Teman-teman, selamat sore!
Kami melanjutkan serangkaian publikasi "tanpa potongan" tentang proyek yang terkait dengan pengembangan, seringkali dengan awalan "web". Mari kita bicara hari ini tentang stress test. Masalahnya adalah bahwa seringkali klien maupun manajer proyek tidak memahami mengapa diperlukan, risiko apa yang dapat dikurangi, bagaimana mengaturnya dan bagaimana, dan ini, saya pikir, sulit, untuk menginterpretasikan hasil-hasilnya untuk kepentingan bisnis. Kami menuangkan kopi dan mari kita pergi ...
Mengapa memuat pengujian proyek web?
Faktanya adalah bahwa sementara autostests masih ditulis dalam beberapa proyek web untuk menjaga kualitas, beberapa orang terlibat dalam pengendalian kinerja pada tahap pengembangan. Sangat jarang melihat proyek web dengan autotests dan tolok ukur kode. Lebih sering dan untuk alasan yang masuk akal, heuristik berikut dipatuhi selama pengembangan, yang memiliki rasio manfaat-biaya yang baik:
- pertanyaan ke MySQL (kami akan menggunakan database populer ini sebagai contoh) melalui API yang cukup memadai yang menggunakan indeks (meskipun kami tidak melihat bagaimana tepatnya indeks digunakan oleh penjadwal, apa kardinalitas mereka)
- hasil mengeksekusi query database dan potongan kode yang berat di-cache
- pengembang 3,14 kali memeriksa pembangunan halaman web di browser dan jika itu tidak memperlambat mata, maka semuanya OK
Heuristik sering bekerja dengan baik, tetapi semakin besar dan lebih berat proyek, sesuatu
mungkin salah dengan kemungkinan yang meningkat secara eksponensial.
Ambil caching. Saat berkembang, seringkali tidak ada waktu untuk memikirkan seberapa sering cache dapat dibangun kembali. Namun sia-sia. Jika membangun kembali cache, katakanlah, katalog produk, membutuhkan waktu lama dan cache diatur ulang ketika satu produk ditambahkan, maka cache akan lebih berbahaya daripada manfaatnya.
Karena itu, omong-omong, tidak disarankan untuk menggunakan cache kueri MySQL bawaan, yang mengalami masalah serupa: jika Anda mengubah setidaknya satu catatan tabel, cache tabel sepenuhnya diatur ulang (bayangkan tabel 100k garis dan absurditas situasi menjadi jelas).
Situasi serupa dengan permintaan MySQL. Jika kueri dieksekusi oleh indeks, maka, secara umum, kueri akan dieksekusi ... "lebih cepat." Anda dapat percaya bahwa waktu eksekusi dari pertanyaan seperti itu tergantung secara logaritma pada jumlah data (O (log (n))). Tetapi dalam praktiknya sering ternyata beberapa permintaan mempengaruhi yang lain, menggunakan pada saat yang sama subsistem umum dari basis data (mengurutkan pada disk yang mulai melambat) dan Anda tidak dapat langsung memprediksi ini.
Juga, sering selama memuat, fitur menarik dari sistem operasi terungkap, khususnya, meluapnya rentang port TCP / IP klien keluar selama pekerjaan intensif dengan memcached. Atau apache akan tersumbat dengan permintaan untuk pemrosesan gambar, karena selama konfigurasi, mereka lupa mengkonfigurasi pemrosesan mereka oleh server proxy nginx caching.
Kadang-kadang mereka lupa menginstal di MySQL jalur untuk tabel sementara ke disk yang memetakan data ke RAM ("/ dev / shm"), karena itu, ketika beban meningkat, server database meletakkan dari penyortiran intensif.
Juga, ketika data ditambahkan ke proyek web, dalam volume yang dekat dengan pertempuran, pertanyaan dan algoritma mulai secara agresif menampilkan "notasi-O" mereka: jika kartesius tidak terlihat untuk sejumlah kecil data, maka ketika volume pertempuran muncul, server database menjadi merah karena tegangan.
Ada banyak contoh lagi, mari kita bahas ini sekarang. Hal utama yang perlu dipahami adalah bahwa pengujian beban diperlukan. Karena itu sangat mahal, sangat lama dan tidak praktis secara ekonomis untuk meramalkan semua opsi yang memungkinkan untuk "mengerem" sistem web berukuran sedang sebelumnya.
Bagaimana cara mengidentifikasi target pengujian stres?
Di sini penting untuk memahami apa yang sebenarnya menunjukkan kepada Anda dan klien tingkat kualitas sistem web selama pengujian stres. Tidak ada yang lebih baik dari contoh konkret target pengujian stres, baik dan buruk:
- Membuat 1 juta hit. Waktu pembuatan laman web rata-rata = 1 detik. Apa yang ditunjukkan oleh ini? Tidak ada Berapa lama pengujian muat berlangsung? Waktu pelaksanaan satu permintaan dapat berupa 1 ms atau 600 detik, dan tidak jelas proporsi mana yang lebih besar. Dan berapa banyak kesalahan yang ada (respons nginx dengan gaya "Kesalahan 50x") juga tidak jelas :-)
- Membuat 1 juta hit. Rata-rata waktu pembuatan halaman web = 1 detik, jumlah kesalahan HTTP adalah 0,5% Apa yang ditampilkan? Sejauh ini, sedikit bermanfaat, tetapi lebih baik. Bagian kesalahan yang tidak memadai yang dapat ditangkap klien, kami sudah tahu bahwa itu hebat dan Anda dapat mulai mempersiapkan dan pergi ke apotek. Median adalah metrik yang lebih tahan terhadap "outlier" daripada rata-rata (lebih "kuat" perkiraan), oleh karena itu, tidak diragukan lagi lebih baik daripada rata-rata aritmatika. Tapi mari kita buat metrik lebih berguna.
- 1 juta hit dilakukan per hari. 25% hit dibuat dalam waktu kurang dari 10 ms, 50% hit dibuat dalam waktu kurang dari 1 detik (ini median atau 50 persentil), 75% hit dibuat dalam waktu kurang dari 1,5 detik, 95% hit dibuat dalam waktu kurang dari 1 detik 5 detik dan jumlah kesalahan HTTP adalah 0,5% Itu saja! Kami melihat proporsi kesalahan tidak memadai yang dapat ditangkap klien, tetapi kami juga melihat proporsi permintaan yang melebihi batas tertentu.
Seperti yang Anda lihat, pilihan metrik yang memadai untuk menilai kecepatan proyek web selama pengujian beban sangat, sangat penting. Hanya ada satu prinsip - metrik harus benar-benar jelas bagi klien dan Anda dan untuk menunjukkan kualitas dengan baik dan jelas. Bahkan, metrik yang paling jelas dan benar adalah distribusi kecepatan pemrosesan hit dari waktu ke waktu. Jika Anda berhasil melakukan ini pada pengujian stres Anda - itu akan menjadi super. Selain itu, Anda dapat membandingkan 2 tes stres dengan sifat distribusi klik waktu dan melihat bagaimana itu menjadi lebih baik dan di mana. Visualisasi adalah kekuatan!
Tidak ada yang jelas: persentil, median, kuantil, konsep, distribusi ...
Semuanya sederhana! Sekarang saya akan menggambar dan menunjukkan di lingkungan yang indah untuk analisis data: Jupyter notebook / Python.
Katakanlah 10 hit dibuat ke situs web dengan waktu dalam milidetik:
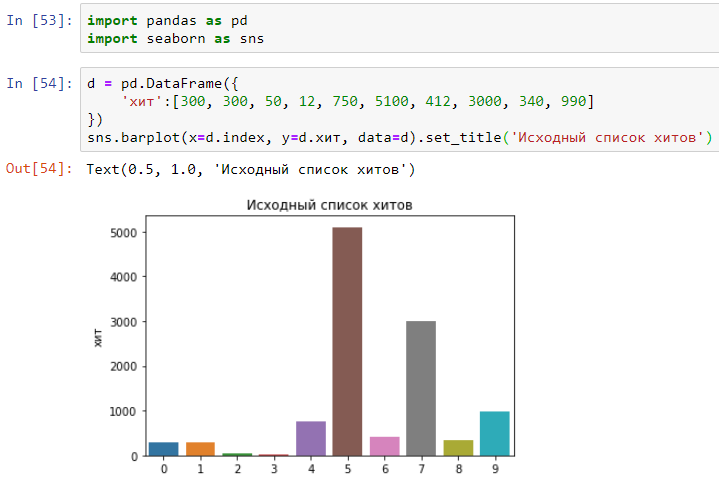
Sekarang sortir waktu yang diperlukan untuk menyelesaikan hit dalam urutan menaik:

Kami satu langkah lagi dari memahami median, 25 dan 75 persen. Semuanya sederhana - kita membagi bagan menjadi dua dan di tengah akan ada "median" (nomor 1 pada tabel). Kuartal pertama grafik akan sesuai dengan persentil ke-25 (nomor 2 pada grafik) dan kuartal ketiga akan sesuai dengan persentil ke-75 (nomor 3 pada grafik). Dengan demikian, persentil lain diperoleh (atau, sebagaimana mereka juga disebut, kuantil) - 90, 95, 99, dll .:
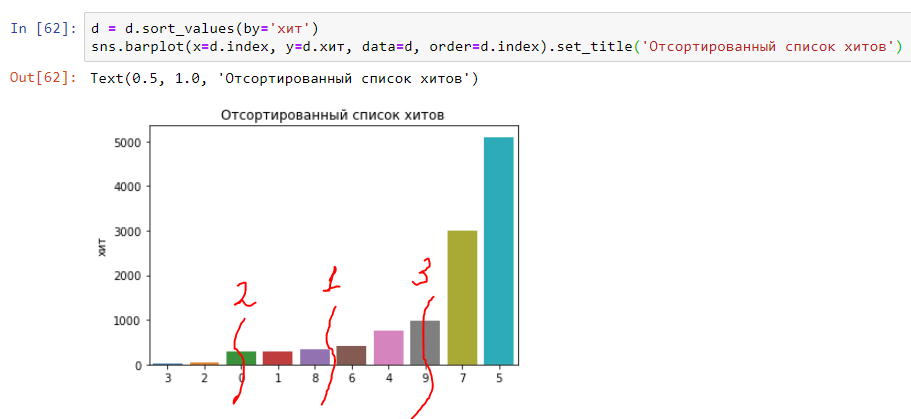
Dan itu akan terlihat seperti distribusi (histogram) selama waktu pelaksanaan hit di atas. Seperti yang Anda lihat, semuanya sangat jelas dan sederhana:
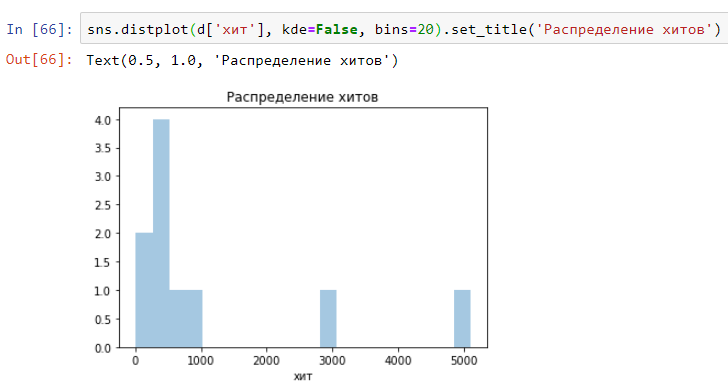
Dan ini adalah bagaimana Anda dapat dengan cepat membangun distribusi (histogram) berdasarkan log permintaan pengujian beban. Ubah ke format log Anda:
Dan Anda mendapatkan sesuatu seperti ini:

Saya harap sekarang semuanya menjadi jelas dan siap. Jika tidak, tanyakan di komentar.
Waktu pengujian stres
Orang-orang sering bertanya - berapa lama seharusnya tes beban suatu proyek web berlangsung? Ada heuristik sederhana - dalam sistem operasi sering tugas terjadwal dilakukan sekali sehari: cadangan, rotasi log, dll., Oleh karena itu, waktu untuk melakukan pengujian beban seharusnya tidak kurang, dengan benar, berhari-hari. Jika proyek web didasarkan pada Bitrix, maka platform juga memiliki banyak tugas yang dijadwalkan dan disarankan untuk memuat sistem web setidaknya selama sehari.
Load balancing
Jika Anda sudah memiliki situs web yang dioperasikan, maka Anda dapat, ya, mengambil log kunjungan dari sana dan memuat sistem web baru dengan menggunakannya. Namun seringkali mereka memecahkan masalah hanya memuat sistem web yang dikembangkan. Untuk perencanaan penyeimbangan muatan, model pembagian rantai kunjungan kunjungan yang prospektif menjadi saham seringkali cocok. Sebagai contoh:
- Beranda - Berita - Berita detail = 50%
- Beranda - Tinjauan Umum Katalog - Katalog Lengkap = 30%
- Katalog Lengkap - Tinjauan Katalog - Katalog Lengkap = 15%
- Hasil Pencarian - Katalog Lengkap = 5%
Dalam perangkat lunak untuk membuat beban (kita sering menggunakan Jmeter), begitu banyak aliran beban dibuat untuk setiap rantai sehingga, dengan mempertimbangkan interval antara hit dalam rantai, jumlah total hit dari setiap rantai per unit waktu dikorelasikan sebagai: 50%, 30%, 15%, 5% .
Penghitungan interval dan aliran muatan mudah dilakukan di Excel atau di atas lembaran dengan pensil.
Struktur rantai beban
Penting untuk mempertimbangkan fitur-fitur dari siklus hidup pengguna sistem web. Seringkali pengguna masuk dan kemudian pergi ke situs web. Untuk melakukan ini, Anda perlu menempatkan tindakan yang mengarah ke otorisasi di awal rantai muat:
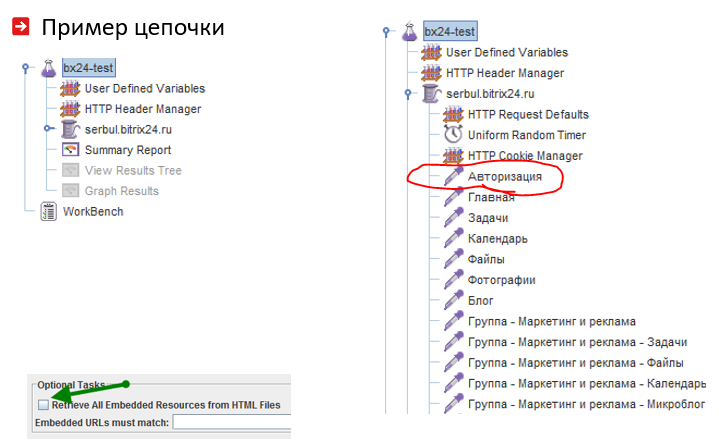
Jelas bagi kuda bahwa tidak mungkin untuk menarik hanya satu halaman rinci dari katalog selama pengujian stres, oleh karena itu berguna untuk membaca dan memutar daftar mereka dari file CSV:

Di antara hit, tentu saja, Anda perlu membuat jeda acak - jadi kami lebih dekat dengan beban yang dibuat oleh pengguna nyata. Jangan lupa tentang menyimpan dan mengembalikan nilai cookie ke server:

Variabel global rantai beban, termasuk jumlah utasnya, mudah dikonfigurasi. Variabel global tertentu kemudian dapat digunakan di berbagai tempat dalam rantai beban:


Bagaimana cara membuat stress testing berakhir dengan aman?
Dalam prakteknya, hampir selalu, pengujian beban pada menit atau jam pertama crash sistem web, semuanya mulai merokok, kemudian terbakar, situs tidak terbuka, MySQL jatuh ke swap dan tidak membiarkan dirinya terhubung, LA pada server mendekati 100, pengembang mulai menjalankan dengan kata-kata "ini seharusnya tidak terjadi", dan sysadmin dengan seringai biasanya menjawab "ada keadilan dalam hidup!" dan mulai minum bir di ruang server.
Tetapi untuk memahami mengapa semuanya telah jatuh dan apa yang harus diperbaiki, untuk menunjukkan kepada klien hasil dari pengujian beban “berhasil” dalam sehari, Anda harus terlebih dahulu mengaktifkan pencatatan metrik utama dari kehidupan sistem operasi - ini mudah dilakukan dalam produk munun / kaktus gratis.
Saya akan mencantumkan apa yang paling sering terjadi pada saat runtuhnya sistem web dan bagaimana hal ini dapat diperbaiki.
Pertama-tama, server web apache atau php-fpm "tersumbat" dengan permintaan:

Paling sering hal ini terjadi karena runtuhnya MySQL - jumlah aliran permintaan menggantung meningkat:

Apa alasannya? Seringkali dari atas mereka lupa membatasi jumlah apache atau aliran permintaan ke MySQL, yang menyebabkan aplikasi keluar dari RAM menjadi swap lambat dengan kejang:
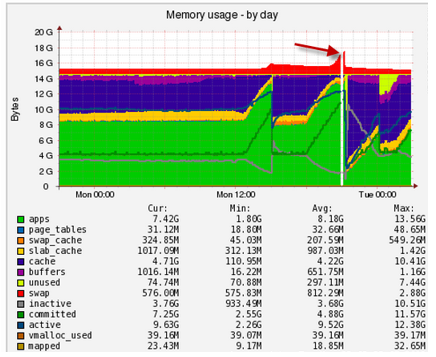
Di sini Anda dapat melihat aktivitas mendadak saat bekerja dengan swap, Anda perlu memahami siapa yang termasuk dalam swap dan di mana:
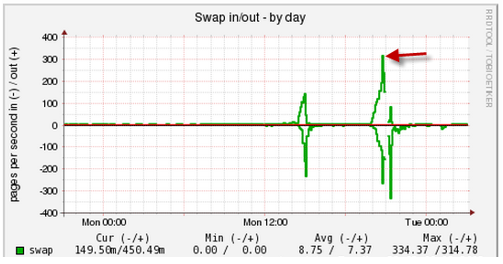
Namun, terkadang masalahnya ada di sisi subsistem hard disk. Dalam kasus ini, LA naik tajam dan persentase pemanfaatan disk mendekati 100 (grafik kanan bawah):


Jelas, saya mengungkapkan hanya sebagian dari hal paling menarik yang dapat dimulai dengan proyek web selama pengujian stres. Tetapi yang utama adalah mengatur arah yang benar dan membangun proses yang benar. Tanyakan di komentar apa yang muncul selama pemuatan, saya akan mencoba membantu.
Interpretasi hasil stress test
Biasanya, setelah 5-10 restart dan penyesuaian, pengujian beban memulai penerbangannya dan berhasil menyelesaikannya. Akibatnya, Anda harus memiliki satu set kira-kira log ini untuk analisis lebih lanjut:
- log permintaan ke nginx dengan waktu permintaan klien (dalam hal ini akan memuat perangkat lunak), waktu proksi dari nginx ke apache / php-fpm
- log kesalahan nginx
- log permintaan apache / php-fpm dengan waktu pemrosesan permintaan dan status respons HTTP
- log kesalahan apache / php-fpm
- MySQL Slow Log
- Log kesalahan MySQL
Selain itu, harus ada grafik analitik selama beberapa hari terakhir tentang penggunaan CPU, disk, MySQL, RAM, pekerja apache, dll. (lihat contoh grafik munin di atas).
Memiliki artefak ini, Anda dapat, menggunakan skrip awk sederhana di awal posting, membangun distribusi (histogram) di atas log ini dan menghitung jumlah dan jenis kesalahan HTTP. Bahkan, Anda dapat menghasilkan laporan tentang keberhasilan stress testing tentang konten ini yang sangat luas dan berguna untuk bisnis dan pengambilan keputusan:
Siang hari membuat 1 juta hit. 25% hit dibuat dalam waktu kurang dari 50 ms, 50% hit dibuat dalam waktu kurang dari 0,5 detik (median), 75% hit dibuat dalam waktu kurang dari 1 detik, 95% hit dibuat dalam waktu kurang dari 5 detik, jumlah kesalahan HTTP - 0,01%. Data uji: katalog, pengguna, berita, artikel kebanjiran dalam volume mendekati yang diharapkan. Satu pengembang menembak dirinya sendiri.
Rantai beban:
Beranda - Berita - Berita detail = 50%
Beranda - Tinjauan Umum Katalog - Katalog Lengkap = 30%
Katalog Lengkap - Tinjauan Katalog - Katalog Lengkap = 15%
Hasil Pencarian - Katalog Lengkap = 5%
Grafik Penggunaan Sumber Daya Server:
...
Ini adalah laporan yang bagus dan dapat dimengerti tentang pengujian beban sistem web. Untuk pecinta nyeri akut, Anda masih dapat merekomendasikan selama pengujian beban untuk memasukkan setiap menit impor-ekspor data ke situs web dari sistem kelas SAP, 1C, dll. dan koneksi sinkron melalui soket TCP / IP dengan layanan pertukaran eksternal, katakanlah, cryptocurrency :-)
Tapi, jujur saja, jika ekspor-impor dilakukan dengan hati-hati dan jujur, maka pengujian beban dan dalam kondisi seperti itu akan menunjukkan angka yang dapat diterima untuk bisnis.
Dari mana datangnya stress testing?
Ngomong-ngomong, ya, kami tidak menyoroti momen ini. Untuk alasan sepele, kurangnya keseimbangan antara pekerja nginx - apache - mysql biasanya muncul. Yaitu pekerja tidak terbatas dari atas, sebagai akibatnya, 500 pekerja (masing-masing kadang-kadang masing-masing 100 MB) dapat segera naik di apache dan 500 utas dengan permintaan akan segera datang ke MySQL - yang akan menyebabkan lonjakan kesalahan HTTP 50x dan kemungkinan keruntuhan.
Di sini, disarankan untuk membatasi jumlah pekerja apache / php-fpm hingga jumlah yang sesuai dengan RAM dan, juga, membatasi jumlah utas di MySQL untuk melindungi terhadap melimpahnya RAM yang tersedia. Idenya sederhana - biarkan klien menunggu di depan nginx, itu dapat memperlambat sedikit pada soket TCP / IP asynchronous dan non-blocking, yang "putus" segera di apache / MySQL.
Dari alasan yang lebih menjengkelkan, mungkin ada segfault PHP. Dalam hal ini, Anda perlu mengaktifkan pengumpulan coredump dan menggunakan gdb untuk melihat mengapa hal ini terjadi. Dalam kebanyakan kasus, masalah dapat diatasi dengan memperbarui / mengkonfigurasi PHP.
Yang tertinggal di balik layar
Ada desas-desus yang terus-menerus bahwa frontend modern untuk web telah begitu aktif menjalani kehidupannya sehingga pengujian beban klasik backend yang disajikan dalam posting ini tidak lagi mencakup semua risiko yang mungkin terjadi pada pembekuan konstruksi halaman web dalam nyali Angular / React / Vue.js - karena itu
jangan gunakan ujung depan yang berat dan buram, tidak teruji, Anda dapat, jika perlu, menyesuaikan rantai beban dengan situasi ini.
Bagaimanapun, jika hasil stress testing backend menunjukkan angka yang baik, dan situs web terus melambat di peramban, sudah jelas siapa yang "memukul wajah merah kurang ajar" :-)
Serius, di posting selanjutnya kami berharap dapat membahas topik penting ini.
Ringkasan dan Kesimpulan
Total - tidak ada yang rumit dalam mengatur dan melakukan pengujian beban sistem web yang berguna untuk pengembangan dan bisnis.
Pengujian beban, terorganisir dengan baik, harus selalu dilakukan - jika tidak, ada risiko mengalami masalah besar selama operasi pertempuran, yang tidak dapat dihilangkan dalam beberapa hari.
Untuk melakukan stress testing, penting untuk menarik tidak hanya pengembang, tetapi juga para ahli sistem operasi dan administrator sistem yang berpengalaman dengan perangkat keras, dan kemudian masalah "jatuh ke swap" atau "meluap jangkauan lokal alamat IP" tidak akan menyebabkan pendarahan dari mata dan pingsan.
Selamat mencoba teman-teman dan ajukan pertanyaan di komentar!