Dalam artikel ini, saya akan memberi tahu Anda bagaimana kami mendekati masalah toleransi kesalahan PostgreSQL, mengapa ini menjadi penting bagi kami, dan apa yang terjadi pada akhirnya.
Kami memiliki layanan yang sangat dimuat: 2,5 juta pengguna di seluruh dunia, 50K + pengguna aktif setiap hari. Server terletak di Amazone di satu wilayah Irlandia: selalu ada 100+ server berbeda yang beroperasi, yang hampir 50 di antaranya menggunakan basis data.
Seluruh backend adalah aplikasi Java stateful monolitik besar yang membuat koneksi websocket konstan ke klien. Dengan kerja simultan dari beberapa pengguna di satu papan, mereka semua melihat perubahan secara real time, karena kami mencatat setiap perubahan dalam database. Kami memiliki sekitar 10 ribu kueri per detik ke basis data kami. Saat beban puncak di Redis, kami menulis di 80-100K kueri per detik.

Mengapa kami beralih dari Redis ke PostgreSQL
Awalnya, layanan kami bekerja dengan Redis, repositori kunci-nilai yang menyimpan semua data dalam RAM server.
Pro Redis:
- Tingkat respons tinggi, seperti semuanya disimpan dalam memori;
- Kenyamanan cadangan dan replikasi.
Cons Redis untuk kita:
- Tidak ada transaksi nyata. Kami mencoba mensimulasikan mereka di tingkat aplikasi kami. Sayangnya, ini tidak selalu berhasil dan diperlukan penulisan kode yang sangat kompleks.
- Jumlah data dibatasi oleh jumlah memori. Ketika jumlah data bertambah, memori akan bertambah, dan pada akhirnya, kita akan bertemu dengan karakteristik instance yang dipilih, yang dalam AWS mengharuskan penghentian layanan kami untuk mengubah jenis instance.
- Penting untuk terus mempertahankan tingkat latensi rendah, seperti Kami memiliki sejumlah besar permintaan. Level delay optimal bagi kami adalah 17-20 ms. Pada level 30-40 ms, kami mendapatkan jawaban panjang untuk permintaan aplikasi kami dan degradasi layanan. Sayangnya, ini terjadi pada kami pada bulan September 2018, ketika salah satu contoh Redis karena alasan tertentu menerima latensi 2 kali lebih tinggi dari biasanya. Untuk mengatasi masalah tersebut, kami menghentikan layanan di tengah hari karena pemeliharaan tidak terjadwal dan mengganti instance Redis yang bermasalah.
- Sangat mudah untuk mendapatkan ketidakkonsistenan data bahkan dengan kesalahan kecil dalam kode dan kemudian menghabiskan banyak waktu menulis kode untuk memperbaiki data ini.
Kami memperhitungkan kerugian dan menyadari bahwa kami perlu pindah ke sesuatu yang lebih nyaman, dengan transaksi normal dan lebih sedikit ketergantungan pada latensi. Melakukan penelitian, menganalisis banyak opsi dan memilih PostgreSQL.
Kami telah pindah ke database baru selama 1,5 tahun dan hanya mentransfer sebagian kecil dari data, jadi sekarang kami bekerja secara bersamaan dengan Redis dan PostgreSQL. Informasi lebih lanjut tentang tahapan pemindahan dan pemindahan data antara basis data ditulis dalam sebuah
artikel oleh rekan saya .
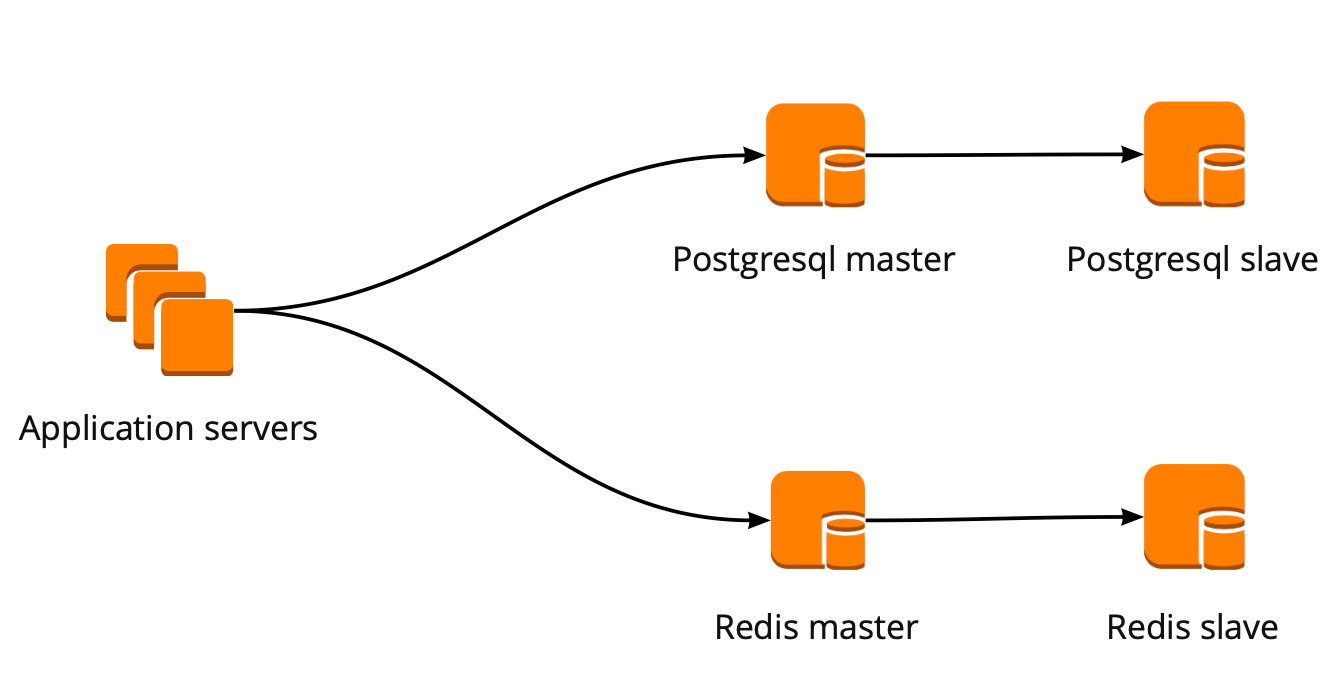
Ketika kami baru saja mulai bergerak, aplikasi kami bekerja secara langsung dengan database dan beralih ke wizard Redis dan PostgreSQL. Cluster PostgreSQL terdiri dari master dan replika asinkron. Beginilah tampilan skema operasi basis data:
Penerapan PgBuncer
Sementara kami bergerak, produk juga berkembang: jumlah pengguna dan jumlah server yang bekerja dengan PostgreSQL meningkat, dan kami mulai kehilangan koneksi. PostgreSQL menciptakan proses terpisah untuk setiap koneksi dan menghabiskan sumber daya. Anda dapat meningkatkan jumlah koneksi hingga titik tertentu, jika tidak, ada peluang untuk mendapatkan operasi basis data yang tidak optimal. Pilihan ideal dalam situasi ini adalah pilihan manajer koneksi yang akan berdiri di depan pangkalan.
Kami memiliki dua opsi untuk manajer koneksi: Pgpool dan PgBouncer. Tetapi yang pertama tidak mendukung mode transaksional bekerja dengan database, jadi kami memilih PgBouncer.
Kami telah menyiapkan skema kerja berikut: aplikasi kami mengakses satu PgBouncer, diikuti oleh Masters PostgreSQL, dan di belakang setiap master, satu replika dengan replikasi asinkron.

Pada saat yang sama, kami tidak dapat menyimpan seluruh jumlah data dalam PostgreSQL, dan kecepatan bekerja dengan basis data penting bagi kami, jadi kami mulai membagikan PostgreSQL pada tingkat aplikasi. Skema yang dijelaskan di atas relatif mudah untuk ini: ketika menambahkan shard PostgreSQL baru, cukup untuk memperbarui konfigurasi PgBouncer dan aplikasi dapat segera bekerja dengan shard baru.
Toleransi Kesalahan PgBouncer
Skema ini bekerja sampai satu-satunya instance PgBuncer meninggal. Kami berlokasi di AWS, di mana semua instance berjalan pada perangkat keras yang mati secara berkala. Dalam kasus seperti itu, instance hanya bergerak ke perangkat keras baru dan bekerja lagi. Ini terjadi dengan PgBouncer, tetapi menjadi tidak tersedia. Hasil musim gugur ini adalah tidak dapat diaksesnya layanan kami selama 25 menit. AWS merekomendasikan penggunaan redundansi di sisi pengguna untuk situasi seperti itu, yang tidak diterapkan bersama kami pada saat itu.
Setelah itu, kami dengan serius memikirkan toleransi kesalahan cluster PgBouncer dan PostgreSQL, karena situasi serupa dapat terjadi lagi dengan contoh apa pun di akun AWS kami.
Kami membangun skema toleransi kesalahan PgBouncer sebagai berikut: semua server aplikasi mengakses Network Load Balancer, di belakangnya terdapat dua PgBouncer. Setiap PgBouncer melihat master PostgreSQL yang sama dari setiap pecahan. Jika instance AWS mogok lagi, semua lalu lintas dialihkan melalui PgBouncer lain. Toleransi kesalahan Network Load Balancer menyediakan AWS.
Skema ini memungkinkan Anda untuk dengan mudah menambahkan server PgBouncer baru.

Membuat Cluster Failover PostgreSQL
Dalam mengatasi masalah ini, kami mempertimbangkan berbagai opsi: failover yang ditulis sendiri, repmgr, AWS RDS, Patroni.
Skrip yang ditulis sendiri
Mereka dapat memantau pekerjaan master dan, jika jatuh, mempromosikan replika ke master dan memperbarui konfigurasi PgBouncer.
Kelebihan dari pendekatan ini adalah kesederhanaan maksimum, karena Anda sendiri yang menulis skrip dan memahami persis cara kerjanya.
Cons:
- Master mungkin tidak mati, sebaliknya, kegagalan jaringan dapat terjadi. Failover, tanpa mengetahui hal ini, akan memajukan replika ke master, dan master lama akan terus bekerja. Akibatnya, kami mendapatkan dua server sebagai master dan kami tidak tahu yang mana dari mereka yang memiliki data aktual terkini. Situasi ini juga disebut otak-terpisah;
- Kami dibiarkan tanpa replika. Dalam konfigurasi kami, master dan satu replika, setelah beralih replika, itu pindah ke master dan kami tidak lagi memiliki replika, jadi kami harus secara manual menambahkan replika baru;
- Kami membutuhkan pemantauan tambahan untuk operasi failover, sementara kami memiliki 12 pecahan PostgreSQL, yang berarti kami harus memantau 12 cluster. Jika Anda menambah jumlah pecahan, Anda harus tetap ingat untuk memperbarui failover.
Kegagalan menulis sendiri terlihat sangat rumit dan membutuhkan dukungan non-sepele. Dengan satu cluster PostgreSQL, ini akan menjadi pilihan termudah, tetapi tidak menskala, jadi tidak cocok untuk kita.
Repmgr
Manajer Replikasi untuk cluster PostgreSQL, yang dapat mengelola operasi cluster PostgreSQL. Pada saat yang sama, tidak ada kegagalan otomatis "di luar kotak" di dalamnya, jadi untuk pekerjaan Anda perlu menulis "bungkus" sendiri di atas solusi yang sudah jadi. Jadi semuanya bisa menjadi lebih rumit daripada dengan skrip yang ditulis sendiri, jadi kami bahkan tidak mencoba Repmgr.
AWS RDS
Ini mendukung semua yang Anda butuhkan untuk kami, tahu cara membuat cadangan dan mendukung kumpulan koneksi. Ini memiliki peralihan otomatis: setelah kematian master, replika menjadi master baru, dan AWS mengubah catatan dns ke master baru, sementara replika dapat berada di AZ yang berbeda.
Kerugiannya termasuk kurangnya pengaturan halus. Sebagai contoh penyesuaian: pada contoh kami ada batasan untuk koneksi tcp, yang, sayangnya, tidak dapat dilakukan di RDS:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
Selain itu, harga AWS RDS hampir dua kali lebih tinggi dari harga contoh biasa, yang merupakan alasan utama untuk menolak keputusan ini.
Patroni
Ini adalah template python untuk mengelola PostgreSQL dengan dokumentasi yang baik, failover otomatis, dan kode sumber github.
Pro dari Patroni:
- Setiap parameter konfigurasi dicat, jelas cara kerjanya;
- Kegagalan otomatis bekerja di luar kotak;
- Itu ditulis dalam python, dan karena kita menulis banyak dalam python sendiri, akan lebih mudah bagi kita untuk mengatasi masalah dan, mungkin, bahkan membantu pengembangan proyek;
- Ini sepenuhnya mengontrol PostgreSQL, memungkinkan Anda untuk mengubah konfigurasi pada semua node cluster sekaligus, dan jika sebuah cluster restart diperlukan untuk menerapkan konfigurasi baru, maka ini dapat dilakukan lagi menggunakan Patroni.
Cons:
- Dari dokumentasi itu tidak jelas cara bekerja dengan PgBouncer. Meskipun sulit untuk menyebutnya minus, karena tugas Patroni adalah mengelola PostgreSQL, dan bagaimana koneksi ke Patroni akan menjadi masalah kita;
- Ada beberapa contoh implementasi Patroni pada volume besar, sementara banyak contoh implementasi dari awal.
Akibatnya, untuk membuat kluster failover, kami memilih Patroni.
Proses Implementasi Patroni
Sebelum Patroni, kami memiliki 12 pecahan PostgreSQL dalam konfigurasi, satu master dan satu replika dengan replikasi asinkron. Server aplikasi mengakses database melalui Network Load Balancer, di belakangnya terdapat dua instance dengan PgBouncer, dan di belakangnya semua adalah server PostgreSQL.
Untuk mengimplementasikan Patroni, kami perlu memilih repositori konfigurasi cluster terdistribusi. Patroni bekerja dengan sistem penyimpanan konfigurasi terdistribusi seperti etcd, Zookeeper, Consul. Kami hanya memiliki cluster Konsul lengkap di prod yang berfungsi bersama Vault dan kami tidak menggunakannya lagi. Alasan yang bagus untuk mulai menggunakan Konsul untuk tujuan yang dimaksud.
Bagaimana Patroni Bekerja dengan Konsul
Kami memiliki sebuah cluster Konsul, yang terdiri dari tiga node, dan sebuah cluster Patroni, yang terdiri dari seorang pemimpin dan sebuah replika (dalam Patroni, seorang master disebut pemimpin cluster, dan budak disebut replika). Setiap instance dari cluster Patroni secara konstan mengirimkan informasi status cluster ke Konsul. Oleh karena itu, dari Konsul Anda selalu dapat mengetahui konfigurasi saat ini dari gugus Patroni dan siapa pemimpinnya saat ini.

Untuk menghubungkan Patroni ke Konsul, cukup mempelajari dokumentasi resmi, yang mengatakan bahwa Anda perlu menentukan host dalam format http atau https, tergantung pada bagaimana kami bekerja dengan Konsul, dan skema koneksi, secara opsional:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
Ini terlihat sederhana, tetapi di sini jebakan dimulai. Dengan Konsul kami bekerja pada koneksi yang aman melalui https dan konfigurasi koneksi kami akan terlihat seperti ini:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Tapi itu tidak berhasil. Pada awalnya, Patroni tidak dapat terhubung ke Konsul, karena ia tetap mencoba mengikuti http.
Kode sumber untuk Patroni membantu mengatasi masalah tersebut. Untung itu ditulis dalam python. Ternyata parameter host tidak diuraikan sama sekali, dan protokol harus ditentukan dalam skema. Berikut ini adalah blok konfigurasi kerja untuk bekerja dengan Konsul bersama kami:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Konsul-templat
Jadi, kami telah memilih penyimpanan untuk konfigurasi. Sekarang Anda perlu memahami bagaimana PgBouncer akan mengubah konfigurasinya ketika mengubah pemimpin di kluster Patroni. Dokumentasi tidak menjawab pertanyaan ini, karena di sana, pada prinsipnya, bekerja dengan PgBouncer tidak dijelaskan.
Dalam mencari solusi, kami menemukan sebuah artikel (sayangnya, saya tidak ingat namanya), di mana ada tertulis bahwa template-Konsul banyak membantu dalam menghubungkan PgBouncer dan Patroni. Ini mendorong kami untuk mempelajari karya Templat Konsul.
Ternyata template-Consul secara konstan memonitor konfigurasi cluster PostgreSQL di Consul. Ketika pemimpin berubah, ia memperbarui konfigurasi PgBouncer dan mengirimkan perintah untuk mem-boot ulang.
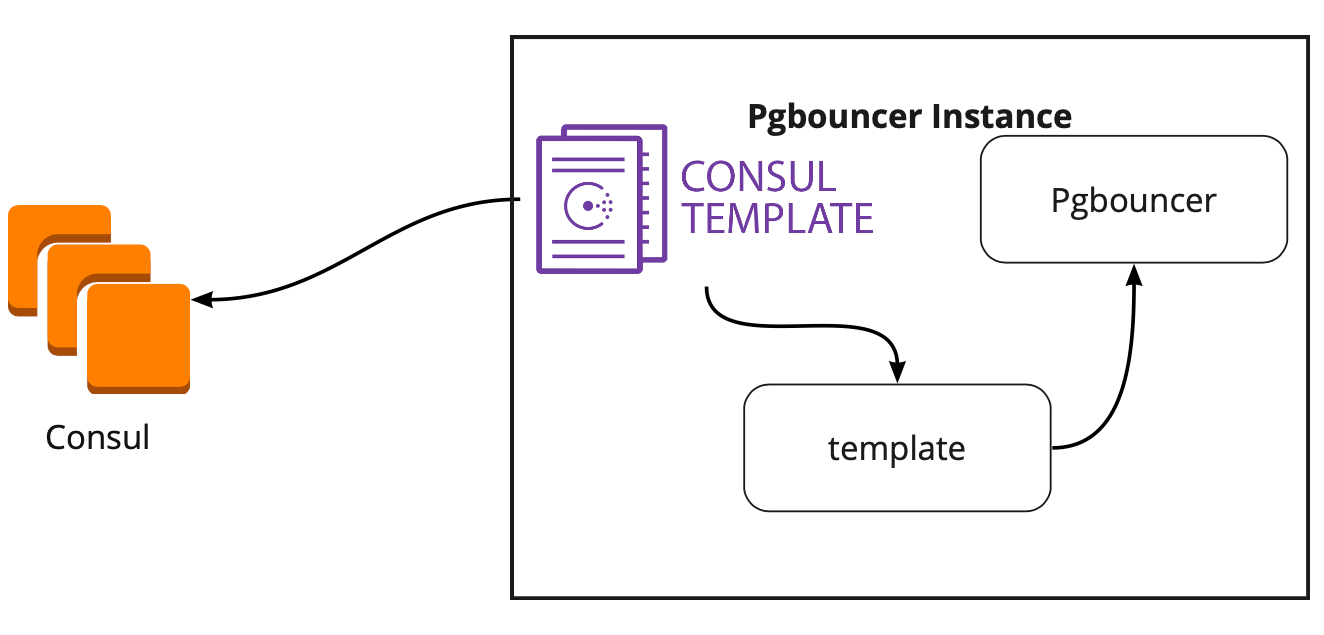
Kelebihan besar templat adalah bahwa ia disimpan sebagai kode, jadi ketika menambahkan pecahan baru, cukup membuat komit baru dan memperbarui templat dalam mode otomatis, mendukung prinsip Infrastruktur sebagai kode.
Arsitektur baru dengan Patroni
Hasilnya, kami mendapat skema kerja ini:

Semua server aplikasi mengakses penyeimbang → dua instance PgBuncuncer berada di belakangnya → pada setiap contoh, onsul-templat diluncurkan, yang memantau status masing-masing cluster Patroni dan memantau relevansi konfigurasi PgBouncer, yang mengirimkan permintaan kepada pemimpin saat ini masing-masing cluster.
Pengujian manual
Sebelum meluncurkan program, kami meluncurkan sirkuit ini pada lingkungan uji kecil dan memeriksa operasi switching otomatis. Mereka membuka papan, memindahkan stiker dan pada saat itu "membunuh" pemimpin gugus itu. Di AWS, matikan instance melalui konsol.

Stiker kembali kembali dalam 10-20 detik, dan kemudian mulai bergerak dengan normal. Ini berarti bahwa kluster Patroni bekerja dengan benar: itu mengubah pemimpin, mengirim informasi ke Konsul, dan template-Konsul segera mengambil informasi ini, mengganti konfigurasi PgBouncer dan mengirim perintah untuk memuat ulang.
Bagaimana cara bertahan hidup di bawah beban tinggi dan mempertahankan downtime minimum?
Semuanya bekerja dengan baik! Tetapi muncul pertanyaan baru: Bagaimana cara kerjanya di bawah beban tinggi? Bagaimana cara menggulung semuanya dengan cepat dan aman ke dalam produksi?
Lingkungan pengujian tempat kami melakukan pengujian beban membantu kami menjawab pertanyaan pertama. Ini benar-benar identik dengan produksi dalam arsitektur dan telah menghasilkan data uji, yang kira-kira sama volumenya dengan produksi. Kami memutuskan untuk hanya "membunuh" salah satu penyihir PostgreSQL selama pengujian dan melihat apa yang terjadi. Tetapi sebelum itu, penting untuk memeriksa penggulungan otomatis, karena pada lingkungan ini kami memiliki beberapa pecahan PostgreSQL, jadi kami akan mendapatkan pengujian skrip konfigurasi yang sangat baik sebelum menjual.
Kedua tugas terlihat ambisius, tetapi kami memiliki PostgreSQL 9.6. Mungkin kita akan segera meningkatkan ke 11.2?
Kami memutuskan untuk melakukan ini dalam 2 tahap: upgrade pertama ke 11.2, lalu luncurkan Patroni.
Pembaruan PostgreSQL
Untuk meningkatkan versi PostgreSQL dengan cepat, Anda harus menggunakan opsi
-k , yang menciptakan tautan keras pada disk dan tidak perlu menyalin data Anda. Dengan basis 300-400 GB, pembaruan membutuhkan waktu 1 detik.
Kami memiliki banyak pecahan, sehingga pembaruan perlu dilakukan secara otomatis. Untuk melakukan ini, kami menulis buku pedoman Ansible, yang melakukan seluruh proses pembaruan untuk kami:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
Penting untuk dicatat di sini bahwa sebelum memulai pemutakhiran, perlu untuk mengeksekusinya dengan parameter
--check untuk memastikan kemungkinan peningkatan. Script kami juga membuat substitusi konfigurasi untuk peningkatan. Script yang kami selesaikan dalam 30 detik, ini adalah hasil yang sangat baik.
Luncurkan Patroni
Untuk mengatasi masalah kedua, lihat saja konfigurasi Patroni. Dalam repositori resmi ada contoh konfigurasi dengan initdb, yang bertanggung jawab untuk menginisialisasi database baru ketika Patroni pertama kali diluncurkan. Tetapi karena kami memiliki database yang sudah jadi, kami baru saja menghapus bagian ini dari konfigurasi.
Ketika kami mulai menginstal Patroni pada cluster PostgreSQL yang sudah jadi dan menjalankannya, kami menghadapi masalah baru: kedua server mulai sebagai pemimpin. Patroni tidak tahu apa-apa tentang keadaan awal cluster dan mencoba memulai kedua server sebagai dua cluster terpisah dengan nama yang sama. Untuk mengatasi masalah ini, hapus direktori data pada slave:
rm -rf /var/lib/postgresql/
Ini harus dilakukan hanya pada budak!Saat menghubungkan replika bersih, Patroni membuat pemimpin cadangan dan mengembalikannya ke replika, dan kemudian mengejar status saat ini dengan wal-log.
Kesulitan lain yang kami temui adalah bahwa semua cluster PostgreSQL disebut main secara default. Ketika setiap cluster tidak tahu apa-apa tentang yang lain, ini normal. Tetapi ketika Anda ingin menggunakan Patroni, maka semua cluster harus memiliki nama yang unik. Solusinya adalah mengubah nama cluster di konfigurasi PostgreSQL.
Uji beban
Kami meluncurkan tes yang mensimulasikan pekerjaan pengguna di papan tulis. Ketika beban mencapai nilai rata-rata harian kami, kami mengulangi tes yang sama persis, kami mematikan satu contoh dengan pemimpin PostgreSQL. Kegagalan otomatis berfungsi seperti yang kami harapkan: Patroni mengubah pemimpin, Konsul-templat memperbarui konfigurasi PgBouncer dan mengirim perintah untuk memuat ulang. Menurut grafik kami di Grafana, jelas bahwa ada keterlambatan 20-30 detik dan sejumlah kecil kesalahan dari server terkait dengan koneksi ke database. Ini adalah situasi yang normal, nilai-nilai tersebut berlaku untuk kegagalan kami dan jelas lebih baik daripada downtime layanan.
Output Patroni untuk produksi
Hasilnya, kami mendapat paket berikut:
- Menyebarkan Templat-Konsul ke server PgBouncer dan meluncurkan;
- Pembaruan PostgreSQL ke versi 11.2;
- Perubahan nama cluster;
- Memulai cluster Patroni.
Pada saat yang sama, skema kami memungkinkan Anda untuk membuat item pertama di hampir setiap saat, kami dapat bergantian menghapus setiap PgBouncer dari pekerjaan dan menjalankan penyebaran di atasnya dan menjalankan template konsul. Jadi kami melakukannya.
Untuk pengguliran cepat, kami menggunakan Ansible, karena kami telah memeriksa semua buku pedoman pada lingkungan pengujian, dan waktu eksekusi skrip lengkap adalah 1,5 hingga 2 menit untuk setiap pecahan. Kami dapat meluncurkan semuanya secara bergantian untuk setiap beling tanpa menghentikan layanan kami, tetapi kami harus mematikan setiap PostgreSQL selama beberapa menit. Dalam hal ini, pengguna yang datanya di beling ini tidak dapat sepenuhnya bekerja saat ini, dan ini tidak dapat diterima oleh kami.
Jalan keluar dari situasi ini adalah pemeliharaan terencana, yang berlangsung setiap 3 bulan. Ini adalah jendela untuk pekerjaan terjadwal ketika kami sepenuhnya mematikan layanan kami dan memperbarui instance database. Masih ada satu minggu tersisa sampai jendela berikutnya, dan kami memutuskan untuk hanya menunggu dan mempersiapkan lebih lanjut. Selama menunggu, kami juga memastikan: untuk setiap beling PostgreSQL, kami mengangkat replika cadangan jika terjadi kegagalan untuk menyimpan data terbaru, dan menambahkan contoh baru untuk setiap beling, yang seharusnya menjadi replika baru dalam gugus Patroni, agar tidak mengeksekusi perintah untuk menghapus data. . Semua ini membantu meminimalkan risiko kesalahan.

Kami memulai kembali layanan kami, semuanya berjalan sebagaimana mestinya, pengguna terus bekerja, tetapi pada grafik kami melihat beban tinggi yang tidak normal pada server Konsul.
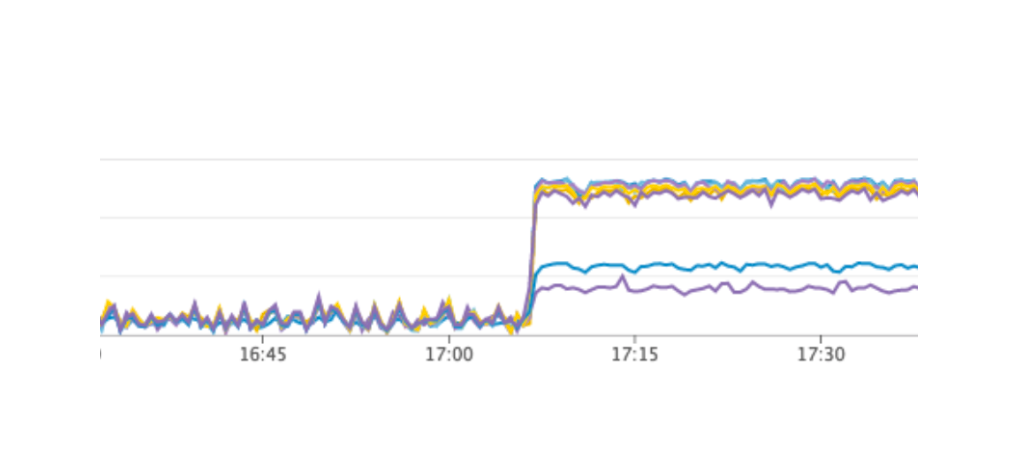
Mengapa kita tidak melihatnya di lingkungan pengujian? Masalah ini menggambarkan dengan sangat baik bahwa perlu untuk mengikuti prinsip Infrastruktur sebagai kode dan memperbaiki seluruh infrastruktur, dimulai dengan lingkungan pengujian dan diakhiri dengan produksi. Kalau tidak, sangat mudah untuk mendapatkan jenis masalah yang kita dapatkan. Apa yang terjadi Konsul pertama kali muncul pada produksi, dan kemudian pada lingkungan pengujian, sebagai hasilnya, pada lingkungan pengujian, versi Konsul lebih tinggi daripada pada produksi. Hanya di salah satu rilis, kebocoran CPU terpecahkan saat bekerja dengan konsul-template. Karena itu, kami baru saja memperbarui Konsul, sehingga menyelesaikan masalah.
Mulai kembali kluster Patroni
Namun, kami mendapat masalah baru yang bahkan tidak kami sadari. Saat memperbarui Konsul, kami cukup menghapus simpul Konsul dari kluster menggunakan perintah cuti konsul → Patroni terhubung ke server Konsul lain → semuanya berfungsi. Tetapi ketika kami mencapai contoh terakhir dari cluster Konsul dan mengirim perintah cuti konsul untuk itu, semua cluster Patroni hanya restart, dan dalam log kami melihat kesalahan berikut:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
Cluster Patroni tidak dapat memperoleh informasi tentang clusternya dan memulai kembali.
Untuk menemukan solusi, kami menghubungi penulis Patroni melalui masalah di github. Mereka menyarankan peningkatan pada file konfigurasi kami:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
Kami dapat mengulangi masalah pada lingkungan pengujian dan menguji parameter ini di sana, tetapi, sayangnya, mereka tidak berhasil.
Masalahnya masih belum terselesaikan. Kami berencana untuk mencoba solusi berikut:
- Gunakan Konsul-agen pada setiap instance dari cluster Patroni;
- Perbaiki masalah dalam kode.
Kami memahami tempat terjadinya kesalahan: masalahnya mungkin menggunakan batas waktu default, yang tidak ditimpa melalui file konfigurasi. Ketika server Konsul terakhir dihapus dari cluster, seluruh cluster Konsul membeku selama lebih dari satu detik, karena Patroni ini tidak bisa mendapatkan keadaan cluster dan sepenuhnya me-restart seluruh cluster.
Untungnya, kami tidak menemukan kesalahan lagi.
Hasil menggunakan Patroni
Setelah peluncuran Patroni yang berhasil, kami menambahkan replika tambahan di setiap kluster. Sekarang di setiap cluster ada kemiripan kuorum: satu pemimpin dan dua replika - untuk memastikan terhadap kasus otak-terpisah ketika beralih.
Patroni telah bekerja di produksi selama lebih dari tiga bulan. Selama waktu ini, dia sudah berhasil membantu kami. Baru-baru ini, pemimpin salah satu cluster meninggal di AWS, kegagalan otomatis bekerja, dan pengguna terus bekerja. Patroni menyelesaikan tugas utamanya.
Ringkasan kecil tentang penggunaan Patroni:- Kemudahan perubahan konfigurasi. Cukup untuk mengubah konfigurasi pada satu instance dan akan ditarik ke seluruh cluster. Jika reboot diperlukan untuk menerapkan konfigurasi baru, Patroni akan melaporkan ini. Patroni dapat me-restart seluruh cluster dengan satu perintah, yang juga sangat nyaman.
- Kegagalan otomatis berfungsi dan telah berhasil membantu kami.
- Pembaruan PostgreSQL tanpa downtime aplikasi. Pertama-tama Anda harus memutakhirkan replika ke versi baru, kemudian mengubah pemimpin di kluster Patroni dan memperbarui pemimpin lama. Dalam hal ini, pengujian yang diperlukan untuk kegagalan otomatis terjadi.