
Beberapa waktu yang lalu, kami melakukan pemantauan Agentless dan alarm untuk itu. Ini adalah analog dari CloudWatch di AWS dengan API yang kompatibel. Sekarang kami sedang mengerjakan balancers dan penskalaan otomatis. Tetapi sementara kami tidak menyediakan layanan seperti itu, kami menawarkan pelanggan kami untuk melakukannya sendiri, menggunakan pemantauan dan tag kami (AWS Resource Tagging API) sebagai penemuan layanan sederhana sebagai sumber data. Kami akan menunjukkan cara melakukan ini di posting ini.
Contoh infrastruktur minimal layanan web sederhana: DNS -> 2 balancers -> 2 backend. Infrastruktur ini dapat dianggap sebagai minimum yang diperlukan untuk operasi dan pemeliharaan yang toleran terhadap kesalahan. Karena alasan ini, kami tidak akan “menekan” infrastruktur ini lebih jauh lagi, hanya menyisakan, hanya satu backend. Tetapi saya ingin menambah jumlah server backend dan mengurangi menjadi dua. Ini akan menjadi tugas kita. Semua contoh tersedia di repositori .
Infrastruktur dasar
Kami tidak akan membahas secara terperinci tentang konfigurasi infrastruktur di atas, kami hanya akan menunjukkan cara membuatnya. Kami lebih memilih untuk menggunakan infrastruktur menggunakan Terraform. Ini membantu untuk dengan cepat membuat semua yang Anda butuhkan (VPC, Subnet, Security Group, VMs) dan ulangi prosedur ini berulang-ulang.
Skrip untuk meningkatkan infrastruktur dasar:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
Semua entitas yang dijelaskan dalam konfigurasi ini, tampaknya, harus dipahami oleh pengguna rata-rata cloud modern. Variabel khusus untuk cloud kami dan untuk tugas tertentu dipindahkan ke file terpisah - terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
Luncurkan Terraform:
terraform berlaku yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
Pengaturan pemantauan
VM yang diluncurkan di atas secara otomatis dimonitor oleh cloud kami. Data pemantauan ini akan menjadi sumber informasi untuk autoscaling di masa depan. Mengandalkan metrik tertentu kita dapat menambah atau mengurangi daya.
Pemantauan di cloud kami memungkinkan Anda untuk mengonfigurasi alarm sesuai dengan kondisi yang berbeda untuk metrik yang berbeda. Sangat nyaman. Kami tidak perlu menganalisis metrik pada interval apa pun dan membuat keputusan - ini akan dilakukan dengan pemantauan cloud. Dalam contoh ini, kami akan menggunakan alarm untuk metrik CPU, tetapi dalam pemantauan kami mereka juga dapat dikonfigurasi untuk metrik seperti: pemanfaatan jaringan (kecepatan / pps), pemanfaatan disk (kecepatan / iops).
cloudwatch put-metric-alarm export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
Deskripsi beberapa parameter yang mungkin tidak dapat dipahami:
--profile - profil pengaturan aws-cli, dijelaskan dalam ~ / .aws / config. Biasanya, kunci akses yang berbeda diatur dalam profil yang berbeda.
--dimensions - parameter menentukan sumber daya alarm yang akan dibuat, dalam contoh di atas - untuk instance dengan pengenal dari variabel $ instance_id.
--namespace - namespace dari mana metrik pemantauan akan dipilih.
--metric-name - nama metrik pemantauan.
--statistic - nama metode agregasi nilai metrik.
- Periode - interval waktu antara pemantauan acara pengumpulan nilai.
--evaluasi-periode - jumlah interval yang diperlukan untuk memicu alarm.
--threshold - nilai ambang metrik untuk menilai status alarm.
--comparison-operator - metode yang digunakan untuk mengevaluasi nilai metrik terhadap nilai ambang batas.
Dalam contoh di atas, dua alarm dibuat untuk setiap instance backend. Scaling-low- <instance-id> akan masuk ke status Alarm saat CPU memuat kurang dari 15% selama 3 menit. Scaling-high- <instance-id> akan masuk ke status Alarm saat CPU memuat lebih dari 80% selama 3 menit.
Kustomisasi tag
Setelah mengatur pemantauan, kami dihadapkan dengan tugas pencarian contoh berikut dan nama mereka (penemuan layanan). Kita perlu entah bagaimana memahami berapa banyak contoh backend yang telah kita luncurkan sekarang, dan kita juga perlu tahu nama mereka. Dalam dunia di luar cloud, misalnya, template konsul dan konsul akan sangat cocok untuk menghasilkan konfigurasi balancer. Tetapi ada tag di cloud kami. Tag akan membantu kami mengelompokkan sumber daya. Dengan meminta informasi untuk tag tertentu (tag-uraikan), kita dapat memahami berapa banyak contoh yang saat ini kita miliki di kumpulan dan id apa yang mereka miliki. Secara default, id instance unik digunakan sebagai nama host. Berkat DNS internal yang bekerja di dalam VPC, id / nama host ini menyelesaikan ke instance ip internal.
Kami menetapkan tag untuk instance dan penyeimbang backend:
EC2 membuat-tag export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
Dimana:
--resources - daftar pengidentifikasi sumber daya untuk tag mana yang akan ditetapkan.
--tags adalah daftar pasangan kunci-nilai.
Contoh-tag yang dijelaskan tersedia dalam dokumentasi CROC Cloud.
Pengaturan penskalaan otomatis
Sekarang setelah cloud memantau, dan kami dapat bekerja dengan tag, kami hanya dapat mensurvei status alarm yang dikonfigurasi untuk pemicunya. Di sini kita membutuhkan entitas yang akan terlibat dalam pemantauan pemantauan berkala dan meluncurkan tugas untuk membuat / menghapus instance. Berbagai alat otomasi dapat diterapkan di sini. Kami akan menggunakan AWX. AWX adalah versi open-source Menara Ansible komersial, produk untuk mengelola infrastruktur Ansible secara terpusat. Tugas utama adalah untuk meluncurkan buku pedoman yang memungkinkan secara berkala.
Contoh penyebaran AWX tersedia di halaman wiki di repositori resmi. Konfigurasi AWX juga dijelaskan dalam dokumentasi Ansible Tower. Agar AWX mulai menjalankan buku pedoman khusus, Anda harus mengonfigurasinya dengan membuat entitas berikut:
- Bukti tiga jenis:
- Kredensial AWS - untuk mengesahkan operasi yang terkait dengan CROC Cloud.
- Kredensial mesin - kunci ssh untuk mengakses mesin virtual yang baru dibuat.
- Kredensial SCM - untuk otorisasi dalam sistem kontrol versi. - Project adalah entitas yang akan mendorong repositori git dari playbook.
- Skrip - skrip inventaris dinamis untuk memungkinkan.
- Inventory adalah entitas yang akan memanggil skrip inventaris dinamis sebelum meluncurkan playbook.
- Templat - konfigurasi panggilan buku pedoman tertentu, terdiri dari sekumpulan Kredensial, Inventaris, dan buku pedoman dari Project.
- Alur kerja - urutan panggilan ke buku pedoman.
Proses penskalaan dapat dibagi menjadi dua bagian:
- scale_up - buat instance ketika setidaknya satu alarm tinggi dipicu;
- scale_down - penghentian instance jika alarm rendah bekerja untuknya.
Dalam lingkup bagian scale_up, Anda perlu:
- Menginterogasi layanan pemantauan cloud tentang keberadaan alarm tinggi dalam keadaan "Alarm";
- hentikan scale_up lebih cepat dari jadwal jika semua alarm tinggi dalam kondisi "OK";
- buat instance baru dengan atribut yang diperlukan (tag, subnet, security_group, dll.);
- buat alarm tinggi dan rendah untuk instance yang sedang berjalan;
- konfigurasikan aplikasi kita di dalam instance baru (dalam kasus kami hanya akan nginx dengan halaman pengujian);
- perbarui konfigurasi haproxy, buat ulang agar permintaan mulai masuk ke instance baru.
buat-instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
Di create-instance.yaml, yang terjadi adalah: membuat instance dengan parameter yang benar, memberi tag instance ini dan membuat alarm yang diperlukan. Instalasi nginx dan skrip konfigurasi juga diteruskan ke data pengguna. Data pengguna diproses oleh layanan cloud-init, yang memungkinkan konfigurasi yang fleksibel dari instance selama startup tanpa menggunakan alat otomatisasi lainnya.
Dalam pembaruan-lb.yaml, file /etc/haproxy/haproxy.cfg dibuat ulang pada instance haproxy dan layanan haproxy reload:
perbarui-lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
Di mana haproxy.cfg.j2 adalah templat file konfigurasi layanan haproxy:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
Karena opsi httpchk ditentukan di bagian haproxy backend, layanan haproxy akan secara otomatis menyurvei keadaan instance backend dan hanya menyeimbangkan lalu lintas antara pemeriksaan kesehatan sebelumnya.
Pada bagian scale_down yang Anda butuhkan:
- periksa status alarm rendah;
- mengakhiri permainan sebelum waktunya jika tidak ada alarm rendah dalam kondisi "Alarm";
- hentikan semua kejadian yang alarmnya rendah di kelas Alarm;
- melarang terminasi dari pasangan instance terakhir, bahkan jika alarmnya dalam kondisi Alarm;
- hapus instance yang kami hapus dari konfigurasi load balancer.
hancurkan-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
Di destroy-instance.yaml, alarm dihapus, instance dan tag-nya diakhiri, dan kondisi yang melarang penghentian instance terbaru diperiksa.
Kami secara eksplisit menghapus tag setelah menghapus instance karena fakta bahwa setelah menghapus instance, tag yang terkait dengannya dihapus ditunda dan tersedia untuk beberapa menit lagi.
AWX
Pengaturan tugas, template
Serangkaian tugas berikut akan membuat entitas yang diperlukan di AWX:
awx-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
Cuplikan sebelumnya akan membuat templat untuk masing-masing buku pedoman yang mungkin digunakan. Setiap templat mengonfigurasi peluncuran buku pedoman dengan serangkaian kredensial dan inventaris yang ditentukan.
Untuk membangun pipa untuk panggilan ke buku pedoman akan memungkinkan templat alur kerja. Menyiapkan alur kerja untuk autoscaling disajikan di bawah ini:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
Templat sebelumnya menunjukkan diagram alur kerja, mis. urutan eksekusi template. Dalam alur kerja ini, setiap langkah berikutnya (success_nodes) akan dilakukan hanya jika yang sebelumnya berhasil diselesaikan. Representasi grafis dari alur kerja ditunjukkan pada gambar:
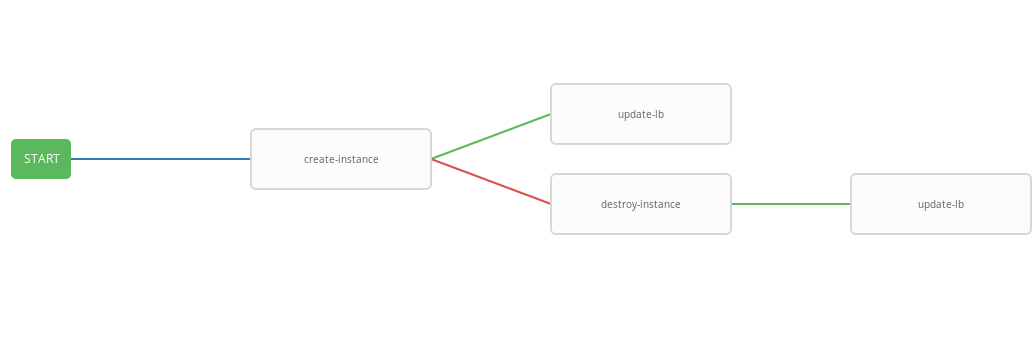
Sebagai hasilnya, alur kerja umum dibuat yang mengeksekusi playbook create-instace dan, tergantung pada status eksekusi, destroy-instance dan / atau update-lb playbooks. Alur kerja terintegrasi nyaman untuk dijalankan pada jadwal yang diberikan. Proses penskalaan otomatis akan dimulai setiap tiga menit, meluncurkan dan menghentikan instance tergantung pada kondisi alarm.
Tes kerja
Sekarang periksa operasi sistem yang dikonfigurasi. Pertama, instal utilitas wrk untuk pembandingan http.
wrk instal ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
Kami akan menggunakan pemantauan cloud untuk memantau penggunaan sumber daya instan saat memuat:
pemantauan function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
Skrip sebelumnya sekali setiap 60 detik mengambil informasi tentang nilai rata-rata metrik CPUUtilization untuk menit terakhir dan polling status alarm untuk contoh backend.
Sekarang Anda dapat menjalankan wrk dan melihat pemanfaatan sumber daya dari instance backend yang dimuat:
wrk run ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
Perintah terakhir akan meluncurkan benchmark selama 500 detik, menggunakan 12 utas dan membuka 100 koneksi http.
Seiring waktu, skrip pemantauan harus menunjukkan bahwa selama benchmark, nilai statistik metrik CPUisasi meningkat hingga mencapai 300%. 180 detik setelah dimulainya patokan, bendera StateValue harus beralih ke status Alarm. Setiap dua menit, alur kerja autoscaling dimulai. Secara default, eksekusi paralel dari alur kerja yang sama dilarang. Artinya, setiap dua menit, tugas untuk mengeksekusi alur kerja akan ditambahkan ke antrian dan akan diluncurkan hanya setelah yang sebelumnya selesai. Jadi, selama pekerjaan wrk, akan ada peningkatan sumber daya yang konstan sampai alarm tinggi dari semua instance backend masuk ke kondisi OK. Setelah selesai, alur kerja scale_down wrk mengakhiri semua kecuali dua instance backend.
Contoh output dari skrip pemantauan:
hasil pemantauan # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
Juga di Cloud CROC, Anda dapat melihat grafik yang digunakan dalam pos pemantauan di halaman instance pada tab yang sesuai.
Lihat alarm tersedia di halaman pemantauan pada tab alarm.
Kesimpulan
Autoscaling adalah skenario yang cukup populer, tetapi, sayangnya, ini belum ada di cloud kami (tetapi hanya untuk saat ini). Namun, kami memiliki banyak API yang kuat untuk melakukan hal serupa dan banyak hal lainnya, menggunakan alat yang populer, hampir standar, seperti Terraform, ansible, aws-cli dan lainnya.