Ekosistem TensorFlow berisi sejumlah penyusun dan pengoptimal yang bekerja di berbagai tingkat tumpukan perangkat lunak dan perangkat keras. Bagi mereka yang menggunakan Tensorflow setiap hari, tumpukan multi-level ini dapat menghasilkan kesalahan yang sulit dipahami, baik waktu kompilasi dan runtime, terkait dengan penggunaan berbagai jenis perangkat keras (GPU, TPU, platform seluler, dll.)
Komponen-komponen ini, dimulai dengan grafik Tensorflow, dapat direpresentasikan dalam bentuk diagram seperti itu:
 Ini sebenarnya lebih sulit
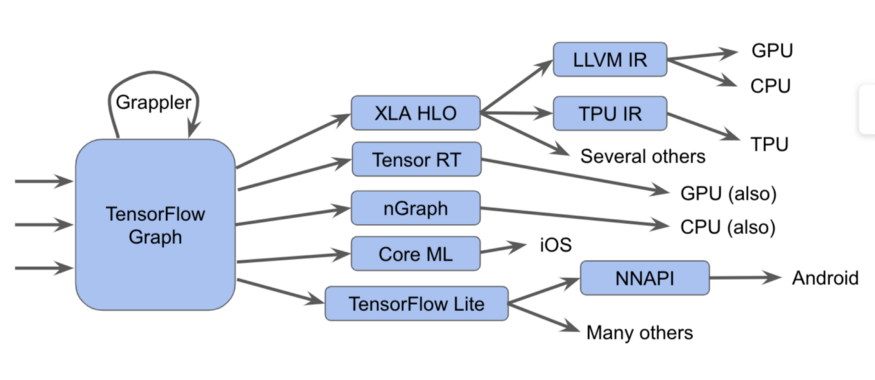
Ini sebenarnya lebih sulitDalam diagram ini, kita dapat melihat bahwa grafik Tensorflow dapat dijalankan dalam beberapa cara berbeda.
sebuah catatanDalam TensorFlow 2.0, grafik dapat tersirat, eksekusi serakah dapat menjalankan operasi secara individu, dalam kelompok, atau pada grafik penuh. Grafik atau fragmen grafik ini harus dioptimalkan dan dieksekusi.
Sebagai contoh:
- Kami mengirim grafik ke pelaksana Tensorflow, yang menyebut kernel tulisan tangan khusus
- Konversikan ke XLA HLO (Representasi Pengoptimal Tingkat Tinggi XLA) - representasi pengoptimal XLA tingkat tinggi, yang, pada gilirannya, dapat memanggil kompiler LLVM untuk CPU atau GPU, atau terus menggunakan XLA untuk TPU , atau menggabungkannya.
- Kami mengonversinya menjadi TensorRT , nGraph , atau format lain untuk set instruksi khusus yang diimplementasikan dalam perangkat keras.
- Kami mengonversinya ke format TensorFlow Lite , berjalan di runtime TensorFlow Lite, atau dikonversi ke kode untuk dijalankan pada GPU atau DSP melalui Android Neural Networks API (NNAPI) atau sejenisnya.
Ada juga metode yang lebih kompleks, termasuk banyak optimasi yang dilakukan pada setiap layer, seperti, misalnya, dalam kerangka Grappler, yang mengoptimalkan operasi di TensorFlow.
Meskipun berbagai implementasi dari kompiler dan representasi perantara ini meningkatkan kinerja, keberagamannya menimbulkan masalah bagi pengguna akhir, seperti pesan kesalahan yang membingungkan saat memasangkan subsistem ini. Juga, pencipta tumpukan perangkat lunak dan perangkat keras baru harus menyesuaikan bagian pengoptimalan dan konversi untuk setiap kasus baru.
Dan berdasarkan semua ini, kami dengan senang hati mengumumkan MLIR, Perwakilan Intermediate Multi-Level. Ini adalah format tampilan menengah dan pustaka kompilasi untuk digunakan antara tampilan model dan kompiler tingkat rendah yang menghasilkan kode yang bergantung pada perangkat keras. Memperkenalkan MLIR, kami ingin memberi jalan kepada penelitian baru dalam pengembangan optimalisasi penyusun dan implementasi penyusun berdasarkan komponen kualitas industri.
Kami berharap MLIR menarik bagi banyak kelompok, termasuk:
- peneliti kompiler, serta praktisi yang ingin mengoptimalkan kinerja dan konsumsi memori model pembelajaran mesin;
- produsen perangkat keras mencari cara untuk mengintegrasikan perangkat keras mereka dengan Tensorflow, seperti TPU, neuroprosesor seluler di telepon pintar, dan ASIC khusus lainnya;
- orang-orang yang ingin memberikan bahasa pemrograman manfaat yang diberikan dengan mengoptimalkan kompiler dan akselerator perangkat keras;
Apa itu MLIR?
MLIR pada dasarnya adalah infrastruktur fleksibel untuk kompiler optimisasi modern. Ini berarti bahwa itu terdiri dari spesifikasi representasi perantara (IR) dan seperangkat alat untuk mengubah representasi ini. Ketika kita berbicara tentang kompiler, pindah dari tampilan level yang lebih tinggi ke tampilan level yang lebih rendah disebut menurunkan, dan kita akan menggunakan istilah ini di masa depan.
MLIR dibangun di bawah pengaruh LLVM dan tanpa malu meminjam banyak ide bagus darinya. Ini memiliki sistem tipe yang fleksibel, dan dirancang untuk mewakili, menganalisis dan mengubah grafik, menggabungkan banyak level abstraksi dalam satu level kompilasi. Abstraksi ini termasuk operasi Tensorflow, daerah loop polyhedral bersarang, instruksi LLVM, dan operasi dan tipe titik tetap.
Dialek-dialek MLIR
Untuk memisahkan berbagai target perangkat lunak dan perangkat keras, MLIR memiliki "dialek", termasuk:
- TensorFlow IR, yang mencakup semua yang dapat dilakukan dalam grafik TensorFlow
- XLA HLO IR, dirancang untuk mendapatkan semua manfaat yang disediakan oleh kompiler XLA, output yang kita bisa dapatkan kode untuk TPU, dan tidak hanya.
- Dialek afinitas eksperimental yang dirancang khusus untuk representasi dan optimisasi polihedral
- LLVM IR, 1: 1 cocok dengan tampilan LLVM asli, memungkinkan MLIR untuk menghasilkan kode untuk GPU dan CPU menggunakan LLVM.
- TensorFlow Lite dirancang untuk menghasilkan kode untuk platform seluler
Setiap dialek berisi serangkaian operasi tertentu, menggunakan invarian, seperti: "itu adalah operator biner, dan input dan outputnya dari jenis yang sama."
Ekstensi MLIR
MLIR tidak memiliki daftar operasi intrinsik global tetap dan built-in. Dialek dapat mendefinisikan tipe kustom sepenuhnya, dan karenanya MLIR dapat memodelkan hal-hal seperti sistem tipe LLVM IR (memiliki agregat kelas satu), abstraksi bahasa domain, seperti tipe terkuantisasi, penting untuk akselerator yang dioptimalkan ML, dan, di masa depan, bahkan sistem tipe Swift atau Dentang.
Jika Anda ingin melampirkan kompiler tingkat rendah baru ke sistem ini, Anda dapat membuat dialek baru dan turun dari dialek grafik TensorFlow ke dialek Anda. Ini menyederhanakan jalur untuk pengembang perangkat keras dan pengembang kompiler. Anda dapat menargetkan dialek ke berbagai tingkat model yang sama, pengoptimal tingkat tinggi akan bertanggung jawab untuk bagian IR tertentu.
Untuk peneliti kompiler dan pengembang kerangka kerja, MLIR memungkinkan Anda membuat transformasi di setiap level, Anda dapat menentukan operasi dan abstraksi Anda sendiri di IR, memungkinkan Anda untuk memodelkan tugas aplikasi Anda dengan lebih baik. Dengan demikian, MLIR lebih dari sekedar infrastruktur kompiler murni, seperti LLVM.
Meskipun MLIR berfungsi sebagai kompiler untuk ML, MLIR juga memungkinkan penggunaan teknologi pembelajaran mesin! Ini sangat penting bagi para insinyur yang mengembangkan perpustakaan numerik, dan tidak dapat memberikan dukungan untuk beragam model dan perangkat keras ML. Fleksibilitas MLIR membuatnya lebih mudah untuk mengeksplorasi strategi untuk penurunan kode ketika berpindah antar level abstraksi.
Apa selanjutnya
Kami telah membuka
gudang GitHub dan mengundang semua orang yang tertarik (lihat panduan kami!). Kami akan merilis sesuatu yang lebih dari kotak alat ini - spesifikasi dialek TensorFlow dan TF Lite, dalam beberapa bulan mendatang. Kami dapat memberi tahu Anda lebih banyak, untuk mengetahui lebih lanjut, lihat
presentasi oleh Chris Luttner dan
README kami
di Github .
Jika Anda ingin mengikuti semua hal yang berkaitan dengan MLIR, bergabunglah dengan
milis baru kami, yang akan segera fokus pada pengumuman rilis proyek kami di masa depan. Tetap bersama kami!