Hari ini kami ingin berbicara tentang fitur Yandex.Cloud yang sangat berguna sebagai mesin virtual yang terganggu. Ini adalah opsi khusus yang dapat Anda pilih saat membuat mesin virtual untuk menggunakan sumber daya komputasi dengan harga yang lebih murah. Apa yang istimewa dari mesin virtual interruptible, mengapa lebih murah daripada yang biasa, dan dalam kasus apa bijak untuk menggunakannya?

Kapasitas Yandex.Cloud, dan lebih tepatnya, layanan infrastruktur
Cloud Yandex , jauh lebih besar daripada yang digunakan oleh pengguna. Secara default, diasumsikan bahwa pengguna harus dapat skala secara sewenang-wenang. Setidaknya untuk alasan-alasan ini, tanpa mempertimbangkan aspek-aspek lain, sumber daya yang tersedia dari platform cloud secara signifikan melebihi permintaan saat ini. Pada kapasitas gratis inilah mesin virtual terputus dibuat.
Keterbatasan utama
Secara singkat, sifat mesin virtual terputus dapat digambarkan sebagai berikut: layanan ini menawarkan untuk menggunakan sumber daya komputasi gratis dengan harga lebih rendah, asalkan sumber daya ini dapat ditarik kembali kapan saja.
Secara umum, mesin virtual terputus bekerja seperti mesin virtual biasa, tetapi mereka memiliki sejumlah keterbatasan:
- Mereka tidak dicakup oleh perjanjian tingkat layanan (SLA).
- Kemampuan untuk membuat dan menjalankan tidak dijamin.
- Mereka bisa dipaksa berhenti kapan saja. Probabilitas pemberhentian kecil, tetapi tidak nol, dapat berhenti dari waktu ke waktu dan bervariasi di berbagai zona Yandex . Ketersediaan keras .
- Mesin virtual terputus tidak dapat dibuat normal, tetapi mesin terputus biasa. Bendera yang sesuai diatur satu kali dan tidak berubah.
- Mesin pasti akan berhenti dalam periode tidak melebihi 24 jam.
Dalam praktiknya, dalam sebagian besar kasus, mesin virtual yang terputus bekerja 24 jam penuh sesuai dengan kondisi layanan. Penghentian paksa biasanya terjadi hanya ketika sejumlah besar mesin virtual biasa dibuat di zona ketersediaan tertentu dalam waktu singkat: pengguna baru muncul dengan kebutuhan serius atau pengguna saat ini diskalakan secara besar-besaran.
Pada saat yang sama, mesin virtual yang dihentikan dapat dimulai lagi: semua data pada disk disimpan baik selama shutdown otomatis dan manual.
Gunakan kasing
Keterbatasan untuk mesin virtual yang terputus menimbulkan pertanyaan logis: bagaimana cara menerapkannya jika sumber daya dapat dicabut kapan saja? Sebagai penjelasan, berikut adalah beberapa kemungkinan kasus penggunaan.
Pemrosesan batch
Pemrosesan batch melibatkan eksekusi paralel dari sejumlah besar tugas sumber daya intensif. Ini mungkin konversi format file, pemrosesan dan pengenalan gambar,
operasi ETL . Intinya adalah bahwa dalam pemrosesan batch ada antrian pekerjaan dan seluruh rangkaian proses kerja (pelaksana) yang menerima pekerjaan dari antrian. Jika seorang eksekutor individu yang berjalan pada mesin yang terputus berhenti, tugas itu hanya akan ditransfer ke pelaksana berikutnya. Dengan kata lain, menghentikan satu atau bahkan beberapa mesin virtual tidak akan memiliki dampak negatif yang signifikan pada proses dan hasil pemrosesan.

Saat mengolah data, kita berbicara tentang menggunakan puluhan mesin virtual. Penggunaan mesin berselang memberikan penghematan yang sangat nyata. Sekarang salah satu konsumen utama mesin virtual diskontinyu produktif dengan 32 core adalah klien Yandex.Cloud yang lama, Seismotech. Seismotek memproses data seismik, yang diperlukan untuk eksplorasi ladang gas dan minyak. Eksplorasi seismik melibatkan bekerja dengan volume informasi yang besar. Data diproses dalam metode batch. Perusahaan secara bersamaan menggunakan hingga 60-plus mesin terganggu: total hingga 2000 vCPU dan 4000 GB RAM.
Proyek di Hadoop
Hadoop digunakan untuk mengembangkan dan menjalankan program terdistribusi yang berjalan pada kelompok ratusan dan ribuan node berbiaya rendah. Mekanisme replikasi file dan restart otomatis tugas yang dilakukan pada node gagal yang disediakan oleh Hadoop memastikan stabilitas sistem terdistribusi terhadap kegagalan mesin individu. Itulah sebabnya, di mana Hadoop digunakan, setidaknya sebagian dari node dapat dengan mudah digunakan untuk mesin virtual yang terganggu. Jika mereka berhenti lebih awal, tugas akan dikirim ke node lain.
Layanan Web Failover
Ketersediaan layanan web yang berkelanjutan dapat dipastikan dengan menggunakan cluster. Cluster terdiri dari dua atau lebih server. Salah satu tugasnya dalam aplikasi ke layanan web adalah untuk memastikan operasi yang stabil pada saat beban puncak. Contoh umum: situs belanja online atau situs olahraga di mana pertumbuhan lalu lintas terikat pada tanggal tertentu. Untuk toko, ini bisa berupa hari libur tradisional atau periode diskon, dan untuk situs yang berhubungan dengan olahraga, itu bisa menjadi hari acara ketika siaran langsung diterbitkan, ulasan dan laporan foto diterbitkan. Pada saat-saat seperti itu, volume lalu lintas dapat meningkat secara signifikan.
Cluster harus mengatasi masuknya pengunjung dengan mendistribusikan lalu lintas ke node yang berbeda. Untuk periode pertumbuhan yang tajam, tetapi berumur pendek, toleransi kesalahan dapat disediakan dengan menambahkan server pada mesin virtual yang dihentikan. Opsi ini tidak mahal dan melakukan tugasnya dengan baik. Penting untuk mengamati satu syarat: gugus seperti itu harus hibrida, yaitu termasuk mesin virtual biasa. Dalam hal ini, bahkan penghentian yang tidak mungkin dari mesin yang terputus tidak akan menyebabkan kegagalan layanan.
Proyek di Kubernetes
Kubernetes mengotomatiskan penyebaran, penskalaan, dan pengelolaan aplikasi kemas di sejumlah besar node. Salah satu entitas utama yang dapat disebut blok bangunan Kubernetes berada di bawah (pod). Pod menyediakan peluncuran satu atau beberapa kontainer pada satu node. Sebuah simpul untuk setiap perapian dipilih dan ditugaskan oleh scheduler Kubernetes. Jika simpul terpisah dengan perapian berjalan gagal, penjadwal akan secara otomatis mentransfernya ke simpul yang beroperasi dalam mode normal. Skema menjaga kesehatan ini menunjukkan bahwa bagian dari node dapat di-host di mesin virtual diskontinyu.
Pengujian Integrasi Berkelanjutan
Praktik integrasi berkelanjutan didasarkan pada seringnya perakitan dan pengujian proyek. Dalam hal ini, sebagian besar pengujian otomatis digunakan. Secara skematis, kelihatannya seperti ini: lingkungan pengujian dibuat pada mesin virtual, bangunan terakhir aplikasi diunggah ke dalamnya, pengujian otomatis dilakukan, hasil pengujian diunggah, mesin virtual dihapus. Sebagai aturan, pengujian membutuhkan waktu puluhan menit, lebih jarang beberapa jam.
Secara tradisional, titik lemah dari integrasi berkelanjutan dianggap biaya yang signifikan untuk mendukung proses integrasi itu sendiri dan tingginya permintaan untuk sumber daya komputasi. Dari sudut pandang ini dan mempertimbangkan kerangka waktu pengujian otomatis, mesin virtual yang dihentikan terlihat lebih cocok untuk integrasi berkelanjutan. Mereka jauh lebih murah, dan kemungkinan mobil berhenti segera pada saat pengujian semakin kecil. Selain itu, bahkan jika mobil masih berhenti, kerusakan dari sudut pandang bisnis akan minimal.
Gunakan bersama dengan layanan Yandex.Cloud lainnya
Layanan Grup Yandex Instance memungkinkan Anda untuk secara otomatis memantau status seluruh kelompok mesin virtual yang terputus. Dia dapat secara mandiri membuat mesin virtual dengan karakteristik yang diberikan, mempertahankan jumlah mesin yang diperlukan dalam grup dan memulai kembali instance yang terputus jika berhenti. Tidak masalah jika penghentian paksa telah terjadi atau 24 jam telah berlalu sejak awal. Hanya satu hal yang penting: restart akan terjadi jika ada sumber daya yang tersedia. Grup Yandex Instance membuat bekerja dengan mesin virtual yang terganggu lebih nyaman, tetapi tidak dapat menjamin bahwa kapasitas bebas akan selalu ada di zona ketersediaan tertentu.
Kinerja ekonomi
Seperti yang kami sebutkan, mesin virtual interruptible dapat mengurangi biaya menggunakan sumber daya komputasi. Di dalam Yandex, kami mulai mengerjakan fungsi serupa beberapa tahun yang lalu. Untuk membagi tugas komputasi menjadi dijamin dapat dieksekusi dan interruptible, diperlukan investasi besar. Tapi itu tidak sia-sia: pada akhirnya, kami meningkatkan tingkat pemanfaatan infrastruktur server yang bermanfaat dari 30-40% menjadi 70-80%.

Sekarang kemampuan serupa tersedia untuk semua pengguna Yandex.Cloud dengan mengklik tombol. Contoh sederhana: jika Anda mentransfer setengah dari mesin virtual yang digunakan dengan beban kernel seratus persen ke format interrupt, Anda dapat menghemat hingga 35-40% dari anggaran.
Dengan biaya yang lebih murah, sumber daya CPU dan RAM tersedia. Ruang disk dan alamat IP dibayar dengan tarif reguler. Inilah yang ditunjukkan perhitungan sederhana untuk platform Cascade Lake.
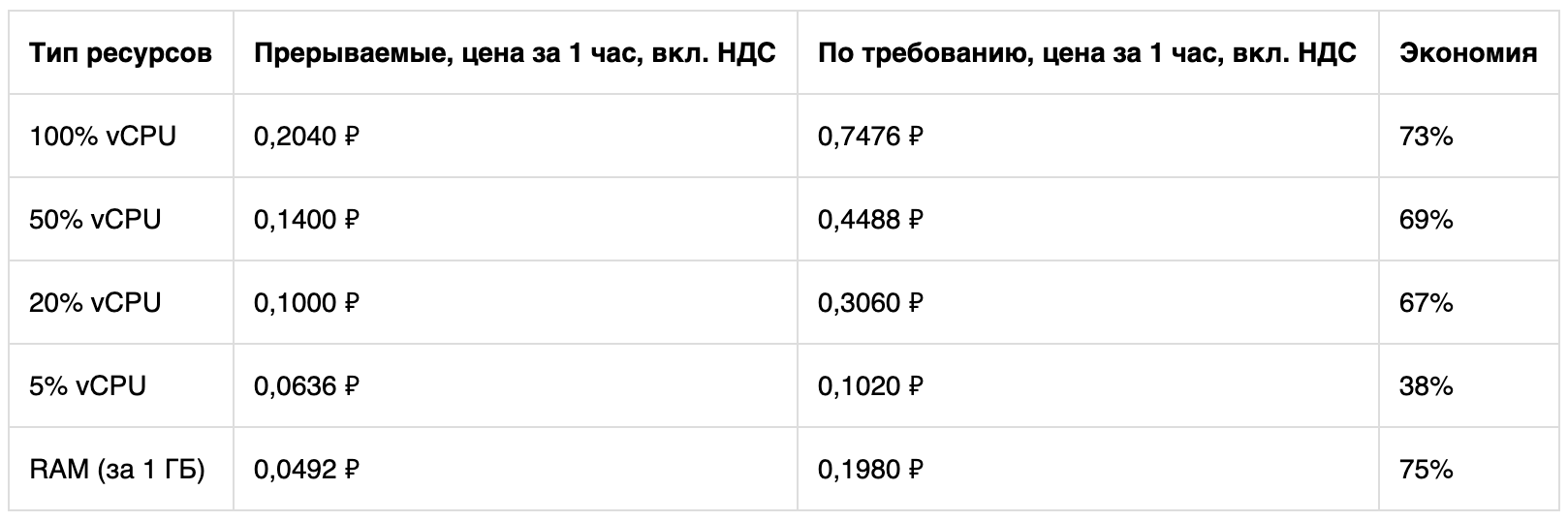
Jika mau, Anda dapat membandingkan biaya menggunakan mesin virtual dalam mode berbeda menggunakan
kalkulator .
Kami berharap bahwa kami dapat memberikan sedikit kejelasan dan memberikan beberapa contoh yang berguna dalam hal ini Anda dapat menggunakan mesin virtual interruptible untuk mengurangi biaya sumber daya komputasi tanpa kehilangan kualitas dalam melakukan tugas.
Publikasi lain tentang Cloud on Habré