Salut, orang Khabrovit! Terjemahan artikel berikut disiapkan khusus untuk siswa kursus
Platform Infrastruktur berbasis Kubernetes , yang akan memulai kelas besok. Mari kita mulai.

Melakukan autoscaling di Kubernetes
Penskalaan otomatis memungkinkan Anda untuk secara otomatis menambah dan mengurangi beban kerja tergantung pada penggunaan sumber daya.
Kubernet autoscaling memiliki dua dimensi:
- Cluster Autoscaler, yang bertanggung jawab untuk penskalaan node;
- Horizontal Pod Autoscaler (HPA), yang secara otomatis menskalakan jumlah perapian dalam set penyebaran atau replika.
Auto-scaling Cluster dapat digunakan bersama dengan auto-scaling hearth horizontal untuk secara dinamis mengontrol sumber daya komputasi dan tingkat konkurensi sistem yang diperlukan untuk mematuhi perjanjian tingkat layanan (SLA).
Cluster autoscaling sangat tergantung pada kemampuan penyedia infrastruktur cloud yang menjadi tuan rumah cluster, dan HPA dapat beroperasi secara independen dari penyedia IaaS / PaaS.
Pengembangan HPA
Penskalaan otomatis perapian horisontal telah mengalami perubahan besar sejak diperkenalkannya Kubernetes v1.1. Versi pertama HPA skala perapian didasarkan pada konsumsi CPU yang diukur, dan kemudian berdasarkan penggunaan memori. Kubernetes 1.6 memperkenalkan API baru yang disebut Metrik Kustom, yang menyediakan akses HPA ke metrik khusus. Kubernetes 1.7 menambahkan level agregasi yang memungkinkan aplikasi pihak ketiga untuk memperluas Kubernetes API dengan mendaftar sebagai add-on API.
Berkat API Metrik Kustom dan tingkat agregasi, sistem pemantauan seperti Prometheus dapat memberikan metrik khusus aplikasi ke pengontrol HPA.
Penskalaan otomatis perapian horisontal diimplementasikan sebagai loop kontrol yang secara berkala menanyakan API Metrik Sumber Daya (API metrik sumber daya) untuk metrik kunci, seperti penggunaan CPU dan memori, dan API Metrik Kustom (API metrik khusus) untuk metrik aplikasi tertentu.
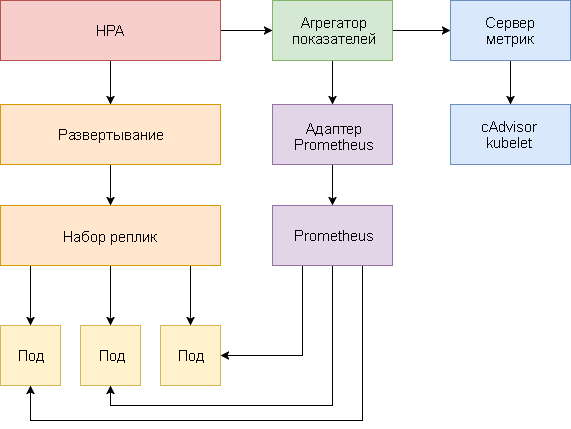
Di bawah ini adalah panduan langkah demi langkah untuk mengkonfigurasi HPA v2 untuk Kubernetes 1.9 dan yang lebih baru.
- Instal Add-in Server Metrik, yang menyediakan metrik kunci.
- Luncurkan aplikasi demo untuk melihat bagaimana skala otomatis perapian bekerja berdasarkan penggunaan CPU dan memori.
- Menyebarkan Prometheus dan server API khusus. Daftarkan server API khusus di tingkat agregasi.
- Konfigurasikan HPA menggunakan metrik khusus yang disediakan oleh aplikasi demo.
Sebelum Anda mulai, Anda harus menginstal Go versi 1.8 (atau lebih baru) dan mengkloning
repositori k8s-prom-hpa di
GOPATH :
cd $GOPATH git clone https:
1. Menyiapkan server metrik
Server
Metrik Kubernetes adalah agregator data pemanfaatan sumber daya intra-cluster yang menggantikan
Heapster . Server metrik mengumpulkan informasi penggunaan CPU dan memori untuk node dan perapian dari
kubernetes.summary_api . API Ringkasan adalah API yang efisien-memori untuk mentransmisikan metrik data Kubelet / cAdvisor ke server.
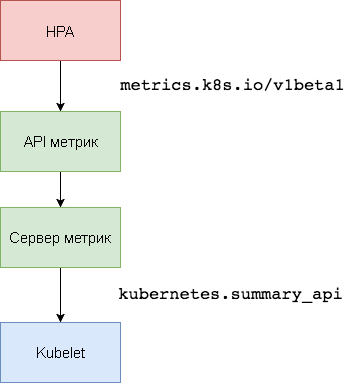
Dalam versi pertama HPA, agregator Heapster diperlukan untuk mendapatkan CPU dan memori. Di HPA v2 dan Kubernetes 1.8, hanya server metrik yang diperlukan jika
horizontal-pod-autoscaler-use-rest-clients enabled diaktifkan. Opsi ini diaktifkan secara default di Kubernetes 1.9. GKE 1.9 dilengkapi dengan server metrik yang telah diinstal sebelumnya.
Perluas server metrik di namespace
kube-system kubus:
kubectl create -f ./metrics-server
Setelah 1 menit,
metric-server akan mulai mengirimkan data tentang penggunaan CPU dan memori melalui node dan pod.
Lihat metrik simpul:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
Lihat indikator detak jantung:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. Penskalaan otomatis berdasarkan penggunaan CPU dan memori
Untuk menguji hearth horizontal auto-scaling (HPA), Anda dapat menggunakan aplikasi web berbasis Golang kecil.
Perluas
podinfo di namespace
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Hubungi
podinfo menggunakan layanan NodePort di
http://<K8S_PUBLIC_IP>:31198 .
Tentukan HPA yang akan melayani setidaknya dua replika dan skala hingga sepuluh replika jika pemanfaatan CPU rata-rata melebihi 80% atau jika konsumsi memori di atas 200 MiB:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
Buat HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
Setelah beberapa detik, pengontrol HPA akan menghubungi server metrik dan menerima informasi tentang penggunaan CPU dan memori:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
Untuk meningkatkan penggunaan CPU, lakukan uji beban dengan rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
Anda dapat memantau acara HPA sebagai berikut:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Hapus podinfo sementara (Anda harus memindahkannya di salah satu langkah selanjutnya dari panduan ini).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. Pengaturan Server Metrik Khusus
Untuk penskalaan berdasarkan metrik khusus, diperlukan dua komponen. Yang pertama - basis data time series
Prometheus - mengumpulkan metrik aplikasi dan menyimpannya. Komponen kedua,
adaptor k8s-prometheus , melengkapi Kubernetes Metrik API Kustom dengan metrik yang disediakan oleh pembangun.
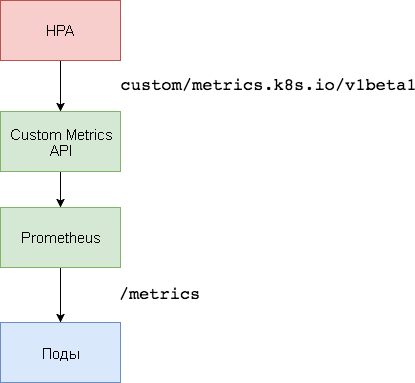
Ruang nama khusus digunakan untuk menggunakan Prometheus dan adaptor.
Buat ruang nama
monitoring :
kubectl create -f ./namespaces.yaml
Perluas Prometheus v2 di ruang nama
monitoring :
kubectl create -f ./prometheus
Hasilkan sertifikat TLS yang diperlukan untuk adaptor Prometheus:
make certs
Menyebarkan adaptor Prometheus untuk API Metrik Khusus:
kubectl create -f ./custom-metrics-api
Dapatkan daftar metrik khusus yang disediakan oleh Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
Kemudian ekstrak data penggunaan sistem file untuk semua pod di namespace
monitoring :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. Penskalaan otomatis berdasarkan metrik khusus
Buat layanan NodePort
podinfo dan gunakan ke namespace
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Aplikasi
podinfo akan melewati
http_requests_total metrik khusus. Adaptor Prometheus akan menghapus akhiran
_total dan menandai metrik ini sebagai penghitung.
Dapatkan jumlah total kueri per detik dari API Metrik Khusus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
Huruf
m berarti
milli-units , jadi, misalnya,
901m adalah 901 milidetik.
Buat HPA yang akan memperluas penyebaran podinfo jika jumlah permintaan melebihi 10 permintaan per detik:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
Perluas HPA
podinfo di namespace
default :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
Setelah beberapa detik, HPA akan mendapatkan nilai
http_requests dari API metrik:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
Terapkan beban untuk layanan podinfo dengan 25 permintaan per detik:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
Setelah beberapa menit, HPA akan mulai mengukur penyebaran:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Dengan jumlah permintaan saat ini per detik, penyebaran tidak akan pernah mencapai maksimum 10 pod. Tiga replika cukup untuk memastikan bahwa jumlah permintaan per detik untuk setiap pod kurang dari 10.
Setelah menyelesaikan tes beban, HPA akan mengurangi skala penyebaran ke jumlah awal replika:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Anda mungkin telah memperhatikan bahwa scaler otomatis tidak segera menanggapi perubahan dalam metrik. Secara default, mereka disinkronkan setiap 30 detik. Selain itu, penskalaan terjadi hanya jika belum ada peningkatan atau penurunan beban kerja selama 3-5 menit terakhir. Ini membantu mencegah keputusan yang bertentangan dan menyisakan waktu untuk menghubungkan scaler otomatis kluster.
Kesimpulan
Tidak semua sistem dapat menegakkan kepatuhan SLA hanya berdasarkan penggunaan CPU atau memori (atau keduanya). Sebagian besar server web dan server seluler untuk menangani lonjakan lalu lintas memerlukan penskalaan otomatis berdasarkan jumlah permintaan per detik.
Untuk aplikasi ETL (dari Eng. Extract Transform Load - "ekstraksi, transformasi, memuat"), penskalaan otomatis dapat dipicu, misalnya, ketika panjang ambang batas yang ditentukan dari antrian pekerjaan terlampaui.
Dalam semua kasus, menginstruksikan aplikasi menggunakan Prometheus dan menyoroti indikator yang diperlukan untuk autoscaling memungkinkan Anda menyempurnakan aplikasi untuk meningkatkan pemrosesan lonjakan lalu lintas dan memastikan ketersediaan infrastruktur yang tinggi.
Gagasan, pertanyaan, komentar? Bergabunglah dengan diskusi di
Slack !
Berikut adalah materi semacam itu. Kami menunggu komentar Anda dan sampai jumpa di
kursus !