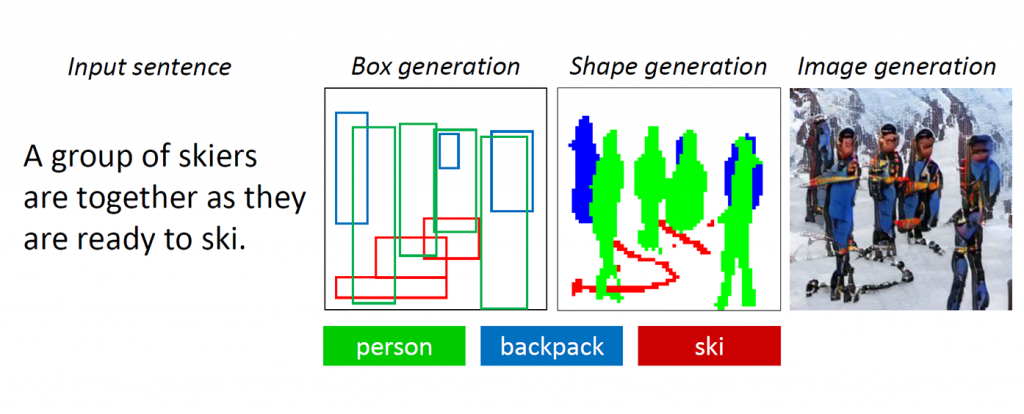
Jika Anda diminta untuk menggambar beberapa orang dengan perlengkapan ski, berdiri di atas salju, kemungkinan Anda akan mulai dengan garis besar tiga atau empat orang yang diposisikan secara wajar di tengah kanvas, kemudian membuat sketsa di papan ski di bawah papan mereka. kaki. Meskipun tidak ditentukan, Anda mungkin memutuskan untuk menambahkan ransel ke setiap pemain ski untuk memenuhi dengan harapan pemain ski apa yang akan olahraga. Akhirnya, Anda akan dengan hati-hati mengisi detail, mungkin mengecat pakaian mereka dengan warna biru, syal merah muda, semuanya dengan latar belakang putih, menjadikan orang-orang ini lebih realistis dan memastikan bahwa lingkungan mereka cocok dengan deskripsi. Akhirnya, untuk membuat pemandangan lebih jelas, Anda bahkan dapat membuat sketsa batu cokelat yang menonjol di salju untuk menunjukkan bahwa pemain ski ini ada di pegunungan.
Sekarang ada bot yang bisa melakukan semua itu.
Teknologi AI baru yang sedang dikembangkan di Microsoft Research AI dapat memahami deskripsi bahasa alami, membuat sketsa tata letak gambar, mensintesis gambar, dan kemudian memperbaiki detail berdasarkan tata letak dan kata-kata individual yang diberikan. Dengan kata lain, bot ini dapat menghasilkan gambar dari deskripsi teks seperti keterangan dari adegan sehari-hari. Mekanisme yang disengaja ini menghasilkan peningkatan yang signifikan dalam kualitas gambar yang dihasilkan dibandingkan dengan teknik state-of-the-art sebelumnya untuk generasi teks-ke-gambar untuk adegan sehari-hari yang rumit, menurut hasil pada tes standar industri yang dilaporkan dalam " Object-driven Text- to-Image Synthesis via Adversarial Training ", yang akan diterbitkan bulan ini di Long Beach, California pada Konferensi IEEE 2019 tentang Visi Komputer dan Pengenalan Pola (CVPR 2019). Ini adalah proyek kolaborasi antara Pengchuan Zhang , Qiuyuan Huang dan Jianfeng Gao dari Microsoft Research AI , Lei Zhang dari Microsoft, Xiaodong He dari JD AI Research, dan Wenbo Li dan Siwei Lyu dari Universitas di Albany, SUNY (sementara Wenbo Li bekerja sebagai magang di Microsoft Research AI).
Ada dua tantangan utama intrinsik untuk masalah bot menggambar berbasis deskripsi. Yang pertama adalah bahwa banyak jenis objek dapat muncul dalam adegan sehari-hari dan bot harus dapat memahami dan menggambar semuanya. Metode pembuatan teks-ke-gambar sebelumnya menggunakan pasangan caption-gambar yang hanya menyediakan sinyal supervisi berbutir kasar untuk menghasilkan objek individual, sehingga membatasi kualitas generasi objek mereka. Dalam teknologi baru ini, para peneliti menggunakan dataset COCO yang berisi label dan peta segmentasi untuk 1,5 juta instance objek di 80 kelas objek umum, memungkinkan bot mempelajari konsep dan tampilan objek-objek ini. Sinyal supervisi berbutir halus ini untuk pembangkitan objek secara signifikan meningkatkan kualitas pembangkitan untuk kelas objek umum ini.
Tantangan kedua terletak pada pemahaman dan generasi hubungan antara banyak objek dalam satu adegan. Sukses besar telah dicapai dalam menghasilkan gambar yang hanya berisi satu objek utama untuk beberapa domain tertentu, seperti wajah, burung, dan objek umum. Namun, menghasilkan adegan yang lebih kompleks berisi banyak objek dengan hubungan semantik yang berarti di seluruh objek tersebut tetap menjadi tantangan signifikan dalam teknologi pembuatan teks-ke-gambar. Bot gambar baru ini belajar untuk menghasilkan tata letak objek dari pola co-kejadian dalam dataset COCO untuk kemudian menghasilkan gambar yang dikondisikan pada tata letak yang dibuat sebelumnya.
Pembuatan gambar penuh perhatian yang digerakkan oleh objek
Inti dari Microsoft Research AI drawing bot adalah teknologi yang dikenal sebagai Generative Adversarial Network, atau GAN. GAN terdiri dari dua model pembelajaran mesin - generator yang menghasilkan gambar dari deskripsi teks, dan diskriminator yang menggunakan deskripsi teks untuk menilai keaslian gambar yang dihasilkan. Generator berusaha untuk mendapatkan gambar palsu melewati pembeda; diskriminator di sisi lain tidak pernah mau dibodohi. Bekerja bersama, diskriminator mendorong generator menuju kesempurnaan.
Bot menggambar dilatih pada dataset 100.000 gambar, masing-masing dengan label objek yang menonjol dan peta segmentasi dan lima keterangan yang berbeda, memungkinkan model untuk menyusun objek individu dan hubungan semantik antara objek. GAN, misalnya, mempelajari bagaimana rupa anjing ketika membandingkan gambar dengan dan tanpa deskripsi anjing.

Gambar 1: Pemandangan kompleks dengan banyak objek dan hubungan.
GAN bekerja dengan baik ketika menghasilkan gambar yang hanya mengandung satu objek yang menonjol, seperti wajah manusia, burung atau anjing, tetapi kualitas mandek dengan adegan sehari-hari yang lebih kompleks, adegan seperti yang digambarkan sebagai "Seorang wanita mengenakan helm sedang menunggang kuda" (lihat Gambar 1.) Ini karena adegan seperti itu mengandung banyak objek (wanita, helm, kuda) dan hubungan semantik yang kaya di antara mereka (wanita memakai helm, wanita menunggang kuda). Bot pertama harus memahami konsep-konsep ini dan menempatkannya di gambar dengan tata letak yang bermakna. Setelah itu, sinyal yang lebih diawasi yang mampu mengajarkan pembuatan objek dan pembuatan tata letak diperlukan untuk memenuhi tugas generasi-pemahaman-dan-gambar-gambar ini.
Ketika manusia menggambar adegan rumit ini, pertama-tama kita memutuskan objek utama untuk menggambar dan membuat tata letak dengan menempatkan kotak pembatas untuk objek-objek ini di kanvas. Kemudian kami fokus pada setiap objek, dengan berulang kali memeriksa kata-kata yang sesuai yang menggambarkan objek ini. Untuk menangkap sifat manusia ini, para peneliti menciptakan apa yang mereka sebut sebagai Object-driven attention GAN, atau ObjGAN, untuk secara matematis memodelkan perilaku manusia dari objek yang menjadi pusat perhatian. ObjGAN melakukan ini dengan memecah teks input menjadi kata-kata individual dan mencocokkan kata-kata tersebut dengan objek tertentu dalam gambar.
Manusia biasanya memeriksa dua aspek untuk memperbaiki gambar: realisme objek individu dan kualitas tambalan gambar. ObjGAN meniru perilaku ini juga dengan memperkenalkan dua pembeda - satu pembeda objek-bijaksana dan satu pembeda tekat-bijaksana. Diskriminator objek-bijaksana sedang mencoba untuk menentukan apakah objek yang dihasilkan realistis atau tidak dan apakah objek konsisten dengan deskripsi kalimat. Diskriminator bijak sedang mencoba untuk menentukan apakah patch ini realistis atau tidak dan apakah patch ini konsisten dengan deskripsi kalimat.
Pekerjaan terkait: visualisasi cerita
Model generasi teks-ke-gambar yang canggih dapat menghasilkan gambar burung yang realistis berdasarkan deskripsi satu kalimat. Namun, pembuatan teks-ke-gambar dapat melampaui sintesis satu gambar tunggal berdasarkan satu kalimat. Dalam " StoryGAN: GAN Bersyarat Berurutan untuk Visualisasi Cerita ", Jianfeng Gao dari Microsoft Research, bersama dengan Zhe Gan, Jingjing Liu dan Yu Cheng dari Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson dan Lawrence Carin dari Universitas Duke, Yelong Shen Tencent AI Research dan Yuexin Wu dari Carnegie Mellon University melangkah lebih jauh dan mengusulkan tugas baru, yang disebut Visualisasi Cerita. Diberikan paragraf multi-kalimat, sebuah cerita lengkap dapat divisualisasikan, menghasilkan urutan gambar, satu untuk setiap kalimat. Ini adalah tugas yang menantang, karena bot menggambar tidak hanya diperlukan untuk membayangkan skenario yang sesuai dengan cerita, model interaksi antara berbagai karakter yang muncul dalam cerita, tetapi juga harus mampu menjaga konsistensi global di seluruh adegan dan karakter yang dinamis. Tantangan ini belum diatasi dengan metode pembuatan gambar atau video tunggal.
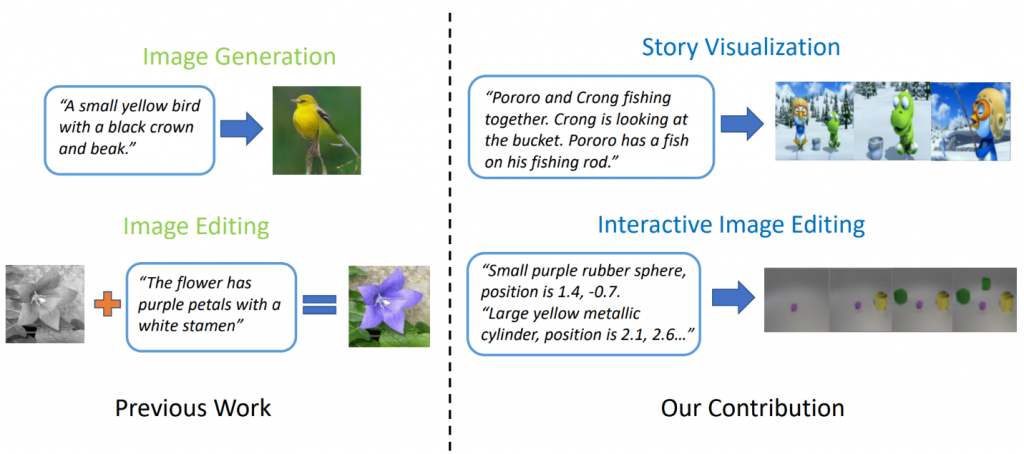
Gambar 2: Visualisasi cerita vs. generasi gambar sederhana.
Para peneliti datang dengan model generasi story-to-image-sequence baru, StoryGAN, berdasarkan kerangka kerja kondisional GAN berurutan. Model ini unik karena terdiri dari Encoder Konteks mendalam yang secara dinamis melacak alur cerita, dan dua diskriminator pada tingkat cerita dan gambar untuk meningkatkan kualitas gambar dan konsistensi dari urutan yang dihasilkan. StoryGAN juga dapat diperluas secara alami untuk mengedit gambar interaktif, di mana gambar input dapat diedit secara berurutan berdasarkan instruksi teks. Dalam hal ini, urutan instruksi pengguna akan berfungsi sebagai input "cerita". Dengan demikian, para peneliti memodifikasi dataset yang ada untuk membuat dataset CLEVR-SV dan Pororo-SV, seperti yang ditunjukkan pada Gambar 2.
Aplikasi praktis - kisah nyata
Teknologi pembuatan teks-ke-gambar dapat menemukan aplikasi praktis yang bertindak sebagai semacam asisten sketsa untuk pelukis dan desainer interior, atau sebagai alat untuk mengedit foto yang diaktifkan suara. Dengan kekuatan komputasi yang lebih besar, para peneliti membayangkan teknologi menghasilkan film animasi berdasarkan skenario, menambah pekerjaan yang dilakukan pembuat film animasi dengan menghilangkan beberapa tenaga kerja manual yang terlibat.
Untuk saat ini, gambar yang dihasilkan masih jauh dari foto realistis. Benda-benda individual hampir selalu mengungkapkan kelemahan, seperti wajah kabur dan atau bus dengan bentuk terdistorsi. Kelemahan ini adalah indikasi yang jelas bahwa komputer, bukan manusia, menciptakan gambar. Namun demikian, kualitas gambar ObjGAN secara signifikan lebih baik daripada gambar GAN terbaik di kelasnya sebelumnya dan berfungsi sebagai tonggak di jalan menuju kecerdasan generik, seperti manusia yang menambah kemampuan manusia.
Agar AI dan manusia dapat berbagi dunia yang sama, masing-masing harus memiliki cara untuk berinteraksi dengan yang lain. Bahasa dan visi adalah dua modalitas terpenting bagi manusia dan mesin untuk berinteraksi satu sama lain. Pembuatan teks-ke-gambar adalah salah satu tugas penting yang memajukan penelitian kecerdasan multi-modal bahasa-visi.
Para peneliti yang menciptakan karya menarik ini berharap dapat berbagi temuan ini dengan para peserta di CVPR di Long Beach dan mendengarkan pendapat Anda. Sementara itu, silakan periksa kode sumber terbuka mereka untuk ObjGAN dan StoryGAN di GitHub