Apa yang penting bagi tim pengembangan yang baru mulai membangun sistem pembelajaran mesin? Arsitektur, komponen, kemampuan pengujian menggunakan integrasi dan pengujian unit, membuat prototipe dan mendapatkan hasil pertama. Dan selanjutnya untuk penilaian input tenaga kerja, pengembangan perencanaan dan implementasi.
Artikel ini akan fokus pada prototipe. Yang dibuat beberapa saat setelah berbicara dengan Manajer Produk: mengapa kita tidak "menyentuh" Pembelajaran Mesin? Secara khusus, NLP dan Analisis Sentimen?
"Kenapa tidak?" Saya jawab. Namun, saya sudah melakukan pengembangan backend selama lebih dari 15 tahun, saya suka bekerja dengan data dan memecahkan masalah kinerja. Tapi saya masih harus mencari tahu, "seberapa dalam lubang kelinci".
Pilih komponen
Untuk menjabarkan sekumpulan komponen yang menerapkan logika inti ML kami, mari kita lihat contoh sederhana penerapan analisis sentimen, salah satu dari banyak yang tersedia di GitHub.
Salah satu contoh analisis sentimen dengan Pythonimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
Mengurai contoh seperti itu merupakan tantangan tersendiri bagi pengembang.
Hanya 45 baris kode, dan 4 (empat, Karl!) Blok logis sekaligus:
- Mengunduh data untuk pelatihan model (baris 25-26)
- Mempersiapkan data yang diunggah - ekstraksi fitur (baris 31-34)
- Membuat dan melatih model (baris 36-39)
- Menguji model yang terlatih dan mengeluarkan hasil (baris 41-45)
Masing-masing poin ini layak mendapat artikel terpisah. Dan itu tentu membutuhkan registrasi dalam modul terpisah. Setidaknya untuk kebutuhan pengujian unit.
Secara terpisah, ada baiknya menyoroti komponen-komponen persiapan data dan pelatihan model.
Dalam setiap cara untuk membuat model lebih tepat, ratusan jam kerja ilmiah dan teknik diinvestasikan.
Untungnya, untuk memulai dengan NLP dengan cepat, ada solusi siap pakai -
perpustakaan NLTK dan
TextBlob . Yang kedua adalah pembungkus NLTK yang melakukan tugas - membuat ekstraksi fitur dari set pelatihan, dan kemudian melatih model pada permintaan klasifikasi pertama.
Tetapi sebelum Anda melatih model, Anda harus menyiapkan data untuk itu.
Mempersiapkan data
Unduh data
Jika kita berbicara tentang prototipe, maka memuat data dari file CSV / TSV adalah dasar. Anda cukup memanggil fungsi
read_csv dari panda library:
import pandas as pd data = pd.read_csv(data_path, delimiter)
Tetapi itu tidak akan menjadi data yang siap digunakan dalam model.
Pertama, jika kita sedikit mengabaikan format csv, maka mudah untuk berharap bahwa setiap sumber akan menyediakan data dengan karakteristiknya sendiri, dan oleh karena itu kita memerlukan semacam persiapan data yang bergantung pada sumber. Bahkan untuk kasus paling sederhana dari file CSV, untuk hanya menguraikannya, kita perlu mengetahui pembatas.
Selain itu, Anda harus menentukan entri mana yang positif dan mana yang negatif. Tentu saja, informasi ini ditunjukkan dalam anotasi ke kumpulan data yang ingin kita gunakan. Tetapi kenyataannya adalah bahwa dalam satu kasus tanda pos / neg adalah 0 atau 1, di lain itu adalah logis Benar / Salah, dalam ketiga itu hanya string pos / neg, dan dalam beberapa kasus, sebuah tupel bilangan bulat dari 0 hingga 5 Yang terakhir ini relevan untuk kasus klasifikasi multi-kelas, tetapi siapa yang mengatakan bahwa kumpulan data seperti itu tidak dapat digunakan untuk klasifikasi biner? Anda hanya perlu mengidentifikasi batas nilai positif dan negatif secara memadai.
Saya ingin mencoba model pada set data yang berbeda, dan diperlukan, setelah pelatihan, model mengembalikan hasilnya dalam satu format tunggal. Dan untuk ini, data heterogennya harus dibawa ke satu bentuk.
Jadi, ada tiga fungsi yang kita butuhkan pada tahap pemuatan data:
- Koneksi ke sumber data adalah untuk CSV, dalam kasus kami ini diterapkan di dalam fungsi read_csv;
- Dukungan untuk fitur format;
- Persiapan data awal.
Ini adalah tampilannya dalam kode.
import numpy as np
Kelas
CsvSentimentDataLoader dibuat, yang dalam konstruktor melewati path ke csv, pemisah, nama teks dan atribut klasifikasi, serta daftar nilai yang menyarankan nilai positif dari teks.
Pemuatan itu sendiri terjadi dalam metode
load_data .
Kami membagi data menjadi set tes dan pelatihan
Oke, kami mengunggah data, tetapi kami masih perlu membaginya ke dalam set pelatihan dan tes.
Ini dilakukan dengan fungsi
train_test_split dari pustaka
sklearn . Fungsi ini dapat mengambil banyak parameter sebagai input, menentukan bagaimana tepatnya dataset ini akan dibagi menjadi kereta dan pengujian. Parameter ini secara signifikan mempengaruhi hasil pelatihan dan set tes, dan mungkin akan mudah bagi kita untuk membuat kelas (sebut saja SimpleDataSplitter) yang akan mengelola parameter ini dan mengagregasikan panggilan ke fungsi ini.
from sklearn.model_selection import train_test_split
Sekarang kelas ini termasuk implementasi paling sederhana, yang, ketika dibagi, akan mempertimbangkan hanya satu parameter - persentase catatan yang harus diambil sebagai set uji.
Kumpulan data
Untuk melatih model, saya menggunakan dataset yang tersedia secara bebas dalam format CSV:
Dan agar lebih nyaman, untuk masing-masing dataset saya membuat kelas yang memuat data dari file CSV yang sesuai dan membaginya menjadi pelatihan dan set tes.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
Ya, untuk pemuatan data, ternyata sedikit lebih dari 5 baris kode dalam contoh asli.
Tapi sekarang sekarang mungkin untuk membuat dataset baru dengan menyulap sumber data dan pelatihan algoritma persiapan set.
Plus, masing-masing komponen jauh lebih nyaman untuk pengujian unit.
Kami melatih model
Model ini telah belajar selama beberapa waktu. Dan ini harus dilakukan sekali, pada awal aplikasi.
Untuk tujuan ini, pembungkus kecil dibuat yang memungkinkan Anda mengunduh dan menyiapkan data, serta melatih model pada saat inisialisasi aplikasi.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
Pertama kita mendapatkan data pelatihan dan tes, kemudian kita melakukan ekstraksi fitur, dan akhirnya kita melatih classifier dan memeriksa akurasi pada set tes.
Pengujian
Setelah inisialisasi, kami mendapatkan log, dilihat dari mana, data diunduh dan model berhasil dilatih. Dan dilatih dengan akurasi (untuk pemula) yang sangat bagus - 0,8878.
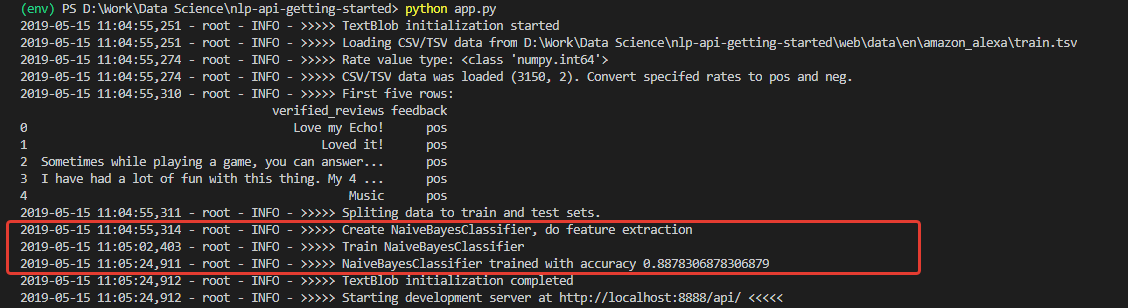
Setelah menerima angka seperti itu, saya sangat antusias. Namun sayangnya, kegembiraan saya tidak lama. Model yang dilatih pada set ini adalah seorang optimis yang tidak dapat ditembus dan, pada prinsipnya, tidak dapat mengenali komentar negatif.
Alasan untuk ini adalah dalam data set pelatihan. Jumlah ulasan positif di set lebih dari 90%. Dengan demikian, dengan akurasi model sekitar 88%, ulasan negatif hanya jatuh ke dalam 12% yang diharapkan dari klasifikasi yang salah.
Dengan kata lain, dengan set pelatihan seperti itu, tidak mungkin untuk melatih model untuk mengenali komentar negatif.
Untuk benar-benar memastikan hal ini, saya melakukan tes unit yang menjalankan klasifikasi secara terpisah untuk 100 frasa positif dan 100 negatif dari kumpulan data lain - untuk pengujian saya mengambil
Set Data Sentimen berlabel Kalimat Data dari University of California.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
Algoritma untuk menguji klasifikasi nilai-nilai positif adalah sebagai berikut:
- Unduh data uji;
- Ambil 100 pos yang ditandai 'pos'
- Kami menjalankan masing-masing melalui model dan menghitung jumlah hasil yang benar
- Tampilkan hasil akhir di konsol.
Demikian pula, penghitungan dibuat untuk komentar negatif.
Seperti yang diharapkan, semua komentar negatif diakui sebagai positif.
Dan jika Anda melatih model pada dataset yang digunakan untuk pengujian -
Sentimen berlabel ? Di sana, distribusi komentar negatif dan positif tepat 50 hingga 50.
Ubah kode dan uji, jalankan Sudah ada sesuatu. Akurasi aktual dari 200 entri dari set pihak ketiga adalah 76%, sedangkan akurasi klasifikasi komentar negatif adalah 79%.
Tentu saja, 76% akan melakukan prototipe, tetapi tidak cukup untuk produksi. Ini berarti bahwa langkah-langkah tambahan akan diperlukan untuk meningkatkan akurasi algoritma. Tapi ini adalah topik untuk laporan lain.
Ringkasan
Pertama, kami mendapat aplikasi dengan selusin kelas dan 200+ baris kode, yang sedikit lebih dari contoh aslinya sebanyak 30 baris. Dan Anda harus jujur - ini hanya petunjuk pada struktur, klarifikasi pertama batas aplikasi masa depan. Prototipe.
Dan prototipe ini memungkinkan untuk menyadari seberapa jauh jarak antara pendekatan ke kode dari sudut pandang spesialis Pembelajaran Mesin dan dari sudut pandang pengembang aplikasi tradisional. Dan ini, menurut saya, adalah kesulitan utama bagi pengembang yang memutuskan untuk mencoba pembelajaran mesin.
Hal berikutnya yang dapat membuat pemula dalam keadaan pingsan - data tidak kalah penting dari model yang dipilih. Ini telah ditunjukkan dengan jelas.
Lebih lanjut, selalu ada kemungkinan bahwa model yang dilatih pada beberapa data akan menunjukkan dirinya tidak memadai pada orang lain, atau pada titik tertentu akurasinya akan mulai menurun.
Oleh karena itu, metrik diperlukan untuk memantau keadaan model, fleksibilitas saat bekerja dengan data, kemampuan teknis untuk menyesuaikan pembelajaran dengan cepat. Dan sebagainya.
Bagi saya, semua ini harus diperhitungkan saat merancang arsitektur dan proses pengembangan bangunan.
Secara umum, "lubang kelinci" tidak hanya sangat dalam, tetapi juga sangat cerdik. Namun yang lebih menarik bagi saya, sebagai pengembang, untuk mempelajari topik ini di masa depan.