Terlepas dari kenyataan bahwa sebagian besar industri TI mengimplementasikan solusi infrastruktur berdasarkan pada wadah dan solusi cloud, perlu untuk memahami keterbatasan teknologi ini. Secara tradisional, Docker, Linux Containers (LXC) dan Rocket (rkt) tidak benar-benar terisolasi karena mereka berbagi inti dari sistem operasi induk dalam pekerjaan mereka. Ya, mereka efektif dalam hal sumber daya, tetapi jumlah total vektor serangan yang diperkirakan dan potensi kerugian dari peretasan masih besar, terutama dalam kasus lingkungan cloud multi-tenant di mana kontainer berada.

Akar masalah kami terletak pada pembatasan lemah wadah pada saat ketika sistem operasi host menciptakan area pengguna virtual untuk masing-masing wadah. Ya, penelitian dan pengembangan telah dilakukan yang bertujuan untuk menciptakan "wadah" nyata dengan kotak pasir penuh. Dan sebagian besar solusi yang dihasilkan mengarah pada restrukturisasi batas antara kontainer untuk meningkatkan isolasi mereka. Dalam artikel ini, kita akan melihat empat proyek unik dari IBM, Google, Amazon, dan OpenStack, masing-masing, yang menggunakan metode berbeda untuk mencapai tujuan yang sama: menciptakan isolasi yang andal. Jadi, IBM Nabla menyebarkan kontainer di atas Unikernel, Google gVisor menciptakan kernel tamu khusus, Amazon Firecracker menggunakan hypervisor yang sangat ringan untuk aplikasi kotak pasir, dan OpenStack menempatkan kontainer dalam mesin virtual khusus yang dioptimalkan untuk alat orkestrasi.
Tinjauan teknologi wadah modern
Kontainer adalah cara modern untuk mengemas, berbagi, dan menggunakan aplikasi. Tidak seperti aplikasi monolitik, di mana semua fungsi dikemas ke dalam satu program, aplikasi wadah atau layanan mikro dimaksudkan untuk penggunaan sempit yang ditargetkan dan mengkhususkan hanya dalam satu tugas.
Wadah mencakup semua dependensi (misalnya, paket, perpustakaan, dan binari) yang dibutuhkan aplikasi untuk menyelesaikan tugas spesifiknya. Akibatnya, aplikasi kemas bersifat platform independen dan dapat berjalan pada sistem operasi apa pun, terlepas dari versi atau paket yang diinstal. Kenyamanan ini menyelamatkan pengembang dari sejumlah besar pekerjaan mengadaptasi berbagai versi perangkat lunak untuk platform atau klien yang berbeda. Meskipun secara konsep tidak sepenuhnya akurat, banyak orang suka menganggap kontainer sebagai "mesin virtual ringan."
Ketika sebuah wadah digunakan pada host, sumber daya dari masing-masing wadah, seperti sistem file, proses, dan tumpukan jaringan, dimasukkan ke dalam lingkungan yang hampir terisolasi yang tidak dapat diakses oleh wadah lain. Arsitektur ini memungkinkan ratusan dan ribuan kontainer berjalan secara bersamaan dalam satu kelompok, dan setiap aplikasi (atau layanan mikro) kemudian dapat dengan mudah diskalakan dengan mereplikasi sejumlah besar contoh.
Dalam hal ini, tata letak wadah didasarkan pada dua “blok penyusun” kunci: Linux namespace dan grup kontrol Linux (cgroups).
Namespace menciptakan ruang pengguna yang hampir terisolasi dan menyediakan aplikasi dengan sumber daya sistem khusus seperti sistem file, tumpukan jaringan, ID proses, dan ID pengguna. Dalam ruang pengguna yang terisolasi ini, aplikasi mengontrol direktori root dari sistem file dan dapat dijalankan sebagai root. Ruang abstrak ini memungkinkan setiap aplikasi untuk bekerja secara independen, tanpa mengganggu aplikasi lain yang hidup di host yang sama. Enam ruang nama saat ini tersedia: mount, komunikasi antar-proses (ipc), sistem pembagian waktu UNIX (uts), id proses (pid), jaringan dan pengguna. Daftar ini diusulkan untuk dilengkapi dengan dua ruang nama tambahan: waktu dan syslog, tetapi komunitas Linux belum memutuskan spesifikasi final.
Cgroup memberikan batasan sumber daya perangkat keras, penentuan prioritas, pemantauan dan kontrol aplikasi. Contoh sumber daya perangkat keras yang dapat mereka kontrol adalah prosesor, memori, perangkat, dan jaringan. Saat menggabungkan namespace dan cgroup, kita dapat dengan aman menjalankan beberapa aplikasi pada host yang sama, dengan masing-masing aplikasi di lingkungannya sendiri yang terisolasi - yang merupakan properti fundamental dari container.
Perbedaan utama antara mesin virtual (VM) dan sebuah wadah adalah bahwa mesin virtual adalah virtualisasi pada tingkat perangkat keras, dan wadah itu adalah virtualisasi pada tingkat sistem operasi. VM hypervisor mengemulasi lingkungan perangkat keras untuk setiap mesin, di mana runtime kontainer pada gilirannya mengemulasi sistem operasi untuk setiap objek. Mesin virtual berbagi perangkat keras fisik host, dan wadah berbagi perangkat keras dan inti OS. Karena kontainer umumnya berbagi lebih banyak sumber daya dengan host, pekerjaan mereka dengan siklus penyimpanan, memori dan CPU jauh lebih efisien daripada dengan mesin virtual. Namun, kelemahan dari akses bersama ini adalah masalah dalam bidang keamanan informasi, karena terlalu banyak kepercayaan dibangun antara wadah dan tuan rumah. Gambar 1 menggambarkan perbedaan arsitektur antara wadah dan mesin virtual.
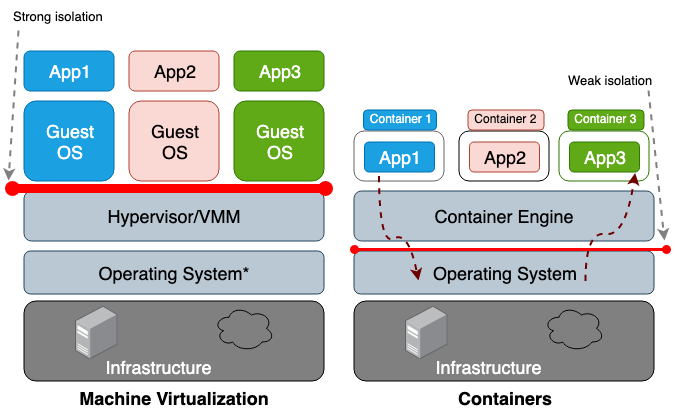
Secara umum, isolasi peralatan tervirtualisasi menciptakan perimeter keamanan yang jauh lebih kuat daripada hanya isolasi namespace. Risiko bahwa penyerang berhasil meninggalkan proses yang terisolasi jauh lebih tinggi daripada kemungkinan berhasil meninggalkan mesin virtual. Alasan untuk risiko yang lebih tinggi melampaui lingkungan wadah yang terbatas adalah isolasi yang buruk yang dibuat oleh namespace dan cgroups. Linux mengimplementasikannya dengan mengaitkan bidang properti baru dengan setiap proses. Bidang-bidang ini dalam sistem file
/proc menunjukkan ke sistem operasi host apakah satu proses dapat melihat proses lainnya, atau berapa banyak sumber daya prosesor / memori yang dapat digunakan proses tertentu. Saat melihat proses yang sedang berjalan dan utas dari OS induk (misalnya, perintah atas atau ps), proses wadah terlihat seperti yang lain. Biasanya, solusi tradisional, seperti LXC atau Docker, tidak dianggap sepenuhnya terisolasi karena mereka menggunakan inti yang sama dalam host yang sama. Oleh karena itu, tidak mengherankan bahwa wadah memiliki jumlah kerentanan yang cukup. Misalnya, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123, dan CVE-2019-5736 dapat mengakibatkan penyerang mendapatkan akses ke data di luar wadah.
Sebagian besar eksploitasi kernel membuat vektor untuk serangan yang berhasil, karena biasanya menghasilkan eskalasi hak istimewa dan memungkinkan proses yang dikompromikan untuk mendapatkan kendali di luar namespace yang dimaksud. Selain menyerang vektor dalam konteks kerentanan perangkat lunak, konfigurasi yang tidak tepat juga dapat berperan. Misalnya, menyebarkan gambar dengan hak istimewa yang berlebihan (CAP_SYS_ADMIN, akses istimewa) atau titik pemasangan kritis (
/var/run/docker.sock ) dapat mengakibatkan kebocoran. Mengingat konsekuensi yang berpotensi bencana ini, Anda harus memahami risiko yang Anda ambil saat menggunakan sistem di ruang multi-penyewa atau saat menggunakan wadah untuk menyimpan data sensitif.
Masalah-masalah ini memotivasi para peneliti untuk menciptakan batas keamanan yang lebih kuat. Idenya adalah untuk membuat wadah kotak pasir nyata yang terisolasi dari OS utama mungkin. Sebagian besar solusi ini termasuk pengembangan arsitektur hybrid yang menggunakan perbedaan ketat antara aplikasi dan mesin virtual, dan berfokus pada peningkatan efisiensi solusi kontainer.
Pada saat penulisan, tidak ada satu proyek pun yang bisa disebut cukup matang untuk diterima sebagai standar, tetapi di masa depan, pengembang tidak diragukan lagi akan menerima beberapa konsep ini sebagai yang utama.
Kami memulai tinjauan kami dengan Unikernel, sistem terspesialisasi yang tertua yang mengemas aplikasi ke dalam satu gambar menggunakan set minimal pustaka OS. Konsep Unikernel sendiri terbukti sangat mendasar bagi banyak proyek yang tujuannya adalah untuk menciptakan gambar yang aman, ringkas dan optimal. Setelah itu, kami akan mempertimbangkan IBM Nabla, proyek untuk meluncurkan aplikasi Unikernel, termasuk kontainer. Selain itu, kami memiliki Google gVisor, sebuah proyek untuk meluncurkan kontainer di ruang kernel pengguna. Selanjutnya, kami akan beralih ke solusi wadah berdasarkan mesin virtual - Amazon Firecracker dan OpenStack Kata. Untuk merangkum posting ini dengan membandingkan semua solusi di atas.
Kernel yang unik
Perkembangan teknologi virtualisasi telah memungkinkan kami untuk pindah ke cloud computing. Hypervisor seperti Xen dan KVM telah meletakkan dasar bagi apa yang sekarang kita kenal sebagai Amazon Web Services (AWS) dan Google Cloud Platform (GCP). Dan meskipun hypervisor modern mampu bekerja dengan ratusan mesin virtual yang digabungkan menjadi satu cluster, sistem operasi tradisional untuk tujuan umum tidak terlalu diadaptasi dan dioptimalkan untuk bekerja di lingkungan seperti itu. OS tujuan umum dimaksudkan, pertama-tama, untuk mendukung dan bekerja dengan berbagai aplikasi sebanyak mungkin, oleh karena itu kernel mereka mencakup semua jenis driver, perpustakaan, protokol, penjadwal dan sebagainya. Namun, sebagian besar mesin virtual yang sekarang digunakan di suatu tempat di cloud digunakan untuk menjalankan satu aplikasi, misalnya, untuk menyediakan DNS, proxy, atau semacam database. Karena aplikasi tunggal semacam itu hanya mengandalkan pekerjaannya pada bagian OS kernel yang spesifik dan kecil, semua "rok" lainnya hanya memboroskan sumber daya sistem, dan dengan fakta keberadaannya menambah jumlah vektor untuk serangan potensial. Memang, semakin besar basis kode, semakin sulit untuk menghilangkan semua kekurangan, dan semakin banyak kerentanan potensial, kesalahan dan kelemahan lainnya. Masalah ini mendorong para spesialis untuk mengembangkan sistem operasi yang sangat terspesialisasi dengan serangkaian fungsi kernel minimum, yaitu untuk membuat alat untuk mendukung satu aplikasi spesifik.
Untuk pertama kalinya, gagasan Unikernel lahir kembali di tahun 90-an. Lalu ia mengambil bentuk sebagai gambar khusus dari mesin dengan ruang alamat tunggal yang dapat bekerja secara langsung pada hypervisor. Ini mengemas aplikasi inti dan kernel-dependen dan fungsi menjadi satu gambar. Nemesis dan Exokernel adalah dua versi penelitian paling awal dari proyek Unikernel. Proses pengemasan dan penyebaran ditunjukkan pada Gambar 2.
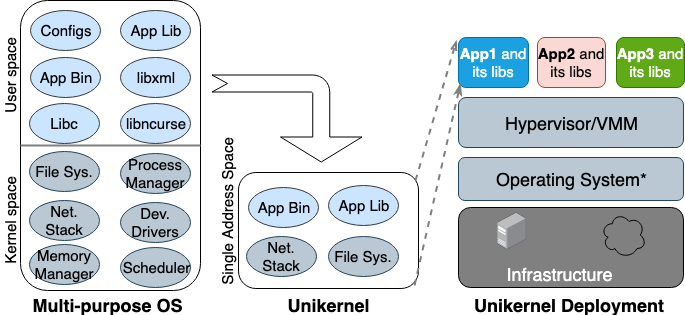 Gambar 2. Sistem operasi multiguna yang dirancang untuk mendukung semua jenis aplikasi, sehingga banyak perpustakaan dan driver dimuat di muka. Unikern adalah sistem operasi yang sangat khusus yang dirancang untuk mendukung satu aplikasi spesifik.
Gambar 2. Sistem operasi multiguna yang dirancang untuk mendukung semua jenis aplikasi, sehingga banyak perpustakaan dan driver dimuat di muka. Unikern adalah sistem operasi yang sangat khusus yang dirancang untuk mendukung satu aplikasi spesifik.
Unikernel memecah kernel menjadi beberapa perpustakaan dan hanya menempatkan komponen yang diperlukan ke dalam gambar. Seperti mesin virtual biasa, unikernel menyebarkan dan berjalan di VM hypervisor. Karena ukurannya yang kecil, dapat memuat dengan cepat dan juga menskalakan dengan cepat. Fitur terpenting dari Unikernel adalah peningkatan keamanan, jejak kecil, optimasi tingkat tinggi, dan pemuatan cepat. Karena gambar-gambar ini hanya berisi pustaka yang bergantung pada aplikasi, dan shell OS tidak dapat diakses jika tidak terhubung dengan sengaja, jumlah vektor serangan yang dapat digunakan oleh penyerang sangat minim.
Artinya, tidak hanya sulit bagi penyerang untuk mendapatkan pijakan di inti unik ini, tetapi pengaruh mereka juga terbatas pada satu contoh inti. Karena ukuran gambar Unikernel hanya beberapa megabyte, mereka diunduh dalam puluhan milidetik, dan ratusan contoh dapat dijalankan pada satu host. Menggunakan alokasi memori dalam satu ruang alamat alih-alih tabel halaman bertingkat, seperti halnya di sebagian besar sistem operasi modern, aplikasi unikernel memiliki penundaan akses memori yang lebih rendah dibandingkan dengan aplikasi yang sama yang berjalan pada mesin virtual biasa. Karena aplikasi datang bersama-sama dengan kernel ketika membangun gambar, kompiler hanya dapat melakukan pemeriksaan tipe statis untuk mengoptimalkan file biner.
Unikernel.org memiliki daftar proyek unikernel. Tetapi dengan semua fitur dan propertinya yang khas, unikernel tidak banyak digunakan. Ketika Docker mengakuisisi Unikernel Systems pada 2016, komunitas memutuskan bahwa perusahaan sekarang akan mengemas kontainer di dalamnya. Namun tiga tahun telah berlalu, dan masih belum ada tanda-tanda integrasi. Salah satu alasan utama untuk implementasi yang lambat ini adalah bahwa masih belum ada alat yang matang untuk membuat aplikasi Unikernel, dan sebagian besar aplikasi ini hanya dapat bekerja pada hypervisor tertentu. Selain itu, porting aplikasi ke unikernel mungkin memerlukan penulisan ulang kode secara manual dalam bahasa lain, termasuk penulisan ulang pustaka kernel yang bergantung. Penting juga bahwa pemantauan atau debugging di unikernels tidak mungkin atau berdampak signifikan pada kinerja.
Semua pembatasan ini mencegah pengembang beralih ke teknologi ini. Perlu dicatat bahwa unikernel dan container memiliki banyak properti yang serupa. Baik yang pertama maupun yang kedua adalah gambar yang sangat terfokus, yang berarti bahwa komponen di dalamnya tidak dapat diperbarui atau diperbaiki, yaitu, Anda selalu harus membuat gambar baru untuk tambalan aplikasi. Hari ini, Unikernel mirip dengan leluhur Docker: maka runtime kontainer tidak tersedia, dan pengembang harus menggunakan alat dasar untuk membangun lingkungan aplikasi yang terisolasi (chroot, unshare, dan cgroups).
Ibm nabla
Suatu ketika, para peneliti dari IBM mengusulkan konsep "Unikernel sebagai proses" - yaitu, aplikasi unikernel yang akan berjalan sebagai proses pada hypervisor khusus. Proyek IBM “Nabla container” memperkuat batas keamanan unikernel, menggantikan hypervisor universal (misalnya, QEMU) dengan pengembangannya sendiri yang disebut Nabla Tender. Alasan di balik pendekatan ini adalah bahwa panggilan antara unikernel dan hypervisor masih menyediakan vektor serangan terbanyak. Itulah sebabnya penggunaan hypervisor yang didedikasikan untuk unikernel dengan lebih sedikit panggilan sistem yang diizinkan dapat secara signifikan memperkuat perimeter keamanan. Nabla Tender mencegat panggilan yang unikernel merutekan ke hypervisor, dan telah menerjemahkannya ke dalam permintaan sistem. Pada saat yang sama, kebijakan Linux seccomp memblokir semua panggilan sistem lain yang tidak diperlukan agar Tender berfungsi. Dengan demikian, Unikernel dalam hubungannya dengan Nabla Tender berjalan sebagai proses di ruang pengguna host. Di bawah ini, pada gambar # 3, ditunjukkan bagaimana Nabla membuat antarmuka tipis antara unikernel dan host.
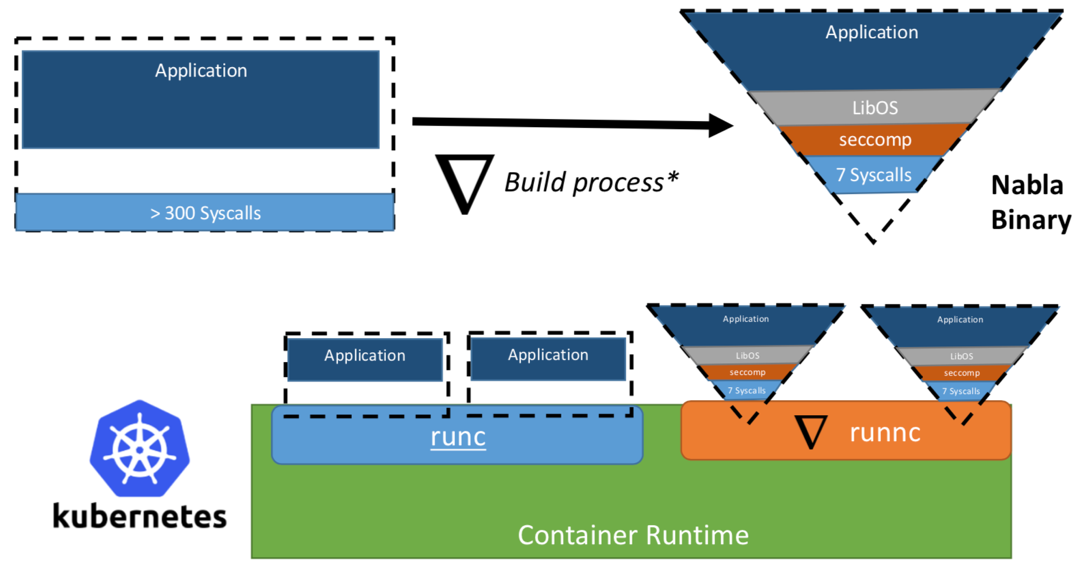 Gambar 3. Untuk menghubungkan Nabla dengan platform runtime kontainer yang ada, Nabla menggunakan lingkungan yang kompatibel dengan OCI, yang pada gilirannya dapat dihubungkan ke Docker atau Kubernetes.
Gambar 3. Untuk menghubungkan Nabla dengan platform runtime kontainer yang ada, Nabla menggunakan lingkungan yang kompatibel dengan OCI, yang pada gilirannya dapat dihubungkan ke Docker atau Kubernetes.Pengembang mengklaim bahwa Nabla Tender menggunakan kurang dari tujuh panggilan sistem dalam pekerjaannya untuk berinteraksi dengan tuan rumah. Karena panggilan sistem berfungsi sebagai semacam jembatan antara proses di ruang pengguna dan kernel dari sistem operasi, semakin sedikit panggilan sistem yang tersedia bagi kami, semakin kecil jumlah vektor yang tersedia untuk menyerang kernel. Keuntungan lain dari menjalankan unikernel sebagai proses adalah Anda dapat men-debug aplikasi seperti itu menggunakan banyak alat, misalnya, menggunakan gdb.
Untuk bekerja dengan platform orkestrasi wadah, Nabla menyediakan
runnc khusus yang diimplementasikan menggunakan standar Open Container Initiative (OCI). Yang terakhir mendefinisikan API antara klien (mis. Docker, Kubectl) dan lingkungan runtime (mis., Runc). Nabla juga dilengkapi dengan konstruktor gambar yang nantinya akan dapat dijalankan oleh
runnc . Namun, karena perbedaan dalam sistem file antara unikernels dan wadah tradisional, gambar Nabla tidak memenuhi spesifikasi gambar OCI dan, oleh karena itu, gambar Docker tidak kompatibel dengan
runnc . Pada saat penulisan, proyek ini masih dalam tahap awal pengembangan. Ada batasan lain, misalnya, kurangnya dukungan untuk pemasangan / mengakses sistem file host, menambahkan beberapa antarmuka jaringan (diperlukan untuk Kubernetes), atau menggunakan gambar dari gambar kernel unik lainnya (misalnya, MirageOS).
Google gVisor
Google gVisor adalah teknologi sandbox menggunakan Mesin Aplikasi Platform Google Cloud (GCP), fitur cloud, dan CloudML. Pada titik tertentu, Google menyadari risiko menjalankan aplikasi yang tidak tepercaya di infrastruktur cloud publik dan ketidakefisienan aplikasi kotak pasir menggunakan mesin virtual. Akibatnya, kernel ruang-pengguna dikembangkan untuk lingkungan terisolasi dari aplikasi yang tidak dapat diandalkan tersebut. gVisor menempatkan aplikasi ini di kotak pasir, mencegat semua panggilan sistem dari mereka ke kernel host dan memprosesnya di lingkungan pengguna menggunakan kernel Sentry gVisor. Pada dasarnya, ini berfungsi sebagai kombinasi dari inti tamu dan hypervisor. Gambar 4 menunjukkan arsitektur gVisor.
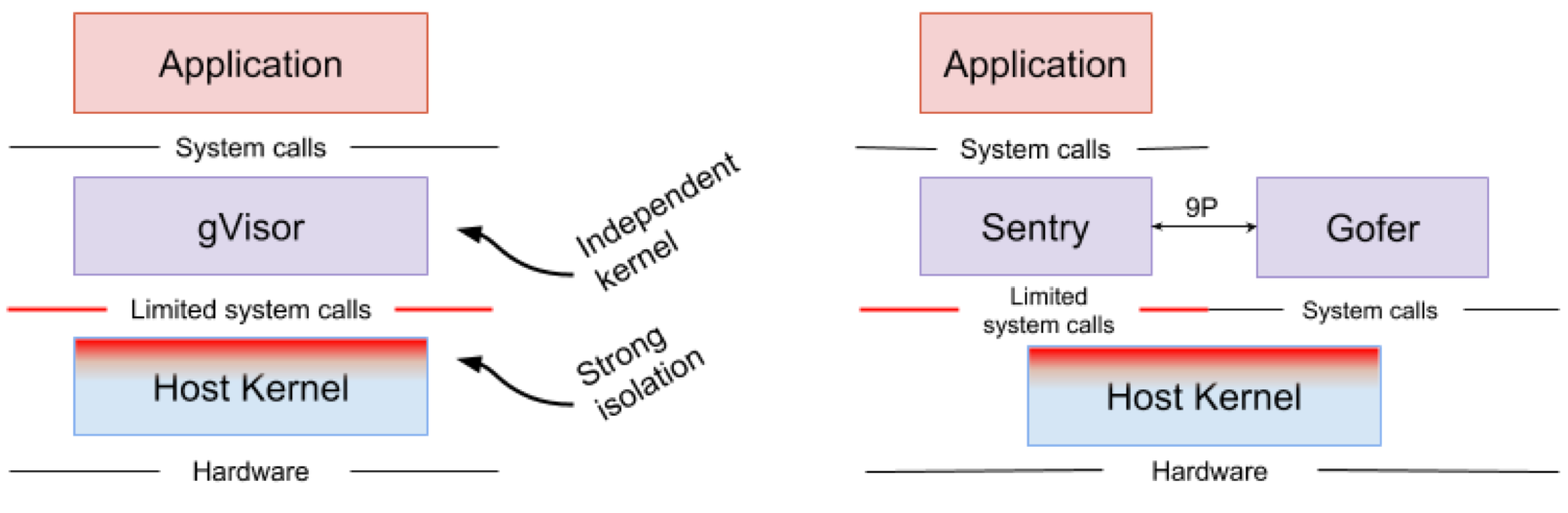 Gambar 4. Implementasi kernel gVisor // Sistem file Sentry dan gVisor Gofer menggunakan sejumlah kecil panggilan sistem untuk berinteraksi dengan host
Gambar 4. Implementasi kernel gVisor // Sistem file Sentry dan gVisor Gofer menggunakan sejumlah kecil panggilan sistem untuk berinteraksi dengan hostgVisor menciptakan perimeter keamanan yang kuat antara aplikasi dan inangnya. Ini membatasi panggilan sistem yang dapat digunakan aplikasi dalam ruang pengguna. Tanpa mengandalkan virtualisasi, gVisor berfungsi sebagai proses host yang berinteraksi antara aplikasi yang berdiri sendiri dan sebuah host. Sentry mendukung sebagian besar panggilan sistem Linux dan fitur inti kernel seperti pengiriman sinyal, manajemen memori, tumpukan jaringan, dan model streaming. Sentry mengimplementasikan lebih dari 70% dari 319 panggilan sistem Linux untuk mendukung aplikasi berpasir. Namun, Sentry menggunakan kurang dari 20 panggilan sistem Linux untuk berinteraksi dengan kernel host. Perlu dicatat bahwa gVisor dan Nabla memiliki strategi yang sangat mirip: melindungi OS host dan kedua solusi ini menggunakan kurang dari 10% panggilan sistem Linux untuk berinteraksi dengan kernel. Tetapi Anda perlu memahami bahwa gVisor menciptakan kernel multi-fungsi, dan, misalnya, Nabla mengandalkan kernel yang unik. Pada saat yang sama, kedua solusi meluncurkan kernel tamu khusus di ruang pengguna untuk mendukung aplikasi terisolasi yang dipercaya oleh mereka.
Seseorang mungkin bertanya-tanya mengapa gVisor membutuhkan kernelnya sendiri, ketika kernel Linux sudah open source dan mudah diakses. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
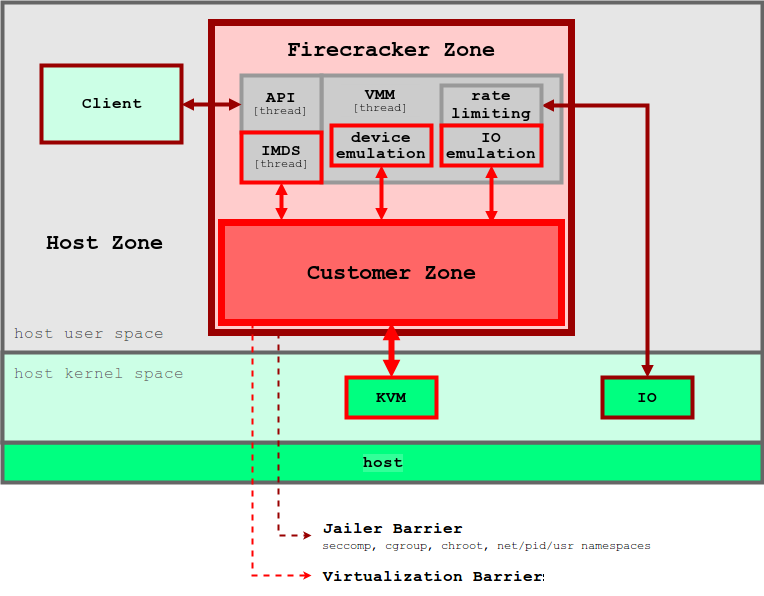 5. Firecracker
5. FirecrackerFirecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
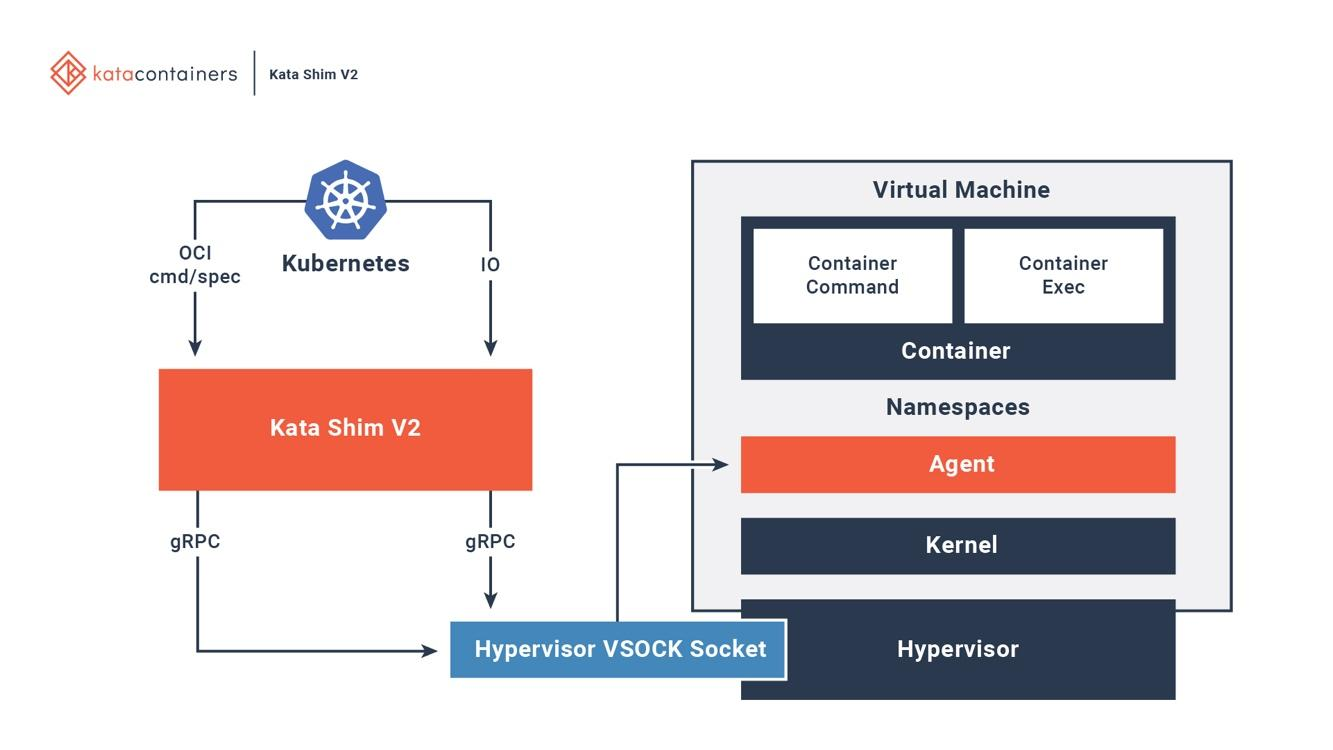 6. Kata Docker Kubernetes
6. Kata Docker KubernetesKata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Kesimpulan
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
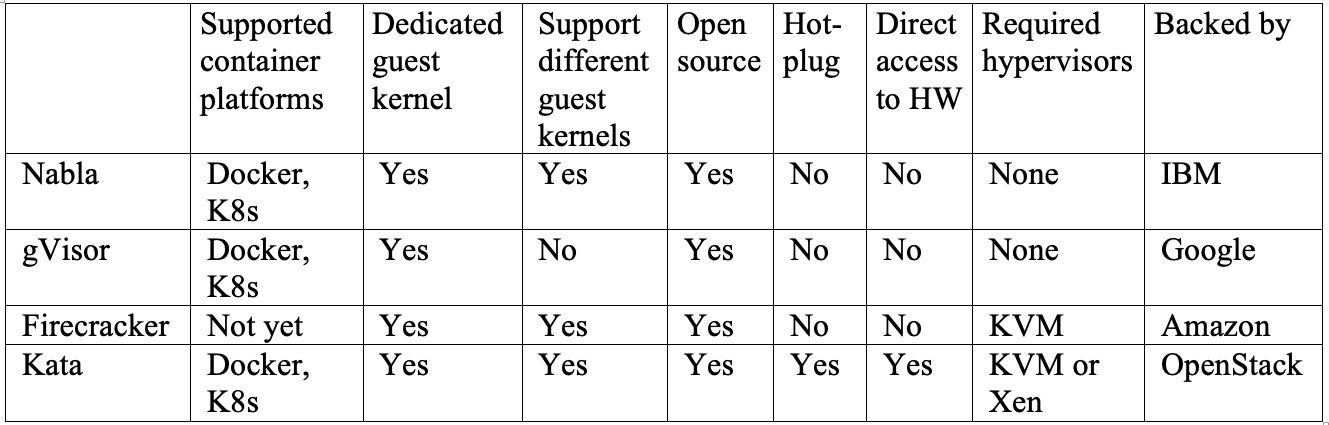
, , , , .