Halo, Habr! Nama saya Sasha dan saya adalah pengembang backend. Di waktu luang saya, saya belajar ML dan bersenang-senang dengan data hh.ru.
Artikel ini adalah tentang bagaimana kami mengotomatiskan proses penugasan tugas rutin untuk penguji menggunakan pembelajaran mesin.
Hh.ru memiliki layanan internal yang tugasnya dibuat di Jira (di dalam perusahaan itu disebut HHS) jika seseorang tidak bekerja atau bekerja dengan tidak benar. Selanjutnya, tugas-tugas ini ditangani secara manual oleh ketua tim QA Alexey dan ditugaskan ke tim yang bidang tanggung jawabnya termasuk kerusakan. Lesha tahu bahwa tugas yang membosankan harus dilakukan oleh robot. Karena itu, dia meminta bantuan saya tentang ML.

Grafik di bawah ini menunjukkan jumlah HHS per bulan. Kami berkembang dan jumlah tugas terus bertambah. Tugas terutama dibuat selama jam kerja, beberapa per hari, dan ini harus terus-menerus terganggu.
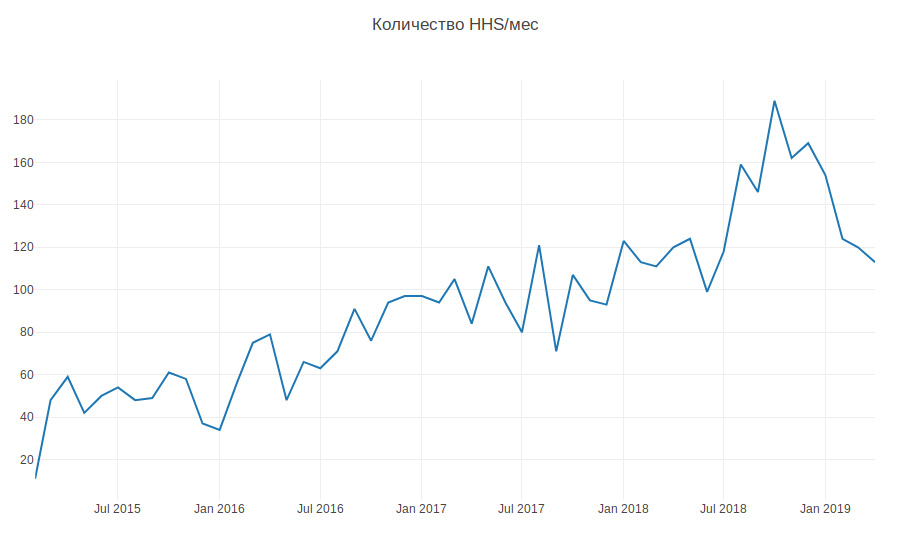
Jadi, menurut data historis, perlu untuk belajar bagaimana menentukan tim pengembangan yang menjadi milik HHS. Ini adalah tugas klasifikasi multi-kelas.
Data
Dalam tugas pembelajaran mesin, yang terpenting adalah data yang berkualitas. Hasil dari solusi untuk masalah tergantung pada mereka. Oleh karena itu, setiap tugas pembelajaran mesin harus dimulai dengan mempelajari data. Sejak awal 2015, kami telah mengakumulasikan sekitar 7000 tugas yang berisi informasi bermanfaat berikut:
- Ringkasan - Judul, Deskripsi Singkat
- Deskripsi - deskripsi lengkap masalah
- Label - daftar tag yang terkait dengan masalah
- Reporter adalah nama pencipta HHS. Fitur ini bermanfaat karena orang bekerja dengan sekumpulan fungsionalitas terbatas.
- Dibuat - Tanggal Pembuatan
- Penerima adalah orang yang kepadanya tugas tersebut diberikan. Variabel target akan dihasilkan dari atribut ini.
Mari kita mulai dengan variabel target. Pertama, setiap tim memiliki bidang tanggung jawab. Terkadang mereka berpotongan, terkadang satu tim dapat bersinggungan dalam pengembangan dengan yang lain. Keputusan akan didasarkan pada asumsi bahwa penerima hak, yang tetap dengan tugas pada saat penutupan, bertanggung jawab atas solusinya. Tapi kita perlu memprediksi bukan orang tertentu, tetapi tim. Untungnya, semua tim di Jira disimpan dan dapat dipetakan. Tetapi dengan definisi tim menurut seseorang, ada sejumlah masalah:
- tidak semua HHS terkait dengan masalah teknis, dan kami hanya tertarik pada tugas-tugas yang dapat ditugaskan ke tim pengembangan. Oleh karena itu, Anda perlu membuang tugas di mana penerima hak tidak dari departemen teknis
- terkadang tim tidak ada lagi. Mereka juga dikeluarkan dari set pelatihan.
- Sayangnya, orang tidak bekerja selamanya di perusahaan, dan terkadang mereka berpindah dari satu tim ke tim lainnya. Untungnya, kami berhasil mendapatkan sejarah perubahan dalam komposisi semua tim. Memiliki tanggal pembuatan HHS dan penerima tugas, Anda dapat menemukan tim mana yang terlibat dalam tugas pada waktu tertentu.
Setelah menyaring data yang tidak relevan, sampel pelatihan dikurangi menjadi 4.900 tugas.
Mari kita lihat distribusi tugas antar tim:
Tugas-tugas perlu didistribusikan antara 22 tim.
Tanda:
Ringkasan dan Deskripsi adalah bidang teks.
Pertama, mereka harus dibersihkan dari karakter berlebih. Untuk beberapa tugas, masuk akal untuk meninggalkan karakter yang membawa informasi, misalnya + dan #, untuk membedakan antara c ++ dan c #, tetapi dalam kasus ini saya memutuskan untuk hanya meninggalkan huruf dan angka, karena tidak menemukan di mana karakter lain mungkin berguna.
Kata-kata perlu lemmatized. Lemmatization adalah pengurangan suatu kata menjadi suatu lemma, bentuk normalnya (kosakata). Misalnya, kucing → kucing. Saya juga mencoba membendung, tetapi dengan lemmatisasi kualitasnya sedikit lebih tinggi. Stamming adalah proses menemukan dasar kata. Dasar ini disebabkan oleh algoritma (dalam implementasi yang berbeda mereka berbeda), misalnya, oleh kucing → kucing. Arti yang pertama dan kedua adalah menyandingkan kata-kata yang sama dalam berbagai bentuk. Saya menggunakan pembungkus python untuk
Yandex Mystem .
Selanjutnya, teks tersebut harus dibersihkan dari kata-kata berhenti yang tidak membawa muatan. Misalnya, “dulu”, “saya”, “belum”. Hentikan kata-kata yang biasa saya ambil dari
NLTK .
Pendekatan lain yang saya coba dalam tugas-tugas bekerja dengan teks adalah fragmentasi kata berdasarkan karakter. Misalnya, ada "pencarian". Jika Anda memecahnya menjadi komponen 3 karakter, Anda mendapatkan kata "poi", "ois", "gugatan". Ini membantu untuk mendapatkan koneksi tambahan. Misalkan ada kata "search". Pemesinan tidak mengarah pada "pencarian" dan "pencarian" dalam bentuk umum, tetapi partisi 3 karakter akan menyoroti bagian umum - "klaim".
Saya membuat dua token. Tokenizer adalah metode yang menerima teks pada input, dan output berisi daftar token - komponen teks. Yang pertama menyoroti kata dan angka lemmatized. Yang kedua hanya menyoroti kata-kata lemmatized, yang dibagi menjadi 3 karakter, yaitu pada output, ia memiliki daftar token tiga karakter.
Tokenizer digunakan dalam
TfidfVectorizer , yang digunakan untuk mengubah data teks (dan tidak hanya) menjadi representasi vektor berdasarkan
tf-idf . Daftar baris diumpankan ke input, dan pada output kita mendapatkan matriks M oleh N, di mana M adalah jumlah baris dan N adalah jumlah tanda. Setiap fitur adalah respons frekuensi dari suatu kata dalam dokumen, di mana frekuensinya didenda jika kata tersebut muncul berulang kali di semua dokumen. Berkat parameter ngram_range TfidfVectorizer, saya menambahkan
bigrams dan trigram sebagai atribut.
Saya juga mencoba menggunakan kata embeddings yang diperoleh dengan Word2vec sebagai fitur tambahan. Embedding adalah representasi vektor dari sebuah kata. Untuk setiap teks, saya meratakan embeddings dari semua kata-katanya. Tetapi ini tidak memberikan peningkatan, jadi saya menolak tanda-tanda ini.
Untuk Label,
CountVectorizer digunakan. Baris dengan tag diumpankan ke input, dan pada output kita memiliki matriks di mana baris sesuai dengan tugas dan kolom sesuai dengan tag. Setiap sel berisi jumlah kemunculan tag dalam tugas. Dalam kasus saya, ini adalah 1 atau 0.
LabelBinarizer muncul untuk Reporter. Ini binarizes atribut satu-ke-semua. Hanya ada satu pencipta untuk setiap tugas. Di pintu masuk LabelBinarizer, daftar pembuat tugas dikirimkan, dan hasilnya adalah matriks, di mana barisnya adalah tugas dan kolom sesuai dengan nama-nama pembuat tugas. Ternyata di setiap baris ada "1" di kolom yang sesuai dengan pencipta, dan sisanya - "0".
Untuk Dibuat, perbedaan hari antara tanggal tugas dibuat dan tanggal saat ini dipertimbangkan.
Hasilnya, tanda-tanda berikut diperoleh:
- tf-idf untuk Ringkasan dalam kata-kata dan angka (4855, 4593)
- tf-idf untuk Ringkasan pada tiga partisi karakter (4855, 15518)
- tf-idf untuk Deskripsi dalam kata-kata dan angka (4855, 33297)
- tf-idf untuk Deskripsi pada partisi tiga karakter (4855, 75359)
- jumlah entri untuk Label (4855, 505)
- tanda biner untuk Reporter (4855, 205)
- tugas seumur hidup (4855, 1)
Semua tanda-tanda ini digabungkan menjadi satu matriks besar (4855, 129478), di mana pelatihan akan dilakukan.
Secara terpisah, perlu dicatat nama-nama tanda. Karena beberapa model pembelajaran mesin dapat mengidentifikasi fitur yang memiliki dampak terbesar pada pengenalan kelas, Anda perlu menggunakan ini. TfidfVectorizer, CountVectorizer, LabelBinarizer memiliki metode get_feature_names yang menampilkan daftar fitur yang urutannya sesuai dengan kolom matriks data.
Pemilihan Model Prediksi
Seringkali
XGBoost memberikan hasil yang baik. Saya mulai dengan itu. Tetapi saya menghasilkan sejumlah besar fitur, jumlah yang secara signifikan melebihi ukuran sampel pelatihan. Dalam hal ini, kemungkinan pelatihan ulang XGBoost tinggi. Hasilnya tidak terlalu bagus. Dimensi tinggi dicerna dengan baik
LogisticRegression . Dia menunjukkan kualitas yang lebih tinggi.
Saya juga mencoba sebagai latihan untuk membangun model pada jaringan saraf di Tensorflow menggunakan tutorial yang sangat baik
ini , tetapi ternyata lebih buruk daripada regresi logistik.
Pemilihan hiperparameter
Saya juga bermain dengan hyperparameter XGBoost dan Tensorflow, tetapi saya meninggalkannya di luar pos, karena hasil regresi logistik tidak melampaui. Akhirnya aku memutar semua pena yang ada. Semua parameter sebagai hasilnya tetap default, kecuali dua: solver = 'liblinear' dan C = 3.0
Parameter lain yang dapat mempengaruhi hasil adalah ukuran sampel pelatihan. Karena Saya berurusan dengan data historis, dan selama beberapa tahun sejarah dapat berubah secara serius, misalnya, tanggung jawab untuk sesuatu dapat pergi ke tim lain, maka data yang lebih baru dapat lebih berguna, dan data lama bahkan dapat menurunkan kualitas. Dalam hal ini, saya menemukan heuristik - semakin tua datanya, semakin sedikit kontribusi yang harus mereka buat untuk model pelatihan. Bergantung pada usia, data dikalikan dengan koefisien tertentu, yang diambil dari fungsinya. Saya menghasilkan beberapa fungsi untuk melemahkan data dan menggunakan salah satu yang memberikan peningkatan terbesar dalam pengujian.
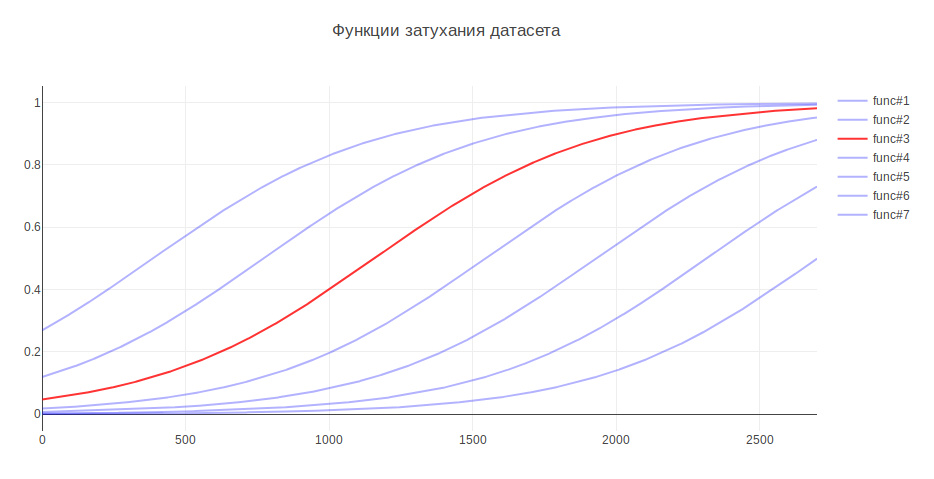
Karena ini, kualitas klasifikasi meningkat 3%
Penilaian kualitas
Dalam masalah klasifikasi, kita perlu memikirkan apa yang lebih penting bagi kita -
akurasi atau kelengkapan ? Dalam kasus saya, jika algoritme salah, maka tidak ada yang salah, kami memiliki pengetahuan yang sangat baik antara tim dan tugas akan ditransfer ke mereka yang bertanggung jawab, atau ke yang utama di QA. Selain itu, algoritma tidak membuat kesalahan secara acak, tetapi menemukan perintah yang dekat dengan masalah. Oleh karena itu, diputuskan untuk mengambil 100% untuk kelengkapan. Dan untuk mengukur kualitas, metrik akurasi dipilih - proporsi jawaban yang benar, yang untuk model akhir adalah 76%.
Sebagai mekanisme validasi, saya pertama kali menggunakan validasi silang - ketika sampel dibagi menjadi N bagian dan kualitas diperiksa pada satu bagian, dan pelatihan dilakukan pada sisanya, dan begitu N kali, sampai setiap bagian dalam peran uji. Hasilnya kemudian dirata-rata. Tetapi dalam kasus saya, pendekatan ini tidak cocok, karena urutan data berubah, dan seperti yang sudah diketahui, kualitas tergantung pada kesegaran data. Karena itu, saya belajar sepanjang waktu pada yang lama, dan divalidasi pada yang baru.
Mari kita lihat perintah mana yang paling sering membingungkan algoritma:

Di tempat pertama adalah Pemasaran dan Pandora. Ini tidak mengherankan sejak itu tim kedua tumbuh dari yang pertama dan mengambil tanggung jawab untuk banyak fungsi. Jika Anda mempertimbangkan anggota tim lainnya, Anda juga dapat melihat alasan yang terkait dengan dapur internal perusahaan.
Sebagai perbandingan, saya ingin melihat model acak. Jika Anda menetapkan orang yang bertanggung jawab secara acak, maka kualitasnya akan sekitar 5%, dan jika untuk kelas yang paling umum, maka - 29%
Tanda-tanda paling signifikan
LogisticRegression untuk setiap kelas mengembalikan koefisien atribut. Semakin besar nilainya, semakin besar kontribusi atribut ini dibuat untuk kelas ini.
Di bawah spoiler, output dari tanda-tanda teratas. Awalan menunjukkan dari mana tanda-tanda itu berasal:
- jumlah - tf-idf untuk Ringkasan dalam kata dan angka
- sum2 - tf-idf untuk Ringkasan pada pemisahan tiga karakter
- desc - tf-idf untuk Keterangan dalam kata dan angka
- desc2 - tf-idf untuk Deskripsi pada partisi tiga karakter
- lab - bidang Label
- Reporter rep - bidang
TandaA-Team: sum_site (1.28), lab_responses_and_invitations (1.37), lab_failure_ kepada majikan (1.07), lab_makeup (1.03), sum_work (1.59), lab_hhs (1.19), lab_feedback (1.06), rep_name (1.16), jendela sum_ (1.13), sum_ break (1.04), rep_name_1 (1.22), lab_responses_seeker (1.0), lab_site (0.92)
API: lab_delete_account (1.12), sum_comment_resume (0.94), rep_name_2 (0.9), rep_name_3 (0.83), rep_name_4 (0.91), rep_name_5 (0.91), lab_measurements_managers (0.87), lab_comments_to_result (1.6) (akun) ), sum_view (0.91), desc_comment (1.02), rep_name_6 (0.85), desc_resume (0.86), sum_api (1.01)
Android: sum_android (1.77), lab_ios (1.66), sum_application (2.9), sum_hr_mobile (1.4), lab_android (3.55), sum_hr (1.36), lab_mobile_application (3.33), sum_mobile (1.4), rep_name_2 (1.34), sum2_jul (1.27) ), sum_android_application (1.28), sum2_pril_rilo (1.19), sum2_pril_ril (1.27), sum2_ril_log (1.19), sum2_ril_log_ (1.19)
Tagihan: rep_name_7 (3.88), desc_account (3.23), rep_name_8 (3.15), lab_billing_wtf (2.46), rep_name_9 (4.51), rep_name_10 (2.88), sum_account (3.16), lab_billing (2.41), rep_name_11 (2.27)) ), sum_service (2.33), lab_payment_services (1.92), sum_act (2.26), rep_name_12 (1.92), rep_name_13 (2.4)
Brandy: penilaian lab_talent (2.17), rep_name_14 (1.87), rep_name_15 (3.36), lab_clickme (1.72), rep_name_16 (1.44), rep_name_17 (1.63), rep_name_18 (1.29), sum_page (1.24), sum_pand (1.39) lab ), sum_constructor (1.59), lab_brand halaman (1.33), sum_description (1.23), sum_description_of perusahaan (1.17), lab_article (1.15)
Clickme: desc_act (0.73), sum_adv_hh (0.65), sum_adv_hh_ru (0.65), sum_hh (0.77), lab_hhs (1.27), lab_bs (1.91), rep_name_19 (1.17), rep_name_20 (1.29), rep_name_20 (1.29), rep_name_20 ), sum_advertising (0.67), sum_placing (0.65), sum_adv (0.65), sum_hh_ua (0.64), sum_click_31 (0.64)
Pemasaran: lab_region (0.9), lab_brakes_site (1.23), sum_mail (1.32), lab_managers_of lowongan (0.93), sum_calender (0.93), rep_name_22 (1.33), lab_requests (1.25), rep_name_6 (1.53), lab_product_1_523) ), sum_yandex (1.26), sum_distribution_vacancy (0.85), sum_distribution (0.85), sum_category (0.85), sum_error_function (0.83)
Merkuri: lab_services (1.76), sum_captcha (2.02), lab_search_services (1.89), lab_lawyers (2.1), lab_authorization_worker (1.68), lab_proforientation (2.53), lab_ready_summary (2.21), rep_name_24 (1.7725_mail) ), sum_user (1.57), rep_name_26 (1.43), lab_moderation_of lowongan (1.58), desc_password (1.39), rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32), sum_version_site (1.26), lab_application (1.51), lab_statistics (1.32), sum_mobile_version_site (1.25), lab_mobile_version (5.1), sum_version (1.41), rep_name_28 (1.24) 1 ), lab_jtb (1.07), rep_name_16 (1.12), rep_name_29 (1.05), sum_site (0.95), rep_name_30 (0.92)
TMS: rep_name_31 (1.39), lab_talantix (4.28), rep_name_32 (1.55), rep_name_33 (2.59), sum_valuation_talantix (0.74), lab_search (0.57), lab_search (0.63), rep_name_34 (0.64), lab_port (0.56), lab_port (0.56) ), lab_tms (0.74), respons sum_hh_ (0.57), lab_mailing (0.64), sum_talantix (0.6), sum2_po (0.56)
Talantix: sum_system (0.86), rep_name_16 (1.37), sum_talantix (1.16), lab_mail (0.94), lab_xor (0.8), lab_talantix (3.19), rep_name_35 (1.07), rep_name_18 (1.33), lab_personal_data (0.79) ), sum_talantics (0.89), sum_proceed (0.78), lab_mail (0.77), sum_response_stop_view (0.73), rep_name_6 (0.72)
WebLayanan: sum_vacancy (1.36), desc_pattern (1.32), sum_archive (1.3), lab_patterns (1.39), sum_number_phone (1.44), rep_name_36 (1.28), lab_lawyers (2.1), lab_invitation (1.27), lab_invitation (1.27), lab_invitation (1.27), ), lab_selected_summages (1.2), lab_key_keys (1.22), sum_find (1.18), sum_phone (1.16), sum_folder (1.17)
iOS: sum_application (1.41), desc_application (1.13), lab_andriod (1.73), rep_name_37 (1.05), lab_mobile_application (1.88), lab_ios (4.55), rep_name_6 (1.41), rep_name_38 (1.35), sum_mobile_apication ), sum_mobile (0.98), rep_name_39 (0.74), sum_resum_hide (0.88), rep_name_40 (0.81), lab_Duplikasi lowongan (0.76)
Arsitektur: sum_statistics_response (1.1), rep_name_41 (1.4), lowongan lab_graphics_views_and_responses_ (1.04), lowongan lab_creation_of (1.16), lab_quotas (1.0), tawaran sum_special (1.02), rep_name_42_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_01_03 ), rep_name_43 (1.09), sum_dependent (0.83), sum_statistics (0.83), lab_responses_worker (0.76), sum_500ka (0.74)
Bank Gaji: lab_500 (1.18), lab_authorization (0.79), sum_500 (1.04), rep_name_44 (0.85), sum_500_site (1.03), lab_site (1.54), lab_visibility_name (1.54), daftar lab_price (1.26), lab_setting_visibility_7 (hasil) sum_error (0.79), lab_delivered_orders (1.33), rep_name_43 (0.74), sum_ie_11 (0.69), sum_500_error (0.66), sum2_site_ite (0.65)
Produk seluler: lab_mobile_application (1.69), lab_backs (1.65), sum_hr_mobile (0.81), lab_applicant (0.88), lab_employer (0.84), sum_mobile (0.81), rep_name_45 (1.2), desc_d0 (0.87), reprame_rame_dr_rame_dr_dr_mobile) 0.79), sum_incorrect_search_work (0.61), desc_application (0.71), rep_name_47 (0.69), rep_name_28 (0.61), sum_work_search (0.59)
Pandora: sum_receive (2.68), desc_receive (1.72), lab_sms (1.59), sum_ letter (2.75), sum_notification_response (1.38), sum_password (1.52), lab_recover_password (1.52), ringkasan lab_mail_mailword (1.91, mail) (1.91) ), lab_mail (1.72), lab_mail (3.37), desc_mail (1.69), desc_mail (1.47), rep_name_6 (1.32)
Paprika: lab_saving_summary (1.43), sum_summing (2.02), sum_oron (1.57), sum_oron_vacancy (1.66), desc_resum (1.19), lab_summing (1.39), sum_code (1.2), sum_index (1.34), sum_index (1.47) ), lab_creation_summary (1.28), rep_name_45 (1.82), sum_civilness (1.47), sum_save_summum (1.18), lab_invital_index (1.13)
Cari-1: sum2_poi_is_search (1.86), sum_loop (3.59), lab_questions_o_search (3.86), sum2_poi (1.86), desc_overs (2.49), lab_observing_summary (2.2), lab_observer (2.32), lab_loser (2.32), lab_loser (2.32), laboratorium (1.62), sum_sinonim (1.71), sum_sample (1.62), sum2_isk (1.58), sum2_is_isk (1.57), lab_auto-update_sum (1.57)
Cari-2: rep_name_48 (1.13), desc_d1 (1.1), lab_premium_in_search (1.02), lab_views_of lowongan (1.4), sum_search (1.4), desc_d0 (1.2), lab_show_contacts (1.17), rep_name_49 (1.12950 ,13950 ,13950) (1.05), lowongan lab_search_of (1.62), lab_responses_and_invitations (1.61), sum_response (1.09), lab_selected_results (1.37), lab_filter_of_responses (1.08)
Produk Super: lab_contact_information (1.78), desc_address (1.46), rep_name_46 (1.84), sum_address (1.74), lab_selected_resumes (1.45), labatalog_worker (1.29), sum_right_shot (1.29), sum_right_shot (1.29), sum_right_range (1.29) ), sum_error_position (1.33), rep_name_42 (1.32), sum_quota (1.14), desc_address_office (1.14), rep_name_51 (1.09)
Tanda-tanda secara kasar mencerminkan apa yang dilakukan tim.
Penggunaan model
Mengenai hal ini, konstruksi model selesai dan dimungkinkan untuk membangun program berdasarkan dasarnya.
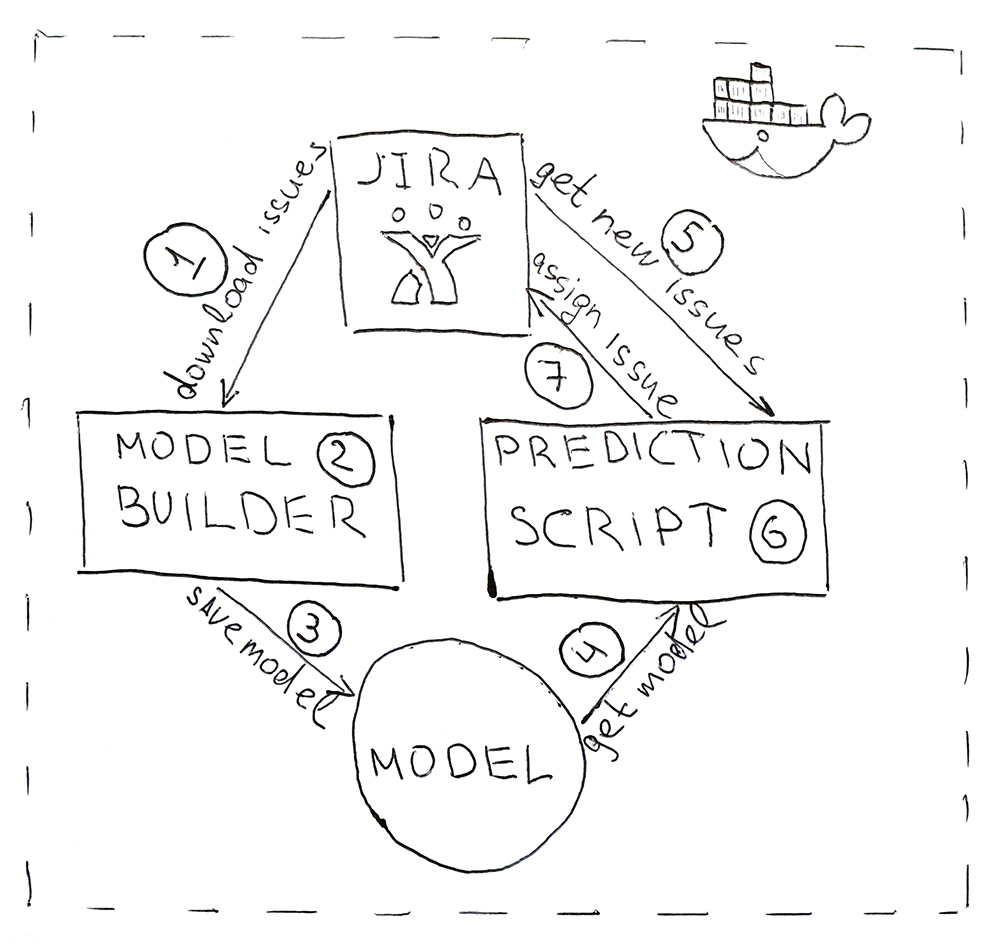
Program ini terdiri dari dua skrip Python. Yang pertama membangun model, dan yang kedua membuat prediksi.
- Jira menyediakan API tempat Anda dapat mengunduh tugas yang sudah selesai (HHS). Sekali sehari, skrip diluncurkan dan mengunduhnya.
- Data yang diunduh dikonversi ke tag. Pertama, data dipukuli untuk pelatihan dan pengujian dan diserahkan ke model ML untuk validasi untuk memastikan bahwa dari awal hingga awal kualitas tidak mulai menurun. Dan kemudian kedua kalinya model dilatih pada semua data. Seluruh proses memakan waktu sekitar 10 menit.
- Model yang terlatih disimpan ke hard drive. Saya menggunakan utilitas dill untuk membuat cerita bersambung objek. Selain model itu sendiri, perlu juga untuk menyimpan semua objek yang digunakan untuk mendapatkan karakteristik. Ini untuk mendapatkan tanda-tanda di ruang yang sama untuk HHS baru.
- dill , 5 .
- Jira HHS.
- , HHS — .
- Jira API. , , — .
, , Docker .
. 76% — , . , , , . ! Hore!