Pengguna ClickHouse tahu bahwa keunggulan utamanya adalah kecepatan tinggi memproses kueri analitik. Tetapi bagaimana kita bisa membuat pernyataan seperti itu? Ini harus didukung oleh tes kinerja tepercaya. Kami akan membicarakannya hari ini.
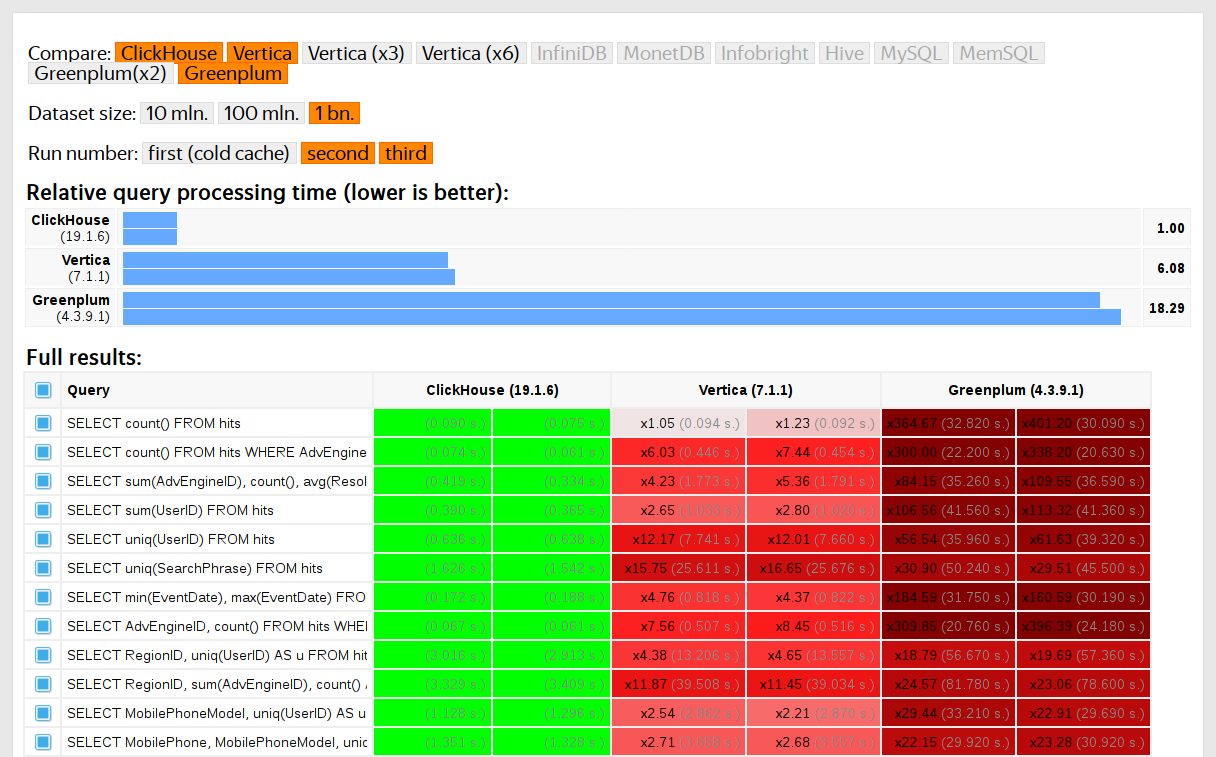
Kami mulai melakukan tes tersebut pada tahun 2013, jauh sebelum produk menjadi tersedia dalam sumber terbuka. Seperti sekarang, maka kami paling tertarik dengan kecepatan layanan data Yandex.Metrica. Kami sudah menyimpan data di ClickHouse sejak Januari 2009. Sebagian dari data telah ditulis ke database sejak 2012, dan sebagian - telah
dikonversi dari
OLAPServer dan Metrage - struktur data yang digunakan di Yandex.Metrica sebelumnya. Karenanya, untuk pengujian, kami mengambil subset pertama yang tersedia dari 1 miliar data tampilan halaman. Tidak ada pertanyaan di Metric, dan kami sendiri mengajukan pertanyaan yang paling menarik bagi kami (semua jenis penyaringan, agregasi, dan penyortiran).
ClickHouse diuji dibandingkan dengan sistem serupa, misalnya, Vertica dan MonetDB. Sejujurnya, ini dilakukan oleh seorang karyawan yang sebelumnya tidak pernah menjadi pengembang ClickHouse, dan kasus-kasus tertentu dalam kode tidak dioptimalkan sampai hasilnya diperoleh. Demikian pula, kami mendapat set data untuk tes fungsional.
Setelah ClickHouse bergabung dengan open source pada tahun 2016, ada lebih banyak pertanyaan untuk pengujian.
Kerugian tes pada data hak milik
Tes kinerja:
- Mereka tidak dapat direproduksi dari luar, karena mereka membutuhkan data pribadi yang tidak dapat dipublikasikan. Untuk alasan yang sama, beberapa tes fungsional tidak tersedia untuk pengguna eksternal.
- Jangan berkembang. Ada kebutuhan untuk ekspansi yang signifikan dari set mereka, sehingga dimungkinkan untuk memverifikasi secara terpisah perubahan kecepatan masing-masing bagian sistem.
- Mereka tidak menjalankan komitmen untuk permintaan kumpulan, pengembang eksternal tidak dapat memeriksa kode mereka untuk regresi kinerja.
Anda dapat memecahkan masalah ini - membuang tes lama dan membuat yang baru berdasarkan data terbuka. Di antara data terbuka, Anda dapat mengambil
data tentang penerbangan ke AS ,
naik taksi di New York, atau menggunakan tolok ukur siap pakai TPC-H, TPC-DS,
Star Schema Benchmark . Ketidaknyamanannya adalah bahwa data ini jauh dari data Yandex.Metrica, dan saya ingin menyimpan permintaan pengujian.
Penting untuk menggunakan data nyata.
Anda perlu menguji kinerja layanan hanya pada data nyata dari produksi. Mari kita lihat beberapa contoh.
Contoh 1Misalkan Anda mengisi basis data dengan nomor pseudorandom yang didistribusikan secara merata. Dalam hal ini, kompresi data tidak akan berfungsi. Tetapi kompresi data adalah properti penting untuk DBMS analitik. Memilih algoritma kompresi yang tepat dan cara yang tepat untuk mengintegrasikannya ke dalam sistem adalah tugas non-sepele di mana tidak ada satu solusi yang benar, karena kompresi data memerlukan kompromi antara kecepatan kompresi dan dekompresi dan rasio kompresi potensial. Sistem yang tidak tahu cara kompres kehilangan data dijamin. Tetapi jika kita menggunakan nomor pseudorandom yang didistribusikan secara seragam untuk pengujian, faktor ini tidak dipertimbangkan, dan semua hasil lainnya akan terdistorsi.
Kesimpulan: data uji harus memiliki rasio kompresi yang realistis.
Tentang optimasi algoritma kompresi data di ClickHouse yang saya bicarakan di
posting sebelumnya .
Contoh 2Mari kita tertarik pada kecepatan query SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Ini adalah permintaan khas untuk Yandex.Metrica. Apa yang penting untuk kecepatannya?
- Bagaimana GROUP BY dilakukan ?
- Struktur data apa yang digunakan untuk menghitung fungsi agregat uniq.
- Berapa banyak RegionID yang berbeda dan berapa banyak RAM yang dibutuhkan oleh setiap negara bagian dari fungsi uniq.
Tetapi juga sangat penting bahwa jumlah data untuk berbagai daerah didistribusikan secara tidak merata. (Mungkin, ini didistribusikan sesuai dengan undang-undang kekuasaan. Saya membuat grafik dalam skala log-log, tapi saya tidak yakin.) Dan jika demikian, penting bagi kita bahwa keadaan fungsi agregat uniq dengan sejumlah kecil nilai menggunakan sedikit memori. Ketika ada banyak kunci agregasi yang berbeda, hitungannya pergi ke unit byte. Bagaimana cara mendapatkan data yang dihasilkan yang memiliki semua properti ini? Tentu saja, lebih baik menggunakan data nyata.
Banyak DBMS menerapkan struktur data HyperLogLog untuk perkiraan perhitungan COUNT (DISTINCT), tetapi mereka semua bekerja relatif buruk karena struktur data ini menggunakan jumlah memori yang tetap. Dan ClickHouse memiliki fungsi yang menggunakan
kombinasi dari tiga struktur data yang berbeda , tergantung pada ukuran set.
Kesimpulan: data uji harus mewakili sifat-sifat distribusi nilai dalam data - kardinalitas (jumlah nilai dalam kolom) dan kardinalitas timbal balik dari beberapa kolom yang berbeda.
Contoh 3Baiklah, mari kita uji kinerja bukan dari DBMS analitik ClickHouse, tetapi sesuatu yang lebih sederhana, misalnya, tabel hash. Untuk tabel hash, memilih fungsi hash yang tepat sangat penting. Untuk std :: unordered_map, ini sedikit kurang penting, karena ini adalah tabel hash berbasis rantai, dan bilangan prima digunakan sebagai ukuran array. Dalam implementasi pustaka standar dalam gcc dan dentang, fungsi hash sepele digunakan sebagai fungsi hash default untuk tipe numerik. Tetapi std :: unordered_map bukanlah pilihan terbaik ketika kita ingin mendapatkan kecepatan maksimum. Saat menggunakan tabel hash pengalamatan terbuka, pilihan fungsi hash yang tepat menjadi faktor penentu, dan kita tidak bisa menggunakan fungsi hash trivial.
Sangat mudah untuk menemukan tes kinerja tabel hash pada data acak, tanpa mempertimbangkan fungsi hash yang digunakan. Juga mudah untuk menemukan tes fungsi hash dengan penekanan pada kecepatan perhitungan dan beberapa kriteria kualitas, bagaimanapun, terpisah dari struktur data yang digunakan. Tetapi kenyataannya adalah bahwa tabel hash dan HyperLogLog memerlukan kriteria kualitas yang berbeda untuk fungsi hash.
Baca lebih lanjut tentang ini di laporan
"Bagaimana Hash Tabel di ClickHouse Diatur" . Agak ketinggalan jaman karena tidak mempertimbangkan
tabel swiss .
Tantangan
Kami ingin mendapatkan data untuk pengujian kinerja pada struktur yang sama dengan data Yandex.Metrica, yang menyimpan semua properti penting untuk tolok ukur, tetapi agar tidak ada jejak pengunjung situs nyata yang tertinggal dalam data ini. Artinya, data harus dianonimkan, dan yang berikut harus disimpan:
- rasio kompresi
- kardinalitas (jumlah nilai yang berbeda),
- kardinalitas timbal balik dari beberapa kolom yang berbeda,
- sifat-sifat distribusi probabilistik dengan mana data dapat dimodelkan (misalnya, jika kami percaya bahwa wilayah didistribusikan menurut hukum daya, maka eksponen - parameter distribusi - untuk data buatan harus kira-kira sama dengan yang asli).
Dan apa yang dibutuhkan agar data memiliki rasio kompresi yang sama? Misalnya, jika LZ4 digunakan, maka substring dalam data biner harus diulangi pada jarak yang kira-kira sama dan pengulangan harus kira-kira sama panjangnya. Untuk ZSTD, kecocokan entropi byte ditambahkan.
Sasaran maksimum: untuk menyediakan alat bagi orang luar, yang dengannya setiap orang dapat menganonimkan kumpulan data mereka untuk publikasi. Sehingga kami melakukan debug dan menguji kinerja pada data orang lain yang mirip dengan data dari produksi. Dan saya ingin menarik untuk menonton data yang dihasilkan.
Ini adalah pernyataan tidak resmi dari masalahnya. Namun, tidak ada yang akan memberikan pernyataan formal.
Upaya untuk dipecahkan
Pentingnya tugas ini tidak boleh berlebihan bagi kita. Sebenarnya, itu tidak pernah ada dalam rencana dan bahkan tidak ada yang akan melakukannya. Saya hanya tidak menyerah berharap bahwa sesuatu akan muncul dengan sendirinya, dan tiba-tiba saya akan memiliki suasana hati yang baik dan banyak hal yang dapat ditunda sampai nanti.
Model Probabilistik Eksplisit
Gagasan pertama adalah memilih keluarga distribusi probabilitas yang memodelkannya untuk setiap kolom tabel. Kemudian, berdasarkan statistik data, pilih parameter pemasangan model dan hasilkan data baru menggunakan distribusi yang dipilih. Anda dapat menggunakan generator angka pseudo-acak dengan seed yang telah ditentukan untuk mendapatkan hasil yang dapat direproduksi.
Untuk bidang teks, Anda dapat menggunakan rantai Markov - model yang dapat dipahami yang dapat digunakan untuk membuat implementasi yang efektif.
Benar, beberapa trik diperlukan:
- Kami ingin menjaga kontinuitas deret waktu - yang berarti bahwa untuk beberapa tipe data perlu dimodelkan bukan nilai itu sendiri, tetapi perbedaan antara yang bertetangga.
- Untuk mensimulasikan kardinalitas bersyarat dari kolom (misalnya, bahwa biasanya ada beberapa alamat IP per pengunjung pengenal), Anda juga perlu menuliskan dependensi antara kolom secara eksplisit (misalnya, untuk menghasilkan alamat IP, hash dari pengenal pengunjung digunakan, tetapi juga beberapa data pseudo-acak lainnya ditambahkan).
- Tidak jelas cara mengekspresikan ketergantungan yang satu pengunjung pada waktu yang sama sering mengunjungi URL dengan domain yang cocok.
Semua ini disajikan dalam bentuk program di mana semua distribusi dan dependensi adalah kode keras - yang disebut "skrip C ++". Namun, model Markov masih dihitung dari jumlah statistik, smoothing dan roughening menggunakan noise. Saya mulai menulis skrip ini, tetapi karena suatu alasan, setelah saya secara eksplisit menulis model untuk sepuluh kolom, tiba-tiba menjadi membosankan tak tertahankan. Dan di tabel hits di Yandex.Metrica kembali pada tahun 2012 ada lebih dari 100 kolom.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Pendekatan terhadap tugas ini gagal. Jika saya mendekatinya lebih rajin, pasti naskahnya sudah ditulis.
Keuntungan:
Kekurangan:
- kompleksitas implementasi,
- solusi yang diterapkan hanya cocok untuk satu jenis data.
Dan saya ingin solusi yang lebih umum - sehingga dapat diterapkan tidak hanya untuk data Yandex.Metrica, tetapi juga untuk mengaburkan data lainnya.
Namun, perbaikan mungkin dilakukan di sini. Anda tidak dapat memilih model secara manual, tetapi menerapkan katalog model dan memilih yang terbaik di antara mereka (paling cocok + semacam regularisasi). Atau mungkin Anda dapat menggunakan model Markov untuk semua jenis bidang, dan bukan hanya untuk teks. Ketergantungan antar data juga dapat dipahami secara otomatis. Untuk melakukan ini, Anda perlu menghitung
entropi relatif (jumlah relatif informasi) antara kolom, atau lebih sederhana, kardinalitas relatif (seperti "berapa banyak nilai A yang berbeda rata-rata untuk nilai tetap B") untuk setiap pasangan kolom. Ini akan memperjelas, misalnya, bahwa URLDomain sepenuhnya bergantung pada URL, dan bukan sebaliknya.
Tetapi saya juga menolak ide ini, karena ada terlalu banyak pilihan untuk apa yang perlu diperhitungkan, dan akan membutuhkan waktu lama untuk menulis.
Jaringan saraf
Saya sudah mengatakan betapa pentingnya tugas ini bagi kita. Tidak ada yang bahkan berpikir untuk membuat creep ke implementasinya. Untungnya, kolega Ivan Puzyrevsky kemudian bekerja sebagai guru di HSE dan pada saat yang sama mengembangkan inti YT. Dia bertanya apakah saya memiliki tugas menarik yang dapat ditawarkan kepada siswa sebagai topik diploma. Saya menawarkan kepadanya yang ini dan dia meyakinkan saya bahwa itu cocok. Jadi saya memberikan tugas ini kepada orang baik "dari jalan" - Sharif Anvardinov (NDA ditandatangani untuk bekerja dengan data).
Dia bercerita tentang semua idenya, tetapi yang paling penting, dia menjelaskan bahwa masalahnya bisa diselesaikan dengan cara apa pun. Dan pilihan yang bagus adalah menggunakan pendekatan yang sama sekali tidak saya mengerti: misalnya, menghasilkan dump data teks menggunakan LSTM. Itu tampak menggembirakan berkat
artikel Efektivitas Yang Tidak Beralasan dari Jaringan Syaraf Berulang , yang kemudian menarik perhatian saya.
Fitur pertama dari tugas ini adalah Anda harus menghasilkan data terstruktur, bukan hanya teks. Tidak jelas apakah jaringan saraf berulang akan dapat menghasilkan data dengan struktur yang diinginkan. Ada dua cara untuk menyelesaikan ini. Yang pertama adalah menggunakan model terpisah untuk menghasilkan struktur dan untuk "pengisi": jaringan saraf seharusnya hanya menghasilkan nilai. Tetapi opsi ini ditunda sampai nanti, setelah itu mereka tidak pernah melakukannya. Cara kedua adalah dengan hanya menghasilkan dump TSV sebagai teks. Praktek telah menunjukkan bahwa di bagian teks dari baris tidak akan sesuai dengan struktur, tetapi baris ini dapat dibuang saat memuat.
Fitur kedua - jaringan saraf berulang menghasilkan urutan data, dan dependensi dalam data hanya dapat mengikuti urutan urutan ini. Namun dalam data kami, mungkin urutan kolom dibalik sehubungan dengan dependensi di antara mereka. Kami tidak melakukan apa pun dengan fitur ini.
Menjelang musim panas, skrip Python yang berfungsi pertama kali muncul yang menghasilkan data. Pada pandangan pertama, kualitas data layak:
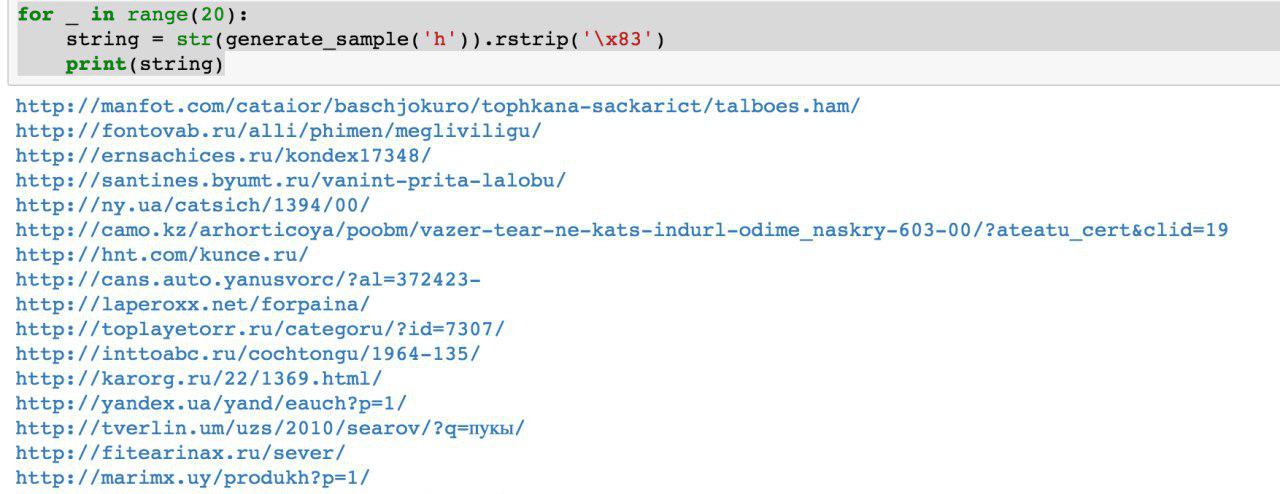
Benar, kesulitan terungkap:
- Ukuran model ini sekitar satu gigabyte. Dan kami mencoba membuat model untuk data yang ukurannya di urutan beberapa gigabyte (untuk pemula). Fakta bahwa model yang dihasilkan sangat besar menimbulkan kekhawatiran: tiba-tiba akan mungkin untuk mendapatkan data nyata dari tempat ia dilatih. Kemungkinan besar tidak. Tapi saya tidak mengerti pembelajaran mesin dan jaringan saraf dan saya belum membaca kode Python dari orang ini, jadi bagaimana saya bisa yakin? Lalu ada artikel tentang cara mengompres jaringan saraf tanpa kehilangan kualitas, tetapi ini dibiarkan tanpa implementasi. Di satu sisi, ini tidak terlihat seperti masalah - Anda dapat menolak untuk menerbitkan model dan hanya mempublikasikan data yang dihasilkan. Di sisi lain, dalam kasus pelatihan ulang, data yang dihasilkan dapat berisi beberapa bagian dari data sumber.
- Pada mesin tunggal dengan CPU, laju pembuatan data sekitar 100 baris per detik. Kami memiliki tugas - untuk menghasilkan setidaknya satu miliar baris. Perhitungan menunjukkan bahwa ini tidak dapat dilakukan sebelum pembelaan ijazah. Dan menggunakan perangkat keras lain tidak praktis, karena saya memiliki tujuan - untuk membuat alat pembuatan data tersedia untuk digunakan secara luas.
Sharif mencoba mempelajari kualitas data dengan membandingkan statistik. Sebagai contoh, saya menghitung frekuensi dengan simbol yang berbeda muncul di sumber dan dalam data yang dihasilkan. Hasilnya menakjubkan - karakter yang paling umum adalah Ð dan Ñ.
Jangan khawatir - dia mempertahankan diploma dengan sempurna, setelah itu kita dengan aman melupakan pekerjaan ini.
Mutasi Data Terkompresi
Misalkan pernyataan masalah dikurangi menjadi satu titik: Anda perlu menghasilkan data yang rasio kompresinya akan persis sama dengan data asli, sedangkan data harus dikompresi pada kecepatan yang persis sama. Bagaimana cara melakukannya? Perlu mengedit byte data terkompresi secara langsung! Maka ukuran data yang dikompresi tidak akan berubah, tetapi data itu sendiri akan berubah. Ya, dan semuanya akan bekerja dengan cepat. Ketika ide ini muncul, saya langsung ingin mengimplementasikannya, meskipun fakta bahwa itu memecahkan beberapa masalah lain, bukan yang asli. Itu selalu terjadi.
Bagaimana cara mengedit file terkompresi secara langsung? Misalkan kita hanya tertarik pada LZ4. Data yang dikompres menggunakan LZ4 terdiri dari dua jenis instruksi:
- Literal: salin N byte berikutnya apa adanya.
- Cocok (cocok, cocok, panjang pengulangan minimum adalah 4): ulangi N byte yang ada di file pada jarak M.
Sumber data:
Hello world Hello .
Data terkompresi (bersyarat):
literals 12 "Hello world " match 5 12 .
Dalam file terkompresi, biarkan cocok apa adanya, dan dalam literal kami akan mengubah nilai byte. Akibatnya, setelah dekompresi, kami memperoleh file di mana semua urutan berulang setidaknya 4 juga diulang, dan diulang pada jarak yang sama, tetapi pada saat yang sama terdiri dari serangkaian byte yang berbeda (secara kiasan, tidak satu byte diambil dari file asli dalam file yang dimodifikasi) )
Tetapi bagaimana cara mengubah byte? Ini tidak jelas karena, selain jenis kolom, data juga memiliki struktur internal, implisit sendiri, yang ingin kami pertahankan. Misalnya, teks sering disimpan dalam pengkodean UTF-8 - dan kami ingin UTF-8 juga valid dalam data yang dihasilkan. Saya membuat heuristik sederhana untuk memenuhi beberapa kondisi:
- null byte dan karakter kontrol ASCII disimpan apa adanya,
- beberapa tanda baca tetap ada,
- ASCII diterjemahkan ke dalam ASCII, dan sisanya, bit yang paling signifikan disimpan (atau Anda dapat secara eksplisit menulis jika diset untuk panjang UTF-8 yang berbeda). Di antara satu kelas byte, nilai baru dipilih secara acak;
- dan juga untuk menyimpan fragmen
https:// dan sejenisnya, jika tidak semuanya terlihat konyol.
Keunikan dari pendekatan ini adalah bahwa data awal itu sendiri bertindak sebagai model untuk data, yang berarti bahwa model tersebut tidak dapat dipublikasikan. Ini memungkinkan Anda untuk menghasilkan jumlah data tidak lebih dari yang asli. Sebagai perbandingan, dalam pendekatan sebelumnya dimungkinkan untuk membuat model dan menghasilkan data dalam jumlah yang tidak terbatas.
Contoh untuk URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Hasilnya menyenangkan saya - itu menarik untuk melihat data. Tapi tetap saja, ada sesuatu yang salah. URL masih terstruktur, tetapi di beberapa tempat terlalu mudah untuk menebak yandex atau avito. Membuat heuristik yang terkadang mengatur ulang beberapa byte di beberapa tempat.
Pertimbangan lainnya mengkhawatirkan. Misalnya, informasi sensitif dapat direpresentasikan dalam kolom tipe FixedString dalam bentuk biner dan untuk beberapa alasan terdiri dari karakter kontrol ASCII dan tanda baca, yang saya putuskan untuk disimpan. Dan saya tidak mempertimbangkan tipe data.
Masalah lain: jika data tipe "panjang, nilai" disimpan dalam satu kolom (ini adalah bagaimana kolom tipe String disimpan), lalu bagaimana memastikan panjangnya tetap benar setelah mutasi? Ketika saya mencoba memperbaikinya, tugas itu segera menjadi tidak menarik.
Permutasi acak
Tetapi masalahnya tidak terpecahkan. Kami melakukan beberapa percobaan, dan itu semakin memburuk. Tetap hanya melakukan apa-apa dan membaca halaman acak di Internet, karena suasana hatinya sudah rusak. Untungnya, pada salah satu halaman ini adalah
penguraian algoritma untuk menampilkan adegan kematian protagonis di game Wolfenstein 3D.

Animasi yang indah - layar dipenuhi dengan darah. Artikel ini menjelaskan bahwa ini sebenarnya permutasi pseudo-acak. Permutasi acak - transformasi satu-ke-satu yang dipilih secara acak dari suatu set. Yaitu, tampilan seluruh rangkaian di mana hasil untuk argumen yang berbeda tidak diulang. Dengan kata lain, ini adalah cara untuk mengulangi semua elemen dari set secara acak. Ini adalah proses yang ditunjukkan pada gambar - kami mengecat setiap piksel, dipilih secara acak dari semua, tanpa pengulangan. Jika kita hanya memilih piksel acak pada setiap langkah, maka akan butuh waktu lama untuk melukiskan yang terakhir.
Gim ini menggunakan algoritma yang sangat sederhana untuk permutasi pseudo-acak -
LFSR (register umpan balik linier). Seperti generator bilangan pseudo-acak, permutasi acak, atau lebih tepatnya keluarga mereka, yang diparameterisasi oleh kunci, dapat kuat secara kriptografis - inilah yang kita perlukan untuk mengonversi data. Meskipun mungkin ada detail yang tidak jelas. Sebagai contoh, enkripsi kriptografis yang kuat dari N byte ke N byte dengan kunci pra-tetap dan vektor inisialisasi, tampaknya, dapat digunakan sebagai permutasi pseudo-acak dari banyak string N-byte. Memang, transformasi semacam itu adalah satu-ke-satu dan terlihat acak. Tetapi jika kita menggunakan transformasi yang sama untuk semua data kita, maka hasilnya dapat dianalisis, karena vektor inisialisasi dan nilai-nilai kunci yang sama digunakan beberapa kali. Ini mirip dengan mode cipher blok
Codebook Elektronik .
Apa cara untuk mendapatkan permutasi pseudo-acak? Anda dapat mengambil transformasi sederhana, satu-ke-satu dan merakit fungsi yang cukup kompleks dari mereka yang akan terlihat acak. Biarkan saya memberi Anda contoh dari beberapa transformasi satu-ke-satu favorit saya:
- perkalian dengan angka ganjil (mis. prime besar) dalam aritmatika komplemen dua,
- xor-shift:
x ^= x >> N , - CRC-N, di mana N adalah jumlah bit argumen.
Jadi, misalnya, dari tiga operasi perkalian dan dua operasi xor-shift, finalizer
murmurhash dirakit . Operasi ini adalah permutasi pseudo-acak. Tapi untuk jaga-jaga, saya perhatikan bahwa fungsi hash, bahkan N bit dalam N bit, tidak harus saling unik.
Atau inilah
contoh lain yang menarik
dari teori bilangan dasar dari situs Jeff Preshing.
Bagaimana kita bisa menggunakan permutasi pseudo-acak untuk tugas kita? Anda dapat mengonversi semua bidang angka menggunakan mereka. Maka akan dimungkinkan untuk mempertahankan semua kardinalitas dan kardinalitas timbal balik dari semua kombinasi bidang. Yaitu, COUNT (DISTINCT) akan mengembalikan nilai yang sama seperti sebelum konversi, dan dengan GROUP BY.
Perlu dicatat bahwa pelestarian semua kardinalitas sedikit bertentangan dengan pernyataan masalah anonimisasi data. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . Dan sebagainya. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
Hasil
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .