Sasaran dan persyaratan untuk pengujian "Akuntansi 1C"
Tujuan utama pengujian adalah untuk membandingkan perilaku sistem 1C pada dua DBMS yang berbeda dalam kondisi identik lainnya. Yaitu konfigurasi basis data 1C dan populasi data awal harus sama selama setiap pengujian.
Parameter utama yang harus diperoleh selama pengujian:
- Waktu pelaksanaan setiap tes (dihapus oleh Departemen Pengembangan 1C)
- Beban pada lingkungan DBMS dan server selama pengujian dihapus oleh administrator DBMS, serta oleh lingkungan server oleh administrator sistem
Pengujian sistem 1C harus dilakukan dengan mempertimbangkan arsitektur client-server, oleh karena itu, perlu untuk meniru pengguna atau beberapa pengguna dalam sistem dengan mengerjakan input informasi dalam antarmuka dan menyimpan informasi ini dalam database. Pada saat yang sama, perlu bahwa sejumlah besar informasi periodik diposting selama periode waktu yang besar untuk membuat total dalam register akumulasi.
Untuk melakukan pengujian, suatu algoritma dikembangkan dalam bentuk skrip untuk pengujian skrip, untuk konfigurasi 1C Accounting 3.0, di mana input serial data uji ke dalam sistem 1C dilakukan. Script memungkinkan Anda menentukan berbagai pengaturan untuk tindakan yang dilakukan dan jumlah data uji. Penjelasan terperinci di bawah ini.
Deskripsi pengaturan dan karakteristik lingkungan yang diuji
Kami di Fortis memutuskan untuk memeriksa ulang hasilnya, termasuk menggunakan
uji Gilev yang terkenal.
Kami juga didorong untuk menguji, termasuk beberapa publikasi tentang hasil perubahan kinerja selama transisi dari MS SQL Server ke PostgreSQL. Seperti:
1C Battle: PostgreSQL 9.10 vs MS SQL 2016 .
Jadi, inilah infrastruktur untuk pengujian:
Server untuk MS SQL dan PostgreSQL adalah virtual dan dijalankan secara bergantian untuk pengujian yang diinginkan. 1C berdiri di server terpisah.
DetailSpesifikasi Hypervisor:Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @ 2.40GHz (2 kaus kaki * 16 CPU HT = 32CPU)
RAM: 212 GB
OS: VMWare ESXi 6.5
PowerProfile: Kinerja
Subsistem Disk Hypervisor:Pengontrol: Adaptec 6805, Ukuran cache: 512MB
Volume: RAID 10, 5,7 TB
Ukuran garis: 1024 KB
Write-cache: aktif
Read-cache: off
Roda: 6 buah. HGST HUS726T6TAL,
Ukuran Sektor: 512 Bytes
Tulis Cache: aktif
PostgreSQL dikonfigurasikan sebagai berikut:- postgresql.conf:
Pengaturan dasar dibuat menggunakan kalkulator - pgconfigurator.cybertec.at , parameter huge_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost diubah berdasarkan informasi yang diterima dari sumber yang disebutkan di akhir publikasi. Nilai parameter temp_buffers meningkat, berdasarkan saran bahwa 1C secara aktif menggunakan tabel sementara:
listen_addresses = '*' max_connections = 1000
- Kernel, parameter OS:
Pengaturan diatur dalam format file profil untuk daemon yang disetel:
[sysctl]
- Sistem file:
Semua isi file postgresql.conf:
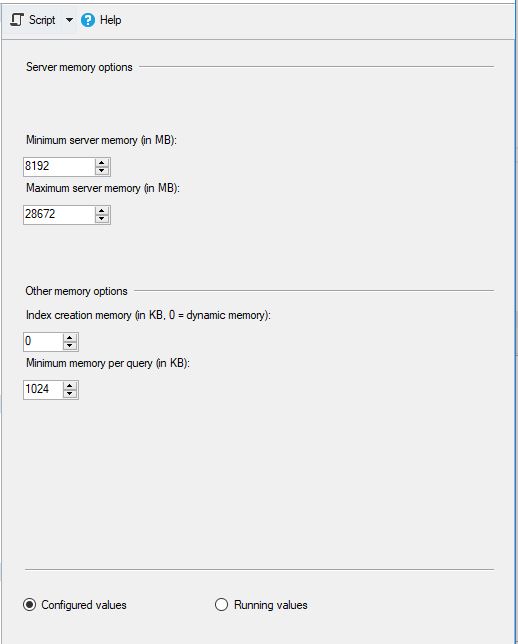
MS SQL dikonfigurasi sebagai berikut: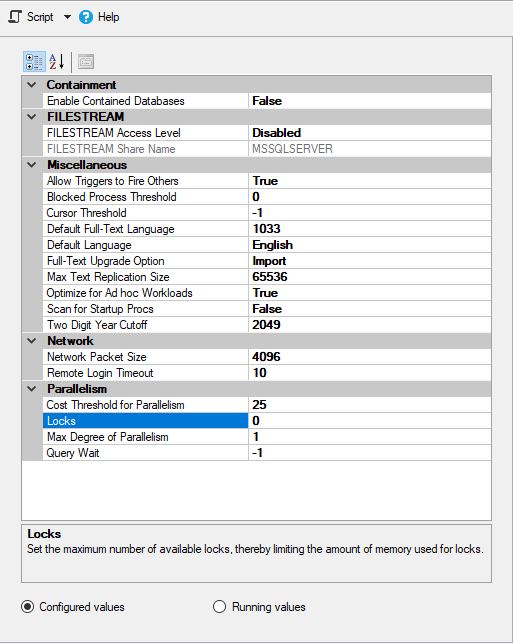
dan
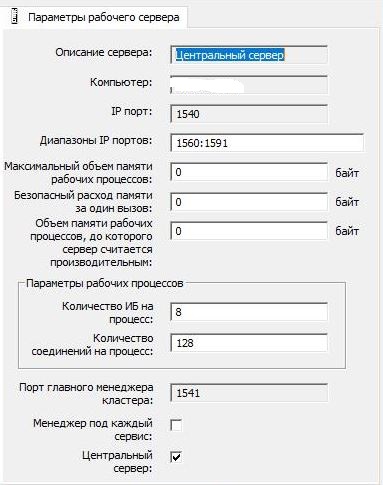
Pengaturan cluster 1C dibiarkan standar:

dan
Tidak ada program antivirus di server dan tidak ada pihak ketiga yang diinstal.
Untuk MS SQL, tempdb dipindahkan ke drive logis terpisah. Namun, file data dan file log transaksi untuk database terletak di drive logis yang sama (yaitu file data dan log transaksi tidak dibagi menjadi drive logis terpisah).
Pengindeksan drive di Windows, di mana MS SQL Server berada, dinonaktifkan pada semua drive logis (seperti kebiasaan dalam kebanyakan kasus di lingkungan prodovskih).
Deskripsi algoritma utama skrip untuk pengujian otomatisEstimasi periode pengujian utama adalah 1 tahun, di mana dokumen dan informasi referensi dibuat untuk setiap hari sesuai dengan parameter yang ditentukan.
Pada setiap hari pelaksanaan, blok input dan output informasi diluncurkan:
- Blok 1 "_" - "Tanda terima barang dan jasa"
- Direktori Counterparties terbuka
- Elemen baru dari direktori "Kontraktor" dibuat dengan tampilan "Pemasok"
- Elemen baru dari direktori "Kontrak" dibuat dengan tampilan "Dengan pemasok" untuk rekanan baru
- Direktori "Nomenklatur" terbuka
- Seperangkat elemen direktori "Nomenklatur" dibuat dengan tipe "Produk"
- Seperangkat elemen direktori "Nomenklatur" dibuat dengan tipe "Layanan"
- Daftar dokumen "Penerimaan barang dan jasa" terbuka.
- Dokumen baru "Barang dan jasa yang diterima" dibuat di mana bagian tabular "Barang" dan "Layanan" diisi dengan kumpulan data yang dibuat
- Laporan "Kartu Rekening 41" dibuat untuk bulan ini (jika interval untuk pembentukan tambahan ditunjukkan)
- Blok 2 "_" - "Penjualan barang dan jasa"
- Direktori Counterparties terbuka
- Elemen baru dari direktori "Rekanan" dibuat dengan tampilan "Pembeli"
- Elemen baru dari direktori "Kontrak" dibuat dengan tampilan "Dengan Pembeli" untuk rekanan baru
- Daftar dokumen "Penjualan barang dan jasa" terbuka.
- Dokumen baru "Penjualan barang dan jasa" dibuat di mana bagian tabular "Barang" dan "Layanan" diisi sesuai dengan parameter yang ditentukan dari data yang dibuat sebelumnya
- Laporan "Kartu Rekening 41" dibuat untuk bulan ini (jika interval untuk pembentukan tambahan ditunjukkan)
- Laporan "Kartu Akun 41" untuk bulan berjalan dihasilkan
Pada akhir setiap bulan di mana pembuatan dokumen dilakukan, blok input dan output informasi dilakukan:
- Laporan "Kartu Rekening 41" dibuat dari awal tahun hingga akhir bulan
- Laporan "Neraca turnover" dihasilkan dari awal tahun hingga akhir bulan
- Prosedur pengaturan "Menutup bulan" sedang dilakukan.
Hasil eksekusi memberikan informasi tentang waktu pengujian dalam jam, menit, detik, dan milidetik.
Fitur utama dari skrip pengujian:- Kemampuan untuk menonaktifkan / mengaktifkan unit individual
- Kemampuan untuk menentukan jumlah total dokumen untuk masing-masing blok
- Kemampuan untuk menentukan jumlah dokumen untuk setiap blok per hari
- Kemampuan untuk menunjukkan jumlah barang dan jasa dalam dokumen
- Kemampuan untuk mengatur daftar indikator kuantitatif dan harga untuk pencatatan. Berfungsi untuk membuat set nilai yang berbeda dalam dokumen
Rencana pengujian dasar untuk masing-masing database:- "Tes pertama." Di bawah satu pengguna, sejumlah kecil dokumen dengan tabel sederhana dibuat, "penutupan bulan" dibentuk
- Waktu tunggu yang diharapkan adalah 20 menit. Mengisi selama 1 bulan. Data: 50 dokumen "sekolah kejuruan", 50 dokumen "RTU", 100 elemen "Nomenklatur", 50 elemen "Pemasok" + "Perjanjian", 50 elemen "Pembeli" + "Perjanjian", 2 operasi "Penutupan bulan". Dalam dokumen 1 produk dan 1 layanan
- « ». ,
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:- , :
- « » « »
- 1 "*.dt"
- « »
Hasil
Dan sekarang hasil yang paling menarik pada DBMS MS SQL Server:Detail:
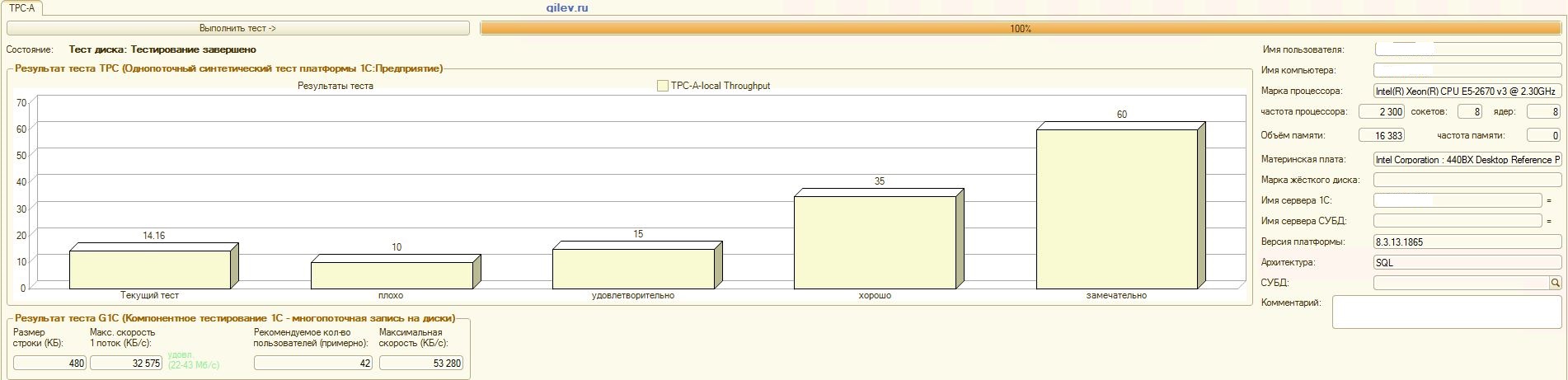
:
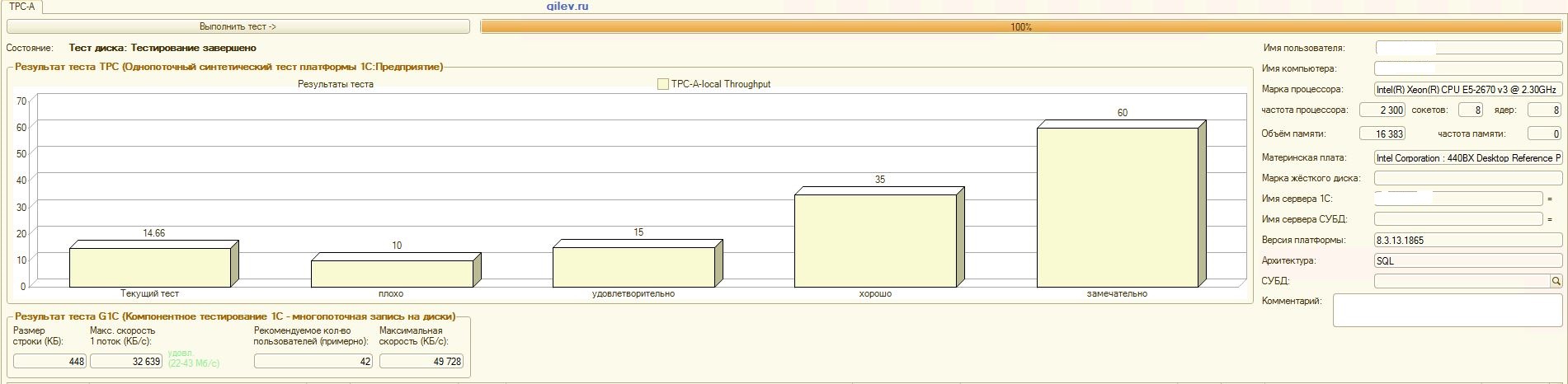
:

PostgreSQL,
, , , :
:
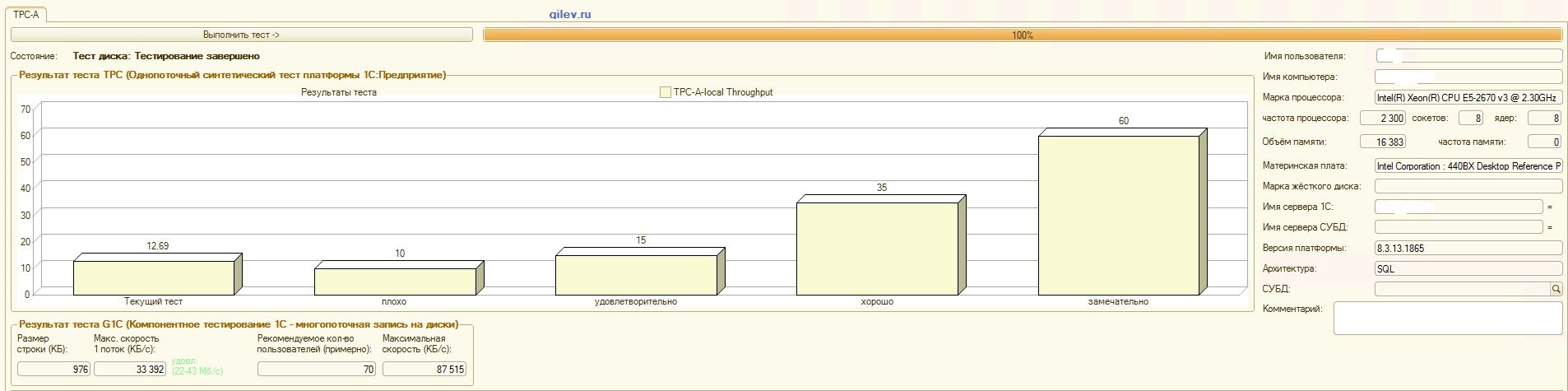
:
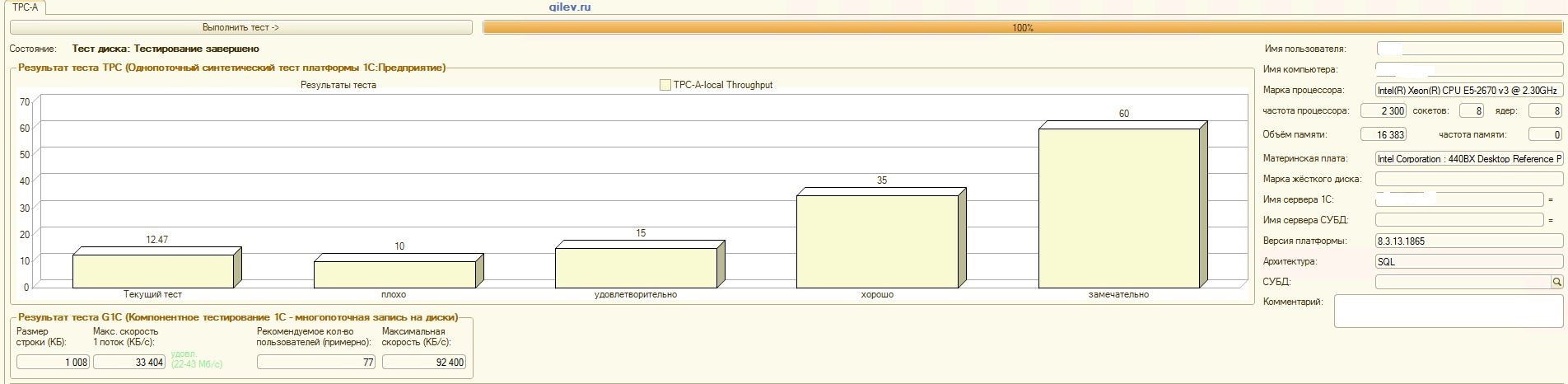
:

Tes Gilev:Seperti dapat dilihat dari hasil, PostgreSQL kehilangan rata-rata 14,82% dari kinerja rata-rata MS SQL DBMSs dalam tes sintetik umum . Namun, menurut dua indikator terakhir, PostgreSQL menunjukkan hasil yang jauh lebih baik daripada MS SQL.Tes khusus untuk Akuntansi 1C:Seperti dapat dilihat dari hasil, Akuntansi 1C bekerja kira-kira sama pada MS SQL dan PostgreSQL dengan pengaturan yang diberikan di atas.Dalam kedua kasus tersebut, DBMS bekerja dengan stabil.Tentu saja, Anda mungkin perlu penyetelan yang lebih halus baik dari DBMS dan dari OS dan sistem file. Semuanya dilakukan saat publikasi disiarkan, yang mengatakan bahwa akan ada peningkatan signifikan dalam produktivitas atau hampir sama ketika beralih dari MS SQL ke PostgreSQL. Selain itu, dalam pengujian ini, sejumlah langkah diambil untuk mengoptimalkan OS dan sistem file untuk CentOS itu sendiri, yang dijelaskan di atas.Perlu dicatat bahwa tes Gilev dijalankan berkali-kali untuk PostgreSQL - hasil terbaik diberikan. Tes Gilev dijalankan pada MS SQL 3 kali, jadi lebih lanjut mereka tidak melakukan optimasi pada MS SQL. Semua upaya selanjutnya adalah membawa gajah ke metrik MS SQL.Setelah mencapai perbedaan optimal dalam uji sintetik Gilev antara MS SQL dan PostgreSQL, pengujian khusus dilakukan untuk Akuntansi 1C, yang dijelaskan di atas.Kesimpulan umum adalah bahwa, meskipun ada penurunan signifikan dalam kinerja pada uji sintetik Gilev dari DBMS PostgreSQL sehubungan dengan MS SQL, dengan pengaturan yang tepat diberikan di atas, Akuntansi 1C dapat diinstal pada DBMS MS SQL dan DBMS PostgreSQL .Komentar
Harus segera dicatat bahwa analisis ini dilakukan hanya untuk membandingkan kinerja 1C dalam berbagai DBMS.Analisis dan kesimpulan ini hanya benar untuk Akuntansi 1C dalam kondisi dan versi perangkat lunak yang dijelaskan di atas. Berdasarkan analisis yang diperoleh, mustahil untuk menyimpulkan dengan tepat apa yang akan terjadi dengan pengaturan dan versi perangkat lunak lainnya, serta dengan konfigurasi 1C yang berbeda.Namun, hasil tes Gilev menunjukkan bahwa pada semua konfigurasi 1C versi 8.3 dan kemudian, dengan pengaturan yang tepat, drawdown maksimum dalam kinerja cenderung tidak lebih dari 15% untuk PostgreSQL DBMSs relatif terhadap MS SQL DBMSs. Perlu juga dipertimbangkan bahwa pengujian terperinci untuk perbandingan yang akurat membutuhkan waktu dan sumber daya yang besar. Berdasarkan ini, kita dapat membuat asumsi yang lebih memungkinkan1C versi 8.3 dan yang lebih baru dapat dimigrasikan dari MS SQL ke PostgreSQL dengan kehilangan kinerja maksimum hingga 15%. Tidak ada hambatan obyektif untuk transisi, t untuk 15% ini mungkin tidak muncul, dan dalam kasus manifestasinya, cukup untuk hanya membeli peralatan yang sedikit lebih kuat jika diperlukan.Penting juga untuk dicatat bahwa database yang diuji kecil, yaitu, secara signifikan kurang dari 100 GB dalam ukuran data, dan jumlah maksimum utas yang berjalan secara bersamaan adalah 4. Ini berarti bahwa untuk database besar yang ukurannya secara signifikan lebih besar dari 100 GB (misalnya, sekitar 1 TB) , serta untuk database dengan akses intensif (puluhan dan ratusan aliran aktif simultan), hasil ini mungkin salah.Untuk analisis yang lebih objektif, akan berguna di masa depan untuk membandingkan dirilis MS SQL Server 2019 Developer dan PostgreSQL 12 yang diinstal pada OS CentOS yang sama, serta ketika MS SQL diinstal pada versi terbaru dari OS Windows Server. Sekarang tidak ada yang menempatkan PostgreSQL di Windows, jadi penurunan kinerja dari DBMSs PostgreSQL akan sangat signifikan.Tentu saja, tes Gilev berbicara secara umum tentang kinerja dan tidak hanya untuk 1C. Namun, saat ini terlalu dini untuk mengatakan bahwa MS SQL DBMS akan selalu lebih baik daripada DBMS PostgreSQL, karena tidak ada fakta yang cukup. Untuk mengkonfirmasi atau membantah pernyataan ini, Anda perlu melakukan sejumlah tes lainnya. Misalnya, untuk .NET Anda perlu menulis aksi atom dan pengujian kompleks, jalankan berulang kali dan dalam kondisi yang berbeda, perbaiki waktu eksekusi dan ambil nilai rata-rata. Kemudian bandingkan nilai-nilai ini. Ini akan menjadi analisis objektif.Saat ini, kami belum siap untuk melakukan analisis seperti itu, tetapi di masa depan sangat mungkin untuk melakukan itu. Kemudian kita akan menulis secara lebih rinci di bawah operasi apa PostgreSQL lebih baik daripada MS SQL dan berapa persen, dan di mana MS SQL lebih baik daripada PostgreSQL dan berapa persen.Juga, pengujian kami tidak menerapkan metode optimasi untuk MS SQL, yang dijelaskan di sini . Mungkin artikel ini lupa mematikan Windows Indexing Indexing.Ketika membandingkan dua DBMS, satu hal penting lagi yang harus diingat: PostgreSQL DBMS gratis dan terbuka, sedangkan MS SQL DBMS dibayar dan memiliki kode sumber tertutup.Sekarang, dengan mengorbankan tes Gilev itu sendiri. Di luar tes, jejak untuk tes sintetis (tes pertama) dan untuk semua tes lainnya dihapus. Tes pertama terutama menanyakan operasi atom (memasukkan, memperbarui, menghapus dan membaca) dan kompleks (dengan merujuk ke beberapa tabel, serta membuat, mengubah, dan menghapus tabel dalam database) dengan jumlah pemrosesan data yang berbeda. Oleh karena itu, uji sintetik Gilev dapat dianggap cukup objektif untuk membandingkan kinerja gabungan rata-rata dua lingkungan (termasuk DBMS) relatif satu sama lain. Nilai absolut itu sendiri tidak mengatakan apa-apa, tetapi rasio mereka dari dua media yang berbeda cukup objektif.Dengan mengorbankan tes Gilev lainnya. Jejak menunjukkan bahwa jumlah utas maksimum adalah 7, tetapi kesimpulan tentang jumlah pengguna lebih dari 50. Selain itu, berdasarkan permintaan, tidak sepenuhnya jelas bagaimana indikator lain dihitung. Oleh karena itu, sisa tes tidak objektif dan sangat bervariasi dan perkiraan. Hanya pengujian khusus yang memperhitungkan secara spesifik tidak hanya sistem itu sendiri, tetapi juga pekerjaan pengguna itu sendiri akan memberikan nilai yang lebih akurat.Ucapan Terima Kasih
- melakukan pengaturan 1C dan meluncurkan tes Gilev, dan juga memberikan kontribusi yang signifikan terhadap pembuatan publikasi ini:
- Roman Buts - pemimpin tim 1C
- Alexander Gryaznov - programmer 1C
- Rekan-rekan Fortis yang memberikan kontribusi signifikan pada pengoptimalan tuning untuk CentOS, PostgreSQL, dll., Tetapi ingin tetap menjadi penyamaran
Terima kasih khusus juga kepada uaggster dan BP1988 untuk beberapa saran tentang MS SQL dan Windows.Kata penutup
Analisis aneh juga dilakukan dalam artikel ini .Dan hasil apa yang Anda miliki dan bagaimana Anda menguji?Sumber