Hai Nama saya Vitaliy Kostousov, saya bekerja di tim Global Tech Heroes, dan hari ini saya akan memberi tahu Anda tentang dukungan - salah satu komponen terpenting dari layanan apa pun. Anda dapat membuat aplikasi yang bagus dengan gambar-gambar keren dan terkadang obrolan bot bercanda. Anda dapat secara terbuka membuang, pada awalnya menawarkan pelanggan layanan murah. Anda dapat menyewa SMM-box yang bagus untuk siapa Anda tidak akan malu dan yang tidak perlu diubah sesering akuntan di tahun 90-an.
Tetapi semua ini dapat tersandung dengan baik tanpa adanya dukungan waras untuk layanan Anda. Dan dukungan dalam arti global - mulai dari memecahkan masalah pengguna hingga memastikan fungsionalitas perangkat lunak dan perangkat keras. Ya ampun, berapa lama orang akan menggunakan aplikasi yang bodoh selama beberapa minggu, tetapi pengembang masih belum menanggapi masalah secara normal, layanan dukungan tidak berlangganan dengan jawaban robot, dan dapatkah Anda mendengarkan musik klasik secara gratis di call center?

Seperti yang telah kita atur semuanya, apa yang kita gunakan dalam pekerjaan kita untuk mendeteksi masalah dan menyelesaikannya, berapa banyak dari kita dan segala sesuatu yang ada di bawah jalan pintas.
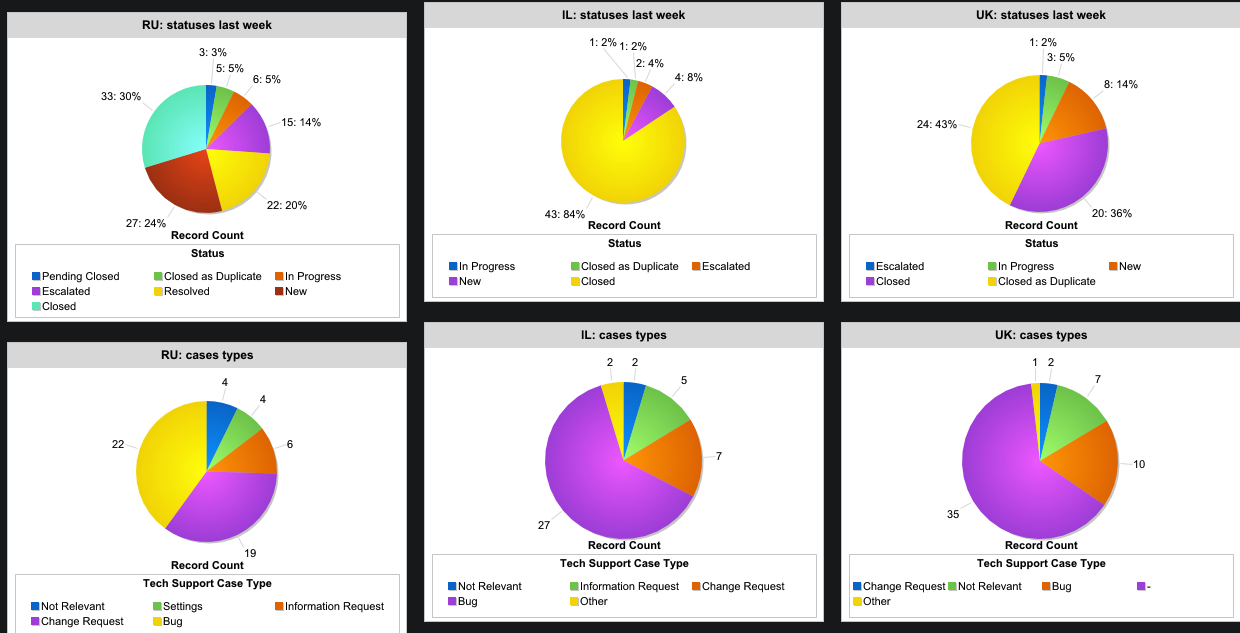
Sekarang kami bekerja di 3 negara: Rusia, Inggris dan Israel, dan kami memiliki ratusan ribu pengguna aktif, pelanggan korporat saja lebih dari 20.000.Ada cukup banyak permintaan harian untuk aplikasi kami. Dan ada driver dan permintaan dari mereka. Dan juga sistem dan pemantauan internal. Semua ini harus bekerja, dan bekerja dengan baik. Untuk melakukan ini, kami memiliki tim dukungan teknis global yang disebut di dalam “Pahlawan Teknologi” - tim R&D, operator eskalasi dan insinyur, serta Manajer Insiden Global. Dan inilah yang mereka hadapi dalam pekerjaan mereka.
Tim dan pengguna
Segera buat reservasi bahwa pengguna akhir dari tim kami tidak hanya berarti pelanggan dan pengemudi yang berada dalam prioritas (baik swasta maupun perusahaan), tetapi juga pemasaran, layanan dukungan, dan departemen internal kami. Tentu saja, mereka menulis untuk mendukung penggunaan aplikasi, atau di jejaring sosial. Jika masalahnya bersifat teknis, maka tugas di dalam SalesForce segera mendatangi kami. Mereka dapat menulis tidak hanya tentang aplikasi dan kualitas pekerjaannya secara keseluruhan atau beberapa fungsi pada khususnya, tetapi juga tentang kinerja layanan internal perusahaan. Ada lebih dari 1000 karyawan Gett yang mengajukan pertanyaan tentang perangkat lunak yang berfungsi, proses organisasi.
Tim kami terdiri dari 8 orang yang didistribusikan di tiga negara - Israel, Inggris Raya dan Rusia. Seorang spesialis dari Rusia bekerja dari jarak jauh, tanggung jawabnya meliputi bekerja dengan proses operasional: memantau dan membuat perubahan pada layanan utama kami. Tujuh sisanya terlibat dalam masalah operasional, dan banyak lainnya: pengujian, bug, spesifikasi, cepat menyelesaikan panggilan yang datang dari spesialis dan manajer operasional, dan juga memantau semua database, layanan, dan layanan mikro kami. Tim ini memproses semua tiket, dari negara mana pun mereka tiba. Untuk sebagian besar, Anda harus bekerja dengan masalah-masalah lokal, tetapi kebetulan ada beberapa bug serius dalam pekerjaan layanan global, kemudian pekerjaan masuk ke mode Global.
Anda juga perlu mempertimbangkan bahwa kami memiliki banyak klien b2b di seluruh dunia - sistem ini memiliki pengaturan yang sangat fleksibel dan kemungkinan integrasi bisnis dengan layanan perusahaan. Artinya, ada lebih banyak kelas mobil daripada yang dilihat pengguna layanan pribadi. Penting untuk dipahami bahwa semua ini mempengaruhi pengoperasian layanan dan jumlah operasi transaksional. Segmen B2B dapat menggunakan akun pribadi di situs web perusahaan.
Perangkat lunak
Ada beberapa sistem untuk bekerja dengan tiket di pasar yang telah membuktikan kegunaannya: LiveAgent, ZenDesk, ZohoDesk, dan lainnya. Anda dapat memilih sesuai kenyamanan, Anda dapat keluar dari kebiasaan, Anda dapat - mulai dari jenis perangkat lunak yang bekerja sama dengan rekan Anda, agar tidak memblokir sekelompok lapisan dan kruk (yang juga harus didukung dan diselesaikan). Oleh karena itu, kami bekerja untuk SalesForce, karena digunakan oleh area operasional utama perusahaan (penjualan dan dukungan). Ini memungkinkan Anda untuk melacak status setiap kasing dari sisi pembuatnya. Ada prioritas otomatis kasus berdasarkan topik banding. SalesForce juga terintegrasi di Jira, dan jika tugas dibuat atau bug diperkenalkan ke pengembangan, statusnya juga ditampilkan dalam kasus ini. Inilah cara kami mencapai komunikasi yang transparan antara Dukungan dan Pengembangan.
 Salesforce, dapat diklik
Salesforce, dapat diklikSistem aplikasi khusus memungkinkan Anda untuk melacak SLA untuk setiap tiket yang datang kepada kami.
Tiket dan permintaan
Secara khusus, tim kami terlibat dalam pekerjaan aplikasi itu sendiri (untuk pengemudi dan penumpang), layanan mikro yang bekerja dengan spesialis operasional, serta pengujian dan pemantauan. Selain itu, selalu ada permintaan untuk laporan dan pemantauan baru, yang mungkin berguna bagi kolega dari departemen lain. Pada saat yang sama, beberapa pemantauan hanya untuk tim kami, jika mereka berhubungan secara eksklusif dengan parameter teknis dari layanan dan basis data. Bagian dari pemantauan mengirimkan peringatan kepada kami, tim yang bertanggung jawab dan dukungan. Jika masalah terhubung, misalnya, dengan aplikasi pengemudi, dukungan akan merespons lebih cepat dan memberi tahu pengemudi jika perlu. Dengan demikian, waktu informasi dikurangi menjadi beberapa menit.
Pemantauan
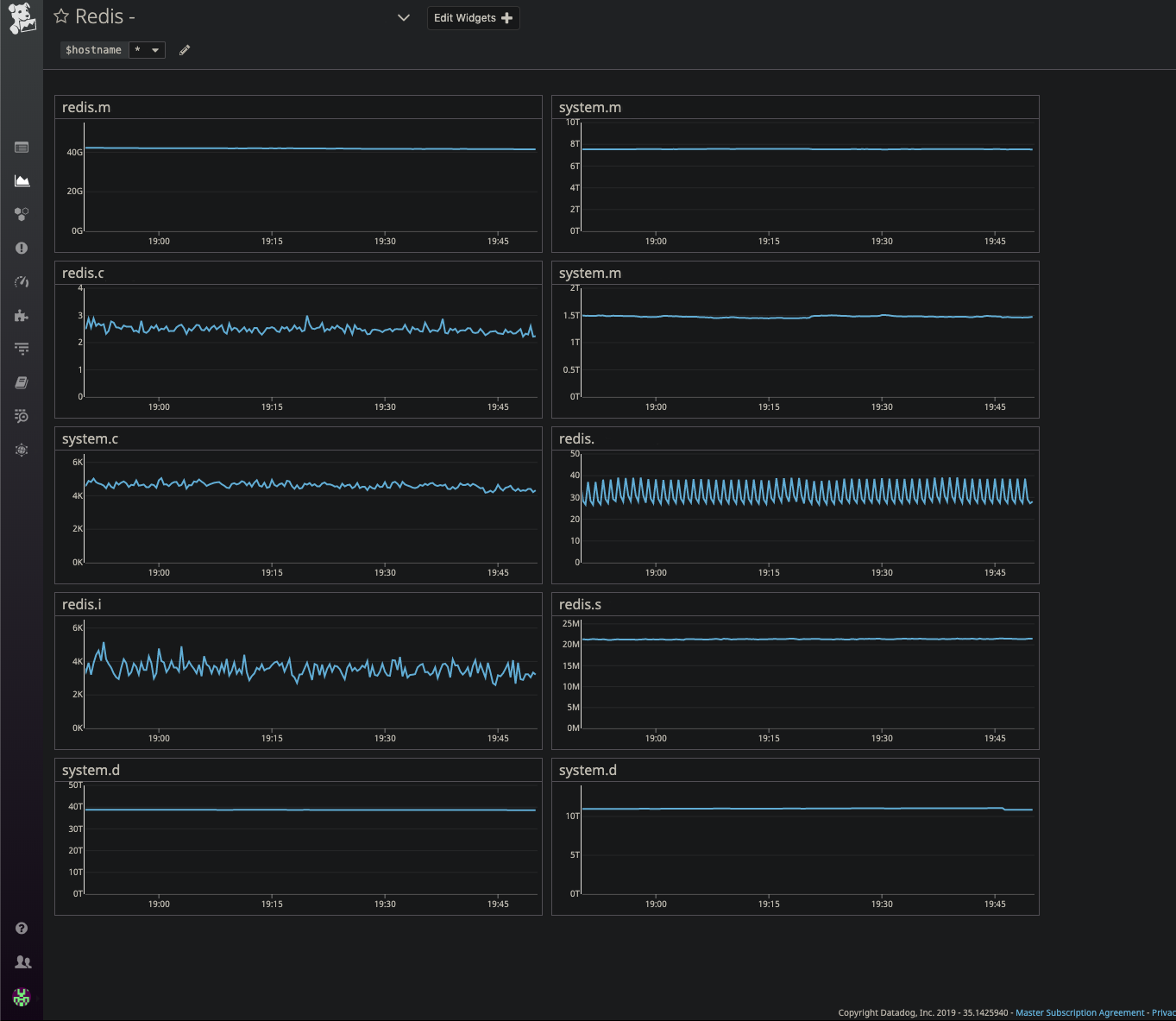
Kami memiliki banyak pemantauan. Segera setelah salah satu dari mereka berfungsi, apakah itu barurelik (layanan sistem naik), grafana (pemantauan skenario tertentu), datadog (waktu infrastruktur), kami segera menerima pemberitahuan di Slack dan kami menerima panggilan pada gilirannya (terima kasih kepada pagerduty). Dan untuk jangka waktu tertentu satu orang ditunjuk. Karena ini terjadi secara otomatis, kemungkinan orang ini saat ini tidak tersedia atau tidak menjawab, maka panggilan akan diteruskan lebih lanjut di sepanjang rantai.
Ketika peringatan dipicu, kami memeriksa kembali kinerja sistem dan mencari tahu penyebab kegagalan (atau peningkatan beban, atau sejumlah besar peristiwa atau panggilan, di sini yang akan terbang). Jika kami memahami bahwa ini adalah masalah dan perlu diselesaikan, kami akan mengirim surat ke grup distribusi khusus untuk spesialis operasional.
Karena itu, kami selalu online.
Manajemen insiden
Jika perusahaan Anda menyediakan layanan, manajemen insiden tidak ada. Kami bekerja sesuai dengan skema ini:
- Deteksi masalah tepat waktu.
- Pemberitahuan masalah orang yang bertanggung jawab.
- Pemberitahuan pemangku kepentingan di semua tingkatan. Artinya, kita berbicara tentang masalah untuk bisnis, sehingga semua orang di sana mengerti persis bagaimana masalah seperti itu mempengaruhi perusahaan dan keuntungan.
- Mempertahankan transparansi kerja maksimum.
- Analisis akar penyebab wajib. Bagaimanapun, ia memiliki asal mula masalah, dan yang berikutnya dapat dicegah. Ini lebih cepat dan lebih bermanfaat daripada menyelesaikannya lagi di babak kedua.
Tujuannya adalah untuk mempelajari masalah pada tahap nol. Saat itulah Anda yang menemukan masalah sebagai karyawan yang menyediakan kapasitas kerja. Tidak ketika klien memberi tahu Anda tentang dia. Oleh karena itu, kami secara aktif menggunakan toolkit APM (Pemantauan Kinerja Aplikasi). Saya akan menyuarakannya sekali lagi.
NewRelic- Memantau semua layanan dan gateway kami
- 50x, 4xx kesalahan
- Redis apdex
- DBs Apdex
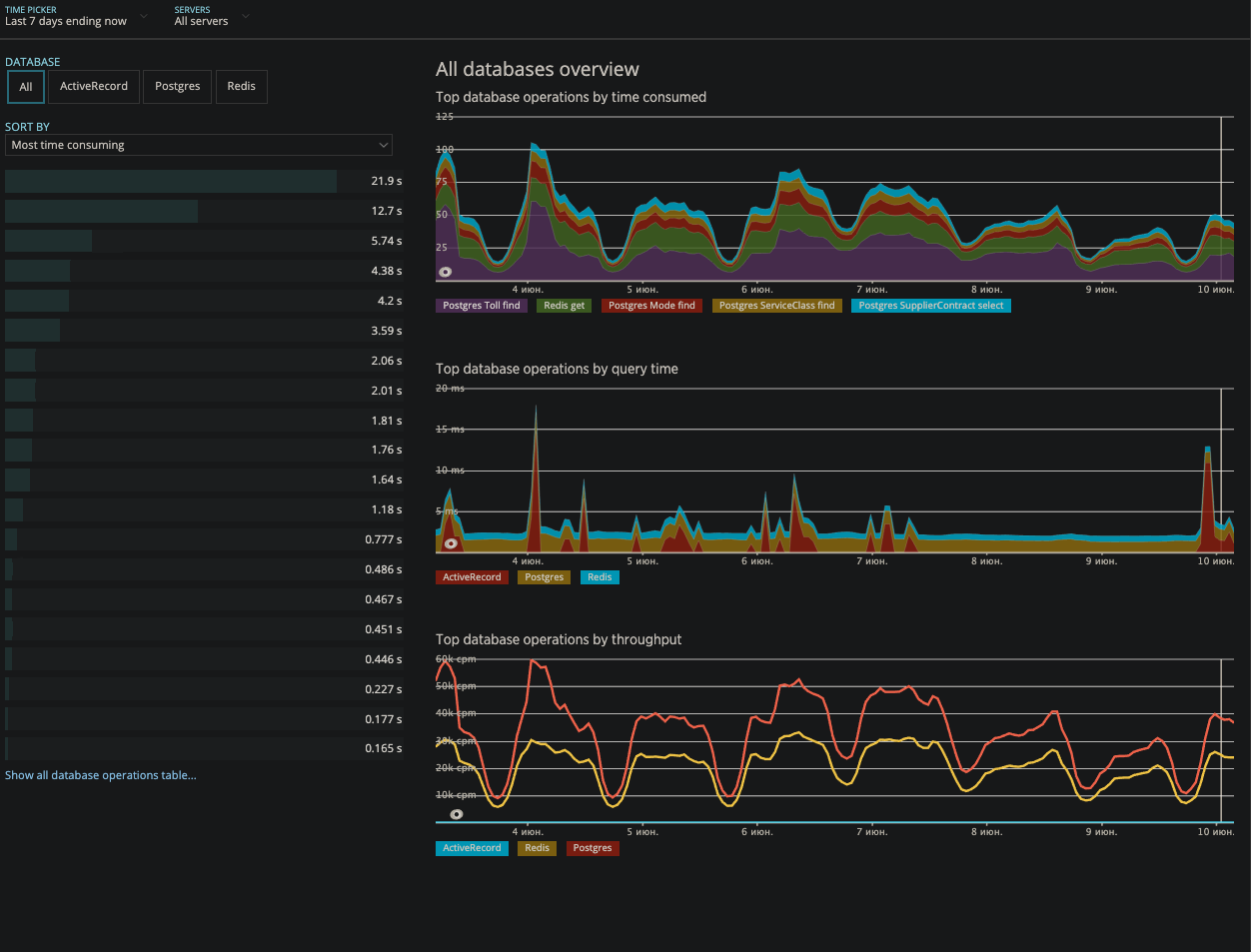 NewRelic, dapat diklikGrafana
NewRelic, dapat diklikGrafana Pemantauan peristiwa (memperjelas apa yang sebenarnya berhenti bekerja atau perilaku berbeda dari normal).
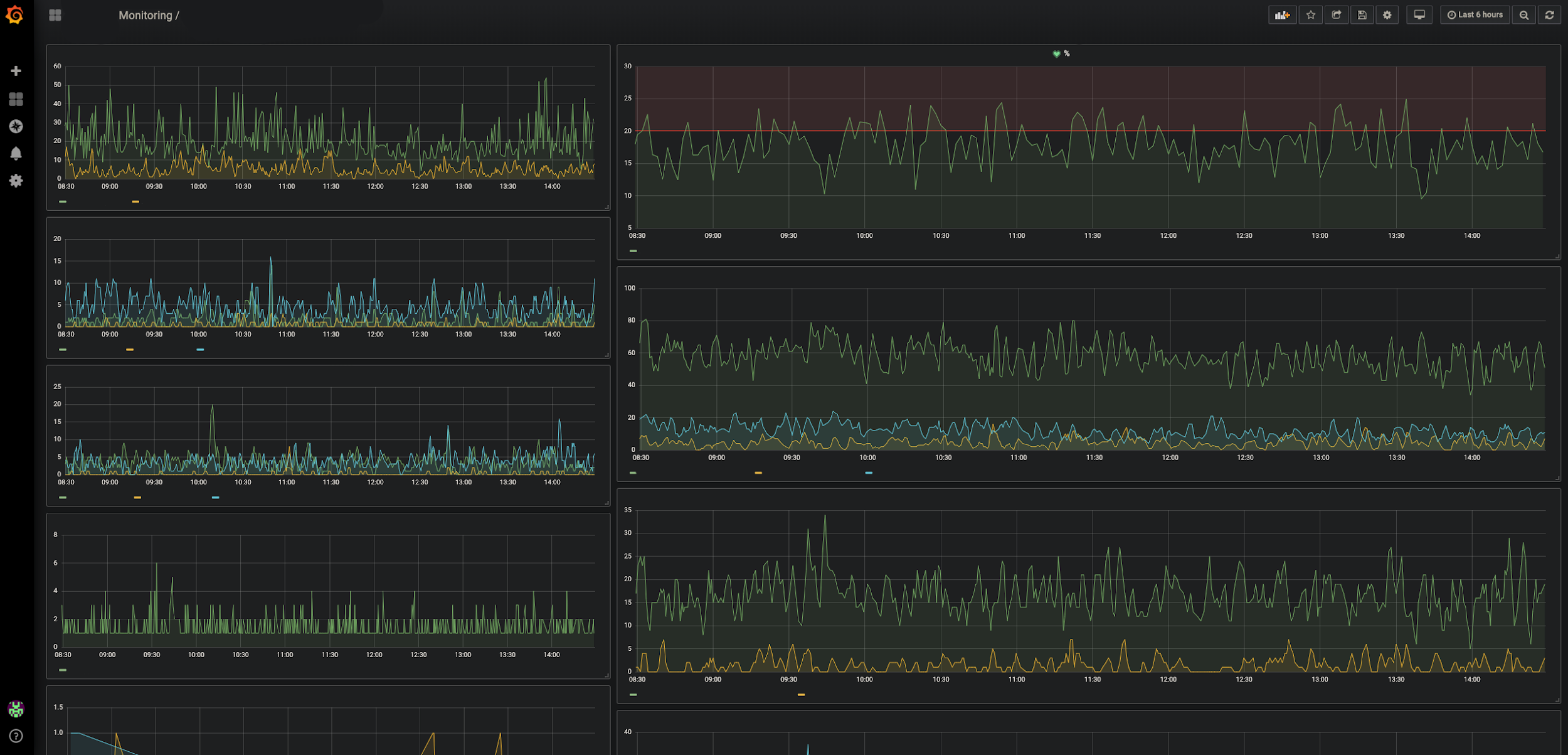 Grafana, dapat diklikDataDog
Grafana, dapat diklikDataDog . Memantau komponen perangkat keras sistem kami (basis data, penyeimbang muatan).
 DataDog, dapat diklikRem udara
DataDog, dapat diklikRem udara Pengecualian Kode untuk aplikasi / layanan mikro (ada daftar pengecualian, misalnya, ketika mengeksekusi kode atau kueri dalam database, jika ada masalah dan ada dalam daftar - kami melacaknya).
Kibana - pemantauan log microservice / aplikasi (driver / klien).
Dan agar semuanya berfungsi tidak hanya untuk deteksi, tetapi juga untuk notifikasi tepat waktu (segera, semakin cepat - semakin baik), semua ini terhubung dengan sejumlah saluran notifikasi, dari Slack dan
PagerDuty hingga notifikasi email lama yang baik. Karena itu, seluruh tim akan segera belajar tentang anomali apa pun. Lansiran dapat dikirim ke saluran yang berbeda. Pemantauan kritis untuk pengoperasian aplikasi selalu mengirimkan peringatan ke tim dukungan teknis dan secara selektif ke saluran tim pengembangan yang bertanggung jawab atas fitur / layanan tertentu. Semua ini membantu mengoptimalkan waktu respons.
Kesulitan muncul pada langkah berikutnya, ketika setelah menemukan masalah Anda harus segera memberi tahu orang yang bertanggung jawab atas layanan tersebut. Dan ini tidak begitu mudah dilakukan jika ada banyak proses dan layanan mikro, yang berarti tidak ada yang kurang bertanggung jawab. Dan lansiran dapat tiba larut malam, saat Anda menginginkan sesuatu, tetapi Anda tidak memilah siapa yang bertanggung jawab atas apa.
Oleh karena itu, kami membuat direktori yang nyaman yang mencantumkan semua pemilik layanan (umumnya di seluruh perusahaan). Seperti yang telah ditunjukkan oleh praktik, ini saja membantu kami mengurangi waktu untuk menyelesaikan setiap insiden sekitar 20%.
Resep terbaik untuk bencana yang berkelanjutan dalam kasus ini adalah meninggalkan insiden tanpa penanggung jawab.
Ada orang khusus, Manajer Insiden Global, yang bekerja sebagai penghubung untuk insiden serius. Dia terlibat dalam memantau dan mengubah sistem dasar untuk menghilangkan kesalahan yang dapat mengarah pada tulang-tulang bisnis, dan bertanggung jawab kepada pejabat tinggi perusahaan, memberikan mereka laporan terperinci tentang analisis akar penyebab.
Oleh karena itu, singkatnya, proses manajemen insiden itu sendiri terlihat seperti ini:
- Kami menentukan penyebab insiden tersebut.
- Kami menemukan orang yang bertanggung jawab.
- Kami sedang mengoordinasikan upaya dengan dia untuk memperbaiki masalah secepat mungkin.
- Kami membuat semua keputusan yang diperlukan selama kejadian.
- Kami memberi tahu bisnis tentang ini, membawa mereka semua masalah.
- Ketika debu tersebar, kami memulai analisis akar penyebab, RCA (Root Cause Analysis).
Kami sedang membangun laporan kejadian di Jira, ada modul yang sesuai,
Insiden , kami telah menambahkan sejumlah bidang tambahan di sana.
Hanya ada tiga tahap RCA.
1. RCA awalIni adalah deskripsi tingkat atas dari penyebab masalah (apakah itu masalah dengan database, atau dengan infrastruktur, atau dengan kode). Laporan ini disiapkan oleh petugas pendukung yang mengelola insiden. Laporan harus diselesaikan dalam waktu 24 jam setelah insiden selesai.
2. R&D RCABagian terpenting dari proses harus diselesaikan dalam waktu 48 jam setelah insiden selesai. Sudah ada analisis teknis lengkap dari akar penyebab - mengapa itu terjadi, mengapa tidak ditemukan (penguji diabaikan atau tidak ada pemantauan yang sesuai), apakah ada kemungkinan bahwa itu akan terjadi lagi, dan apa yang harus dilakukan untuk mencegah hal itu terjadi lagi.
3. TindakanBerdasarkan paragraf kedua, subtugas terkait terbentuk, insiden tetap terbuka sampai subtugas terakhir ditutup. Tidak ada yang menginginkan tugas ini untuk mengambil kanban untuk waktu yang lama, jadi ini memotivasi untuk menyelesaikan semuanya lebih cepat.
Begitulah cara kami di Gett menangani insiden.
Angka dan Teknologi
Kami bekerja, tentu saja, 24/7 dengan SLA 99,99%. Tumpukan utama yang kita miliki di GoLang / Ruby, ini memberikan kecepatan yang diperlukan untuk memproses algoritma yang kompleks. Ada lebih dari 150 microservices secara total, dan semuanya juga ada di GoLang dan Ruby. Kami menggunakan MySQL, Postgres, dan Presto sebagai databasenya. Kami memiliki penyimpanan di AWS.
Beban paling serius pada layanan kami jatuh pada liburan Tahun Baru dan 2 minggu sebelumnya. Kondisi pesaing juga mempengaruhi, misalnya, salah satunya menjatuhkan aplikasi, yang berarti bahwa mesin kami akan lebih sering dipanggil.
Ada juga puncak dalam pekerjaan internal yang mempengaruhi pengguna akhir. Misalnya, ketika kami memperbarui basis data atau melakukan pekerjaan teknis di sisi pemasok dan vendor, atau menggunakan layanan baru untuk produksi (bukan pada hari Jumat, ya), atau kami menugaskan fitur yang segera mempengaruhi sejumlah besar pengguna atau transaksi.
Kami adalah orang-orang juga, dan kadang-kadang terjadi bahwa pengaturan yang salah atau intervensi manual menyebabkan kesalahan operasional, jadi kami mengembangkan rencana untuk kasus ini:

Tidak, bukan itu. Di sini:
- Kami memeriksa data dalam layanan, log, dan audit.
- Kami menguji dan melaksanakan operasi pembaruan di Scrum.
- Kami menyiapkan tugas untuk tim dan memantau pelaksanaan tugas pada produksi.
Jika Anda tertarik pada detail apa pun, jangan ragu untuk bertanya di komentar, kami akan menjawabnya di sini, atau di pos terpisah yang terpisah.