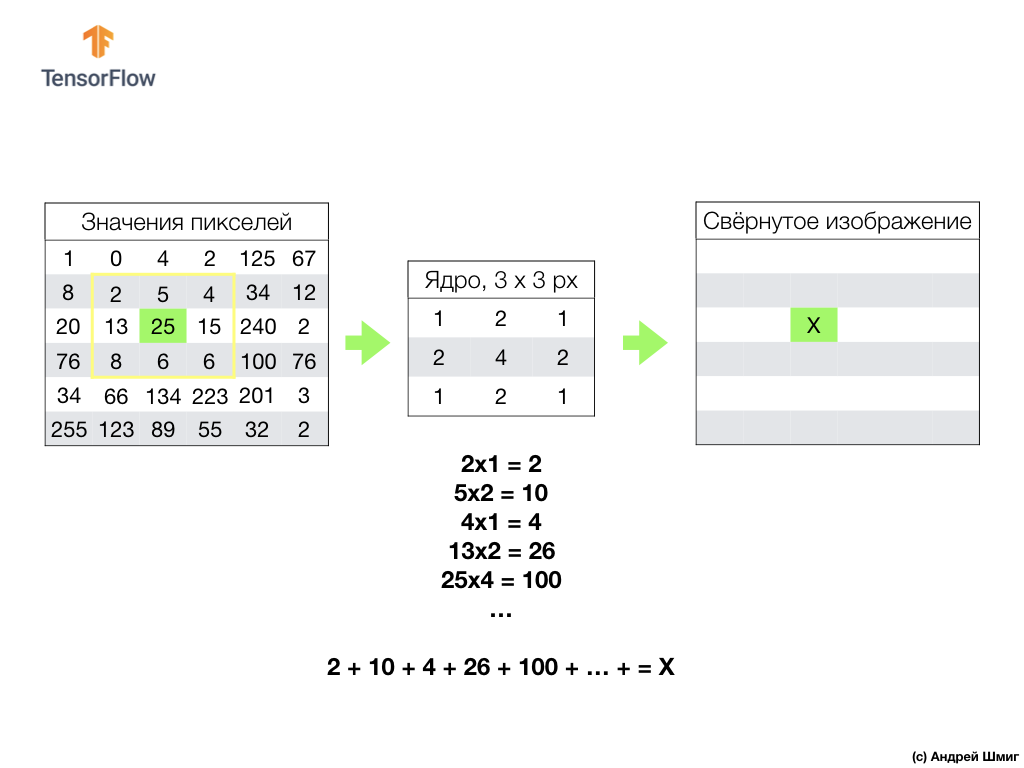
Filter terletak pada piksel gambar tertentu yang akan dikonversi, lalu setiap nilai filter dikalikan dengan nilai piksel yang sesuai dalam gambar dan semua nilai ini dijumlahkan. Nilai piksel akhir diatur pada gambar baru di tempat piksel asli yang dikonversi berada. Operasi ini diulang untuk setiap piksel dari gambar asli.
Perlu juga diingat bahwa selama operasi konvolusi, agar tidak kehilangan informasi di perbatasan gambar, kita dapat menerapkan pelurusan dan menempelkan tepi gambar dengan angka nol:

Sekarang mari kita cari tahu bagaimana kita dapat melakukan operasi konvolusi pada gambar berwarna.
Sama seperti ketika mengonversi gambar dalam nuansa abu-abu, kita mulai dengan memilih ukuran filter (inti) dari ukuran tertentu.

Satu-satunya perbedaan sekarang adalah bahwa sekarang filter itu sendiri akan menjadi tiga dimensi, dan nilai parameter kedalaman akan sama dengan nilai jumlah saluran warna pada gambar - 3 (dalam kasus kami, RGB). Untuk setiap "lapisan" saluran warna, kami juga akan menerapkan operasi konvolusi dengan filter dengan ukuran yang dipilih. Mari kita lihat bagaimana ini akan menjadi contoh.
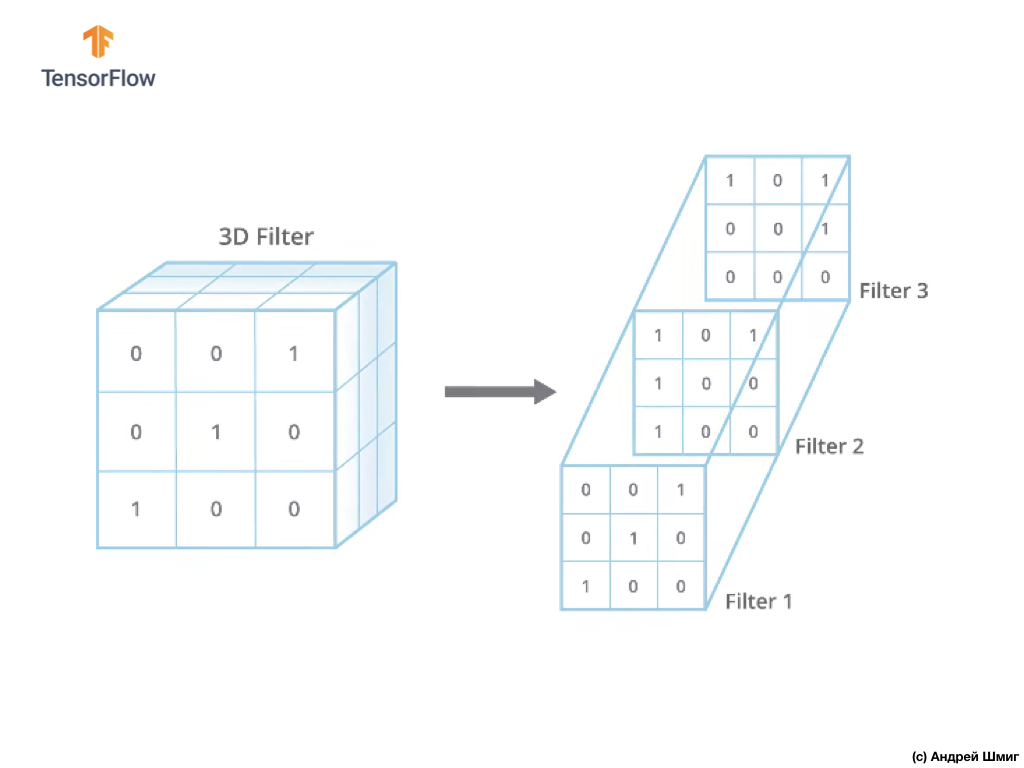
Bayangkan kita memiliki gambar RGB dan kita ingin menerapkan operasi konvolusi dengan filter 3D berikutnya. Perlu memperhatikan fakta bahwa filter kami terdiri dari 3 filter dua dimensi. Untuk kesederhanaan, mari kita bayangkan bahwa gambar RGB kami berukuran 5x5 piksel.

Ingat juga bahwa setiap saluran warna adalah array dua dimensi dari nilai warna piksel.
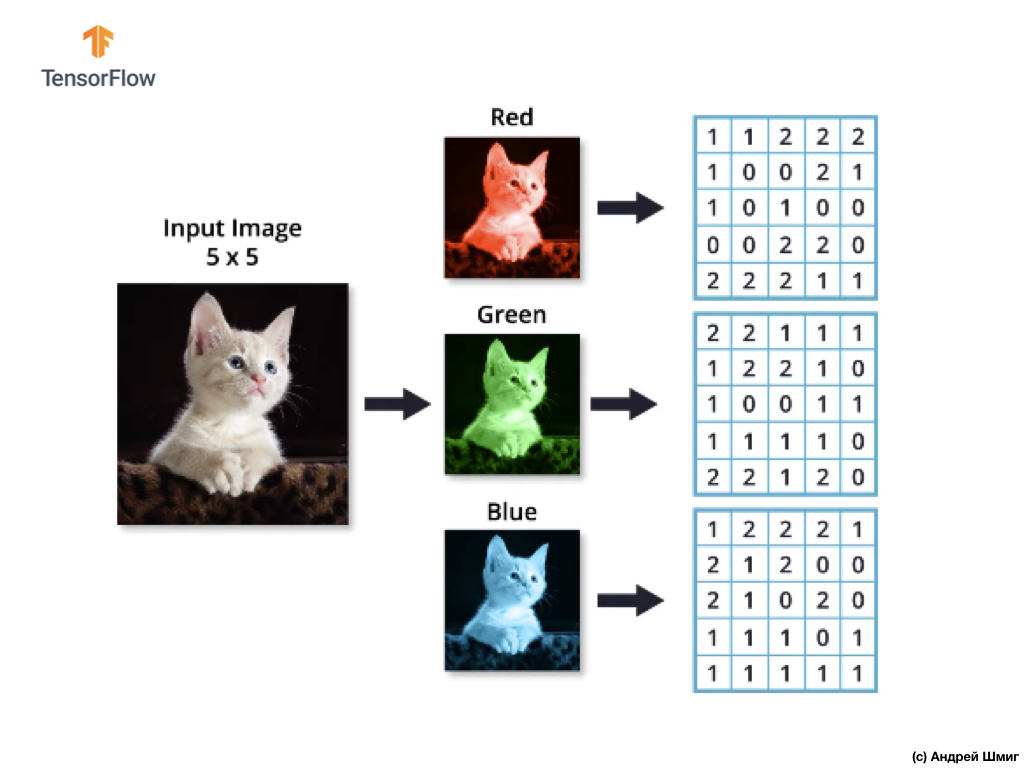
Seperti halnya pengoperasian konvolusi pada gambar dalam nuansa abu-abu, serta dengan gambar berwarna - kami akan melakukan penyelarasan dan melengkapi gambar di tepinya dengan nol untuk mencegah hilangnya informasi di perbatasan.
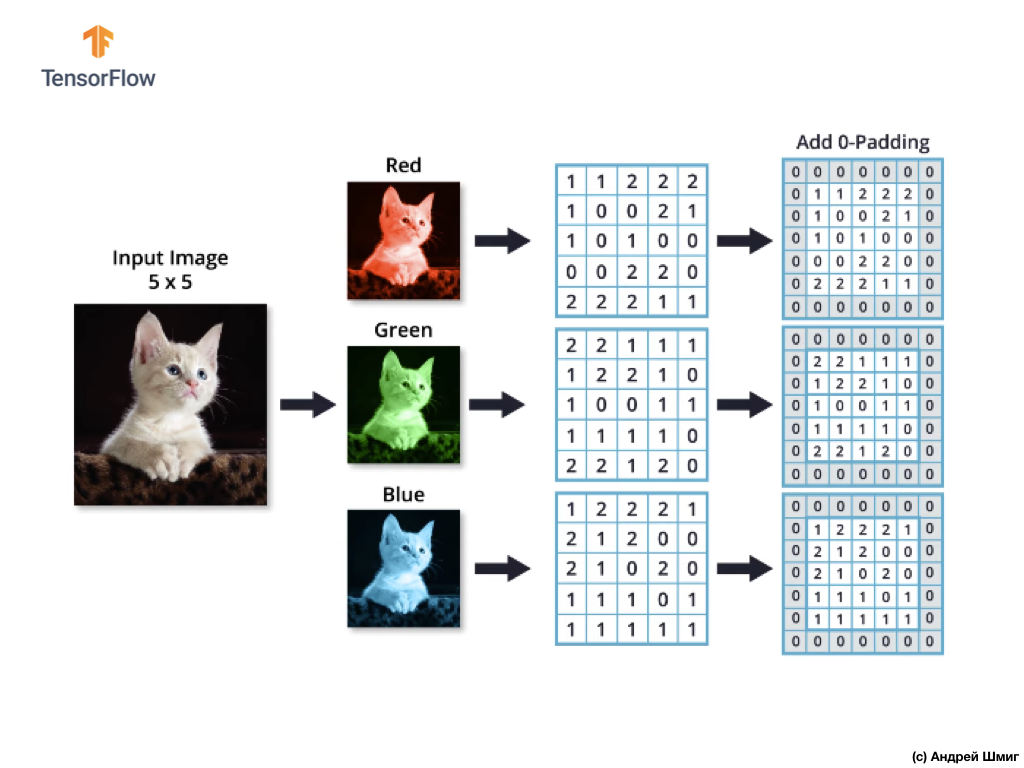
Sekarang kami siap untuk operasi konvolusi!
Mekanisme konvolusi untuk gambar berwarna akan serupa dengan proses yang kami lakukan dengan gambar skala abu-abu. Satu-satunya perbedaan antara operasi yang dilakukan pada gambar skala abu-abu dan warna adalah bahwa operasi konvolusi sekarang perlu dilakukan 3 kali untuk setiap saluran warna.
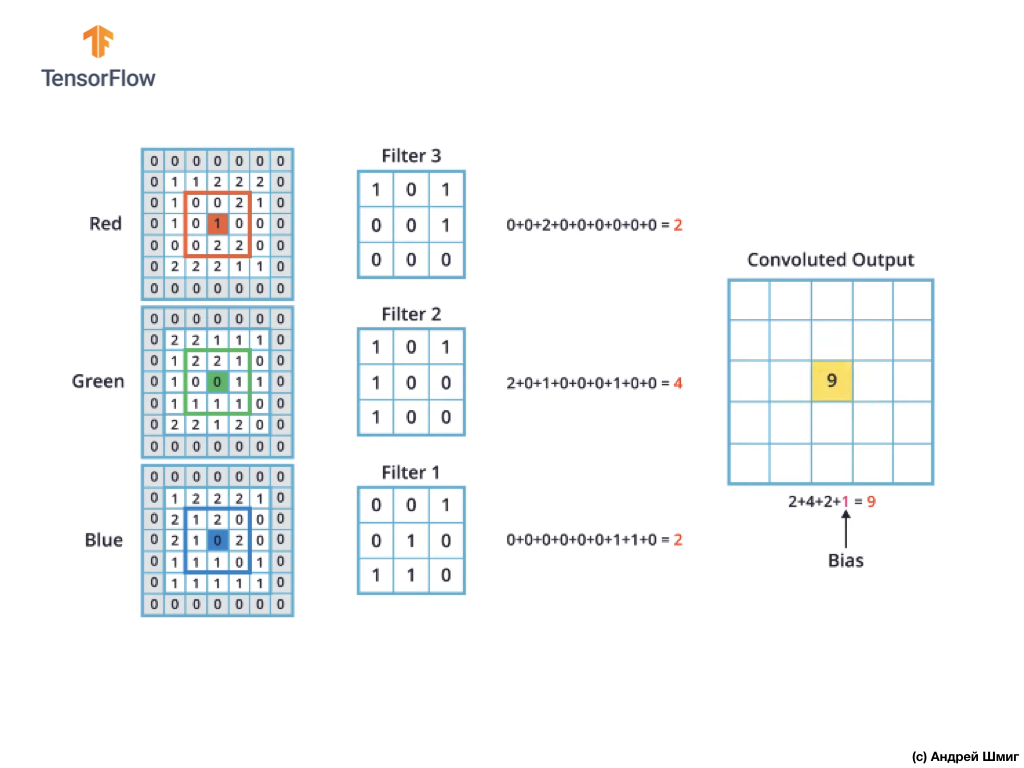
Kemudian, setelah kami melakukan operasi konvolusi pada setiap saluran warna, tambahkan tiga nilai yang diperoleh dan tambahkan 1 ke mereka (nilai standar yang digunakan saat melakukan operasi semacam ini). Nilai baru yang dihasilkan ditetapkan pada posisi yang sama pada gambar baru, di mana posisi piksel yang dikonversi saat itu.
Kami melakukan operasi konversi yang serupa (operasi konvolusi) untuk setiap piksel pada gambar asli kami dan untuk setiap saluran warna.
Dalam contoh khusus ini, gambar yang dihasilkan memiliki ukuran tinggi dan lebar yang sama dengan gambar RGB asli kami.
Seperti yang Anda lihat, menerapkan operasi konvolusi dengan filter 3D tunggal menghasilkan nilai output tunggal.
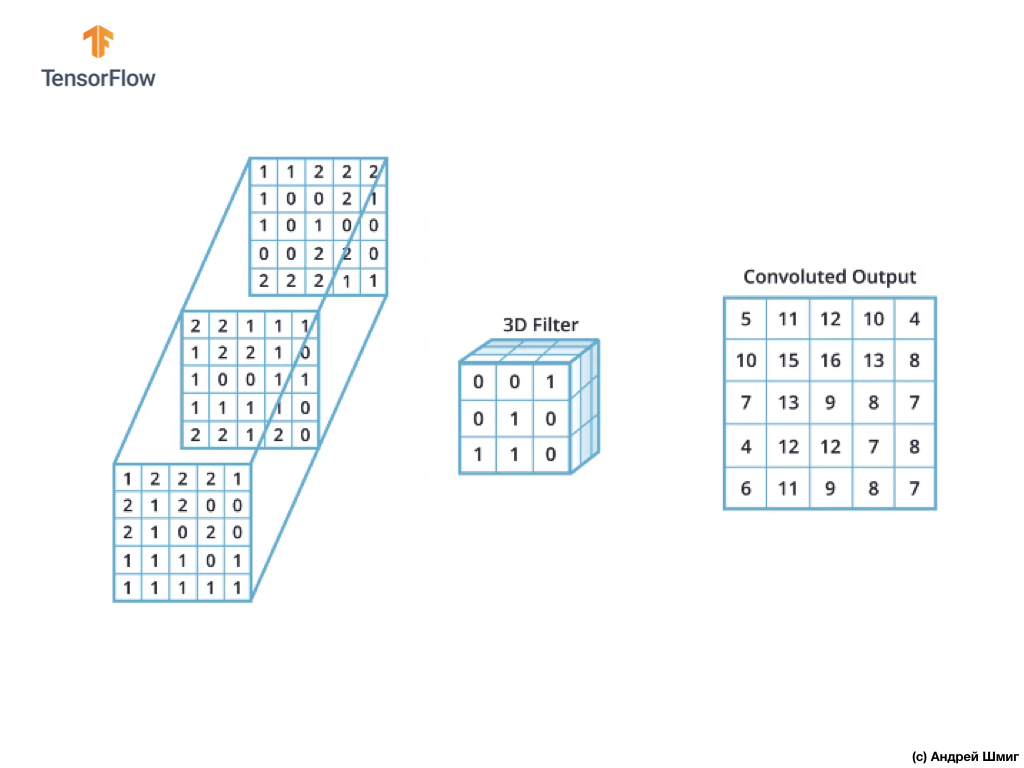
Namun, ketika bekerja dengan jaringan saraf convolutional, adalah praktik umum untuk menggunakan lebih dari satu filter 3D. Jika kami menggunakan lebih dari satu filter 3D, hasilnya akan menjadi beberapa nilai output - setiap nilai adalah hasil dari satu filter.
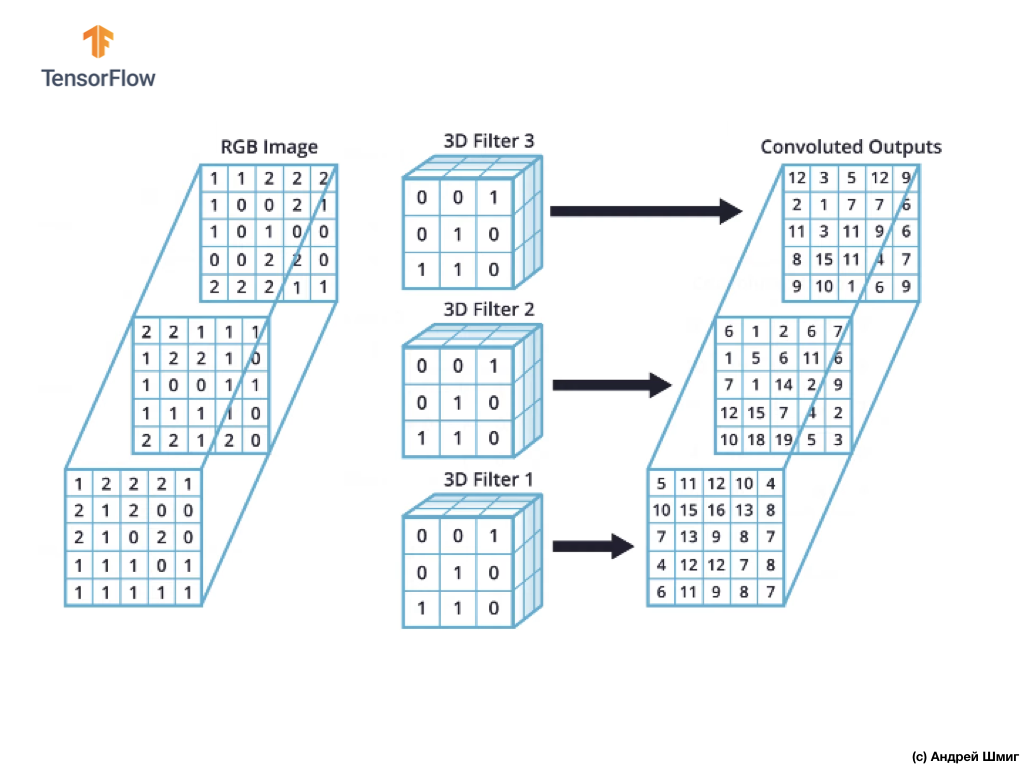
Dalam contoh kami di atas, karena kami menggunakan 3 filter, representasi 3D yang dihasilkan akan memiliki kedalaman 3 - setiap lapisan akan sesuai dengan nilai output dari konversi satu filter di atas gambar dengan semua saluran warnanya.
Jika, misalnya, alih-alih 3 filter, kami memutuskan untuk menggunakan 16, maka representasi 3D output akan berisi 16 lapisan kedalaman.
Dalam kode, kita dapat mengontrol jumlah filter yang dibuat dengan memberikan nilai yang sesuai untuk parameter filters :
tf.keras.layers.Conv2D(filters, kernel_size, ...)
Kami juga dapat menentukan ukuran filter melalui parameter kernel_size . Misalnya, untuk membuat 3 filter ukuran 3x3, seperti yang terjadi pada contoh di atas, kita dapat menulis kode sebagai berikut:
tf.keras.layers.Conv2D(3, (3,3), ...)
Ingatlah bahwa selama pelatihan jaringan saraf convolutional, nilai-nilai dalam filter 3D akan diperbarui untuk meminimalkan nilai fungsi kehilangan.
Sekarang kita tahu bagaimana melakukan operasi konvolusi pada gambar berwarna, sekarang saatnya mencari cara untuk menerapkan operasi subsampling ke hasil maksimum dengan nilai maksimum (penyatuan maks yang sama).
Pengoperasian subsampling dengan nilai maksimum dalam gambar berwarna
Sekarang mari kita belajar bagaimana melakukan operasi subsampling pada nilai maksimum pada gambar berwarna. Bahkan, operasi subsampling dengan nilai maksimum bekerja dengan cara yang sama seperti bekerja dengan gambar dalam nuansa abu-abu dengan sedikit perbedaan - operasi subsampling sekarang perlu diterapkan pada setiap representasi output yang kami terima sebagai hasil dari penerapan filter. Mari kita lihat sebuah contoh.
Untuk kesederhanaan, mari kita bayangkan tampilan output kami terlihat seperti ini:
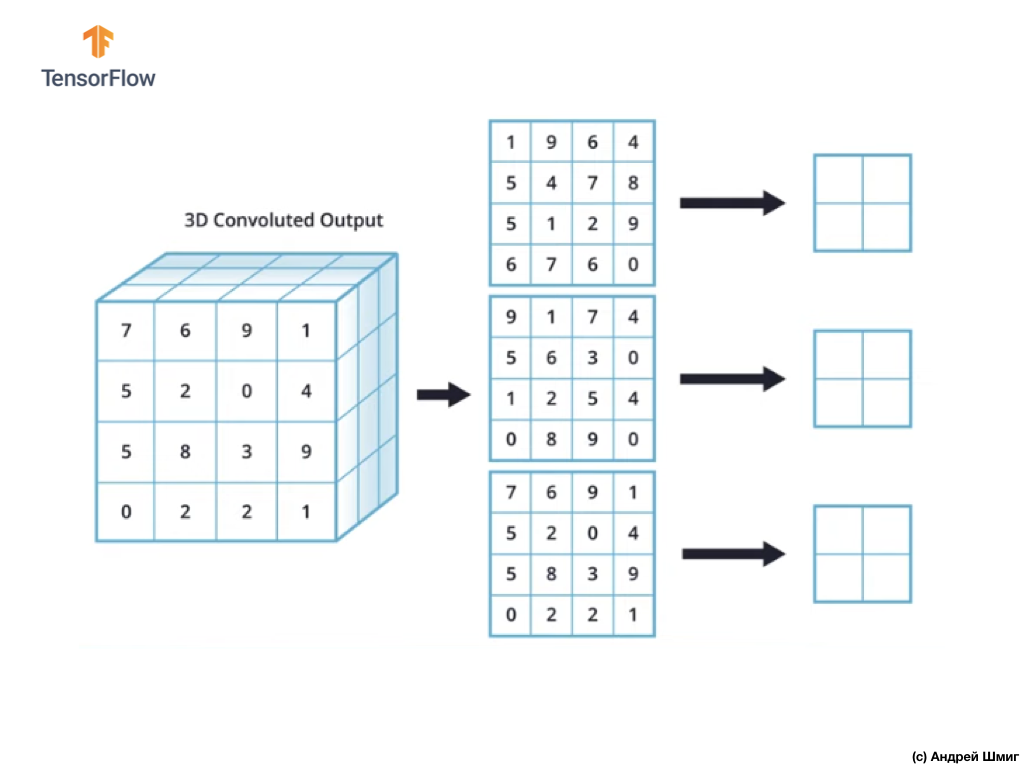
Seperti sebelumnya, kita akan menggunakan kernel 2x2 dan langkah 2 untuk melakukan operasi subsampling pada nilai maksimum. Operasi subsampling dengan nilai maksimum dimulai dengan "instalasi" kernel 2x2 di sudut kiri atas setiap representasi output (representasi yang diperoleh setelah menerapkan operasi konvolusi).

Sekarang kita dapat memulai operasi subsampling dengan nilai maksimum. Sebagai contoh, dalam representasi output pertama kami, nilai-nilai berikut jatuh ke dalam kernel 2x2 - 1, 9, 5, 4. Karena nilai maksimum di kernel ini adalah 9, itu yang dikirim ke representasi output baru. Operasi serupa diulang untuk setiap representasi input.
Sebagai hasilnya, kita harus mendapatkan hasil berikut:

Setelah melakukan operasi subsampling dengan nilai maksimum, hasilnya adalah 3 array dua dimensi, masing-masing 2 kali lebih kecil dari representasi input asli.
Jadi, dalam kasus khusus ini, ketika melakukan operasi subsampling dengan nilai maksimum pada representasi input tiga dimensi, kita mendapatkan representasi output tiga dimensi dari kedalaman yang sama, tetapi dengan nilai tinggi dan lebar setengah dari nilai awal.
Jadi, inilah keseluruhan teori yang kita perlukan untuk penelitian lebih lanjut. Sekarang mari kita lihat bagaimana ini bekerja dalam kode!
CoLab: kucing dan anjing
CoLab asli dalam bahasa Inggris tersedia di tautan ini .
CoLab dalam bahasa Rusia tersedia di tautan ini .
Dalam tutorial ini, kita akan membahas cara mengategorikan gambar kucing dan anjing. Kami akan mengembangkan penggolong gambar menggunakan model tf.keras.Sequential , dan menggunakan tf.keras.Sequential untuk memuat data.
Gagasan yang akan dibahas di bagian ini:
Kami akan mendapatkan pengalaman praktis dalam mengembangkan classifier dan mengembangkan pemahaman intuitif konsep-konsep berikut:
- Membangun model aliran data ( jalur input data ) menggunakan
tf.keras.preprocessing.image.ImageDataGenerator (Bagaimana cara efisien bekerja dengan data pada disk yang berinteraksi dengan model?) - Pelatihan ulang - apa itu dan bagaimana menentukannya?
Sebelum kita mulai ...
Sebelum memulai kode di editor, kami sarankan Anda mengatur ulang semua pengaturan di Runtime -> Reset semua di menu atas. Tindakan semacam itu akan membantu menghindari masalah dengan kekurangan memori, jika Anda bekerja secara paralel atau bekerja dengan beberapa editor.
Paket impor
Mari kita mulai dengan mengimpor paket yang Anda butuhkan:
os - baca file dan struktur direktori;numpy - untuk beberapa operasi matriks di luar TensorFlow;matplotlib.pyplot - merencanakan dan menampilkan gambar dari dataset uji dan validasi.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
Impor TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Pemuatan data
Kami memulai pengembangan classifier kami dengan memuat dataset. Kumpulan data yang kami gunakan adalah versi yang disaring dari kumpulan data Anjing vs Kucing dari layanan Kaggle (pada akhirnya, kumpulan data ini disediakan oleh Microsoft Research).
Di masa lalu, CoLab dan saya menggunakan dataset dari modul TensorFlow Dataset itu sendiri, yang sangat nyaman untuk bekerja dan pengujian. Namun, dalam CoLab ini, kita akan menggunakan kelas tf.keras.preprocessing.image.ImageDataGenerator untuk membaca data dari disk. Oleh karena itu, pertama-tama kita perlu mengunduh kumpulan data Anjing VS Kucing dan unzip.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
Kumpulan data yang kami unduh memiliki struktur berikut:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Untuk mendapatkan daftar direktori lengkap, Anda dapat menggunakan perintah berikut:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
Akibatnya, kami mendapatkan sesuatu yang serupa:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Sekarang tetapkan jalur yang benar ke direktori dengan set data untuk pelatihan dan validasi ke variabel:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Memahami data dan strukturnya
Mari kita lihat berapa banyak gambar kucing dan anjing yang kita miliki dalam kumpulan data pengujian dan validasi (direktori).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
Output dari blok terakhir adalah sebagai berikut:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Pengaturan parameter model
Untuk kenyamanan, kami akan menempatkan pemasangan variabel yang kami butuhkan untuk pemrosesan data lebih lanjut dan pelatihan model dalam pengumuman terpisah:
BATCH_SIZE = 100
Persiapan data
Sebelum gambar dapat digunakan sebagai input untuk jaringan kami, mereka harus dikonversi ke tensor dengan nilai floating point. Daftar langkah yang harus diambil untuk melakukan ini:
- Baca gambar dari disk
- Dekode konten gambar dan konversikan ke format yang diinginkan dengan mempertimbangkan profil RGB
- Konversikan ke tensor dengan nilai floating point
- Untuk menormalkan nilai tensor dari interval dari 0 hingga 255 ke interval dari 0 hingga 1, karena jaringan saraf bekerja lebih baik dengan nilai input yang kecil.
Untungnya, semua operasi ini dapat dilakukan menggunakan kelas tf.keras.preprocessing.image.ImageDataGenerator .
Kita dapat melakukan semua ini menggunakan beberapa baris kode:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
Setelah kami menetapkan generator untuk satu set data pengujian dan validasi, metode flow_from_directory akan memuat gambar dari disk, menormalkan data, dan mengubah ukuran gambar hanya dengan satu baris kode:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Kesimpulan:
Found 2000 images belonging to 2 classes.
Generator data validasi:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Kesimpulan:
Found 1000 images belonging to 2 classes.
Visualisasikan gambar dari set pelatihan.
Kami dapat memvisualisasikan gambar dari dataset pelatihan menggunakan matplotlib :
sample_training_images, _ = next(train_data_gen)
Fungsi next mengembalikan blok gambar dari kumpulan data. Satu blok adalah tupel (banyak gambar, banyak label) . Saat ini, kami akan melepaskan label, karena kami tidak membutuhkannya - kami tertarik dengan gambar itu sendiri.
plotImages(sample_training_images[:5])
Contoh output (2 gambar, bukan semua 5):

Pembuatan model
Kami menggambarkan model
Model ini terdiri dari 4 blok konvolusi, setelah masing-masing terdapat blok dengan lapisan subsampel. Selanjutnya, kami memiliki lapisan yang terhubung penuh dengan 512 neuron dan relu aktivasi relu . Model ini akan memberikan distribusi probabilitas untuk dua kelas - anjing dan kucing - menggunakan softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Kompilasi model
Seperti sebelumnya, kami akan menggunakan pengoptimal adam . Kami menggunakan sparse_categorical_crossentropy sebagai fungsi kerugian. Kami juga ingin memantau akurasi model di setiap iterasi pelatihan, jadi kami meneruskan nilai accuracy ke parameter metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Tampilan model
Mari kita lihat struktur model kita berdasarkan level menggunakan metode ringkasan :
model.summary()
Kesimpulan:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
Kesimpulan:
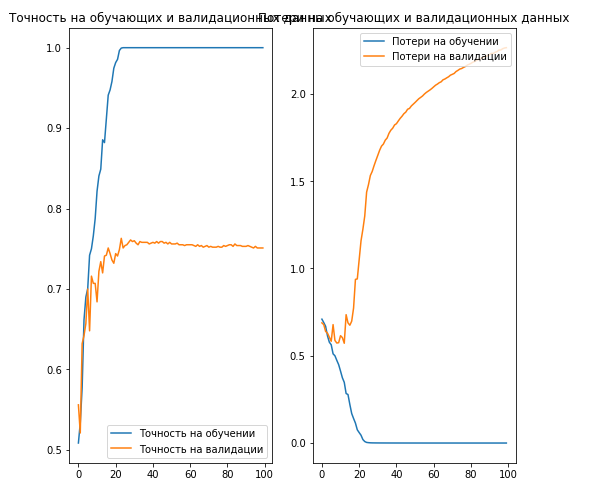
, 70% ( ).
. , .
… .
... dan ajakan bertindak standar - daftar, beri nilai tambah, dan bagikan :)
YouTube
Telegram
VKontakte